
이번에는 multi-modal 중에서 visual data와 audio data를 함께 활용하는 learning에 대해서 알아보고자 한다. 그래서 visual data를 중심으로 audio data를 활용하거나 visual data와 audio data를 합성해서 활용하는 application에 대해서 알아볼 것이다.
Sound representation
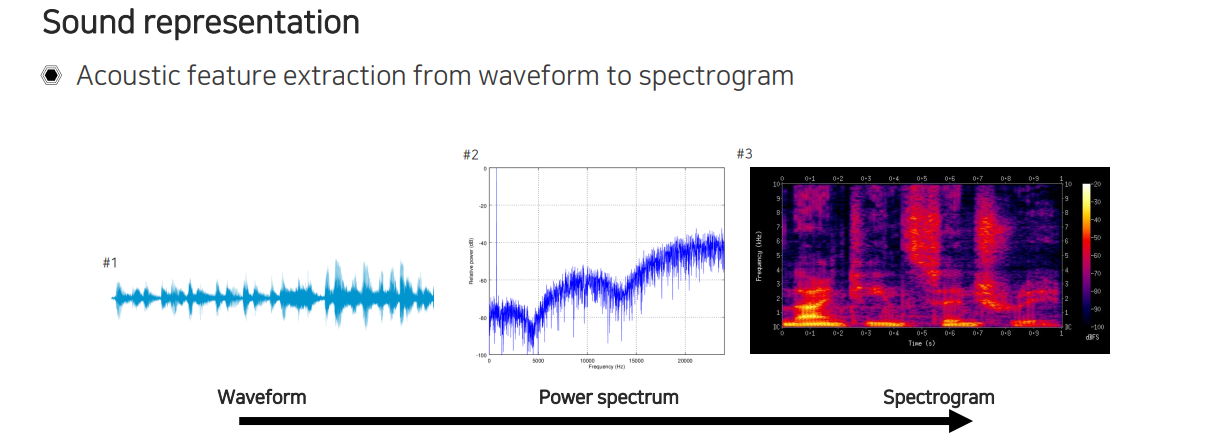 먼저 audio data를 활용하기 위해서 sound data가 어떻게 사용되는지 알아야 한다. 보통 sound feature들은 waveform 형태의 1D signal의 떨림을 기록한 1D vector에서부터 추출된다. 1D vector를 처리해서 spectogram 형태로 만들어 놓은 다음에 여기서부터 이 spectogram을 그대로 활용하거나 또다른 feature를 추출하는 형태로 구현이 된다. Waveform의 경우에는 굉장히 긴 signal에 해당한다. 우리는 이렇게 긴 signal을 오랫동안 관찰해야 하는데, 실제로 중요한 것은 주파수 성분이다. 소리나 음성에서 특징적으로 잘 파악하고 소리를 그대로 듣도록하는 특징들은 모두 주파수로부터 확인할 수 있다. 그렇기 때문에 우리는 audio data에서 주파수를 분석하는 것이 굉장히 중요하다. 이를 위해서 waveform을 power spectrum이라고 하는 주파수 domain으로 옮긴 다음에 분석을 하게 된다. Power spectrum이라 해서 전체 signal을 주파수로 전부 옮겨서 보는 것이 아니라 각 시간다마 주파수 성분이 얼마만큼 있는지 단위 시간마다 주파수 성분을 분석할 수 있도록 만든 것이 바로 spectogram이다. Spectrum을 2D로 time 축으로 쌓은 것을 spectogram이라고 하는 것이다.
먼저 audio data를 활용하기 위해서 sound data가 어떻게 사용되는지 알아야 한다. 보통 sound feature들은 waveform 형태의 1D signal의 떨림을 기록한 1D vector에서부터 추출된다. 1D vector를 처리해서 spectogram 형태로 만들어 놓은 다음에 여기서부터 이 spectogram을 그대로 활용하거나 또다른 feature를 추출하는 형태로 구현이 된다. Waveform의 경우에는 굉장히 긴 signal에 해당한다. 우리는 이렇게 긴 signal을 오랫동안 관찰해야 하는데, 실제로 중요한 것은 주파수 성분이다. 소리나 음성에서 특징적으로 잘 파악하고 소리를 그대로 듣도록하는 특징들은 모두 주파수로부터 확인할 수 있다. 그렇기 때문에 우리는 audio data에서 주파수를 분석하는 것이 굉장히 중요하다. 이를 위해서 waveform을 power spectrum이라고 하는 주파수 domain으로 옮긴 다음에 분석을 하게 된다. Power spectrum이라 해서 전체 signal을 주파수로 전부 옮겨서 보는 것이 아니라 각 시간다마 주파수 성분이 얼마만큼 있는지 단위 시간마다 주파수 성분을 분석할 수 있도록 만든 것이 바로 spectogram이다. Spectrum을 2D로 time 축으로 쌓은 것을 spectogram이라고 하는 것이다.
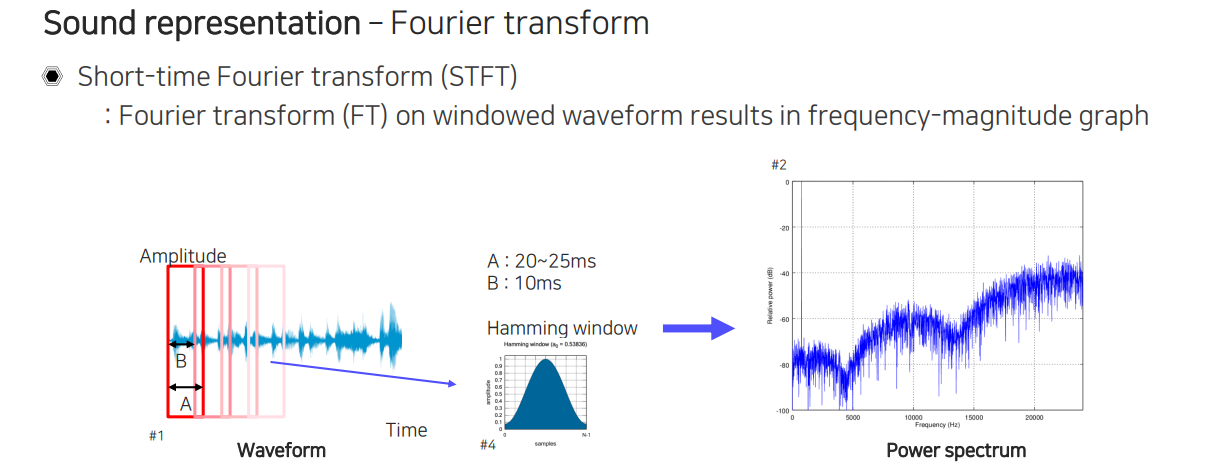 그래서 우리는 먼저 spectogram을 어떻게 만드는지부터 알아보고자 한다. 주파수 분석을 위해서는 Fourier transform이 필요하다. 주파수 분석을 waveform 전체에 대해서 하게 되면 시간 정보는 다 없어지고 주파수 정보만 남기 때문에 전체적인 주파수 성분의 분석을 할 수는 있지만 현재 말하고 있는 내용들을 따라가면서 주파수 분석을 할 수 없게 된다.
그래서 우리는 먼저 spectogram을 어떻게 만드는지부터 알아보고자 한다. 주파수 분석을 위해서는 Fourier transform이 필요하다. 주파수 분석을 waveform 전체에 대해서 하게 되면 시간 정보는 다 없어지고 주파수 정보만 남기 때문에 전체적인 주파수 성분의 분석을 할 수는 있지만 현재 말하고 있는 내용들을 따라가면서 주파수 분석을 할 수 없게 된다.
