
Visual data & Text
1. Text embedding
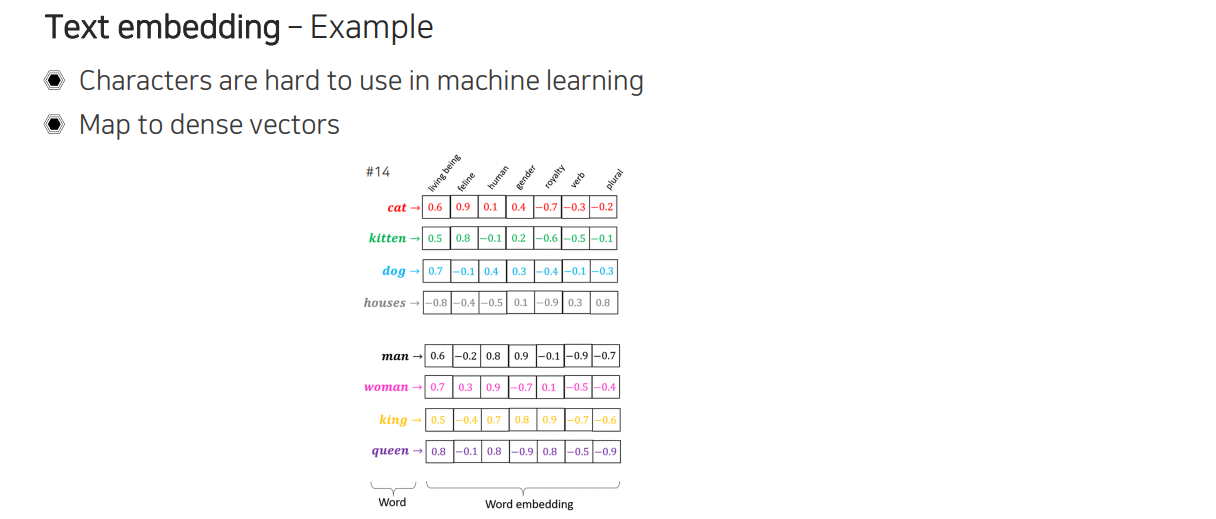 먼저 text가 어떻게 digital data로 표현이 되는지 알아볼 것이다. 대표적인 방법으로 text embedding이 있다. 여기서 중요한 점은 문자 단위가 아닌 단어 단위로 나누는 것이다. 문자 단위로 text를 나누게 되면 machine learning 알고리즘을 이용하여 활용하기가 굉장히 어렵다. "A"라는 문자가 들어갔을 때 의미를 파악하기 보다는 어떠한 문자인지만을 파악하기 때문에 이 경우에는 어떻게 조합이 되어야 의미를 가지는지 high level knowledge를 따로 학습을 해줘야 할 것이다. 항상 모든 task를 수행할 때 low level knowledge에서 시작하는 것은 굉장히 어려운 부분이다. 그래서 image에서도 0부터 255까지의 밝기를 pixel 단위로 나누어 조합하여 의미를 파악하는 것은 굉장히 어려운 부분이다. 이러한 문제 때문에 text에서는 단어 단위로 표현을 하려고 하는 것이다.
먼저 text가 어떻게 digital data로 표현이 되는지 알아볼 것이다. 대표적인 방법으로 text embedding이 있다. 여기서 중요한 점은 문자 단위가 아닌 단어 단위로 나누는 것이다. 문자 단위로 text를 나누게 되면 machine learning 알고리즘을 이용하여 활용하기가 굉장히 어렵다. "A"라는 문자가 들어갔을 때 의미를 파악하기 보다는 어떠한 문자인지만을 파악하기 때문에 이 경우에는 어떻게 조합이 되어야 의미를 가지는지 high level knowledge를 따로 학습을 해줘야 할 것이다. 항상 모든 task를 수행할 때 low level knowledge에서 시작하는 것은 굉장히 어려운 부분이다. 그래서 image에서도 0부터 255까지의 밝기를 pixel 단위로 나누어 조합하여 의미를 파악하는 것은 굉장히 어려운 부분이다. 이러한 문제 때문에 text에서는 단어 단위로 표현을 하려고 하는 것이다.
 Text가 들어오면 위와 같이 단어를 dense vector로 변경해주는 mapping을 만들어서 사용한다. 그래서 각 단어마다 고정된 1차원의 vector를 만들어 할당해주는 word embedding을 먼저 수행해준다. Word embedding의 특징은 위와 같이 2차원으로 visualization해서 본다고 했을 때, 비슷한 의미를 가지는 단어들이 비슷한 위치에 존재하는 것이다. 그래서 위에서는 고양이와 관련있는 단어는 가깝게 있고, 개는 고양이와 조금 떨어져 있으며, 집과 같이 동물에 해당하지 않는 경우에는 멀리 존재하게 되는 것이다. 다른 재밌는 점은 남자와 여자, 왕과 왕비처럼 유사 관계가 그대로 유지되는 것을 볼 수도 있다.
Text가 들어오면 위와 같이 단어를 dense vector로 변경해주는 mapping을 만들어서 사용한다. 그래서 각 단어마다 고정된 1차원의 vector를 만들어 할당해주는 word embedding을 먼저 수행해준다. Word embedding의 특징은 위와 같이 2차원으로 visualization해서 본다고 했을 때, 비슷한 의미를 가지는 단어들이 비슷한 위치에 존재하는 것이다. 그래서 위에서는 고양이와 관련있는 단어는 가깝게 있고, 개는 고양이와 조금 떨어져 있으며, 집과 같이 동물에 해당하지 않는 경우에는 멀리 존재하게 되는 것이다. 다른 재밌는 점은 남자와 여자, 왕과 왕비처럼 유사 관계가 그대로 유지되는 것을 볼 수도 있다.
