12시쯤 누워도 컴퓨터 영상보다가 늦게 자게 됨.
그래도 어제는 1시 이전에 자긴 했는데, 취침 시간을 12:30분 이전으로 맞추기
그래야 7:30 기상 기준으로 7시간 잘 수 있음.
08:21 입실
오늘은 오전에 페이지 테이블, 세그먼트 테이블로 논리주소가 어떻게 물리주소로 변환되는지 원리 확실히 이해하기
페이징
페이징의 전반적인 흐름도
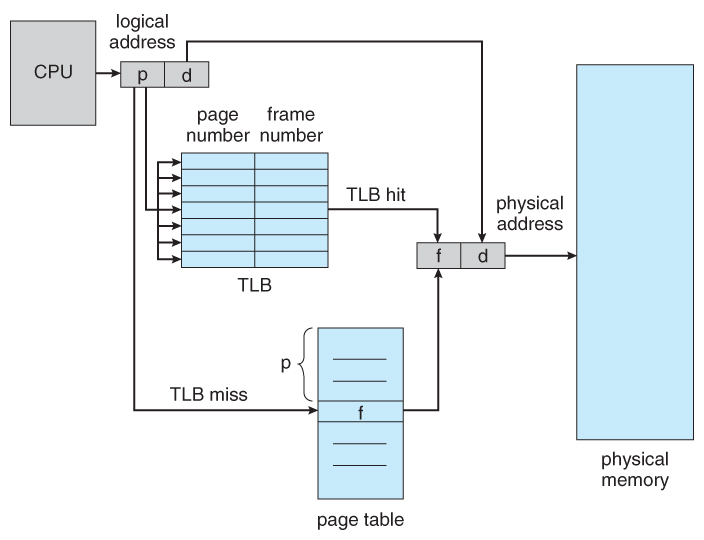
논리주소는 어떻게 구성되나?
페이징에서 논리주소는 페이지 번호와 오프셋 두 부분으로 나뉜다.
페이지 번호: 해당 데이터 또는 코드가 저장된 페이지 식별 번호
페이지 오프셋: 페이지 내 실제 주소 위치 나타내는 값(변위)
예) 0x1234:5678에서 0x1234는 페이지 번호, 0x5678은 오프셋
TLB란 무엇인가?
Translation Lookaside Buffer(변환 색인 버퍼)
하드웨어 캐시이다. 페이지 테이블 엔트리 일부를 캐싱한다.
CPU가 논리주소에서 페이지 번호를 획득한 후,
TLB에 해당 페이지 번호에 해당하는 엔트리가 있으면 TLB 히트가 발생사고, 프레임 번호를 획득한다.
하지만 TLB에 해당 페이지 번호가 없으면 TLB 미스가 발생하고,
그때는 페이지 테이블에 접근하여 프레임 번호를 획득한다.
페이지 테이블에 어떻게 접근하나?
레지스터(PTBR)에 해당 프로세스 페이지 테이블의 시작 주소(베이스 주소)가 있다.
그럼 베이스 주소에 페이지 번호를(페이지 단위로 분할되어 있음)를 더하면
해당 엔트리에 접근할 수 있다.(이 과정 또한 마치 재귀처럼 논리주소 -> 물리주소 변환이 일어난다.)
엔트리에 접근 후 해당 페이지가 적재되어 있는 프레임 번호와 프레임 물리 주소를 알 수 있다.
프레젠트 비트(페이지 히트 & 페이지 폴트)
엔트리에는 프레젠트 비트가 있다. 이건 해당 페이지가 실제 물리 메로리에 적재되어 있는지를 나타낸다.
프레젠트 비트가 1이면 적재되어 있다는 뜻(페이지 히트)으로, 바로 프레임에 접근해서 데이터를 가져올 수 있다.
하지만 프레젠트 비트가 0이면 미적재 상태(페이지 폴트)이므로, 디스크 스왑영역에서 페이지를 가져와 메모리 적재 후 엔트리를 업데이트 후 TLB를 업데이트(캐핑)한다.
스왑영역으로 데이터를 가져오는 과정은?
운영체제가 스왑 영역의 위치 정보를 내부 데이터 구조에 저장(커널 또는 메모리 관리 모듈에서 관리)
프레임 번호 획득 후 어떻게 물리 주소로 변환되나?
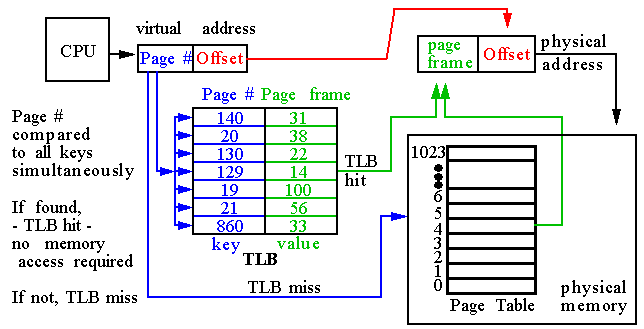
이 작업은 MMU가 관여한다.
TLB 또는 페이지 테이블에서 프레임 번호 획득한 후,
프레임 번호 * 프레임 크기를 하면 해당 프레임이 시작되는 물리 주소를 얻을 수 있다.
프레임 물리 주소에 논리 주소 상의 오프셋을 더하면 논리 주소가 가리키는 메모리 주소 번지에 접근할 수 있다.
예) 페이지 크기는 4KB(4096)이다. 오프셋은 2KB이다.
TLB 또는 페이지 테이블에서 프레임 번호 5를 얻었다.
5 * 4096을 하면 프레임이 적재된 물리 주소를 알 수 있다. (=20,480)
여기에 2048을 더하면 22,528바이트(0x5800) 이 주소가 최초 논리주소에 매핑되는 물리주소이다.
페이지 디렉토리 & 테이블

세그멘테이션
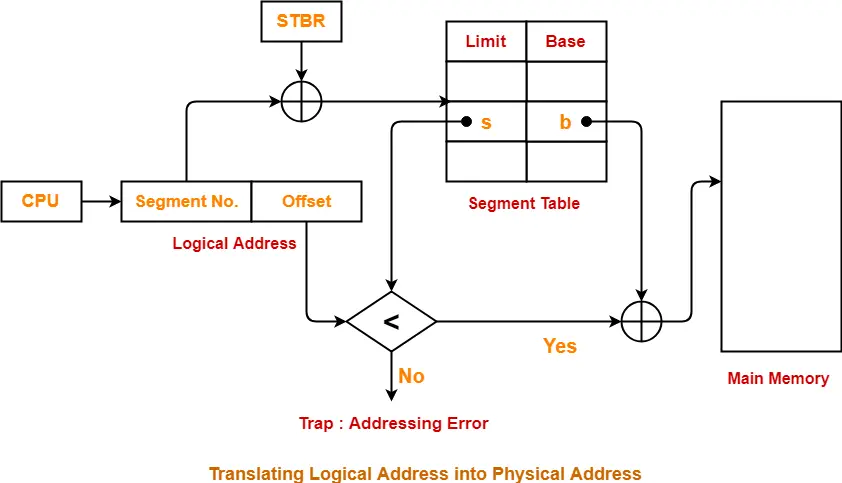
세그멘테이션의 전반적인 흐름도
세그먼트 테이블도 TLB에 캐싱되나?
일반적으로 TLB는 페이지 테이블 엔트리 캐싱에 주로 사용됨.
아키텍처 및 운영체제에 따라 세그먼트 테이블도 캐싱될 수 있다고 함.
세그먼트 테이블에 어떻게 접근하나?
