작업 마무리 못해서 2시에 잠
오늘은 malloc best fit까지 구현해보고, 명시적 리스트까지 만들어 보기
09:16 입실
Malloc-lab
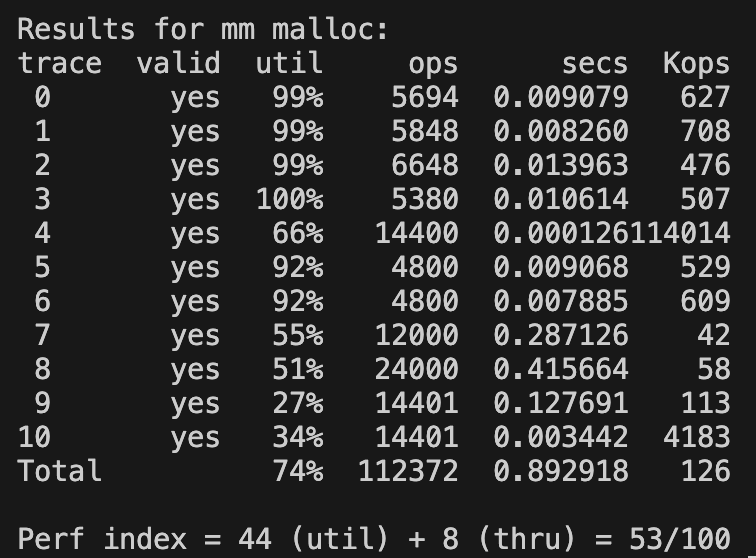
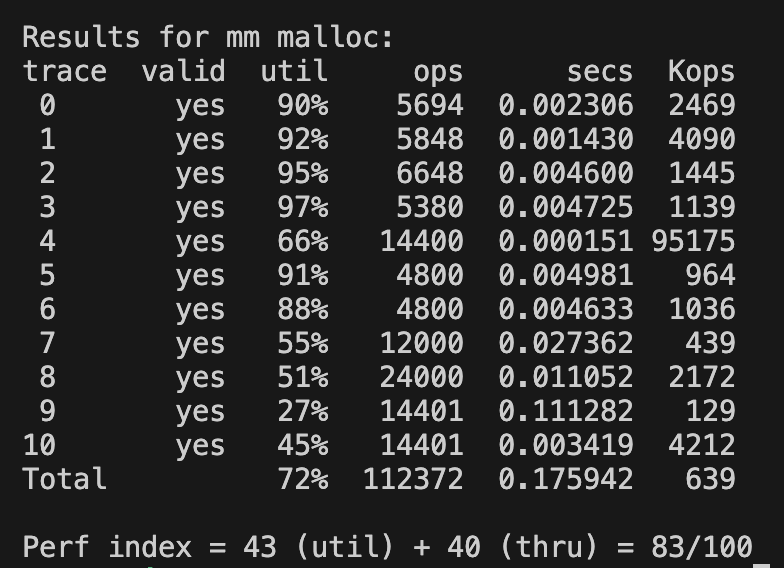
first fit vs next fit
first fit 결과
static void *first_fit(size_t allocated_size)
{
void *bp;
for (bp = heap_listp; GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp))
{
if (!GET_ALLOC(HDRP(bp)) && (allocated_size <= GET_SIZE(HDRP(bp))))
{
return bp;
}
}
return NULL;
}next fit 결과
static void *next_fit(size_t allocated_size)
{
void *bp;
for (bp = NEXT_BLKP(next_bp); GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp))
{
if (!GET_ALLOC(HDRP(bp)) && (allocated_size <= GET_SIZE(HDRP(bp))))
{
next_bp = bp;
return bp;
}
}
for (bp = heap_listp; bp < NEXT_BLKP(next_bp); bp = NEXT_BLKP(bp))
{
if (!GET_ALLOC(HDRP(bp)) && (allocated_size <= GET_SIZE(HDRP(bp))))
{
next_bp = bp;
return bp;
}
}
return NULL;
}
next_bp = NEXT_VLKP(bp);를 했더니 next fit이 제대로 동작하지 않았음.
그 이유를 가든님이 명쾌하게 찾아 주었음.
next fit으로 할당 후에 place함수를 통해 뒤쪽에 새로운 블록을 생성할지, 생성하지 않을지를 결정하는데, 만약 새로운 블록이 생성되면 기존에 저장한 next_bp 이전에 블록이 생성됨. 그래서 place를 통해 생성되는 블록에 무관하게 최근 블록부터 탐색하기 위해서next_bp = bp라고 해야 한다.
first fit은 항상 처음부터 블록을 검색해서 첫 번째로 검색되는 할당 가능한 블록을 할당한다. 즉, 앞 쪽에는 이미 할당된 블록일 가능성이 높기 때문에 검색시간(thru)에서 오버헤드가 발생한다.