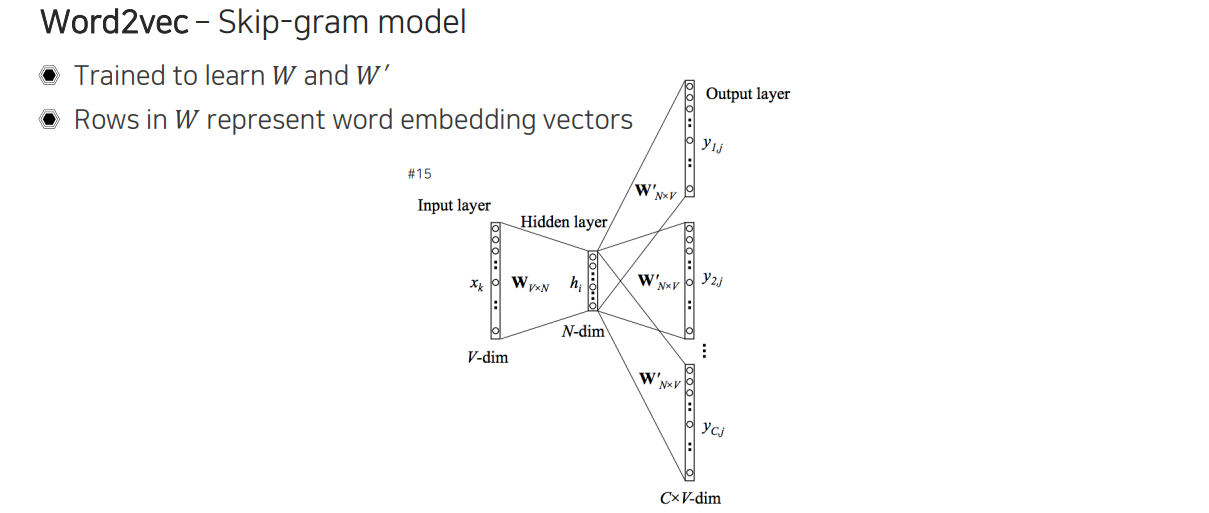 Word2vec은 이러한 word embedding을 학습하기 위한 학습 방법 중 하나로, 우리는 이를 skip-gram model이라고 한다. 먼저 input layer에 V개의 단어를 one-hot vector 형태로 표현하게 된다. 그리고 중간에 있는 것이 word embedding에 해당하게 되는데, 우리는 이 word embedding이 되도록 학습하고 싶은 것이다. 는 그저 V를 N으로 바꿔주도록 곱해주게 되는데, 우리가 one-hot vector를 사용하기 때문에 1에 대응되는 row를 W에서 골라 word embedding vector로 사용하게 되는 것이다. 다음으로는 을 이용해서 input 단어가 하나가 들어왔을 때 옆에 어떠한 단어가 올지를 맞추는 task를 만들어주게 된다.
Word2vec은 이러한 word embedding을 학습하기 위한 학습 방법 중 하나로, 우리는 이를 skip-gram model이라고 한다. 먼저 input layer에 V개의 단어를 one-hot vector 형태로 표현하게 된다. 그리고 중간에 있는 것이 word embedding에 해당하게 되는데, 우리는 이 word embedding이 되도록 학습하고 싶은 것이다. 는 그저 V를 N으로 바꿔주도록 곱해주게 되는데, 우리가 one-hot vector를 사용하기 때문에 1에 대응되는 row를 W에서 골라 word embedding vector로 사용하게 되는 것이다. 다음으로는 을 이용해서 input 단어가 하나가 들어왔을 때 옆에 어떠한 단어가 올지를 맞추는 task를 만들어주게 된다.
 조금 더 자세하게 살펴보면 위와 같이 문장이 주어졌을 때, brown을 기준으로 한다면 brown 옆에 어떠한 단어가 위치할지를 학습하도록 하는 것이다. Sliding window 방식을 이용해서 만약 window size가 5라고 한다면 각 단어를 기준으로 5개의 단어를 보면서 하나의 문장을 처음부터 지나가면서 training pair를 만들어주게 된다. 이렇게 가운데 단어를 두고 주변 단어들을 prediction하는 식으로 학습을 시키게 된다. 이렇게 학습을 하면 단어간 관계성에 대한 이해도가 높아지게 되는 것이다.
조금 더 자세하게 살펴보면 위와 같이 문장이 주어졌을 때, brown을 기준으로 한다면 brown 옆에 어떠한 단어가 위치할지를 학습하도록 하는 것이다. Sliding window 방식을 이용해서 만약 window size가 5라고 한다면 각 단어를 기준으로 5개의 단어를 보면서 하나의 문장을 처음부터 지나가면서 training pair를 만들어주게 된다. 이렇게 가운데 단어를 두고 주변 단어들을 prediction하는 식으로 학습을 시키게 된다. 이렇게 학습을 하면 단어간 관계성에 대한 이해도가 높아지게 되는 것이다.
