자다가 뒤척일 때 이어폰 터치 눌려서 음악 재생되는 바람에 여러 번 잠에서 깸
터치 기능 비활성화하면 됨.
약간 나태해짐. 강의실 입실 08:04
시험 보기 직전까지 백준 문제 푼다!
CSAPP는 너무 깊이 지엽적으로 파지 말고 전반적인 흐름을 숙지하면서 읽어 나가기
단, 커리큘럼에 강조된 부분은 심도 깊게 이해하기
백준 1946 신입 사원 (어제 이어서)
그리디는 무조건 2중, 3중 반복문을 쓰는 게 아니다.
최적화 할 수 있는 부분이 있으면 최적화하기!
반복문은 한 번만 줄여도 시간 복잡도가 현저하게 줄어든다.
import sys
T = int(sys.stdin.readline().strip())
tests = [[] for _ in range(T)]
for i in range(T):
N = int(sys.stdin.readline().strip())
for _ in range(N):
paper, interview = map(int, sys.stdin.readline().strip().split())
tests[i].append((paper, interview))
result = []
for test in tests:
# 서류 석차를 기준으로 정렬
# 이 시점에서 모든 지원자는 서류로 앞 선 지원자를 이길 수 없음.
# 즉, 지금까지 나온 면접 최고점보다 내가 면접 순위가 높아야 됨.
# 만약 내가 면접 최고 순위를 갱신하지 못한다면,
# 서류에서는 무조건 지고, 면접에서도 지는 경우가 생기는 것!
test.sort()
max_interview_rank = float('inf')
passed = 0
for paper, interview in test:
if interview < max_interview_rank:
passed += 1
max_interview_rank = interview
result.append(passed)
for n in result:
print(n)백준 1700 멀티탭 스케줄링
최적의 해는 가장 적게 사용되는 기기가 아니라,
앞으로 전혀 사용되지 않거나, 가장 나중에 사용되는 기기
백준 1890 점프
80분정도 걸림.
재귀로 풀었는데, DP로 바꾸는 과정에서 헤맴.
재귀에서는 DP테이블을 업데이트 했는데,
DP로 가져온 후에는 DP 테이블을 업데이트 하지 않아서 계속 틀림.
이 문제 집중하면서 재귀와 DP에 대한 개념이 업그레이드됨.
그래도 오로지 혼자 힘으로 풀었다는 데에서 만족.
import sys
N = int(sys.stdin.readline().strip())
maze = []
for _ in range(N):
maze.append(list(map(int, sys.stdin.readline().strip().split())))
dp = []
for _ in range(N):
dp.append([0] * N)
def search(maze, N, i, j):
result = 0
now_value = maze[i][j]
if now_value == 0 and i == N - 1 and j == N - 1:
return 1
if now_value > 0 and i + now_value < N:
if dp[i + now_value][j] > 0:
result += dp[i + now_value][j]
else:
result += search(maze, N, i + now_value, j)
dp[i][j] = result
if now_value > 0 and j + now_value < N:
if dp[i][j + now_value] > 0:
result += dp[i][j + now_value]
else:
result += search(maze, N, i, j + now_value)
dp[i][j] = result
return result
print(search(maze, N, 0, 0))CSAPP 7. 링커
링킹(linking)
- 여러 개의 코드와 데이터를 연결하여 메모리에 로드 및 실행 가능한 한 개의 파일로 만드는 작업
- 컴파일 시 수행 가능(
- 소스코드 -> 머신코드
7.1 컴파일러 드라이버
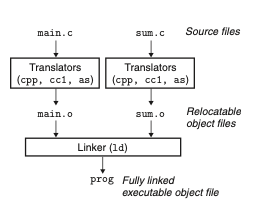
링커는 다수의
*.o파일을 연결해서 최종적으로 실행 가능한 실행 파일을 생성한다.
컴파일러의 전반적인 과정 설명해 보기!
전처리기가 소스 파일 main.c를 중간파일 main.i 생성
드라이버가 중간파일 main.i를 어셈블리파일 main.s 생성
어셈블러가 main.s를 바이너리 목적파일 main.o 생성(이 과정이 다른 c파일에도 적용)
링커가 최종적으로 main.o를 비롯한 다른 목적파일을 연결하여 실행 파일 main(main.out) 생성
생성된 파일은 쉘에서 파일명을 입력하면 실행할 수 있는데,
쉘은 로더(loader)라는 운영체제 내의 함수를 호출하고,
로더는 실행파일의 코드와 데이터를 메모리로 복사하고,
제어를 프로그램 시작 부분을 전환한다.
