이번에는 센서가 포착한 빛으로부터 어떻게 디지털 이미지가 생성이 되는지 이해할 것이다. 그래서 이미지가 어떻게 형성이 되는지와 이에 따라서 카메라가 처리하는 과정에 대해서 알아보려고 한다.
Image Formation in the Eye
카메라는 인간의 눈과 같은 기능을 하도록 만들어졌다. 그렇기 때문에 구조적으로 인간의 눈과 디지털 카메라는 같은 기능을 하기 때문에, 카메라가 처리하는 과정을 알아보기 전에 인간의 눈에 대해서 간단하게 알아보고자 한다. 대표적으로 눈의 iris(홍채)는 해부학적으로 가장 시각적인 부분을 담당한다. Iris는 수축과 이완을 통해서 pupil(동공)의 크기를 조절하여 안구로 들어오는 빛의 양을 조절해준다. 이는 카메라로 따지면 aperture에 해당하는 부분으로, 구멍을 열고 닫는 정도에 따라 통과되는 빛의 양을 조절하게 되는 것이다.
Retina
Retina(망막)은 인간의 눈에서 가장 안쪽을 둘러싸고 있는 내벽을 구성하는 얇은 층으로, 신경 세포로 이루어져 잇다. 이 retina는 카메라에서는 film의 역할을 하게 되는 것인데, retina의 일부분이 빛을 받고 나머지 부분은 그림자로 되어 있는 물체를 세밀하게 식별하게 해주는 약간의 차이점이 존재한다.
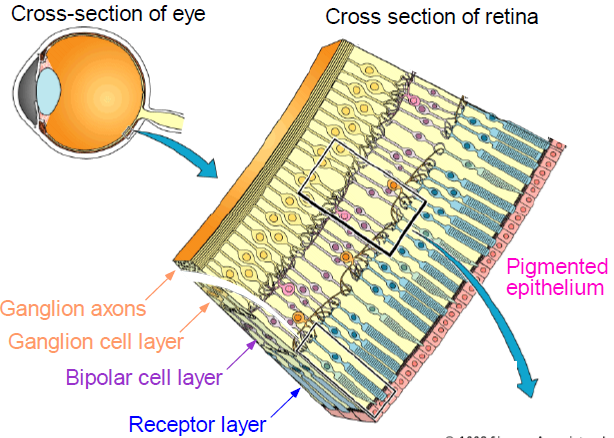
2 Types of Light Sensitive Receptors
인간의 retina에는 광자를 받아들이는 receptor가 2종류가 있다. 하나는 cone이고 다른 하나는 rod이다.
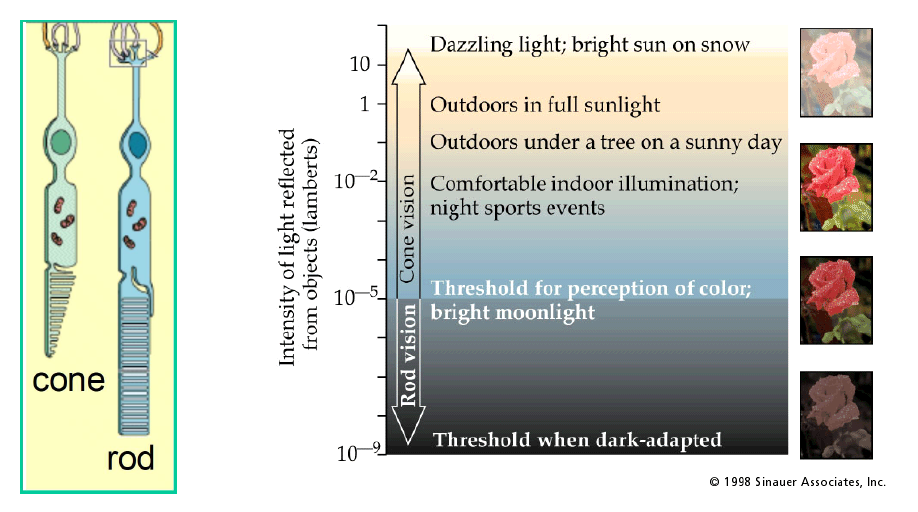 우선 cone은 원뿔 모양으로 생겨서 이름이 cone이며, 빛이 많을 때 활성화가 되며 빛에 대해서는 덜 sensitive하다. Cone은 3가지 종류로 구성되어 있으며, 이는 각각 빨간생(R), 초록색(G), 그리고 파란색(B)를 담당한다.
