기술 면접 관련 유튜브 보다가 늦게 잠..
08:00 입실
일찍 자야지..
CSAPP 7. 링크
7.5 심볼과 심볼 테이블
심볼의 종류
1. 모듈 m에 의해 정의되고 다른 모듈에 의해 참조될 수 있는 전역 심볼: 비정적 C함수, 전역변수에 대응
2. 모듈 m에 의해 참조되지만, 다른 모듈에 의해 정의된 전역 심볼: external이라고 함. 다른 모듈 내 전역 변수와 비정적 C함수에 대응
3. 모듈 m에 의해 배타적으로 참조되고 정의된 지역 심볼: static 타입 선언된 정적 C 함수와 전역변수 대응(다른 모듈에 의해 참조될 수 없음)
7.6 심볼 해석
링커는 재배치 가능 목적파일들의 심볼 테이블로부터 정확히 한 개의 심볼 정의에 각 참조를 연결시켜 심볼 참조를 해석함.
링커가 입력 모듈 중 참조된 심볼을 위한 정의를 찾을 수 없다면,
컴파일 시에는 문제가 없을 수 있지만 링커에서 에러가 발생할 수도 있음.
7.6.1 링커가 중복으로 정의된 전역 심볼 해결 방법
링커의 입력은 여러 개의 재배치가 가능한 오브텍트 모듈들
이 모듈 각각의 심볼 테이블이 있다.
자기 모듈 내의 심볼만 있는 경우도 있고(지역적)
다른 모듈의 심볼을 정의한 경우도 있다.(전역적)
근데 전역 심볼이 중복될 수도 있다!
이때 리눅스 링커는 다음 규칙을 사용한다.
규칙1. 동일명 복수의 강한 심볼 비허용
규칙2. 동일명 강한 심볼과 약한 심볼 중 강한 심볼을 선택
규칙3. 동일명 다수의 약한 심볼은 아무거나 선택해도 무관
7.6.2 정적 라이브러리와 링크하기
실행 파일 생성 시 링커는 응용프로그램이 참조하는 라이브러리 내의 객체 모듈들만 복사함
연관된 함수들은 별도의 객체 모듈로 컴파일해서 하나의 정적 라이브러리 파일로 패키지화
응용프로그램은 명령줄에 한 개의 파일 이름만 명시해서 라이브러리 내에 정의된 어떤 함수라도 사용할 수 있다.
예를 들어 C에서는 libc.a 표준 라이브러리도 문자열 처리 함수(printf, scanf 등)을 사용할 수 있다.
헤더 파일이 라이브러리 파일인가?
아님! 헤더 파일은 함수 및 변수의 선언이 주목적.
하지만 선언만 한다고 사용할 수 없다. 선언한 함수와 변수를 사용할 수 있는 최종적인 작업이 라이브러리 파일 링킹이다.
예를 들어 stdio.h에 선언된 내용은 libc.a에 구현되어 있다.
(컴파일 시 libc.a는 별도 참조 없이도 컴파일러가 알아서 링킹한다.)
7.6.3 링커가 참조 해석을 위해 정적 라이브러리 사용 방법
링킹 과정에서 일어나는 에러를 링크 타임 에러라고 함.
7.7 재배치
재배치를 요약하면,
목적 파일의 심볼과 런타임 메모리 메모리 주소를 매핑하는 과정!
-
섹션과 심볼 정의를 재배치: 프로그램 내 모든 인스트럭션과 전역변수들은 유일한 런타임 메모리 주소를 가진다. 섹션과 심볼 간의 상대적인 위치 조정으로, 심볼 참조를 완전히 해결하지 못함.
비유하자면 집을 짓기는 했는데, 이 집이 어떤 도로와 연결되는지, 다른 집과 어떤 관계인지는 안 정해짐. 그냥 집의 위치와 크기만 정해짐. -
섹션 내 심볼 참조 재배치: 링커는 코드와 데이터 섹션들 내의 모든 심볼 참조들을 수정, 정확한 런타임 주소를 가리키도록 함.(재배치 엔트리 자료구조에 의존)
비유하자면 집과 주변 도로, 주변 집과의 연결을 결정.
7.7.1 재배치 엔트리
목적 파일에 재배치 엔트리가 생성되면, 실행 파일 생성 시 재배치 엔트리를 활용해 섹션 내 심볼 참조(2단계)를 재배치 함.
7.7.2 심볼 참조의 재배치
pc-상대 참조 재배치: 프로그램 내에서 상대적이 메로리 주소 사용(오프셋 등)
절대 참조 재배치: 프로그램 내에서 실제 메모리 주소 직접 지정
(주로 메모리 주소를 하드웨어 장치와 연결하는 경우, 특정 레지스터 값을 특정 주소로 설정하는 경우)
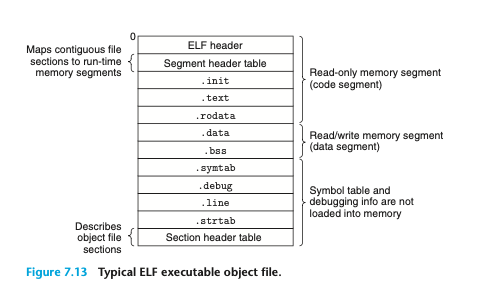
7.8 실행 가능한 목적 파일
7.9 실행 가능한 목적파일의 로딩
자, 최종 실행 파일을 실행해보자.
쉘에 ./prog처럼 실행 파일명을 입력하면 쉘은 prog가 내장 명령어가 아니니까
실행 가능한 목적파일이라고 가정하고, loader를 호출해서 이 프로그램을 실행함.
로더는 디스크에서 목적파일 내의 코드와 데이터를 메모리로 복사하고,
첫 번째 인스트럭션(엔트리 포인트)으로 점프해서 프로그램을 실행한다.
이러한 과정을 로딩이라고 부름!!
로딩이 무엇인지 알았다..
로더가 디스크의 내용을 메모리로 복사하고 실행하는 게 로딩이었다..
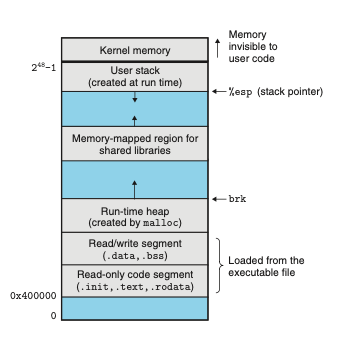
런타임 시 메모리 모습(단순화된 이미지임)
7.10 공유 라이브러리로 동적 링크
정적 라이브러리는 라이브러리가 바뀌면 모든 응용 프로그램을 다시 컴파일 해야 함.
공유 라이브러리 동적 링크는 컴파일 시 실행 파일에 라이브 코드가 직접 코함되는 게 아니라,
응용 프로그램이 런타임 시 필요한 라이브러리를 동적으로 로드하는 것
공유 라이브러리는 정적 라이브러리의 단점을 극복하는 현대의 혁신!!(?!)