7.2 정적 연결
실행 파일을 만들기 위한 링커의 주요 작업
1단계. 심볼 해석(심볼 해결, symbol resolution)
심볼(함수, 전역변수, 정적변수 등 코드 내에서 사용되는 이름) 참조를 하나의 심볼 정의에 연결
심볼 정의는 해당 심볼의 정의 또는 선언(함수는 정의, 전역 변수 선언 등)
심볼 참조는 코드에서 해당 심볼 사용 또는 호출(함수 호출, 변수 접근)
다수의 목적 파일에서 정의된 변수나 함수명이 하나의 실행 파일로 통합될 때 동일한 동작이나 동일한 메모리 위치를 가리키도록 연결하는 것
2단계. 재배치(relocation)
어셈블리는 바이너리 파일로 변환할 때 메모리 주소가 아닌 상대적인 주소 또는 심볼로 주소를 표현한다.
이걸 링커가 0x와 같은 실제 메모리 주소(가상 메모리 주소)로 변환한다.
7.3 목적 파일
목적 파일의 3가지 종류
1. 재배치 가능 목적파일: 실행 가능 프로그램 만들기 위한 중간 단계
2. 실행 가능 목적파일: 최종적으로 실행할 수 있는 프로그램(실행 시 메모리에 로드되는 파일)
3. 공유 목적파일: 동적 링크 라이브러리 형태, 여러 프로그램에서 필요할 때 메모리에 로드
컴파일러, 어셈블러: 재배치 가능 목적 파일, 공유 목적파일 생성
링커: 실행 가능 목적파일 생성
이해했다! 컴파일 과정에서 목적 파일이라는 용어가 자주 나오는데,
어떤 건 실행 가능하고 어떤 건 실행 불가능한가? 라고 생각했는데 여기서 정리 됨.
목적 파일을 최종적인 파일이라고 생각한 건 오개념이었음!
목적 파일은 컴파일 과정 중 생성되는 이진 형식의 중간 파일을 통칭하는 개념!
링커가 최종적으로 실행 가능한 목적 파일을 생성하는 거고,
그 이전에 중간 단계로 생성되는 목적 파일은 컴파일러와 어셈블러가 생성하는 것!
7.4 재배치 가능 목적 파일(중요)
목적 파일 구조를 알아보자.(ELF 포맷 기준)
Executable and Linkable Format
기존적인 구조는 섹션 헤더 - 섹션 내용 - 섹션 헤더 테이블
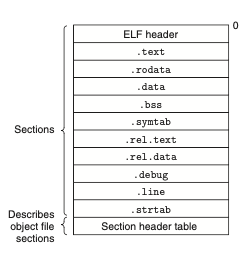
섹션 헤더(ELF header)
워드 크기와 시스템 바이트 순서를 나타내는 16바이트 배열로 시작
(그 다음은 링커가 필요한 정보를 담고 있음.)
- ELF 헤더 크기
- 목적 파일 타입(재배치 가능, 실행 가능, 공유)
- 머신 타입(예 x86-64)
- 섹션 헤더 테이블 파일 오프셋
- 섹션 헤더 테이블 크기, 엔트리 수
섹션 내용
.text: 컴파일된 프로그램 머신 코드
.rodata prinft: 읽기-허용 데이터
.data: 초기화된 C 전역변수 및 정적변수(참고로 지역변수는 런타임에 스택에 저장)
.bss: 초기화되지 않거나 0으로 초기화된 C 전역변수 및 정적변수
(단, 이 섹션은 목적파일 실제 공간 차지하지 않음. 초기화되지 않은 건 공간을 차지할 필요가 없으니까.)
.symtab: 전역변수들과 함수에 대한 정보를 가자ㅣ고 있는 심볼 테이블(지역 변수 엔트리는 없음)
.rel.text: 링커가 이 파일을 연결할 때 수정되어야 하는 .text섹션 내 위치 리스트
.rel:data: 전역변수들에 대한 재배치 정보
.debug: 디버깅 심볼 테이블. 컴파일 -g옵션 시 생성
.line: 최초 C와 .text 섹션 내 머신 코드 인스트럭션 라인 번호 매핑. 컴파일 -g옵션 시 생성
.strtab: .strtab과 .debug 섹션 내에 있는 심볼 테이블과 섹션 헤더들에 있는 섹션 이름들을 위한 스트링 테이블. 스트링 테이블은 널 문자로 종료된 스트링의 배열.(단순히 문자열 관련 테이블이라고 이해)
코치진 면담
5개월 후에 얉고 넓은 지식으로 채용에 도전해도 되는 것인지?
(자격이 되는지, 비양심적(?)인 건 아닌지)
5개월 후에 모든 걸 깊이 있게 알지 못할 가능성이 매우 높다.
정글 협력사는 지식의 양보다 성장의 기울기를 본다.
(반대로 말하면 기술 스택 숙련도를 보는 비협력사 채용에는 불리할 수 있다.)