그래서 고안이 된 방법이 Short-time Fourier transform(STFT)를 적용하는 것이다. 정해진 구간의 window size를 정의하고 window 내에서만 Fourier transform을 하는 것이다. 여기서 window를 정의할 때 끝을 잘라버리게 되면 음성이 뚝 끊긴 것과 같아지게 된다. 이를 자연스럽게 마무리해주기 위해서 Hamming window라는 것을 적용해서 window 구간의 중심점에 있는 것들을 많이 볼 수 있도록 만들고 잘리는 정보인 가장자리에서는 덜 보는 식으로 weight를 적용할 수 있다. 이렇게 Hamming window를 통해서 weight를 준 뒤에 Fourier transform을 적용시키는 방법이 바로 STFT이다. 두번째 특징으로는 끝에 정보 손실이 발생하기 때문에 다음 window를 overlap 시켜서 적용시킨다. 가장자리의 정보를 최대한 놓치지 않기 위해서 overlap을 시켜주는 것이다. 이렇게 각 window마다 Fourier transform을 통해서 power spectrum으로 변환시켜주는 것이다.
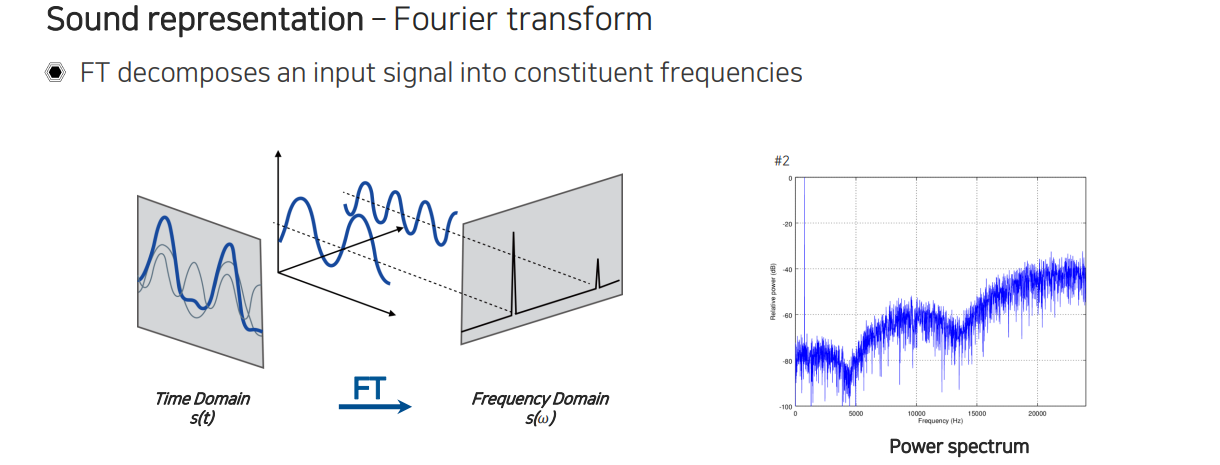 Fourier transform을 통해서 time series의 signal이 들어왔을 때 각 sin 함수마다 얼만큼의 주파수 성분이 있는지를 분석하게 된다. 그래서 각 window마다 각각의 주파수 성분이 얼만큼 포함되어 있는지를 파악할 수 있게 된다.
Fourier transform을 통해서 time series의 signal이 들어왔을 때 각 sin 함수마다 얼만큼의 주파수 성분이 있는지를 분석하게 된다. 그래서 각 window마다 각각의 주파수 성분이 얼만큼 포함되어 있는지를 파악할 수 있게 된다.
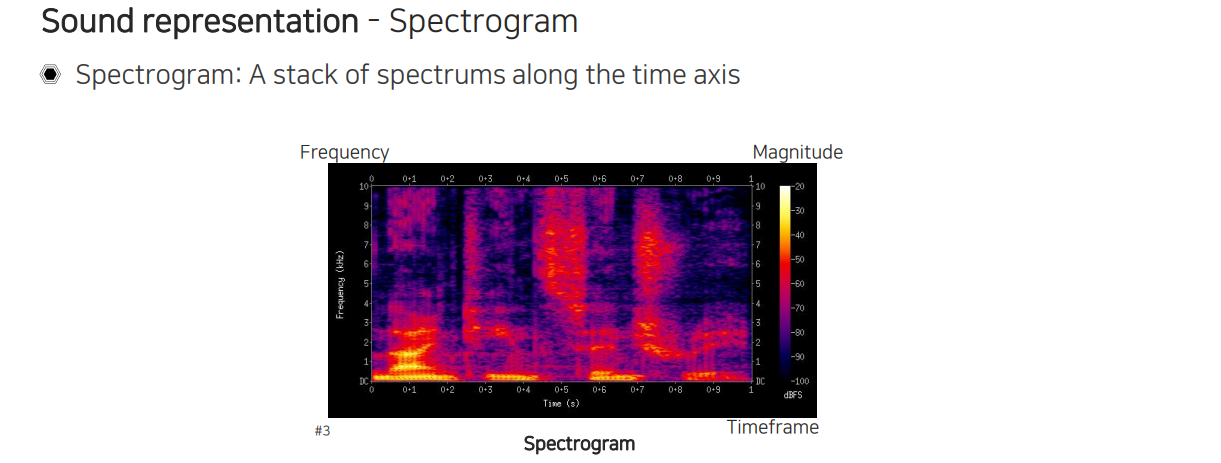 그러면 이제 power spectrum을 이용해서 spectrum들을 쌓아서 spectogram을 만들어줘야 한다. 각 시간마다 window를 움직이면서 한줄씩 끼워 넣어 만들 수 있다.
그러면 이제 power spectrum을 이용해서 spectrum들을 쌓아서 spectogram을 만들어줘야 한다. 각 시간마다 window를 움직이면서 한줄씩 끼워 넣어 만들 수 있다.
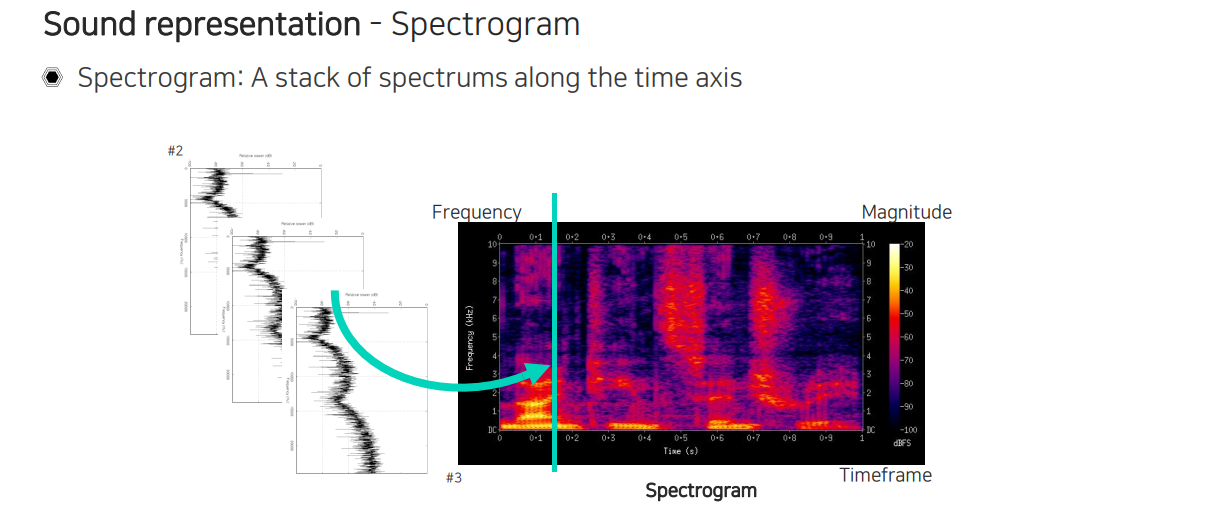 한줄마다 주파수 성분이 들어있는 spectrum들이 slice해서 끼워져 있는 것이다. 그래서 마지막에는 결국 시간과 주파수 축의 2차원 정보를 활용하게 되는 것이다. 이렇게 만들면 image와 비슷한 특성을 가질 수 있게 된다. 물론 축에 대한 물리량이 다르기 때문에 domain knowledge를 사용해서 이후에 network architecture도 디자인해줘야 한다.
