
데이터마이닝 내용은 개인적인 공부를 위해서 정리하는 용도이다. 개인적으로 인터넷을 통해서 공부한 내용을 포함하여 POSTECH의 김원화 교수님의 데이터마이닝 강의를 기반으로 정리할 것이다.
Data
Big data는 전세계적으로 굉장히 중요한 것이 되었다. Data는 모든 것을 알고 있으며 매일 같이 새로운 data는 만들어지고 있다. Big data는 많은 영역에서 등장했고, 약 15년 전부터 database 분야가 computer science 분야에서 굉장히 인기가 많았다. 어떻게 data를 저장하고 효율적으로 이용하는지가 정말 중요하다. 최근 A.I.가 발전하면서 data로부터 의미있는 pattern을 추출하는 과정이 정말 중요해졌다. Big data는 특히 4개의 V로 그 성질을 설명할 수 있다. Volume, Variety, Velocity, Veracity가 바로 4개의 V에 해당한다.
1. Volume - scale of data : 사람들은 매일 많은 양의 data를 접하게 되는데, 이는 회사뿐만 아니라 개인적으로도 자주 접하게 된다. 회사의 경우에는 많은 양의 data를 분석해서 제품과 서비스를 만들어낸다. 그 속에는 많은 양의 data가 전세계 사람들의 정보를 가지고 있기 때문이다.
2. Variety - different forms of data : 사람들이 인지하지 못할 때에도 주변의 device들을 통해서 data가 수시로 만들어지고 있다. SNS에 사진을 업로드하는 순간에도 물론이며, 예기치 못한 상황에도 data는 수집이 되고 사용되어지고 있다.
3. Velocity - analysis of streaming data : 시간이 존재하는 영화같은 data는 streaming이라는 단어를 사용해서 표현하며, 이는 data의 flow를 의미하기도 한다. 노래, 소리 등은 시간적인 개념이 존재하는 data이다.
4. Veracity - uncertainty of data : 많은 양의 data가 존재한다고 하더라도 사실 의미있는 data가 전부일 순 없다. 필요없거나 의미가 없는 data는 사용하지 않아야 하는데, 이는 사람의 판단으로 data의 의미를 잘 생각해봐야 한다.
이에 대해서 좀 더 자세하게 정리해보고자 한다.
1. Volume
How much data is out there? 10년 전에도 매일같이 2.5 quintillion byte의 data가 만들어졌다. 전세계로부터 만들어지는 data의 양은 최근들어 기하급수적으로 증가해오고 있다. 특히, 최근에 들어와서는 fake news 등 불필요하거나 불법적인 내용이 담긴 data들이 많이 생겨나고 있으며, 이러한 data를 청소하는데에도 불필요하게 많은 양의 돈이 사용되고 있다. Data의 양이 많아짐에 따라 단점도 존재하고 장점도 존재하게 되는 것이다. 그리고 이러한 많은 양의 data를 통해서 기업이 성장할 수 있는 계기가 되기도 한다.
2. Variety
Types of data. Data의 양이 많아짐에 따라 그 종류도 다양해지고 있다. Structured data, semi-structured data, unstructured data, multimedia data 등 data는 무수히 많은 형태로 존재하고 있다.
컴퓨터 공학을 전공하게 되면 database table, CSV/TSV file들과 같은 structured data를 자주 접하게 된다. 그리고 살짝 느슨한 구조를 가지는 semi-structured data로는 XML, JSON 등이 존재한다. 특정 구조를 가지지 않는 unstructed data로는 text data가 있고, multimedia data로는 image, video, audio 등이 해당한다. 이외에도 matrix, graph, time-series 등의 형태로 data가 존재하기도 하며, 특히 graph는 edge와 node를 통해서 data가 구성되어 있어서 그 특성상 주변에서 자주 활용되는 data이다.
이렇게 data의 type에 따라서 data를 처리하거나 적용하는 기술들이 전부 다르게 형성된다. 만약 image에 적용이 가능한 특별한 기술이 존재한다고 하면, 이 기술은 아마도 graph에 쉽게 적용하기 힘든 기술일 것이다.