레지스터(STBR)에 해당 프로세스 세그먼트 테이블의 시작 주소(베이스 주소)가 있다.
그럼 베이스 주소에 세그먼트 주소를 더하면 해당 엔트리에 접근할 수 있다.
엔트리에 접근 후 해당 세그먼트가 적재되어 있는 물리 주소(base)를 알 수 있다.
세그먼트 테이블에는 리밋(사이즈)가 있는데 만약 변위가 이 리밋을 넘어가면 운영체제에서 해당 메모리 엑세스를 거부하고 오류를 발생시킨다.(세그먼트 폴트)
프레젠트 비트
페이징과 같다.
스왑영역으로 데이터를 가져오는 과정은?
페이징과 같다. 이때 스왑영역에서 세그먼트 전체, 또는 일부를 로드한다.
세그먼트 번호 획득 후 어떻게 물리 주소로 변환되나?
이 작업은 MMU가 관여한다.
세그먼트 번호를 통해 엔트리에 접근하면 해당 세그먼트 베이스 물리 주소를 획득할 수 있다.
여기에 논리주소 상의 오프셋을 더하면 접근하려는 메모리 주소번지를 획득한다.
이때 변위가 리밋을 넘어가는 경우 세그먼트를 넘어가는 것이므로 운영체제에서 해당 메모리 엑세스를 거부하고 오류를 발생시킨다.(세그먼트 폴트)
예) 세그멘트 크기 8KB, 오프셋 2KB, 세그멘트 번호 3
세그멘트 번호를 통해 엔트리에 접근하여 세그멘트 3에 해당하는 물리 메모리 베이스 주소 획득
만약 0x30000이라고 가정하면, 오프셋 2KB를 더함.
결과는 0x31000바이트가 되고, 물리 주소 0x31000에 접근함.
세그먼트 번호는 어떻게 얻나?
프로세스가 생성될 때 운영체제 의해 할당됨.
(프로세스가 생성될 때 운영체제가 '힙 영역 세그먼트는 3번, 스택 영역 세그먼트는 5번' 이런 식으로 알려 줌)
페이지 테이블과 세그먼트 테이블 차이!
페이지 테이블은 페이지를 인덱스로 관리한다. 즉 인덱스에 페이지 크기를 곱하면 해당 페이지가 매핑되는 프레임의 물리 주소를 알 수 있다.
세그먼트는 베이스와 리밋으로 관리된다. 베이스는 세그먼트가 적재된 물리 메모리의 시작 주소 그 자체이며, 리밋을 세그먼트의 종료 지점을 계산한다.
네트워크 계층
OSI 7계층
Open Systems Interconnection
OSI는 개방형 시스템 상호 연결의 약자
다른 시스템끼리 통신할 수 있도록 국제표준화기구에서 만든 개념 모델
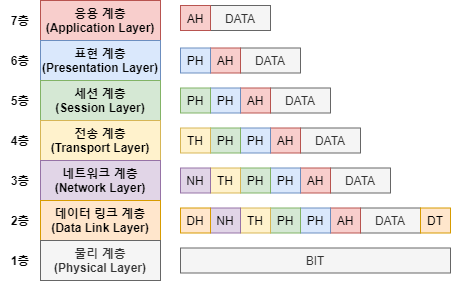
7계층. 응용 프로그램 계층
사용자에게 데이터를 표시하고, 사용자의 입력을 수신하는 역할. 사용자와 직접 통신하는 계층.
6계층. 프레젠테이션 계층
응용 프로그램 계층이 6계층을 이용한다. 6계층이 데이터를 이용할 있도록 데이터를 표현한다. 예를 들어 데이터 인코딩, 디코딩, 암호화 등.
그리고 5계층으로 전송하기 전에 압축도 한다.
5계층. 세션 계층
두 기기 사이의 통신을 시작하고 종료하는 일. 통신이 지속되는 시간을 세션이라고 함.
4계층. 전송 계층
실제 데이터를 전송하는 계층. 이때 데이터 조각 분할, 조립, 전송속도 결정 등을 함.
전송의 신뢰성을 담당함.
3계층. 네트워크 계층
서로 다른 네트워크의 통신을 위해 필요
두 장치가 동일한 네트워크라면 네트워크 계층이 필요하지 않다.
서로 다른 두 네트워크 간 데이터 전송을 위해 네트워크 계층이 필요하다.
라우팅이 핵심.
(서로 다른 네트워크의 목적지에 데이터를 보내야 하기 때문에 IP가 필요하다.)
2계층. 데이터 연결 계층
동일 네트워크 통신을 위해 필요
동일 네트워크의 두 개 장치 간의 데이터 전송을 용이하게 한다.
1계층. 물리적 계층
케이블, 스위치 등 물리적 장비가 포함.
물리적 처리가 이루어 짐.
TCP/IP 모델
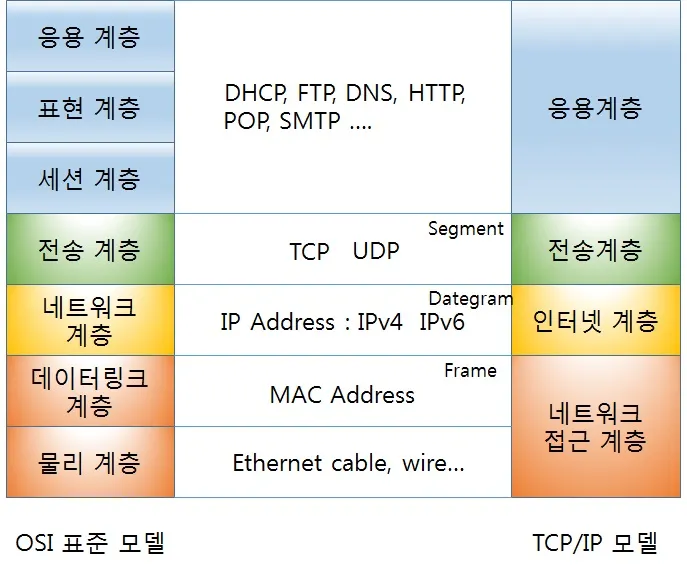
OSI 모델은 표준적인 추상화된 모델같은 개념이라면, TCP/IP는 현대 인터넷 네트워크 모델로 구체화된 것이다. 인터넷 통신 중 핵심 프로토콜이 TCP와 IP이기 때문에 TCP/IP모델로 불리고 있다.
TCP 프로토콜
Transmission Control Protocol 전송 제어 프로토콜
TCP 세그먼트를 생성해서 신뢰성 있는 방식으로 데이터를 송수신한다.
TCP 프로토콜의 특징
- 신뢰성
- 연결 기반
- 흐름 제어
- 에러 검출 및 복구
- 순서 보장
- 포트 및 소켓(포트 번호를 사용하여 송신자와 수신자 식별)
- 양방향 통신(전이중 통신 제공, 데이터 동시 송수신 가능)
- 네트워크 계층 독립(다양한 종류 네트워크에서 사용 가능: TCP/IP 스택 외에서도 사용될 수 있음.)
즉, TCP는 특정 네트워크 환경에 종속적인 기술이 아님.
TCP 프로토콜은 신뢰성, 순서가 보장된 전송만 할 줄 알지 어디로 데이터 보내야 하는지는 모름
IP 프로토콜
Internet Protocol, 인터넷 프로토콜
데이터 패킷의 라우팅과 전달을 관리하는 프로토콜
IP 프로토콜의 특징
- IP 주소
- 패킷 스위칭(데이터를 작은 패킷으로 나누고 패킷 스위칭으로 패킷을 전송)
- 루팅(길을 정함)
- 연결리스(개별 패킷을 독립적으로 처리된다.)
