스타벅스 12:30
일요일은 정글 커리큘럼 상관 없이 하고 싶은 거 공부함!
오늘은 랭체인 공식문서 살펴보기!
랭체인 공식문서
랭체인의 모델
- LLM: 문자열 입력 -> 문자열 반환
- ChatModel: 메세지 목록(list of messages)을 입력 -> 메세지(message)를 반환
메세지란?
(문자열은 누구나 다 아는데, 메시지가 뭐야?)
기본적인 메시지 인터페이스는 BaseMessage 객체에 정의 되어 있음.
이 객체는 2개의 필수 속성이 있음.
- content: 메시지의 내용. 일반적으로 문자열 형태.
- role: 메시지를 보내는 개체(entity)
BaseMessage를 기반으로 한 확장된 메시지 객체
- HumanMessage: human/user로부터 오는 BaseMessage
- AIMessage: AI/assistant로부터 오는 BaseMessage
- SystemMEssage: system으로부터 오는 BaseMessage
- FunctinoMessage(ToolMessage): 함수/도구 출력으로부터 오는 BaseMessage
- 적절한 역할에 따른 메시지 객체가 없다면 ChatMessage 클래스를 통해 커스텀 가능
랭체인 모듈
LLM과 ChatModel에서 모두 사용할 수 있는 인터페이스를 제공함.
하지만 각 모델을 효과적인 프롬프트으로 구성하려면 각 모델의 차이를 이해해야 함.
예를 들어 두 모델에서 모두 사용할 수 있는 메서드로 .invoke()가 있음.
- LLM.invoke: 문자열 입력, 문자열 반환
- ChatModel.invoke: BesageMessage 리스트 입력, BaseMessage 출력
(입력 유형은 더 복잡하지만 설명할 때는 단순화)
invoke()
invoke()는 특정 메시지에 대한 처리를 시작하고, 모델에게 메시지를 전달
1. 입력 메시지 처리
2. 모델 선택
3. 메시지 전달(메시지를 전달받은 모델이 입력 메시지를 처리하고 응답 생성)
4. 응답 반환(일반적으로 문자열 형태)
5. 예외 처리(오류 처리)
모델 불러오기
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
llm = OpenAI()
chat_model = ChatOpenAI()두 모델은 configuration objects객체 이다.
configuration objects란?
다른 객체나 시스템의 동작은 구성하거나 설정하는 데 사용되는 객체
주로 설정 값, 옵션 또는 구성 정보를 저장하고 다른 객채에 전달해서 해당 객체의 동작을 변경하거나 조절
객체 지향 설계에서 객체 간의 결합도를 줄이고 유지 관리성을 향상 시킴
설정하기
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
llm = OpenAI()
chat_model = ChatOpenAI()
# 모델 정할 수 있음
# llm = OpenAI(model="gpt-3.5-turbo-instruct")
text = "What would be a good company name for a company that makes colorful socks?"
messages = [HumanMessage(content=text)]
llm.invoke(text)
# >> Feetful of Fun
# llm은 문자열로 반환
chat_model.invoke(messages)
# >> AIMessage(content="Socks O'Color")
# chat_model은 메시지로 반환Prompt tmeplates
LLM 앱에서 사용자의 입력을 직접 모델에 전달하지는 않는다.
다양한 부가 정보를 함께 전달하는데 그때 사용하는 게 프롬프트 템플릿이다.
사용자의 입력에 추가적인 컨텍스트를 추가해서 최종 프롬프트를 산출하는 것
즉, 사용자의 입력을 컨텍스트를 추가한 프롬프트 전환하기 위해 형시고하된 템플릿으로 묶는 것
이때 변수를 사용해서 동적으로 프롬프트를 결정할 수 있음.
예를 들어 사용자가 '피자'만 입력해도
템플릿을 통과한 최종 프롬프트는 '{피자}의 레시피를 알려줘'라고 변경되는 것
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template("What is a good name for a company that makes {product}?")
prompt.format(product="colorful socks")템플릿은 파이썬의 f-string과 비슷함!
프롬프트 템플릿 챗 모델 사용례
from langchain.prompts.chat import ChatPromptTemplate
template = "You are a helpful assistant that translates {input_language} to {output_language}."
human_template = "{text}"
chat_prompt = ChatPromptTemplate.from_messages([
("system", template),
("human", human_template),
])
chat_prompt.format_messages(input_language="English", output_language="French", text="I love programming.")
