08:10 입실
오전에 퀴즈 준비 힙 공부하기
명시적 해제 리스트 구현 끝내기
최적화까지 해보기
가비지 컬렉터 이야기
malloc을 구현하면서 할당기에 대한 전반적인 개념을 잡았다.
GC관련해서 인스타그램의 재미있는 사례가 있다.
https://luavis.me/python/dismissing-python-garbage-collection-at-instagram
요약하면 파이썬으로 개발한 인스타그램에게 파이썬 GC를 끄고 난 후 10%의 성능 향상이 있었다는 내용.
그럼 GC를 끄면 메모리 누수는 어떻게 관리하나?
파이썬 인터프리터는 참조 카운트가 0이 되면 메모리를 해제하고
GC는 순환 참조 같은 참조 카운트 사용이 불가능할 때 쓰이는 부가적인 역할이라고 함.
힙 정렬
이번 주 커리큘럼은 아니지만 퀴즈에 출제하신다고 함.
중요 키워드라서 추가로 출제하시는 느낌.
파이썬으로 힙 정렬 알고리즘 구현해보고 이해하기!
힙이란?
부모의 값이 자식의 값보다 항상 크다(혹은 항상 작다)는 조건은 만족하는 완전 이진 트리
힙을 활용한 정렬을 힙 정렬이라고 함.
힙에서 최댓값은 루트에 위치한다.
배열과 힙의 관계
원소 a[i]에서
- 부모: a[(i-1) // 2]
- 왼쪽 자식: a[i * 2 + 1]
- 오늘쪽 자식: a[i * 2 + 2]
힙 정렬 원리
힙에서 최대값인 루트를 꺼낸다.(최대힙)
루트 이외 부분을 다시 힙으로 만든다.
1. 마지막 원소를 루트로 이동
2. 큰 값을 가진 자식과 위치 교환 - 반복
힙 정렬 파이썬 코드
from typing import MutableSequence
def heap_sort(a: MutableSequence) -> None:
"""힙 정렬"""
def down_heap(a: MutableSequence, left: int, right: int) -> None:
"""a[left] ~ a[right]로 힙 만들기"""
temp = a[left]
parent = left
while parent < (right + 1) // 2:
cl = parent * 2 + 1
cr = cl + 1
child = cr if cr <= right and a[cr] > a[cl] else cl
if temp >= a[child]:
break
a[parent] = a[child]
parent = child
a[parent] = temp
n = len(a)
# 초기 힙 구성: 최대 힙으로 배열 a를 구성합니다.
# 이 단계에서는 가장 큰 값이 루트 노드에 위치합니다.
for i in range((n - 1) // 2, -1, -1):
down_heap(a, i, n - 1)
print(a)
# 정렬 단계: 최대 힙으로 구성된 배열에서 가장 큰 값을 뒤로 이동시키고,
# 나머지 부분에 대해 힙 정렬을 반복 수행하여 배열을 오름차순으로 정렬합니다.
for i in range(n - 1, 0, -1):
a[0], a[i] = a[i], a[0]
# 남은 부분에 대해 다시 힙을 조정하여 정렬을 진행합니다.
down_heap(a, 0, i - 1)
print(a)
if __name__ == "__main__":
print("힙 정렬을 수행합니다.")
num = int(input("원소 수를 입력하세요: "))
x = [None] * num
for i in range(num):
x[i] = int(input(f"x[{i}]: "))
heap_sort(x)
print("오름차순으로 정렬했습니다.")
for i in range(num):
print(f"x[{i}] = {x[i]}")파이썬 heapq 모듈
파이썬은 heapq로 힙을 간단히 구현할 수 있다.
코딩 테스트에서는 이걸 쓰더라고, 직접 힙을 구현할 수는 있어야 함
heappush(), heappop()을 제공
파이썬의 힙은 최소 힙으로 구성되어 있다.
import heapq
from typing import MutableSequence
def heap_sort(a: MutableSequence) -> None:
"""힙 정렬(heapq.push와 heapq.pop을 사용)"""
heap = []
for i in a:
heapq.heappush(heap, i)
for i in range(len(a)):
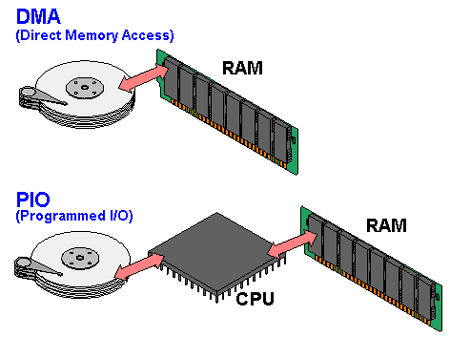
a[i] = heapq.heappop(heap)DMA 그림 보충
퀴즈 복기
힙 정렬
힙 정렬 문제 풀다가 못 풀었음.
