08:00 입실
오전에 CSAPP 6장 빠르게 정리하기!
CSAPP 6. 메모리 계층구조
레지스터는 0 사이클로 접근 가능
캐시는 4~75 사이클
메인 메모리는 수 백 사이클
디스크는 수 천만 사이클
6.1 저장장치 기술
초기 컴퓨터의 램은 겨우 몇 킬로바이트
최초의 PC는 하드 디스크도 없었음.
1982년 10메가 바이트 디스크(하드디스크)
6.1.1 랜덤 접근 메모리
1. 정적 램(SRAM)
- 동적램보다 훨씬 빠르고 더 비쌈.
- 캐시 메모리로 사용
- 일반적인 데스트톱에서 수십 메가
- 이중안정 메모리 셀에 비트를 저장
- 각 셀은 여섯 개의 트랜지스터 회로로 구성
- 전원 공급되는 한 무한히 유지, 외란(외부환경 방해요인: 빛, 전기적 잡음)에도 안정적임
- 트랜지스터를 더 많이 사용하므로 집적도가 낮고, 비싸고, 전력 소모가 많음.
2. 동적 램(DRAM)
- 메인메모리
- 그래픽 시스템 프레임 버퍼
- 일반적인 데스트톱에서 수천 메가
- 비트를 전하로 캐패시터에 저장
- 각 셀은 캐패시티 하나, 접근 트랜지스터 하나로 구성
- 외란(외부환경 방해요인)에 민감
- 햇볕에 노출되면 캐패시터 전압이 변함 -> 회복 불가
- 디카, 캠코더 센서는 실질적으로 DRAM 셀 배열임.
- 시간이 지나면 전하가 누수되며, 주기적으로 메모리의 모든 비트를 읽었다가 다시 써 주는 방식으로 리프레시 해야 한다.
- 트랜지스터를 더 적게 사용하므로 집적도가 높고, 싸고, 전력 소모가 적음.
3. 일반 DRAM
램은 2차원 배열 형태로 되어 있다.(행, 열)
그래서 비트를 전송할 때 행 주소와 열 주소를 차례로 보낸다.
2차원 배열 형태로 구성하는 이유는 핀 주소를 절반으로 줄일 수 있음.
(선형 배열 형태로 구성했다면 핀 수가 2배로 늘어 남.)
왜 선형 배열은 주소 핀 수가 2배 더 많이 필요하나?
GPT에 나오지 않아서 나름대로 생각해봄
예를 들어 16개의 셀의 주소를 나타내는 핀에서 2차원 배열로 하면 최대(3, 3)의 주소가 나옴.
그럼 2비트로 해당 주소를 모두 표현할 수 있음. 즉, 2개의 주소 핀으로 표현할 수 있음.
(단, 주소 전송은 2번 해야 됨.)
근데 이걸 선형 배열로 하면 0~15까지의 주소를 표현해야 하니까, 4비트가 필요함.
그래서 주소핀이 4개가 필요한 게 아닐까?
정리하면 주소 핀은 1개 당 1개의 비트는 처리해서 그런 거 아닐까?
비휘발성 메모리
ROM(Read only memory)
사실 재기록될 수도 있지만 역사적인 이유로 그냥 읽기 전용이라고 불림.
근데 PROM(Programmable ROM)은 진짜 한 번만 프로그램됨. 셀에 높은 전류가 흐르면 끊어지는 일종의 퓨즈가 있음.
플래시 메모리가 EEPROM(Erasable programmable ROM) 기반의 비휘발성 메모리다.
ROM에 저장된 소프트웨어를 펌웨어라고 함.
메인 메모리 접근
버스: 공유된 전기 회로. 주소, 데이터, 제어신호를 포함하는 병렬 선들의 집합
선은 같은 선을 공유할 수도, 다른 선을 사용할 수 도 있다.
CPU와 메모리 간 전송을 버스 트랜잭션이라고 함.
읽기 트랜잭션: 데이터가 메인 메모리 -> CPU로 이동
쓰기 트랜잭션: 데이터가 CPU -> 메인 메모리로 이동
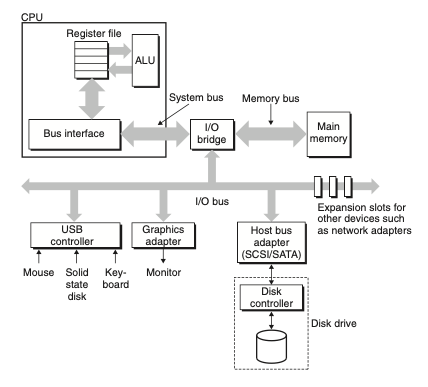
I/O 브릿지는 시스템 버스의 전기적 신호를 메모리 버스의 전기적 신호로 변환
읽기 트랜잭션 과정
movq A,%rax
주소 A의 내용이 %rax에 로드된다.
CPU내 버스 인터페이스 회로가 버스에서 읽기 트랜잭션 개시
1. CPU가 주소 A를 시스템 버스에 보내고 I/O브릿지가 신호를 메모리 버스를 따라 보낸다.
2. 메인메모리가 메모리 버스에서 주소 신호 감지, 메모리 버스로부터 주소를 읽고, DRAM에서 데이터 워드 선입, 데이터를 메모리 버스에 쓴다. I/O브릿지가 메모리 버스 신호를 시스템 버스 신호로 변환해서 시스템 버스로 넘겨 준다.
3. CPU가 시스템 버스에서 데이터를 감지하고, 버스에서 데이터를 읽어서 레지스터에 복사한다.
쓰기 트랜잭션 과정
movq %rax,A
%rax 내용을 주소 A에 기록한다.
CPU가 쓰기 트랜잭션을 개시
1. CPU는 주소를 시스템 버스에 보내고, 메모리는 메모리 버스에서 주소를 읽고 데이터가 도착하기를 기다림
2. CPU가 %rax에 있는 데이터를 시스템 버스에 복사함.
3. 메인메모리가 데이터를 메모리 버스에서 읽고 비트를 DRAM에 저장
6.1.2 디스크 저장장치
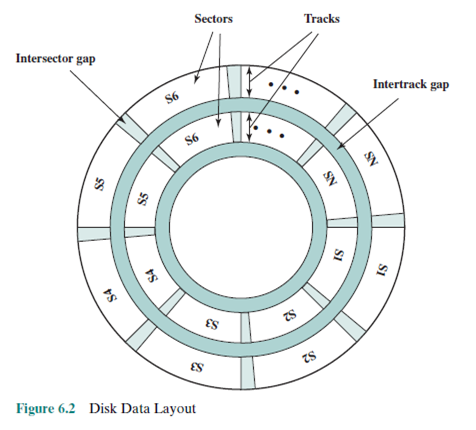
트랙별로 섹터 수를 동일하게 하면 바깥쪽이 더 낭비 아닌가?
(바깥 쪽이 비트가 밀도가 낮게 저장됨)
맞음! 그래서 초기에는 데이터 밀집도가 높지 않을 때는 문제가 없었는데,
밀집도가 높아진 지금은 낭비되는 공간이 많아짐.
그래서 이렇게 바뀜.(다중 영역 레코딩)
DMA vs PIO
I/O 버스는 시스템 버스, 메모리 버스보다는 느리지만 타사의 광범위한 I/O 디바이스에 연결 가능
시스템 버스, 메모리 버스는 CPU에 특화됨.
디바이스(주변 장치)가 CPU 개입 없이 스스로 읽기, 쓰기 버스 트랜잭션을 수행하는 과정을 직접 메모리 접근(DMA)
DMA는 하드웨어
DMA가 필요한 이유는?
디스크는 진짜 느린 장치이다.(인스트럭션이 1600개 실행될 정도의 시간)
그래서 일종의 CPU 대행자처럼 DMA가 디스크(또는 주변장치)와 메인 메모리 간의 트랜잭션을 대행해 준다.
굳이 CPU를 거치지 않으니 CPU는 단순 메모리 트랜잭션은 DMA에게 넘겨주고, 자기는 더 중요한 일(?)을 한다.