한줄마다 주파수 성분이 들어있는 spectrum들이 slice해서 끼워져 있는 것이다. 그래서 마지막에는 결국 시간과 주파수 축의 2차원 정보를 활용하게 되는 것이다. 이렇게 만들면 image와 비슷한 특성을 가질 수 있게 된다. 물론 축에 대한 물리량이 다르기 때문에 domain knowledge를 사용해서 이후에 network architecture도 디자인해줘야 한다.
Joint embedding
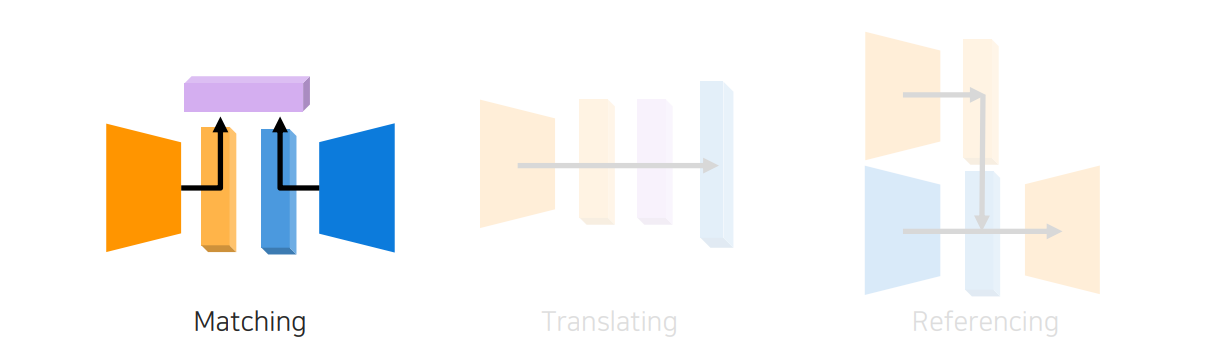 Multi-modal learning을 할 때 visual data와 audio data를 혼합해서 사용한다고 할 때 혼합할 수 있는 방법이 여러가지가 존재한다. 그래서 가장 먼저 살펴볼 방법은 joint embedding을 사용하는 것이다.
Multi-modal learning을 할 때 visual data와 audio data를 혼합해서 사용한다고 할 때 혼합할 수 있는 방법이 여러가지가 존재한다. 그래서 가장 먼저 살펴볼 방법은 joint embedding을 사용하는 것이다.
 먼저 살펴볼 task는 scene recognition으로, sound가 주어졌을 때 해당 sound가 어디서부터 왔는지를 파악하고 classification하는 task이다.
먼저 살펴볼 task는 scene recognition으로, sound가 주어졌을 때 해당 sound가 어디서부터 왔는지를 파악하고 classification하는 task이다.
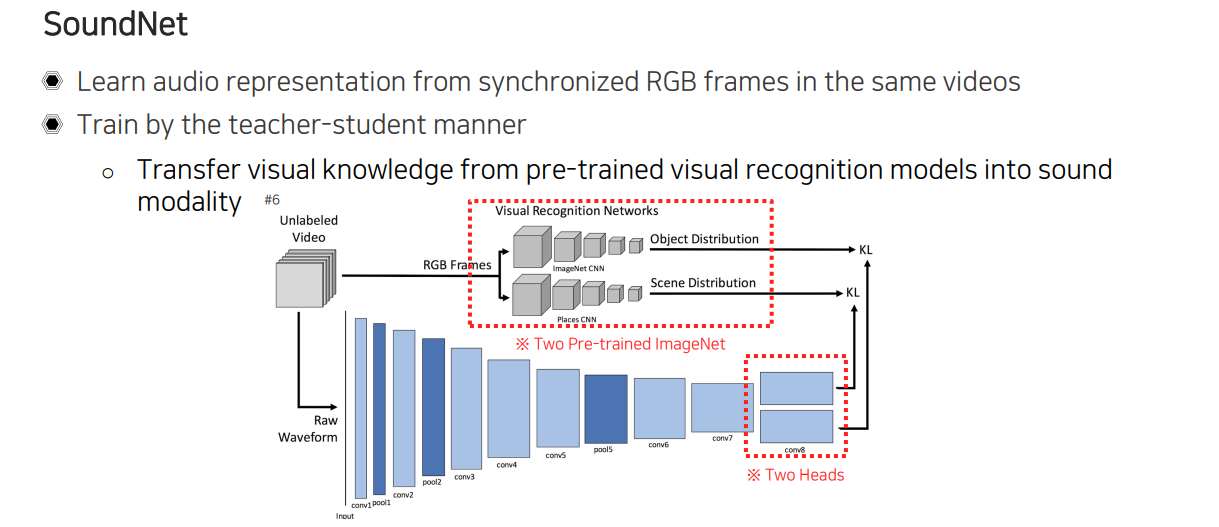 이를 학습하기 위해서 사용된 방법으로 SoundNet이 존재한다. 이 방법은 sound를 미리 정의해놓고 sound에 해당하는 class를 미리 정의해놓고 사람이 annotation을 해서 supervised-learning을 하는 것이 아니라, 여기서는 joint embedding을 학습하려고 하는데 미리 data가 supervision이 없이 학습을 하도록 만들게 된다. 이를 위해서 video를 사용하는데 video에는 RGB frame과 함께 싱크가 맞춰진 audio가 포함되어 있는 특징이 있다. 그래서 video가 주어지면 video에 존재하는 sound를 뽑아오고 CNN을 통해서 sound feature를 뽑은 뒤에 이를 2개의 형태로 표현을 바꿔서 사용하게 된다.
이를 학습하기 위해서 사용된 방법으로 SoundNet이 존재한다. 이 방법은 sound를 미리 정의해놓고 sound에 해당하는 class를 미리 정의해놓고 사람이 annotation을 해서 supervised-learning을 하는 것이 아니라, 여기서는 joint embedding을 학습하려고 하는데 미리 data가 supervision이 없이 학습을 하도록 만들게 된다. 이를 위해서 video를 사용하는데 video에는 RGB frame과 함께 싱크가 맞춰진 audio가 포함되어 있는 특징이 있다. 그래서 video가 주어지면 video에 존재하는 sound를 뽑아오고 CNN을 통해서 sound feature를 뽑은 뒤에 이를 2개의 형태로 표현을 바꿔서 사용하게 된다.
여기서 2개로 나뉘어 뽑힌 embedding의 형태가 어떠한 물리량을 나타내는지는 따로 사용되는 teacher network에 의해서 결정이 된다. Teacher network 부분은 영상에서 object를 인식하는 network하고 scene을 인식하는 network를 활용한다. 이때, 2개의 network는 ImageNet으로 pre-train 된 network를 활용한다. Audio에 대해서는 어떠한 정보와 label도 없기 때문에 audio 쪽 network를 student로 삼아서 teacher network를 따라하도록 만드는 것이다. 그래서 sound 정보가 input으로 들어오면 한쪽은 어떠한 scene인지 classification하도록 학습하고 반대쪽은 어떠한 object가 들어있는지 classification하도록 학습하게 된다. 다른 의미로 본다면 visual data로부터 학습된 정보와 지식을 아무것도 알지 못하는 sound network로 transfer해주는 식으로 학습을 진행했다고 이해할 수도 있다.