# [
# SystemMessage(content="You are a helpful assistant that translates # # English to French.", additional_kwargs={}),
# HumanMessage(content="I love programming.")
# ]템플릿 메시지 -> 챗 프롬프트 형태로 변환 -> 포맷팅
Output parsers
raw 출력 결과를 downstream에서 활용할 수 있는 포맷으로 변환하는 것
파싱 타입 예시
- LLM Text -> JSON, CSV
- ChatMessage -> String
- 메세지(콘텐츠)외에 다른 추가 정보 파싱
from langchain.schema import BaseOutputParser
class CommaSeparatedListOutputParser(BaseOutputParser):
"""Parse the output of an LLM call to a comma-separated list."""
def parse(self, text: str):
"""Parse the output of an LLM call."""
return text.strip().split(", ")
CommaSeparatedListOutputParser().parse("hi, bye")
# >> ['hi', 'bye']랭체인의 큰 흐름 이해하기!
입력(템플릿) -> 처리(모델) -> 출력(파서)
Composing with LCEL
LCEL: LangChain Expression Language
체인을 쉽게 구성하는 선언적 방법
자동으로 전체 동기화, 비동기 및 스트리밍 지원
입력 -> 처리 -> 출력의 일련의 과정을 하나의 체인으로 묶기!
각 단계는 여러번 묶을 수도 있음.
마치 리눅스의 파이프와 비슷한 개념
from typing import List
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import BaseOutputParser
class CommaSeparatedListOutputParser(BaseOutputParser[List[str]]):
"""Parse the output of an LLM call to a comma-separated list."""
def parse(self, text: str) -> List[str]:
"""Parse the output of an LLM call."""
return text.strip().split(", ")
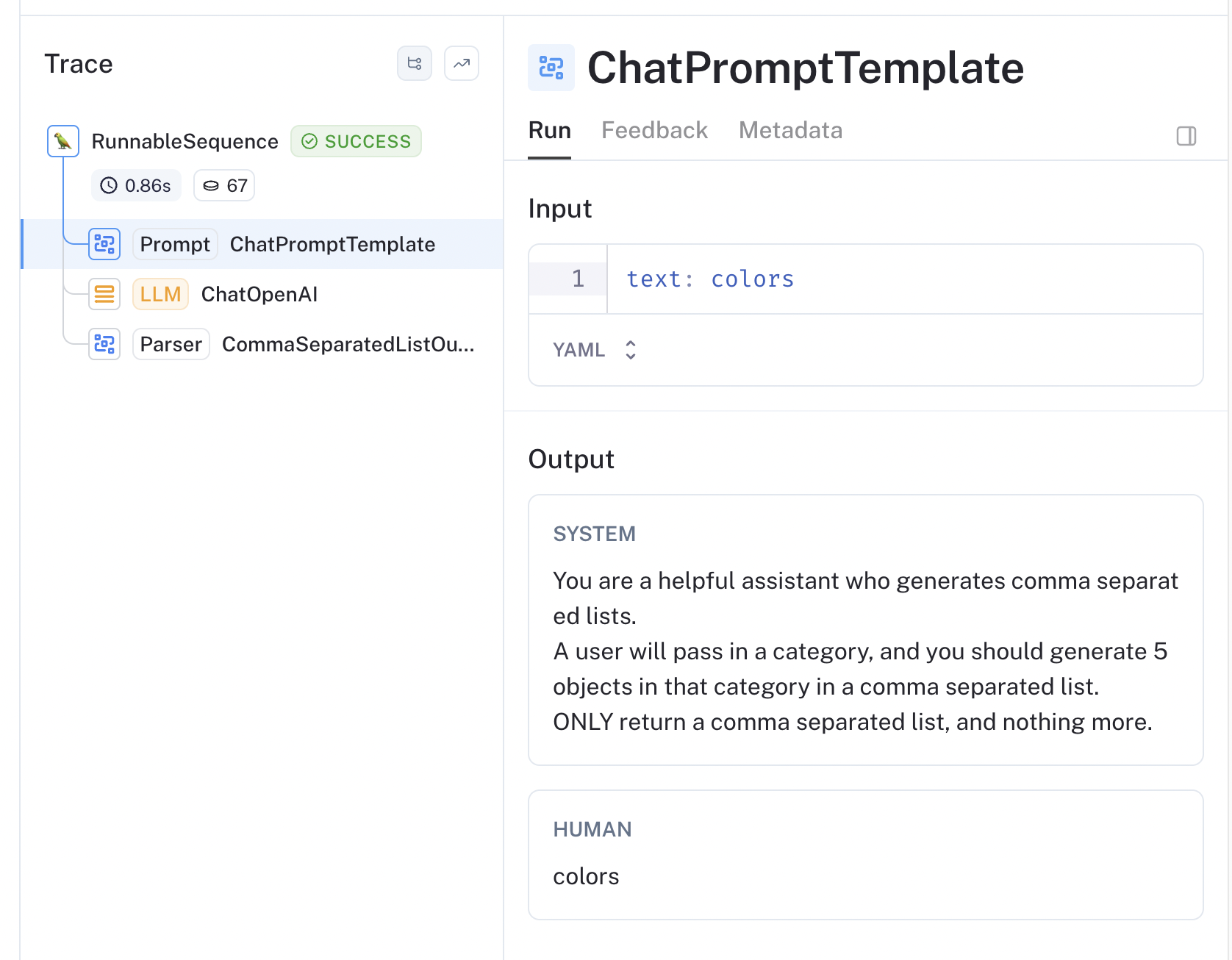
template = """You are a helpful assistant who generates comma separated lists.