- IPv4, IPv6
IP는 주어진 데이터를 패킷을 잘게 쪼개서 목적지에 보내는 프로토콜이다. 하지만 신뢰성 있는 전송을 책임지지는 않는다. 그냥 데이터를 전송하기만 하는것. 즉, TCP에서 넘어온 데이터를 IP가 효율적으로 목적지까지 보내주는 것.
클라이언트-서버 모델
서비스 요청자인 클라이언트와 서비스 자원 제공자인 서버를 나누는 네트워크 아키텍처
분산 환경에서 이 모델이 유용하다. 왜냐면 서버가 여러 클라이언트의 요청을 동시에 처리할 수 있다.
네트워크를 통해 지리적으로 떨어진 클라이언트와 서버 간의 통신도 가능하다.
클라이언트-서버 모델에서 네트워크가 이루어질 때 필요한 규약을 프로토콜이라고 한다.
그럼 통신 모델에서 클라이언트-서버 모델 말고 다른 모델도 있나?
있음!
P2P모델: 중앙 서버 없이 노드 간 직접 통신
클라이언트-서버 모델 변형: 웹 서버 간의 통신, 마이크로 아키텍처 간의 통신
다계층모델: 서버가 여러 계층에 존재. 대표적으로 DNS
소켓
인터넷 소켓, 네트워크 소켓
소켓이 뭐지?
네트워크로 연결되어 있는 컴퓨터의 통신의 접점에 위치한 통신 객체
네트워크 통신 프로그램은 소켓을 생성한다.
소켓 구성 요소
- 인터넷 프로토콜(TCP, UDP, raw IP)
- 로컬 IP
- 로컬 포트
- 원격 IP
- 원격 포트
소켓 프로그래밍
네트워크 프로그램을 만드는 걸 소켓 프로그래밍이라고 하고, 네트워크를 할 수 있는 다양한 함수를 활용
소켓은 일종의 객체이다. 네트워크 통신을 위한 프로그래밍 인터페이스이다.
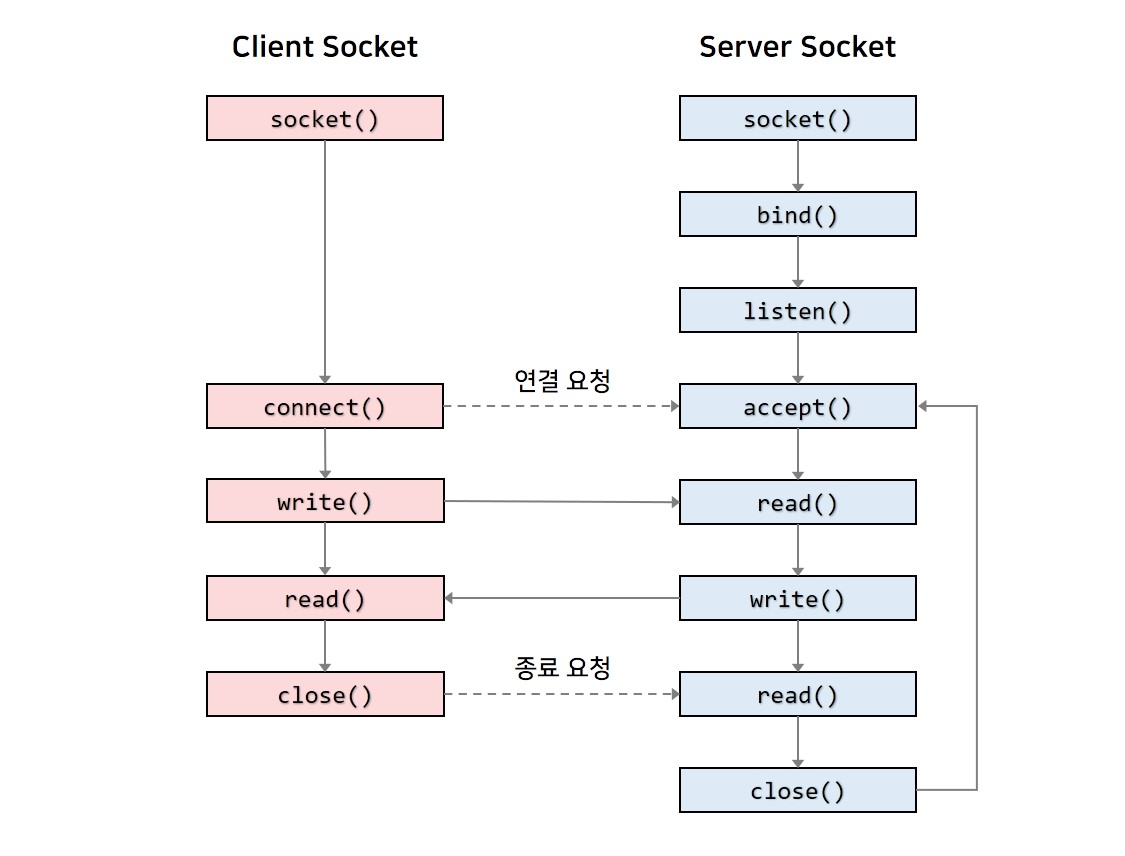
소켓을 생성한다는 건 소켓 객체를 생성한다는 것이다. 이렇게 생성된 객체의 다양한 메서드를 활용해서 네트워크 프로그램을 만드는 것. 즉, 소켓을 일종의 터미널 역할을 한다. 소켓을 서버와 클라이언트에 각각 생성한다. 각각 생성된 소켓 객체를 통해서 서로 통신하는 것.
인터페이스가 뭘까?
용어가 좀 어려운데 우선 이렇게 생각하기로 함.
뭔가를 할 수 있는 도구 모음집
메서드
socket : 소켓 객체 생성(사용할 프로토콜, 소켓 유형을 지정한다.)
bind : 소켓을 특정 주소와 포트 번호에 바인딩
listen : (서버 소켓) 연결 요청을 수신할 수 있게 대기 상태로 전환(연결 요청 수 제한도 가능)
accept : (서버 소켓) 클라이언트 연결 요청이 수신되면 연결 수락, 클라이언트 통신을 위한 새로운 소켓 생성
connect : (클라이언트 소켓) 클라이언트가 서버에 연결을 요청
close : 소켓 연결을 닫음(해당 소켓 사용 불가 상태, 연결 종료)
write: 데이터를 소켓에 전송
read : 수신된 데이터를 읽음
소켓 프로그래밍 예시
import socket
# 클라이언트 소켓 생성
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 서버에 연결 요청
server_address = ('localhost', 12345)
client_socket.connect(server_address)
try:
# 서버로 데이터 송신
message = "안녕, 서버!"
client_socket.send(message.encode())
# 서버로부터 데이터 수신
data = client_socket.recv(1024)
print(f"서버 응답: {data.decode()}")
finally:
# 클라이언트 소켓 닫기
client_socket.close()위의 메서드는 표준 규약일 뿐이고, 각각의 구체적인 메서드명은 언어나 라이브러리에 따라 달라질 수 있음.
Datagram Socket vs Stream Socket
socket : 소켓 객체 생성할 때 지정하는 소켓 유형이다.