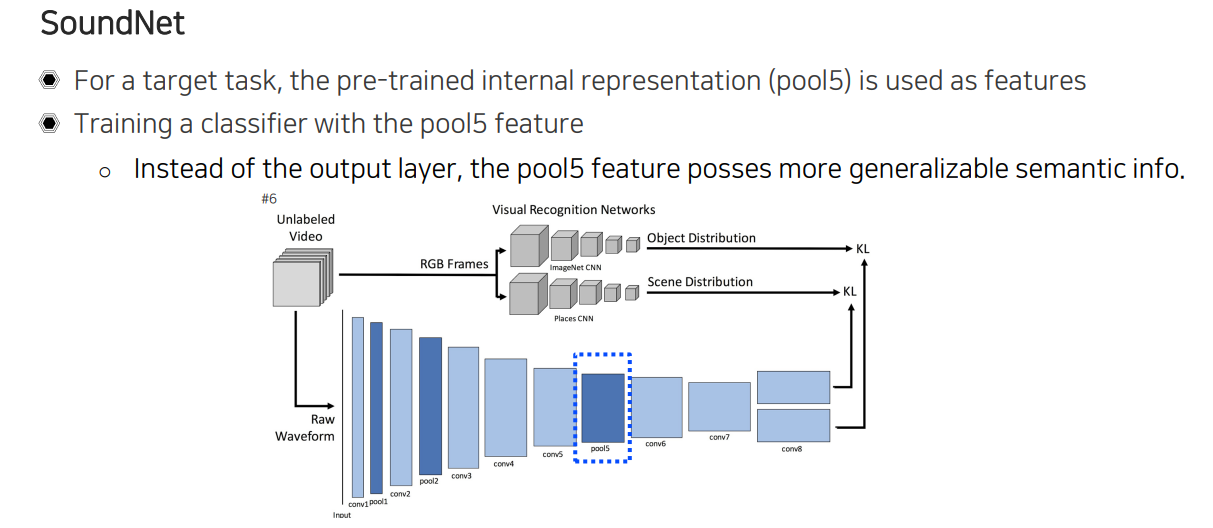 이렇게 학습을 한 뒤에 우리가 다른 sound task에 적용하기 위해서 응용할 수도 있다. 다른 sound task에 응용할 때에는 끝에 추출된 feature들을 사용하기 보다는 pool5에 있는 internal feature를 사용하는 것이 훨씬 유용하다는 것이 알려지게 되었다. 그래서 다른 classifier를 pool5 위에서 학습을 시켰더니 상당히 generalization이 잘 된 결과를 얻었음을 확인할 수 있었다.
이렇게 학습을 한 뒤에 우리가 다른 sound task에 적용하기 위해서 응용할 수도 있다. 다른 sound task에 응용할 때에는 끝에 추출된 feature들을 사용하기 보다는 pool5에 있는 internal feature를 사용하는 것이 훨씬 유용하다는 것이 알려지게 되었다. 그래서 다른 classifier를 pool5 위에서 학습을 시켰더니 상당히 generalization이 잘 된 결과를 얻었음을 확인할 수 있었다.
Cross modal translation
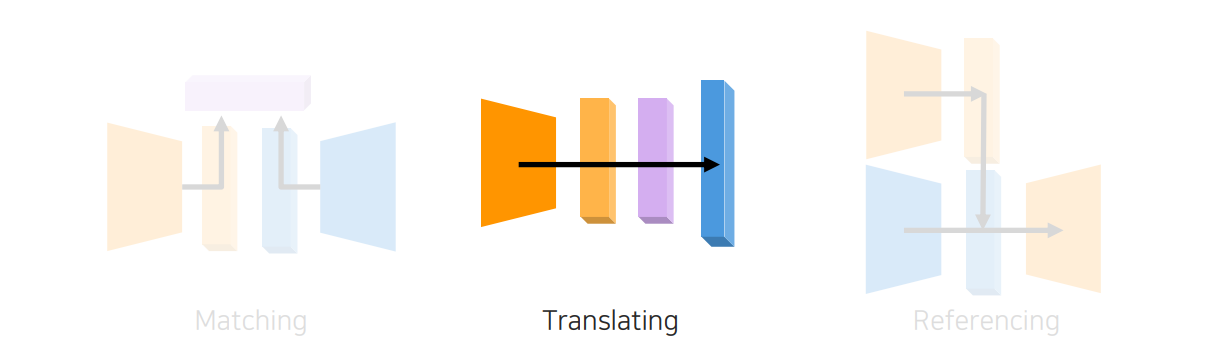 다음으로 cross modal translation을 통해서 image에서 audio 혹은 audio에서 image로 할 수 있는지에 대해서 알아보고자 한다.
다음으로 cross modal translation을 통해서 image에서 audio 혹은 audio에서 image로 할 수 있는지에 대해서 알아보고자 한다.
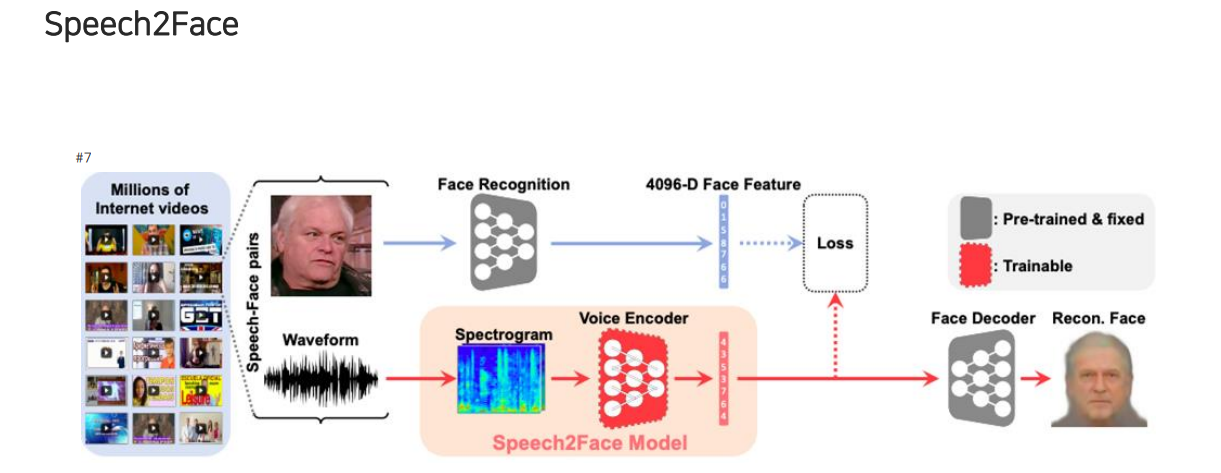 Speech2Face는 소리나 음성을 듣고나서 상대방의 얼굴이 어떻게 생겼을지를 상상하는 network이다. 이 model은 waveform을 우선 spectogram으로 바꿔서 voice encoder에 넣어 embedding을 출력한 뒤에, 이 embedding을 pre-train 된 decoder에 넣어서 얼굴을 reconstruction하게 된다. 이때, 미리 학습된 face decoder와 voice encoder의 호환성을 맞춰야 한다. 그래서 미리 학습된 face decoder에 맞춰서 Speech2Face model이 학습을 하게 되는 구조이다. 학습을 위해서는 목소리와 사람의 얼굴이 pair로 존재해야 하기 때문에 다양한 인터뷰 영상들을 통해서 목소리와 영상이 함께 존재하는 data를 활용하곤 한다.