(DMA의 반대는 PIO(프로그램 입출력), 입출력이 CPU를 경우하는 것)
6.1.3 Solid State Disks(SSD)
회전하는 디스크 대체품
플래시 메모리를 사용(반도체 메모리)
6.1.4 저장장치 기술 동향
요약: CPU 발전 속도를 메모리 발전 속도가 따라가지 못하는 중
즉, CPU와 메모리 사이의 속도 차이는 점점 더 벌어짐.
그래서 현대 컴퓨터는 프로세서-메모리 속도 차이를 극복하기 위해 SRAM 기반 캐시를 사용함.
6.2 지역성
시간 지역성
최근 액세스 메모리 위치에 다시 액세스할 가능성이 높다.
예) 동일 변수를 계속 사용하는 것, for문에서의 i
공간 지역성
메모리 위치 주변의 데이터에 액세스할 가능성이 높다.
예) 배열 순회
좋은 소프트웨어란 좋은 지역성을 가지고 있다!
6.3 메모리 계층 구조
메모리 계층 구조 핵심 개념
K레벨의 저장 장치가 K+1(하위)레벨에 있는 저장장치를 위한 캐시 서비스를 제공하는 것!
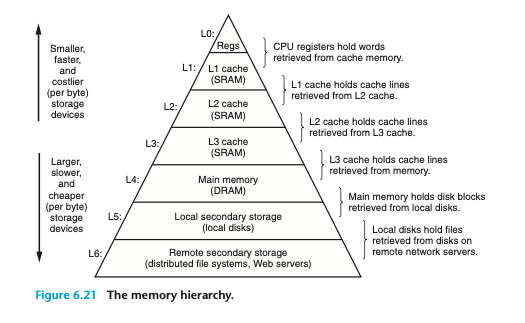
메모리 계층에서 클라우드는 생각도 못했는데..
로컬 디스크가 클라우드의 캐시가 될 수 있다!
하위로 내려갈 수록 접근시간이 길어지기 때문에 더 큰 블록을 사용한다.
인접 계층끼리는 같은 블록 단위를 사용한다.
예를 들어,
L1 <-> L0은 워드 크기 블록,
L2 <-> L1은 수십 바이트 블록,
L5 <-> L4는 수백, 수천 바이트 블록
캐시
캐시 적중(히트)
K+1 레벨에 있는 데이터가 필요한 상황에서 K레벨을 먼저 접근했을 때
우연히 그 데이터가 있는 경우
캐시 미스
캐시 적중의 반대.
캐시 미스라면 K+1에서 K로 데이터를 가지고 옴.
K가 이미 꽉 찬 상태라면 덮어쓰기를 함.
이때 덮어씌여지는 블록을 희생블록이라고 함.
(희생블록을 선정하는 여러 정책이 있음)
캐시 미스의 종류
콜드 캐시: 캐시 자체가 비어있어서 모든 캐시 접근이 미스가 되는 경우
충돌 미스: 여러 데이터, 명령어가 동일 캐시 라인에 접근할 때
용량 미스: 캐시 메모리 용량 부족, 캐시에 더 많은 데이터를 저장하려고 할 때
캐시 히트를 높이기 위해서 이차원 배열 탐색 시,
[행][열]에서 열을 탐색하고, 행을 탐색하는 방법은 공간 지역성에서 나쁜 영향을 준다.
(행이 지역적으로 가까운 데이터이기 때문에 행부터 탐색해야 한다.)
6.4 캐시 메모리
L1 캐시: 약 4클럭
L2 캐시: 약 10클럭
L3 캐시: 약 50클럭
6.4.6 캐시 계층구조
캐시는 데이터만 저장하는 게 아니다.
인스트럭션도 저장할 수 있다.
인스트럭션만 보관하는 캐시는 i-cache라고 부른다.
현재 프로세서는 i-cache와 d-cache를 가지고 있다.
이렇게 캐시가 분리되어 있으면 인스트럭션 워드와 데이터 워드를 동시에 읽을 수 있다.
i-cache는 보통 읽기만 허용되며 더 단순하다.
근데 cpu가 i-cache에 명령어를 저장한다고 하는데.. 그럼 쓰기도 허용하는 거 아니야?
저장과 쓰기는 다른 개념이다. 저장은 어떤 데이터를 보간, 기록하는 작업.
쓰기는 데이터를 변경하거나 업데이트하는 과정.
메모리 할당 정책
1. first fit(최초 적합)
가용공간 중 첫 번째 공간에 할당
1-1. next fit
최초 적합 방식의 변형으로, 지난 번 검색이 끝난 곳에서부터 시작해서 가용공간 중 첫 번째 공간에 할당
2. best fit(최적 적합)
가용 공간 중 크기 차이가 가장 적은 곳을 선택. 가용 공간이 정렬되어 있지 않다면 전체를 검색해야 함.
3. worst fit(최악 적합)
가용 공간 중 가장 큰 것을 선택. 할당 후 남은 공간을 크게 해서 다른 프로세스들이 사용할 수 있게 처리.
정렬되어 있지 않다면 전체를 검색해야 함.
최초, 최적 적합이 시간 효율성, 공간 효율성 측면에서 최악 적합보다 좋다는 것이 입증 되었음.
스캐닝 이슈로 인해 일반적으로 최초 적합이 최적 적합보다 성능이 뛰어남.
가상 메모리
컴퓨터에서 이용 가능한 기억 자원을 이상적으로 추상화하여 사용자들에게 큰 메모리로 보이게 만드는 기술.
가상 메모리는 일부는 물리 메모리, 일부는 디스크에 맵핑된다.
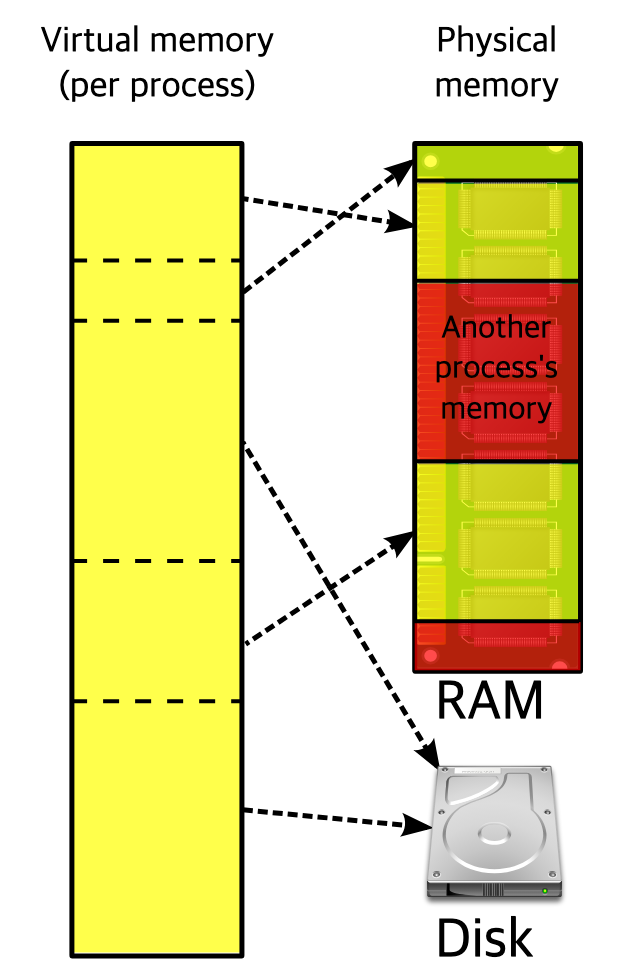
- 가상 주소 공간이 있다.
- 페이지 파일이 있다.
- 가상 메모리는 페이지 단위, 물리 메로리는 프레임 단위로 구성된다.(일반적으로 4, 8KB 단위)
- 페이지 교체가 일어난다.
- 페이지 테이블 자료 구조가 존재한다.(가상 주소 <-> 물리 주소)
쉽게 표현하면, 프로그램한테 '이 컴퓨터의 물리 메모리 너가 다 써!' 라고 꾸며내는 것(추상화)
진짜로 다 쓰려고 하면 그때그때 디스크에 있는 데이터를 메모리로 올려서 진짜로 다 쓰는 것처럼 속임.
단편화(끊을 단, 조각 편)
fragmentation: 분열
단편화: 기억 장치 또는 자료가 여러 개의 조각으로 나뉘는 현상
내부 단편화, 외부 단펴화는 그 전에 공부함!