Datagram Socket
- 데이터를 데이터그램 단위로 전송
- 데이터그램은 독립적인 패킷, 다른 경로 전송 가능
- UDP(User Datagram Protocol)을 기반으로 작동
- 신뢰성 보장 안 됨.(순서 보장 안 됨, 패킷 손실 및 중복 미처리)
- 빠른 속도, 낮은 오버헤드 -> 실시간 통신이 필요한 응용 프로그램에 유용
Stream Socket
- 연결된 스트림을 전송
- 스트림은 데이터의 흐름, 데이터를 순서대로 전송
- TCP(Transmission Control Protocol)를 기반으로 작동
- 신뢰성 보장(순서 보장, 패킷 손실 및 중복 처리)
- 파일 전송, 웹 브라우징, 이메일 등 데이터의 완전한 신뢰성이 필요한 응용 프로그램에 적합
WebServer
웹서버: HTTP 요청을 받아들이고, HTML 문서같은 웹 페이지를 반환하는 프로그램
웹서버의 주요 기능은 웹 페이지를 클라이언트로 전달하는 것
웹 서버의 주요 기능
1. HTTP 요청 처리
2. 정적 콘텐츠 제공
3. HTTP 응답 전송
4. 요청 라우팅
5. 보안 및 인증
6. 로그 기록
웹서버가 동적 컨텐츠를 제공하기 위해서는 웹서버는 받은 요청을 WAS로 보내고, 결과를 받아서 클라이언트에 전송한다.
대표적인 웹 서버 소프트웨어
- 아파치
- Nginx
- IIS
- Tomcat
웹서버와 WAS(웹 어플리케이션 서버)는 다른 개념이다.
동적 콘텐츠 제공, 복잡한 비지니스 로직은 WAS가 담당한다.
예를 들어 서버 내 알고리즘, 비니지스 로직, DB조회, 동적 콘텐츠 생성 등은 웹 서버가 아닌 WAS가 담당한다.
웹 서버와 웹 어플리케이션 서버를 분리하는 이유는?
CPU와 GPU의 역할 분배와 비슷하다.
복잡한 로직은 WAS에서 처리하고, 비교적 단순한 처리는 웹 서버에서 처리한다.
또한 물리적 분리를 위해 보안이 강화된다.
웹 서버 1대에 여러 대의 WAS를 연결하여 로드 밸런싱 용도로 쓸 수도 있다.
수평 스케일링이 유리하다.
여러 언어의 웹 어플리케이션 서비스가 가능하다.(다양한 기술 스택 활용)
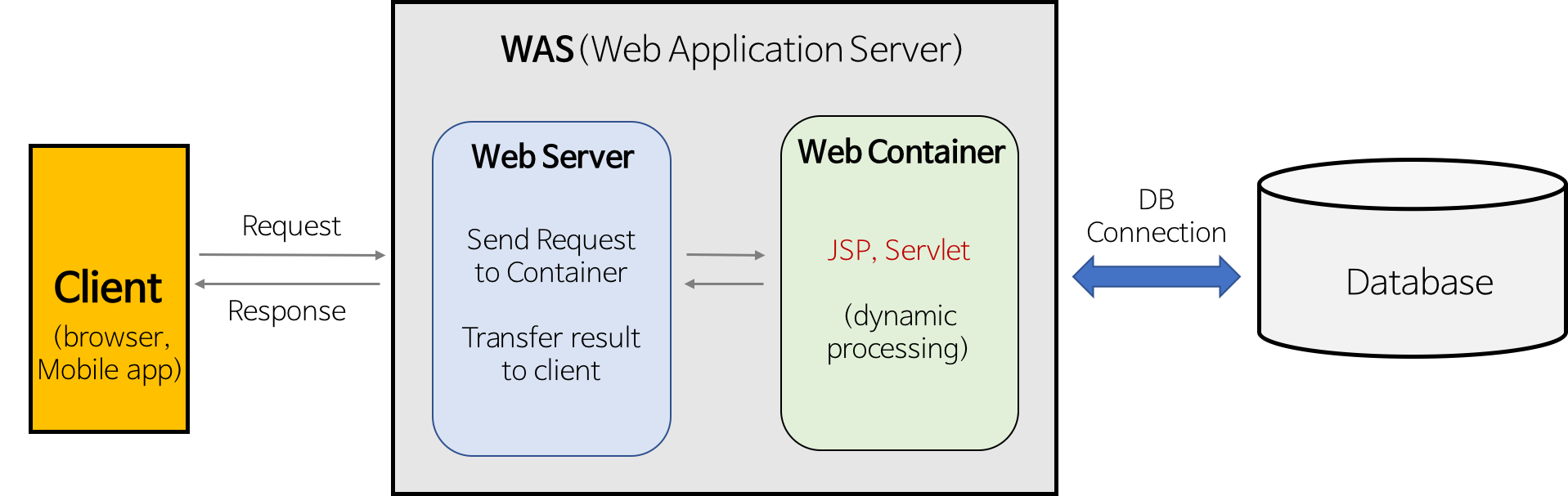
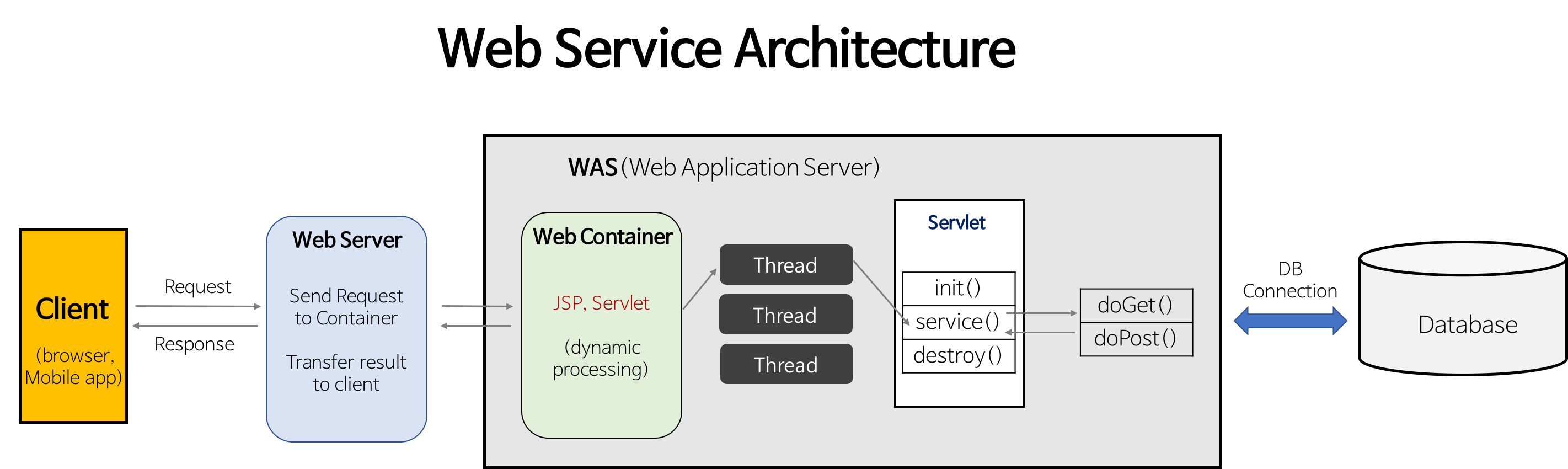
그림처럼 통합할 수도 있도 별도로 둘 수도 있다.
CGI(Common Gateway Interface)
공용 게이트웨이 인터페이스
웹 서버에서 동적인 페이지를 보여 주기 위해 임의의 프로그램을 실행할 수 있는 기술
(동적 페이지 구현 기술의 원조)
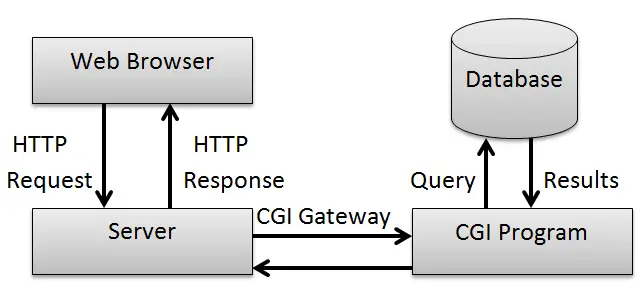
게이트웨이가 뭐지?