(MS는 공유 라이브러리를 DLL(dynamic link libraries)라고 함.)
비유하면 파워포인트를 저장할 때,
이미지와 폰트를 모두 포함해서 파워포인트 파일 딱 1개만 가지고 가는건 정적 라이브러리,
이미지와 폰트의 참조만 저장하고 따로 첨부하는 방식이 공유 라이브러리 동적 링크
7.11 응용으로부터 공유 라이브러리 로드, 링크
동적 로더가 실행 직전에 링크할 수도 있지만,
런타임 시 공유 라이브러리를 로드하고 링크할 수도 있음.
7.12 위치-독립성 코드(PIC)
(여기서 위치는 메모리 위치를 의미함.)
위치 독립성 코드: 어떠한 재배치 작업 없이 로드될 수 있는 코드
위치 독립성 코드로 컴파일된 공유 파이브러리는 어느 곳에나 로드될 수 있으며, 다수의 프로세스에 의해 런타임에 공유된다.
공유 라이브러리를 쓸 수 있는 이유는 라이브러리를 메모리 특정 영역에 적재시키고,
다수의 프로세스들이 해당 메모리 주소로 접근해서 코드를 사용할 수 있게 하는 것인데,
이 경우 공유 라이브러리가 사용되지 않는 경우에도 항상 특정 영역에 적재되어 메모리 낭비가 발생하고,
메모리 관리에 어려움이 생긴다.
(공유 라이브러리가 많아질수록 이 문제는 심각해진다.)
이 문제 해결을 위해 현대 시스템은 공유 모듈 코드 일부를 컴파일한다.
그럼 특정 영역이 아니라 라이브러리 기능을 원하는 메모리 위치에 적재할 수 있다.
(즉, 라이브러리가 메모리 위치에 제약을 받지 않고 적재되어 실행될 수 있다.)
공유 라이브러리는 기본적으로 특정 메모리 영역에서만 로드되는 경향이 있다.
하지만 위치 독립성 코드로 컴파일된 공유 라이브러리는 메모리 위치에 구애받지 않고 메모리에 적재될 수 있다.
이렇게 되면 여러 응용 프로그램이 같은 라이브러리를 공유하면서도 메모리 낭비를 줄일 수 있다.
7.13 라이브러리 삽입
리눅스 링커가 지원하는 라이브러리 삽입 기술(library interpositioning)
라이브러리 상의 함수 호출을 가로채서 다른 함수(랩퍼)를 실행 시킬 수 있음.
이 기능을 활용하면 특정 함수가 얼마나 호출 되었는지 추적 가능(malloc, free 호출 추적 등)
라이브러리 삽입 방법
1. 컴파일 시 삽입
2. 링크 시 삽입
3. 런타임 삽입(LD_PRELOAD 환경 변수 활용)
7.14 목적파일 조작 도구
GNU binutils 패키지
- AR: 정적 라이브러리 생성, 멤버 추가, 삭제, 리스트, 추출
- STRINGS: 목적파일 내 인쇄 가능한 스트링 나열
- STRIP: 심볼 테이블 정보 삭제
- NM: 심볼 테이블 정의된 심볼 나열
- SIZE: 섹션들의 이름과 크기 나열
- READELF: ELF 헤더 구조 나타냄. SIZE, NM기능 포함.
- OBJDUMP: 모든 바이너리 도구들의 어머니(?), 목적파일 내 모든 정보를 표시. .text섹션 내 바이너리 인스트럭션들 역어셈블
실행 파일을 역어셈블 할때 쓰던 objdump가 여기 있었다!!!
7. 링커 챕터 읽고 느낀 점
링킹이 단순히 외부 라이브러리를 포함하는 단순한 작업이 아니었음.
규칙에 따라 심볼 처리도 하고, 라이브러리 링킹 방식도 정적/동적으로 나눠지는 것 알게 됨.
어제 가상머신과 컨테이너에서 나왔던 lib이 도대체 뭐지 했는데
이 파트 읽으면서 목적 파일과 링킹되는 라이브러리 개념에 대해서 알게됨!
8. 예외적인 제어 흐름(ECF)
exceptional control flow
하드웨어 이벤트(예외 핸들러), 시그널 핸들러, 커널 문맥전환
제어흐름은 기본적으로 순차적으로 진행된다.
이때 jump, call과 같은 인스트럭션은 제어흐름에 변화를 가져오는데,
이런 걸 ECF라고 한다.
ECF는 동시성을 이해하는 데 도움이 된다.
'시스템 콜'도 ECF의 한 가지 형태임!
8.1 예외 상황
예외 상황을 잘 설명하는 그림이다.
예외처리 핸들러가 제어이동(예외)를 촉발시키고,
처리가 끝나면 핸들러는 제어를 중단되었던 프로그램으로 돌리거나 실행을 중단함.
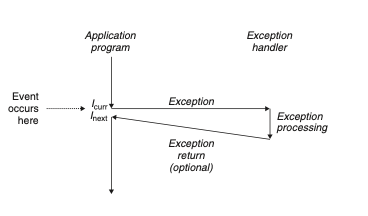
프로세서는 이벤트가 발생했다는 것을 감지하면,
예외 테이블이라는 점프 테이블을 통해 예외처리 핸들러(서브루틴)으로 간접 프로시저 콜을 한다.
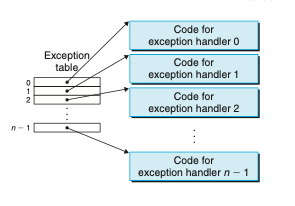
예외 처리가 끝나면 다음 중 하나가 발동된다.
1. 제어를 원래 인스트럭션으로 다시 돌려줌.
2. 제어를 원래 인스트럭션 다음 인스트럭션으로 돌려줌.
3. 중단된 프로그램을 종료함.
8.1.1 예외처리
런타임 시 프로세서가 이벤트 발생 감지
-> 대응되는 예외번호 K 결정
-> 예외 테이블의 엔트리 k를 통해 간접 프로시저 콜 방식으로 예외 상황 발생
예외 테이블도 메모리에 적재되어 있다. 이 테이블의 시작 주소는 예외 테이블 베이스 레지스터라는 특별한 CPU 레지스터에 담겨 있다.
프로시저 콜과 예외상황의 다른 점
프로시저 콜은 핸들러 분기 전 스택에 리턴 주소를 푸시
스택에 프로세서 상태를 푸시함.
프로시저 콜을 일반적으로 사용자 모드에서 동작함.
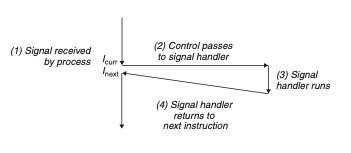
예외상황은 리턴주소가 현재 인스트럭션, 다음 인스트럭션이 됨.
예외 핸들러는 커널 모드에서 동작함.
