[계산사진학] Image Synthesis & Generation - GAN Based Image Manipulation
Computational Photography

Image Completion
Image editing, image manipulation에도 deep learning 기반의 연구들이 많이 존재한다. Image completion도 이와 비슷한 예제이고, image inpainting, holl filling과 동일한 이름이다.
Globally and Locally Consistent Image Completion
Image inpainting에 대해서 여러 deep learning method들이 제안되어 오고있다. 2017년도에 "Globally and Locally Consistent Image Completion"이라는 논문에서 deep learning 기반의 방법이 제안되었으며, 이 아이디어는 정말로 간단하다.
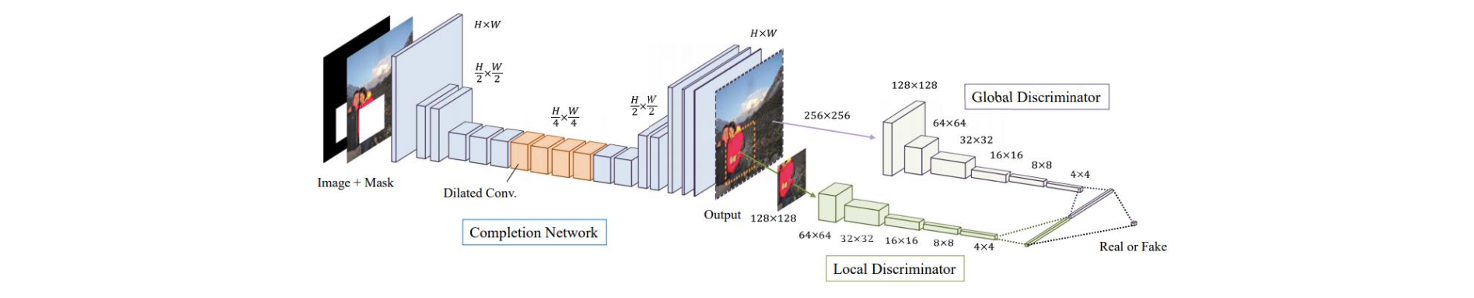 위와 같은 convolutional neural network는 2개의 input image를 사용한다. 하나는 구멍이 뚫린 image이고 다른 하나는 구멍의 위치를 가리키는 mask이다. Neural network는 구멍이 채워진 output image를 예측하기 위해서 학습을 진행한다. 여기에 GAN의 아이디어를 사용해서 generator와 discriminator를 동시에 사용한다. 특히 discriminator의 경우 2개를 사용하는데 하나는 local 용으로, 다른 하나는 global 용으로 사용한다.
위와 같은 convolutional neural network는 2개의 input image를 사용한다. 하나는 구멍이 뚫린 image이고 다른 하나는 구멍의 위치를 가리키는 mask이다. Neural network는 구멍이 채워진 output image를 예측하기 위해서 학습을 진행한다. 여기에 GAN의 아이디어를 사용해서 generator와 discriminator를 동시에 사용한다. 특히 discriminator의 경우 2개를 사용하는데 하나는 local 용으로, 다른 하나는 global 용으로 사용한다.
구멍이 뚫린 image의 경우 매우 부자연스러울 것이고, 구멍이 채워진 image는 자연스러울 것이다. 그래서 구멍이 없는 image를 여러개 모아 adversarial learning을 통해서 neural network를 학습시키게 된다. 그래서 global discriminator는 image를 받아서 real image인지 fake image인지 구분하게 된다. 여기서 real image란 구멍이 없는 자연스러운 image를 이야기하고, fake image는 generator의 output image를 말한다. 퀄리티를 개선시키기 위해서 구멍에 대해서 구멍에만 사용이 되는 pixel용으로 local discriminator를 사용한다.