본인의 성장의 기울기를 어필해라.
면접관이 할 고민을 지원자가 하지 마라.
자격이 되고 말고는 면접관이 평가한다.
지원자가 자신감이 없으면 면접을 통해 나 자신을 평가받을 기회를 놓치게 된다.
면접 기회를 많이 가져가라.
수료 직후 채용은 어려울 수 있다.
채용이 쉽지는 않다.
(But 지난 기수를 살펴보면 수료 후 6개월을 두고 보면 취업률은 괜찮다.)
채용 면접팁
채용 면접에서 단답형으로 대답하지 마라.
대화를 이어갈 수 있게 대답해라.
대화를 많이 하면 호감도가 올라간다.
경력자는 레퍼런스 체크를 할 수 있지만, 신입은 면접에서 대화를 통해 셀프 레퍼런스 체크를 하는 것과 같다.
(그렇다고 해서 확실히 거를 수 있는 건 아니지만)
포인터
포인터 개론
포인터는 주소를 가리키는 변수다.
즉, 포인터의 타입에 무관하게 무조건 8바이트이다.(64비트 아키텍처 기준)
그럼 왜 데이터 타입에 맞게 포인터 변수를 선언해야 하냐?
포인터 연산에서는 포인터 데이터 타입에 따라 연산값이 달라진다.
또한 역참조 할때 타입이 맞아야 제대로된 값을 역참조할 수 있다.
(C는 강타입 언어이다.)
포인터 타입은 컴파일러에게 해당 메모리 위치에서 얼마나 많은 바이트를 읽어야 하는지,
그 바이트를 어떻게 해석해야 하는지 알려준다.
예를 들어int *포인터 역참조 시 컴파일러는 포인터 주소에서 4바이트를 읽어 정수로 해석한다.
이때char *라면 포인터 주소에서 1바이트를 읽고 문자로 해석한다.
* (애스터리스크) and & (엠퍼샌드)
애스터리스크 역할 1. 포인터 변수 선언
해당 변수가 포인터 변수임을 나타내며, 메모리 주소를 저장할 것을 의미
애스터리스트 역할2. 역참조
포인터가 가리키는 메모리 위치의 값에 접근
앰퍼샌드 역할1. 메모리 주소 얻기
특정 변수의 값이 아닌 메모리 주소를 얻는다.
#include <stdio.h>
int main() {
int a = 5;
int* ptr; // 변수명 ptr에는 int타입을 가리키는 메모리 주소(포인터)를 담을 거임!
ptr = &a; // ptr변수에 a변수의 메모리 주소(정확히는 시작 메모리 주소)을 할당함!
printf("value of ptr is %d\n", *ptr); // ptr을 역참조하는데 int*니까 해당 메모리 주소에서 4바이트(64비트 아키텍처 기준)를 읽어와서 정수로 해석함!
return 0;
}메모리 주소와 포인터는 다른 개념인가?
다른 개념임! 메모리 주소는 메모리 셀의 특정 위치를 가리키는 숫자임.
포인터는 메모리 주소를 저장하기 위해 사용되는 변수!
포인터가 메모리 주소를 담고 있는 것!
포인터 변수의 값이 메모리 주소이다.
포인터 연산
포인터는 산술 연산을 할 수 있다.(덧셈, 뺄셈) (++, --도 가능)
이때 포인터 + 1이 단순히 산술적으로 1을 증가시키는 게 아니다.
포인터 타입에 따라 +1이 1, 2, 4, 8바이트로 해석된다.(sizeof())
포인터의 산술 연산은 포인터가 가리키는 타입의 크기에 의존적이다.
즉, 포인터 연산은 배열 인덱스라고 생각하면 됨!
#include <stdio.h>
int main() {
int a = 5;
int* ptr; // 변수명 ptr에는 int타입을 가리키는 메모리 주소(포인터)를 담을 거임!
int* ptr2;
ptr = &a; // ptr변수에 a변수의 메모리 값(정확히는 시작 메모리 주소)을 할당함!
printf("address of ptr is %p\n", ptr);
ptr2 = ptr + 1; // ptr이 int* 이기 때문에 여기서 +1은 포인트 변수가 담고 있는 메모리 주소에 +4바이트를 한다.
printf("address of ptr2 is %p\n", ptr2);
printf("value of ptr is %d\n", (void*)*ptr);
printf("value of ptr2 is %d\n", (void*)*ptr2); // ptr2는 a의 범위를 벗어나서 역참조 하기 때문에 정의되지 않은 동작으로 위험한 코드이다.
return 0;
}
address of ptr is 0x16b08b2b8
address of ptr2 is 0x16b08b2bc //포인트 연산으로 +1을 했지만 메모리 주소로는 4바이트(sizeof(int))가 증가함.
value of ptr is 5
value of ptr2 is 0포인터 산술을 사용해서 배열 내의 요소에 접근할 수 있다.
