
GNN Benchmarks
이번에는 GNN을 평가하는데 있어 사용되는 여러 benchmark들에 대해서 알아보고자 한다. 이번에 살펴볼 benchmark들은 여러 machine learning 학회에서 볼 수 있는 논문들에 기반한 것들이다.
TUDataset
 가장 먼저 가장 유명하고 많이 사용되었던 TUDataset에 대해서 알아보고자 한다. 이해하기 쉽게 이 dataset은 GNN의 MNIST라고 생각하면 된다. 해당 dataset은 vertex가 약 20개에서 100개로 구성된 small-scale graph들로 구성되어 있으며, feature도 상대적으로 적다. 이들은 chemical, biological, social network 등으로 구성되어 있으며, GNN의 초기 모델들을 평가하는데 주로 사용되었다. 그러나 요즘에 이 dataset으로 GNN 연구를 평가하고자 한다면 풀고자하는 문제는 좀 더 어려워야할 것이다. 왜냐하면 사람들이 이 dataset은 variance가 매우 크기에 이전에 논문들에서는 cross validation을 이용하여 평균결과를 보여주곤 했다. 아무래도 data의 분포의 variance가 상당히 크다면, 하나의 실험으로는 그 결과가 의미가 없을 것이기에 여러번의 실험 결과를 보여주는 것이 좀 더 타당할 것이다. 따라서 graph dataset에서 high variance인 경우에는 조심해서 평가할 필요가 있다.
가장 먼저 가장 유명하고 많이 사용되었던 TUDataset에 대해서 알아보고자 한다. 이해하기 쉽게 이 dataset은 GNN의 MNIST라고 생각하면 된다. 해당 dataset은 vertex가 약 20개에서 100개로 구성된 small-scale graph들로 구성되어 있으며, feature도 상대적으로 적다. 이들은 chemical, biological, social network 등으로 구성되어 있으며, GNN의 초기 모델들을 평가하는데 주로 사용되었다. 그러나 요즘에 이 dataset으로 GNN 연구를 평가하고자 한다면 풀고자하는 문제는 좀 더 어려워야할 것이다. 왜냐하면 사람들이 이 dataset은 variance가 매우 크기에 이전에 논문들에서는 cross validation을 이용하여 평균결과를 보여주곤 했다. 아무래도 data의 분포의 variance가 상당히 크다면, 하나의 실험으로는 그 결과가 의미가 없을 것이기에 여러번의 실험 결과를 보여주는 것이 좀 더 타당할 것이다. 따라서 graph dataset에서 high variance인 경우에는 조심해서 평가할 필요가 있다.
CiteSeer, Cora, Pubmed (Node-wise) Datasets
 다음은 좀 더 유명한 node-wise dataset이다. 여기에는 cora, citeseer, pubmed 등의 social network가 포함되어 있다. 해당 dataset은 정말로 널리 사용되었기 때문에 새로운 GNN을 만들었다면 이 dataset으로 평가해볼 필요가 있다. 이러한 node-wise dataset을 이야기할 때 흥미로운 부분 중 하나는 사람들이 이 dataset을 이용할 때 고려하는 문제 중 하나가 homophily 관련 문제라는 것이다. GNN은 기본적으로 neighbor 사이의 정보를 모으고자 한다. 그렇기 때문에 만약 GNN이 주변의 비슷한 정보를 모으게 된다면 아무래도 주변의 vertex에 비슷한 label을 부여하는 식으로 prediction을 하게 될 것이다. 그래서 사람들은 각 dataset을 homophily ratio에 따라서 분류해놓곤 했다. 가령 Texas dataset은 homophily ratio가 매우 작아서 대부분 이웃간 다른 label이 부여되었을 것이고, 반대로 Cora는 homophily ratio가 매우 커서 이웃간 비슷한 label이 대부분 할당되었을 것이다. GNN은 기본적으로 homophily dataset에 대한 성능이 heterophily dataset보다 크다. 그래서 GCN만 보더라도 Texas보다 Cora에서 훨씬 좋은 성능을 보여준 것을 확인할 수 있다.