요약하면 내부 단편화는 블록 내부에 안 쓰는 공간이 낭비되는 것.
외부 단편화는 조각난 메모리 공간을 모으면 프로세스 실행이 충분한데,
조각들이 흝어져 있어서 프로세스 할당이 불가능 한 것.
페이징
메모리를 고정 크기 블록인 페이지로 분할하는 방법
가상 주소는 순서쌍(p, d)로 나타낼 수 있음.
p는 페이지 번호, d는 페이지 p내에서 참조될 수 있는 항목이 위치하는 변위
(d = distance)
프레임: 물리 메모리를 일정 크기로 나눈 블록
페이지: 가상 메모리를 일정 크기로 나눈 블록
페이지 크기는 x86, amd64에서는 4KB, i64에서는 8KB(i64는 단종된 듯?)
프레임을 할당받지 못한 페이지는 디스크에 저장된다!
프레임과 페이지 크기는 동일함.
페이징의 핵심은 페이지 교체와 프레임 할당
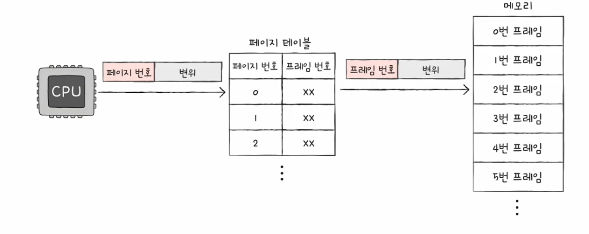
페이지 테이블
페이징 기법에서 사용되는 자료 구조
하나의 프로세스는 하나의 페이지 테이블을 가진다.
가상 메모리의 가상 주소와 물리 메모리의 물리 주소를 연결시켜 주는 테이블
페이지 테이블이 있어서 CPU는 물리적으로 불연속적으로 할당된 메모리를
마치 연속적으로 배치된 것처럼 추상화해서 접근할 수 있다.
p는 해당 프로세스가 가지고 있는 페이지 테이블의 위치,
그곳에서 변위(d)만큼을 더하면 프레임(물리 메모리 주소)를 알 수 있다.
페이지 테이블 각각의 행을 페이지 엔트리라고 하고, 다양한 필드가 저장되어 있다.
(필드 세부 내용은 하단 기재)
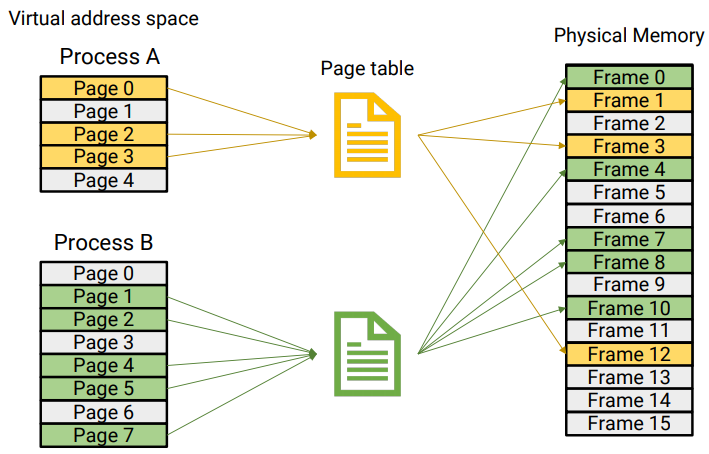

페이지 테이블이 왜 필요할까?
페이징은 기본적으로 프로세스를 쪼개서 메모리에 불연속 할당을 한다.
연속 할당이라면 그냥 처음 주소부터 연속적으로 실행하면 되지만,
불연속 할당이면 그게 안 됨.
그럼 CPU입장에서는 쪼개진 데이터가 어디에 위치하는지 알 수가 없다.
이때 페이지 테이블을 통해 가상 주소를 물리 주소로 변환하여 물리 메모리에 있는 데이터에 접근할 수 있다.
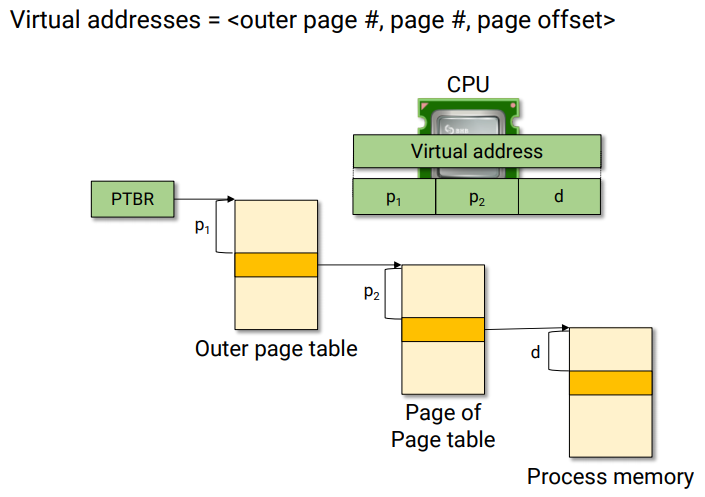
PTBR(Page Table Base Register)
프로세스는 하나의 페이지 테이블을 가진다.
그럼 그 페이지 테이블 위치는 어디에 저장되냐?
바로 PTBR 레지스터!
물리 메모리 시작 주소에 페이지 주소를 결합해서 물리 메모리 주소를 알 수 있음!
운영체제도 프로세스니까 자신만의 페이지 테이블이 있음!(커널 메모리 영역)
동적 주소 변환
1. 프로세스가 가상 주소 V(p, d)를 참조한다.
2. 페이지 p가 프레임 p'에 있음을 알아낸다.(p'는 물리 메모리 시작 주소)
3. 실주소 r = p' + d를 구한다.
가상 메모리와 물리 메모리를 매핑 시키는 하드웨어가 MMU(Memory Management Unit)
페이지 테이블 엔트리(PTE)
페이지 테이블의 레코드(페이지 테이블의 각각의 행)
- 페이지 기본 주소(Page base address)
- 플래그 비트
- 접근 비트(Accessed bit): 페이지에 대한 접근이 있었는지- 변경 비트(Dirty bit): 페이지 내용의 변경이 있었는지
- 존재 비트(Present bit): 페이지가 실제 물리 메모리에 적재되어 있는지
- 읽기/쓰기 비트(Read/Write bit): 읽기/쓰기에 대한 권한 표시
테이지 테이블은 메모리에 적재되어 있기 때문에 느리다
기본적으로 페이지 테이블을 이용하려면,
페이지 테이블에 접근할 때 메모리 접근 1회,
이후 가져온 주소로 다시 메모리 접근 1회, 총 2회 메모리 접근이 발생한다.
그래서 TLB(Translation Lookaside Buffer, TLB, 변환 색인 버퍼)
라는 페이지 테이블의 캐시 메모리에 일부 페이지를 저장한다.
TLB히트, TLB 미스 개념이 있음.
히트면 메모리에 1번만 접근, 미스면 메모리에 2번 접근해야 한다.

VPN: Virtual Page Number(가상 페이지 번호)
PFN: Page Frame Number(물리 메모리의 프레임 번호)
Other bits: valid bit, protection bit, recently bit, dirty bit, ASID
스왑 인 & 아웃
스왑 인(페이지 인): 디스크에서 메모리로 데이터 적재
스왑 아웃(페이지 아웃): 메모리에 적재될 필요가 없는 페이지를 디스크로 아웃
페이지 교체 알고리즘
페이지 폴트가 발생하면 기존 페이지를 스왑해야 한다.
이때 어떤 기준으로 어떤 페이지를 아웃할 것인가?
1. FIFO
가장 단순한 방식
메모리에 가장 먼저 올라온 페이지부터 스왑 아웃
2. 최적 페이지 교체
앞으로 남은 CPU 참조 시점을 기준으로
미래에 가장 늦게 참조될 페이지를 먼저 페이지 아웃
성능이 가장 좋지만(페이지 폴트가 적게 일어나지만)
구현이 어렵다. (미래를 예측해야 됨.)