 결과를 보면 구멍이 뚫린 input image랑 비교했을 때 자연스럽게 채워진 것을 볼 수 있다. Inpainting의 경우 매우 deep learning을 동반한다고 해도 어려운 task이기에 그만큼 자연스러운 결과를 낸다는 것은 대단한 일이다. 만약 구멍이 있는 임의의 image에 위에서 제시한 method를 사용하게 되면 매우 실망스러운 결과를 볼 것이다. 대부분의 연구들이 image inpainting 문제를 잘 해결하지 못하고 있다.
결과를 보면 구멍이 뚫린 input image랑 비교했을 때 자연스럽게 채워진 것을 볼 수 있다. Inpainting의 경우 매우 deep learning을 동반한다고 해도 어려운 task이기에 그만큼 자연스러운 결과를 낸다는 것은 대단한 일이다. 만약 구멍이 있는 임의의 image에 위에서 제시한 method를 사용하게 되면 매우 실망스러운 결과를 볼 것이다. 대부분의 연구들이 image inpainting 문제를 잘 해결하지 못하고 있다.
GauGAN
Hole filling 외에도 GAN을 적용하는 여러 분야의 task들이 존재한다. 그 중 하나로 2019년도에 "Semantic Image Synthesis with Spatially-Adaptive Normalization"에서 제안한 GauGAN이 있다. 사용자가 임의로 그림을 그리게 되면 이에 따라 현실 반영된 풍경을 만들어낸다. 여기서는 spatially adaptive denomalization(SPADE) layer를 사용하는데, 이는 AdaIN layer로부터 영감을 받아서 만들어졌다.
여기서는 spatially adaptive denomalization(SPADE) layer를 사용하는데, 이는 AdaIN layer로부터 영감을 받아서 만들어졌다.
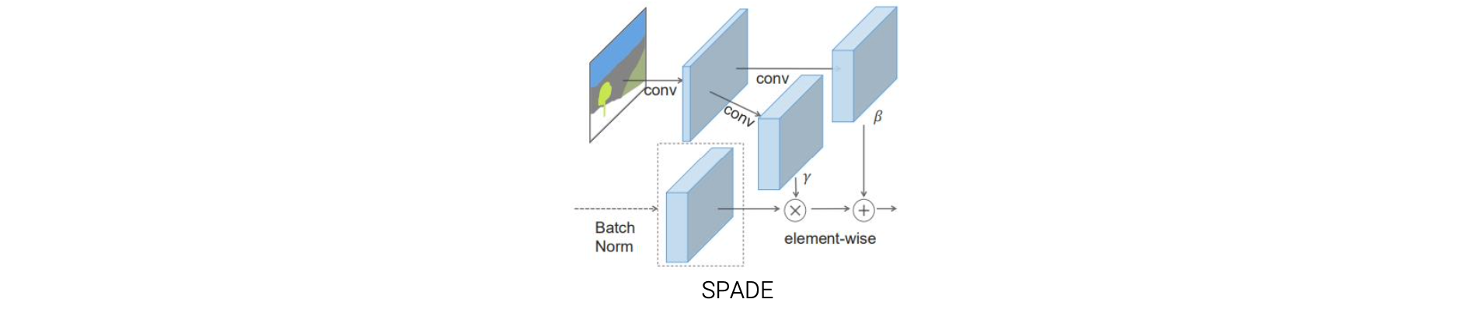 Semantic segmentation label map이 있다고 했을 때 하고자 하는 것은 이 image의 style을 바꾸는 것이다. Style을 바꿈으로써 style transferred result를 만들어낼 수 있다. 정확히 이야기하면 다르긴하지만 style을 바꿔서 자연스러운 image를 만들고 싶은 것이다. 이 논문에서는 AdaIN layer를 수정했다고 봐도 무방하다.
Semantic segmentation label map이 있다고 했을 때 하고자 하는 것은 이 image의 style을 바꾸는 것이다. Style을 바꿈으로써 style transferred result를 만들어낼 수 있다. 정확히 이야기하면 다르긴하지만 style을 바꿔서 자연스러운 image를 만들고 싶은 것이다. 이 논문에서는 AdaIN layer를 수정했다고 봐도 무방하다.