포인터는 배열의 인덱스와 동일한 효과를 낼 수 있다.
#include <stdio.h>
int main() {
int arr[] = {10, 20, 30, 40, 50}; // 정수 배열 선언
int *ptr = arr; // ptr은 배열의 첫 번째 요소를 가리킵니다.
printf("첫 번째 요소: %d\n", *ptr); // 10을 출력합니다.
ptr++; // ptr을 증가시켜 배열의 다음 요소를 가리킵니다.
printf("두 번째 요소: %d\n", *ptr); // 20을 출력합니다.
ptr += 2; // ptr을 2 증가시켜 네 번째 요소를 가리킵니다.
printf("네 번째 요소: %d\n", *ptr); // 40을 출력합니다.
ptr--; // ptr을 감소시켜 세 번째 요소를 가리킵니다.
printf("세 번째 요소: %d\n", *ptr); // 30을 출력합니다.
// 배열의 시작으로부터 세 번째 요소의 주소 계산
int *ptr2 = &arr[0] + 2;
printf("직접 계산한 세 번째 요소: %d\n", *ptr2); // 30을 출력합니다.
// 포인터 간의 차이를 계산
printf("ptr2와 ptr의 요소 간의 거리: %ld\n", ptr2 - ptr); // 1을 출력합니다. (세 번째 요소와 네 번째 요소 사이)
return 0;
}비교 연산자로 포인터 간의 비교가 가능하다.(단, 같은 객체를 가리키거나 같은 배열 요소 범위 내에서 유효)
C의 규칙이다.
포인터 비교는 기본적으로 연속된 메모리 주소 기반으로 이루어지는데,
동일 객체나 동일 배열이 아니면 비교 대상이 연속된 메모리가 아니므로 비교 연산 결과를 신뢰할 수 없다.
void포인터
어떠한 객체도 가리킬 수 있는 포인터이다. 하지만 산술 연산은 불가능하다.
void포인터는 역참조를 하면 컴파일러가 어떤 타입의 데이터를 읽어야 할지 모르니까 컴파일 에러 발생
즉, void포인터로 역참조를 하려면 역참조 전에 타입 캐스팅을 해야 한다.
메모리 할당 함수는 void포인터를 반환한다. 이걸 캐스팅해서 원하는 타입으로 사용할 수 있다.
포인터 간 캐스팅이 가능하지만, 예기치 않은 문제를 발생시킬 수 있다.
포인터에 const 키워드를 사용하면 포인터를 통해 값 변경을 불가능하게 만든다.
// 데이터 값에 const를 지정하는 경우
#include <stdio.h>
int main() {
int value = 10;
const int *ptr = &value;
*ptr = 20; // ptr이 가리키는 데이터가 const이므로 변경 불가
value = 20; // value자체는 const가 아니므로 변경 가능
return 0;
}
// 포인터 변수에 const를 지정하는 경우
#include <stdio.h>
int main() {
int value = 10;
int value2 = 20;
int *const ptr = &value; // ptr은 const 포인터이므로, ptr이 가리키는 주소는 변경할 수 없음.
ptr = &value2; // ptr이 가리키는 데이터가 const이므로 변경 불가
*ptr = 30; // value자체는 const가 아니므로 변경 가능
return 0;
}
// 데이터값과 포인터 변수에 모두 const를 지정하는 경우
#include <stdio.h>
int main() {
int value = 10;
const int *const ptr = &value; // ptr은 const 포인터이므로, ptr이 가리키는 주소는 변경할 수 없음.
*ptr = 20; // ptr이 가리키는 데이터가 const이므로 변경 불가
ptr = &value; // ptr자체도 const이므로 변경 불가능
return 0;
}가상화, VMware
시스템 요소들과 소통할 수 있는 명령을 특권 명령(privileged instruction)이라고 하는데
특권 명령은 OS만 가능하다. 즉, OS는 특권 명령 때문에 하드웨어 시스템 당 하나만 돌아간다.
일반 프로그램은 특권 명령이 필요 없기 때문에 많은 프로그램을 동시에 수행할 수 있다.
가상화의 반댓말(Bare-Metal: 컴퓨터에 직접 OS가 설치된 상태)
가상화 개론
컴퓨터 리소스를 추상화하는 과정
하나의 물리적 리소스를 여러 가상 리소스로 분할하거나,
여러 물리적 리소스를 하나의 가상 리소스로 통합할 수 있음.