우선 cone은 원뿔 모양으로 생겨서 이름이 cone이며, 빛이 많을 때 활성화가 되며 빛에 대해서는 덜 sensitive하다. Cone은 3가지 종류로 구성되어 있으며, 이는 각각 빨간생(R), 초록색(G), 그리고 파란색(B)를 담당한다.
그리고 이와는 다르게 rod는 막대 모양으로 생겨서 이름이 rod로 불리며, cone과는 다르게 빛에 매우 sensitive한 특징이 있다. 그렇기 때문에 주로 빛이 많이 없는 밤에 활성화가 되며, 색에 대해서는 구분을 하지 못하고 오로지 gray scale에만 관여하도록 되어 있다.
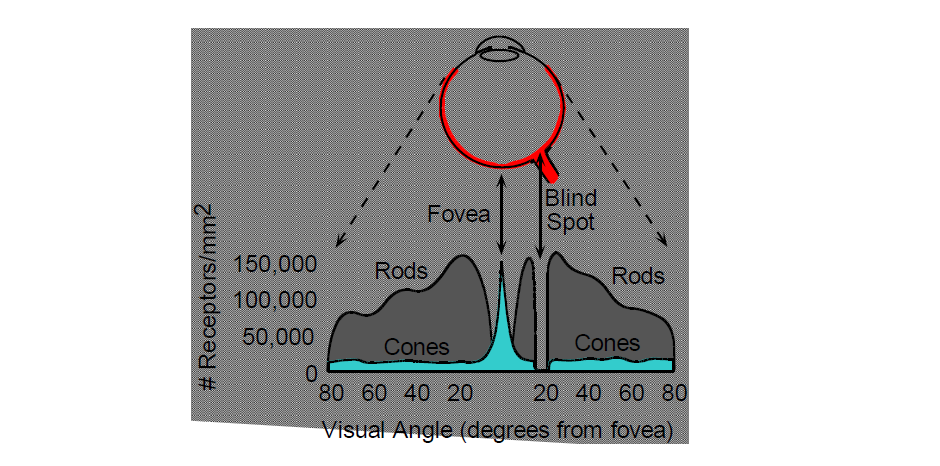 Retina의 표면에 걸쳐서 rod와 cone이 분포되어 있다. 눈에는 fovea(중심와)가 존재하는데, retina 중에서 뒷쪽의 빛이 들어와서 초점을 맺는 부위가 존재한다. 이 부분은 retina에 있고 색을 감지하는 세포가 많이 존재한다. 위의 분포에서도 보다시피 fovea에서는 rod보다는 cone 위주로 되어 있음을 알 수가 있다. 그리고 이 부분을 제외하고는 대부분 rod가 cone보다 많은 비중을 차지하고 있다. 하지만 blind spot에서는 cone과 rod가 존재하지 않는다. 그 이유가 이 부분에는 뇌와 연결하는 neuron이 케이블 처럼 다발로 연결이 되어 있다. 그렇기 때문에 이 부분에는 rod와 cone이 존재하지 않게 되는 것이다.
