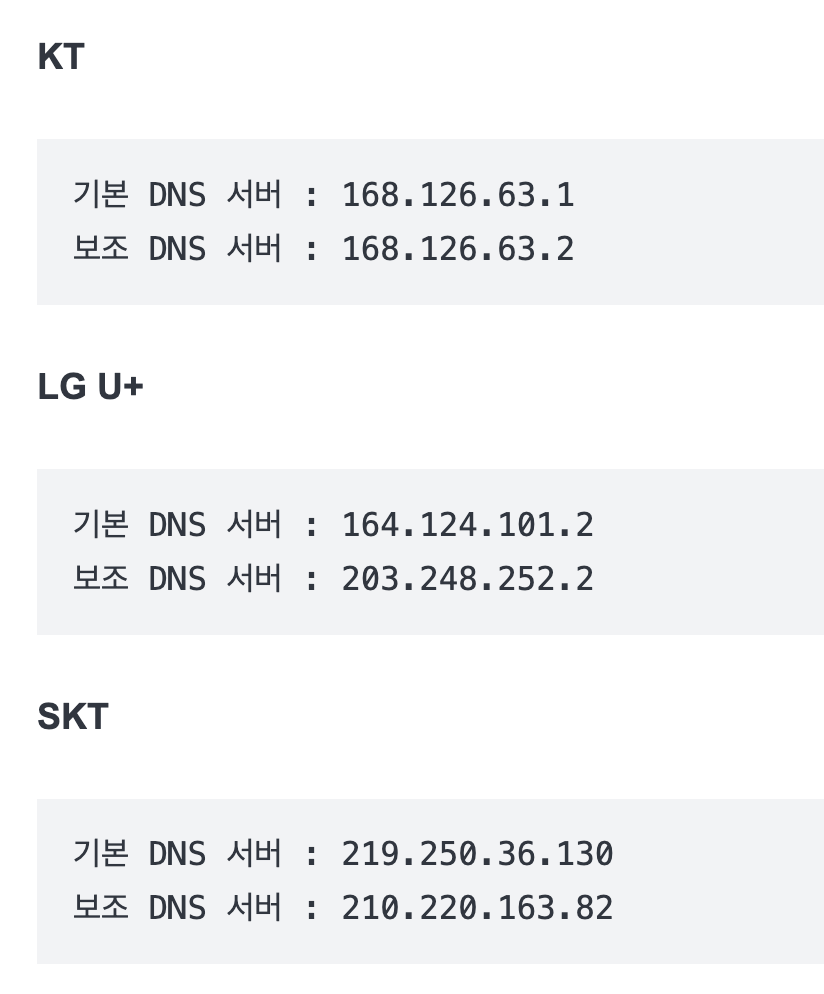
08:21 입실
C 웹 서버 무한 루프 오류 해결하기
주소에 따른 파일 전송 형식 구현하기
프록시 서버 구현 시작하기
숙제 문제 10.9, 10.10
무한루프 해결
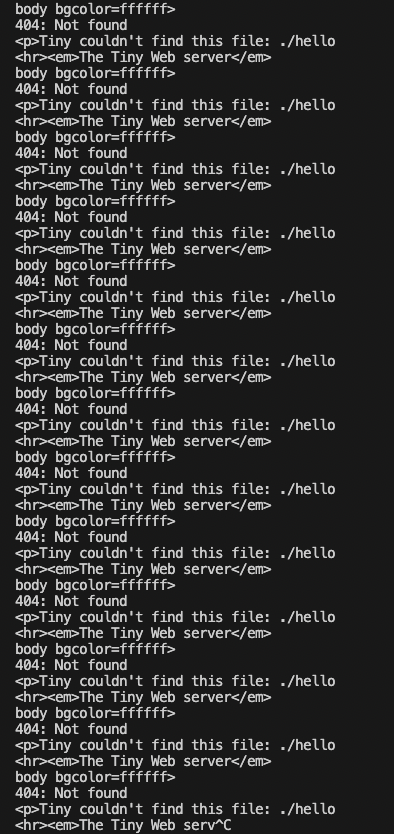
잘못된 URL로 최초 1회 접속 후 새로고침을 하면 아래 오류가 발생함.