A user will pass in a category, and you should generate 5 objects in that category in a comma separated list.
ONLY return a comma separated list, and nothing more."""
human_template = "{text}"
chat_prompt = ChatPromptTemplate.from_messages([
("system", template),
("human", human_template),
])
chain = chat_prompt | ChatOpenAI() | CommaSeparatedListOutputParser()
chain.invoke({"text": "colors"})
# >> ['red', 'blue', 'green', 'yellow', 'orange']LangSmith
LLM용 추적 및 디버깅 도구
환경 변수 세팅 후 수행 모델 및 체인 호출은 자동으로 LangSmith에 기록됨.
LangServe
LCEL체인을 REST API로 배포하는 서비스: 애플리케이션용 서버 생성
FastAPI와 통합되어 있음.
데이터 검증을 위해 pydantic 사용
python serve.py로 실행 가능
localhost:8000으로 실행
서버 코드
serve.py 생성
1. 체인 정의
2. FastAPI 앱
3. 체인 제공 경로: langserve.add_routes
#!/usr/bin/env python
from typing import List
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema import BaseOutputParser
from langserve import add_routes
# 1. Chain definition
class CommaSeparatedListOutputParser(BaseOutputParser[List[str]]):
"""Parse the output of an LLM call to a comma-separated list."""
def parse(self, text: str) -> List[str]:
"""Parse the output of an LLM call."""
return text.strip().split(", ")
template = """You are a helpful assistant who generates comma separated lists.
A user will pass in a category, and you should generate 5 objects in that category in a comma separated list.
ONLY return a comma separated list, and nothing more."""
human_template = "{text}"
chat_prompt = ChatPromptTemplate.from_messages([
("system", template),
("human", human_template),
])
category_chain = chat_prompt | ChatOpenAI() | CommaSeparatedListOutputParser()
# 2. App definition
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple API server using LangChain's Runnable interfaces",
)
# 3. Adding chain route
add_routes(
app,
category_chain,
path="/category_chain",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)클라이언트 호출
from langserve import RemoteRunnable
remote_chain = RemoteRunnable("http://localhost:8000/category_chain/")
remote_chain.invoke({"text": "colors"})
# >> ['red', 'blue', 'green', 'yellow', 'orange']원래는 서버 측에서 invoke를 실행했는데,
LangServe로 클라이언트에서 API와 함께 invoke를 원격으로 호출할 수 있음.
LCEL(랭체인 표현 언어)
체인을 쉽게 구성하는 선언적 방법
가장 단순한 형태는 "프롬프트 + LLM"
랭체인 사용 이유?
-
스트리밍 지원
각 단계별로 가장 최적의 시간에 빠르게 데이터 얻을 수 있음. -
비동기 지원
-
최적화된 병렬 실행
-
재시도 및 대체
-
중간 결과 액세스
-
입력 및 출력 스키마
-
모든 단계 자동 LangSmith 기록
https://python.langchain.com/docs/expression_language/why
LCEL이 없으면 각 단계를 콜백함수 형태로 체이닝 해야 함.
그 외 코드를 획기적으로 줄여주는 여러 이점이 있음.