Speech2Face는 소리나 음성을 듣고나서 상대방의 얼굴이 어떻게 생겼을지를 상상하는 network이다. 이 model은 waveform을 우선 spectogram으로 바꿔서 voice encoder에 넣어 embedding을 출력한 뒤에, 이 embedding을 pre-train 된 decoder에 넣어서 얼굴을 reconstruction하게 된다. 이때, 미리 학습된 face decoder와 voice encoder의 호환성을 맞춰야 한다. 그래서 미리 학습된 face decoder에 맞춰서 Speech2Face model이 학습을 하게 되는 구조이다. 학습을 위해서는 목소리와 사람의 얼굴이 pair로 존재해야 하기 때문에 다양한 인터뷰 영상들을 통해서 목소리와 영상이 함께 존재하는 data를 활용하곤 한다.
Face recognition network는 loss를 측정해야 하기 때문에 실제 test할 때에는 사용이 되지 않는다. 이 network는 Speech2Face model을 학습하는 과정 중에 필요하게 된다. 첫번째로는 사전에 학습이 된 face recognition model로부터 얼굴의 embedding vector를 추출하고 face decoder를 학습시키게 된다. Face feature로부터 원본 face의 정면이 나오도록 학습을 시켜서 face decoder를 두번째로 학습을 시키게 된다. 정리하면 첫번째로는 face recognition network를 학습하고 두번째로 face decoder를 학습시키는 것이다.
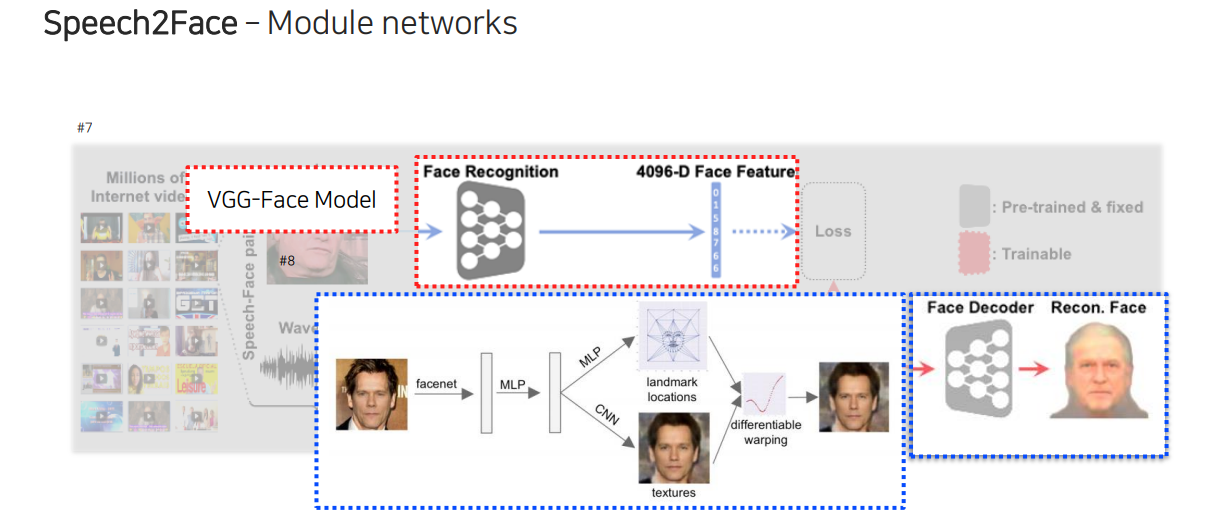 이때 face rercognition model은 사전에 학습 된 VGG-face model을 사용하고, face decoder는 face recognition model에서 나온 face feature를 MLP나 CNN에 넣어 표정이나 질감을 표현하도록 만든다. 이렇게 face decoder를 구성할 수 있는데, 여기서 항상 정면을 바라볼 수 있는 geometric mapping을 배우는 것이다.
이때 face rercognition model은 사전에 학습 된 VGG-face model을 사용하고, face decoder는 face recognition model에서 나온 face feature를 MLP나 CNN에 넣어 표정이나 질감을 표현하도록 만든다. 이렇게 face decoder를 구성할 수 있는데, 여기서 항상 정면을 바라볼 수 있는 geometric mapping을 배우는 것이다.
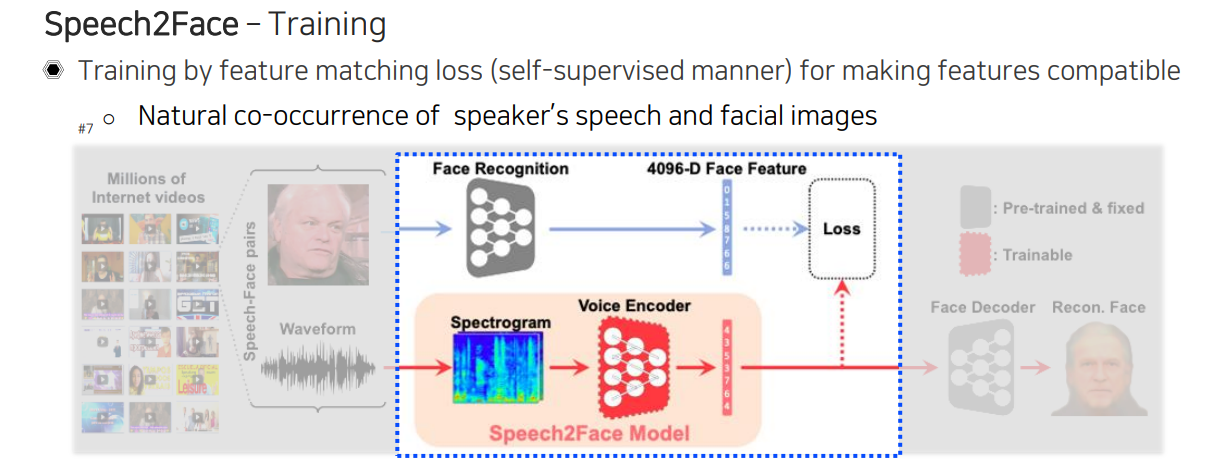 이렇게 face recognition과 face decoder가 다 준비가 되면 face decoder를 최종적으로 출력단으로 사용할 것이다. 그래서 이제는 face decoder에 맞춰서 Speech2Face model의 audio 부분의 호환성을 맞춰줘야 한다. 이를 위해서 여기서 나온 vector를 face feature와 맞출 수 있게 teacher network를 따라가도록 학습이 이루어진다. 이렇게 함으로써 사람의 말과 얼굴이 동시에 발생하는 특징들을 이용해서 voice encoder가 목소리를 듣고 얼굴에 대한 feature embedding을 출력하고 나서 이 embedding을 호환성이 있는 face decoder에 넣어서 얼굴을 다시 만드는 구성을 만들게 된다.
이렇게 face recognition과 face decoder가 다 준비가 되면 face decoder를 최종적으로 출력단으로 사용할 것이다. 그래서 이제는 face decoder에 맞춰서 Speech2Face model의 audio 부분의 호환성을 맞춰줘야 한다. 이를 위해서 여기서 나온 vector를 face feature와 맞출 수 있게 teacher network를 따라가도록 학습이 이루어진다. 이렇게 함으로써 사람의 말과 얼굴이 동시에 발생하는 특징들을 이용해서 voice encoder가 목소리를 듣고 얼굴에 대한 feature embedding을 출력하고 나서 이 embedding을 호환성이 있는 face decoder에 넣어서 얼굴을 다시 만드는 구성을 만들게 된다.
 이외에도 image가 들어왔을 때 caption을 한 것처럼 image를 말로 설명해주는 image-to-speech synthesis task도 존재한다. 이러한 식으로 captiong과 굉장히 비슷한 구조로 만들어서 활용할 수 있다.