3. LRU(Least Recently Used)
최적 페이지 교체의 변형
가장 오래 전에 참조한 페이지를 페이지 아웃
스레싱
프로세스, 스레드 할 때의 스레드와 스펠링이 다름(thread vs thrashing)
프로세스가 실행되는 시간보다 페이징에 더 많은 시간을 소요하여 CPU 이용률이 저해되는 문제.
CPU이용률이 현저하게 떨어지는 시점이 '스레싱이 발생한' 시점임.
요약하면 페이지 폴트가 증가하여 CPU 이용률이 급격하게 떨어지는 현상
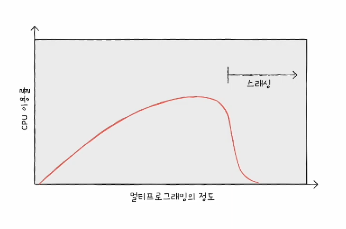
스레싱은 동시 프로세스 수를 늘린다고 해서 CPU 이용률이 높아지는 건 아님을 의미함.
왜냐면 프로세스가 많아지면 페이지 폴트가 그에 비례해서 더 많이 늘어나니까.
스레싱이 왜 발생할까?
각 프로세스가 필요로 하는 최소한의 프레임 수가 보장되지 않음.
해결책: 프로세스별로 필요한 최소한의 프레임 수를 파악하고, 프로세스에게 적절한 프레임을 할당해야 함.
프레임 할당
스레싱을 해결하려면 프로세스별로 최적의 프레임을 할당해야 한다.
정적 할당 방식: 프로세스 실행 전에 프레임 할당
1. 균등 할당
모든 프로세스들에게 균등하게 프레임을 할당
2. 비례 할당
프로세스 크기에 비례해서 프레임을 할당
실행이 아닌 단순 프로세스 크기를 기준으로 할당한다.
프로세스 별로 필요한 프레임은 크기가 아닌 실행 해봐야 정확히 산정할 수 있음.
동적 할당 방식: 프로세스 실행 중에 프레임 할당
3. 작업 집합 모델
작업 집합: 실행 중인 프로세스가 일정 시간 동안 참조한 페이지의 집합
실행 과정에서 배분할 프레임 결정
CPU가 특정 시간 동안 주로 참조한 페이지 개수만큼 프레임 할당
4. 페이지 폴트 빈도 기반
페이지 폴트율이 낮으면 프레임이 적다는 의미
페이지 폴트율이 높으면 프레임이 많다는 의미
작동 방식 요약
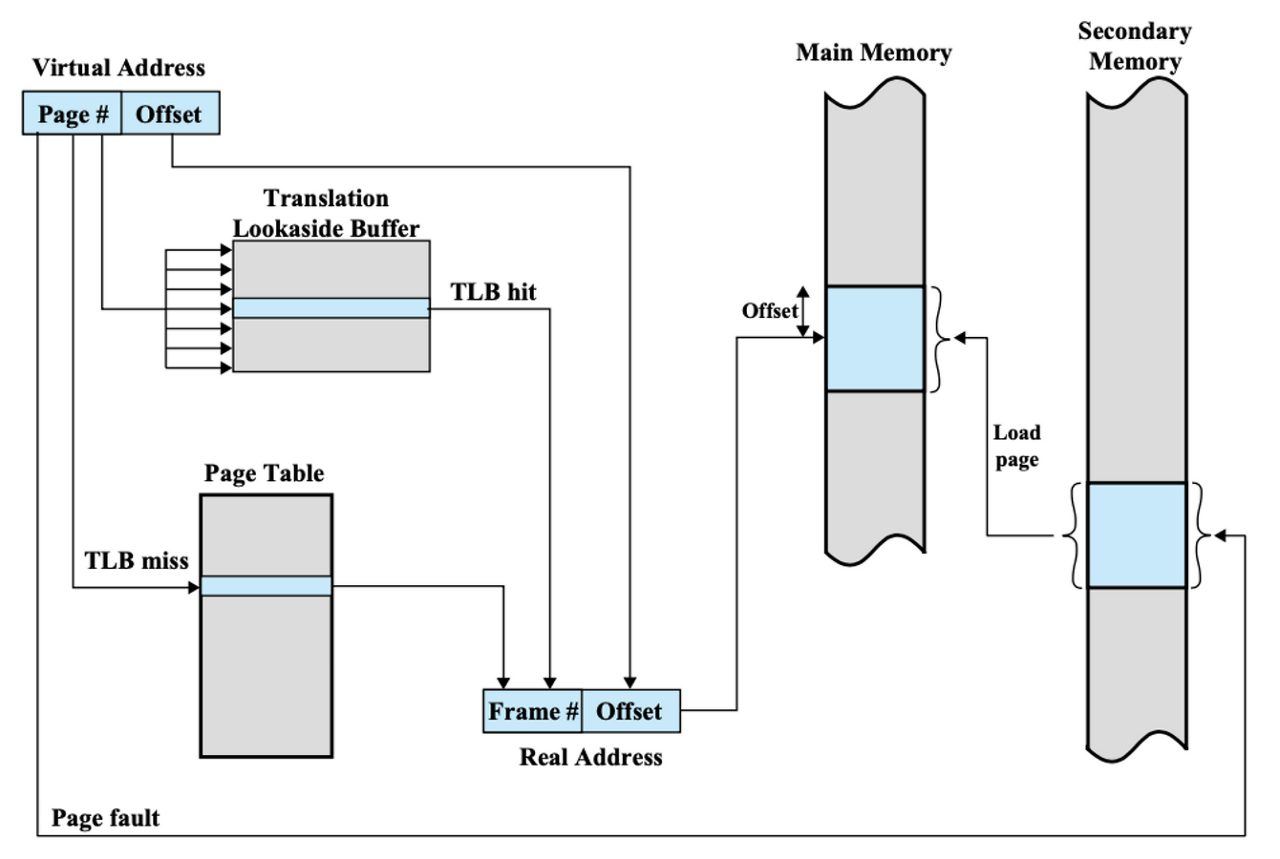
- MMU가 TLB에서 테이블 엔트리 찾음
2-1. TLB에서 테이블 엔트리 찾으면(히트) 프레임 번호 반환 -> 4로 이동
2-2. 못 찾으면(미스) 메모리 상의 페이지 테이블에 접근 후 테이블 엔트리 찾음 - PTE를 TLB에 적재 -> TLB 히트 -> 4로 이동
- Frame Number와 Offset 결합해서 물리 메모리 접근
출처: https://hojunking.tistory.com/119
쓰기 시 복사
Fork 시 자식 프로세스는 우선 부모 프로세스를 가리키고,
자식 프로세스가 쓰기 작업을 하면 그때 복사본을 생성
부모 프로세스의 페이지를 당분간 함께 사용하도록 하는 것.
둘 중 한 프로세스가 공유중인 페이지에 쓸 때 그 페이지의 복사본이 만들어 지는 것.
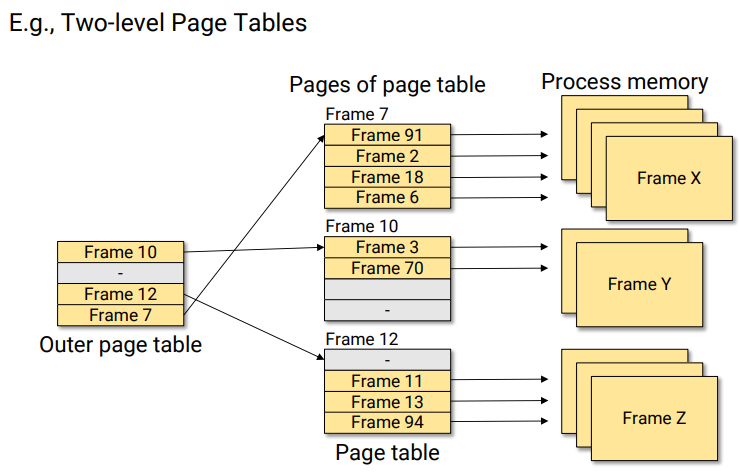
계층적 페이징
프로세스가 크면 페이지 테이블 자체가 커질 수 있다.