반면, next fit은 직전 검색 시점 이후부터 검색을 한다. 이 경우에서 이미 검색한 블록은 한 바퀴를 돌았을 때 검색하기 때문에 비교적 빠르게 비어있는 메모리 공간을 찾을 가능성이 높다. 하지만 직전 포인터를 저장하는 공간이 추가로 필요하기 때문에 util에서 손해가 발생한다.
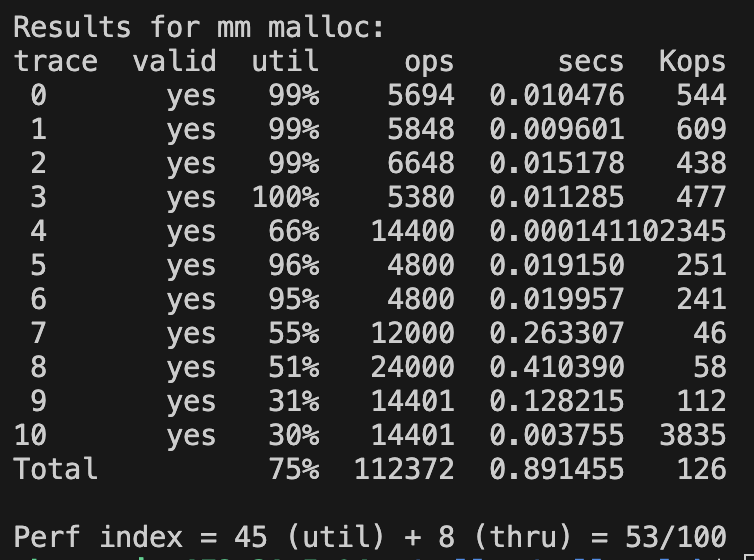
best fit
best fit 결과
처음부터 모든 블록을 순회한다.
이때 단편화 공간이 가장 작은 곳을 최신화하면서 bp를 최신화한다.
모든 블록 순회가 끝나면 단편화가 가장 적은 블록을 반환한다.
static void *best_fit(size_t allocated_size)
{
void *bp;
void *best_fit_bp = NULL;
size_t best_fragmentation_size = SIZE_MAX; // Initialize with a large value
for (bp = heap_listp; GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp))
{
if (!GET_ALLOC(HDRP(bp)) && allocated_size <= GET_SIZE(HDRP(bp)))
{
size_t fragmentation_size = GET_SIZE(HDRP(bp)) - allocated_size;
if (fragmentation_size < best_fragmentation_size)
{
best_fragmentation_size = fragmentation_size;
best_fit_bp = bp;
}
}
}
return best_fit_bp;
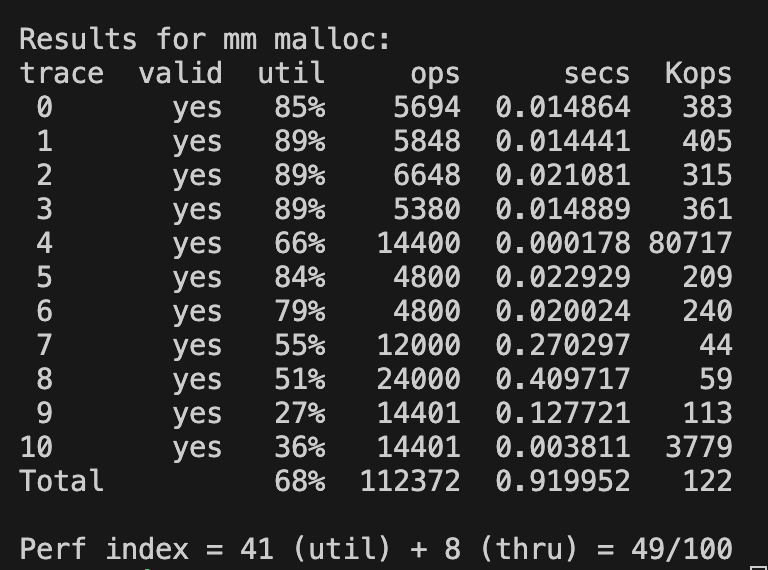
}Worst fit
Worst fit 결과
static void *worst_fit(size_t allocated_size)
{
void *bp;
void *worst_fit_bp = NULL;
size_t worst_fragmentation_size = 0;
for (bp = heap_listp; GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp))
{
if (!GET_ALLOC(HDRP(bp)) && allocated_size <= GET_SIZE(HDRP(bp)))
{
size_t fragmentation_size = GET_SIZE(HDRP(bp)) - allocated_size;
if (fragmentation_size > worst_fragmentation_size)
{
worst_fragmentation_size = fragmentation_size;
worst_fit_bp = bp;
}
}
}
return worst_fit_bp;
}명시적 해제 리스트
메모리 블록 구조
명시적 해제 리스트는 기존 메모리 블록에 pred 포인터(워드), succ 포인터(워드)가 추가된다.