이외에도 image가 들어왔을 때 caption을 한 것처럼 image를 말로 설명해주는 image-to-speech synthesis task도 존재한다. 이러한 식으로 captiong과 굉장히 비슷한 구조로 만들어서 활용할 수 있다.
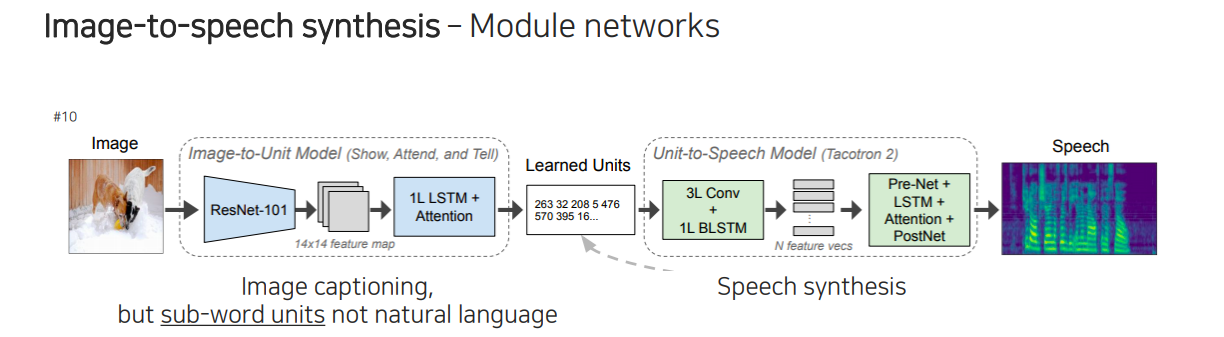 먼저 image가 들어오면 unit 단위로 나누게 된다. 이 unit은 나중에 speech synthesis model에 들어가서 unit에서부터 speech가 reconstruction되도록 만든다. 앞부분은 image captioning하고 똑같지만 출력이 기존의 caption이 아닌 당장 해석은 안되지만 어떠한 unit 단위로 나오게 될 것이다.
먼저 image가 들어오면 unit 단위로 나누게 된다. 이 unit은 나중에 speech synthesis model에 들어가서 unit에서부터 speech가 reconstruction되도록 만든다. 앞부분은 image captioning하고 똑같지만 출력이 기존의 caption이 아닌 당장 해석은 안되지만 어떠한 unit 단위로 나오게 될 것이다.
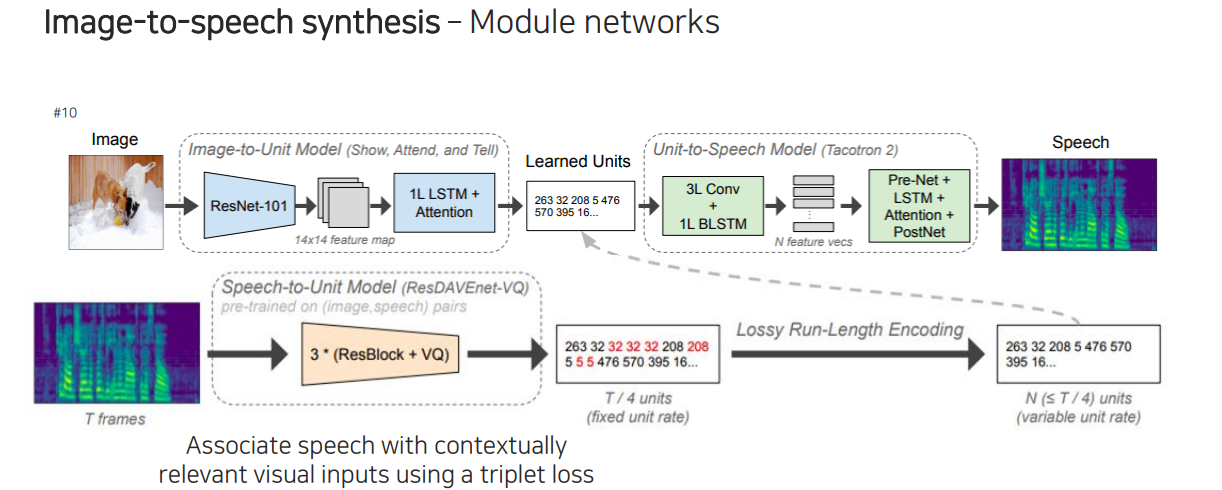 이제 unit 단위가 무엇인지, 그리고 unit으로부터 speech를 어떻게 연결시켜주는지 알아보고자 한다. 이 부분은 Speech2Face에서도 활용한 형태의 사전에 학습된 network를 사용하는데 이를 module network라고 부른다. Speech2Face와 마찬가지로 여기서도 뒷부분을 먼저 학습하게 된다. 결국 똑같이 input으로 들어간 것과 같은 결과가 나오도록 학습을 먼저 시키는 것이다. 무엇인지 정확히는 알 수 없지만 중간에 있는 output이 unit이 되도록 encoder와 decoder구조를 사용해서 미리 학습을 진행한다. 이렇게 학습을 통해서 정의가 된 unit을 이용해서 image가 들어왔을 때 speech로부터 마지막에 나온 unit을 supervision으로 이용해서 Speech-to-Unit model과 Image-to-Unit model이 호환이 되도록 학습을 시켜주게 된다.
이제 unit 단위가 무엇인지, 그리고 unit으로부터 speech를 어떻게 연결시켜주는지 알아보고자 한다. 이 부분은 Speech2Face에서도 활용한 형태의 사전에 학습된 network를 사용하는데 이를 module network라고 부른다. Speech2Face와 마찬가지로 여기서도 뒷부분을 먼저 학습하게 된다. 결국 똑같이 input으로 들어간 것과 같은 결과가 나오도록 학습을 먼저 시키는 것이다. 무엇인지 정확히는 알 수 없지만 중간에 있는 output이 unit이 되도록 encoder와 decoder구조를 사용해서 미리 학습을 진행한다. 이렇게 학습을 통해서 정의가 된 unit을 이용해서 image가 들어왔을 때 speech로부터 마지막에 나온 unit을 supervision으로 이용해서 Speech-to-Unit model과 Image-to-Unit model이 호환이 되도록 학습을 시켜주게 된다.
Cross modal reasoning
 마지막으로 cross modal reasoning은 audio가 영상을 참조해서 우리가 원하는 target task를 수행하는 일련의 디자인 방법이다.
마지막으로 cross modal reasoning은 audio가 영상을 참조해서 우리가 원하는 target task를 수행하는 일련의 디자인 방법이다.
