08:11 입실
명시적 리스트 4가지 할당 전략 구현하기!
분리 가용 리스트(segregated는 적어도 개념은 익히기!)
malloc lab
할당 가능한 블록에는 앞, 뒤 포인터가 있다.
이때 메모리 블록이 3더블워드를 유지할 필요는 없다.
왜냐하면 할당 가능할 상태일 때는 앞, 뒤 포인터의 더블워드가 필요하지만
할당 후에는 이 포인터 위치는 필요 없기 때문에
전체 메모리 블록은 여전히 2더블워드만 유지하면 된다.
할당된 메모리 블록은 앞, 뒤 포인터(더블워드 크기) 필드가 필요없다!
그럼 왜 초기화 때 이미 할당된 블록인 프롤로그 블록에는 포인터 필드가 들어가나?
그건 초기부터 명시적 가용 리스트를 활용하기 위해서임.
이렇게 하면 프롤로그와 에플로그 블록을 명시적 가용 리스트 경계로 활용 가능
이거 이해 못해서 코드 한참 들여다 봄.
명시적 해제 리스트 next fit 구현
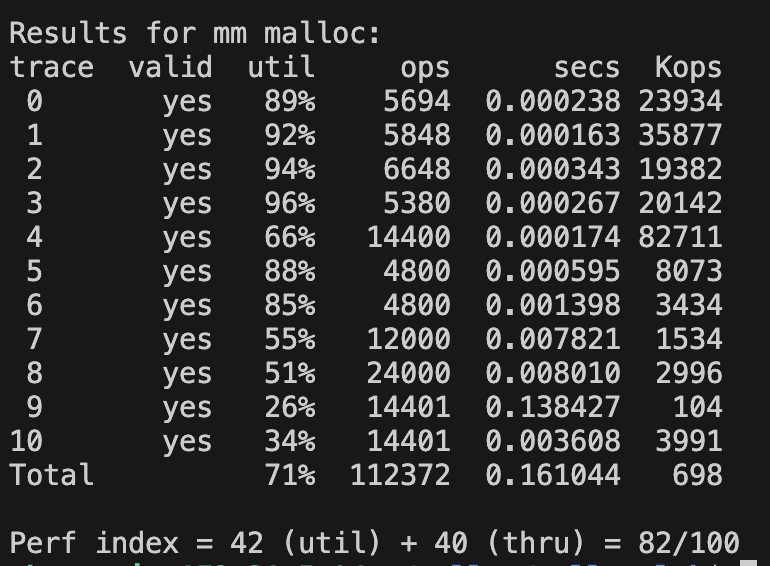
기존 작성한 코드 참고해서 구현.
반복문 조건에서 마지막 블록 탐색하는 걸 생각못해서 오래 걸림.
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <unistd.h>
#include <string.h>
#include "mm.h"
#include "memlib.h"
/* single word (4) or double word (8) alignment */
#define ALIGNMENT 8
/* rounds up to the nearest multiple of ALIGNMENT */
#define ALIGN(size) (((size) + (ALIGNMENT - 1)) & ~0x7)
#define SIZE_T_SIZE (ALIGN(sizeof(size_t)))
/* Basic constants and macros */
#define WSIZE 4
#define DSIZE 8
#define CHUNKSIZE (1 << 12)
#define MAX(x, y) ((x) > (y) ? (x) : (y))
#define PACK(size, alloc) ((size) | (alloc))
#define GET(p) (*(unsigned int *)(p))
#define PUT(p, val) (*(unsigned int *)(p) = (val))
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1)
#define HDRP(bp) ((char *)(bp) - (WSIZE))
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - (DSIZE))
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp)-WSIZE)))
#define PREV_BLKP(bp) ((char *)(bp)-GET_SIZE(((char *)(bp)-DSIZE)))
#define PRED_FREEP(bp) (*(void **)(bp))
#define SUCC_FREEP(bp) (*(void **)(bp + WSIZE))
static void *heap_listp;
static void *free_listp;
static void *last_bp;
static void *extend_heap(size_t words);
static void *coalesce(void *bp);
static void *find_fit(size_t allocated_size);
static void *next_fit(size_t allocated_size);
static void place(void *bp, size_t allocated_size);
static void append_free_block(void *bp);
static void remove_free_block(void *bp);
int mm_init(void)
{
if ((heap_listp = mem_sbrk(6 * WSIZE)) == (void *)-1)
return -1;
PUT(heap_listp, 0);
PUT(heap_listp + (1 * WSIZE), PACK(DSIZE * 2, 1));
PUT(heap_listp + (2 * WSIZE), NULL);
PUT(heap_listp + (3 * WSIZE), NULL);
PUT(heap_listp + (4 * WSIZE), PACK(DSIZE * 2, 1));
PUT(heap_listp + (5 * WSIZE), PACK(0, 1));
free_listp = heap_listp + DSIZE;
last_bp = free_listp;
if (extend_heap(CHUNKSIZE / WSIZE) == NULL)
return -1;
return 0;
}
static void *extend_heap(size_t words)
{
void *bp;
size_t size;
size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE;
if ((bp = mem_sbrk(size)) == (void *)-1)
return NULL;
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1));
return coalesce(bp);
}
void *mm_malloc(size_t size)
{
size_t allocated_size;
size_t extendsize;
char *bp;
if (size == 0)
return NULL;
if (size <= DSIZE)