이때 계층적 페이지로 페이지 테이블의 페이지 테이블을 담는 것
최상단(아웃터) 페이지 테이블만 메모리에 올라가 있고,
다음 계층 페이지는 디스크에 적재. 필요할 때 스왑 인으로 메모리에 적재
계층적 페이징은 페이지 테이블 자체를 페이징 하는 것
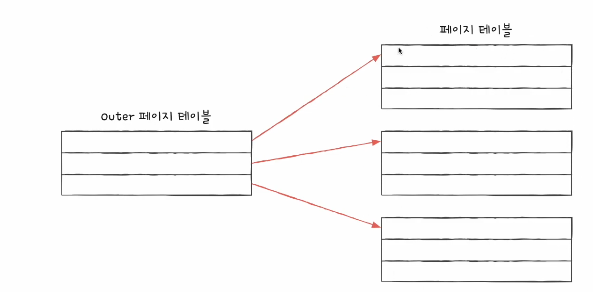
동적 메모리 할당
메모리 구조(feat. 힙)
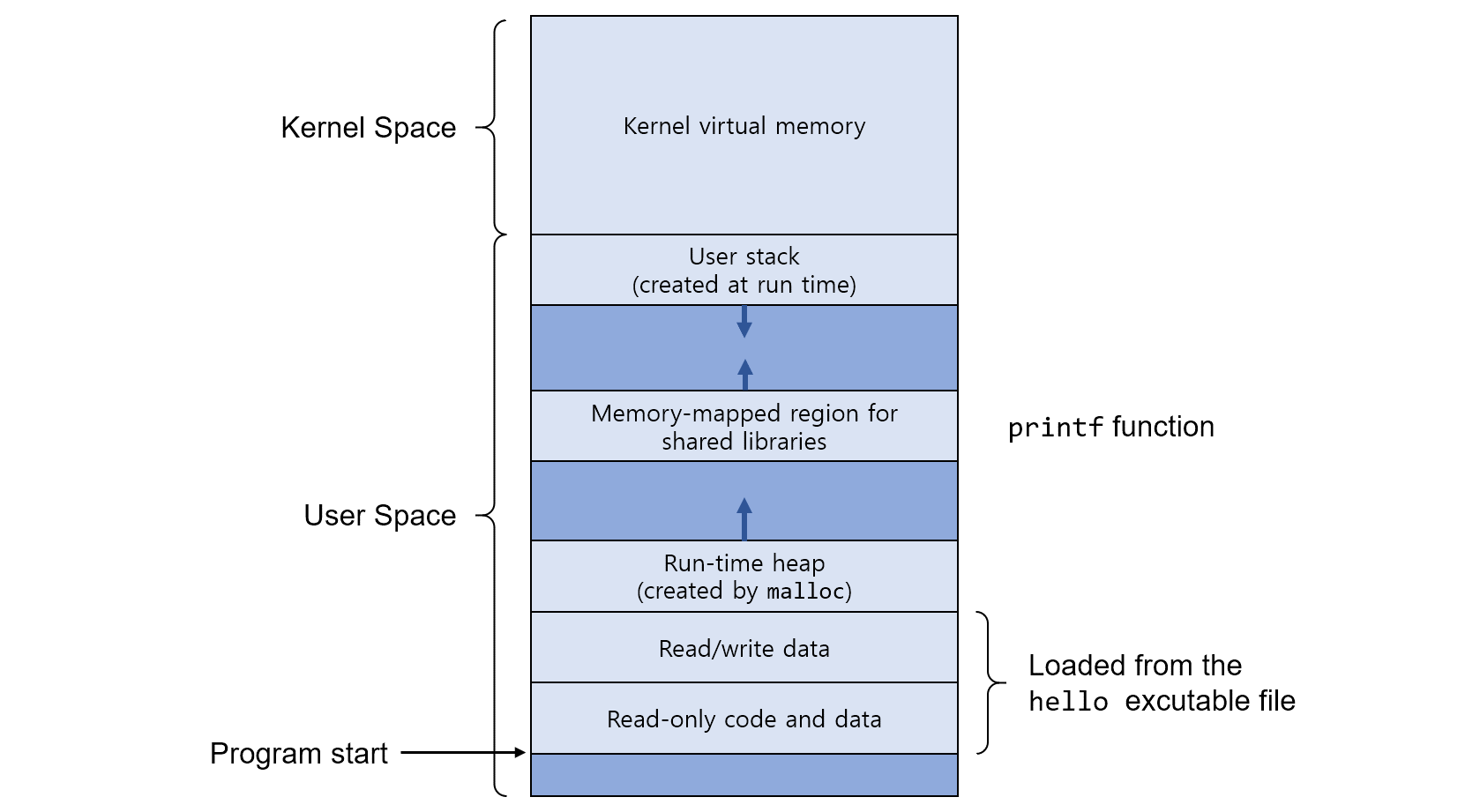
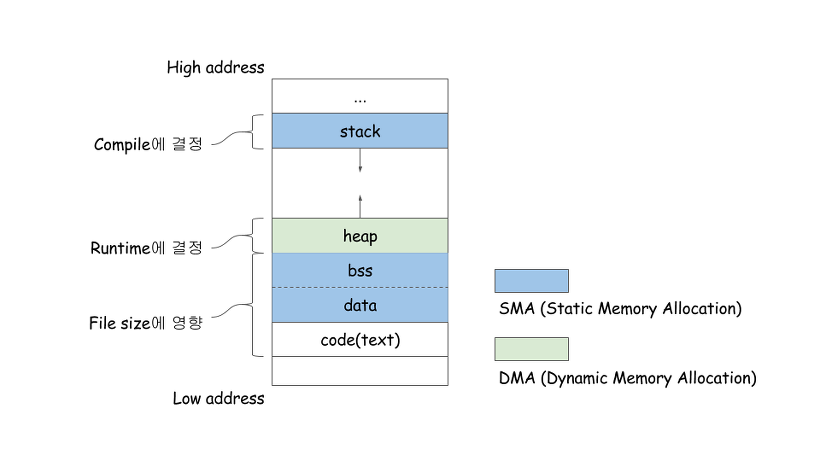
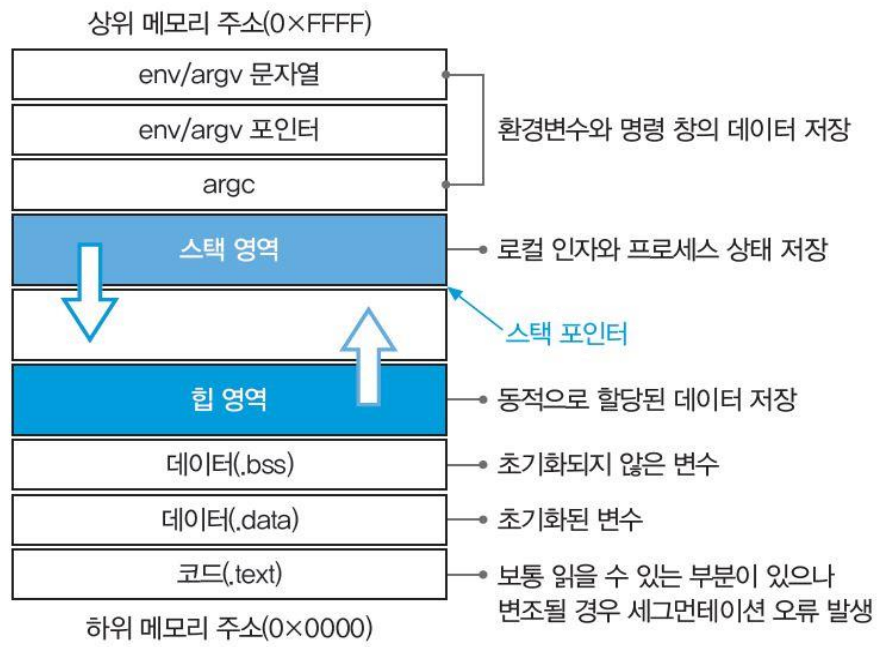
코드(code, 텍스트)영역
프로세스가 실행할 코드
매크로 상수
Read-Only 영역
데이터(Datea)영역
전역 변수
정적 변수
Read-Write 영역(실행 도중에 전역 변수 변경 가능)
세부적으로 다음 영역으로 나뉨
- 데이터(.bss, Block Started by Symbol): 초기화되지 않은 전역 변수 및 정적 변수. 초기값이 없어므로 프로그램 시작될 때 0 또는 기본 값으로 초기화.