예)
- 서버 가상화 : 하나의 서버를 여러 개의 가상 서버로 분할
- 스토리지 가상화 : 물리적인 스토리지 리소스를 논리적인 단위로 추상화
- 네크워크 가상화 : 물리적 네트워크 리소스를 가상 네트워크로 분할
- 데스크톱 가상화 : 네트워크를 통해 (서버에 호스팅된) 데스크톱에 접속
- 애플리케이션 가상화 : 애플리케이션을 개별 클라이언트 머신에 설치하지 않고, 서버에서 실행
추상화란?
컴퓨터 과학에서 추상화란 복잡성을 관리하기 위해 세부 사항을 숨기고 단순한 모델을 사용하여 복잡한 시스템을 이해하고 사용하는 과정을 말한다.
즉, 추상화란 '단순화'라고 할 수 있다!
컴퓨터 리소스를 추상화한다는 건 컴퓨터 리소스의 세부 사항을 단순화시켜서 사용하기 간단하게 만드는 것!
가상화의 장점
- 리소스의 유연한 할당
- 비용 절감
- 관리 편의
- 재해 복구 용이
가상화의 단점
- 성능 저하(가상화 과정에서 오버헤드 발생)
- 비용 복잡성
- 보안 우려
- 자원 분배 문제(자원 경합)로 인한 성능 저하
- 가용성과 재해 복구(하나의 물리적 머신에서 문제가 발생하면 가상 리소스 전체에 영향)
- 라이선스 문제
VMware
클라우드 컴퓨팅 및 가상화 소프트웨어를 판매하는 기업이다.
가상화 기술의 선구자(?)이기 때문에 가상화 소프트웨어(또는 가상화 기술)를 일컫는 용어로 쓰인다.
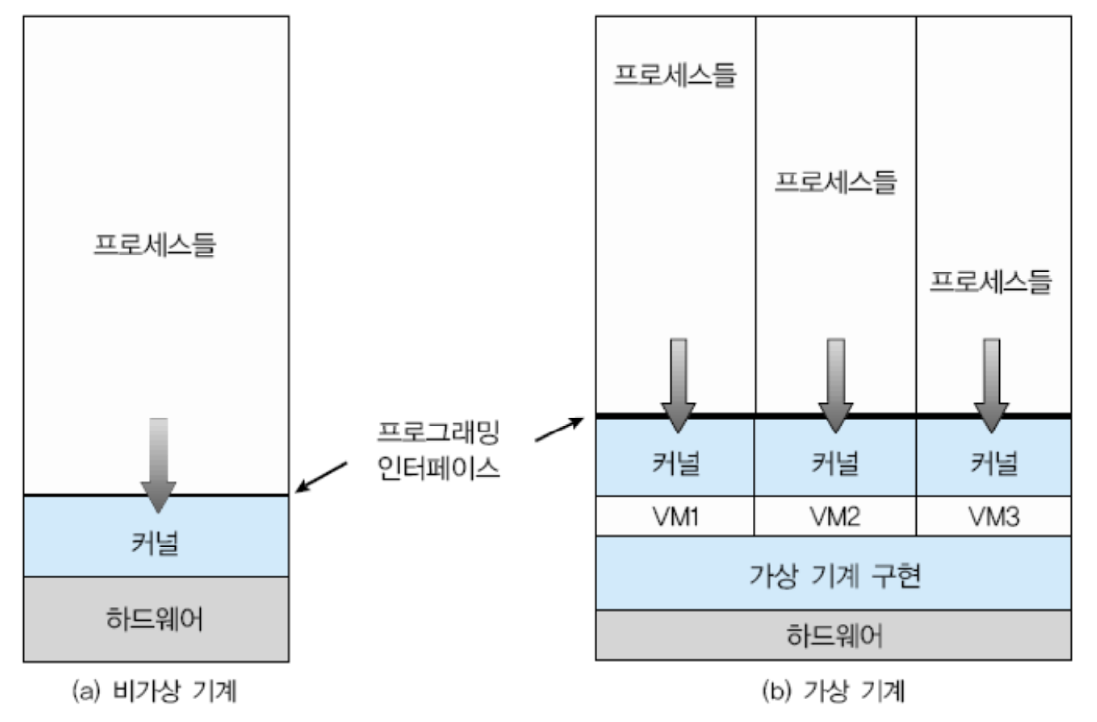
가상머신(Virtual Machine)
컴퓨터 안에서 소프트웨어에 의해 생성된 컴퓨터의 에뮬레이션(모방 프로그램)
가상머신 소프트웨어(VMware, VirtualBox 등)를 사용하여 생성되는 소프트웨어 에뮬레이션.
컴퓨터의 실제 하드웨어 자원을 사용하여 가상의 하드웨어 환경을 제공(추상화)
하나의 리소스를 여러 개의 가상 리소스로 추상화할 수 있다!