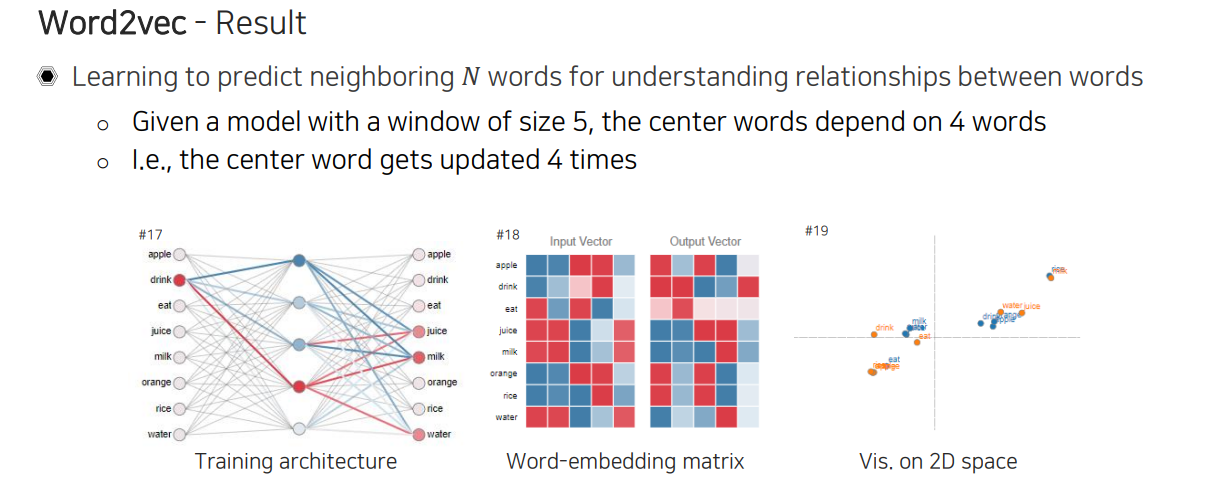 중심 단어 하나가 있을 때 옆에 있는 단어들을 prdiction하게 만들기 때문에 해당 단어가 update되는 횟수는 window size가 5이기 때문에 4번이 될 것이다. 와 을 이용하여 matrix multiplication을 통해서 최종 output을 만들어내게 되는데, 이때 바로 다음 단어에 무엇이 올지에 관한 score가 prediction 될 것이다.
중심 단어 하나가 있을 때 옆에 있는 단어들을 prdiction하게 만들기 때문에 해당 단어가 update되는 횟수는 window size가 5이기 때문에 4번이 될 것이다. 와 을 이용하여 matrix multiplication을 통해서 최종 output을 만들어내게 되는데, 이때 바로 다음 단어에 무엇이 올지에 관한 score가 prediction 될 것이다.
2. Joint embedding
 지금까지는 text를 어떻게 단어 단위로 표현하는지 살펴보았다. 지금부터는 이를 어떻게 visual data와 함께 사용하는지 알아보고자 한다.
지금까지는 text를 어떻게 단어 단위로 표현하는지 살펴보았다. 지금부터는 이를 어떻게 visual data와 함께 사용하는지 알아보고자 한다.
 Word2vec와 visual data를 함께 엮어서 사용할 수 있는 대표적인 task로 image tagging이 있다. Image tagging은 하나의 image가 input으로 들어왔을 때 해당 image의 tag를 생성해주는 것이다. 혹은 tag를 keyword로 주고 image를 만들어낼 수도 있을 것이다. 좌측과 같이 image 하나가 주어졌을 때 해당 image과 관련있는 tag들을 출력해볼 수 있을 것이다. 혹은 우측과 같이 tag keyword를 주었을 때 각 image에 해당하는 tag들이 존재할 것인데, 단어들 사이의 similarity를 측정하여 영상을 검색하는데도 충분히 활용할 수 있을 것이다.
Word2vec와 visual data를 함께 엮어서 사용할 수 있는 대표적인 task로 image tagging이 있다. Image tagging은 하나의 image가 input으로 들어왔을 때 해당 image의 tag를 생성해주는 것이다. 혹은 tag를 keyword로 주고 image를 만들어낼 수도 있을 것이다. 좌측과 같이 image 하나가 주어졌을 때 해당 image과 관련있는 tag들을 출력해볼 수 있을 것이다. 혹은 우측과 같이 tag keyword를 주었을 때 각 image에 해당하는 tag들이 존재할 것인데, 단어들 사이의 similarity를 측정하여 영상을 검색하는데도 충분히 활용할 수 있을 것이다.
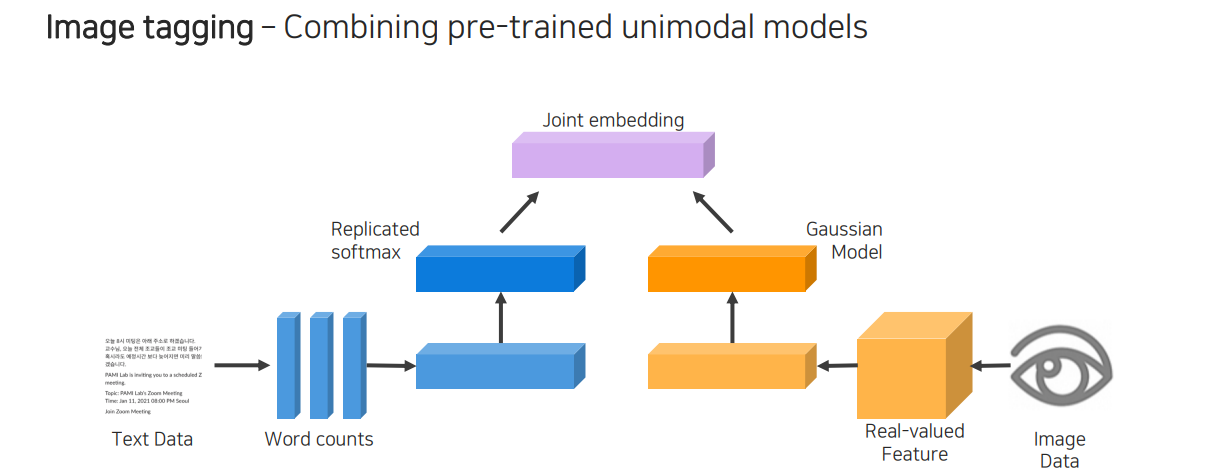 지금부터는 image tagging application을 어떻게 구현하는지 살펴보고자 한다. 가장 먼저 text data로부터 단어를 count하여 얼마나 많은 단어들이 존재하는지 파악한다. 만약 단어만 input으로 들어왔다고 하면 바로 word embedding으로 사용할 수도 있는 것이다. 이렇게 text로 부터 embedding vector화를 시켜주는 과정을 한쪽에서 진행하고 반대쪽에서는 image data를 embedding vector화 시켜주어 마지막에 두가지 vector를 함께 사용하는 것이 joint embedding이다. 여기서 중요한 점은 어느쪽에서 오는 embedding vector든 동일한 차원으로 맞춰줘야 한다는 것이다. 학습을 시켜줄 때 양쪽의 vector들이 같은 의미를 가지고 있다면 이 두 vector를 거리가 가까워지도록 학습을 시켜주는 것이다.