다음은 좀 더 유명한 node-wise dataset이다. 여기에는 cora, citeseer, pubmed 등의 social network가 포함되어 있다. 해당 dataset은 정말로 널리 사용되었기 때문에 새로운 GNN을 만들었다면 이 dataset으로 평가해볼 필요가 있다. 이러한 node-wise dataset을 이야기할 때 흥미로운 부분 중 하나는 사람들이 이 dataset을 이용할 때 고려하는 문제 중 하나가 homophily 관련 문제라는 것이다. GNN은 기본적으로 neighbor 사이의 정보를 모으고자 한다. 그렇기 때문에 만약 GNN이 주변의 비슷한 정보를 모으게 된다면 아무래도 주변의 vertex에 비슷한 label을 부여하는 식으로 prediction을 하게 될 것이다. 그래서 사람들은 각 dataset을 homophily ratio에 따라서 분류해놓곤 했다. 가령 Texas dataset은 homophily ratio가 매우 작아서 대부분 이웃간 다른 label이 부여되었을 것이고, 반대로 Cora는 homophily ratio가 매우 커서 이웃간 비슷한 label이 대부분 할당되었을 것이다. GNN은 기본적으로 homophily dataset에 대한 성능이 heterophily dataset보다 크다. 그래서 GCN만 보더라도 Texas보다 Cora에서 훨씬 좋은 성능을 보여준 것을 확인할 수 있다.