이때 가상머신이 실행되는 원래 물리적인 컴퓨터를 호스트 시스템,
생성된 가상화 환경의 시스템을 게스트 시스템이라고 함.
각 VM은 완전히 격리된 환경을 제공. 하나의 VM의 오류나 변경이 다른 VM에 영향을 미치지 않는다.
VM별로 독립된 운영체제를 가지며, 당연히 커널도 다르다.
VM과 호스트의 커널이 독립적이다.
가상머신 vs 컨테이너
도커 엔진을 통해 컨테이너에서 실행되는 애플리케이션은 호스트 OS의 커널과 하드웨어 리소스를 이용할 수 있음
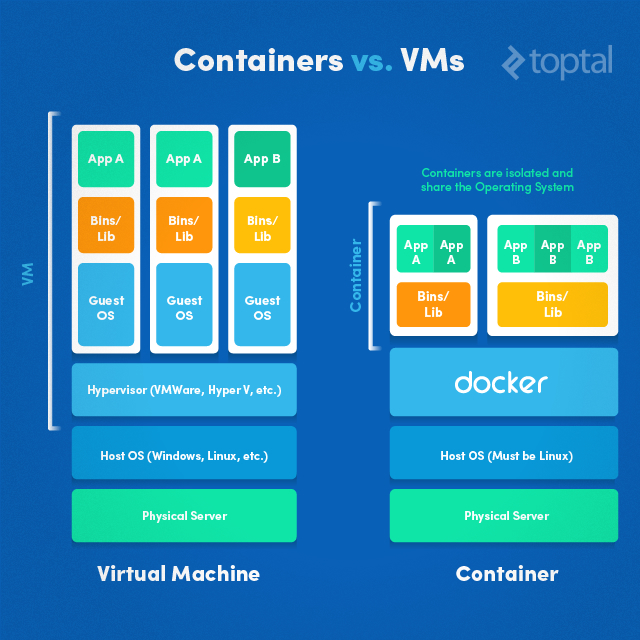
(그림에서 bins/library는 각각 바이너리, 라이브러리를 의미하며 app을 실행하기 위한 의존 코드라고 볼 수 있음.)
| 가상머신 | 컨테이너 |
|---|---|
| 게스트 OS 필요 | 게스트 OS 없음 |
| OS, 가상화 하드웨어 모두 완전한 가상 인스턴스 | OS수준의 가상화, 호스트 OS 커널 공유 |
| VM끼리 완전 격리(보안 높음) | 사용자 공간 격리 수준(커널 수준 취약점은 모든 컨테이너가 영향) |
| 세팅 비교적 오래 걸림(OS 부팅 필요함) | 세팅 비교적 빠름(이미지에서 시작, OS 부팅 없음) |
| 독립 OS로 인해 스토리지, 메모리 더 많이 필요 | 리소스 비교적 적게 듦 |
| 호환성 좋음(거의 모든 OS 가상화 가능) | 컨테이너 이미지를 인한 이식성 좋음(일관된 실행환경 제공) |
| 하이퍼바이저(VMware)에 의해 리소스 관리 | 오케스트레이션 시스템에 의해 관리(자동화 유리) |
| 하이퍼바이저로 인한 오버헤드 | 리소스 직접 접근 가능 |
| 이식성 상대적으로 낮음(OS를 포함하는 것부터 이미지 크기 큼) | 이식성 높음(이미지도 경량화) |
컨테이너의 빠른 배포(빠른 이식)이 좋은 이유! CI/CD 파이프라인에 유리함!
가상머신이 좋은 이유! 보안성이 높아 보안이 중요하거나, 규제가 엄격한 환경에서 유리함!
컨테이너 기술은 기본적으로 리눅스에서 시작된 것. 따라서 리눅스 커널 기능을 사용하는게 기본이며, 윈도우즈에서 컨테이너를 쓰려면 wsl을 이용하거나 별도의 가상 머신이 필요함.
컨테이너의 이식성은 주로 같은 종류의 운영 체제 내, 즉 같은 커널을 공유하는 시스템 간에 높다. Windows Subsystem for Linux (WSL 2)를 통해 윈도우에서도 리눅스 컨테이너를 실행할 수 있으나, 이는 실제 리눅스 환경을 에뮬레이트하는 것이므로 성능과 호환성이 실제 리눅스 시스템과 차이가 날 수 있다.