- 데이터(.data): 초기화된 전역 변수 및 정적 변수. 프로그램 시작 시 초기값 가지고 있음.
왜 초기화 여부로 데이터 공간을 나누나?
프로세스가 실행될 때 가상 메모리 생성 시 .bss 세그먼트는 0으로 일괄 초기화 함.
.data 영역은 코드에 따라 지정된 초기값으로 초기화 함.
스택(Stack)영역
프로그램 동작을 위한 인자(Argument)
프로세스 상태 저장
레지스터 임시 저장
서브루틴 복귀 주소(Return Address)
서브루틴 인자 전달 값
저장한 값이 호출 완료되면 사라짐.
상위 주소 -> 하위 주소 방향으로 성장
후입선물(LIFO)
(서브루틴은 함수라고 보면 됨. 컴퓨터 수준에서 보는 함수)
함수가 호출되면 스택에 스택 프레임이 쌓임.
스택 프레임에는 로컬 변수, 인자, 반환주소, 이전 프레임 포인터가 저장됨.
스택은 함수 호출과 복귀를 관리하는데 사용된다.
스택은 함수 호출과 관련된 메모리 영역이라고 이해하면 됨.
함수가 호출되지 않으면 스택에는 스택 프레임이 쌓이지 않음.
힙(Heap)
- 동적 메모리 할당을 위한 영역
- 사용자가 직접 메모리를 할당하고 해제할 수 있는 공간
- 동적 할당 데이터는 힙에 저장됨(동적 배열, 구조체, 클래스, 문자열)
- 가변적인 양의 데이터 저장을 위해 프로세스가 사용할 수 있도록 예약된 메인 메모리
- 힙이 부족하면 메모리 부족으로 프로세스 비정상 종료
힙에 할당되는 메모리 블록 구조
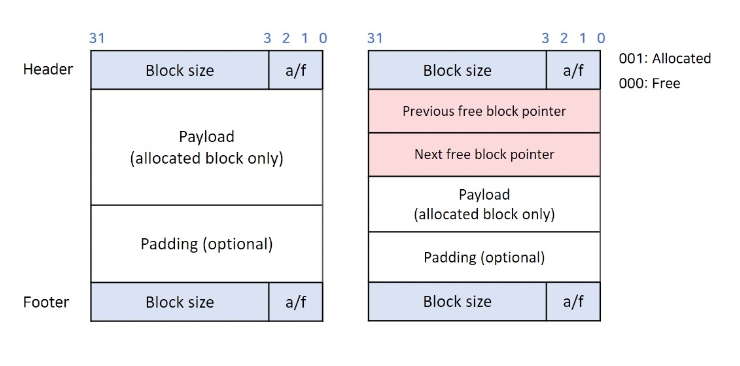
왼쪽은 묵시적 해제 리스트를 쓸 때, 오른쪽은 명시적 해제 리스트를 쓸 때
sbrk(set break)
"끝을 설정한다."
개념
unix계열에서 사용되는 기본 메모리 관리 시스템 콜
증감 바이트를 하나의 인수로 받는다.
프로세스의 힙 메모리 공간에서 데이터 세그먼트 크기 조절하는데 사용
프로그램의 데이터 공간을 늘리거나 줄임(양수면 증가, 음수면 감소)
sbrk로 조절하면 처음 지정은 누가 하냐? brk가 함.
동작 원리
데이터 세그먼트 조정 후 이전 끝을 가리키는 포인터를 반환
대체
sbrk가 있지만 malloc, calloc, free와 같은 현대적인 메모리 할당 함수에 밀림
sbrk 현대적인 프로그래밍 관행에서는 권장되지 않음.
sbrk와 brk 차이
원래 brk가 쓰이다가 sbrk가 확장판으로 등장.
brk는 단순히 데이터 세그먼트 끝을 설정. brk의 인수로 메모리 주소가 들어감.
brk로 끝을 설정하고, sbrk로 확장, 축소가 가능.
brk로 끝을 지정하면 시작은 어떻게 지정함?
이전 데이터 세그먼트의 다음 주소가 시작점이 됨.
그래서 임의로 시작점을 지정하려면 먼저 brk를 호출하고, 그 다음 다시 brk를 호출하면 그 전 지정된 값의 다음 주소부터 지정할 수 있음.
mmap(memory map)
개념
unix계열에서 사용되는 파일, 기타 객체를 가상 메모리에 매핑하는 기능을 하는 시스템 콜
주요 기능
1. 파일 매핑
2. 읽기 쓰기 권한 설정
3. 공유 메모리
4. 읽기 전용 복사
5. 무작위 액세스
realloc
malloc, calloc 개념은 공부했고 RB Tree에서 구현해 봤음!
realloc은 realloc(arr, sizeof(int) * 10); 처럼 기존 메모리의 주소를 증감할 수 있다.
이때 드는 의문은 '그럼 메모리를 늘리다가 연속된 공간을 넘어서면 어떡하지?'
정답은 realloc은 기본적으로 인자의 메모리 주소를 기준으로 증감 작업을 하다가,
메모리 주소가 부족하다면 새로운 메모리 블록을 할당하고 이전 데이터를 복사하고 새로운 주소를 반홤함.
크기를 줄일 때는 나머지 부분의 메모리 주소가 free()되는 것.
brk, sbrk와 malloc, calloc, free와 차이가 뭐지?
brk, sbrk는 c와 무관한 unix계열의 커널 수준의 시스템 콜이다.(저수준 시스템 콜)
반면 malloc, calloc, free는 유저 수준의 함수이다.(고수준 유저 함수)
그래서 malloc, calloc, free 함수를 호출하면 커널 수준에서 brk, sbrk와 같은 시스템 콜이 호출된다.
암시적(묵시적) & 명시적 해제 리스트
둘 다 메모리를 할당 받을 때 할당 가능한 블록이 어디인지 찾기 위한 리스트!
메모리 할당 및 해제를 관리하는 두 가지 주요 방법
두 방법 모두 메모리를 직접 제어하는 방식이다.
(가비지 컬렉터는 메모리 직접 제어가 아님.)
'해제'라는 용어에서 헷갈렸음.
free를 '할당 가능한, 사용할 수 있는'으로 생각하면 이해가 더 잘 됨!
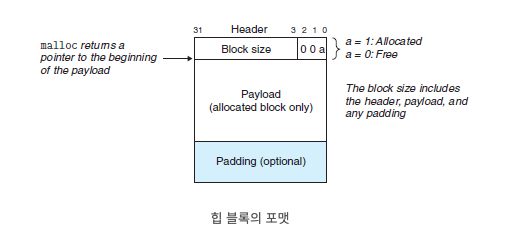
힙으로 메모리를 할당하는 건 블록이 생성되는 거고, 위와 같은 포맷으로 생성되는 것!
즉, 사용자가 요청하는 공간만큼이 페이로드로 생기는 거고
그외의 정보가 담기는 것을 포함해서 블록으로 같이 생성되는 것!
즉, 사용자가 10바이트를 할당받으면 페이로드는 10바이트가 생성되지만,
malloc으로 생성되는 전체 데이터 블록 크기는 10바이트보다 큼!
사용자가 접근할 수 있는 영역은 페이로드 부분임.
정적 할당은 별도의 메타데이터 블록이 필요하지 않다.
하지만 동적 할당은 메모리 재할당, 해제 등의 작업이 필요하기 때문에 메타데이터가 필요하다.
그래서 블록에 페이로드 외에 메타데이터가 들어가는 것!
implicit free list(암시적, 묵시적 해제 목록)
암시적 해제(가용) 목록(implicit)
가용 블록이 헤더 내 필드에 의해서 묵시적으로 연결되어 있기 때문에(CSAPP p.816)
메모리 블록이 해제되면 해당 블록 메타데이터가 자동으로 연결되어 관리
브루트 포스 방식으로 모든 블록을 탐색
블록의 헤더나 푸터에 할당 여부를 나타내는 플래그가 있음.
오버헤드가 적다. 할당 및 해제 작업이 빠르게 수행된다.
메모리 효율성 낮을 수 있음.(외부 단편화 발생 가능성: 메모리 해제가 임의의 순서로 발생)
하나의 거대
왜 암시적(묵시적)이라고 하지?