네트워크에서 서로 다른 통신말이나 프로토콜을 사용하는 네트워크 간의 통신을 가능하게 가능 컴퓨터 또는 소프트웨어
게이트웨이를 파나마 운하에 비유하면 될 것 같은..?
해수면 높이 차이를 완충시켜서 서로 다른 뱃길을 연결시켜주는 느낌
왜 '공용'이라는 말이 붙었을까?
CGI는 특정 웹서버에 종속되지 않고 다양한 종류의 웹서버에서 실행될 수 있어서 '공용'이라고 한다.
CGI의 역할
게이트웨이 정의에 따라 CGI는 웹 서버와 외부 프로그램(또는 스크립트)의 상호 작용을 돕는다.
예를 들어 웹서버와 데이터베이스의 통신해서 데이터베이스의 쿼리를 이용해 동적 컨텐츠 생성을 할 때 데이터베이스와 웹서버가 통신해야 한다. 이때 서로의 프로토콜이 다른데 이걸 맞춰주는 게 CGI의 역할.
파이썬 CGI 예시
#!/usr/bin/python3
import cgi
import sqlite3
# 웹 요청 파라미터를 파싱
form = cgi.FieldStorage()
# 데이터베이스 연결
conn = sqlite3.connect('example.db')
cursor = conn.cursor()
# 데이터베이스에 사용자 정보 입력
if 'username' in form and 'email' in form:
username = form['username'].value
email = form['email'].value
cursor.execute("INSERT INTO users (username, email) VALUES (?, ?)", (username, email))
conn.commit()
# 사용자 정보 조회
cursor.execute("SELECT * FROM users")
users = cursor.fetchall()
# 웹 페이지 출력
print("Content-type: text/html\n")
print("<html><head><title>Python CGI with Database</title></head><body>")
print("<h1>Users:</h1>")
print("<ul>")
for user in users:
print(f"<li>{user[1]} - {user[2]}</li>")
print("</ul>")
print("<h2>Enter User Information:</h2>")
print("<form method='post' action='cgi_script.py'>")
print("Username: <input type='text' name='username'><br>")
print("Email: <input type='text' name='email'><br>")
print("<input type='submit' value='Submit'>")
print("</form>")
print("</body></html>")
# 데이터베이스 연결 종료
conn.close()CGI는 요청이 들어오면 프로세스가 하나씩 실행된다는 강력한 단점 때문에 현재는 널리 쓰이지 않는다.
MIME Type
Multipurpose Internet Mail Extensions
인터넷과 메일에서 다양한 멀티미디어 데이터 형식을 지원하기 위해 개발된 표준
초창기에는 이메일(전자우편, interner mail)에서 미디어를 처리하기 위해 만들어졌으나, 이후에는 웹에서도 처리하게 됨.
초창기 인터넷에서 콘텐츠는 텍스트가 전부였고, 이건 아스키로 주고 받으면 되었다.
하지만 콘텐츠 종류가 다양해지면서 아스키가 아닌 바이너리 파일을 보내는 경우가 생겼고,
이메일에 이러한 콘텐츠를 담기 위해서 바이너리 파일을 텍스트로 변환해야 했다.
이때 변환된 텍스트 파일이 원래 어떤 유형의 바이너리 파일이였는지를 표기해야 했고,
이렇게 콘텐츠의 다양한 형태를 표기하는 표준이 MIME Type이다.
인터넷에서 다양한 미디어 유형 및 파일 형식 표준 식별자
웹 브라우저와 웹 서버가 어떤 종류의 데이터가 전송되고 처리해야 하는지 알려줌
타입/서브타입 형태로 표기
'미디어'에 대한 오해!
나에게 '미디어'란 영상과 같은 동적인 컨텐츠를 떠올리게 한다.
하지만 인터넷에서 미디어란 '디지털 콘텐츠'를 통칭하는 용어이다.
따라서 비디오 뿐만 아니라 텍스트, 이미지, 오디오, 비디오, 내이메이션 등 다양한 형태일 수 있다.
즉, 텍스트도 미디어다!
그럼 'content-type'은 뭘까?
MIME Type이 일종의 추상적인 규약이라면 HTTP프로토콜에서 MIME Type을 구체화한 게 Content-Type이다. 즉, Content Type이 MIME Type을 이용하는 것!
대표적인 MIME Type
text/html: HTML 문서의 MIME Type입니다. 웹 페이지를 표현하는 데 사용됩니다.
image/jpeg: JPEG 이미지의 MIME Type으로, 정적 이미지를 나타냅니다.
audio/mp3: MP3 오디오 파일의 MIME Type으로, 음악 파일을 나타냅니다.
video/mp4: MP4 비디오 파일의 MIME Type으로, 비디오 파일을 나타냅니다.
application/pdf: PDF 문서의 MIME Type으로, 전자 문서를 나타냅니다.
application/json: JSON 데이터의 MIME Type으로, 데이터 교환 형식을 나타냅니다.
text/css: CSS 스타일 시트의 MIME Type으로, 웹 페이지의 스타일을 정의하는 데 사용됩니다.
application/javascript: JavaScript 코드의 MIME Type으로, 웹 페이지의 동적 기능을 구현하는 데 사용됩니다.
image/png: PNG 이미지의 MIME Type으로, 투명한 이미지를 나타냅니다.
text/plain: 일반 텍스트의 MIME Type으로, 텍스트 파일을 나타냅니다.
HTTP
Hyper Text Transfer Protocol
웹상에서 정보를 주고받을 수 있는 프로토콜
역사
1996년 HTTP/1.0
1999년 HTTP/1.1
2015년 HTTP/2
2022년 HTTP/3
HTTP가 뭐야?
요약하면 클라이언트와 서버 사이에서 이루어지느 요청, 응답 프로토콜
어떻게 요청하고, 어떻게 응답할지 정해놓은 규약이다.
정해진 양식으로 요청과 응답이 이루어지면 서버와 클라이언트는 그에 따라 필요한 작업을 할 수 있다.
비유하면 우편 보낼 때 받는이, 이름, 우편번호, 도로명 주소 등을 적어야 하는 규약과 같은 것.
결국 어떤 메시지 포맷으로 요청, 응답이 이루어지는지 정해놓은 것
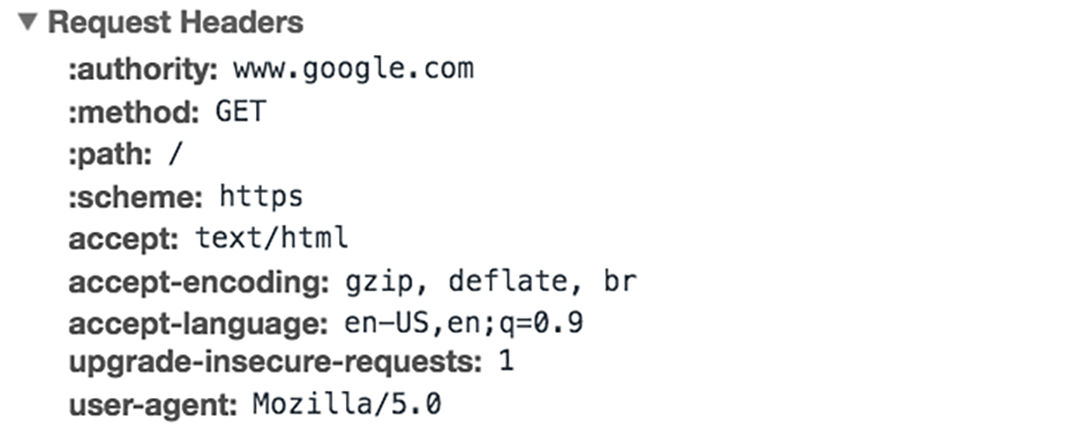
요청(Request) 구성 요소
1. HTTP 메서드
GET, POST, PUT, DELETE, PATCH
2. URI
/index.html, /api/users/123
URI과 URL의 차이는?