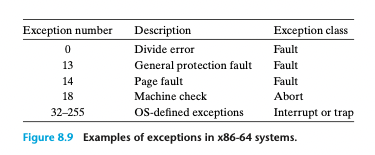
8.1.2 예외의 종류
예외가 모두 오류는 아니다!
1. 인터럽트
프로세서 외부에 있는 입출력 디바이스로부터의 시그널의 결과고 비동기적으로 발생
비동기적으로 발생한다는 말은 특정 인스트럭션으로 인해 발생한 것이 아닌 외부적인 요인에 의해서 발생
핸들러가 리턴할 때 제어를 다음 인스트럭션으로 돌려준다.
-> 인터럽트가 발생하지 않은 것처럼 계속해서 실행되는 효과
2. 트랩
트랩은 의도적인 예외 상황. 어떤 인스트럭션 실행 결과로 발생.
핸들러가 리턴할 때 다음 인스트럭션으로 돌려준다.
대표적인 트랩이 '시스템 콜'
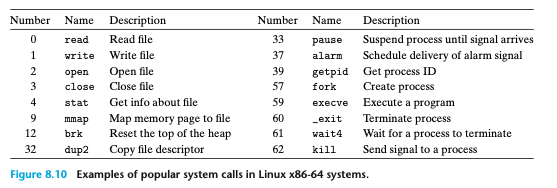
시스템 콜은,
사용자 프로그램이 read, fork, execve, exit와 같은 작업을 커널에서 요청할 필요가 있을 때,
사용자 프로그램이 사용하는 특별한 인스트럭션 'n' (x86 아키텍처에서는 syscall)
syscall인스트럭션은 트랩이 인자들을 해독하고, 적절한 커널 루틴을 호출하는 예외 핸들러로 가게 함.
시스템 콜은 커널모드의 전환을 유발하며, 사용자 모드의 특권 명령을 사용해서 커널 모드로 진입 후
커널 모드 특권 명령을 통해 시스템 콜 번호 확인 후 해당하는 시스템 콜 핸들러를 실행함.
3. 오류(fault)
오류는 핸들러가 정정할 수 있을 가능성이 있는 에러 조건으로부터 발생.
오류가 발생하면 프로세서는 제어를 오류 핸들러로 이동.
핸들러가 에러 조건을 정정할 수 있다면, 제어를 오류를 발생시킨 인스트럭션으로 돌려주어 재실행.
그렇지 않으면 핸들러는 커널 내부 abort 루틴으로 리턴해서 오류 유발 응용 프로그램 종료시킴.
Fault와 Error는 뭐가 다르나?
Fault는 예상 가능한 것. 예외 처리를 통해 처리(네트워크 끊김 등)
Error는 좀더 일반적인 용어, 시스템 오작동, 예상치 못한 상황 의미.(메모리 부족 등)
4. 중단(abort)
DRAM, SRAM 고장 시 발생하는 패리티 에러, 하드웨어 복구 불가능 등 치명적인 에러에서 발생
중단 핸들러는 응용 프로그램으로 제어를 리턴하지 않고, 중료하는 중단 루틴으로 넘김.
중단은 프로그램이 더 이상 안정적으로 실행될 수 없을 때 발생.
핸들러가 뭐지?
핸들러라는 말이 자주 나오는데(예외 핸들러, 오류 핸들러..) 핸들러가 정확히 뭘까?
핸들러는 특정 이벤트나 예외 상황을 처리하는 루틴 또는 함수!
즉, 특정 상황에서 어떤 동작을 수행해야 하는지 정의한 코드라고 할 수 있음.
8.2 프로세스
프로세스: 실행 프로그램의 인스턴스
문맥: 프로그램이 돌아가기 위해 필요한 상태
(코드, 데이터, 스택, 범용 레지스터, 프로그램 카운터, 환경변수, 열려있는 파일 식별자)
쉘에 목적파일이 입력되면 쉘은 새로운 프로세스를 생성 후 프로세스 문맥에서 목적파일을 실행함.
응용 프로그램이 새로운 프로세스를 만들 수 있음.(fork)
8.2.1 논리적인 제어흐름
PC값들을 논리적 제어흐름(논리흐름)이라고 할 수 있음!
프로세스는 여러 프로그램들이 동시적으로 동작하고 있음.
근데 프로세서를 혼자 사용한다는 착각을 느끼게 함. 이게 어떻게 가능하나?
하나의 프로세서를 여러 프로세스들이 교대로 돌아가면서 사용함!
8.2.2 동시성 흐름
동시성 흐름
(하나의 프로세서에서) 자신의 실행시간이 다른 흐름과 겹치는 논리흐름
어떤 프로세스가 동시성 관계에 있다는 건 A, B의 전체 흐름이 서로 겹쳐야 한다.
즉 A의 시작과 종료과, B의 시작과 종료가 시간 상으로 겹쳐지는 부분이 있어야 한다.