MoleculeNet, ZINK250k, PCQMv2
 이외에도 small molecular dataset으로 MoleculeNet, ZINC250k, PCQMv2 등이 있다.
이외에도 small molecular dataset으로 MoleculeNet, ZINC250k, PCQMv2 등이 있다.
Large-Scale Graphs
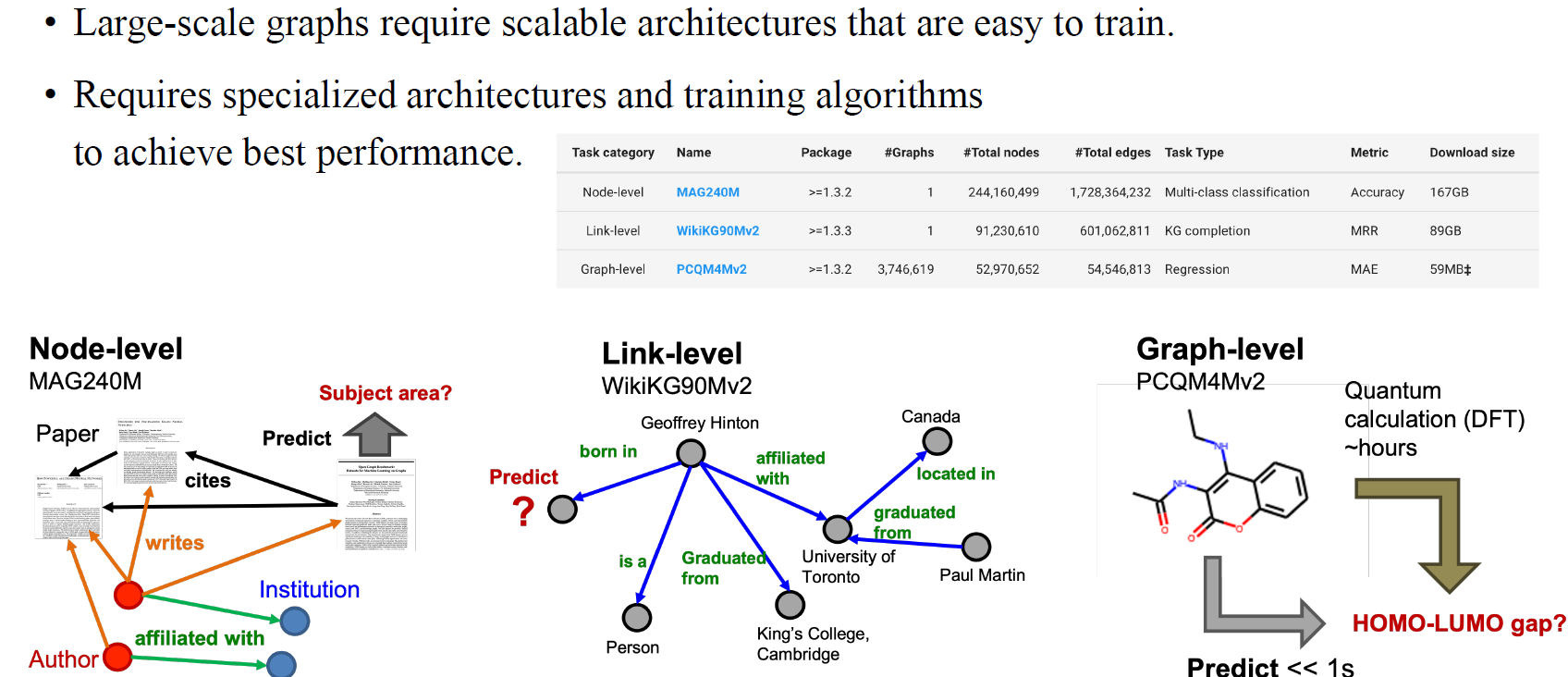 최근 들어서는 large-scale graph들로 구성된 dataset도 많이 등장했다. 이러한 dataset을 평가하기 위해서 많은 scalable GNN이 등장했다. 이전의 dataset과는 다르게 large graph에 동작하는 GNN을 만들어서 평가하곤 한다.
최근 들어서는 large-scale graph들로 구성된 dataset도 많이 등장했다. 이러한 dataset을 평가하기 위해서 많은 scalable GNN이 등장했다. 이전의 dataset과는 다르게 large graph에 동작하는 GNN을 만들어서 평가하곤 한다.