동적 메모리 할당
malloc (엠얼록, memory allocation)
정적 메모리 할당
컴파일 타임에 메모리를 할당하고 고정된 크기의 메모리 공간을 사용
런타임 동안 크기가 변경되지 않음
메모리 소비량 예측 가능
메모리 할당 및 해제 비용 들지 않음
동적으로 메모리 확장, 축소 불가
동적 메모리 할당
런타임 중 메모리를 동적으로 할당하고 해제하는 방식
프로그램 유연성 높임, 메모리 사용 최적화 적합
메모리 할당 및 해제 비용 소모
메모리 누수 및 오류 방지 주의
#include <stdio.h>
#include <stdlib.h>
int main() {
static int count = 0; // 정적 할당, 정적 변수 선언과 초기화
int numbers[5]; // 정적 할당, 크기가 5인 정적 배열 선언
int *arr;
int size = 5;
arr = (int *)malloc(size * sizeof(int)); // 동적 할당, 크기가 20바이트인 메모리 공간을 확보하고 처음 주소를 포인터로 반환
if (arr == NULL) { // 메모리 할당에 실패하면 NULL을 반환한다.
fprintf(stderr, "메모리 할당 오류\n");
return 1;
}
// 메모리 해제
free(arr);
return 0;
}메모리 할당 크기와 데이터 형식을 일치시켜야 한다.
arr = (int *)malloc(5 * sizeof(char));이런 건 잘못된 메모리 할당 수행!
calloc (contiguous allocation)
malloc과 비슷한 역할을 수행하지만, 특정 크기 메모리를 할당하고 모든 비트를 0으로 초기화
연속적인(인접한) 메모리 공간을 할당하는 역할
주로 배열을 동적으로 할당하고 초기화 할 때 사용
void *calloc(size_t num_elements, size_t element_size);
num_elements: 할당하려는 요소의 개수
element_size: 각 요소의 크기
#include <stdio.h>
#include <stdlib.h>
int main() {
int *arr;
int num_elements = 5;
// 5개의 int 크기 요소를 가지는 배열을 할당하고 0으로 초기화
arr = (int *)calloc(num_elements, sizeof(int));
if (arr == NULL) {
fprintf(stderr, "메모리 할당 오류\n");
return 1;
}
// 배열에 데이터 저장 또는 사용
// 메모리 해제
free(arr);
return 0;
}malloc이 1개의 파라미터로 통째로 메모리 공간을 할당한다면,
calloc은 2개의 파라미터로 '배열 몇 개' * 데이터 타입' 형태로 메모리 할당을 할 수 있어
배열 할당에 조금 더 편리하다.
그럼 초기화를 통해 안정적인 코딩을 할 수 있는 calloc쓰지 왜 malloc쓰나?
초기화에 따른 오버헤드가 발생하니까 유불리 고려해서 선택.
굳이 0으로 초기화 할 필요가 없을 수도 있는데 초기화해서 오버헤드 발생시킬 필요 없음.
배열 생성 후 바로 별도의 값으로 초기화를 한다면 calloc을 쓸 필요가 없지.
[용어 정리] 오버 헤드란?
어떤 작업을 수행할 때 추가적으로 소비되는 리소스나 시간
realloc (reallocate)
이미 할당된 메모리 블록 크기를 조절
void *realloc(void *ptr, size_t size);
ptr이 가리키는 메모리 블록의 크기는 size로 변경한다.
#include <stdio.h>
#include <stdlib.h>
int main() {
int *arr;
int newSize = 10;
// 초기로 5개의 int 크기의 메모리 블록 할당
arr = (int *)malloc(5 * sizeof(int));
if (arr == NULL) {
fprintf(stderr, "메모리 할당 오류\n");
return 1;
}
// 할당된 메모리에 값을 저장
for (int i = 0; i < 5; i++) {
arr[i] = i;
}
// 메모리 블록의 내용 출력
for (int i = 0; i < 5; i++) {
printf("%d ", arr[i]);
}
printf("\n");
// 메모리 블록의 크기를 10개의 int로 늘리기
int *newArr = (int *)realloc(arr, newSize * sizeof(int));
if (newArr == NULL) {
fprintf(stderr, "메모리 재할당 오류\n");
return 1;
}
// 새로운 메모리 블록에 데이터 복사
for (int i = 5; i < newSize; i++) {
newArr[i] = i;
}
// 새로운 메모리 블록의 내용 출력
for (int i = 0; i < newSize; i++) {
printf("%d ", newArr[i]);
}
printf("\n");
// 메모리 해제
free(newArr);
return 0;
}GCC(GNU Complier Collection)
GNU에서 제작한 오픈소스 컴파일러
GCC는 단일 컴파일러가 아닌 여러 개의 컴파일러로 이루어진 소프트웨어 패키지
처음에는 C만 지원했는데 지금은 다양한 프로그래밍 언어를 지원하는 컴파일러를 포함하고 있다.
(C, C++, Fortran, Ada, Go ...)