지금부터는 image tagging application을 어떻게 구현하는지 살펴보고자 한다. 가장 먼저 text data로부터 단어를 count하여 얼마나 많은 단어들이 존재하는지 파악한다. 만약 단어만 input으로 들어왔다고 하면 바로 word embedding으로 사용할 수도 있는 것이다. 이렇게 text로 부터 embedding vector화를 시켜주는 과정을 한쪽에서 진행하고 반대쪽에서는 image data를 embedding vector화 시켜주어 마지막에 두가지 vector를 함께 사용하는 것이 joint embedding이다. 여기서 중요한 점은 어느쪽에서 오는 embedding vector든 동일한 차원으로 맞춰줘야 한다는 것이다. 학습을 시켜줄 때 양쪽의 vector들이 같은 의미를 가지고 있다면 이 두 vector를 거리가 가까워지도록 학습을 시켜주는 것이다.
 자세하게 학습 방법을 살펴보면 양쪽에서 온 embedding vector를 fully-connected layer와 같은 것을 사용하여 동일한 차원으로 transform 시켜줘야 한다. 그러면 결국 동일한 차원을 공유하고 있게 되어 거리를 측정하는 다양한 방식을 활용하여 비교할 수 있게 된다. 결국 서로 다른 modality로부터 출발했지만 동일한 차원으로의 embedding vector를 통해서 비교가 가능해졌으며, 이를 metric learning이라고 부른다.
자세하게 학습 방법을 살펴보면 양쪽에서 온 embedding vector를 fully-connected layer와 같은 것을 사용하여 동일한 차원으로 transform 시켜줘야 한다. 그러면 결국 동일한 차원을 공유하고 있게 되어 거리를 측정하는 다양한 방식을 활용하여 비교할 수 있게 된다. 결국 서로 다른 modality로부터 출발했지만 동일한 차원으로의 embedding vector를 통해서 비교가 가능해졌으며, 이를 metric learning이라고 부른다.
 Image tagging application에서 이러한 식으로 joint embedding을 학습할 수 있었는데, joint embedding도 위에서 본 word embedding과 마찬가지로 analogy 관계가 형성이 된다. 그래서 위와 같이 파란 자동차 사진에서 blue를 빼고 red를 더하게 되는 간단한 연산 과정을 통해서 dataset 내에서 검색을 해보면 빨간 자동차 사진들을 찾을 수 있게 된다. 흥미로운 사실은 yellow를 더해서 검색하면 노란색 자동차 사진들을 찾을 수가 있다.
Image tagging application에서 이러한 식으로 joint embedding을 학습할 수 있었는데, joint embedding도 위에서 본 word embedding과 마찬가지로 analogy 관계가 형성이 된다. 그래서 위와 같이 파란 자동차 사진에서 blue를 빼고 red를 더하게 되는 간단한 연산 과정을 통해서 dataset 내에서 검색을 해보면 빨간 자동차 사진들을 찾을 수 있게 된다. 흥미로운 사실은 yellow를 더해서 검색하면 노란색 자동차 사진들을 찾을 수가 있다.
 이를 활용하는 분야는 단순히 image를 tagging하는 task뿐만 아니라 음식 사진이 들어오면 이에 해당하는 레시피를 보여주는 task에도 적용이 가능하다.
이를 활용하는 분야는 단순히 image를 tagging하는 task뿐만 아니라 음식 사진이 들어오면 이에 해당하는 레시피를 보여주는 task에도 적용이 가능하다.
 마찬가지로 metric learning을 하는데, 각 재료를 단어 단위로 LSTM과 같은 model에 넣어서 하나의 고정된 dimensioinal vector로 만들고 instruction도 순서대로 LSTM에 넣어서 고정된 차원의 vector로 만들어준다. 그리고 이들을 합쳐서 하나의 vector로 만들어주면 된다. 이때의 결과를 image 쪽에서 neural network를 지난 결과와 결합하여 metric learning을 진행해준다. 이때 cosine similarity를 사용하여 simiarity를 angular domain에서 비교하고자 한다. 이러한 식으로 결국 joint embedding learning과 비슷한 방식으로 학습을 진행하게 된다. 더불어 high-level semantic 정보를 활용하기 위해서 추가적인 loss도 사용할 수 있다.
마찬가지로 metric learning을 하는데, 각 재료를 단어 단위로 LSTM과 같은 model에 넣어서 하나의 고정된 dimensioinal vector로 만들고 instruction도 순서대로 LSTM에 넣어서 고정된 차원의 vector로 만들어준다. 그리고 이들을 합쳐서 하나의 vector로 만들어주면 된다. 이때의 결과를 image 쪽에서 neural network를 지난 결과와 결합하여 metric learning을 진행해준다. 이때 cosine similarity를 사용하여 simiarity를 angular domain에서 비교하고자 한다. 이러한 식으로 결국 joint embedding learning과 비슷한 방식으로 학습을 진행하게 된다. 더불어 high-level semantic 정보를 활용하기 위해서 추가적인 loss도 사용할 수 있다.