Long-Range Graph Benchmark
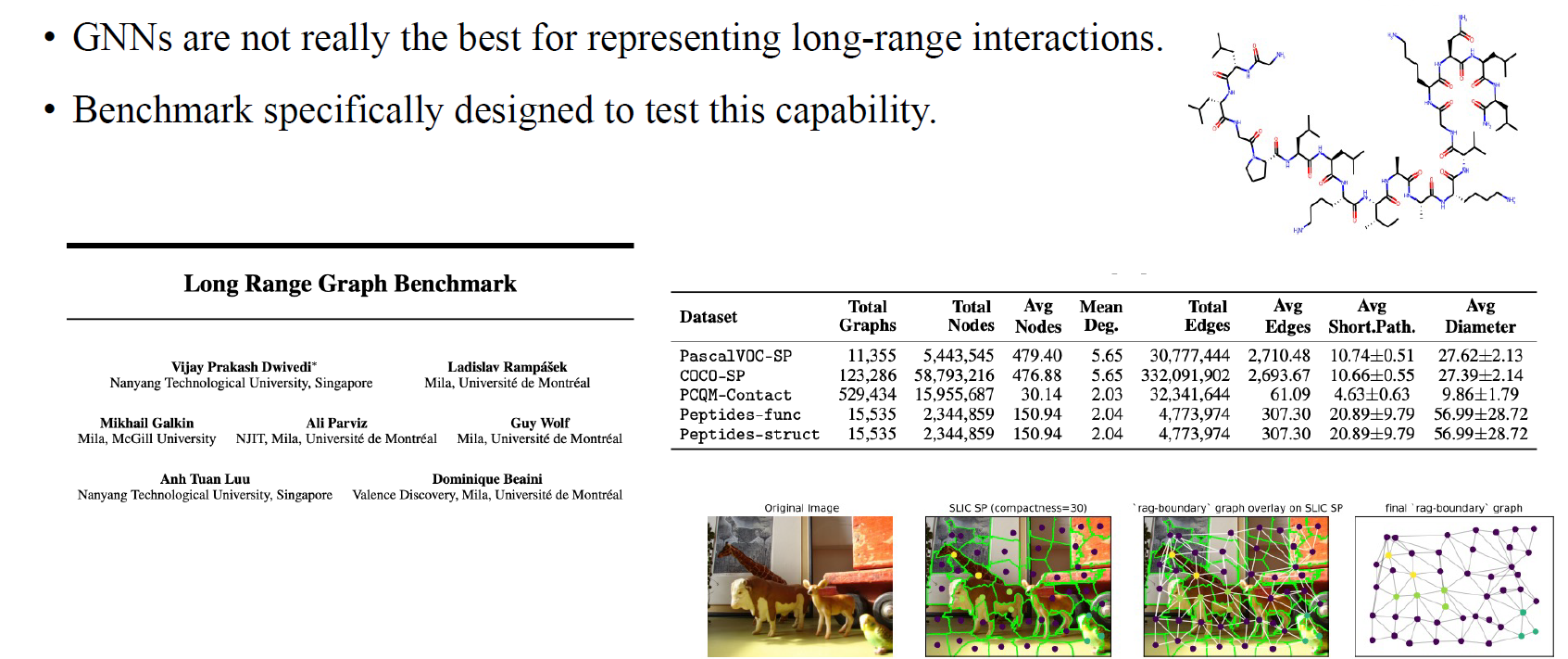 또한 long-range graph benchmark들도 많이 등장하는데, 이 dataset들이 정말로 중요하다. 기본적으로 GNN은 매우 먼 vertex사이의 interaction을 포착하는 것이 쉽지가 않다. 따라서 우리는 특별한 GNN을 사용해서 거리가 먼 vertex간 long-range interaction을 포착할 필요가 있는 것이다.
또한 long-range graph benchmark들도 많이 등장하는데, 이 dataset들이 정말로 중요하다. 기본적으로 GNN은 매우 먼 vertex사이의 interaction을 포착하는 것이 쉽지가 않다. 따라서 우리는 특별한 GNN을 사용해서 거리가 먼 vertex간 long-range interaction을 포착할 필요가 있는 것이다.
Temporal Graph Benchmark
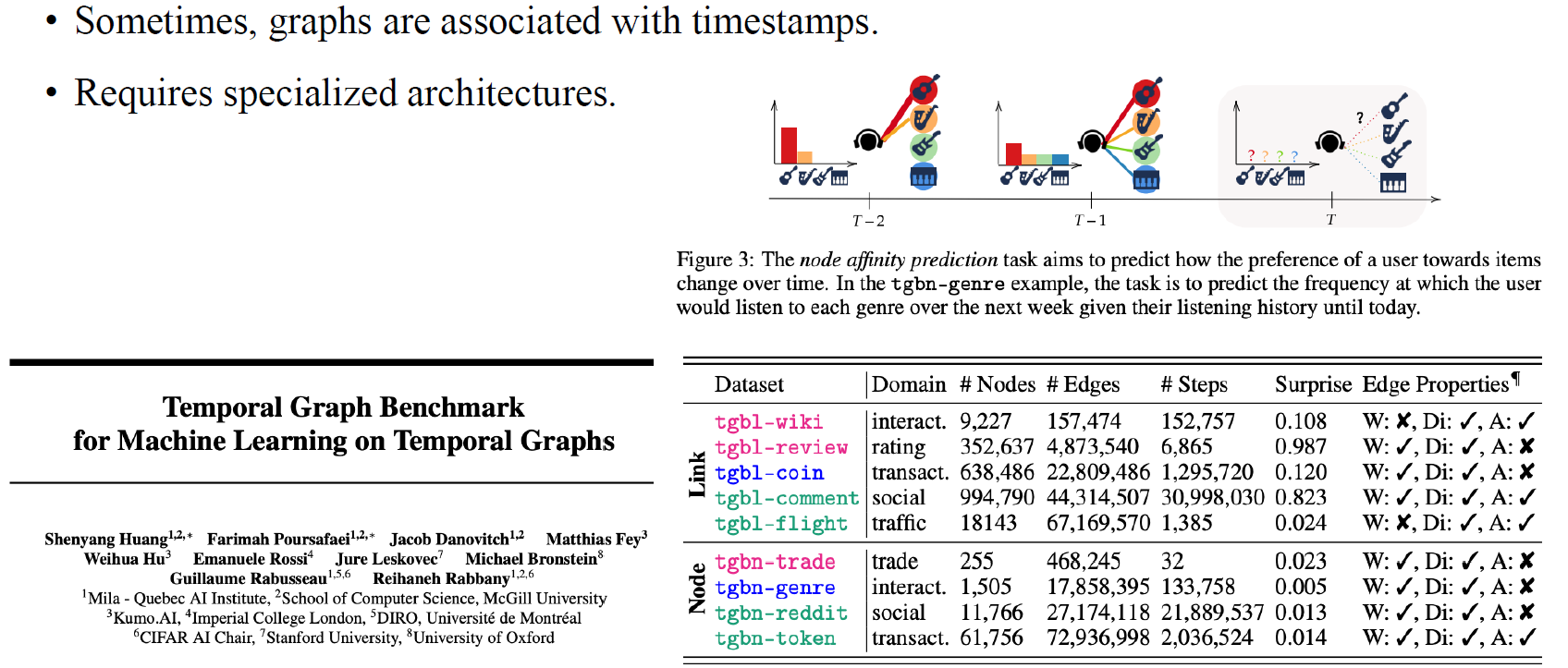 Temporal graph benchmark에서는 각각의 time step에 따라서 graph들이 변하게 된다. 따라서 우리는 temporal graph를 파악할 수 있는 GNN을 만들어야 한다. 실제로 temproal graph의 예시로 bitcoin이 있으며 실제 세계를 반영한 dataset에 가깝다고 볼 수 있다.
