
Classification
Classification: Definition
Decision tree는 classification을 하기 위한 방법 중 하나로, 우리는 본격적으로 decision tree를 알아보기 전에 먼저 classification에 대해서 알아보려고 한다. Training set으로 record들이 주어지게 되면 각 record는 attribute set 와 class label 로 만들어진 tuple 에 의해서 characterization 될 수 있다. 여기서 는 attribute, predictor, independent variable, input 등으로 부를 수 있고, 는 class, response, dependent variable, output 등으로 부를 수 있다. 이를 기반으로 classification이 하고자 하는 task는 각각의 attribute set 를 미리 정의가 된 class label 중 하나로 mapping하는 model을 학습하는 것이다.
General Approach for Building Classfication Model
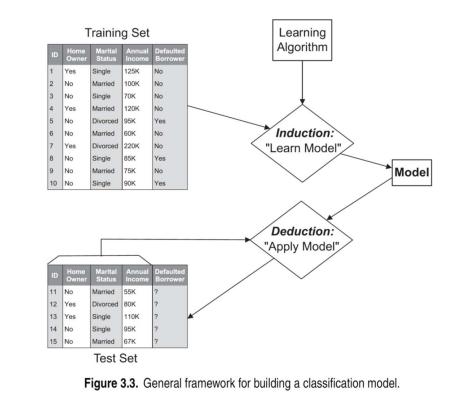 위의 training set에는 각 ID마다 3개의 attribute와 1개의 class label이 존재한다. Classification을 하기 위해서는 이러한 data를 기반으로 model을 학습시켜야 한다. 우리는 learning algorithm을 선택하고 training data를 통해서 model을 학습시킬 것이다. 그렇게 되면 학습이 된 model이 생길 것이고, 여기에 test set을 넣어 각각의 data object에 대하여 class label을 찾을 수 있다. Test set의 경우에는 attribute에 해당하는 만이 채워져 있고, class label에 해당하는 는 question mark(?)로 되어 있어 이 값들을 찾아야 한다. 즉, 와 같이 attribute set을 통해서 class label을 찾는 것이다.
위의 training set에는 각 ID마다 3개의 attribute와 1개의 class label이 존재한다. Classification을 하기 위해서는 이러한 data를 기반으로 model을 학습시켜야 한다. 우리는 learning algorithm을 선택하고 training data를 통해서 model을 학습시킬 것이다. 그렇게 되면 학습이 된 model이 생길 것이고, 여기에 test set을 넣어 각각의 data object에 대하여 class label을 찾을 수 있다. Test set의 경우에는 attribute에 해당하는 만이 채워져 있고, class label에 해당하는 는 question mark(?)로 되어 있어 이 값들을 찾아야 한다. 즉, 와 같이 attribute set을 통해서 class label을 찾는 것이다.
Classification Techniques
위와 같은 classifier를 만들기 위해서는 다양한 method들이 존재하고, decision tree도 이 중 하나인 셈이다. Decision tree와 같이 기본이 되는 classifier들은 다음과 같다.
Base Classfiers :
- Decision Tree based Methods
- Rule-based Methods
- Nearest-neighbor
- Naive Bayes and Bayesian Belief Networks
- Support Vector Machines
- Neural Networks, Deep Neural Nets
이외에도 ensenble classifier가 존재하고, 이는 여러개의 classifier가 있을 때 각 classifier를 통해서 prediction 결과를 도출하고 이를 aggregation을 통해서 최종 결과를 찾아내는 것이다. 이때, 각 classfier를 서로 다른 training method를 통해서 heterogeneous하게 만들어야 한다. 각 classifier가 동일한 의견을 제시하기를 원하지 않기 때문이다. 서로 다른 다양한 의견이지만 적절한 결과를 도출시키고자 하는 것이 ensemble classifier의 목적이다.
Ensemble Classifiers :
- Boosting, Baggin, Random Forests
Decision Tree
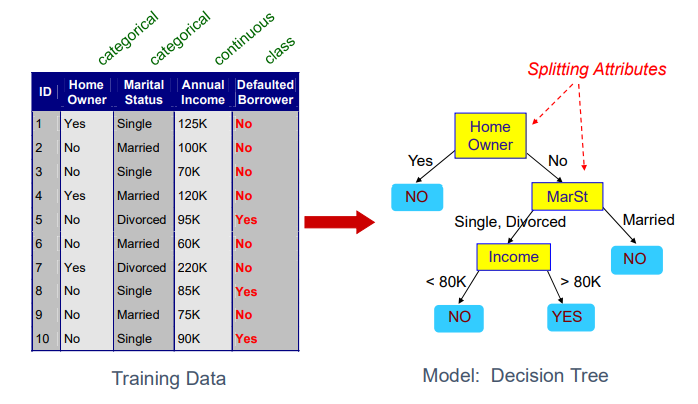 Decision tree는 training set을 기반으로 만든 classifier이다. 위의 경우는 3개의 attribute와 1개의 class prediction이 있는 data이고, 각 attribute는 decision tree에서 question에 대응하게 된다. Decision tree를 보면 노란색의 node들과 파란색의 leaf node들로 구성된 것을 볼 수 있다. 이때 노란색의 node는 training data에서 attribute에 대응하고 있다. 그리고 파란색의 leaf node들을 유심히 보면 각각이 모두 class label로 되어있는 것을 볼 수 있다.