(번갈아 가면서 작업하는 것)
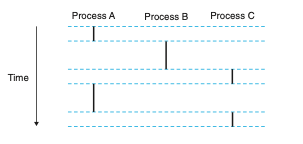
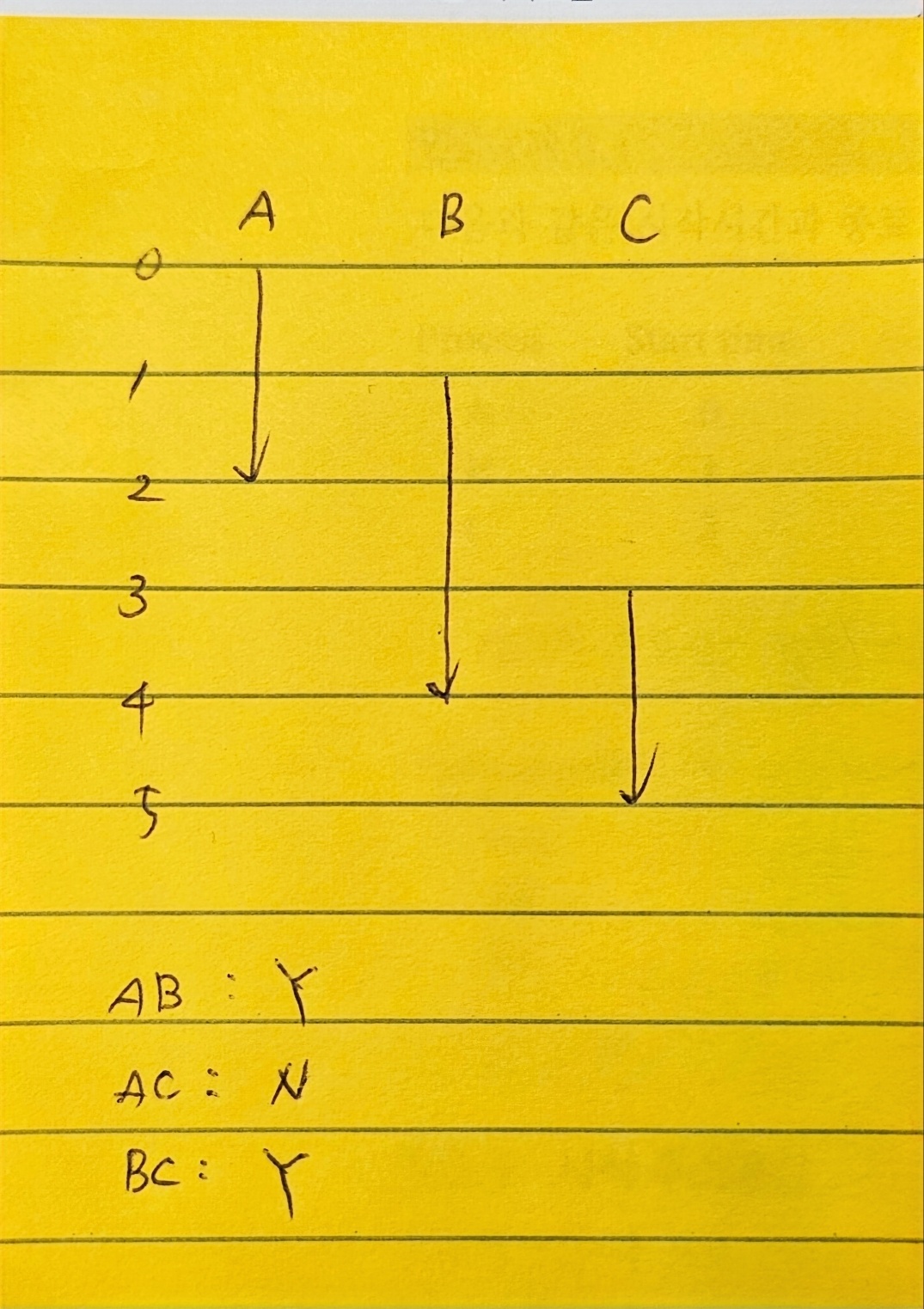
위 그림을 보자.
A의 시작과 종료와 B의 시작과 종료는 시간상으로 중첩되는 부분이 있다. 동시적이다.
A의 시작과 종료와 C의 시작과 종료로 시간상으로 중첩되는 부분이 있다. 동시적이다.
하지만 B의 시작과 종료와 C의 시작과 종료는 중첩되는 부분이 없다. 동시적이지 않다.
(B가 완전히 종료된 후 C가 실행된다.)
어떤 프로세스 간에 동시적인지를 판별할 때는 문맥교환을 고려하는 게 아니라 전체 프로세스의 시작과 종료를 가지고 중첩되는 부분이 있는지로 판단.
병렬 흐름
두 개의 흐름이 서로 다른 프로세서 코어나 컴퓨터 등에 동시에 돌아가는 것
동시성이라는 말이 오해를 일으킨다. 동시성 흐름은 물리적으로 같은 시간에 실행되는 게 아니라
하나의 프로세서를 번갈아가면서 (하나의 프로세서)에서 동시에 실행되는 것을 의미한다.
(즉, 논리적으로 동시에 실행되는 것!)
병렬 흐름은 별개의 프로세서에서 물리적으로 같은 시간에 실행되는 것을 의미한다.
(즉, 물리적으로 동시에 실행되는 것!)
동시성, 병렬성 개념 몰랐는데 확실히 알게됨!
연습문제 8.1
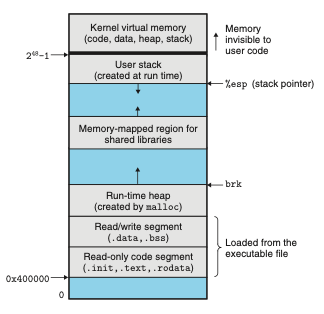
8.2.3 사적 주소공간
n비트 머신에서 주고 공간은 2^n-1 번지까지 존재한다.
프로세스는 각 프로그램에서 자신만의 사적 주소공간을 제공한다.
사적 주소공간은 (일반적으로) 다른 프로세스에 의해 읽히거나 쓰일 수 없다.
(그래서 사적이라고 표현)
사적 주소 공간을 가상 메모리라고 할 수 있음!
주소공간 아랫부분은 일반적인 코드, 데이터, 힙, 스택, 세그먼트
코드 세그먼트는 항상 0x400000에서 시작
주소 공간 윗 부분은 커널을 위해 예약(운영체제 메모리 상주 부분)
커널이 프로세스를 대신해서 인스트럭션 실행할 때 사용하는 코드(시스템 콜), 데이터, 스택 포함
8.2.4 사용자 및 커널 모드
프로세서는 완벽한 프로세스 추상화를 제공하기 위해서(보안, 격리, 안정성, 자원관리 등을 이유로)
응용프로그램이 접근할 수 있는 주소 공간과 실행할 수 있는 인스트럭션들을 제한해야 한다.
모드 비트로 모드를 결정할 수 있다.
모드 비트가 설정되면 커널 모드(슈퍼바이저 모드)로 동작한다.
커널 모드에서는 어떤 인스트럭션도 실행될 수 있으며,
시스템 내의 어떤 메모리에도 위치할 수 있다.
모드 비트가 설정되지 않은 상태(유저 모드)에서는 특수 인스트럭션 실행이 불가능하며,
주소 공간의 커널 영역에 있는 코드나 데이터를 직접 참조할 수 없다.
(시스템 콜을 통해 커널 코드와 데이터에 간접적으로 접근할 해야 함.)
사용자 모드에서 커널 모드로 어떻게 진입하냐?
예외를 통해서 모드를 바꿀 수 있음.
(인터럽트, 오류, 트랩(시스템 콜))
제어가 예외 핸들러로 넘어가면 프로세서는 사용자 모드에서 커널 모드로 변경
핸들러는 커널 모드에서 돌아간다.
8.2.5 문맥 전환(context switch)
컨텍스트는 커널이 선점된 프로세스를 다시 시작하기 위해서 필요로 하는 상태
(범용 레지스터, 부동소수점 레지스터, 프로그램 카운터, 사용자 스택, 상태 레지스터, 커널 스택, 페이지 테이블, 프로세스 테이블, 파일 테이블 등의 값)
커널이 어떤 프로세스 중에 무엇을 정지하고 무엇을 다시 시작할지 결정하는데, 이걸 스케줄링이라고 함.
스케줄링을 실행하는 코드를 스케줄러라고 함.
문맥 전환의 절차
1. 현재 프로세스 컨텐스트 저장
2. 이전에 선점된(일시 정지된) 프로세스의 컨텍스트 복원
3. 제어를 새롭게 복원된 프로세스로 전달
8.4 프로세스 제어
몇 가지 시스템 콜을 살펴본다.