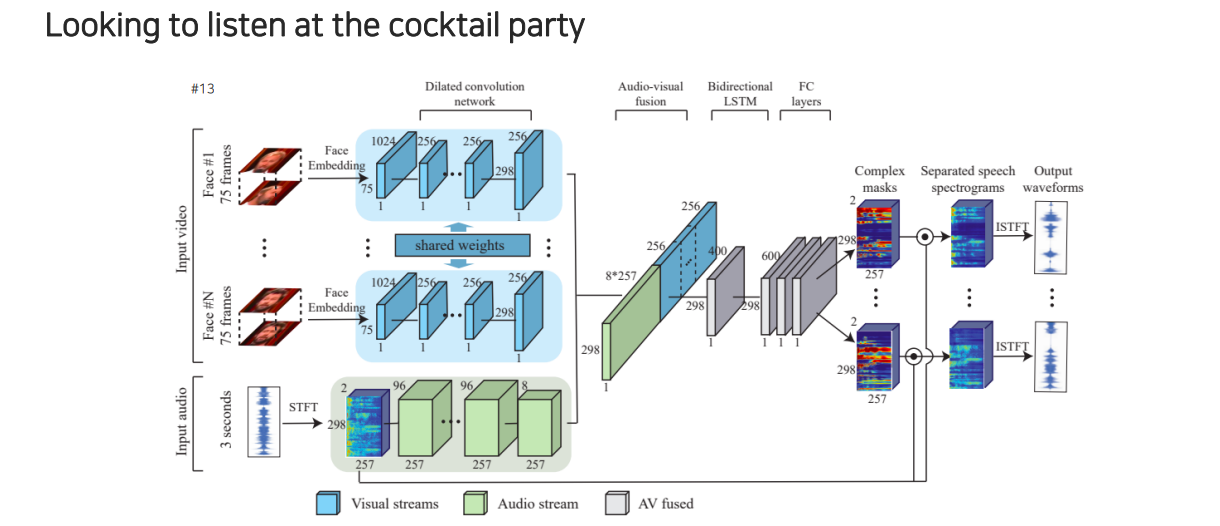 Google에서 제시했던 speech seperation task는 두 사람이 이야기할 때 겹치는 음성을 분리하여 각 사람이 어떠한 음성으로 이야기하는지를 확인할 수 있다. 이 model의 구조를 살펴보면 먼저 얼굴 정보가 들어오면 각 얼굴의 움직임 정보가 있을 것이다. 그래서 얼굴의 움직임들을 facial network를 통해서 feature를 추출할 수 있다. 그리고 여기에 해당하는 음성도 spectogram 형태로 바꿔서 STFT를 활용하여 audio network로부터 feature를 뽑아 feature끼리 concatenation을 시켜준다. 이 두가지 정보를 모두 참조하여 최종적으로 지금 사용하고 있는 얼굴에 대한 mask를 뽑을 수 있다. 그리고 이 mask와 원본 spectogram을 활용하여 element-wise multiplication을 통해서 masking을 해주게 된다. 이렇게 하면 얼굴에 해당하는 speech signal만 출력단에 남게 되고, 이를 반대로 inverse STFT를 통해서 waveform으로 바꿔 깨끗한 음성만 출력하게 만들 수가 있다.
Google에서 제시했던 speech seperation task는 두 사람이 이야기할 때 겹치는 음성을 분리하여 각 사람이 어떠한 음성으로 이야기하는지를 확인할 수 있다. 이 model의 구조를 살펴보면 먼저 얼굴 정보가 들어오면 각 얼굴의 움직임 정보가 있을 것이다. 그래서 얼굴의 움직임들을 facial network를 통해서 feature를 추출할 수 있다. 그리고 여기에 해당하는 음성도 spectogram 형태로 바꿔서 STFT를 활용하여 audio network로부터 feature를 뽑아 feature끼리 concatenation을 시켜준다. 이 두가지 정보를 모두 참조하여 최종적으로 지금 사용하고 있는 얼굴에 대한 mask를 뽑을 수 있다. 그리고 이 mask와 원본 spectogram을 활용하여 element-wise multiplication을 통해서 masking을 해주게 된다. 이렇게 하면 얼굴에 해당하는 speech signal만 출력단에 남게 되고, 이를 반대로 inverse STFT를 통해서 waveform으로 바꿔 깨끗한 음성만 출력하게 만들 수가 있다.
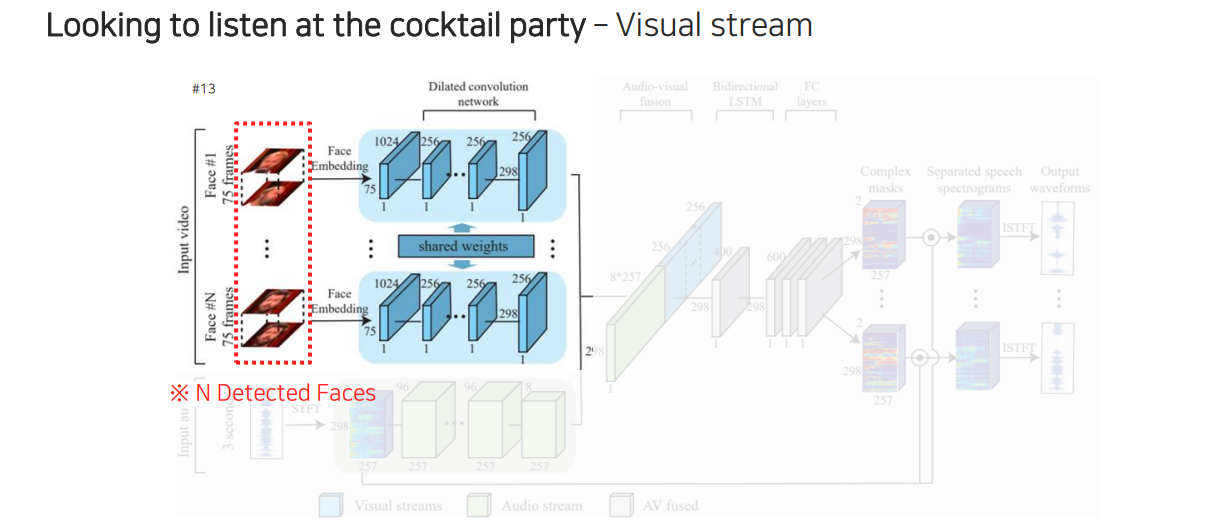 자세히 살펴보면 개의 얼굴들을 활용해서 각 feature를 뽑을 수가 있다.
자세히 살펴보면 개의 얼굴들을 활용해서 각 feature를 뽑을 수가 있다.
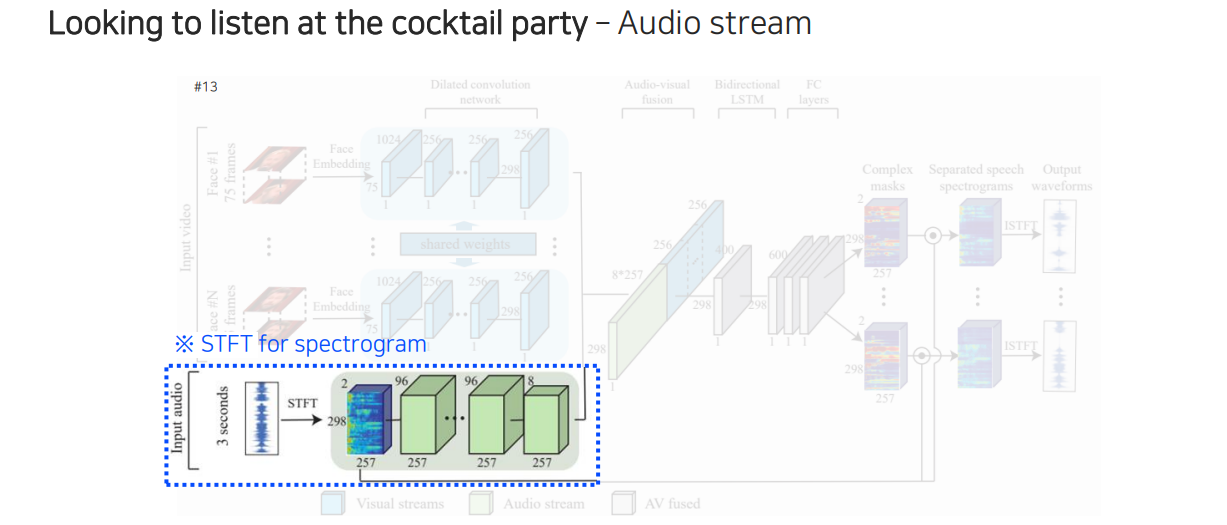 두번째로는 STFT를 활용해서 합쳐진 음성들을 audio network를 통해서 feature를 뽑을 수 있다.