URI는 해당 리소스 그 자체를 식별하는 고유한 식별자이며, URL은 위치를 나타낸다.
마치 값과 포인터의 관계
3. HTTP 버전
HTTP/1.1
4. 헤더
요청에 대한 추가 정보
Host, User-Agent, Content-Type, Set-Cookie 등
5. 요청 본문
POST, PUT, PATCH 등에서 사용
(GET은 본문 안 날아감)
서버로 전송하는 데이터가 포함됨
예를 들어 폼 데이터, JSON 데이터, 파일 업로드
6. 쿼리 매개변수
URI에 포함되는 매개 변수
주로 GET에서 사용
?page=1&size=10
응답(Response) 구성 요소
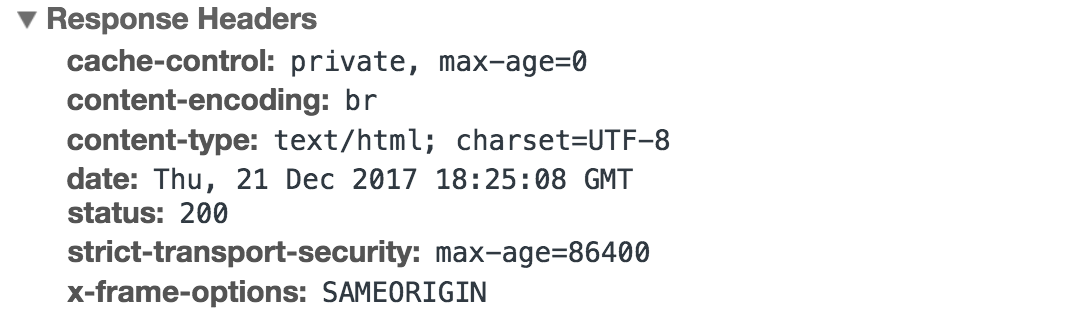
1. 상태 라인
응답 상태 코드와 상태 메시지
HTTP/1.1 200 OK, HTTP/1.1 404 Not Found
2. 헤더
응답에 대한 추가 정보
Content-Type, Content-Length, Cache-Control 등
3. 응답 본문
HTML, 이미지, JSON 등
4. 쿠키(헤더에 실려서 전송)
서버가 클아이언트에게 설정하는 정보, 클아이언트 상태 정보 유지 및 세션 추적에 사용
set-Cookie헤더로 전송되며, 클라이언트를 이를 저장하고 이후 요청 시 자동 재전송(헤더에 실려서 감) 함.
URI
URI는 리소스를 식별하는 일반적인 개념을 나타냄
URL말고 URN도 있음
(URN 형식) urn:namespace:identifier
대표적으로 ISBN을 표현할 수 있다.
urn:isbn:0451450523
URN은 이름만 식별한다. URL은 해당 콘텐츠가 삭제되면 접근이 불가능하다.
그래서 고유한 식별체계인 URN을 쓴다.
특정 콘텐츠의 인터넷 ID라고 생각하면 됨.
URI 구조
scheme://host:port/path?query#fragment
scheme: 리소스에 접근하기 위한 프로토콜 (예: "http", "https").
host: 리소스를 호스팅하는 서버의 도메인 이름 또는 IP 주소.
port: 서버의 포트 번호 (일반적으로 생략될 수 있으며, 기본값은 프로토콜에 따라 다릅니다).
path: 서버에서 리소스의 위치를 지정하는 경로.
query: 요청의 매개변수를 나타내는 쿼리 문자열 (선택적).
fragment: 리소스 내에서 특정 위치를 가리키는 프래그먼트 식별자 (선택적).
상태 코드
HTTP 요청이 성공적으로 완료되었는지 나타내는 3자리 코드
5개의 블록으로 구분됨
- 1XX Informational
- 2XX 성공
- 3XX 리디렉션
- 4XX 클라이언트 오류
- 5XX Server Error
상태코드 목록
https://developer.mozilla.org/ko/docs/Web/HTTP/Status
400번대와 500번대의 차이를 확실하게 알았음! 400번대는 클라이언트 오류, 500번대는 서버쪽 오류였다!
HEAD 메서드
특정 리소스를 GET으로 요청핬을 때 돌아올 헤더를 요청
특정 리소스에 대한 헤더 정보를 요청할 때 사용
GET 메서드와 유사하지만, 본문을 반환하지 않고 헤더 정보만 응답으로 제공
HEAD 메서드에 대한 응답은 본문을 가져서는 안 된다.
응답 시 Content-Length 같은 개체 헤더는 포함할 수 있으나,
이때 개체 헤더는 HEAD의 본문이 아닌(HEAD의 응답에는 본문이 없으므로)
GET메서드로 요청했을 때를 가정해서 Content-Length가 포함되는 것
HEAD 메서드를 왜 쓸까?
- 리소스의 수정 일자, 크기, MIME 타입, 기타 헤더 정보만을 확인할 용도
- 리소스가 존재하는지 확인(리소스가 없으면 404 반환)
- 캐싱 관리(리소스가 수정되었는지 확인 가능)
- 본문이 필요없는 경우 본문을 가져오지 않아 데이터 전송량 감소로 네트워크 대역폭 절약
- 리소스 본문 숨길 때 사용
GET, POST, PATCH, PUT, DELETE 외에 HEAD 메서드는 처음 들어본다..?
알고 보니 이것 외에도 다양한 메서드들이 있었음?!

HTTP 관련해서는 아래 사이트 참고!
https://developer.mozilla.org/ko/docs/Web/HTTP/Headers/Accept
Proxy
프록시란?
proxy는 대리자라는 뜻
네트워크에서 중간 매개체 역할을 하는 서버 또는 소프트웨어를 뜻함.
클라이언트와 서버 통신을 중계, 필터링
- 익명성 : 클라이언트 IP 숨김
- 보안 강화 : 외부 통신 중계
- 캐싱 : 이전 요청 리소스를 캐싱
- 접근 제어 : 기업 네트워크에서 특정 웹 사이트, 콘텐츠 접근 제한
- 로드 밸런싱 : 여러 서버에 대한 부하 분산 및 로드 밸런싱
프록시의 종류
포워드 프록시(Forward Proxy)
일반적으로 프록시라고 하면 포워드 프록시는 말한다.
- 클라이언트를 대신하여 외부 서버 또는 리소스에 접근
- 클라이언트 -> 포워드 프록시 -> 인터넷 -> 서버
- 클라이언트 익명성 보호 목적
- 방화벽 통과하여 외부 서버 접근
-캐싱을 통한 웹 페이지 로딩 속도 향상
-대표적으로 회사 내부 네트워크에서 인터넷 접속할 때 프록시 서버 사용
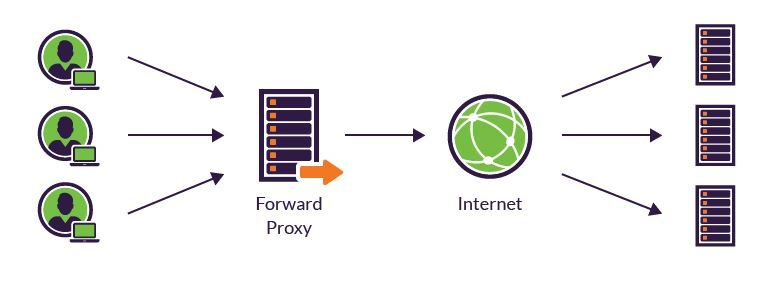
서버 입장에서는 어떤 클라이언트가 요청을 보냈는지 알 수가 없다.