allocated_size = 2 * DSIZE;
else
allocated_size = DSIZE * ((size + (DSIZE) + (DSIZE - 1)) / DSIZE);
if ((bp = find_fit(allocated_size)) != NULL)
{
place(bp, allocated_size);
return bp;
}
extendsize = MAX(allocated_size, CHUNKSIZE);
if ((bp = extend_heap(extendsize / WSIZE)) == NULL)
return NULL;
place(bp, allocated_size);
return bp;
}
void append_free_block(void *bp)
{
SUCC_FREEP(bp) = free_listp;
PRED_FREEP(bp) = NULL;
PRED_FREEP(free_listp) = bp;
free_listp = bp;
}
void remove_free_block(void *bp)
{
if (bp == free_listp)
{
PRED_FREEP(SUCC_FREEP(bp)) = NULL;
free_listp = SUCC_FREEP(bp);
}
else
{
SUCC_FREEP(PRED_FREEP(bp)) = SUCC_FREEP(bp);
PRED_FREEP(SUCC_FREEP(bp)) = PRED_FREEP(bp);
}
}
static void *find_fit(size_t allocated_size)
{
return next_fit(allocated_size);
}
static void *next_fit(size_t allocated_size)
{
void *bp;
for (bp = last_bp; GET_ALLOC(HDRP(bp)) != 1; bp = SUCC_FREEP(bp))
{
if (allocated_size <= GET_SIZE(HDRP(bp)))
{
last_bp = bp;
return bp;
}
}
for (bp = free_listp; GET_ALLOC(HDRP(bp)) != 1 && bp != last_bp; bp = SUCC_FREEP(bp))
{
if (allocated_size <= GET_SIZE(HDRP(bp)))
{
last_bp = bp;
return bp;
}
}
return NULL;
}
static void place(void *bp, size_t allocated_size)
{
size_t current_size = GET_SIZE(HDRP(bp));
remove_free_block(bp);
if ((current_size - allocated_size) >= (2 * DSIZE))
{
PUT(HDRP(bp), PACK(allocated_size, 1));
PUT(FTRP(bp), PACK(allocated_size, 1));
bp = NEXT_BLKP(bp);
PUT(HDRP(bp), PACK(current_size - allocated_size, 0));
PUT(FTRP(bp), PACK(current_size - allocated_size, 0));
append_free_block(bp);
}
else
{
PUT(HDRP(bp), PACK(current_size, 1));
PUT(FTRP(bp), PACK(current_size, 1));
}
}
void mm_free(void *bp)
{
size_t size = GET_SIZE(HDRP(bp));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
coalesce(bp);
}
static void *coalesce(void *bp)
{
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size = GET_SIZE(HDRP(bp));
if (prev_alloc && next_alloc)
{
// 앞, 뒤 모두 할당 블록이므로 병합 불가
}
else if (prev_alloc && !next_alloc)
{
remove_free_block(NEXT_BLKP(bp));
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}
else if (!prev_alloc && next_alloc)
{
remove_free_block(PREV_BLKP(bp));
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
bp = PREV_BLKP(bp);
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}
else
{
remove_free_block(PREV_BLKP(bp));
remove_free_block(NEXT_BLKP(bp));
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
append_free_block(bp);
last_bp = bp;
return bp;
}
void *mm_realloc(void *bp, size_t size)
{
void *old_bp = bp;
void *new_bp;
size_t copySize;
new_bp = mm_malloc(size);
if (new_bp == NULL)
return NULL;
copySize = GET_SIZE(HDRP(old_bp));
if (size < copySize)
copySize = size;
memcpy(new_bp, old_bp, copySize);
mm_free(old_bp);
return new_bp;
}
구현하고 보니 뭔가 이상했다.