3. Cross modal translation
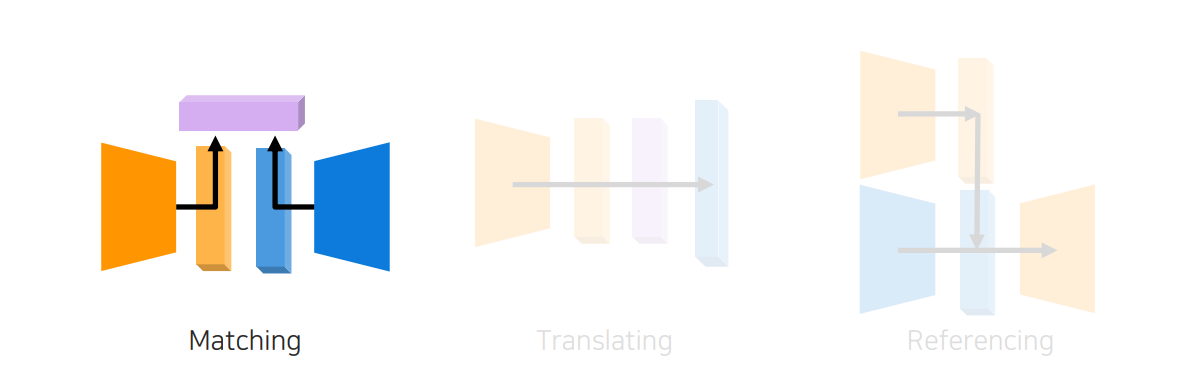
 다음으로는 translating 방식을 통해서 하나의 modality를 다른 modality로 번역시키는 것을 알아볼 것이고, 이를 cross modal translation이라고 부른다.
다음으로는 translating 방식을 통해서 하나의 modality를 다른 modality로 번역시키는 것을 알아볼 것이고, 이를 cross modal translation이라고 부른다.
 대표적인 application으로는 image captioning이 존재한다. Image가 들어오면 글로 설명해주는 model을 만드는 것이다.
대표적인 application으로는 image captioning이 존재한다. Image가 들어오면 글로 설명해주는 model을 만드는 것이다.
 가장 간단한 것으로는 image classification을 생각할 수 있다. Image로부터 text에 해당하는 category가 output으로 나오는 것이다. Image captioning에서는 image가 들어왔을 때 단어가 아닌 문장을 만들고 싶은 것이다. 이를 위해서 image가 들어왔을 때 문장으로 바꿔주는 구조 2개를 결합시켜야 한다. Image를 표현하는 CNN과 text를 잘 다루는 RNN 계열을 합쳐서 사용하곤 한다.
가장 간단한 것으로는 image classification을 생각할 수 있다. Image로부터 text에 해당하는 category가 output으로 나오는 것이다. Image captioning에서는 image가 들어왔을 때 단어가 아닌 문장을 만들고 싶은 것이다. 이를 위해서 image가 들어왔을 때 문장으로 바꿔주는 구조 2개를 결합시켜야 한다. Image를 표현하는 CNN과 text를 잘 다루는 RNN 계열을 합쳐서 사용하곤 한다.
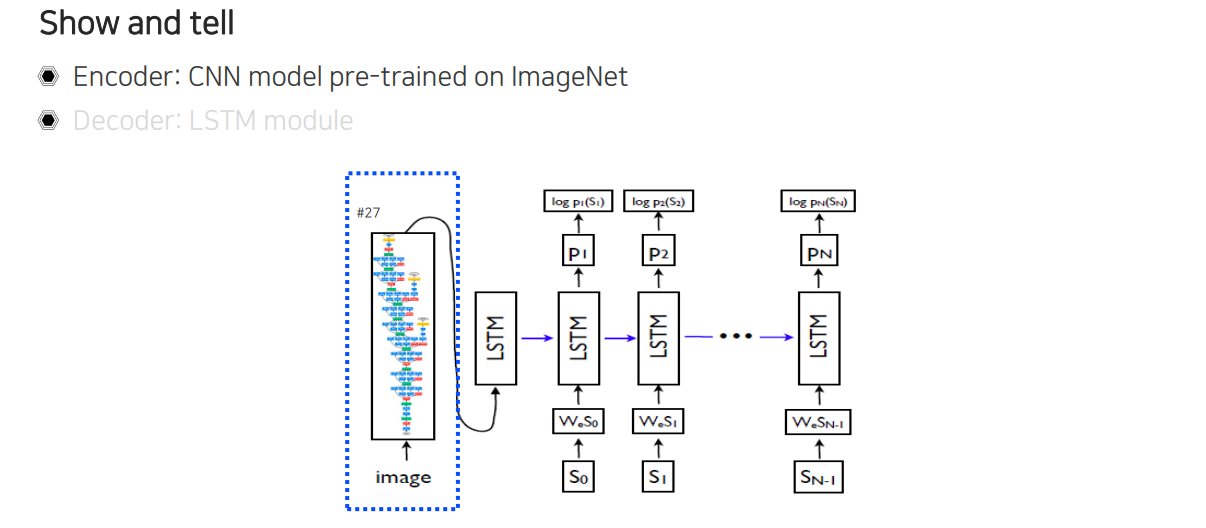 그래서 encoder에서는 굉장히 강한 CNN 계열의 image를 잘 표현해서 고정된 차원의 vector로 만들어주는 CNN 부분이 pre-train 되어 사용이 된다.
그래서 encoder에서는 굉장히 강한 CNN 계열의 image를 잘 표현해서 고정된 차원의 vector로 만들어주는 CNN 부분이 pre-train 되어 사용이 된다.