아래 링크에서 확인 가능

LCEL 예시
프롬프트 + 모델 연결
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
model = ChatOpenAI()
output_parser = StrOutputParser()
chain = prompt | model | output_parser
chain.invoke({"topic": "ice cream"})
RAG
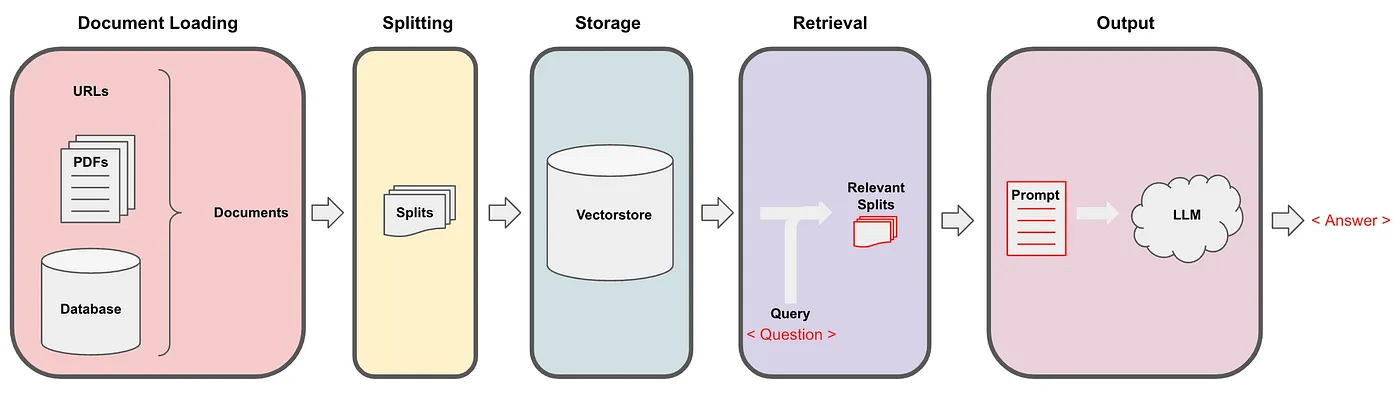
Retrieval(검색)-Augumented(증강) Generation(생성)
새로운 지식에 관한 텍스트를 데이터 소스에 임베딩 후 Vector stores에 저장
프롬프트 구성 시 외부 데이터 소스를 이용해 프롬프트 구성하고 LLM에게 답변 얻기
검색-생성 단계로 이루어짐.
1. 검색: 벡터 저장소에서 외부 데이터 소스 검색
2. 생성: 검색 단계에서 얻는 정보로 LLM이 답변 생성(검색 정보 + 자체 학습 지식 결합)
LLM에게 미학습 데이터를 주입하는 방법 2가지가 있음.
1. Fine-Tuning
2. RAG
RAG를 활용하면 최신 정보 및 특정 분야 전문 지식 질문에 대한 답변 생성 가능
RAG 예시 코드
# Requires:
# pip install langchain docarray
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableParallel, RunnablePassthrough
from langchain.vectorstores import DocArrayInMemorySearch
vectorstore = DocArrayInMemorySearch.from_texts(
["harrison worked at kensho", "bears like to eat honey"],
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI()
output_parser = StrOutputParser()
# context는 검색기가 가져온 문서 결과, question은 원래 질문
# RunnablePassthrough() 입력을 그대로 통과시키는 간단한 함수, 원래 질문을 복사하는 데 사용
setup_and_retrieval = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
)
chain = setup_and_retrieval | prompt | model | output_parser
chain.invoke("where did harrison work?")다음 체인에 의해서 먼저 데이터를 읽고 그 다음 체인을 진행함.
chain = setup_and_retrieval | prompt | model | output_parser
프롬프트 생성 전 문서를 검색해서 해당 내용을 프롬프트의 컨텍스트로 구성 후 LLM 모델로 넘김

LCEL Interface
체인을 쉽게 구현할 수 있는 Runnable 프로토콜
주요 메서드(동기)
- stream: 응답 청크 back stream, 연속적인 데이터 플로우 처리
- invoke: 단일 입력 값에 대해 체인 호출
- batch: 입력 리스트에 대해 체인 호출
비동기 메서드
- astrem: 비동기적으로 stream
- ainvoke: 비동기적으로 invoke
- abatch: 비동기적으로 batch
- astream_log: 데이터 처리 또는 실행 체인 중에 발생하는 중간 단계를 실시간으로 스트리밍하고, 최종 응답과 함께 이러한 중간 단계들을 로깅
입력 및 출력 유형
| Component | Input Type | Output Type |
|---|---|---|
| Promprt | Dictionary | PromptValue |
| ChatModel | string, chat messages, PromptValue | ChatMessage |
| LLM | string, chat messages, PromptValue | String |
| OutputParser | output of LLM/ChatModel | Depents on the parser |
| Retriever | string | List of Documents |
| Tool | string, dictionary, depending on the tool | Depends on the tool |
입력 및 출력 스키마
스키마를 통해 입력 및 출력 형태를 검사할 수 있음.