명시적 해제 리스트는 꼭 next fit 전략을 쓸 필요가 없지 않나?
왜냐면 암시적은 처음부터 다 검색하면 불필요한 블록을 검색하니까 next fit이 필요하지만
명시적 해제 리스트는 처음부터 검색해도 모두 할당 가능한 블록이잖아?
그래서 GPT 불어봤더니 청천벽력같은 소식

괜찮음! 그래도 next fit 구현하면서 이중 포인터 개념 익힐 수 있었음
명시적 해제 리스트 best fit 구현
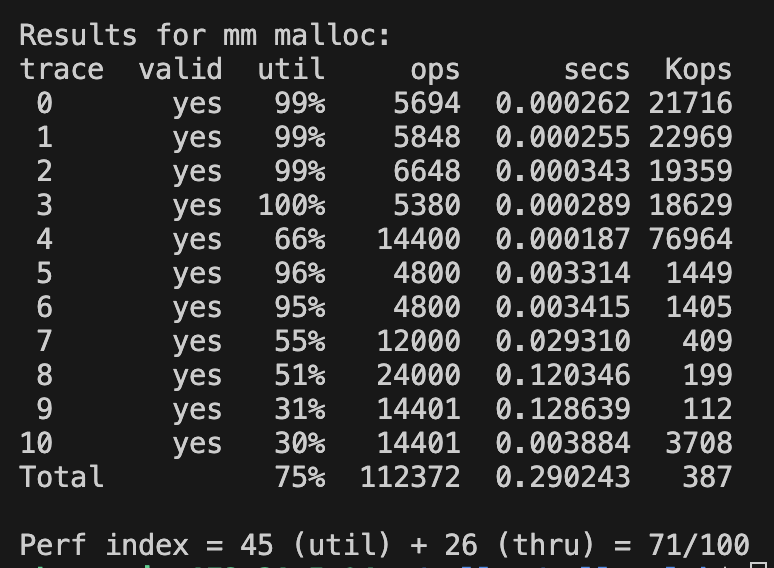
확실히 내부단편화를 최소화하는 로직은 util에서 높은 점수이다.
/*
* mm-naive.c - The fastest, least memory-efficient malloc package.
*
* In this naive approach, a block is allocated by simply incrementing
* the brk pointer. A block is pure payload. There are no headers or
* footers. Blocks are never coalesced or reused. Realloc is
* implemented directly using mm_malloc and mm_free.
*
* NOTE TO STUDENTS: Replace this header comment with your own header
* comment that gives a high level description of your solution.