1. 프로세스 ID 가져오기
#include <sys/types.h>
#include <unistd.h>
pid_t getpid(void);
pid_t getppid(void);2. 프로세스 생성과 종료
(프로그래머 관점에서) 프로세스는 다음 세 가지 상태를 지닌다.
(1) 실행 중: CPU에서 실행 되거나, 실행을 기다리고 있음. 커널이 스케줄할 예정.
(2) 정지: 스케줄 되지 않음
(3) 종료: 영구적으로 정지(종료 시그널, 메일 루틴 리턴, exit 호출)
#include <stdlib.h>
void exit(int status); // 종료 status로 프로세스 종료#include <sys/types.h>
#include <unistd.h>
pid_t fork(void); // 자식 프로세스를 fork 한다.3. 자식 프로세스 청소
프로세스가 종료될 때 커널은 시스템에서 종료된 프로세스를 즉시 제거하지 않음.
부모 프로세스가 청소할 때까지 종료된 자식 프로세스는 남아 있는데, 이걸 '좀비 프로세스'라고 함.
부모 프로세스가 종료할 때, 커널은 init 프로세스를 모든 고아가 된 자식들의 양부모로 만든다.
(init 프로세스 PID는 1이며, 시스템 초기화 때 커널에 의해 생성되고 결코 종료되지 않으며, 모든 프로세스의 조상이다.)
부모 프로세스가 자식 프로세스를 청소하지 않으면, 양부모가 된 init 프로세스가 자식들을 청소한다.
#include <sys/types.h>
#include <sys/waith>
pid_t waitpid(pid_t pid, int *statusp, int options);4. 프로세스 재우기
프로세스 정지
sleep()은 요청한 시간이 경과하면 0을 리턴하고, 그렇지 않으면 남은 시간 동안 잠을 정지
pause()는 시그널이 프로세스에 의해 수신될 때까지 잠을 재움
#include <unistd.h>
unsigned int sleep(unsigned int secs);
int pause(void);5. 프로그램의 로딩과 실행
execve함수는 현재 프로그램의 컨텍스트 내에서 새로운 프로그램을 로드하고 실행
#include <unistd.h>
int execve(const char *filename, const char *argv[], const char *envp[]);시스템 콜 호출은 함수 호출과 유사하다.
8.5 시그널
소프트웨어 형태의 예외적 제어 흐름
예외와 시그널의 차이는?
예외는 프로그램 실행 도중 비정상적인 상황이 발생했을 때 발생
예외는 주로 프로그램 실행 흐름 내에서 관리됨.
시그널은 간단한 메시지 형태로 이벤트를 알리는 방법
시그널은 운영체제가 프로세스에 전달하는 좀 더 낮은 수준의 메커니즘.
대표적인 시그널은 포그라운드에서 돌아가는 프로세스에 Ctrl+C를 입력하면 프로세스가 종료되는 것
8.5.1 시그널 용어
시그널을 목적지 프로세스로 전달하는 2단계
1단계. 시그널 보내기
2단계. 시그널 받기
시그널을 수신한 프로세스는 특정 동작(핸들러)를 실행한다.
시그널도 ECF라고 할 수 있을까?
ECF는 예외 처리를 일반화한 용어로 정상적인 제어 흐름을 변경하는 메커니즘이라는 관섬에서는 ECF의 형태로 볼 수 있지만, 통상적으로 ECF라는 용어는 소프트웨어 내부의 예외 처리에 초점이 맞추어진 용어임. 따라서 시그널과 ECF는 분리해서 사용하는게 맥락에 더 맞다고 볼 수 있음.
8.8 요약
프로세스 추상화의 큰 핵심 두 가지 기억하기!
1. 각 프로그램이 프로세서를 독점하고 있다는 착각(논리적 제어 흐름) - 컨텍스트 스위칭을 통해 구현
2. 각 프로그램이 메인 메모리를 독점하고 있다는 착각(사적 주소 공간) - 페이징, 세그멘테이션으로 구현
이 추상화를 구현하기 위해 ECF가 활용된다!
구체적으로 보면 타이머 인터럽트를 통해 컨텍스트 스위칭을 구현해 논리적 제어 흐름을 만들어내고,
프로세스가 유효하지 않는 메모리 접근을 시도하면 예외를 발생시켜 가상 메모리의 일관성을 유지한다.
(페이지 폴트를 통해 스왑 영역에서 데이터를 가져오는 예외 핸들러 작동)
9. 가상 메모리(VM)
메인 메모리의 추상화
'추상화'라는 용어가 계속 등장함.
추상화를 '사실 없는데 있다 치고'라고 생각하면 편함.
(그리고 실제로 있는 것처럼 동작함)
가상 메모리의 주요 기능
1. 메인 메모리를 디스크에 저장된 주소공간에 대한 캐시로 취급(필요할 때만 씀) -> 메인 메모리 효율화
2. 각 프로세스에 통일된 주소 공간을 제공 -> 메인 메모리 관리 단순화
3. 다른 프로세스에 의한 메모리 손상 방지 -> 메인 메모리 안정화
가상 메모리는 프로그래머 개입 없이 잘 동작하지만 왜 알아야 되냐?
우선, 가상 메모리는 컴퓨터 시스템에서 위대한 아이디어 중 하나다!!
- 모든 컴퓨터 수준에서 가상 메모리가 중심이다.
- 가상 메모리는 강력하다.
- 가상 메모리는 위험하다.
9.1 물리 및 가상주소 방식
물리 주소 방식
메인 메모리는 M개의 연속적인 바이트 크기 셀의 배열이다.
각 바이트는 0부터 시작하는 고유 물리 주소(PA)를 가진다.
CPU는 그냥 물리 주소로 메모리에 접근할 수 있다.
초기 PC는 이 방식을 사용하였음.
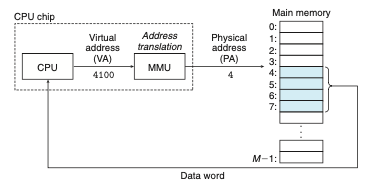
가상 주소 방식
CPU는 가상 주소(VA)를 생성해서 적절한 물리 주소로 변환해서 메인 메모리에 접근한다.
가상 주소를 물리 주소로 변환하는 작업을 주소 번역이라고 한다.
주소 번역을 하는 전용 하드웨어가 메모리 관리 유닛(MMU)
MMU는 메인 메모리에 저장된 참조 테이블(페이지 테이블)을 사용해서 실행 중에 가상주소를 번역한다.
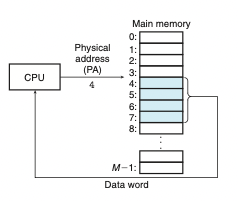
9.2 주소 공간
주소 공간은 비음수 정수이다.(0부터)
9.3 캐싱 도구로서의 VM
가상 페이지는 중첩되지 않은 다음 부분 집합으로 나뉨.