(무한루프에 빠짐)
void read_requesthdrs(rio_t *rp)
{
char buf[MAXLINE];
Rio_readlineb(rp, buf, MAXLINE);
while (strcmp(buf, "\r\n"))
{
Rio_readlineb(rp, buf, MAXLINE);
printf("%s", buf);
}
return;
}아마 이쪽에서 잘못된 요청 후에 제일 밑에 함수가 실행되어서 그런게 아닐까?
/* Read request line and headers */
Rio_readinitb(&rio, fd);
Rio_readlineb(&rio, buf, MAXLINE);
printf("Request headers:\n");
printf("%s", buf);
sscanf(buf, "%s %s %s", method, uri, version);
if (strcasecmp(method, "GET") && strcasecmp(method, "HEAD")) /* 동일하면 0을 반환 */
{
clienterror(fd, filename, "501", "Not Implemented", "Tiny does not implement this method");
return;
}
read_requesthdrs(&rio);존재하지 않는 URL로 접속했을 때 소켓 연결이 안 끊기는 걸까?
아주 다양하게 무한루프에 빠진다.
제대로 된 주소에 접속해서 새로고침하면 무한루프 빠지는 경우가 있다.
아마 버퍼에 일부 데이터가 계속해서 출력되는 거 같은데..
고치려면 좀 오래 걸릴 것 같음
웹 서버 작성 중 알게된 사실
쿼리스트링은 일반적으로key=value형태로 보내지만 값만 보내는 것도 가능하다.
http://example.com/cgi-bin/your-cgi-script?10&20&30
연습문제 11.9
TINY를 수정해서 정적 컨텐츠를 처리할 때 요청한 파일을 mmap과 rio_readn 대신에 malloc, rio_readn, rio_writen을 사용해서 연결 식별자에게 복사하도록 하시오.
void serve_static(int fd, char *filename, int filesize)
{
int srcfd;
char *srcp, filetype[MAXLINE], buf[MAXBUF];
get_filetype(filename, filetype);
sprintf(buf, "HTTP/1.1 200 OK\r\n");
sprintf(buf, "%sServer: Tiny Web Server\r\n", buf);
sprintf(buf, "%sConnection: close\r\n", buf);
sprintf(buf, "%sContent-length: %d\r\n", buf, filesize);
sprintf(buf, "%sContent-type: %s\r\n\r\n", buf, filetype);
Rio_writen(fd, buf, strlen(buf));
printf("Response headers:\n");
printf("%s", buf);
srcfd = Open(filename, O_RDONLY, 0); // 파일을 열고 디스크립터 할당
// srcp = Mmap(0, filesize, PROT_READ, MAP_PRIVATE, srcfd, 0);
srcp = (char *)malloc(filesize); // 파일 사이즈만큼 메모리 할당
if (srcp == NULL)
{
fprintf(stderr, "Memory allocation error\n");
return ;
}
ssize_t bytes_read = Rio_readn(srcfd, srcp, filesize); // srcfd 파일을 읽어서 srcp 메모리에 데이터 저장
if (bytes_read < 0)
{
fprintf(stderr, "Error reading file\n");
free(srcp);
Close(srcfd);
return;
}
Close(srcfd); // 스태틱 파일 디스클비터 닫기
Rio_writen(fd, srcp, filesize); // fd소켓 쓰기로 클라이언트에 데이터 전송
// Munmap(srcp, filesize);
free(srcp); // 스태틱 파일 메모리 해제
}혼자서는 못 풂.. GPT 베낌.
코드 이해만 하기.