3. Velocity
Streaming data. Velocity는 streaming 형태의 data로 주가, 고속도로 센서, 날씨 정보, 전화, 비디오 등 flow가 존재하는 data들이 주변에 널려있다. 즉, 이러한 data는 시간과 밀접한 관련이 있다고 생각하면 된다.
4. Veracity
Uncertain and imprecise data. 4개의 V 중에서 가장 중요한 V가 바로 veracity이다. 왜냐하면 많은 양의 data를 접하기 때문에 이러한 성질은 중요한 부분으로 작용한다. Data가 믿을 수 있는지 없는지는 작아보여도 큰 영향을 끼치게 된다. 사용하려는 data의 신뢰도는 높아야하며, 또한 veracity는 불확실성과 더불어 noise를 뜻하기도 한다. 즉, 내가 원하는 data가 사실은 어떠한 relation도 존재하지 않을 때 이는 나에게 있어서는 중요하지 않은 data로 분류될 수 있다. 예를 들어 많은 사람들이 찾아보는 wikipedia의 경우 사실 사람들의 손을 거쳐서 data가 입력이 되기 때문에 충분히 의심하고 사용해야 한다.
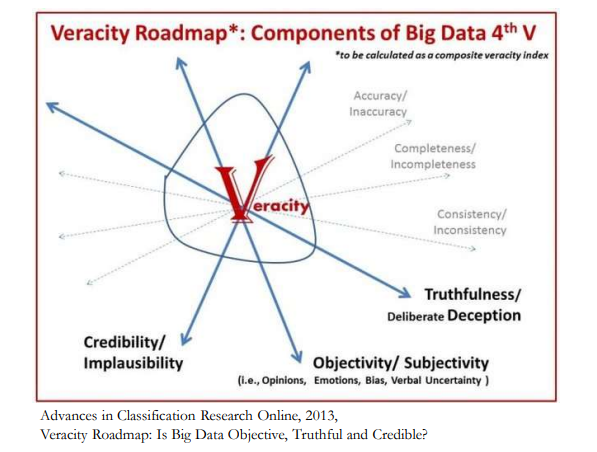 이를 요약하면 data를 사용할 수 있는지 없는지로 말할 수가 있다. 불확실성이 크다면 그 data는 사용하지 않아야 한다.
이를 요약하면 data를 사용할 수 있는지 없는지로 말할 수가 있다. 불확실성이 크다면 그 data는 사용하지 않아야 한다.
Datasets
이렇게 많은 data들은 특정 연구나 제품과 서비스 생산에 사용되기 위해서 하나의 dataset으로 묶일 수 있다. 많은 사람들이 접근할 수 있는 dataset도 요즘들어 많아졌으며, 연구자들을 위해서 특정 data를 활용한 대회도 열어 dataset을 적극 활용할 수 있도록 해준다.
Dataset들은 손쉽게 인터넷을 통해서 구할 수도 있다. Amazon public dataset, data.gov, 공공 데이터 포털, linked data 등을 통해서 원하는 dataset을 사용할 수가 있다. 이 중에서 한국 정부에서는 공공데이터포털을 통해서 한국인을 위한 한국과 관련한 data를 사용할 수 있도록 노력하고 있다. Linked data는 graph data를 다루고 있으며, web page를 예로 들면 다른 web page의 연결 상태를 link로 관리하고 있어 이를 linked data라고 하는 것이다. Database를 봐도 link의 구조로 data를 연결시켜주고 관리한다.
Data Mining
Introduction
Data의 특성, 종류, 활용 분야 등에 대해서 알아보았다면 이제는 data mining이 무엇인지 알아볼 차례이다. 여기서 mining이라는 단어만 따로 보게 되면 보통 채굴이나 채광 등에 사용되는 단어이다. 이러한 단어가 data와 합쳐지게 된다면 그 의미는 채굴하는 대상이 data가 된다는 것이다.