1. Unallocated: 비할당 페이지들.
2. Cached: 물리 메모리에 캐시되어 할당된 페이지들.
3. Uncached: 물리 메모리에 캐시되지 않은 할당된 페이지들.(보조 기억 장치 스왑 영역에 적재되어 있음)
9.3.1 DRAM 캐시
SRAM(캐시 메모리) > DRAM(메인 메모리, SRAM 보다 10배 더 느림) < DISK(100,000배 더 느림)
DRAM vs SRAM은 무슨 차이?
DRAM은 1셀 1트랜지스터 + 1캐패시티. 캐패시티에 전하(데이터)를 저장. 주기적으로 전하 재충전 필요.
SRAM은 1셀 6트랜지스터 + 캐패시티 없음. 플립 플롭 회로로 데이터 저장.
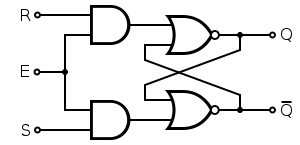
플립플롭이 뭐야?
1비트 정보를 유지(기억)할 수 있는 논리 회로
9.3.2 페이지 테이블
MMU가 주소 번역을 할 때 페이지 테이블을 읽는다.
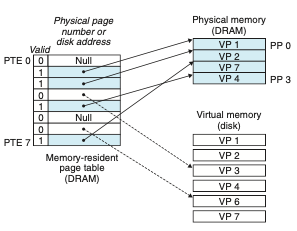
페이지 테이블은 PTE(페이지 테이블 엔트리)의 배열이다.
페이지 테이블은 프로세스마다 존재한다.
메모리가 쪼개져서 할당되니까 CPU는 특정 메모리를 읽고 그 다음을 어디를 읽어야 하는지 모른다.
그때 참조하는게 페이지 테이블이다.(다음 페이지가 어느 프레임에 있는지 적혀있는 테이블)
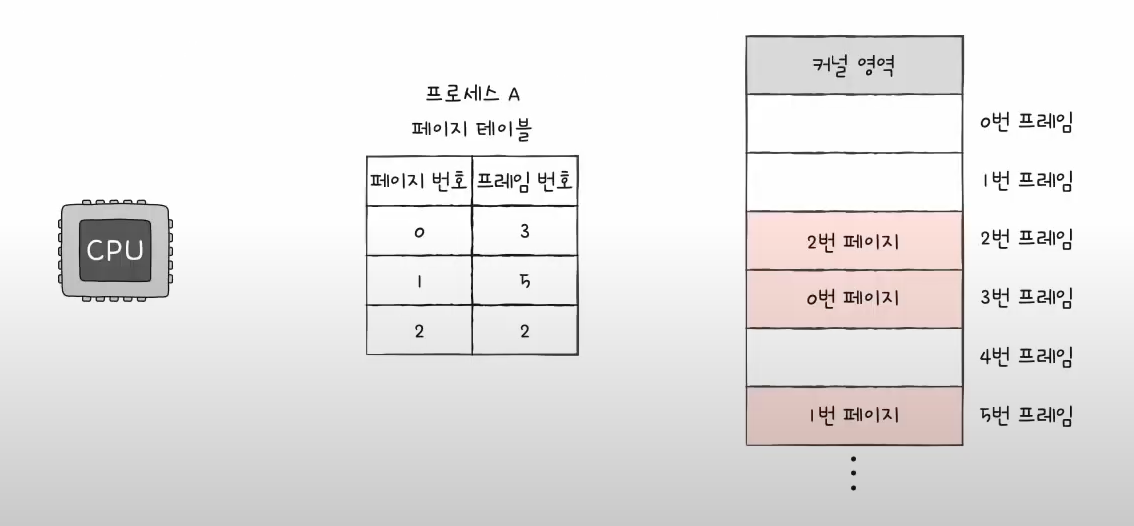
(출처 및 추천영상: https://www.youtube.com/watch?v=8ufliWkgqMo&t=11s)
가상 메모리를 페이지 단위로 나누고, 물리 메모리를 프레임 단위로 나누어서
페이지를 프레임에 끼워 넣는 방식으로 동작한다.
페이징은 메모리 할당 크기를 통일시켜서 외부 단편화를 해결하지만,
페이지 내부에 공간이 낭비되는 내부 단편화를 야기할 수 있다.
페이지 테이블은 단순히 페이지 엔트리, 프레임 엔트리만 있는 게 아니다.
유효 비트, 보호 비트, 참조 비트, 수정 비트 등 다양한 정보가 함께 있다.
(예를 들어 CPU 참조 횟수를 나타내는 참조 비트로 페이지 적중률을 높일 수 있음.)
9.3.3 페이지 적중
DRAM에 페이지가 적재되어 있는 경우
9.3.4 페이지 오류(page fault)
유효 비트로부터 DRAM에 페이지가 적재되어 있지 않다는 것을 알 수 있음.
이때 예외 핸들러를 호출해서 디스크에서 페이지를 스왑 인.
페이지는 프로세스마다 생성되며 메인 메모리에 적재된다.
그 말은 프로세스는 페이지 테이블에 한 번, 실제 실행 할 때 한번 총 두 번의 메인 메모리 접근이 일어나서
이는 매우 느린 작업이다.
그래서 TLB(Translation Lookaside Buffer)캐시에 페이지 테이블 일부를 캐싱한다.
TLB는 MMU 내부에 존재한다.
CPU는 가상 주소를 물리 주소로 변환해야 할 때 먼저 TLB를 확인하고, 없으면 메인 메모리에 적재된 페이지 테이블에 접근한다.
요구 페이징 기법이 뭐야?
프로그램을 처음부터 물리 메모리에 올리는 게 아니라 필요한 순간에 페이지를 물리 메모리로 올리는 기법!
9.6 주소 번역
주소 변환은 페이지 번호 + 변위로 구성됨!
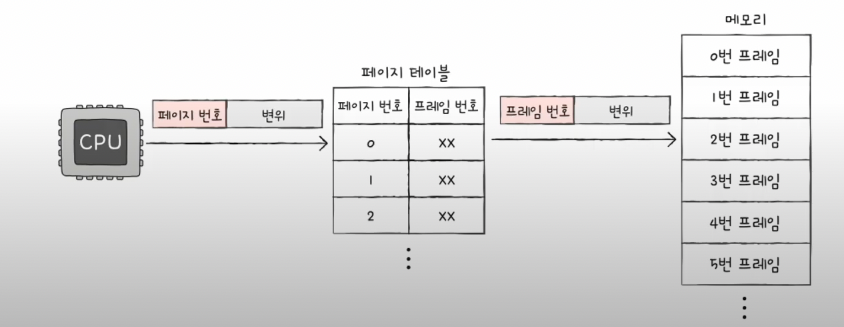
CPU내의 제어 레지스터인 페이지 테이블 베이스 레지스터(PTBR)는 현재 페이지 테이블을 가리키며,
오프셋을 통해 주소 번역이 이루어진다.