Decision tree는 training set을 기반으로 만든 classifier이다. 위의 경우는 3개의 attribute와 1개의 class prediction이 있는 data이고, 각 attribute는 decision tree에서 question에 대응하게 된다. Decision tree를 보면 노란색의 node들과 파란색의 leaf node들로 구성된 것을 볼 수 있다. 이때 노란색의 node는 training data에서 attribute에 대응하고 있다. 그리고 파란색의 leaf node들을 유심히 보면 각각이 모두 class label로 되어있는 것을 볼 수 있다.
예를 들어 ID 5를 decision tree에 넣으면 home owner가 아니고 divorced하고 income이 80K를 넘기 때문에 우리는 decision tree를 통해서 ID 5의 class label을 "YES"로 예측할 것이다. 사실 현재 decision tree는 좌측의 training data를 기반으로 만들어졌기 때문에 또다시 training data를 이용해 검증을 할 순 없지만, 이후에 test data를 통해서 검증할 것이고 training data에 대해서는 당연히 잘 동작할 것이다.
Apply Model to Test Data
그럼 이제 decision tree를 이용해서 test data에 적용해보도록 할 것이다. 다음의 test data를 decision tree의 가장 상단 node에 있는 attribute부터 확인하면서 내려가면 된다.
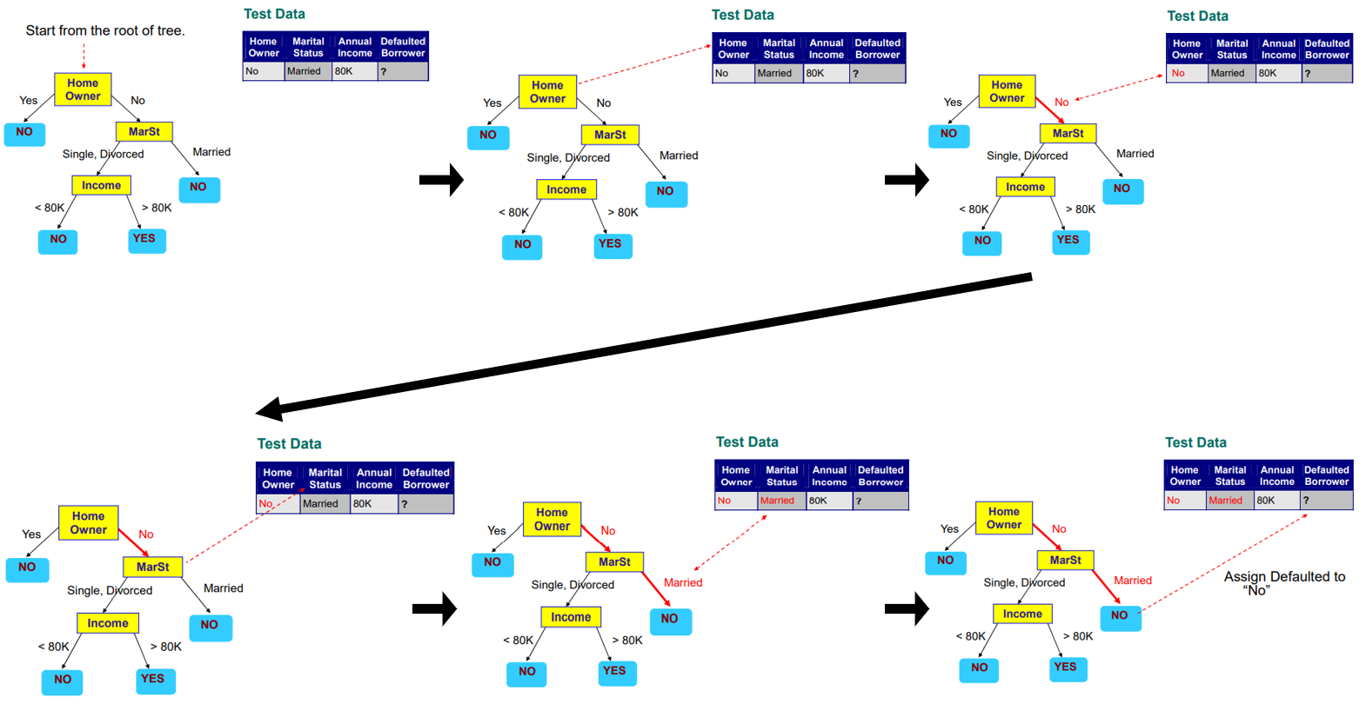 이번 test data의 경우에는 home owner와 marital status만을 통해서 class label을 prediction 할 수 있었다. Training data를 기반으로 decision tree를 만들었기 때문에 annual income의 경우 확인하지 않아도 class label을 판단할 수 있었다.