묵시적 해제 리스트에서는 2워드의 메타데이터와, 2워드의 페이로드로 세팅(기본 4워드)
명시적 해제 리스트에서는 4워드의 메타데이터와, 2워드의 페이로드로 세팅(기본 6워드)
메모리 블록 할당 시 로직
여유 블록이 있을 때
1. 새로 생성된 블록의 pred를 할당된 기존 블록의 pred로 복사
2. 새로 생성된 블록의 succ를 할당된 기존 블록의 succ로 복사
여유 블록이 없을 때
1. 현재 블록의 pred 접근
3. 이전 블록의 succ를 현재 블록의 succ로 교체
- 현재 블록의 succ에 접근
- 다음 블록의 pred를 현재 블록의 pred로 교체
메모리 블록 해제 시 로직
- 해제된 메모리 블록의 PREDP를 0으로 초기화한다.
- 해제된 메모리 블록의 SUCCP를 현재 heap_listp(즉, 새롭게 블록이 추가될 주소지점)로 설정한다.
(즉, 힙 리스트의 맨 앞으로 새로운 블록을 넣는 것) - heap_listp블록의 PREDP에 해제된 메모리 블록의 bp를 할당한다.
- heap_listp를 새롭게 해제 된 bp로 설정해서, 다음 할당은 우선 방금 해제된 메모리 블록부터 검색.
이건 해제된 메모리 블록을 힙 리스트 맨 앞으로 집어 넣는 것!
명시적 해제 리스트는 제로 베이스에서 혼자 구현은 불가. 참고 코드 보면서 나만의 방식으로 해석해봄.
https://d-cron.tistory.com/33
스터디
char* 캐스팅 이유
#define HDRP(bp) ((char *)(bp)-WSIZE)
bp는 void*이다. 따라서 포인터 연산이 불가능하다.
그런데 HERP(헤더 포인터)를 구하려면 4바이트(1워드)를 bp에서 빼야 한다.
WSIZE가 4로 매크로 상수가 지정되어 있기 때문에 4를 4바이트로 해석해서 bp에서 빼면된다.
그래서 bp를 char*로 캐스팅하고 4를 빼면 4바이트만큼을 bp에서 뺄 수 있다.
char*로 캐스팅하는 방법은 바이트 단위로(주소) 포인트 연산을 해야할 때 자주 사용하는 기법이다.
가상 메모리 페이지 I/O 메커니즘 파악하기
1. 프로세스가 실행되면 모든 정보는 스왑 영역에 적재되는가?
아님! 레지던트 로딩(Resident Loading)이라는 개념이 있음.
프로그램의 일부 또는 전체를 처음부터 물리 메모리에 로딩하여 실행하는 것을 의미
즉, 일부는 처음부터 메모리에 적재되어서 실행되지만, 나머지 영역은 스왑영역에 위치하게 됨.
이때, 프로그램을 실행하면 가상 메모리가 할당되고, 이 가상 메모리에 기본적으로 실행되어야 하는 코드영역 등은 물리 메모리나 스왑 영역으로 매핑되는 가상 메모리에 적재되는 것
2. 그럼 프로세스가 실행 중일 때는 어쨌든 전체 데이터가 물리 메모리와 스왑 영역에 걸쳐서 모두 적재되어 있는 상태인가?
맞음.
3. 페이지 아웃될 때, 기존 프레임에 다시 적재하거나, 또는 새로운 프레임에 적재할 수 있는건가?
맞음. 그래서 레지던트 로딩으로 적재된 페이지는 스왑 영역에 아예 프레임 자체가 없기 때문에 이때 페이지 아웃될 때는 새로운 프레임을 할당함.
4. 더티 비트가 1인 페이지는 페이지 아웃될 때, 디스크의 프레임에 쓰기 작업이 진행되고, 더티 비트가 0이면 그냥 기존 프레임을 그대로 유지하는건가?
맞음.
5. 정리하면, 더티 비트가 1이면 표면적으로는 데이터가 물리 메모리에서 디스크로 이동한다고 볼 수 있고, 더티 비트가 0이면 표면적으로 데이터가 물리 메모리에서 디스크가 이동하는 게 아니라 그냥 물리 메모리에서 삭제된다고 볼 수 있나?
맞음.
페이지 I/O시 참조되는 비트
페이지 적재 시간, 참조비트(R) 등을 고려하여 페이지 교체 대상을 선정하며,
수정비트(더티비트)를 통해 단순히 페이지를 삭제할지, 디스크에 이동(쓰기 작업)을 할지 결정함.