두번째로는 STFT를 활용해서 합쳐진 음성들을 audio network를 통해서 feature를 뽑을 수 있다.
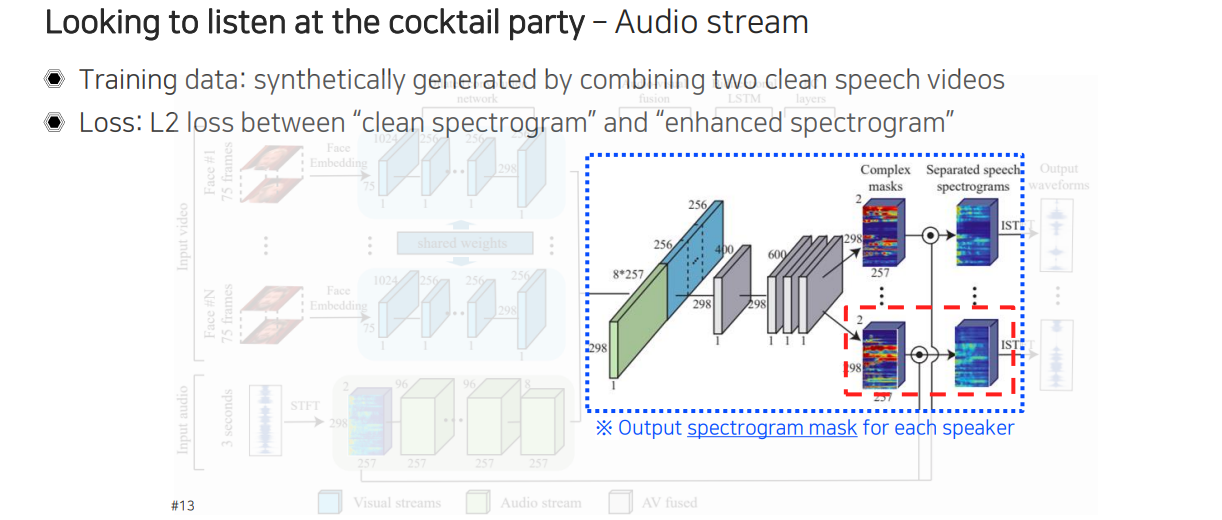 출력은 각 사람의 얼굴에 해당하는 mask들이 나오게 되고 원본 음성들이 섞여있는 spectogram을 weighting을 해서 출력을 만들어서 각 사람마다 목소리를 출력할 수 있도록 만든다. 그렇다면 이를 어떻게 학습할 수 있을까? 여러가지 음성이 동시에 말하고 있고 마지막에 나오는 출력은 각 사람마다 깨끗한 음성이다. 이러한 음성 pair를 dataset으로 구축할 수 있냐고 하면은 현실적으로 불가능할 것이다. 일단 말이 섞이면 녹음 당시에 따로 분리해서 할 수가 없기 때문이다.
출력은 각 사람의 얼굴에 해당하는 mask들이 나오게 되고 원본 음성들이 섞여있는 spectogram을 weighting을 해서 출력을 만들어서 각 사람마다 목소리를 출력할 수 있도록 만든다. 그렇다면 이를 어떻게 학습할 수 있을까? 여러가지 음성이 동시에 말하고 있고 마지막에 나오는 출력은 각 사람마다 깨끗한 음성이다. 이러한 음성 pair를 dataset으로 구축할 수 있냐고 하면은 현실적으로 불가능할 것이다. 일단 말이 섞이면 녹음 당시에 따로 분리해서 할 수가 없기 때문이다.
그래서 이 논문의 아이디어는 먼저 한 사람 각각 따로 말하는 동영상을 활용한다. 깨끗한 speech video 2개를 합성하는데, 이때 얼굴은 어차피 따로 잘라서 넣으니까 그냥 양옆에 붙여 넣는 것이다. 그리고 비디오를 동시에 재생을 시켜준다. 그러면 얼굴은 동시에 움직이게 될 것이다. 그렇다면 audio는 어떻게 합칠 수 있을까? 영상들을 재생시킬 때 동시에 말을 하는 것처럼 만들기 위해서 두개를 더해주게 된다. Waveform signal 2개를 더해줌으로써 이 사람들이 동시에 이야기하는 것처럼 waverform을 만들어주는 것이다. 이렇게 training data를 만들고 간단한 L2 loss를 통해서 학습을 시키게 된다.
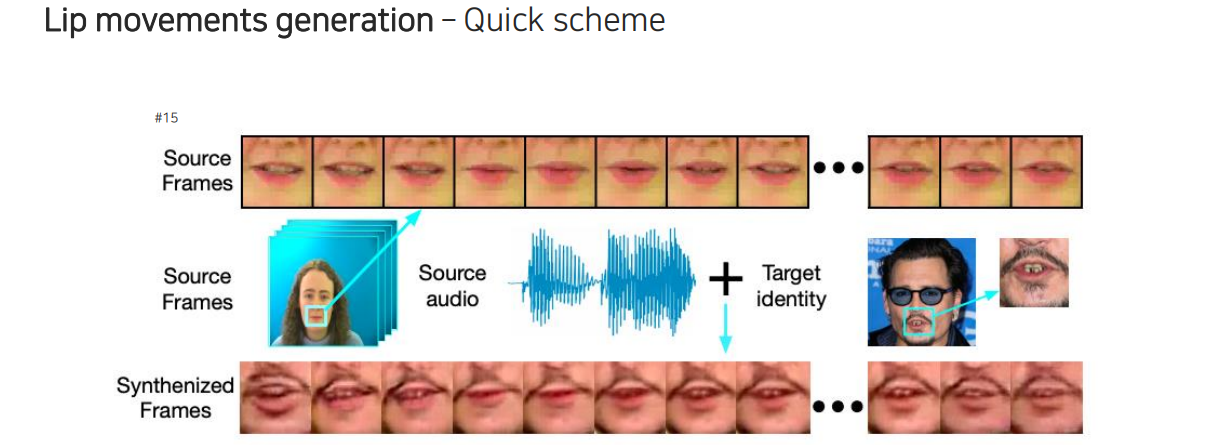 또다른 reasoning task로는 lip movement를 generation할 수 있다. 지금까지는 얼굴과 음성을 두고 음성을 seperation하는 task를 알아보았다. 이번에는 반대로 얼굴과 음성을 두고 입의 움직임을 출력하도록 하는 것이다. 어떠한 음성이 주어졌을 때 한 사람의 입의 움직임을 립싱크하듯이 만들어주는 model을 만들었다.
또다른 reasoning task로는 lip movement를 generation할 수 있다. 지금까지는 얼굴과 음성을 두고 음성을 seperation하는 task를 알아보았다. 이번에는 반대로 얼굴과 음성을 두고 입의 움직임을 출력하도록 하는 것이다. 어떠한 음성이 주어졌을 때 한 사람의 입의 움직임을 립싱크하듯이 만들어주는 model을 만들었다.
이러한 lip motion을 만드는 것도 결국 비슷한 과정이다. Source frame에 있는 사람의 말과 audio signal이 있으면 audio signal은 그냥 참조하고 입의 움직임은 매 frame마다 존재할 것이다. 여기서 원하는 바는 연예인이 말하는 것처럼 바꾸고 싶은 것이다. 이때, 원하는 사람의 얼굴을 embedding vector로 바꾸고 speech 정보와 섞어서 lip motion frame들을 합성할 수가 있다.
 자율 주행의 경우 주변 환경과 자동차의 모든 센서들을 활용해서 이를 모두 취합하여 가장 좋은 선택을 내리게 된다.
자율 주행의 경우 주변 환경과 자동차의 모든 센서들을 활용해서 이를 모두 취합하여 가장 좋은 선택을 내리게 된다.