이번 test data의 경우에는 home owner와 marital status만을 통해서 class label을 prediction 할 수 있었다. Training data를 기반으로 decision tree를 만들었기 때문에 annual income의 경우 확인하지 않아도 class label을 판단할 수 있었다.
Another Decision Tree
이번에는 조금 다른 형태의 tree를 보려고 한다.
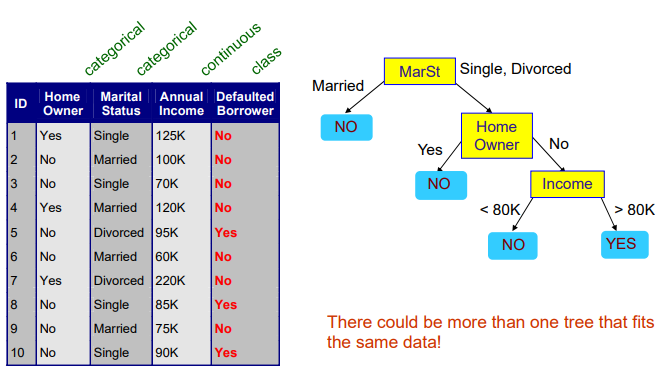 자세히 보면 training data는 위에서 본 것과 동일하다. 하지만 이를 기반으로 만든 우측의 decision tree의 경우 위와는 조금 다른 형태를 보이고 있다. Tree의 경우 형태는 다르지만 똑같은 대답을 만들어낼 수 있다. 2개의 tree 모두 동일한 training data에 대해서 100% accuracy를 보이고 있다. 동일한 data에 동일한 성능인데 tree의 구조가 다른 이유는 무엇일까? 바로 물어보고자 하는 attribute의 순서에 따라 tree의 구조가 달라진 것이다. 첫번째 tree의 경우에는 home owner, marital status, annual income 순서였다면, 두번째 경우에는 marital status, home owner, annual income 순서이다. 즉, attribute의 순서가 tree의 구조를 만든다는 이야기다. 동일한 data에 대해서 적어도 하나 이상의 tree가 존재할 수 있다.
자세히 보면 training data는 위에서 본 것과 동일하다. 하지만 이를 기반으로 만든 우측의 decision tree의 경우 위와는 조금 다른 형태를 보이고 있다. Tree의 경우 형태는 다르지만 똑같은 대답을 만들어낼 수 있다. 2개의 tree 모두 동일한 training data에 대해서 100% accuracy를 보이고 있다. 동일한 data에 동일한 성능인데 tree의 구조가 다른 이유는 무엇일까? 바로 물어보고자 하는 attribute의 순서에 따라 tree의 구조가 달라진 것이다. 첫번째 tree의 경우에는 home owner, marital status, annual income 순서였다면, 두번째 경우에는 marital status, home owner, annual income 순서이다. 즉, attribute의 순서가 tree의 구조를 만든다는 이야기다. 동일한 data에 대해서 적어도 하나 이상의 tree가 존재할 수 있다.
Induction
Tree를 만드는 방법에는 여러가지가 존재한다. 어떠한 algorithm을 사용하는지에 따라 만들어지는 tree의 모양은 달라지게 될 것이다.
- Hunt's Algorithm
- CART
- ID3, C4.5
- SLIQ, SPRINT
General Structure of Hunt's Algorithm
Tree를 만드는 여러 algorithm들 중에서 우리는 가장 기본이 되는 Hunt's Algorithm에 대해서 알아보고자 한다.