연습문제 11.10
쿼리스트링이 키=밸류 형태가 아니라 밸류&밸류 형태로 가야한다.
웹서버 코드를 수정하는 것보다 자바스크립트 처리가 더 빠르다고 생각했다.
cgi-bin으로 쿼리 스트링 없이 접속했을 때는 동적 콘텐츠를 송출하게 코드를 일부 수정했다.
if (!strstr(uri, "cgi-bin")) /* 정적 컨텐츠 요청 */
{
strcpy(cgiargs, "");
strcpy(filename, ".");
strcat(filename, uri);
if (uri[strlen(uri) - 1] == '/')
strcat(filename, "home.html");
return 1;
}
else
{
ptr = index(uri, '?');
if (ptr)
{
strcpy(cgiargs, ptr + 1);
*ptr = '\0';
}
else
{
strcpy(cgiargs, "");
strcpy(filename, ".");
strcat(filename, uri);
strcat(filename, ".html");
return 1;
}
strcpy(filename, ".");
strcat(filename, uri);
return 0;
}
}<form id="myForm" action="/cgi-bin/adder" method="GET">
<input id="value1" type="number" required>
<input id="value2" type="number" required>
<button type="button" onclick="submitValues()">Submit</button>
</form>
<script>
function submitValues() {
const value1 = document.getElementById("value1").value;
const value2 = document.getElementById("value2").value;
// 쿼리 문자열을 직접 구성하여 URL을 생성
const url = "/cgi-bin/adder?" + value1 + '&' + value2;
// 새 창 또는 현재 창으로 이동
window.location.href = url;
}
</script>
동적 컨텐츠 CGI 처리 완료!
브라우저 신기한 현상 발견
아이피를 입력하고 엔터를 안 쳤는데 서버로 요청이 간다.
http를 입력하지 않고, 그냥 아이피만 입력하면 이런 현상이 있다.
IP, MAC
ifconfig