Temporal graph benchmark에서는 각각의 time step에 따라서 graph들이 변하게 된다. 따라서 우리는 temporal graph를 파악할 수 있는 GNN을 만들어야 한다. 실제로 temproal graph의 예시로 bitcoin이 있으며 실제 세계를 반영한 dataset에 가깝다고 볼 수 있다.
Algorithm Reasoning
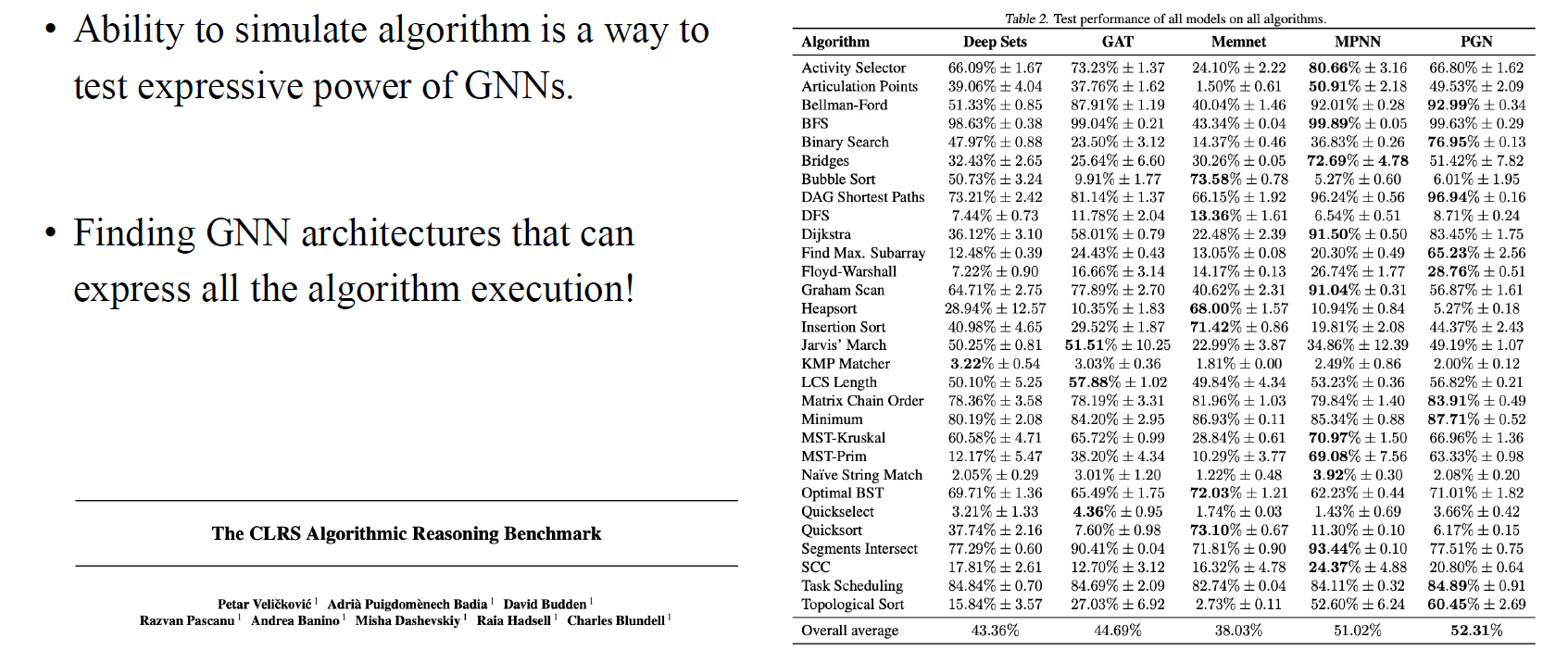 Algorithm reasoning이라는 흥미로분 task가 있다. 이 task가 하는 것은 유명한 algorithm들이 위와 같이 있을 때 해당 알고리즘의 output을 예측하는 능력을 기반으로 해서 GNN의 expressive power를 정량화하는 것이다. 위의 결과를 보면 대부분의 GNN이 shortest path 알고리즘이나 bubble sort 알고리즘 등에 강력한 것을 볼 수 있다.