Data mining이라는 기술은 machine learning, A.I., pattern recognition, statistics, database system 등으로 부터 어떠한 아이디어를 가져오는 것을 의미한다. 방금 말한 모든 것은 사실 서로 다른 분야를 설명하고 있다. Data mining에서는 이러한 모든 개념을 통해서 data를 다루게 된다. 옛날 기술은 더이상 최근 등장하는 엄청난 양의 data와 고차원의 data에 적용할 수가 없어졌다. 더불어 정돈되지 않은 data도 물론 옛날 기술로는 data를 다룰 수가 없다.
사람을 설명한다고 생각해봤을 때 이름, 외모, 성격, 국적, 나이 등의 정보를 통해서 해당 사람의 정보를 파악할 수가 있다. 사실 이외에도 무수히 많은 종류의 data들이 존재하고, data의 성질 조차도 완전히 다른 경우가 대부분이다. Big data의 등장으로 data mining이라는 기술이 적극적으로 필요해지게 된 것이다.
Definition
Data mining이란 data로부터 어떠한 사실을 알아내는 기술로 많은 양의 data로부터 흥미로운 pattern 혹은 knowldege를 얻어내는데 사용한다. 앞서 data의 양이 엄청 많은 경우에 대부분은 사용할 가치가 없는 data들로 구성되어 있다고 말했다. 그래서 우리가 필요한 것이 무엇인지 그 흥미로운 정보를 data들로부터 얻을 수 있어야 한다. 여기서 흥미로운 정보라는 것은 사소하지 않으며 내포하고 있는 의미가 있어 이전에는 알지 못하고 잠재적으로 사용할 가치가 높은 것을 말한다. 그리고 data mining은 탐구와 분석이 요구가 되며, 이는 특정 컴퓨터를 동반한 algorithm으로 자동적으로 data를 추출해야 한다. 컴퓨터는 모든 계산이 가능하고 많은 양의 data를 처리하기에 적합하다.
그렇다면 data mining이 아닌 것은 무엇일까? 위와는 반대로 흥미롭지 않은 data에 대해서는 해당하지 않는다. 그리고 knowldge나 pattern이 아닌 그저 단순히 data를 모으는 행위는 data mining에 해당하지 않는다.
Task
Data mining의 task로는 prediction method와 description method가 포함된다.
- Prediction method는 알지 못하거나 미래의 sample들에 대해서 예측할 수 있는 variable들을 사용하는 방법이다. Data로부터 특정 pattern을 학습한다고 했을 때, 새로운 data가 들어온 경우에 data mining이 잘 되었다면 쉽게 새로운 data의 성질을 예측할 수 있을 것이다.
- Description method는 data를 설명하는데 사람이 해석할 수 있는 pattern을 찾을 수 있는 방법이다. Data로부터 평균, 분산 등 쉽게 계산이 가능하고 어떻게 data들이 cluster를 이루고 있는지 등과 같은 것이 바로 description method이다.
 15개의 data sample들이 위와같이 존재한다고 했을 때, clustering의 경우 예를 들어 3개의 cluster로 data sample들을 나누는 것이다. 우측 상단의 decision tree는 새로운 sample이 왔을 때 해당 tree를 통과하면서 특정 결과에 도달하게 된다. 이러한 방식으로 결과를 예측하는데 사용되는 것이 decision tree이다. 혹은 data 자체를 분석해서 특정 variable 사이의 relation을 분석할 수도 있다. Clustering 이후에 어떠한 cluster에도 해당하지 않는 sample이 존재한다면 이를 weird sample이라 부르고, 이를 abnormal sample로 분류하면 된다. Normal을 정의하고 나면 abnormal도 정의할 수 있게되는 셈이다.
15개의 data sample들이 위와같이 존재한다고 했을 때, clustering의 경우 예를 들어 3개의 cluster로 data sample들을 나누는 것이다. 우측 상단의 decision tree는 새로운 sample이 왔을 때 해당 tree를 통과하면서 특정 결과에 도달하게 된다. 이러한 방식으로 결과를 예측하는데 사용되는 것이 decision tree이다. 혹은 data 자체를 분석해서 특정 variable 사이의 relation을 분석할 수도 있다. Clustering 이후에 어떠한 cluster에도 해당하지 않는 sample이 존재한다면 이를 weird sample이라 부르고, 이를 abnormal sample로 분류하면 된다. Normal을 정의하고 나면 abnormal도 정의할 수 있게되는 셈이다.