Retina의 표면에 걸쳐서 rod와 cone이 분포되어 있다. 눈에는 fovea(중심와)가 존재하는데, retina 중에서 뒷쪽의 빛이 들어와서 초점을 맺는 부위가 존재한다. 이 부분은 retina에 있고 색을 감지하는 세포가 많이 존재한다. 위의 분포에서도 보다시피 fovea에서는 rod보다는 cone 위주로 되어 있음을 알 수가 있다. 그리고 이 부분을 제외하고는 대부분 rod가 cone보다 많은 비중을 차지하고 있다. 하지만 blind spot에서는 cone과 rod가 존재하지 않는다. 그 이유가 이 부분에는 뇌와 연결하는 neuron이 케이블 처럼 다발로 연결이 되어 있다. 그렇기 때문에 이 부분에는 rod와 cone이 존재하지 않게 되는 것이다.
하나 재미있는 질문을 해보자. 밤 하늘에 별이 굉장히 많이 존재할 때, 사람의 시야에서 왜 중앙부보다 외곽부에 더 많은 별들이 보이는 것일까? 정답은 바로 averted vision이라는 한 technique 때문이다. 이는 우리가 집중해서 보고있는 한 물체가 있을 때, 이 물체뿐만 아니라 주변 부분도 어느정도는 인식이 되는 것과 관련이 있다. 그리고 이러한 현상으로부터 인간의 눈이 2종류의 빛을 감지하는 세포로 되어있음을 확인할 수 있었다. 중심부는 우리에게 색에 대한 정보를 주지만, 조금 벗어나게 되면 흑과 백에 대한 정보를 제공해주는 비중이 커진다. 그래서 한쪽으로 시선을 돌리면 희미한 물체에서 나오는 더 많은 빛이 rod 세포에 부딪히게되어 우리가 볼 수 있게 되는 것이다.
Image Formation in the Camera
인간의 눈에 대해서는 어느정도 살펴보았기 때문에, 이제부터는 카메라에 대해서 알아보려고 한다. 특히 디지털 이미지에 초점을 맞춰서 이미지가 어떻게 형성이 되는지 알아볼 것이다. 먼저, 이미지가 어떠한 형태로 존재할 수 있는지 알아보자.
Grayscale Digital Image
Gray-scale은 각각의 픽셀에 대해서 흑과 백의 정도를 0부터 255까지의 unsigned char(uint8) 타입으로 정의한 것이다. 완전히 검은색이면 0이고 완전히 하얀색이면 1이 되는 것이다. 적절하게 그 사이의 값을 통해서 강도가 다른 회색으로 이미지를 표현하면 된다. 이미지는 보통 2차원이기 때문에 픽셀 값으로 0 ~ 255를 정해주고 이를 2D array로 표현하면 gray-scale의 디지털 이미지를 만들 수 있다. 256개의 숫자가 필요하기 때문에 이는 2의 8제곱으로 픽셀마다 8bit면 충분하다.
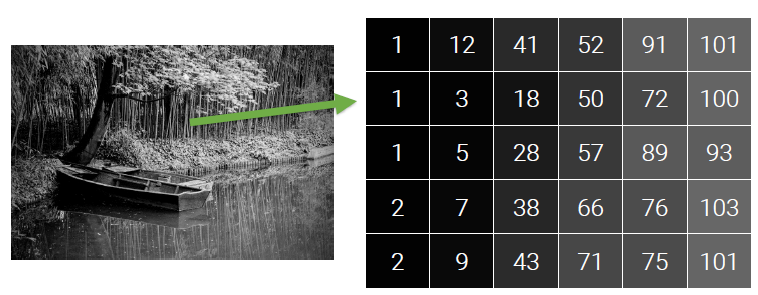
Color Digital Image
Gray-scale과는 다르게 모든 픽셀이 R, G, B 값의 조합으로 특정한 색으로 나타나게 되고, 이를 종합하여 만든 디지털 이미지를 color digital image라고 한다. 3종류의 색에 대응되는 각 채널을 0부터 255까지의 강도를 다르게 주어 조합하기 때문에 픽셀마다 8bit가 필요하게 되고, 이는 총 3개가 필요하기 때문에 각 픽셀에는 24bit가 필요하다. Gray-scale과는 다르게 실제 색을 표현할 수 있기 때문에, 인간의 눈으로 관찰하는 것과 똑같이 현실적으로 표현이 가능하다.