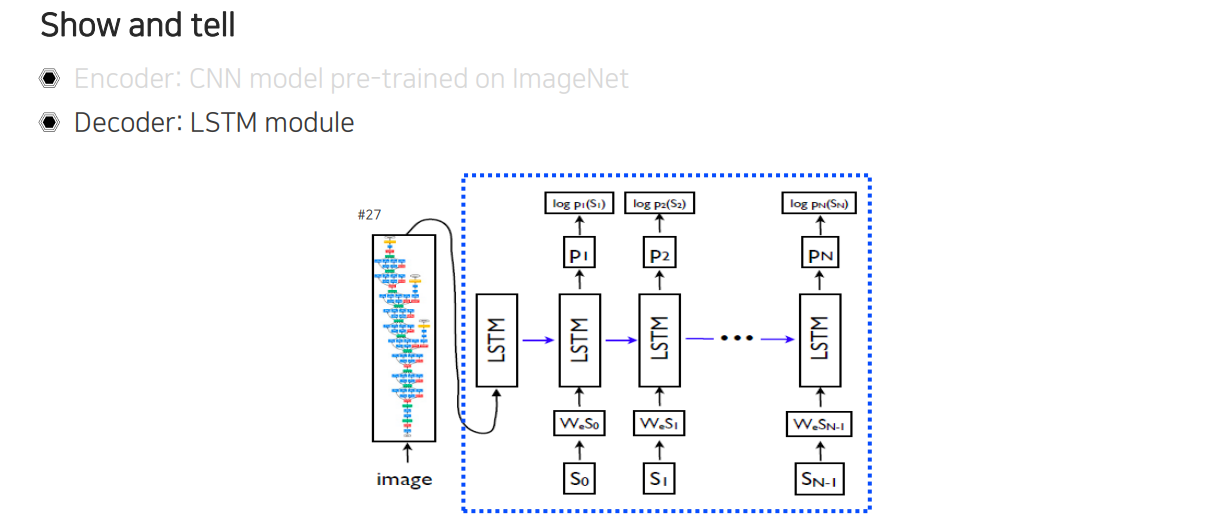 Decoder 부분은 LSTM을 사용해서 image vector가 들어오면 다음부터 iamge를 설명하는 단어를 내보내도록 한다.
Decoder 부분은 LSTM을 사용해서 image vector가 들어오면 다음부터 iamge를 설명하는 단어를 내보내도록 한다.
 "Show and tell"과 같은 연구들이 image가 들어왔을 때 caption을 생성하는 연구들이다. 여기서 image의 어떠한 부분을 참조해서 caption을 만들어내는지를 확인하는 연구가 "Show, attend, and tell" 연구이다.
"Show and tell"과 같은 연구들이 image가 들어왔을 때 caption을 생성하는 연구들이다. 여기서 image의 어떠한 부분을 참조해서 caption을 만들어내는지를 확인하는 연구가 "Show, attend, and tell" 연구이다.
 이 연구가 어떻게 구현이 되었는지 자세하게 살펴보도록 할 것이다. 이 연구는 input으로 image가 들어왔을 때 CNN을 통과해서 RNN으로 들어가게 되는데, 이때 CNN의 output과 RNN의 output이 서로를 계속해서 참조하게 된다. 이를 온전히 translating이라고 볼 수는 없고 아래에서 살펴 볼 referencing도 어느정도 포함된 내용으로 생각할 수 있다. 이렇게 매 순간마다 참조를 해서 단어들을 prediction하고, 이를 합쳐서 최종적으로 문장을 만들어내게 된다.
이 연구가 어떻게 구현이 되었는지 자세하게 살펴보도록 할 것이다. 이 연구는 input으로 image가 들어왔을 때 CNN을 통과해서 RNN으로 들어가게 되는데, 이때 CNN의 output과 RNN의 output이 서로를 계속해서 참조하게 된다. 이를 온전히 translating이라고 볼 수는 없고 아래에서 살펴 볼 referencing도 어느정도 포함된 내용으로 생각할 수 있다. 이렇게 매 순간마다 참조를 해서 단어들을 prediction하고, 이를 합쳐서 최종적으로 문장을 만들어내게 된다.
 여기서 attention이라는 개념이 등장하는데, 위와 같이 사람이 어떠한 웹페이지에서 특정 부분에 눈이 머무는 시간이 전부 다를 것이고 중요한 부분에는 오래 머물게 될 것이다. 사람은 visual data를 습득할 때 모든 부분을 다 보는 것이 아니라 rough하게 먼저 다 보고 초점을 맞추고 싶은 부분에 집중해서 보곤 한다. 그래서 각 위치마다 주목해서 보게 되는데, 우리는 이를 attention이라고 부르고 이를 구현해야 하는 것이다.
여기서 attention이라는 개념이 등장하는데, 위와 같이 사람이 어떠한 웹페이지에서 특정 부분에 눈이 머무는 시간이 전부 다를 것이고 중요한 부분에는 오래 머물게 될 것이다. 사람은 visual data를 습득할 때 모든 부분을 다 보는 것이 아니라 rough하게 먼저 다 보고 초점을 맞추고 싶은 부분에 집중해서 보곤 한다. 그래서 각 위치마다 주목해서 보게 되는데, 우리는 이를 attention이라고 부르고 이를 구현해야 하는 것이다.
 구현은 먼저 CNN으로 image에서 feature map을 뽑은 다음에 이 feature map을 RNN에 참조시킨 다음에 RNN에서 나오는 interaction map을 사용하게 된다. 이들을 이용해서 최종적인 output 단어를 prediction하고 이를 이용해서 다시 RNN에서 다음 단어를 prediction하도록 만드는 것이다.
구현은 먼저 CNN으로 image에서 feature map을 뽑은 다음에 이 feature map을 RNN에 참조시킨 다음에 RNN에서 나오는 interaction map을 사용하게 된다. 이들을 이용해서 최종적인 output 단어를 prediction하고 이를 이용해서 다시 RNN에서 다음 단어를 prediction하도록 만드는 것이다.
 좀 더 자세하게 풀어서 살펴보면 image로부터 CNN을 사용해서 visual feature가 spatial dimension과 channel dimension이 있는 상태로 나오게 될 것이다.