왜냐면 프록시 서버를 경유해서 프록시가 서버에 요청하기 때문이다.
리버스 프록시(Reverse Proxy)
- 서버를 대신하여 프록시 서버가 클라이언트 요청에 응답함.
- 클라이언트 -> 인터넷 -> 리버스 프록시 -> 서버
- 서버 익명성 보호 목적
- 대표적으로 인터넷망에서 내부 인트라넷 서버 호출하기 위해 프록시 서버에 요청하면 프록시 서버가 내부 망에 접속하여 응답해 주는 것
- HTTPS 인증서 관리에도 유용하다. 프록시 서버에만 SSL 인증서 설치하고, 나머지 서버는 그냥 써도 됨. 어차피 나머지 서버는 프록시 서버하고만 통신하니까 문제 없음.
- 웹서버인 NGINX가 리버스 프록시 역할도 함.
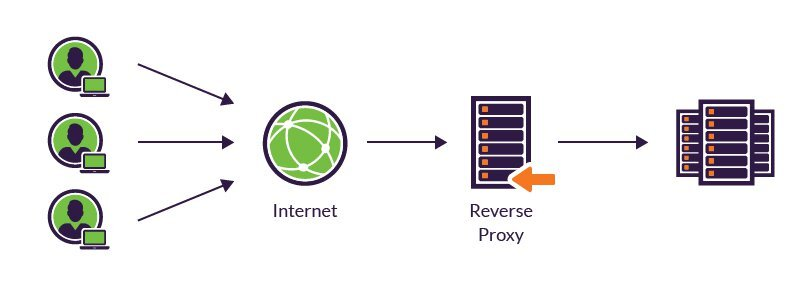
클라이언트 입장에서는 어떤 서버로부터 응답을 받았는지 알 수가 없다.
클라이언트가 프록시 서버에 요청하고, 프록시 서버가 숨겨진 서버를 호출하기 때문이다.
왜 각각 '포워드', '리버스'일까?
이건 통신의 흐름을 생각하면 된다.
포워드는 클라이언트 -> 서버쪽으로 흐르는 통신에 초점이 맞춰져 있고,
리버스는 클라이언트 <- 서버쪽으로 흐르는 통신에 초점이 맞춰져 있다.
포워드는 클라이언트쪽 네트워크게 구성되고, 리버스는 서버쪽 네트워크에 구성된다.
파일 디스크립터
파일 서술자, 파일 식별자
파일 제어 블록이라고도 함.(FCB, File Control Block)
특정 파일에 접근하기 위한 추상적인 키
정수로 표현된다
- 표준 입력: 0, 키보드 입력을 나타냄
- 표준 출력: 1, 모니터 또는 터미널 출력
- 표준 에러: 2, 오류 메시지 출력
파일 디스크립터는 CSAPP에서 자세히 살펴보기!
CSAPP 10 시스템 수준 입출력
10.1 Unix I/O
리눅스에서 네트워크, 디슽, 터미널 등 I/O 디바이스는 모두 파일로 모델링 된다.
따라서 모든 I/O 동작은 해당 파일을 읽거나 쓰는 형식으로 수행된다.
즉, 디바이스가 파일로 매핑되는 것!
따라서 디바이스에 접근하는 건 그냥 파일을 여는 것과 마찬가지이다.
리눅스는 '모든 것이 파일이다'는 철학
10.2 파일
리눅스 파일의 타입
- 일반 파일 : 텍스트 파일, 바이너리 파일
- 디렉토리: 링크들의 배열. 각각의 디렉토리는 (.)과 (..)의 링크를 포함한다.
- 소켓: 네트워크 상 다른 프로세스와 통신하기 위한 파일
이것 외에 이름 있는 파이프, 심볼형 링크, 문자 및 블록 장치가 있으나 CSAPP 범위를 벗어남.
빈 디렉토리(또는 임의의 디렉토리)에서
ls -a을 했을 때 나오는.과..이 결국 링크였음.
그리고 이것 또한 파일이다.
리눅스에서 /는 루트 디렉토리를 의미하며, 모든 파일은 루트 디렉토리의 후손이다.
절대 경로와 상대 경로
절대 경로
사선(루트)으로 시작, 루트로부터의 경로를 나타냄.
/home/droh/lello.c
상대 경로
파일 이름부터 시작, 현재 작업 디렉토리로부터의 경로를 나타냄.
./hello.c
../home/droh/hello.c
10.3 파일 열기와 닫기(연습문제 10.1)
int open(char *filename, int flags, mode_t mode);
flags인자
- O_RDONLY: reading only
- O_WRONLY: writing only
- O_RDWR: reading and writing
비트 마스크로 추가 비트 or 연산 가능
- O_CREAT: 열려는 파일이 존재하지 않으면 비어 있는 파일 생성
- O_TRUNC: 파일이 이미 존재하면 파일 내용 비우기
- O_APPEND: 매 쓰기 연산 전에 파일 위치를 파일의 마지막으로 설정
mode 인자
접근 권한 비트

#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
int fd1, fd2;
fd1 = open("foo.txt", O_RDONLY, 0); // 이 시점에서 파일 식별자는 3
close(fd1); // 파일이 종료되면서 3식별자 사라짐
fd2 = open("./baz.txt", O_RDONLY, 0); // 식별자 3으로 파일 오픈
printf("fd2 = %d\n", fd2); // fd2 = 3 이 출력된다. 단, 파일이 없으면 -1 출력
exit(0);
}c가 제대로 실행되지는 않음.
파일 식별자는 정수로 표현된다.
0: 표준 입력
1: 표준 출력
2: 표준 오류 출력
이후 열린 파일에 대하여 식별자 3부터 시작해서 연속적으로 부여된다.
즉, 첫 번째 열린 파일은 식별자 3을 할당 받는다.
파일 식별자는 프로세스 내에서 파일을 식별하고 관리하는데 사용된다.
파일 디스크립터 이해됨! 파일 식별자라고 해석하는게 가장 쉽다.
파일을 열었을 때 그 파일에 번호를 부여하는 것.
리눅스에서는 모든 것이 파일이기 때문에 외부 디바이스로 파일 식별자가 부여되는 것
이미 닫은 파일 식별자를 닫게 되면 에러가 발생한다.
파일을 오픈했는데 왜 파일 내용이 변수에 안 담길까?
open()은 파일 내용을 오픈하는게 아니라 해당 파일을 오픈하고 식별자를 부여하는 함수다.
파일 내용을 읽으려면 식별자를 read()로 호출하면 된다.
10.4 파일 읽기와 쓰기
read(), write() 함수를 이용해서 읽기와 쓰기 수행할 수 있다.
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
int fd; // 파일 식별자
char buffer[1024]; // 데이터를 읽고 쓸 버퍼
// 파일 열기 (읽기 모드)
fd = open("input.txt", O_RDONLY);
if (fd == -1) {
perror("open");
exit(1);
}
// 파일 읽기
ssize_t bytes_read;
while ((bytes_read = read(fd, buffer, sizeof(buffer))) > 0) {
// 읽은 데이터를 화면에 출력
write(STDOUT_FILENO, buffer, bytes_read);
}
// 파일 닫기
close(fd);
return 0;
}
10.5 RIO I/O 패키지
구현 파트는 추후 따로 구현해보기!