Image Formation Process
이제 카메라가 어떻게 찍고자하는 물체나 풍경을 디지털 이미지로 만들어주는지 그 과정을 알아볼 것이다. 다음의 간단한 구조를 통해서 이야기해보자.
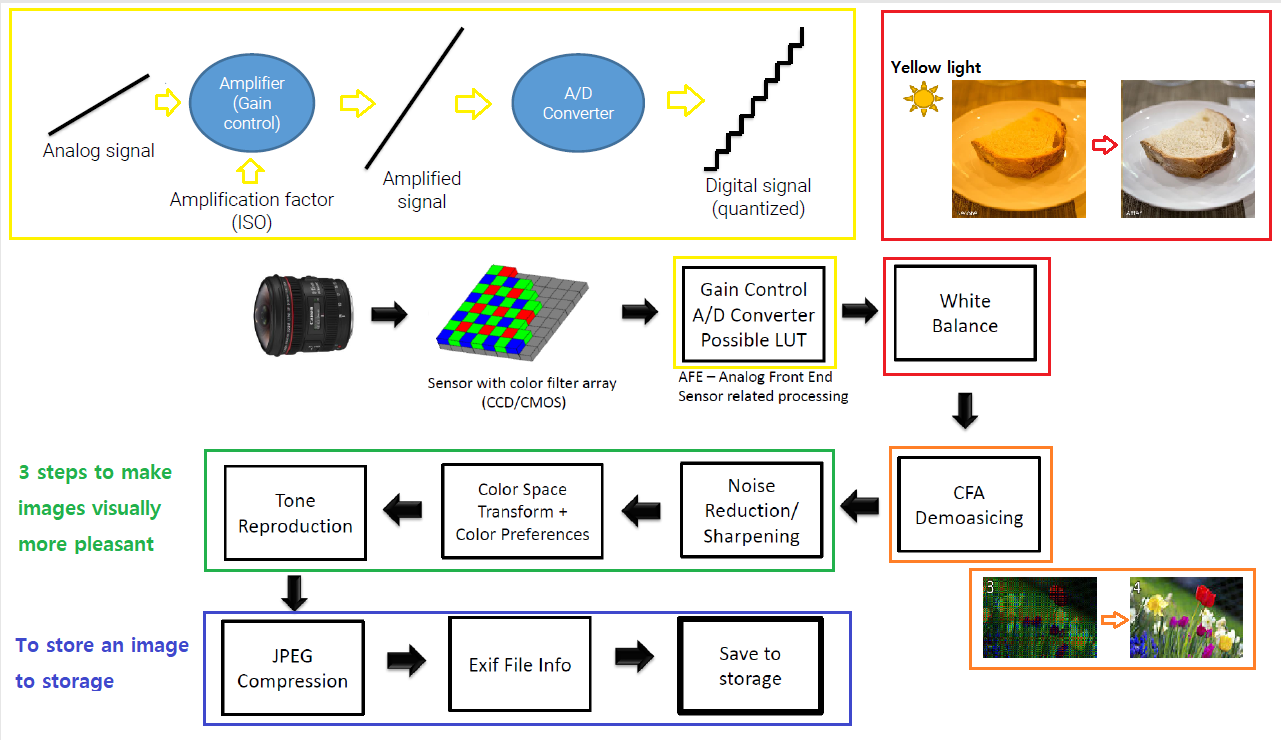
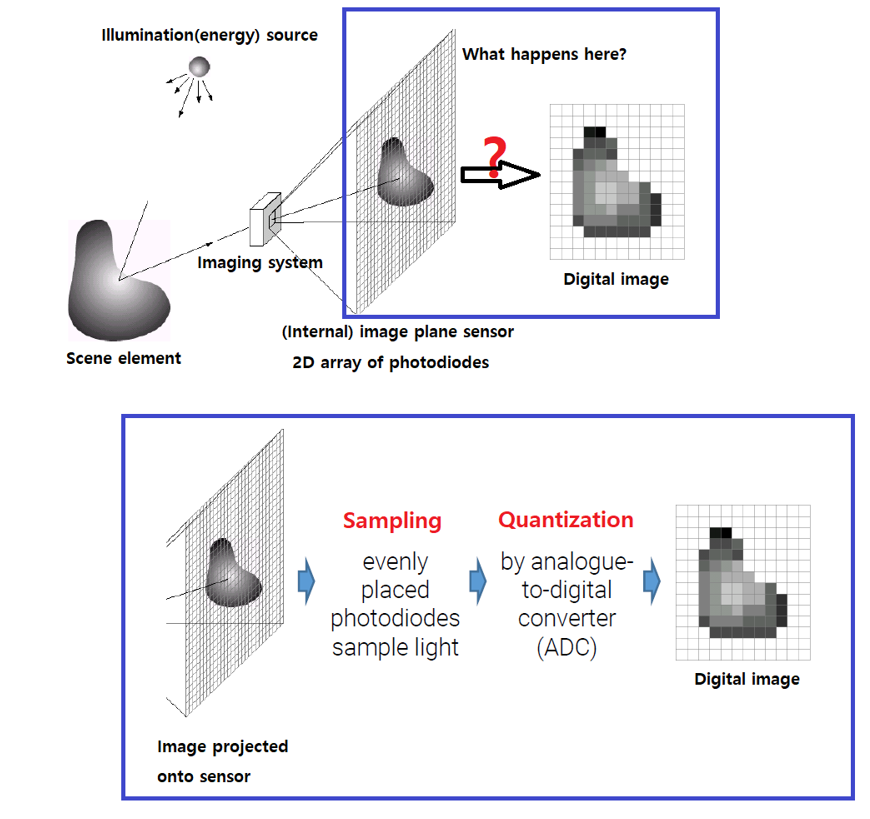 디지털 이미지가 형성되려면 빛이라는 에너지 자원이 필요하게 된다. 이 에너지는 태양이나, 전구를 통해서 빛을 카메라가 찍기 원하는 물체에 제공하게 되면 물체에 도달한 빛은 반사되어 카메라와 같은 imaging system에 도달하게 된다. 그러면 빛을 구성하는 광자가 imaging system 내부의 sensor 받아 image plane에 투영하게 되고 어떠한 처리 과정 후에 디지털 이미지가 생성이 된다.
디지털 이미지가 형성되려면 빛이라는 에너지 자원이 필요하게 된다. 이 에너지는 태양이나, 전구를 통해서 빛을 카메라가 찍기 원하는 물체에 제공하게 되면 물체에 도달한 빛은 반사되어 카메라와 같은 imaging system에 도달하게 된다. 그러면 빛을 구성하는 광자가 imaging system 내부의 sensor 받아 image plane에 투영하게 되고 어떠한 처리 과정 후에 디지털 이미지가 생성이 된다.
여기서 중요한 것은 도대체 어떠한 과정을 통해서 물체에 반사된 빛으로부터의 이미지 정보를 디지털 이미지로 바꾸는 것일까? 우선 photodiode라고 하는 검출기가 광전효과에 의해서 광자를 받아 전자로 바꿔준다. 이러한 과정을 sampling이라고 하여 쉽게 이야기하면 빛에 대한 정보를 얻는다고 생각하면 된다. 그리고 noise가 존재하거나 연속적인 이러한 정보들을 quantization을 통해서 아날로그 정보를 디지털 정보로 바꿔준다. 이 역할은 converter 등이 수행해줘서 디지털 값으로 바꾸게 되어 디지털 이미지를 생성하는 것이다.