*/
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <unistd.h>
#include <string.h>
#include <stdint.h>
#include "mm.h"
#include "memlib.h"
/* single word (4) or double word (8) alignment */
#define ALIGNMENT 8
/* rounds up to the nearest multiple of ALIGNMENT */
#define ALIGN(size) (((size) + (ALIGNMENT - 1)) & ~0x7)
#define SIZE_T_SIZE (ALIGN(sizeof(size_t)))
/* Basic constants and macros */
#define WSIZE 4
#define DSIZE 8
#define CHUNKSIZE (1 << 12)
#define MAX(x, y) ((x) > (y) ? (x) : (y))
#define PACK(size, alloc) ((size) | (alloc))
#define GET(p) (*(unsigned int *)(p))
#define PUT(p, val) (*(unsigned int *)(p) = (val))
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1)
#define HDRP(bp) ((char *)(bp) - (WSIZE))
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - (DSIZE))
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp)-WSIZE)))
#define PREV_BLKP(bp) ((char *)(bp)-GET_SIZE(((char *)(bp)-DSIZE)))
#define PRED_FREEP(bp) (*(void **)(bp))
#define SUCC_FREEP(bp) (*(void **)(bp + WSIZE))
static void *heap_listp;
static void *free_listp;
static void *extend_heap(size_t words);
static void *coalesce(void *bp);
static void *find_fit(size_t allocated_size);
static void *best_fit(size_t allocated_size);
static void place(void *bp, size_t allocated_size);
static void append_free_block(void *bp);
static void remove_free_block(void *bp);
int mm_init(void)
{
if ((heap_listp = mem_sbrk(6 * WSIZE)) == (void *)-1)
return -1;
PUT(heap_listp, 0);
PUT(heap_listp + (1 * WSIZE), PACK(DSIZE * 2, 1));
PUT(heap_listp + (2 * WSIZE), NULL);
PUT(heap_listp + (3 * WSIZE), NULL);
PUT(heap_listp + (4 * WSIZE), PACK(DSIZE * 2, 1));
PUT(heap_listp + (5 * WSIZE), PACK(0, 1));
free_listp = heap_listp + DSIZE;
if (extend_heap(CHUNKSIZE / WSIZE) == NULL)
return -1;
return 0;
}
static void *extend_heap(size_t words)
{
void *bp;
size_t size;
size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE;
if ((bp = mem_sbrk(size)) == (void *)-1)
return NULL;
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1));
return coalesce(bp);
}
void *mm_malloc(size_t size)
{
size_t allocated_size;
size_t extendsize;
char *bp;
if (size == 0)
return NULL;
if (size <= DSIZE)
allocated_size = 2 * DSIZE;
else
allocated_size = DSIZE * ((size + (DSIZE) + (DSIZE - 1)) / DSIZE);
if ((bp = find_fit(allocated_size)) != NULL)
{
place(bp, allocated_size);
return bp;
}
extendsize = MAX(allocated_size, CHUNKSIZE);
if ((bp = extend_heap(extendsize / WSIZE)) == NULL)
return NULL;
place(bp, allocated_size);
return bp;
}
void append_free_block(void *bp)
{
SUCC_FREEP(bp) = free_listp;
PRED_FREEP(bp) = NULL;
PRED_FREEP(free_listp) = bp;
free_listp = bp;
}
void remove_free_block(void *bp)
{
if (bp == free_listp)
{
PRED_FREEP(SUCC_FREEP(bp)) = NULL;
free_listp = SUCC_FREEP(bp);
}
else
{
SUCC_FREEP(PRED_FREEP(bp)) = SUCC_FREEP(bp);
PRED_FREEP(SUCC_FREEP(bp)) = PRED_FREEP(bp);
}
}
static void *find_fit(size_t allocated_size)
{
return best_fit(allocated_size);
}
static void *best_fit(size_t allocated_size)
{
void *bp;
void *best_fit_bp = NULL;
size_t best_fragmentation_size = SIZE_MAX;