좀 더 자세하게 풀어서 살펴보면 image로부터 CNN을 사용해서 visual feature가 spatial dimension과 channel dimension이 있는 상태로 나오게 될 것이다.
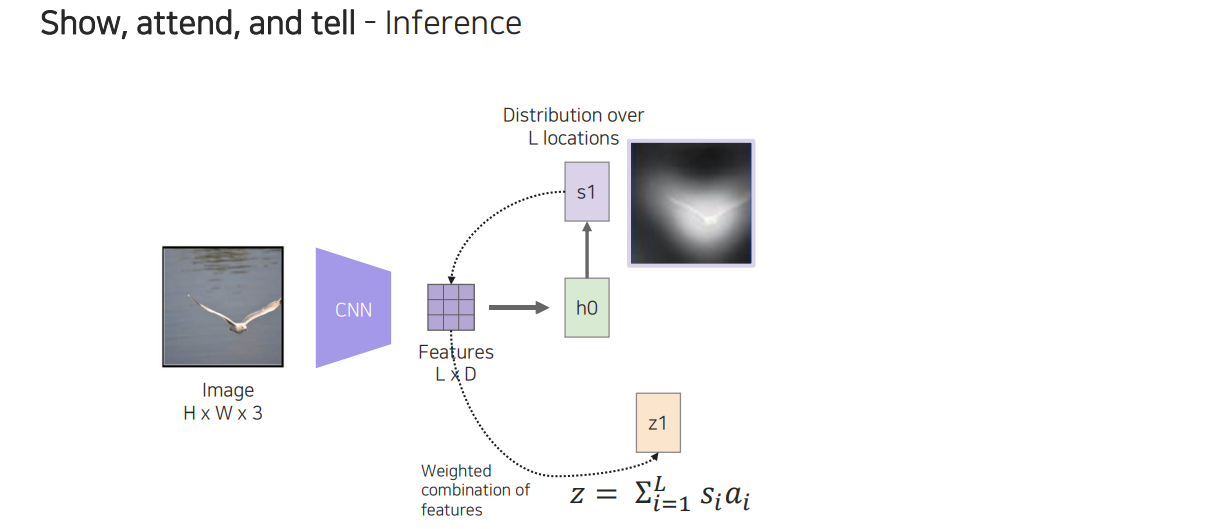 이 feature를 RNN에 넣어주게 되면 위와 같이 RNN output으로 distribution이 나오게 될 것이다. 이를 통해서 어느 부분을 주목해야 하는지 확인할 수 있고, 이를 통해서 feature로부터 해당하는 부분과 linear combination을 해주게 된다. 그러면 feature로부터 가중치가 들어간 feautre를 얻을 수가 있다.
이 feature를 RNN에 넣어주게 되면 위와 같이 RNN output으로 distribution이 나오게 될 것이다. 이를 통해서 어느 부분을 주목해야 하는지 확인할 수 있고, 이를 통해서 feature로부터 해당하는 부분과 linear combination을 해주게 된다. 그러면 feature로부터 가중치가 들어간 feautre를 얻을 수가 있다.
 이렇게 얻은 feature를 단어와 함께 다음 step의 LSTM에 input으로 넣어주게 된다.
이렇게 얻은 feature를 단어와 함께 다음 step의 LSTM에 input으로 넣어주게 된다.
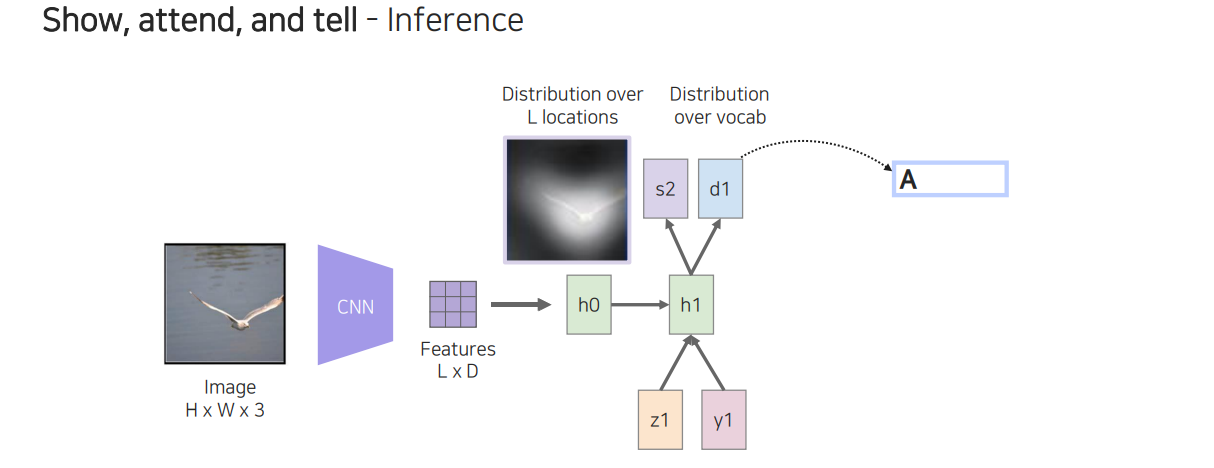 그러면 위와 같이 특정 단어를 하나 출력해주게 될 것이다. 이와 동시에 다음에 봐야할 곳은 어딘지에 관한 spatial distribution을 얻을 수 있게 된다.
그러면 위와 같이 특정 단어를 하나 출력해주게 될 것이다. 이와 동시에 다음에 봐야할 곳은 어딘지에 관한 spatial distribution을 얻을 수 있게 된다.