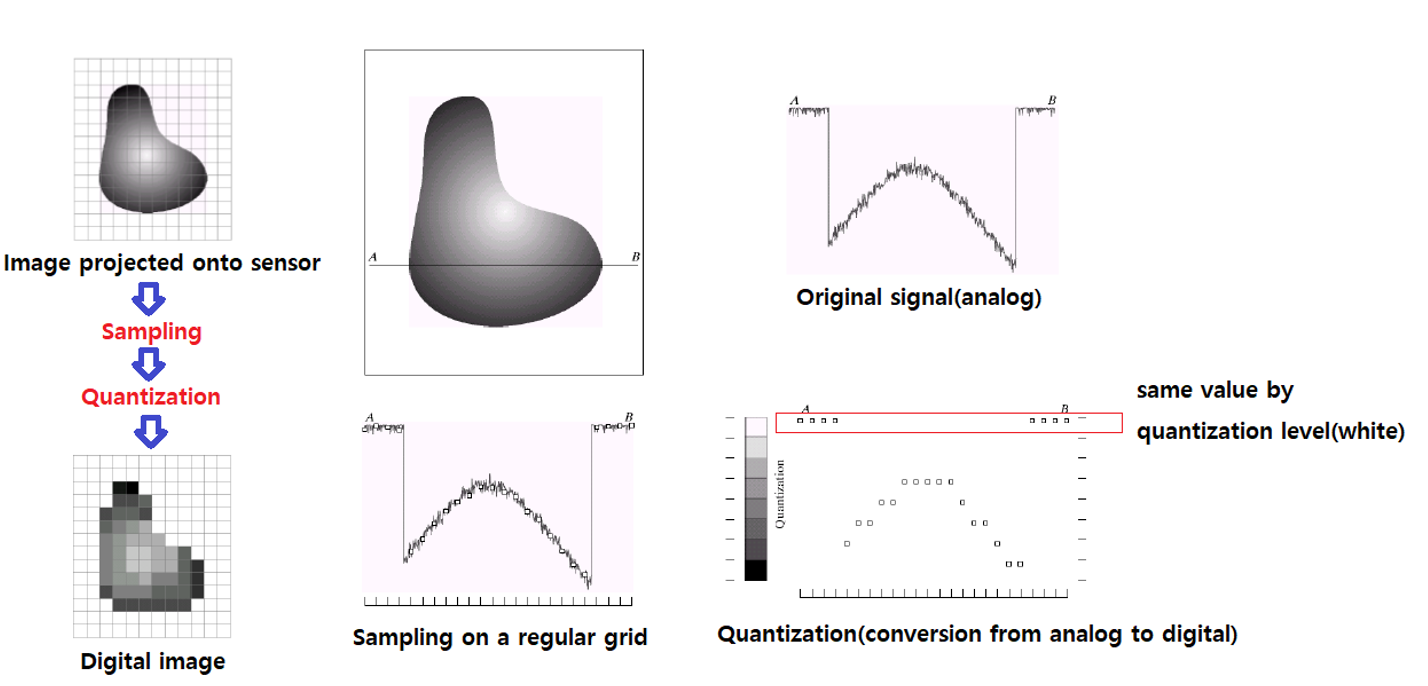 조금 더 자세하게 이 과정을 보면 우선 타겟으로하는 물체에서 빛이 반사되어 오면 어느정도의 depth 정보를 알게 되는데, 이때 가로로 선을 그린다고 생각하고 signal을 sampling하면 지저분하고 연속적인 값들이 추출이 될 것이다. 이 과정을 gray-scale이라고 하면 0 ~ 255까지의 강도로 quantization을 진행하여 이를 2D array에 픽셀 값으로 바꿔주게 된다. 그러면 우리는 연속적인 값이라 하더라도 이산적인 디지털 값으로 전환이 되어 이미지를 표현할 수 있게 되는 것이다.
조금 더 자세하게 이 과정을 보면 우선 타겟으로하는 물체에서 빛이 반사되어 오면 어느정도의 depth 정보를 알게 되는데, 이때 가로로 선을 그린다고 생각하고 signal을 sampling하면 지저분하고 연속적인 값들이 추출이 될 것이다. 이 과정을 gray-scale이라고 하면 0 ~ 255까지의 강도로 quantization을 진행하여 이를 2D array에 픽셀 값으로 바꿔주게 된다. 그러면 우리는 연속적인 값이라 하더라도 이산적인 디지털 값으로 전환이 되어 이미지를 표현할 수 있게 되는 것이다.