for (bp = free_listp; GET_ALLOC(HDRP(bp)) != 1; bp = SUCC_FREEP(bp))
{
if (allocated_size <= GET_SIZE(HDRP(bp)))
{
size_t fragmentation_size = GET_SIZE(HDRP(bp)) - allocated_size;
if (fragmentation_size < best_fragmentation_size)
{
best_fragmentation_size = fragmentation_size;
best_fit_bp = bp;
}
}
}
return best_fit_bp;
}
static void place(void *bp, size_t allocated_size)
{
size_t current_size = GET_SIZE(HDRP(bp));
remove_free_block(bp);
if ((current_size - allocated_size) >= (2 * DSIZE))
{
PUT(HDRP(bp), PACK(allocated_size, 1));
PUT(FTRP(bp), PACK(allocated_size, 1));
bp = NEXT_BLKP(bp);
PUT(HDRP(bp), PACK(current_size - allocated_size, 0));
PUT(FTRP(bp), PACK(current_size - allocated_size, 0));
append_free_block(bp);
}
else
{
PUT(HDRP(bp), PACK(current_size, 1));
PUT(FTRP(bp), PACK(current_size, 1));
}
}
void mm_free(void *bp)
{
size_t size = GET_SIZE(HDRP(bp));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
coalesce(bp);
}
static void *coalesce(void *bp)
{
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size = GET_SIZE(HDRP(bp));
if (prev_alloc && next_alloc)
{
// 앞, 뒤 모두 할당 블록이므로 병합 불가
}
else if (prev_alloc && !next_alloc)
{
remove_free_block(NEXT_BLKP(bp));
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}
else if (!prev_alloc && next_alloc)
{
remove_free_block(PREV_BLKP(bp));
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
bp = PREV_BLKP(bp);
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}
else
{
remove_free_block(PREV_BLKP(bp));
remove_free_block(NEXT_BLKP(bp));
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
append_free_block(bp);
return bp;
}
void *mm_realloc(void *bp, size_t size)
{
void *old_bp = bp;
void *new_bp;
size_t copySize;
new_bp = mm_malloc(size);
if (new_bp == NULL)
return NULL;
copySize = GET_SIZE(HDRP(old_bp));
if (size < copySize)
copySize = size;
memcpy(new_bp, old_bp, copySize);
mm_free(old_bp);
return new_bp;
}### 명시적 해제 리스트 worst fit 구현
(best fit에서 find fit 부분만 변경)
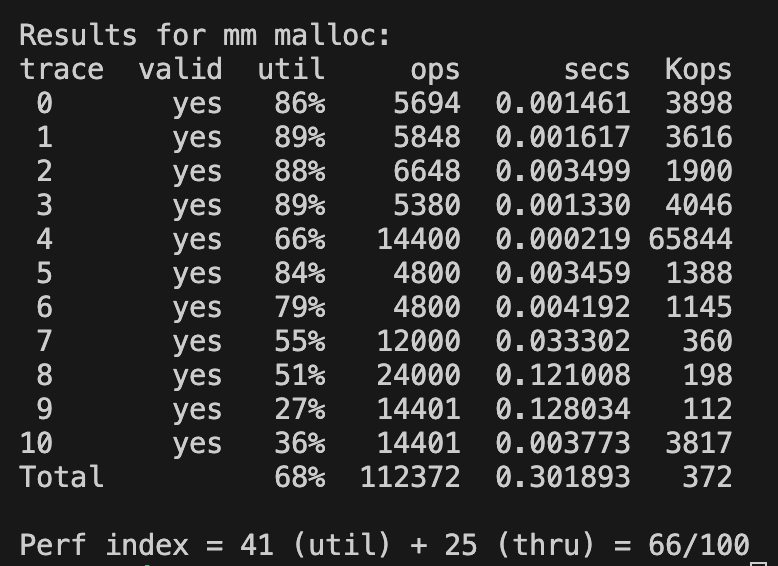
static void *find_fit(size_t allocated_size)
{
return worst_fit(allocated_size);
}
static void *worst_fit(size_t allocated_size)
{
void *bp;
void *worst_fit_bp = NULL;
size_t worst_fragmentation_size = 0;
for (bp = free_listp; GET_ALLOC(HDRP(bp)) != 1; bp = SUCC_FREEP(bp))
{
if (allocated_size <= GET_SIZE(HDRP(bp)))
{
size_t fragmentation_size = GET_SIZE(HDRP(bp)) - allocated_size;
if (fragmentation_size > worst_fragmentation_size)
{
worst_fragmentation_size = fragmentation_size;
worst_fit_bp = bp;
}
}
}
return worst_fit_bp;
}명시적 해제 리스트 & 암시적 해제 리스트 구현 결과 정리
| List Type | Allocation | Utilization(자원 활용도) | throughput(시간당 처리율) | Sum/100 | Rank |
|---|---|---|---|---|---|
| implicit | First Fit | 44 | 8 | 53 | 6️⃣ |
| implicit | Next Fit | 44 | 40 | 84 | 🥇 |
| implicit | Best Fit | 45 | 8 | 53 | 5️⃣ |
| implicit | Worst Fit | 41 | 8 | 49 | 7️⃣ |
| explicit | First Fit | 42 | 40 | 82 | 🥈 |
| explicit | Next Fit | 42 | 40 | 82 | 🥈 |
| explicit | Best Fit | 45 | 26 | 71 | 🥉 |
| explicit | Worst Fit | 41 | 25 | 66 | 4️⃣ |
열심히 달려서 기본적인 암시적 & 명시적 로직은 구현했다!