- input_schema: Runnable에서 자동 생성된 입력 Pydantic 모델
- output_schema: Runnable에서 자동 생성된 출력 Pydantic 모델
Pydantic은 Python에서 사용하는 데이터 검증 및 설정 관리 라이브러리
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
model = ChatOpenAI()
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
chain = prompt | model
# 해당 체인에 최초로 입력되는 데이터가 어떤 스키마 구조를 따라야 하는지를 정의하고 검증
chain.input_schema.schema()
# 해당 프롬프트에 입력되는 데이터가 어떤 스키마 구조를 따라야 하는지를 정의하고 검증
prompt.input_schema.schema()
# 해당 모델에 입력되는 데이터가 어떤 스키마 구조를 따라야 하는지를 정의하고 검증
model.input_schema.schema()아웃풋도 동일함!
# The output schema of the chain is the output schema of its last part, in this case a ChatModel, which outputs a ChatMessage chain.output_schema.schema()
stream
생성되면 바로바로 실시간으로 출력됨
for s in chain.stream({"topic": "bears"}):
print(s.content, end="", flush=True)
# > Why don't bears wear shoes?
# > Because they already have bear feet!stream 메소드가 range() 함수와 비슷한 "lazy evaluation" 방식으로 작동한다고 볼 수 있습니다.
invoke
chain.invoke({"topic": "bears"})
# > AIMessage(content="Why don't bears wear shoes?\n\nBecause they already have bear feet!")batch
chain.batch([{"topic": "bears"}, {"topic": "cats"}])
# 동시 요청 최대 수 제한
# 설정 값만큼 동시 요청되며 나머지는 대기 후 순차적으로 처리
chain.batch([{"topic": "bears"}, {"topic": "cats"}], config={"max_concurrency": 5})Parallelism(병렬 요청)
from langchain.schema.runnable import RunnableParallel
chain1 = ChatPromptTemplate.from_template("tell me a joke about {topic}") | model
chain2 = (
ChatPromptTemplate.from_template("write a short (2 line) poem about {topic}")
| model
)
combined = RunnableParallel(joke=chain1, poem=chain2)Bind runtime args
Runnable 객체에 상수 인자를 바인딩
Runnable 시퀀스에서 이전 출력 또는 사용자 입력이 아닌 제 3의 값을 인자로 전달하기 위해 미리 설정
단순히 포매팅 용도가 아니라 모델 제어를 위한 조건 값 등을 넘기는 것
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Write out the following equation using algebraic symbols then solve it. Use the format\n\nEQUATION:...\nSOLUTION:...\n\n",
),
("human", "{equation_statement}"),
]
)
model = ChatOpenAI(temperature=0)
runnable = (
{"equation_statement": RunnablePassthrough()} | prompt | model | StrOutputParser()
)
print(runnable.invoke("x raised to the third plus seven equals 12"))
runnable = (
{"equation_statement": RunnablePassthrough()}
| prompt
| model.bind(stop="SOLUTION") # stop의 매개 변수로 "SOLUTION"을 사용하는 것
| StrOutputParser()
)
print(runnable.invoke("x raised to the third plus seven equals 12"))model이 "SOLUTION"이라는 단어를 만나면 처리를 중단하도록 지시할 수 있습니다.
이 bind 호출은 model의 실행 방식에 특정 조건을 미리 설정하는 데 사용됩니다.
이를 통해 model의 실행을 더 세밀하게 제어할 수 있습니다.
함수를 바인딩 할 수도 있음.
function = {
"name": "solver",
"description": "Formulates and solves an equation",
"parameters": {
"type": "object",
"properties": {
"equation": {
"type": "string",
"description": "The algebraic expression of the equation",
},
"solution": {
"type": "string",
"description": "The solution to the equation",
},
},
"required": ["equation", "solution"],
},
}
# Need gpt-4 to solve this one correctly
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Write out the following equation using algebraic symbols then solve it.",
),
("human", "{equation_statement}"),
]
)
# 여기서 함수를 바인딩
model = ChatOpenAI(model="gpt-4", temperature=0).bind(
function_call={"name": "solver"}, functions=[function]
)
runnable = {"equation_statement": RunnablePassthrough()} | prompt | model
runnable.invoke("x raised to the third plus seven equals 12")충격.. AI에서는 함수의 역할이 완전히 달라진다..