Color Filter Array(CFA)
우리는 흔히 화소, 픽셀, 해상도 등에 대해서 많이 들어보았다. 사실 이 단어들은 같은 것을 말하게 된다. 화소의 수가 많으면 화질이 좋다고 알고 있을 것이지만, 사실 화소의 수는 최종적으로 출력하는 물체의 크기를 결정하는 것에 대한 정보이다. 화소의 수가 많으면 화질이 좋다고 볼 수도 있지만, 그보다는 화소의 수가 많다는 것은 더욱 큰 크기의 출력이 가능하다는 것을 말한다. 가령 Full HD 영상의 경우 총 화소의 수는 1,920 x 1,080 = 2,073,600 화소이며, 이보다 나은 영상으로 4K UHD를 사용하게 되면 총 화소의 수는 3,840 x 2,160 = 8,294,400 화소가 되어 Full HD 화소보다 약 4배 정도 더 크게 된다.
그래서 우리는 흔히 이런 영상들에 대해서 R, G, B 색을 감지할 수 있는 화소가 200만개, 800만개 포함이 된 이미지 센서를 사용하는 것으로 생각할 수 있다. 하지만 실제로는 각 화소는 실제로는 color 정보를 감지하는 것이 아니라 단지 흑과 백의 밝기만을 감지하게 된다. 이 화소 위에 특정한 color 정보만을 투과시키는 일종의 color filter가 결합이 되어 color가 만들어지게 되는데, 이때 결합되는 color filter들의 array를 color filter array(CFA)라고 한다.
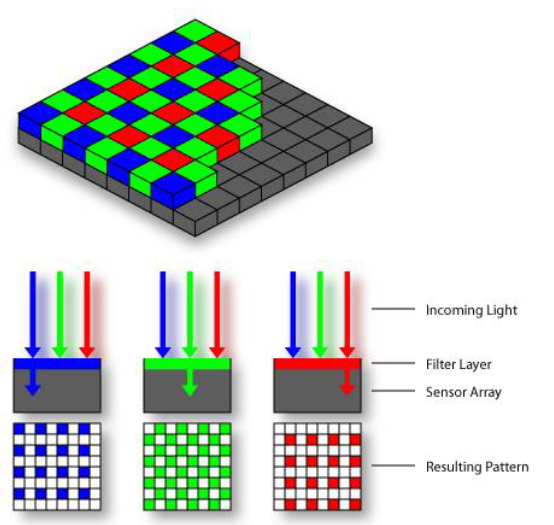 위의 사진처럼 아래에는 실제로 색을 담지 못하는 photodiode가 광자를 잡기 위해서 존재하고, 이 위에 R, G, B 중 하나의 photodiode를 결합하여 붙여놓게 된다. 여기서 초록색의 filter가 더 많은 이유는 단순하게 인간의 눈이 초록색에 더욱 sensitive하기 때문이다.
위의 사진처럼 아래에는 실제로 색을 담지 못하는 photodiode가 광자를 잡기 위해서 존재하고, 이 위에 R, G, B 중 하나의 photodiode를 결합하여 붙여놓게 된다. 여기서 초록색의 filter가 더 많은 이유는 단순하게 인간의 눈이 초록색에 더욱 sensitive하기 때문이다.
전통적으로 R, G, B filter들은 일정한 패턴을 통해서 filter를 만들게 되는데, 인간의 눈이 초록색에 민감하여 G filter의 비중을 높여 만든 filter를 Bayer filter라고 한다. R과 B가 25% 존재하고, 나머지 50%는 G로 구성되어 있는 이 filter는 가장 대표적인 filter이다. 이는 아래에서 예시로 사용 될 것이다.