별도의 리스트로 관리되지 않고 블록 자체적으로 관리되기 때문에 암시적(묵시적)이라고 표현함.
블록 노드에 다음 포인터가 없는데 어떻게 다음 블록으로 이동하지?
그냥 블록 사이즈만큼 옆으로 이동하면 됨.
explicit free list(명시적 해제 목록)
명시적 해제(가용) 목록(explicit)
할당 및 해제된 메모리 블록을 명시적으로 추적
이중 연결 리스트 자료구조로 관리
각 할당 가능 블록에는 다음 할당 가능한 블록 포인터가 있음.
블록 크기에 따라 관리 가능하며 메모리 효율성 향상
관리에 오버헤드가 발생
할당 및 해제 작업이 복잡해짐.
묵시적 해제 리스트는 할당을 할 때 이미 할당된 것도 다 검색해야 하는데,
명시적 해제 리스트는 할당을 할 때 별도의 자료구조에서 해제된 것만 검색할 수 있기 때문에 더 빠르다!
여기서 주의할 점!
명시적 해제 목록은 메모리에 별도의 연결 리스트를 만드는 게 아니다.
할당 메모리 블록에 prev, next free block의 포인터 메타데이터를 추가해서
메모리 블록 자체를 노드로 해서 연결 리스트로 관리하는 것이다!
Demand-zero memory
: 필요할 때 0으로 초기화해서 할당하는 메모리
즉, 여기서 demand는 최초 메모리 할당을 요구 받는 시점이 아닌
메모리에 접근하는 demand가 있을 때 zero로 초기화해서 할당한다는 의미
demand zero memory는 프로세스가 메모리를 요청할 떄 실제 물리적인 페이지가 미할당 상태이지만,
모든 비트가 0으로 초기화된 페이지를 가리킴.
실제 물리 메모리에 할당되지 않았으므로, 요청 메모리 초기화 전까지는 물리 메모리 할당되지 않음.
lazy한 방식으로 초기화된다.(Lazy initialization)
즉 커널한테 메모리 할당해 달라고 하면 커널을 할당 안하고 대충 할당했다고 거짓말을 함.
그 뒤에 진짜로 그 페이지에 뭔가 읽기/쓰기 접근이 이루어지면 그제서야 부랴부랴 할당을 함.
이때 0으로 초기화해서 할당함.
당연히 항상 최초 접근 시에는 페이지 폴트가 발생함.
대신 이 방식은 오버헤드를 최소화하고 메모리 사용을 효율적으로 할 수 있음.
메모리 할당과 초기화는 비용이 듦.
초기화를 미뤄서 만약 나중에 안 쓰인다면 오버헤드를 줄일 수 있는 것.
즉 진짜 필요한 페이지만 초기화하고 물리 메모리에 적재할 수 있음.
malloc으로 동적으로 메모리 할당을 받으면
일반적으로 demand zero memory방식으로 메모리를 할당 받는다!
예전에 파이썬 장고에서 lazy_가 붙은 함수가 있었는데(찾아보니 reverse_lazy, ORM도 lazy하다고 함) lazy한 방식이 프로그래밍에서 범용적으로 쓰이는 용어였음!! 더불어 파이썬의 range도 lazy한 방식으로 사용된다는 걸 알 수 있다!
시스템 콜
system call, syscall
응용 프로그램에서 커널의 서비스를 사용하는 방법이 시스템 호출이다.
시스템을 콜을 요약하면 커널만이 실행할 수 있는 특권 명령어를 응용 소프트웨어가 커널에서 실행해 달라고 요청하는 것
운영체제 커널에 서비스를 요청하고 실행하는 인터페이스 또는 메커니즘
사용자 레벨의 응용 프로그램에서 직접 호출하기 어려운 특수한 기능을 말함.
즉, 응용 프로그램에서 시스템 콜을하면 운영체제 커널이 이 요청을 받아 커널 모드에서 기능을 수행함.
예를 들어 파일 읽고 쓰기, 메모리 할당 해제, 프로세스 생성 등을 시스템 콜을 통해 수행 됨.
시스템 콜을 직접 호출하는 건 어렵고, 고수준 프로그래밍 언어에서 함수로 추상화되어 제공된다.
그런 추상화된 함수를 이용해 시스템 콜을 쉽게 이용할 수 있다.
리눅스에서
man syscalls로 시스템 콜 리스트 확인할 수 있음.
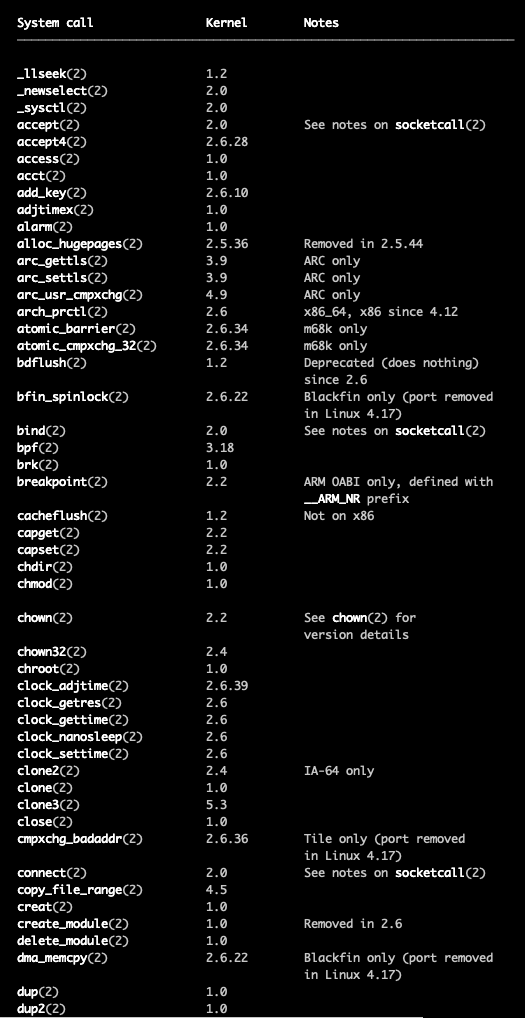
파이썬이나 C로 작성한 코드가 어떻게 시스템 콜을 호출하지?
프로그래밍 언어별로 해당 운영체제에 맞는 API를 구현해서 시스템 콜을 호출한다.
즉, 사용자가 직접 시스템 콜을 호출하는 게 아니라 추상화된 프로그래밍 언어 함수를 통해
시스템 콜을 호출할 수 있다.
DMA(Direct Memory Access)
I/O 버스는 시스템 버스, 메모리 버스보다는 느리지만 타사의 광범위한 I/O 디바이스에 연결 가능
시스템 버스, 메모리 버스는 CPU에 특화됨.
디바이스(주변 장치)가 CPU 개입 없이 스스로 읽기, 쓰기 버스 트랜잭션을 수행하는 과정을 직접 메모리 접근(DMA)
DMA는 하드웨어
DMA가 필요한 이유는?
디스크는 진짜 느린 장치이다.(인스트럭션이 1600개 실행될 정도의 시간)
그래서 일종의 CPU 대행자처럼 DMA가 디스크(또는 주변장치)와 메인 메모리 간의 트랜잭션을 대행해 준다.
굳이 CPU를 거치지 않으니 CPU는 단순 메모리 트랜잭션은 DMA에게 넘겨주고, 자기는 더 중요한 일(?)을 한다.
(DMA의 반대는 PIO(프로그램 입출력), 입출력이 CPU를 경우하는 것)
PIO(Programmed Input/Output) & IIO(Interrupt I/O)
둘 다 CPU를 통한 입출력임. DMA는 CPU 없이 입출력이 이루어지는 것.
PIO
입출력을 프로그램이 직접 제어하는 방식
CPU가 직접 입출력을 제어
소프트웨어 수준에서 입출력이 제어
IIO
입출력을 인터럽트를 통해 제어하는 방식
CPU가 관여하는 건 맞지만 CPU는 우선 디바이스로부터 알림을 받고 필요한 경우에만 작업을 수행
하드웨어 수준에서 입출력이 제어
PIO, IIO, DMA 관계를 정리해 보자.