Algorithm reasoning이라는 흥미로분 task가 있다. 이 task가 하는 것은 유명한 algorithm들이 위와 같이 있을 때 해당 알고리즘의 output을 예측하는 능력을 기반으로 해서 GNN의 expressive power를 정량화하는 것이다. 위의 결과를 보면 대부분의 GNN이 shortest path 알고리즘이나 bubble sort 알고리즘 등에 강력한 것을 볼 수 있다.
Knowledg Graph Reasoning
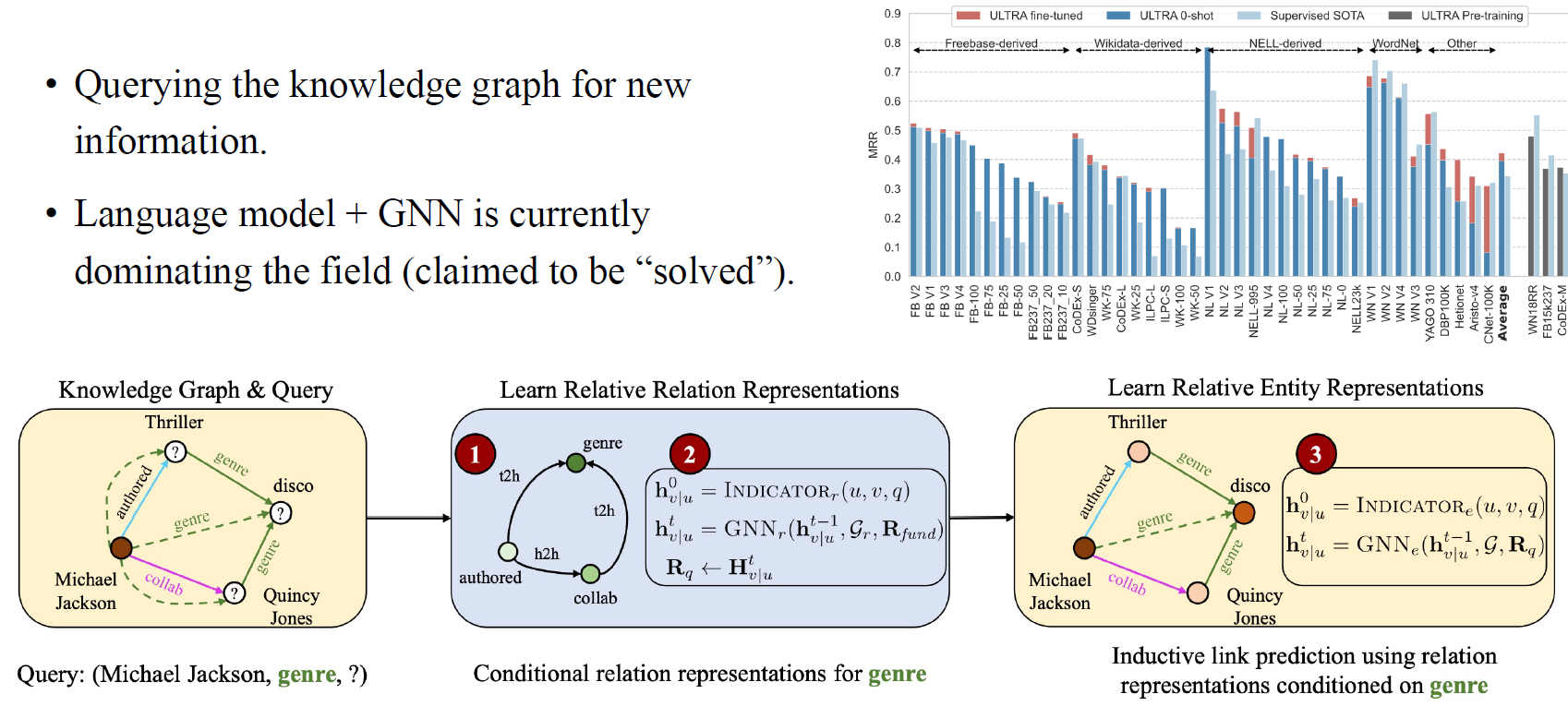 마지막으로 또다른 유명한 task로 knowledge graph reasoning이 있다. 이는 knowledge와 관련된 매우 큰 graph들이 있는 dataset을 기반으로 한다. 예를 들어 Michael Jackson이 있고 thriller, disco, Quincy Jones와 같은 관련 키워드가 있을 때, Michael Jackson이 어떠한 장르와 관련이 있는지 맞추는 task이다. 즉, 우리는 어떠한 특정 query를 통해서 원하는 결과를 도출해내야 하는 것이다. 그래서 사람들은 이러한 knowledge graph를 처리하는 GNN을 개발하려고 시도해오고 있고, 이는 실제로 datamining community에서 굉장히 중요하게 여겨지고 있다. 최근에 이 문제를 풀기 위해서 language model이 GNN과 함께 사용되어 개발되어지고 있다. 그리고 사실 language model이 너무 강력해서 knowledge graph model이 필요없을 정도로 발전해오고 있다.
마지막으로 또다른 유명한 task로 knowledge graph reasoning이 있다. 이는 knowledge와 관련된 매우 큰 graph들이 있는 dataset을 기반으로 한다. 예를 들어 Michael Jackson이 있고 thriller, disco, Quincy Jones와 같은 관련 키워드가 있을 때, Michael Jackson이 어떠한 장르와 관련이 있는지 맞추는 task이다. 즉, 우리는 어떠한 특정 query를 통해서 원하는 결과를 도출해내야 하는 것이다. 그래서 사람들은 이러한 knowledge graph를 처리하는 GNN을 개발하려고 시도해오고 있고, 이는 실제로 datamining community에서 굉장히 중요하게 여겨지고 있다. 최근에 이 문제를 풀기 위해서 language model이 GNN과 함께 사용되어 개발되어지고 있다. 그리고 사실 language model이 너무 강력해서 knowledge graph model이 필요없을 정도로 발전해오고 있다.