이제 segregated 구현 도전!
Next Fit 뭔가 이상하다?
next fit에서 궁금한 점
해제 후 병합과정에서 기존 next_bp의 포인터의 메모리 블록이 병합되어 헤더가 사라질 수 있으니까,
coalesce에서 병합 후에는 next_bp의 포인터를 병합되어 할당 가능한 블록으로 옮기는데,
그럼 next fit 알고리즘에 맞는 전략인가?
팀원 설명으로는 코드 상으로는 이 정의를 맞추려면 병합이 일어날 때 무조건 next_bp를 옮기는게 아니라, 병합으로 인해 next_bp 블록이 사라질 때만 옮기면 정의에 맞는 거라고 생각한다고 함. 그럼 이 방법으로 좀더 정확한 코드 짜보기.
병합 시 무조건 next_bp를 옮기는 방식에서 next_bp가 사라질 때만 옮기를 방식으로 수정
static void *coalesce(void *bp)
{
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size = GET_SIZE(HDRP(bp));
if (prev_alloc && next_alloc)
{
if (recent_bp == bp)
{
recent_bp = PREV_BLKP(bp);
}
return bp;
}
else if (prev_alloc && !next_alloc)
{
if (recent_bp == bp || recent_bp == NEXT_BLKP(bp))
{
recent_bp = PREV_BLKP(PREV_BLKP(bp));
}
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}
else if (!prev_alloc && next_alloc)
{
if (recent_bp == bp)
{
recent_bp = PREV_BLKP(PREV_BLKP(bp));
}
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
else
{
if (recent_bp == bp || recent_bp == NEXT_BLKP(bp))
{
recent_bp = PREV_BLKP(PREV_BLKP(bp));
}
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
return bp;
}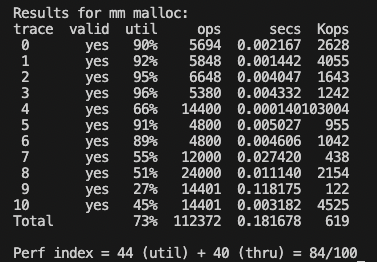
이렇게 했더니 1점 올랐다?!!!
이유를 생각해보니 병합 시 무조건 next_bp를 옮기면,
만약 새로 병합된 블록에 할당을 실패하면 first fit과 마찬가지로 그 이전에 탐색했던 불필요한 블록을 또 탐색해야 됨.
그래서 새로 병합되어 해제 블록이 생기면 그때만 예외적으로 next_bp직전으로 옮겨서 그 블록을 탐색할 기회를 한 번 더 주는 것!
(번외) 과적합 느낌처럼 청크사이즈를 수동으로 조정해 봄
4100~4600: 85점
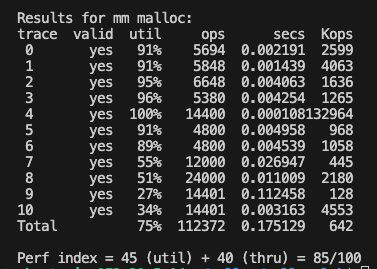
(청크사이즈 4100)
realloc 최적화 (실패!)
현재 realloc은 무조건 새로운 메모리 블록에 할당하는 문제가 있다.
만약 새로운 블록에 할당할 필요가 없다면 기존 블록에서만 조정하면 되지 않을까?
1. 사이즈가 동일한 경우 재할당 하지 않기
결과: 최적화 실패(점수 82~84점 분포)
추정 이유: 헤더에 접근하고, 사이즈를 계산하는데 오버헤드 발생. 하지만 정작 사이즈가 정확히 일치하는 경우가 많지 않음.
if (GET_SIZE(HDRP(bp)) == size)
{
return bp;
}2. 요청 사이즈가 작은 경우 기존 메모리 블록 사이즈만 줄이기
다양한 코드로 실험해 봤지만 계속 테스트 9에서 No 뜨거나 세그멘테이션 폴트 실패
분리 가용 리스트(Segregated Free List)
기존의 묵시적, 명시적 가용 리스트는 단일 가용 블록 리스트였음.