페이지 테이블의 dirty bit의 역할
수정된 페이지 테이블은 스압 아웃 시 디스크에서 값을 동기화해줘야 하기 때문.
만약 페이지 테이블이 스왑 인 이후 수정되지 않았다면 디스크 값 다시 갱신할 필요가 없음.
(초기값은 0, 쓰기 작업이 진행되면 1)
9.9 동적 메모리 할당
메모리 할당은 할당기(memory allocator)가 담당한다.
동적 메모리 공간을 할당하고 회수하는 기능을 수행하는 시스템이다.
동적 메모리 할당은 heap을 관리한다.
힙은 낮은 주소에서 높은 주소로 확장되는 형태의 메모리 영역이다.
(스택은 높은 주소에서 낮은 주소로)
힙의 꼭대기를 가리키는 변수는 brk("break"로 발음)
명시적 할당기
메모리 할당과 해제를 명시적으로 직접 관리
예) malloc(), free() 같은 것
묵시적 할당기
메모리 할당과 해제를 시스템이 자동으로 함
예) 가비지 콜렉터
9.9.1 malloc(), free()
malloc()의 구현 예시
#include <unistd.h>
void *malloc(size_t size) {
void *block;
block = sbrk(size);
if (block == (void *) -1) {
return NULL; // 메모리 할당 실패
}
return block;
}sbrk함수는 커널의 brk 포인터에 incr을 더해서 힙을 늘리거나 줄인다.
성공하면 이전 brk를 리턴하고, 아니면 -1을 리턴한다.
9.9.2 동적 메모리 할당 쓰는 이유
컴파일 시점에서는 런타임에 필요한 자료 구조 크기를 알 수 없어서.
예를 들어 사용자에게 특정 값을 입력 받는데, 사용자가 얼마나 많은 자료를 입력할지 모를 때는
컴파일 시에 배열 크기를 미리 지정해 버리면 배열을 초과하는 데이터는 입력 받을 수 없다.
이때 런타임 시에 배열이 가득 차면 동적 할당을 통해 새로운 배열을 생성할 수 있다.
9.9.4 단편화
이건 어제 정리했음! 간단히 다시 복기!
내부 단편화
할당된 블록이 데이터 자체보다 더 클 때
외부 단편화
메모리 공간이 전체적으로 모았을 때는 충분하지만, (모두 조각 나 있어서) 단일 가용 블록이 없는 경우
9.9.5 ~ 구현 이슈(할당기 직접 구현)
이건 그냥 우선 가볍게 훑어보고.. 아마 다음 주차(?)에서 구현해 볼 듯?
9.10 가비지 컬렉션
가비지 컬렉터는 더 이상 프로그램에서 사용하지 않는 블록들(가비지)을 자동으로 반환하는 동적 저장장치 할당기
이렇게 자동으로 힙 저장장치를 반납하는 과정을 가비지 컬렉션이라고 함!
C는 기본적으로 가비지 컬렉터가 없다. 즉 malloc으로 동적 할당 후에는 반드시 free 로 메모리를 반납해야 한다. 하지만 외부 라이브러리를 통해 할당만 하고 해제는 가비지 컬렉터를 쓰는 것과 같은 효과를 낼 수 있다.
9.11 가비지 컬렉터 기초
가비지 컬렉처는 기본적으로 방향성 도달 그래프로 메모리를 고려한다.
루트 노드와 힙 노드로 구분한다.
각 힙 노드는 힙 내 한 개의 할당된 블록에 대응
에지 p -> q는 블록 p 내부의 위치가 블록 q 내부의 위치를 가리킨다는 것
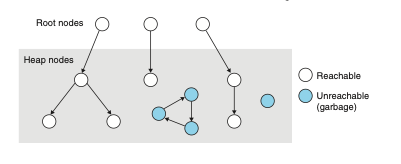
여기서 그래프 자료구조가 나온다!!
9.12 메모리 관련 버그
1. 잘못된 포인터 역참조
주소를 전달해야 하는데 값을 전달하는 경우
2. 초기화되지 않은 메모리를 읽는 경우
배열은 0으로 초기화하거나, calloc사용하기
3. 스택 버퍼 오버플로우 허용
입력 값을 버퍼에 쓸 때 길이를 제한하지 않으면 버퍼 오버플로우 발생
fgets으로 입결 길이 제한하기
4. 포인터와 이들이 가리키는 객체드링 같은 크기라고 가정하기
sizeof(int*)와 sizeof(int)는 다르다!
5. off-by-one 에러
덮어쓰기 오류.
반복문, 배열 인덱스에서 시작이나 끝 조건을 잘못 계산하여
기대하는 범위의 값보다 하나 적게 혹은 하나 더 많게 처리할 때 발생
6. 포인터가 가리키는 객체 대신에 포인터 참조하기
*size--;는 포인터 자신을 감소시킨다.
(와 --는 우선순위가 같아서 우에서 좌로 결합됨)
`(size)--;`와 같이 써야 한다. (원래 목적이 객체 값을 감소시키는 것)
연산자의 우선순위를 잘 모르겠으면 ()괄호로 명확하게 하기!
7. 포인터 연산에 대한 오해
포인트 연산은 바이트 단위가 아닌 객체의 크기 단위로 이루어 지는 것 기억하기!
8. 존재하지 않는 변수 참조하기
9. 가용 힙 블록 내 데이터 참조하기
10. 메모리 누수 유발
블록을 할당하고 반환하지 않을 때 발생
leak이 계속 발생하면 메모리는 가비지로 가득 차게 되고,
최악의 경우 전체 가상 주소를 모두 소모하게 된다.
메모리 누수는 데몬, 서버와 같이 종료되지 않는 프로그램의 경우에는 심각하다.
RB-Tree
레드-블랙 트리가 뭐야?
정의
이진 검색 트리: 왼쪽 서브 트리는 해당 노드 보다 작은 값, 오른쪽 서브 트리는 해당 노드 보다 큰 값
각 노드한 색깔을 기억하는 추가 비트가 존재함.
루트에서 리프까지 나타나는 노드의 색깔을 제한한다.
-> 어떤 것도 다른 것보다 두 배 이상 길지 않음을 보장
-> 근사적으로 균형을 이룬 트리를 만듦!
노드의 필드
color
key
left
right
p
NIL 노드
한 노드의 자식 또는 부모가 존재하지 않으면 그에 대응되는 노드의 포인터 필드는 NIL값으로 채워짐.
NIL은 이진 검색 트리의 리프 노드들에 대한 포인터들로 간주
기를 가지는 정상 노드는 트리의 내부 노드로 간주
(nil은 특별한 의미는 아니고 그냥 null하고 동일함.)
레드-블랙 트리의 조건(특성)
- 모든 노드는 레드, 또는 블랙
- 루트는 블랙
- 모든 리프(NIL)은 블랙
- 노드가 레드이면 그 노드의 자식은 모두 블랙(= 레드 노드는 연속되지 않는다.)