먼저 feature map에 normalization을 적용하고 feature distribtuion을 다시 바꾸게 된다. 그래서 자연스러운 image로 최종적으로 바꾸게 된다.
GAN Inversion
DCGAN에서는 latent vector가 arithmetic property가 있어서 arithmetic operation을 통해서 vector를 계산에 사용할 수 있었다. 이는 latent vector를 조작함으로써 GAN에 의해 만들어진 image의 의미를 부여할 수 있었다. 그러나 오로지 latent vector에만 적용이 되는 내용이라 GAN에 의해 만들어진 image에만 적용할 수 있었다. 만약 현실 세계의 image를 조작할 수 있으면 어떠할까? 현실 세계의 image는 latent vector가 아니다. 그래서 이를 현실 세계의 image에 적용하기 위해서 GAN inversion이라는 것이 소개되었다.
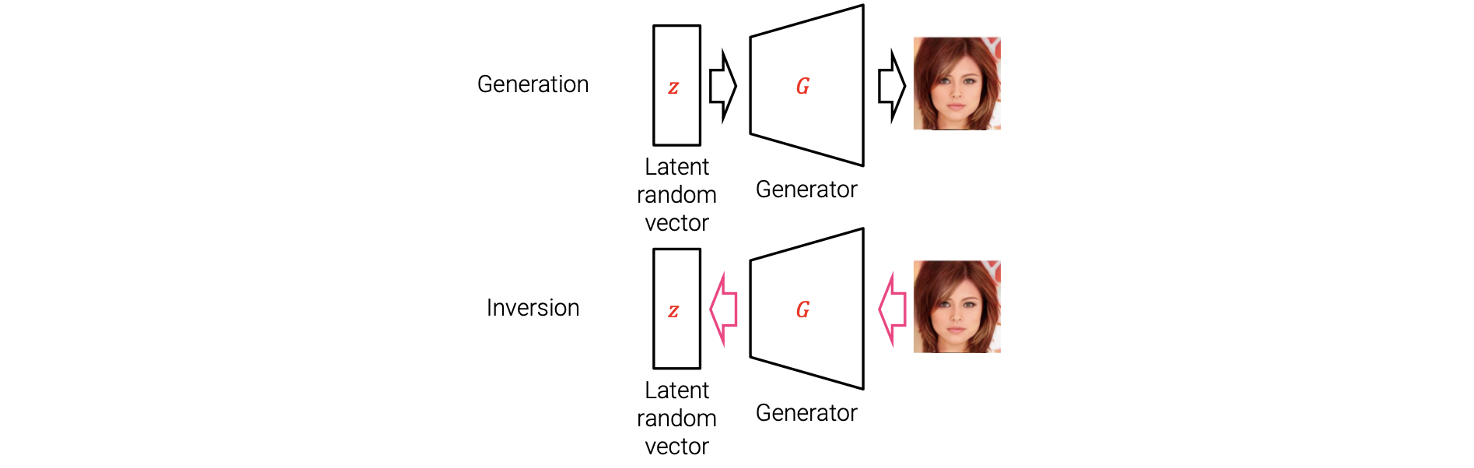 GAN inversion은 target image에 대응되는 latent random vector를 찾는 문제이다. Generator는 latent random vector로부터 fake image를 만들어낸다. 반면, GAN inversion은 이 과정을 반대로 생각하면 된다. 그래서 target image로부터 latent random vector를 찾게 된다.
GAN inversion은 target image에 대응되는 latent random vector를 찾는 문제이다. Generator는 latent random vector로부터 fake image를 만들어낸다. 반면, GAN inversion은 이 과정을 반대로 생각하면 된다. 그래서 target image로부터 latent random vector를 찾게 된다.
Image2StyleGAN
Fake image 에서 target image 를 빼서 loss function에 사용해서 최소로 만들고자 하면 이 문제를 풀 수가 있다. 이렇게 간단하게 GAN inversion을 수행할 수 있다. 또 다른 방법으로 image2styleGAN에서 styleGAN을 기반으로 GAN inversion을 수행할 수 있다. 이 방법은 2019년도에 "Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space?"라는 논문에서 제안되었다. 이 논문에서는 optimization-based approach를 사용했으며, energy function을 최소로 만들고자 했다.