이번에는 다수의 가용 리스트를 사용하는 분리 가용 리스트.
기본 아이디어
각 리스트는 거의 동일한 크기의 블록을 저장
size class의 동일 클래스 집합들로 분리
예) 2의 제곱으로 블록 클래스 나누기
참고할 포스팅
https://velog.io/@gitddabong/week06.-malloc-lab-Segregated-list
C
문자열
c에서 문자열 다루는 게 익숙하지 않아서 정리
#include <stdio.h>
int main()
{
char str1[] = "Hello, world!";
char *str2 = "Hi, world!";
char str3[] = {'H', 'e', 'l', 'l', 'o', '\0'};
printf("%s\n", str1);
printf("%s\n", str2);
printf("%s\n", str3);
return 0;
}C에서는 문자열 자체가 포인터이다.
printf("%s\n", "hello");
배열의 인덱스는 역참조와 같은 표현이다.
printf("%d\n", nums[0]); printf("%d\n", *(nums));
배열로 하나씩 문자를 넣을 때는 마지막에 널 문자가 들어가야한다.
근데 이게 생략되면 컴파일러가 알아서 넣어줌.
시스템 콜
시스템 콜의 핵심
syscall은 특권 레벨 0의 os시스템 콜 핸들러를 깨운다.(invoke)
privilege level은 0~3까지 있다.
0: 커널 모드(수퍼바이저 모드)
1: 하이퍼바이저 모드(가상화 모드)
2: 거의 안 쓰임
3: 유저 모드
시스템 콜의 동작 프로세스
- 일반 함수를 호출하면 연동된 라이브러리 내 시스템 콜 호출
- 시스템 콜은 os수준의 시스템콜 핸들러를 invoke, 이때 커널 모드로 전환되며 제어권이 os로 넘어간다.
- 시스템콜 핸들러는 특권 명령어 수행
- 수행 결과를 라이브러리 내 호출 함수에게 리턴(시스리턴)
시스템콜 확인하기
(리눅스) strace {실행파일}
(맥) dtruss
(유닉스) truss
OSI 7계층
갑자기 궁금해져서 정리해 봄.
(택배 서비스에 비유)
7. 응용 계층(고객 관리)
- 사용자가 직접 상호 작용하는 계층
- 웹 브라우저, 이메일 클라이언트, 파일 공유 프로그램 등 애플리케이션
- 택배를 보낼 물건을 만드는 작업실을 관리(차고, 주방, 공방 등)
6. 표현 계층(고객 관리)
- 데이터 형식 변환, 데이터 암호화, 압축 등과 관련
- 만든 물건 자체를 어떻게 포장할지, 태그는 어떻게 붙일지 결정
5. 세션 계층(고객 관리)
- 컴퓨터간 대화, 데이터 교환 관리
- 퀵서비스, 택배, 등기, 준등기, 일반우편 등 어떻게 보낼지 결정
4. 전송 계층(택배 회사(커널)가 관리)
- 데이터 보내고 받는 데 대한 품질과 속도 관리
- 주소를 입력하고 택배를 접수함.
- 제대로된 주소를 입력해야하고, 명절에는 택배를 못 보냄.
- 너무 큰 택배면 여러 상자에 나눠서 보내야 됨.
3. 네트워크 계층(택배 회사(커널)가 관리)
- 길을 관리, 패킷이 어떻게 목적지로 이동할지 결정
- 택배를 보낼 때 중간 물류센터(터미털, 허브)를 어떻게 거쳐야 하는지, 어떠 경로로 배달하는 게 좋은지 결정
2. 데이터 링크 계층(택배 기사)
- 데이터 물리 전송, 에러 검출 및 수정 수행
- 택배 상자에 완충재가 잘 포장됐는지, 박스 상자 손상되지 않았는지 체크
- 운송장 스티커를 제대로 붙였는지 확인
- 배달하기 위험한 물건은 아닌지 체크
- 배달 가도 되는지 결정(도로가 막혔거나, 배달 불가 상황이면 배달 안 감)
1. 물리 계층(택배 기사)
- 네트워크 케이블, 전기신호, 물리적 연결
- 택배를 보내는데 필요한 물리적인 기반 인프라
- 실제 도로 등을 통해 운전해서 배달함.