"Interface Configuration"의 약어로, 네트워크 인터페이스를 구성하고 관리하는 명령어
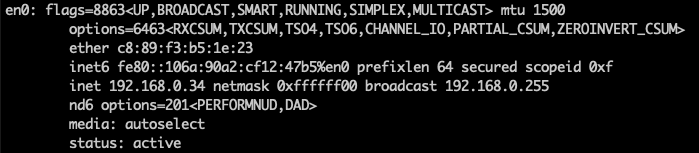
로컬 IP 확인
ifconfig
ifconfig en0
외부 IP 확인
curl ifconfig.me
MAC 주소 확인
ifconfig
HTTP
상태코드 300
리디렉션을 의미하는 300번대 상태코드는 리디렉션이 필요한 경우에는 헤더에 Loacation 필드에 새로운 URL이 같이 온다.
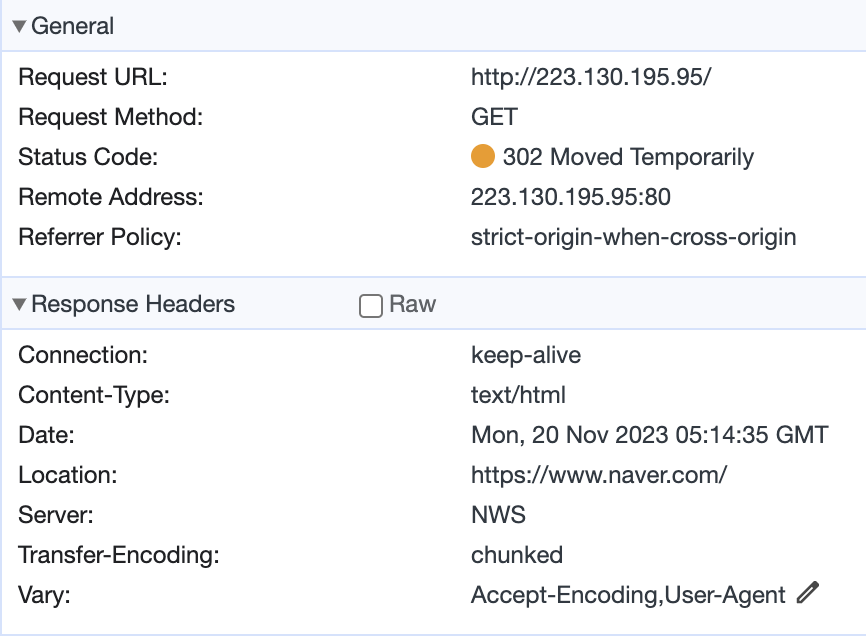
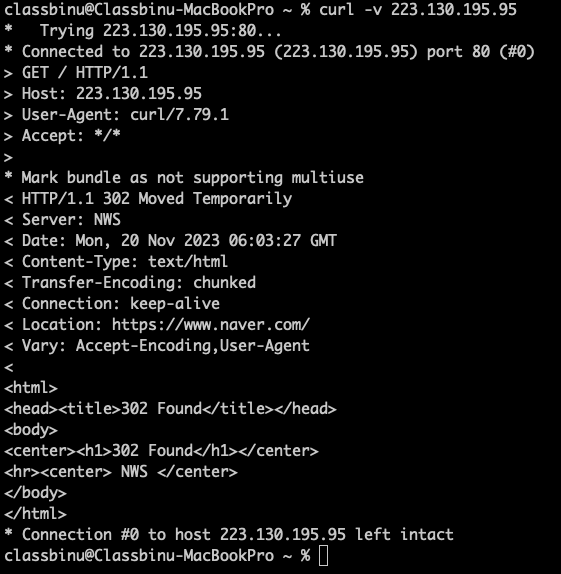
예를 들어 네이버 HTTP로 http://223.130.195.95/ 에 요청하면
응답 헤더에 Location: https://www.naver.com/ 이 넘어온다.
DNS 캐싱
클라이언트(브라우저) 캐싱
웹브라우저 및 네트워크 응용 프로그램 자체에서 DNS 캐싱 수행
로컬 DNS 캐시를 확인하여 해당 도메인 이름에 대한 IP 주소 찾음
로컬 DNS 캐시에 정보가 없으면 운영체제 레벨 DNS캐시 확인
운영체제 캐싱
운영체제 DNS캐시는 네트워크 설정에 관계없이 모든 애플리케이션에 대한 공통 캐시
운영체제에도 정보가 없으면 DNS 서버로 요청
공유기 캐싱
일부 공유기에는 공유기 자체에 DNS 캐싱 기능이 내장되어 있ㅇ
공유기가 일종의 DNS 서버 역할을 한다.
(ISP) DNS 서버
DNS 서버는 조회에 대한 응답 반환 적 DNS캐싱을 수행
반응 캐시(Recursive Cache)
이전 처리한 DNS 조회에 대한 응답을 저장
(= 다른 애들이 요청한 결과에 대한 캐싱)
동일 조회 발생 시 빠르게 반환
즉, 단순 응답 결과만 캐싱
권한 캐시(Authoritative Cache)
해당 도메인 공식 DNS 서버로부터 얻은 정보 저장
동일 도메인에 대한 조회를 해야할 때 공식 DNS 정보 사용
즉, 다른 공식 도메인의 전체적인 레코드 정보를 캐싱도메인
루트 DNS
ISP 및 설정한 DNS는 루트 DNS로 질의를 보낸다.
루트 DNS는 최상위 도메인(TLD) 서버의 IP주소를 반환한다.
TLD는 .com, .org, .net 등
TLD DNS
TLD는 도메인 공식 DNS 서버의 주소를 반환.
공식 DNS는 특정 도메인의 IP주소 및 기타 DNS 정보를 관리하는 서버
다시 (ISP) DNS
최종 IP주소를 로컬 캐시에 저장 후 응답(ip)을 사용자에게 반환
이후 사용자는 ip로 접속함.