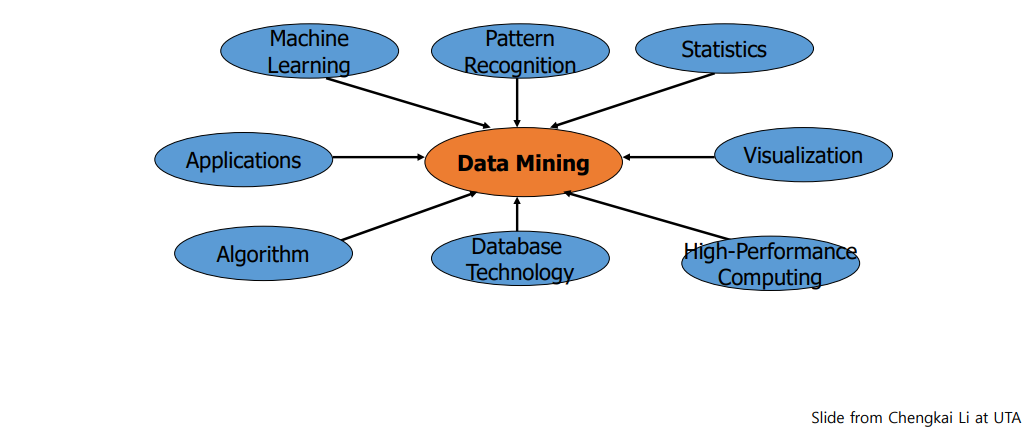 Data mining을 confluence of multiple disciplines(interdisciplinary area)라고도 한다. 이는 많은 영역들로부터 결론을 도출하는 것을 말한다. Data mining에는 machine learning은 물론 statistics, visualization, database technology 등 많은 기술들의 종합물이다. Machine learning은 data로부터 학습하는데 사용되는 기술이고, pattern recognition은 data가 어떠한 pattern을 가지고 있는지에 대한 것이고, statistics을 통해서 통계적인 부분도 필요하다. Visualization은 data가 어떠한 pattern을 가지는지 쉽게 알아볼 수 있고, 빠르게 data를 처리하기 위해서는 high-performance computing 기술이 필요하며, data를 저장하기 위해서는 database 기술이 필요하다. Algorithm도 data로부터 어떠한 pattern이 있는지 알아낼 수 있고, application은 data mining을 통해서 수입이 생길 수도 있음을 말하고 있다.
Data mining을 confluence of multiple disciplines(interdisciplinary area)라고도 한다. 이는 많은 영역들로부터 결론을 도출하는 것을 말한다. Data mining에는 machine learning은 물론 statistics, visualization, database technology 등 많은 기술들의 종합물이다. Machine learning은 data로부터 학습하는데 사용되는 기술이고, pattern recognition은 data가 어떠한 pattern을 가지고 있는지에 대한 것이고, statistics을 통해서 통계적인 부분도 필요하다. Visualization은 data가 어떠한 pattern을 가지는지 쉽게 알아볼 수 있고, 빠르게 data를 처리하기 위해서는 high-performance computing 기술이 필요하며, data를 저장하기 위해서는 database 기술이 필요하다. Algorithm도 data로부터 어떠한 pattern이 있는지 알아낼 수 있고, application은 data mining을 통해서 수입이 생길 수도 있음을 말하고 있다.
이 중에서 machine learning과 pattern recognition, statistics는 밀접한 관련이 있다. 1960년대로 가보면 컴퓨터 공학과 통계학이 서로 같은 것을 하고 있음을 깨달았으며, 이로부터 지금의 A.I.까지 발전하게 된 것이다. 그래서 요즘은 사실 이러한 부분을 디테일하게 나누는 일은 흔하지 않다.