계속 고민하다가 마지막에 후다닥 풀었는데 70%정도 적다가 시간이 끝나 버림.
정확하게 푸는 방법을 모르고 있었음.

팀원 도움으로 확실하게 이해함.
계속 TEMP를 이해하지 못하고 있었는데,
다운 힙의 과정이 TEMP(즉, 루트)를 어디 위치에 넣을지를 탐색하는 과정.
그래서 계속 TEMP와 비교해서 밑으로 내려갈지, 거기서 멈추고 TEMP를 넣을지를 찾는 과정이었음.
보이저엑스의 v-flat 앱으로 칠판 스캔했는데 신세계를 보았다.
진심 스캐너 대체할 수 있을 것 같음.
세그멘테이션
페이징 말고 세그멘테이션은 정확히 찾아본 적 없음.
세그멘테이션과 페이징 모두 가상 메모리 관리 기술임.
세그멘테이션은 가상 주소 공간을 서로 다른 세그먼트로 나누는 메모리 관리 기술
이때, 세그먼트는 논리적으로 관련된 데이터나 코드 묶음을 나타내며,
프로세스의 메타데이터에 저장된 세그먼트 디스크립터에 의해 정의됨.
프로세스 메타데이터에는 해당 세그먼터 시작 주소와 크기가 저장되어 있음.
세그멘테이션은 프로세스의 가상 주소 공간을 서로 다른 세그먼트로 나누어 프로그램 논리 구조를 유지하는 게 사용됨.
페이징은 가상 메모리를 페이지로 나누고 물리 메모리를 프레임으로 나눠서 매핑하는 기술
결론은 세그멘테이션을 주소 공간을 서로 다른 세그먼트로 나누는 것,
페이징은 주소 공간을 고정 크기 페이지로 나누는 것
페이징은 할당된 메모리 전체를 페이지 단위로 쪼개서 관리하는 것.
세그먼트 테이블도 별도로 있음.
즉, 힙 세그먼테이션이 스택 세그먼테이션을 침범하거나 부여된 힙 세그먼테이션을 넘어가면 세그먼테이션 폴트가 발생하는 것.
가상 메모리 구조에서 보이는 데이터 영역, 힙 영역, 스택 영역 등에서 '영역'에 해당하는게 사실 세그먼트임!!
익숙해지기 위해서 '힙 영역', '스택 영역'이라고 표현하는 것 보다 '힙 세그먼트', '스택 세그먼트'라고 하는 게 좋을 것 같음.
이중 포인터 + %s
배열을 이용한 이중 포인터까지는 잘 찾아갔는데,
%s는 문자열을 포매팅하는데, %s는 해당 주소가 가리키는 문자열을 시작으로 \0을 만날 때까지 계속해서 데이터를 읽어옴.
C가 익숙치 않아서 오답 적음.
이건 C언어 기초 부족.
C에서 문자열
%s는 조금 특별한 서식 문자라고 볼 수 있다.
(참고) C 서식 문자
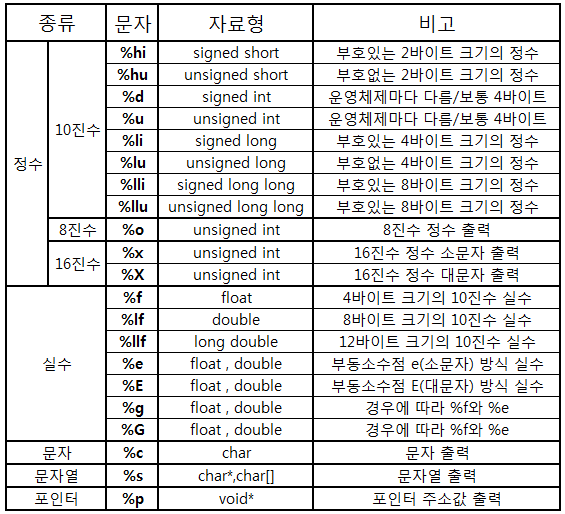
문자열은 문자의 모임 또는 문자열로 표현할 수 있음.