브라우저 아키텍처
브라우저 아키텍처는 표준이 없다.
크롬 아키텍처를 살펴 봄
- 탭 하나 당 하나의 렌더러 프로세스가 실행
- 플러그인 프로세스도 플러그 당 프로세스가 실행
- 브라우저 프로세스는 1개
- GPU 프로세스는 1개
프록시 구현
프록시가 해야 하는 일
- 명령줄에 지정되는 포트에서 들어오는 연결 수신
- 연결이 설정되면 프록시를 클라이언트 요청 전체 읽고 요청 구문 분석
- 클라이언트의 HTTP 요청이 유효한지 확인
- 유효하면 적절한 웹 서버에 자체 연결 설정 후 클라이언트가 지정한 개체 요청
- 서버의 응답을 읽고 클라이언트에 전달
아니, 프록시에 어떻게 요청을 보내는거야?
구현하는 프록시가 포워드 프록시인 것 같은데,
그럼 어쨌든 모든 요청이 프록시로 먼저 가야된다는건데,
그럼 프록시와 최종 목적지를 같이 요청하는건가?
그럼 클라우드에다가 프록시 서버를 운용하는 게 기술적으로 가능한 거야?
도대체 이 과정이 이해가 안 됐는데,
맥북에서 프록시를 따로 설정할 수 있는 거였음.
https://support.apple.com/ko-kr/guide/mac-help/mchlp25912/mac