 우리는 를 node 에 도달하는 training record들의 set으로 정의하고자 한다. 위와 같이 node가 있으면 training data가 도착할 것이다. 만약 가 class 와 동일한 record를 가지고 있다면, 는 로 label이 붙은 leaf node가 될 것이다. 예를 들어, 의 모든 class label이 Yes라면, 어떠한 data가 node에 도달하든지 간에 class prediction으로 Yes를 부여할 것이다. 또한, 만약 가 하나 이상의 class에 속하는 record를 가지고 있다면, attribute test를 사용해서 data를 더 작은 subset들로 나누고자 한다. 즉, class label의 개수에 따라서 data를 여러개의 branch로 나누겠다는 것이다. 그리고 반복해서 이러한 과정을 각 subset에 적용하면 된다.
우리는 를 node 에 도달하는 training record들의 set으로 정의하고자 한다. 위와 같이 node가 있으면 training data가 도착할 것이다. 만약 가 class 와 동일한 record를 가지고 있다면, 는 로 label이 붙은 leaf node가 될 것이다. 예를 들어, 의 모든 class label이 Yes라면, 어떠한 data가 node에 도달하든지 간에 class prediction으로 Yes를 부여할 것이다. 또한, 만약 가 하나 이상의 class에 속하는 record를 가지고 있다면, attribute test를 사용해서 data를 더 작은 subset들로 나누고자 한다. 즉, class label의 개수에 따라서 data를 여러개의 branch로 나누겠다는 것이다. 그리고 반복해서 이러한 과정을 각 subset에 적용하면 된다.
지금까지 본 tree를 보면 attribute를 기준으로 branch를 나누곤 했다. 그래서 branch를 나누기 위해서는 attribute를 선택해야만 했다. 위의 예시에서는 home owner, marital status, annual income 중에서 순서를 선택해 나누었던 것이다. 을 통해서 다음 node에 도착하게 되면 에 의해서 branch가 나뉘게 되고 다시 다음 node에 도착하게 되면 에 의해서 또 branch가 나뉘게 되는 구조이다. 만약 에 의해서 node에 도착하게 되면 과 같이 branch를 2개로 나눌 것이다. 이렇게 우리는 위와 같이 general procedure에 따라서 tree를 만들어나갈 수 있다. 만약 모든 class label이 homogeneous하다면 leaf node를 만들면 되고, 만약 그렇지 않다면 branch를 만들면 되는 것이다. Branch는 특정 attribute에 따르면 된다. 말로만 하면 어렵기 떄문에 이제부터는 하나하나 예시를 통해서 자세하게 보도록 하자.
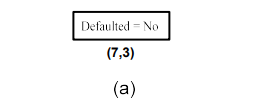 (a) 가장 먼저 위의 training data 를 기준으로 시작할 것이다. Branch를 만들기 전에 class label의 전체 distribution부터 보고자 한다. 총 7개의 No와 3개의 Yes가 있고, 이들은 서로 homogeneous하지 않아서 branch를 split 할 필요가 생겼다.
(a) 가장 먼저 위의 training data 를 기준으로 시작할 것이다. Branch를 만들기 전에 class label의 전체 distribution부터 보고자 한다. 총 7개의 No와 3개의 Yes가 있고, 이들은 서로 homogeneous하지 않아서 branch를 split 할 필요가 생겼다.
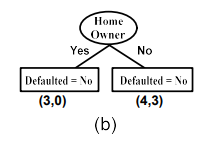 (b) 처음에는 home owner attribute를 따라서 split을 하고자 한다. Yes를 대답한 사람은 로 총 3명이고, No를 대답한 사람은 으로 총 7명이다. 즉, 우리는 과 가 된 상황 속에서 각각 No를 대답한 사람은 3명과 4명이 되었다. 현재 상황에서 class label에 따라 은 전부 No를 대답하여 이 된 것이고, 에서는 4명이 No를 대답하여 이 된 것이다. 은 전부 동일한 class label을 말하고 있으므로 leaf node로 만들어 No를 부여하면 된다. 의 경우에는 homogeneous하지 않아 이 node에 대해서는 다시 branch를 만들어야 할 필요가 있다.
(b) 처음에는 home owner attribute를 따라서 split을 하고자 한다. Yes를 대답한 사람은 로 총 3명이고, No를 대답한 사람은 으로 총 7명이다. 즉, 우리는 과 가 된 상황 속에서 각각 No를 대답한 사람은 3명과 4명이 되었다. 현재 상황에서 class label에 따라 은 전부 No를 대답하여 이 된 것이고, 에서는 4명이 No를 대답하여 이 된 것이다. 은 전부 동일한 class label을 말하고 있으므로 leaf node로 만들어 No를 부여하면 된다. 의 경우에는 homogeneous하지 않아 이 node에 대해서는 다시 branch를 만들어야 할 필요가 있다.