// 문자의 모임으로 표현
char eng[4] = {'A', 'B', 'C', '\0'};
// 문자열로 표현
char eng[4] = "ABC";문자열 상수에서는 널 문자가 자동으로 붙는다.
즉'a'는 1바이트로 저장되지만,"a"는 널문자를 포함해서 2바이트가 저장됨.
malloc-lab
명시적 가용 리스트 착각
무조건 전, 후 포인터가 들어가는게 아니었다!
해제된 블록에서는 전, 후 포인터가 빠지고
할당된 블록에만 포인터가 들어가는 거였다.
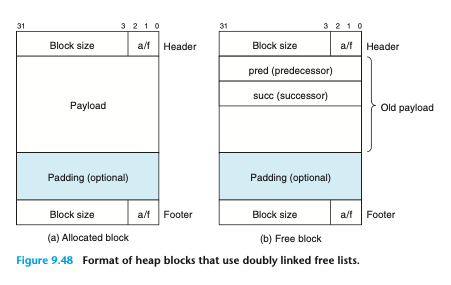
왼쪽이 할당된 블록, 오른쪽이 해제된 블록
무조건 전, 후 포인터를 갖는다고 생각해서 계속 헛발질
왜 헤더와 푸터 업데이트 순서 바꾸면 안 될까?
else if (!prev_alloc && next_alloc)
{
remove_free_block(PREV_BLKP(bp));
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
bp = PREV_BLKP(bp);
PUT(FTRP(bp), PACK(size, 0)); // 여기 순서 때문에 Segmentation fault (core dumped)
PUT(HDRP(bp), PACK(size, 0));
}위 코드에서 FTRP를 HDRP보다 먼저 하면 에러가 발생한다.
이유는 FTRP에 접근하려면 먼저 HDRP를 통해 사이즈를 획득하고 푸터로 접근하기 때문이다.
즉, 헤더를 먼저 최신화 하지 않고 푸터로 접근하면, 푸터는 그 이전 상태의 푸터에 접근해서 업데이트 하기 때문에 최신화된 푸터를 업데이트 할 수 없다.
요약하면, 푸터의 위치는 헤더의 위치에 종속적이기 때문이다.
메모리 블록 업데이트를 항상 헤더 -> 푸터 순으로 해야 한다.
명시적 해제 리스트 first fit 구현
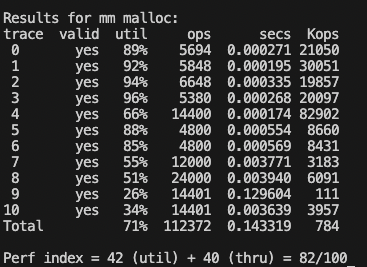
/* single word (4) or double word (8) alignment */
#define ALIGNMENT 8
/* rounds up to the nearest multiple of ALIGNMENT */
#define ALIGN(size) (((size) + (ALIGNMENT - 1)) & ~0x7)
#define SIZE_T_SIZE (ALIGN(sizeof(size_t)))
/* Basic constants and macros */
#define WSIZE 4
#define DSIZE 8
#define CHUNKSIZE (1 << 12)
#define MAX(x, y) ((x) > (y) ? (x) : (y))
#define PACK(size, alloc) ((size) | (alloc))
#define GET(p) (*(unsigned int *)(p))
#define PUT(p, val) (*(unsigned int *)(p) = (val))
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1)
#define HDRP(bp) ((char *)(bp) - (WSIZE))
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - (DSIZE))
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp)-WSIZE)))
#define PREV_BLKP(bp) ((char *)(bp)-GET_SIZE(((char *)(bp)-DSIZE)))
#define PRED_FREEP(bp) (*(void **)(bp))
#define SUCC_FREEP(bp) (*(void **)(bp + WSIZE))
static void *heap_listp;
static void *free_listp;
static void *extend_heap(size_t words);
static void *coalesce(void *bp);
static void *find_fit(size_t allocated_size);
static void *first_fit(size_t allocated_size);
static void place(void *bp, size_t allocated_size);
static void append_free_block(void *bp);
static void remove_free_block(void *bp);
int mm_init(void)
{
if ((heap_listp = mem_sbrk(6 * WSIZE)) == (void *)-1)
return -1;
PUT(heap_listp, 0);
PUT(heap_listp + (1 * WSIZE), PACK(DSIZE * 2, 1));
PUT(heap_listp + (2 * WSIZE), NULL);
PUT(heap_listp + (3 * WSIZE), NULL);
PUT(heap_listp + (4 * WSIZE), PACK(DSIZE * 2, 1));
PUT(heap_listp + (5 * WSIZE), PACK(0, 1));
free_listp = heap_listp + DSIZE;
if (extend_heap(CHUNKSIZE / WSIZE) == NULL)
return -1;
return 0;
}
static void *extend_heap(size_t words)
{
void *bp;
size_t size;
size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE;
if ((bp = mem_sbrk(size)) == (void *)-1)
return NULL;