우선 세 가지 모두 입출력을 어떻게 제어하는지에 관한 방식이다.
PIO는 소프트웨어적인 프로그램을 통해 CPU를 경유해서 입출력을 제어한다.
IIO는 하드웨어적인 인터럽트를 통해 CPU를 경유해서 입출력을 제어한다.
DMA는 하드웨적인 물리 장치로, CPU 중재 없이 디스크와 메인 메모리 사이의 입출력을 제어한다.
이더넷(Ethernet)
네트워크에 연결된 각 기기들이 48비트 길이의 고유한 MAC주소로
상호 간에 데이터 통신을 하는 것에 관한 컴퓨터 네트워크 프로토콜
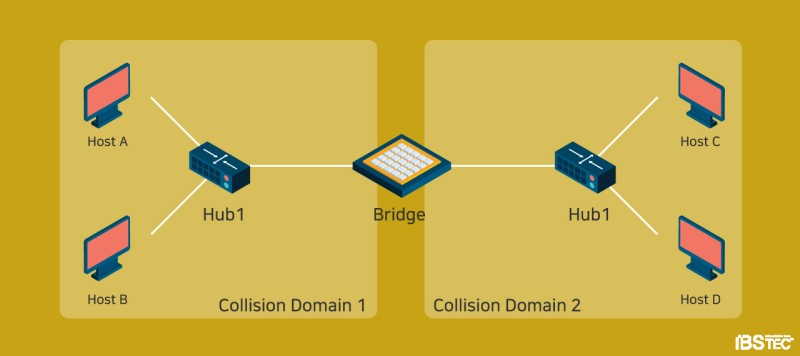
(명칭은 빛의 매질로 여겨졌던 에테르에서 유래되었음.)
이더넷 규격
OSI 7계층 모델로 설명할 수 있음.
물리 계층: 신호와 배선
BNC 케이블, UTP/STP 케이블
연결 장치: 허브, 네트워크 스위치, 리피터
데이터 링크 계층: MAC 패킷, 프로토콜 형식
CSMA/CD 방식(반송파 감지 다중 접속 및 충돌 방지)
-> 약간 대충 눈치껏 알아서 통신하기..느낌. 회선이 비어있으면 데이터 보내기
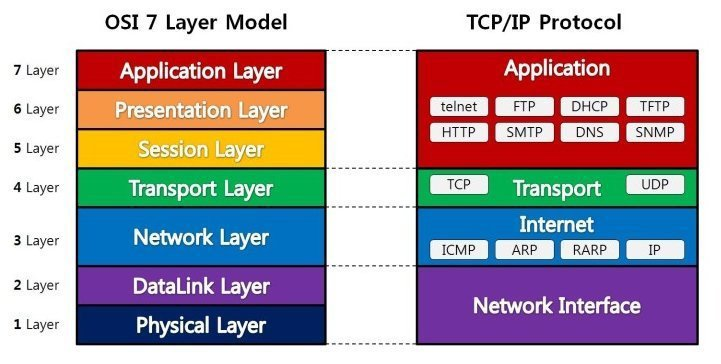
이더넷은 물리 계층, 데이터 링크 계층의 프로토콜이라고 볼 수 있음.
더 위에 http, TCP/IP 등 프로토콜 등 상위 프로토콜이 있으며
이더넷은 비교적 하위 계층의 프로토콜이라고 할 수 있음.
계층별 프로토콜 예시
물리 계층 (Physical Layer):
대표적인 프로토콜: Ethernet, USB, Bluetooth, Wi-Fi
데이터 링크 계층 (Data Link Layer):
MAC 주소를 이용한 네트워크 통신을 다루는 계층
대표적인 프로토콜: Ethernet, PPP (Point-to-Point Protocol)
네트워크 계층 (Network Layer):
다른 네트워크와의 통신 및 경로 선택을 다루는 계층
대표적인 프로토콜: IP (Internet Protocol), ICMP (Internet Control Message Protocol), OSPF (Open Shortest Path First)
전송 계층 (Transport Layer):
엔드투엔드 통신 및 데이터 신뢰성을 관리하는 계층
대표적인 프로토콜: TCP (Transmission Control Protocol), UDP (User Datagram Protocol)
세션 계층 (Session Layer):
세션 관리와 동기화를 다루는 계층
대표적인 프로토콜: NetBIOS, RPC (Remote Procedure Call)
표현 계층 (Presentation Layer):
데이터의 표현 및 암호화를 처리하는 계층
대표적인 프로토콜: SSL/TLS (Secure Sockets Layer/Transport Layer Security)
응용 계층 (Application Layer):
최종 사용자와 상호 작용하며 응용 프로그램을 지원하는 계층
대표적인 프로토콜: HTTP (Hypertext Transfer Protocol), FTP (File Transfer Protocol), SMTP (Simple Mail Transfer Protocol), DNS (Domain Name System)
RB Tree 과제 발표
C언어 상단에 함수를 정의한 이유는?
순차적으로 함수를 호출하는 경우 문제가 없지만,
순서가 바뀌는 경우(의존 관계가 생기는 경우)
하단에 작성된 함수를 상단에서 호출할 수 없다.
그래서 코드 최상단에 함수를 선언해 준다.
선언(declaration)과 정의(definition) 구분하기!
선언은 컴파일러에게 함수 이름, 매개변수 목록 및 반관 값의 데이터 형식 알려주는 것
몸체(실체 코드)는 없고, 단순히 함수 존재만 알림.
함수를 여러 파일에서 사용하려면 해당 파일에서 함수 먼저 선언해야 함.
정의는 함수의 구현을 제공하는 것.(수행할 작업을 정의)
그럼 선언 내용을 헤더 파일에 넣으면 되나?
관행적으로 외부로 공개되는, 즉 public한 함수는 헤더 파일에 넣지만,
작성 코드 내에서만 사용되는 코드는 헤더에 넣지 않고 코드 상단부에 선언한다.
예외 처리 시 assert써도 되나?
assert는 디버깅용 함수다. 컴파일러에서 디버그 옵션 끄면 컴파일 안 돼서 프로덕트 레벨에서 쓸 수 없다.
운영진 면담
-
(내 고민) 컴퓨터 공부하다보니 메모리 -> 반도체 -> 트랜지스터 -> 전자 -> 우주 -> 빅뱅(?)
어느 선까지 공부를 해야 하는지에 대한 김코치님의 명쾌한 답변.
0과 1로 표현하는 디지털 수준까지 학습하면 된다.
그 밑의 내용은 정글이나, 개발자가 다루는 영역이 아니다.이 조언이 매우 큰 도움이 되었음. 디지털 레벨까지 공부하면 됨!
-
2000년대 초반 정부 주도로 대규모로 자바 개발자 양성
우스갯 소리로 나오는 '개발자 -> 치킨집 루트'는 자바만 할 줄 알아서 생기는 문제 -
백엔드, 프론트엔드, 자바, 언어.. 이런 게 중요한 게 아님.
기초 체력을 다져놓으면 프레임워크, 언어 학습은 금방 할 수 있다.
(전 기수에서 끝날 때까지 이 고민하던 수강생 있었음.) -
채용 시장에서 레이어마다 채용 기준이 다르다.
팀장급에서는 당장 내 일을 덜어줄 수 있는 사람을 선호,
C레벨에서는 성장 가능성이 있는 사람을 선호.
최종 결정은 C레벨에서 하지만, 팀장 픽을 무시할 수는 없음.
-> 정글 수료한다고 바로 취업이 어려울 수도 있는 이유
(하지만 기초가 좋으면 실무 능력 학습을 빠르게 할 수 있음.)
정글에 와서 진심으로 느낀 점
CS 기초 지식이 있으면 프레임워크, 새로운 프로그래밍 언어 학습이 어렵지 않을 것 같음.
오늘도 새로 알게된 lazy 개념도 예전에 파이썬 장고에서 엄청 이해 못하고
그냥 피상적으로만 이해하고 쓰던 함수였는데,
lazy한 방식의 동작 원리를 이해하니까 예전 코드가 연쇄적으로 이해가 됨!
또 파이썬에서 range() 함수의 동작 원리를 주절주절 설명했어야 하는데,
'lazy한 방식으로 작동된다'는 표현으로 깔끔하게 정리할 수 있게 되었음!