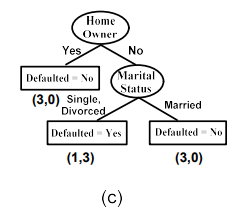 (c) 그래서 이번에는 marital status를 따라서 split을 하고자 한다. Single, divorced는 총 4명이고 married는 총 3명이다. 그래서 전자는 , 후자는 가 되는 것이다. 후자의 경우 모두 No라는 class label을 가지고 있어 homogeneous하다. 그렇기 때문에 married의 경우에 대해서는 다시 leaf node가 되고 class label은 No를 부여하면 된다. 전자의 경우에는 No가 1명, Yes가 3명이라 다시 이 node에 대해서는 branch를 만들어야 한다.
(c) 그래서 이번에는 marital status를 따라서 split을 하고자 한다. Single, divorced는 총 4명이고 married는 총 3명이다. 그래서 전자는 , 후자는 가 되는 것이다. 후자의 경우 모두 No라는 class label을 가지고 있어 homogeneous하다. 그렇기 때문에 married의 경우에 대해서는 다시 leaf node가 되고 class label은 No를 부여하면 된다. 전자의 경우에는 No가 1명, Yes가 3명이라 다시 이 node에 대해서는 branch를 만들어야 한다.
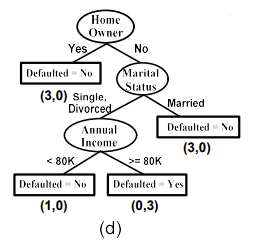 (d) 마지막으로는 annual income을 따라서 split을 하면 되는데, 이 경우에는 모두 continuous value를 가지고 있다. 그래서 threshold를 만들어 branch를 나눠야 하고, 기준은 2개의 branch로 만들었을 때 양쪽 모두 homogeneous한 class label을 가지고 있도록 해야한다. 그래서 80K를 threshold로 설정하게 되면, 은 class label로 No, 은 class label을 Yes로 가지고 있어 양쪽 모두 homogeneous하게 만들 수 있는 것이다. 이러한 방식으로 decision tree를 만들면 된다.
(d) 마지막으로는 annual income을 따라서 split을 하면 되는데, 이 경우에는 모두 continuous value를 가지고 있다. 그래서 threshold를 만들어 branch를 나눠야 하고, 기준은 2개의 branch로 만들었을 때 양쪽 모두 homogeneous한 class label을 가지고 있도록 해야한다. 그래서 80K를 threshold로 설정하게 되면, 은 class label로 No, 은 class label을 Yes로 가지고 있어 양쪽 모두 homogeneous하게 만들 수 있는 것이다. 이러한 방식으로 decision tree를 만들면 된다.
Design Issues of Induction
Decision tree를 induction하는 과정에서 몇가지 design issue가 존재한다.
- 1. How should training records be split?
이 질문은 split을 하는 기준과 관련이 있다. 위의 예시에서는 그저 attribute를 순서대로 선택해서 tree를 만들어나갔다. 하지만 가장 최적으로 split을 하기 위해서는 test condition과 관련한 method를 사용해야 한다. 또한, test condition의 좋고 나쁨을 평가하는 measure들도 존재한다. 우리가 attribute를 선택해서 split을 한다고 했을 때, 어떠한 기준이 존재해야 한다는 것이다.
- 2. How should the splitting procedure stop?
이번에는 splitting procedure를 언제 어떻게 멈춰야하는지와 관련이 있다. 우리는 모든 class label이 완벽하게 분류가 되거나, 100%는 아니더라도 어느정도 완벽하다는 판단이 되었을 경우에 미리 멈춰도 된다. 위에서 살펴본 경우에는 marital status를 기준으로 나누었을 때, 하나의 error가 존재하지만 어느정도 잘 되었다는 판단 하에 멈춘다는 것이다. 이 경우에는 어떠한 data가 해당 node에 도달하든 상관없이 Yes라는 대답을 하겠다고 결정하겠다는 것이다. 90% accuracy를 가지는 tree에서 만족할 수도 있고, 더 나아가 100% accuracy를 가지는 tree를 만들 수도 있다. 하지만 여기서 중요한 점은 90% tree가 simple하고 100% tree가 complex하다는 것이다. 그래서 단순하지만 덜 정확할지, 복잡하지만 더 정확할지에 따른 것은 온전히 tree를 만드는 사람에게 달려있다. 때로는 완벽하진 않아도 간단한 model을 필요로하는 경우가 존재할 것이다. 만약 model이 너무나도 complex하다면 training data에 대해서는 완벽할지라도 test data에서는 accuracy가 많이 떨어질 수 있다. 우리는 이러한 상황을 overfitting이라 부를 것이다.