CFA Interpolation(Demosaicing)
여기서 이상한 점을 생각할 수 있을 것이다. 디지털 이미지 상에서 각 픽셀은 R, G, B의 정보를 전부 가지고 색상을 표현하게 되는데, 이제와서는 실제로는 이미지 센서가 각 필셀에서 R, G, B 중 어느 한 색만을 감지한다고 이야기하는 것일까. 그 이유는 바로 각 픽셀마다 주변 픽셀의 생상 값을 기반으로 interpolation하여 색을 구성하기 때문이다. 이 방법을 CFA interpolation, 혹은 demosaicing이라고 한다. 방법은 여러가지가 있을 수 있지만, 간단한 방법을 이야기해보려고 한다.
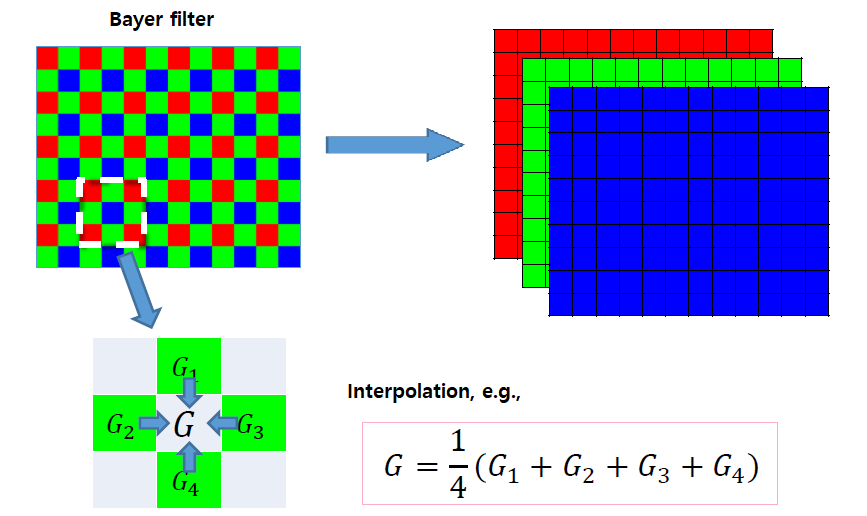 직관적인 방법으로 bilinear interpolation을 이야기할 것이다. 위의 박스가 쳐진 9개의 픽셀 조합이 있다. 가운데 파란색의 픽셀을 표현하기 위해서 상하좌우로는 초록색의 픽셀이 존재하고 대각 방향으로는 빨간색의 픽셀이 존재한다. 그러면 우리가 원하는 픽셀은 주변부의 같은 색의 픽셀을 더해서 그 개수만큼 나눠준 값으로 표현할 수 있다. 그렇게 R, G, B의 값을 통해서 하나의 픽셀을 하나의 특정 색상으로 표현하는 것이다.
직관적인 방법으로 bilinear interpolation을 이야기할 것이다. 위의 박스가 쳐진 9개의 픽셀 조합이 있다. 가운데 파란색의 픽셀을 표현하기 위해서 상하좌우로는 초록색의 픽셀이 존재하고 대각 방향으로는 빨간색의 픽셀이 존재한다. 그러면 우리가 원하는 픽셀은 주변부의 같은 색의 픽셀을 더해서 그 개수만큼 나눠준 값으로 표현할 수 있다. 그렇게 R, G, B의 값을 통해서 하나의 픽셀을 하나의 특정 색상으로 표현하는 것이다.
 이러한 CFA를 통해서 우리가 사진을 찍기 원하는 곳의 물체나 풍경으로부터 정보를 받아들여서 디지털 이미지를 생성하게 되는 것이다.
이러한 CFA를 통해서 우리가 사진을 찍기 원하는 곳의 물체나 풍경으로부터 정보를 받아들여서 디지털 이미지를 생성하게 되는 것이다.
Camera ISP
이제부터는 ISP에 대해서 알아보려고 한다. ISP라는 것은 Image Signal Processing의 약자로서 카메라의 센서로부터 들어오는 raw 데이터를 가공하는 전반적인 이미지 프로세싱의 과정이다.
Camera Imaging Pipeline for JPEG