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1));
return coalesce(bp);
}
void *mm_malloc(size_t size)
{
size_t allocated_size;
size_t extendsize;
char *bp;
if (size == 0)
return NULL;
if (size <= DSIZE)
allocated_size = 2 * DSIZE;
else
allocated_size = DSIZE * ((size + (DSIZE) + (DSIZE - 1)) / DSIZE);
if ((bp = find_fit(allocated_size)) != NULL)
{
place(bp, allocated_size);
return bp;
}
extendsize = MAX(allocated_size, CHUNKSIZE);
if ((bp = extend_heap(extendsize / WSIZE)) == NULL)
return NULL;
place(bp, allocated_size);
return bp;
}
void append_free_block(void *bp)
{
SUCC_FREEP(bp) = free_listp;
PRED_FREEP(bp) = NULL;
PRED_FREEP(free_listp) = bp;
free_listp = bp;
}
void remove_free_block(void *bp)
{
if (bp == free_listp)
{
PRED_FREEP(SUCC_FREEP(bp)) = NULL;
free_listp = SUCC_FREEP(bp);
}
else
{
SUCC_FREEP(PRED_FREEP(bp)) = SUCC_FREEP(bp);
PRED_FREEP(SUCC_FREEP(bp)) = PRED_FREEP(bp);
}
}
static void *find_fit(size_t allocated_size)
{
return first_fit(allocated_size);
}
static void *first_fit(size_t allocated_size)
{
void *bp;
for (bp = free_listp; GET_ALLOC(HDRP(bp)) != 1; bp = SUCC_FREEP(bp))
{
if (allocated_size <= GET_SIZE(HDRP(bp)))
{
return bp;
}
}
return NULL;
}
static void place(void *bp, size_t allocated_size)
{
size_t current_size = GET_SIZE(HDRP(bp));
remove_free_block(bp);
if ((current_size - allocated_size) >= (2 * DSIZE))
{
PUT(HDRP(bp), PACK(allocated_size, 1));
PUT(FTRP(bp), PACK(allocated_size, 1));
bp = NEXT_BLKP(bp);
PUT(HDRP(bp), PACK(current_size - allocated_size, 0));
PUT(FTRP(bp), PACK(current_size - allocated_size, 0));
append_free_block(bp);
}
else
{
PUT(HDRP(bp), PACK(current_size, 1));
PUT(FTRP(bp), PACK(current_size, 1));
}
}
void mm_free(void *bp)
{
size_t size = GET_SIZE(HDRP(bp));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
coalesce(bp);
}
static void *coalesce(void *bp)
{
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size = GET_SIZE(HDRP(bp));
if (prev_alloc && next_alloc)
{
// 앞, 뒤 모두 할당 블록이므로 병합 불가
}
else if (prev_alloc && !next_alloc)
{
remove_free_block(NEXT_BLKP(bp));
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}
else if (!prev_alloc && next_alloc)
{
remove_free_block(PREV_BLKP(bp));
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
bp = PREV_BLKP(bp);
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(bp), PACK(size, 0));
}
else
{
remove_free_block(PREV_BLKP(bp));
remove_free_block(NEXT_BLKP(bp));
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
append_free_block(bp);
return bp;
}
void *mm_realloc(void *bp, size_t size)
{
void *old_bp = bp;
void *new_bp;
size_t copySize;
new_bp = mm_malloc(size);
if (new_bp == NULL)
return NULL;
copySize = GET_SIZE(HDRP(old_bp));
if (size < copySize)
copySize = size;
memcpy(new_bp, old_bp, copySize);
mm_free(old_bp);
return new_bp;
}
이렇게 유용한 정보를 공유해주셔서 감사합니다.