Semantic Photo Manipulation with a Generative Image Prior
2019년도에는 "Semantic Photo Manipulation with a Generative Image Prior"라는 논문에서 GAN inversion을 image manipulation에 적용한 연구가 소개되었다.
 이 논문에서는 interative editing system을 제안했고 여기에는 GAN inversion이 사용되었다. Input photo가 있을 때 원하는 개체를 지울 수가 있다.
이 논문에서는 interative editing system을 제안했고 여기에는 GAN inversion이 사용되었다. Input photo가 있을 때 원하는 개체를 지울 수가 있다.
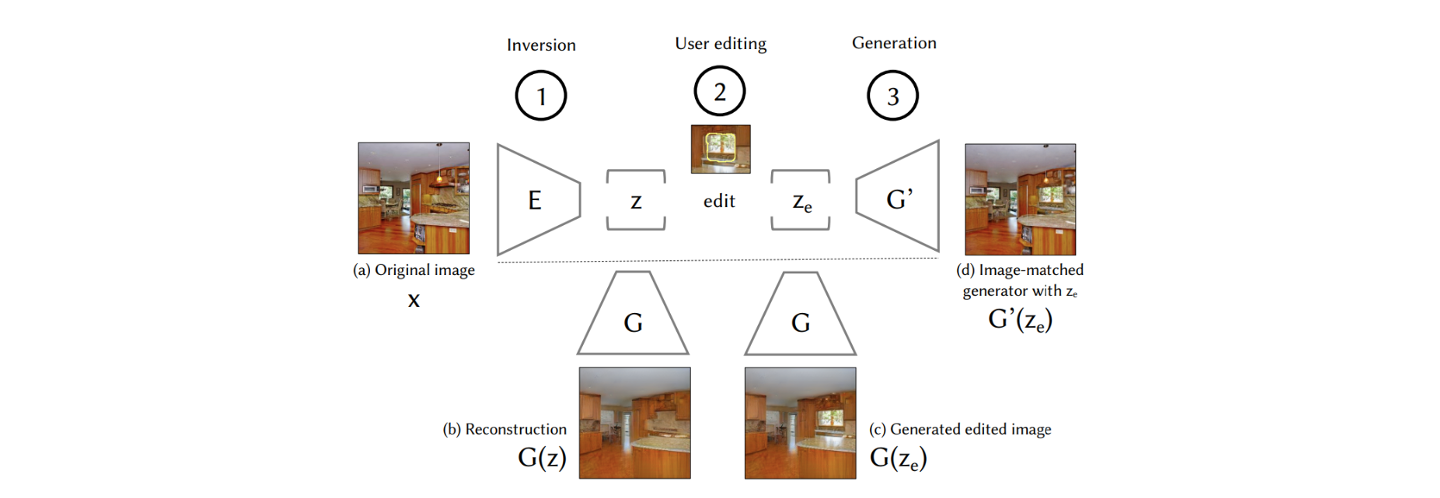 Image 에 먼저 GAN inversion을 이용해서 latent vector 를 찾는다. 그리고 image에서 창문을 만들고 싶다고 했을 때, 창문에 대한 latent vector 를 만들 수 있다. 그리고 이 를 generator에 넣어서 수정 된 image를 만들게 된다. 그러면 결과적으로 창문이 생기는 결과를 볼 수 있다. 이렇게 GAN inversion을 통해서 semantic editing을 수행할 수 있다.
Image 에 먼저 GAN inversion을 이용해서 latent vector 를 찾는다. 그리고 image에서 창문을 만들고 싶다고 했을 때, 창문에 대한 latent vector 를 만들 수 있다. 그리고 이 를 generator에 넣어서 수정 된 image를 만들게 된다. 그러면 결과적으로 창문이 생기는 결과를 볼 수 있다. 이렇게 GAN inversion을 통해서 semantic editing을 수행할 수 있다.