말록랩 구현 및 5주차 소감
컴퓨터 과학에서 쓰이는 개념들이 결국 다 통한다는 걸 느낌.
예를 들어 제로 디맨드 메모리에서 쓰이는 lazy evaluation(지연 평가, 지연 계산)
django에서 클래스형 뷰에서는 reverse_lazy를 쓰고
함수형 뷰에서는 reverse를 쓰는 걸 그냥 외웠는데, 지금 보니까
class는 객체가 생성되고 난 다음(뷰가 인스턴스화된 후)에 사용되어야 하니까 lazy한 방식으로 호출되고,
함수형은 이미 객체가 생성되어 있으니까 lazy를 쓰는 것이었음!!!
기초가 튼튼하면 도구는 쉽게 배운다는 말이 와 닿는 5주차였음.(참고) reverse는 뷰의 파라미터를 실제 url로 변환하는 함수
클래스형뷰는 인스턴스가 생성되지기 전에 reverse를 호출하면 파라미터가 없어 값 리턴에 문제가 생길 수 있어서 reverse_lazy를 씀.
반면 함수형뷰는 이미 파라미터가 세팅되어 있기 때문에 reverse를 쓰면 됨.파이썬2에서는 range가 지연 평가 방식이 아니고 즉시 모든 배열을 반환하였다고 함. 이게 파이썬 3에서는 range가 lazy evaluation 방식으로 변경됨.
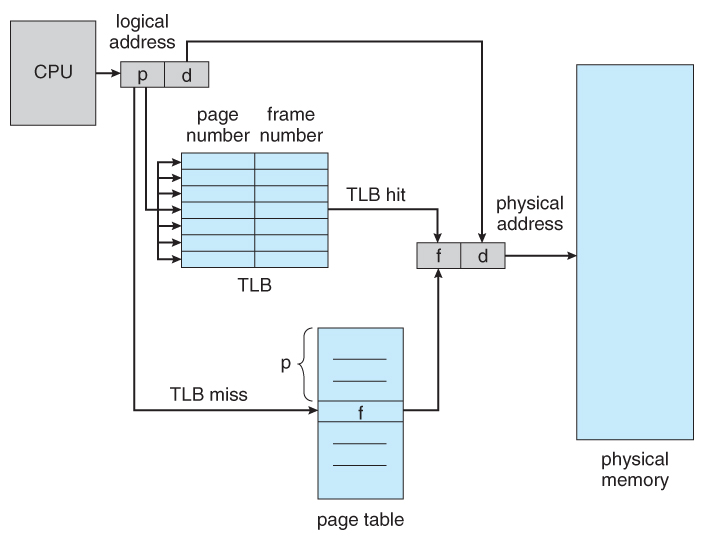
메모리 블록 헤더의 주소와 할당 비트의 결합 방식이
세그멘테이션 및 페이징의 논리 주소를 구성하는 베이스 주소와 오프셋(변위) 결합와 비슷한 개념임!
(각 테이블에는 프레임/세그먼트 번호와 사이즈로 구성되어 있음. 변위는 사이즈보다 클 수 없음. 그럼 해당 프레임이나 세그먼트를 넘어가서 폴트가 생김)
매주 보는 퀴즈에 대한 소감
기술 면접 후기를 보면 면접에 후드려 맞고(?) 모르는 걸 알게 되어서 새롭고 공부한다는 후기가 많음.
정글 매주 퀴즈가 마치 매주 모의 면접을 보는 효과가 있는 것 같음.
1:1과 같은 소수는 아니지만,
적은 비용으로 대량 평가가 가능하다는 지필 평가의 장점을 활용해서
효율적으로 모의 기술 면접을 보는 효과가 있음.
정글의 퀴즈 프로그램은 더욱 발전시키면 수강생들에게 매우 유용할 것 같음.