function vs tool
function: 단일 기능
tool: 여러 function의 집합(그룹화)
그래서 function은 딕셔너리 형태로 구성되고, tool은 리스트 형태로 구성됨.
Configuration Fields
매개변수를 더 세밀하게 조정
또는 기본값 설정 후 추후 세팅을 커스텀 할 때 사용
ConfigurableField를 사용하면 매개변수를 구성 가능한 필드로 정의해서 유연하게 사용 가능
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
model = ChatOpenAI(temperature=0).configurable_fields(
temperature=ConfigurableField(
id="llm_temperature",
name="LLM Temperature",
description="The temperature of the LLM",
)
)HubRunnables
Hub에 저장된 리소스나 기능을 재사용
from langchain.runnables.hub import HubRunnable
prompt = HubRunnable("rlm/rag-prompt").configurable_fields(
owner_repo_commit=ConfigurableField(
id="hub_commit",
name="Hub Commit",
description="The Hub commit to pull from",
)
)도커 허브, npm, pip과 비슷한 플랫폼
Configurable Alternatives
여러 객체에 다양한(여러 개의) 설정값 세팅 가능
LLM모델에 적용 예
llm = ChatAnthropic(temperature=0).configurable_alternatives(
# This gives this field an id
# When configuring the end runnable, we can then use this id to configure this field
ConfigurableField(id="llm"),
# This sets a default_key.
# If we specify this key, the default LLM (ChatAnthropic initialized above) will be used
default_key="anthropic",
# This adds a new option, with name `openai` that is equal to `ChatOpenAI()`
openai=ChatOpenAI(),
# This adds a new option, with name `gpt4` that is equal to `ChatOpenAI(model="gpt-4")`
gpt4=ChatOpenAI(model="gpt-4"),
# You can add more configuration options here
)
prompt = PromptTemplate.from_template("Tell me a joke about {topic}")
chain = prompt | llm프롬프트 적용 예
llm = ChatAnthropic(temperature=0)
prompt = PromptTemplate.from_template(
"Tell me a joke about {topic}"
).configurable_alternatives(
# This gives this field an id
# When configuring the end runnable, we can then use this id to configure this field
ConfigurableField(id="prompt"),
# This sets a default_key.
# If we specify this key, the default LLM (ChatAnthropic initialized above) will be used
default_key="joke",
# This adds a new option, with name `poem`
poem=PromptTemplate.from_template("Write a short poem about {topic}"),
# You can add more configuration options here
)
chain = prompt | llm설정 저장
체인 자체를 새로운 객체로 저장할 수 있음!
openai_poem = chain.with_config(configurable={"llm": "openai"})
openai_poem.invoke({"topic": "bears"})
# > AIMessage(content="Why don't bears wear shoes?\n\nBecause they have bear feet!")다음 공부할 차례!
https://python.langchain.com/docs/expression_language/how_to/fallbacks
내일 발표 초안(백업용)
😱 컴퓨터에서 정수가 아닌 실수의 표기 및 연산은 정확하지 않을 수 있다.
💸 부동 소수점 연산은 가수와 지수 부분 계산을 위한 오버헤드가 발생한다. 같은 메모리 공간이지만 꼭 필요하지 않으면 float가 아닌 int 사용이 좋다. (부동 소수점 표현 방식 추가 학습하기)
😅 부동 소수점을 지원하지 않는 시스템에서는 연산에서 소수 부분은 반올림(또는 버림)으로 근사치를 정수로 반환한다.
🤔 고정 소수점으로 표기해도 결국은 정수형으로 바꾸면 정밀도가 낮아지지 않나?
🙆 맞다. 정수로 변환되는 마지막에는 정밀도가 사라질 수 있지만, 고정 소수점으로 저장하면 연산 과정에서 정밀도가 일정 부분 보존 되므로 누적 오차를 줄일 수 있다.
🧑💻 예) 3 나누기 2의 결과는 정수 부분 1, 분수 부분 1/2이지만 최종적으로 1만 남게 된다. 하지만 이걸 고정소수로 인코딩하면 0 00000000000000001 . 1000000000000 (12288)으로 분수 부분을 살릴 수 있다. 이후 이 값을 디코딩하면 1이 되지만, 연산 과정에서 인코딩된 값으로 연산을 하면 정밀도를 살릴 수 있다.
👏 정수와 고정 소수점이 변환되는 과정을 통해 인코딩, 디코딩의 개념을 이해했다.