구성 요소
- 전저리기: cpp0(C), cc1-E(C++)
- 컴파일러: cc1
- 어셈블러: as
- 링커: collect2(내부 도우미), ld(실제 링킹 프로세스 수행 명령어)
주요 옵션
-g: 디버깅 정보를 포함하여 출력 파일 생성
-W: 합법적이지만 모호한 코딩에 대해 경고 메시지 출력
-Wall: 모든 모호한 코딩에 대해 경고 메시지 출력
-O2: 최적화 수준(-O0, -O1, -O2, -O3 가능) (Optimize)
-o {filename}: 출력 실행 파일 이름 지정(옵션 없으면 a.out 생성)
출력 제어 옵션
-E: 전처리 결과를 화면에 출력
-S: 컴파일만 수행, 어셈블리어까지만 변환(.s 파일 생성)
-c: 컴파일과 어셈블만 수행, (.o 파일 생성)
-v: 컴파일 과정의 각 명령어와 gcc 버전 정보 표시
-save-temps: 컴파일 중간 파일 생성(.i, .s)
전처리 옵션
-D{Macro}[=value] : 상수 선언(#define)
선택적 컴파일이나 외부 상수 선언에 사용
-I{dir}: 헤더 파일의 검색 경로 추가
기타 옵션
-m32: i386의 32비트 아키텍처로 컴파일
-M, -MM: 소스 파일 종속성 정보 표시(makefile에 사용)
컴파일러 최적화 수준이 높으면 좋은 거 아냐?
꼭 그런건 아님. 최적화 수준이 높으면 컴파일 시간이 오래 걸림.
또 컴파일러가 코드를 엄격하게 분석하므로, 일부 코드 최적화 문제로 컴파일 오류 발생 가능성 높음.
컴파일 수준이 높으면 특정 하드웨어나 아키텍처, 또는 특정 컴파일러에 종속적일 수 있어 이식성 떨어짐.
일반적으로 개발 초기 단계에서는 최적화 수준 낮추고, 성능 최적화 필요한 시점에서 높은 최적화 선택.
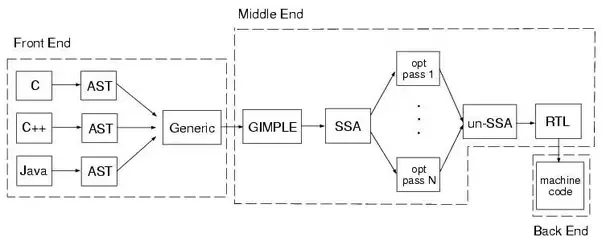
컴파일러 주요 구성 요소
프론트엔드
소스 코드 분석, 초기 단계 번역 수행
- 구문 문석(Parsing): 소스 코드를 토큰으로 분할, 문법 구조 분석 추상 구문 트리(Abstract Syntax Tree, AST) 또는 중간 표현(Intermediate Representation, IR) 생성
- 의미 분석(Sementic Analysis): 타입 검사, 변수 및 함수 스코프 확인, 오류 검츨 등 의미적 분석
- 최적화(Optimization): 일부 최적화(미들엔드에서 더 많은 최적화가 일반적임)
- 중간 표현 생성(Intermediate Representation Generation): 중간 표현 또는 어셈블리 코드 생성 후 미들엔드로 전달
미들엔드
프론트엔드에서 넘어온 중간 표현 또는 어셈블리 코드를 최적화
- 최적화(Optimization): 중간 표현 분석, 수정(최적화 기술 적용)
- 중간 표현 생성(Intermediate Representation Generation): 최적화된 중간 표현 또는 어셈블리 코드 변환
- 코드 재배치(Code Reordering): 명령어 순서 최적화
백엔드
최적화된 중간 표현, 어셈블리 코드를 목적 코드(기계어 코드)로 번역
- 목적 코드 생성(Code Generation): 기계어 코드 번역(실행 가능한 프로그램 생성)
- 레지스터 할당(Register Allocation): 목적 코드 성능 최적화
- 기계어 코드 최적화(Machine Code Optimization): 목적 코드 추가 최적화
- 링킹(Linking): 목적 코드 파일, 라이브러리 파일 겹함 -> 최종 실행 파일 생성
GCC
gcc -g hello.c -o hello.out
gcc : GNU Complier Collection 오픈소스 컴파일러
-g: gdb 디버깅 정보 포함
hello.c : 소스 파일
-o : 이름을 지정하겠다는 옵션(지정하지 않으면 a.out이 생성됨)
hello.out : 출력 파일
변환된 파일을 실행하려면 ./a.out 하면 됨.
.out 확장자는 무슨 뜻?
컴파일러 실행 파일 확장자(output의 줄임말)
실행파일로 역어셈블하기
objdump -d {file}
GDB(GNU Debugger) 디버깅 도구
gdb <디버깅할 실행 프로그램>