- 각 노드에서 자손 리프까지 가는 경로에는 모두 같은 수의 블랙 노드가 있어야 한다.
(노드 길이를 제한하기 위한 조건)
경계 노드(NIL 노드)
한계 조건을 간단하게 해 주는 더미 객체
NIL노드는 노드 값이 NIL이 아니라 포인터이다.
NIL은 서로 다른 객체가 아니다.(표기상으로는 서로 다른 것처럼 그리는 게 이해해 쉬울 수는 있다.)
(물론 다른 객체를 가리키게 할 수도 있지만..우선 NIL이 서로 다른 객체가 아니라고 생각하기로 함)
RB트리는 왜 노드에 색을 집어 넣냐?
핵심 이유는 트리의 전체적인 높이를 균형 잡히게 만들기 위해서!
색을 기준으로 정렬해서 트리가 한 쪽으로만 치우치지 않게 함.
RB Tree 초기화 구현
rbtree *new_rbtree(void) {
rbtree *t = (rbtree *)calloc(1, sizeof(rbtree));
if (!t) {
printf("메모리 할당에 실패하였습니다.\n");
return NULL;
}
// NIL 노드를 생성합니다. 생성된 NIL 노드는 트리 내에서 계속 사용됩니다.
node_t *nil_node = (node_t*)calloc(1, sizeof(node_t));
if (!nil_node) {
printf("메모리 할당에 실패하였습니다.\n");
free(t);
return NULL;
}
// NIL 노드의 멤버를 설정합니다.
nil_node->color = RBTREE_BLACK;
nil_node->parent = nil_node;
nil_node->left = nil_node;
nil_node->right = nil_node;
// 트리의 멤버를 설정합니다.
t->root = nil_node;
t->nil = nil_node;
return t;
}RB Tree 삭제 구현
void delete_rbtree(rbtree *t) {
if (!t) return;
// 스택 공간을 할당합니다.
node_t *stack[1024];
int stack_top = 0;
// 스택에 루트 노드를 넣고 스택 포인터를 +1합니다.
if (t->root != t->nil) {
stack[stack_top] = t->root;
stack_top++;
}
// 스택이 비어있을 때까지 반복합니다.
while (stack_top > 0) {
// 스택에서 노드를 pop합니다.
stack_top--;
node_t *node = stack[stack_top];
// 오른쪽 노드를 먼저 넣어서 전위 순회를 구현합니다.
// T.nil이 아니면 오른쪽 노드를 스택에 push합니다.
if (node->right != t->nil) {
stack[stack_top] = node->right;
stack_top++;
}
// T.nil이 아니면 왼쪽 노드를 스택에 push합니다.
if (node->left != t->nil) {
stack[stack_top] = node->left;
stack_top++;
}
// 꺼낸 노드를 해제합니다.
free(node);
}
// 모든 노드를 해제 후에 T.nil을 해제합니다.
free(t->nil);
// 트리를 해제합니다.
free(t);
}스택 공간을 동적으로 할당해야 할 것 같음.
스택 공간이 2 * log₂(N+1) 만큼 필요함.(레드 블랙 트리의 최대 높이)
스택 포인터가 가장 최근에 push된 곳을 가리키는 것만 있는 건 아님. 이건 하드웨어, 시스템 스택 포인터 개념.
소프트웨어, 사용자 정의 스택포인터에서 포인터는 top을 의미하며, 이때의 스택 포인터는 가장 최근에 추가된 요소의 다음 위치를 가리킴.
RB Tree의 회전이란?
삽입, 삭제 시 레드 블랙 트리의 특성을 위반할 수 있음.
이러한 특성을 복구하기 위해 트리 내의 일부 노드들의 색깔과 포인터를 변경해야 함.
이를 위해 회전을 사용함.
회전은 이진 검색 트리 특성(균형 맞추기)을 보전해주는 국소적인 연산
좌회전과 우회전이 있음.
좌회전 방법
(우회전은 좌회전에 대칭)
노드 x에 대해서 좌회전을 적용할 때 오른쪽 자식 y는 T.nil이 아니라고 가정한다.
(x는 오른쪽 자식이 T.nil이 아닌 모든 노드에 해당)
좌회전은 x와 y를 연결하는 링크를 중심축으로 하여 적용
y는 서브 트리의 새로운 루트가 되며,
x는 y의 왼쪽 자식이 되고,
y의 왼쪽 자식은 x의 오른쪽 자식이 된다.
RB Tree 회전 수도 코드
Y X
/ \ / \
X c <-----------> a Y
/ \ / \
a b b c좌회전
void LeftRotate(rbtree *T, node_t *x) {
node_t *y = x->right; // x노드를 통해 y를 설정
x->right = y->left; // y의 왼쪽 서브 트리를 x의 오른쪽 서브 트리로 옮긴다.
if (y->left != T->nil) { // y의 왼쪽 서브트리가 nil이 아니면
y->left->parent = x; // y의 왼쪽 서브트리의 부모를 x로 업데이트
}
y->parent = x->parent; // y의 부모를 x의 부모로 업데이트
if (x->parent == T->nil) { // 만약 x가 루트였다면
T->root = y; // y를 새로운 루트로 설정
} else if (x == x->parent->left) { // x가 부모의 왼쪽 자식이었다면
x->parent->left = y; // y를 부모의 왼쪽 자식으로 설정
} else { // x가 부모의 오른쪽 자식이었다면
x->parent->right = y; // y를 부모의 오른쪽 자식으로 설정
}
y->left = x; // x를 y의 왼쪽 자식으로 설정
x->parent = y; // x의 부모를 y로 업데이트
}우회전
void RightRotate(rbtree *T, node_t *y) {
node_t *x = y->right; // y노드를 통해 x를 설정
y->left = x->right; // x의 오른쪽 서브 트리를 y의 왼쪽 서브 트리로 옮긴다.
if (x->right != T->nil) { // x의 오른쪽 서브트리가 nil이 아니면
x->right->parent = y; // x의 오른쪽 서브트리의 부모를 y로 업데이트
}
x->parent = y->parent; // x의 부모를 y의 부모로 업데이트
if (y->parent == T->nil) { // 만약 y가 루트였다면
T->root = x; // x를 새로운 루트로 설정
} else if (y == y->parent->left) { // y가 부모의 왼쪽 자식이었다면
y->parent->left = x; // x를 부모의 왼쪽 자식으로 설정
} else { // y가 부모의 오른쪽 자식이었다면
y->parent->right = x; // x를 부모의 오른쪽 자식으로 설정
}
x->right = y; // y를 x의 왼쪽 자식으로 설정
y->parent = x; // y의 부모를 x로 업데이트
}좌회전을 우회전으로 반대로 생각해서 2시간 정도 헤맴.
어떤지 이상하더라..
우선 RB트리 회전 개념까지는 이해했음!