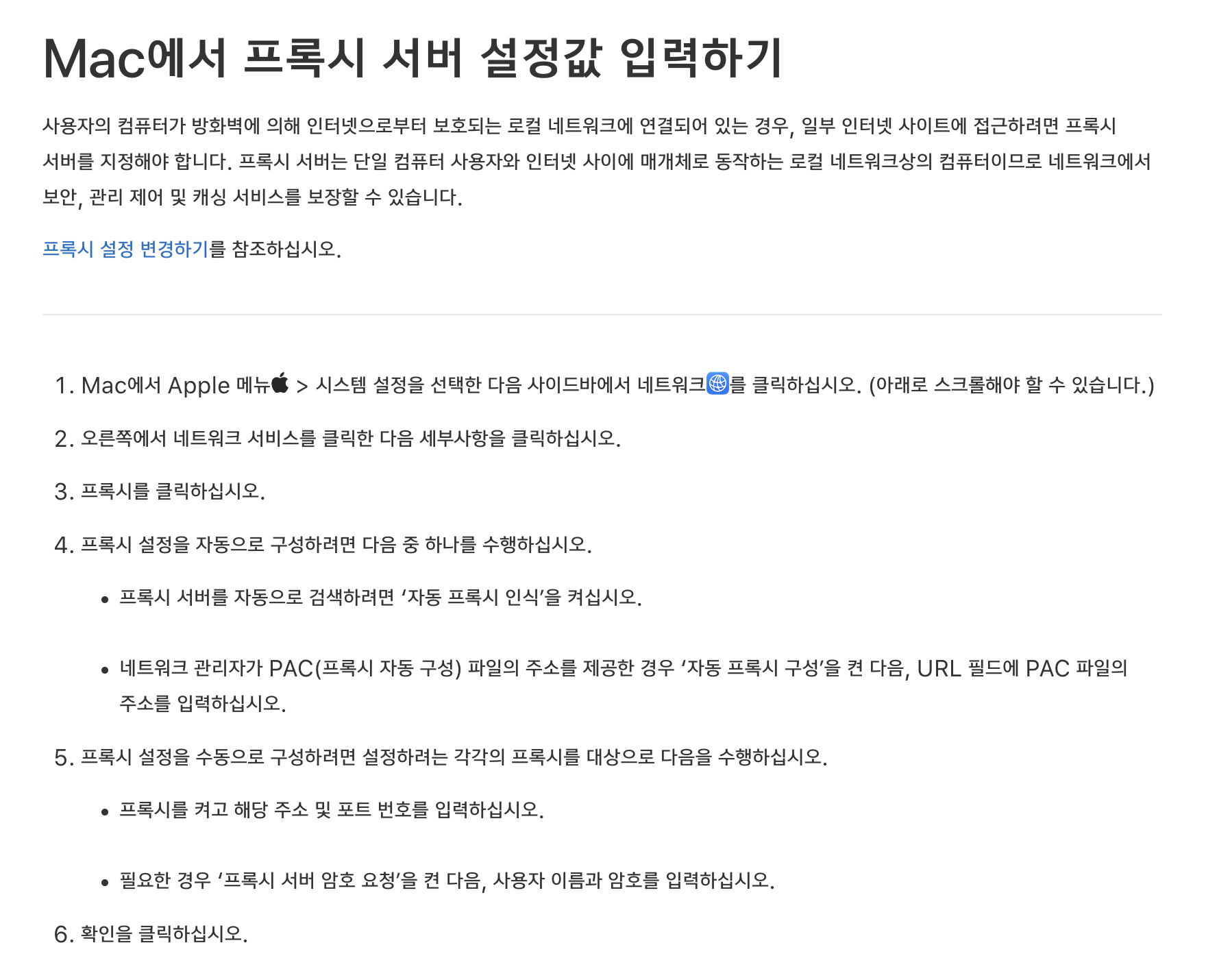
즉, 맥북에서 프록시를 설정해주면 모든 요청이 먼저 프록시로 가는 거였다!
그럼 난 이제 열심히 프록시 서버를 만들고 그 프록시 주소를 맥북으로 세팅하면 되는 거다!
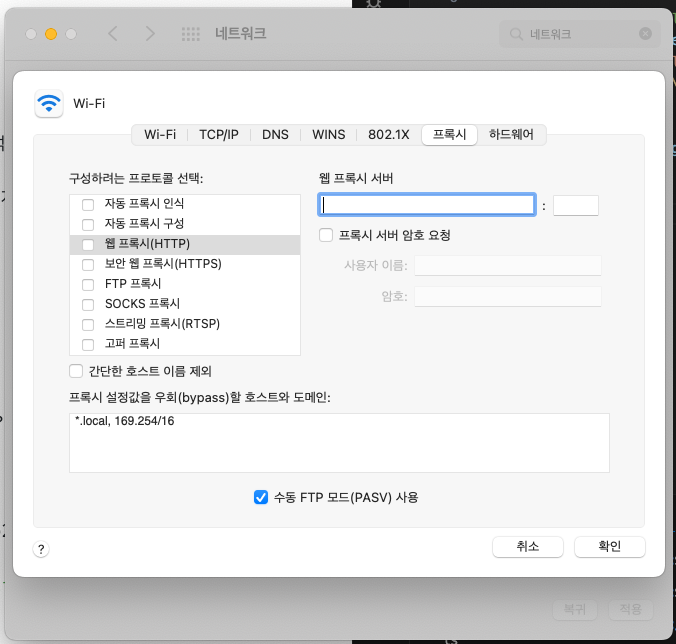
또는 curl에서는 이렇게 proxy를 경유해서 요청할 수도 있다.
curl --proxy {http://localhost:proxy포트/path} {http://localhost:tiny포트/path}
curl --proxy http://localhost:7000/ http://localhost:8000/세그멘테이션 폴트
계속해서 세그멘테이션 폴트가 났음.
이유는 port 데이터 타입 문제였음!
int port로 해놓고 배열 형태로 참조하려고해서 계속 세그멘테이션 폴트!
port도 char*로 바꾸니 정상적으로 작동함!
대신, 지금 uri 파싱 코드를 하드코딩해서 패턴에 맞춰서 파싱 코드로 바꿔야 함!