10.6 파일 메타테이터 읽기
stat(), fstat() 함수를 호출해서 메타테이터를 읽을 수 있음.
stat()은 파일 이름으로 구초체를 채워주고,
fstat()은 파일 이름 대신 파일 식별자를 인자로 받는다.
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
int fd;
struct stat file_stat;
// 파일 열기
fd = open("example.txt", O_RDONLY);
if (fd == -1) {
perror("open");
return 1;
}
// 파일 메타데이터 읽기 (fstat)
if (fstat(fd, &file_stat) == -1) {
perror("fstat");
close(fd);
return 1;
}
// 파일 크기 출력
printf("File Size: %lld bytes\n", (long long)file_stat.st_size);
// 파일 종료
close(fd);
return 0;
}
10.7 디렉토리 내용 읽기
readdir() 계열 함수로 디렉토리 내용 읽을 수 있음.
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <dirent.h>
int main() {
DIR *dir;
struct dirent *entry;
// 디렉토리 열기
dir = opendir(".");
if (dir == NULL) {
perror("opendir");
return 1;
}
// 디렉토리 내의 파일 및 하위 디렉토리 읽기
while ((entry = readdir(dir)) != NULL) {
printf("%s\n", entry->d_name);
}
// 디렉토리 닫기
closedir(dir);
return 0;
}10.8 파일 공유
커널은 세 개의 자료구조로 오픈한 파일을 표현함.
파일 공유 메커니즘을 통해 서로 다른 프로세스가 동일한 파일을 참조할 수 있게 한다.
예를 들어 서로 다른 프로세스가 한 개의 파일에 로그를 작성하는 등
식별자 테이블
프로세스별로 식별자 테이블 보유
파일 테이블
모든 프로세스들이 공유하는 한 개의 파일 테이블
식별자를 닫으면(또는 프로세스가 종료되면) 파일 테이블 엔트리에서 참조 횟수 감소
v-노드 테이블
모든 프로세스들이 공유하는 파일 메타데이터 관리 테이블
각 엔트리는 st_mode, st_size 포함해서 stat 구조 대부분 정보 보유
세 개의 테이블을 각각 독립된 테이블이 아니라,
일종의 계층적 테이블이라고 할 수 있음.
할당기 구현 후에 파일 시스템 관련 코드를 보니까 코드가 훨씬 더 잘 이해됨.
파일 시스템이 어떻게 구현되었는지는 모르겠지만 이것 또한 추상화된 기능이라는 점에서는 동일!
10.9 I/O 재지정
리눅스 쉘에서 표준 입력 및 출력의 방향을 디스크 파일과 연결하는 기능
I/O 재지정 연산자는 > 또는 <
ls > foo.txt
이 명령어에서 쉘은 ls 프로그램을 로드하고 실행한다.
원래 표준 출력을 모니터이므로, 결과가 모니터로 출력되지만 재지정 연산자로
출력의 흐름을 foo.txt로 바꿔주었기 때문에 출력 결과가 모니터가 아닌 foo.txt로 넘어간다.
파일 시스템 함수로는 dup2()를 이용할 수 있다.
dup2()는 식별자 테이블 엔트리의 이전 내용을 덮어써서
식별자 테이블 엔트리 oldfd를 newfd로 복사한다.
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main() {
int fd1, fd2;
// 파일을 열고 fd1에 연결
fd1 = open("file.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
if (fd1 == -1) {
perror("open");
return 1;
}
// fd1을 복제하여 fd2에 연결 (새로운 파일 디스크립터)
fd2 = dup2(fd1, 100); // 100은 임의의 다른 파일 디스크립터 번호
if (fd2 == -1) {
perror("dup2");
return 1;
}
// fd1 또는 fd2를 통해 파일에 쓰기
write(fd1, "Hello, fd1!\n", 12);
write(fd2, "Hello, fd2!\n", 12);
// 파일 디스크립터 닫기
close(fd1);
close(fd2);
return 0;
}재지정 연산 왜 하는지 잘 이해 안되서 GPT 물어 봄.

재지정 연산자
>과>>차이는?
>는 덮어쓰기,>>은 새로운 파일 생성 및 추가
연습문제 10.2
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
// foobar.txt는 아스키 문자 "foobar"가 저장됨
int main()
{
int fd1, fd2;
char c;
fd1 = open("foobar.txt", O_RDONLY, 0);
fd2 = open("foobar.txt", O_RDONLY, 0);
read(fd1, &c, 1); // fd1에서 1바이트를 읽어서 변수에 저장
read(fd2, &c, 1); // fd2에서 1바이트를 읽어서 변수에 저장
printf("c = %c\n", c); // "c = f"
exit(0);
}연습문제 10.4
표준 입력을 식별자 5로 재지정하려면 dup2를 어떻게 사용하겠는가?
dup2(5,0)
위 코드는 키보드로 입력받는 표준 입력을 파일 디스크립터 5로 연결한다.
이 파일은 텍스트 파일일 수도 있고, 또는 다른 하드웨어 장치일 수도 있다.
10.11 리눅스 I/O & C표준 I/O & Rio(Robust I/O 패키지)
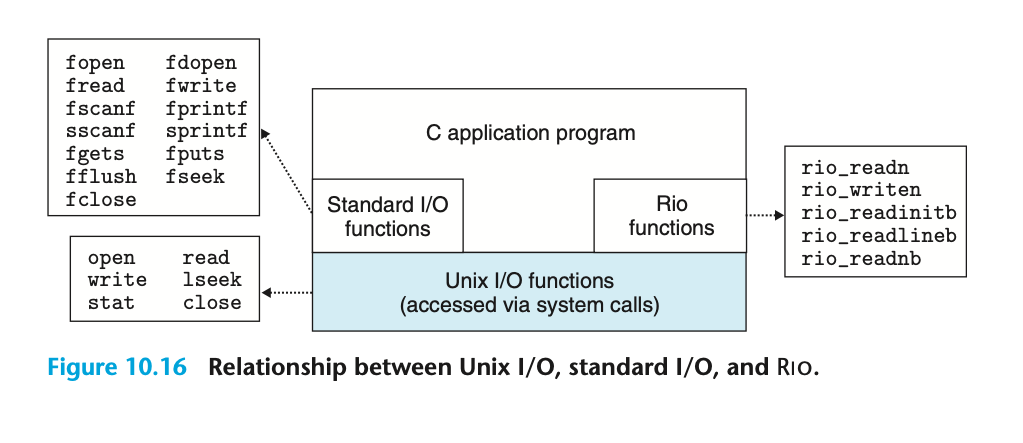
대부분의 경우는 표준 I/O를 쓰는게 좋지만, 네트워크 환경에서는 표준 I/O를 지원하지 않는 경우가 많아 Rio 패키지를 쓰는 걸 권장
Rio는 C 라이브러리로 주로 소켓 프로그래밍 및 네트워크 통신에 사용됨.
표준 I/O가 있는데 왜 Rio가 있는 걸까?
표준 I/O는 간단한 입출력에는 효과적이지만 복잡한 작업에는 제한적임. 오류 처리, 비동기, 효율성, 추가 기능, 일관성 등 기존 표준 I/O를 보완하여 별도 연구자들이 개발한 입출력 라이브러리임.
내일 연습문제 3, 5 풀기!
오늘은 23시 퇴근