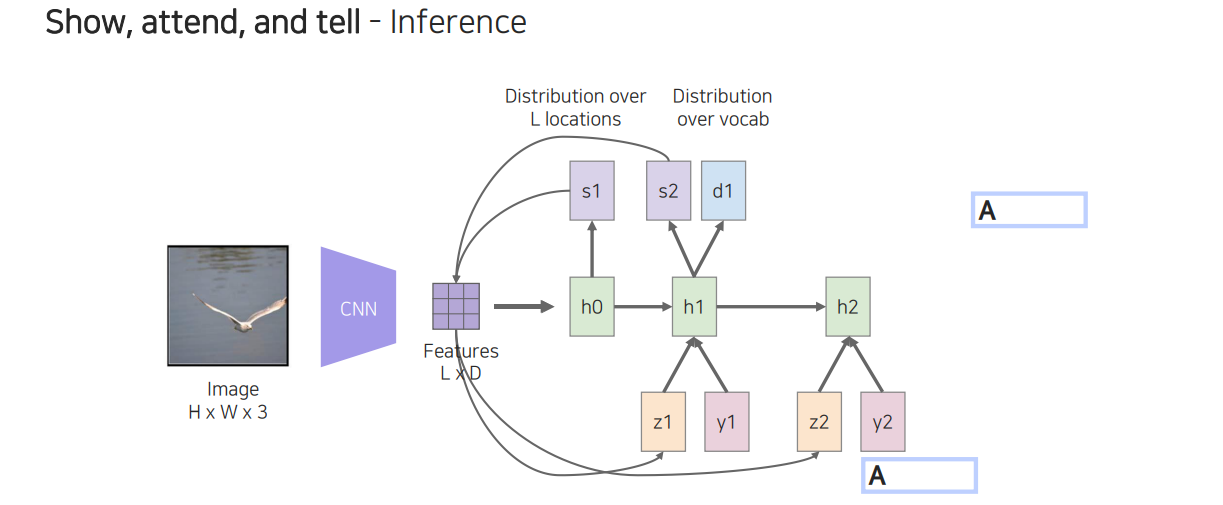 이러한 과정을 계속 반복하면 다음에 주목해야할 곳과 단어를 계속해서 만들어낼 수가 있게 된다.
이러한 과정을 계속 반복하면 다음에 주목해야할 곳과 단어를 계속해서 만들어낼 수가 있게 된다.
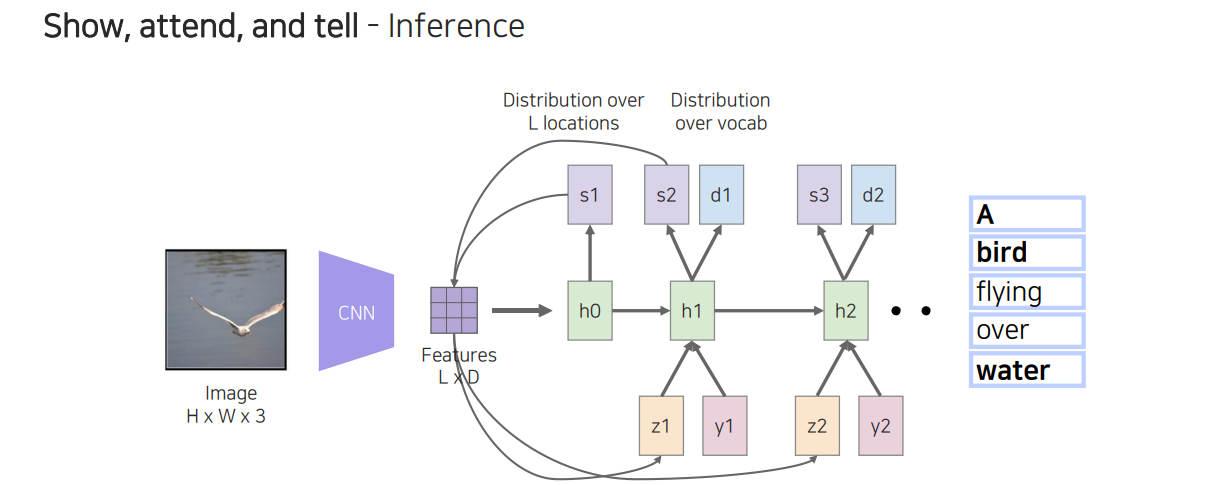 이렇게 많은 과정을 통해서 단어를 순차적으로 얻어낼 수 있고, 이를 통해서 문장을 만들 수가 있다. 정보를 계속 활용하여 다음 단계로 넘어가는 식으로 계속해서 순환하게 된다. 이러한 식으로 image로부터 text를 captioning하는 작업을 수행할 수 있다.
이렇게 많은 과정을 통해서 단어를 순차적으로 얻어낼 수 있고, 이를 통해서 문장을 만들 수가 있다. 정보를 계속 활용하여 다음 단계로 넘어가는 식으로 계속해서 순환하게 된다. 이러한 식으로 image로부터 text를 captioning하는 작업을 수행할 수 있다.
 위와는 반대로 어떠한 text가 주어졌을 때 이를 image로 만들어낼 수도 있다.
위와는 반대로 어떠한 text가 주어졌을 때 이를 image로 만들어낼 수도 있다.
 이를 구현하기 위해서는 generative model에서 볼 수 있는 generator를 사용할 수 있다. Generative model에는 Guassian noise로부터 random vector를 생성하여 사용했었는데, 이와 더불어 우리는 문장이 주어졌을 때 문장과 관련된 조건도 함께 고려하고 싶은 것이다. 그래서 문장을 embedding하여 vector로 바꿔서 generator로부터 image를 만들어낼 수 있다.
이를 구현하기 위해서는 generative model에서 볼 수 있는 generator를 사용할 수 있다. Generative model에는 Guassian noise로부터 random vector를 생성하여 사용했었는데, 이와 더불어 우리는 문장이 주어졌을 때 문장과 관련된 조건도 함께 고려하고 싶은 것이다. 그래서 문장을 embedding하여 vector로 바꿔서 generator로부터 image를 만들어낼 수 있다.
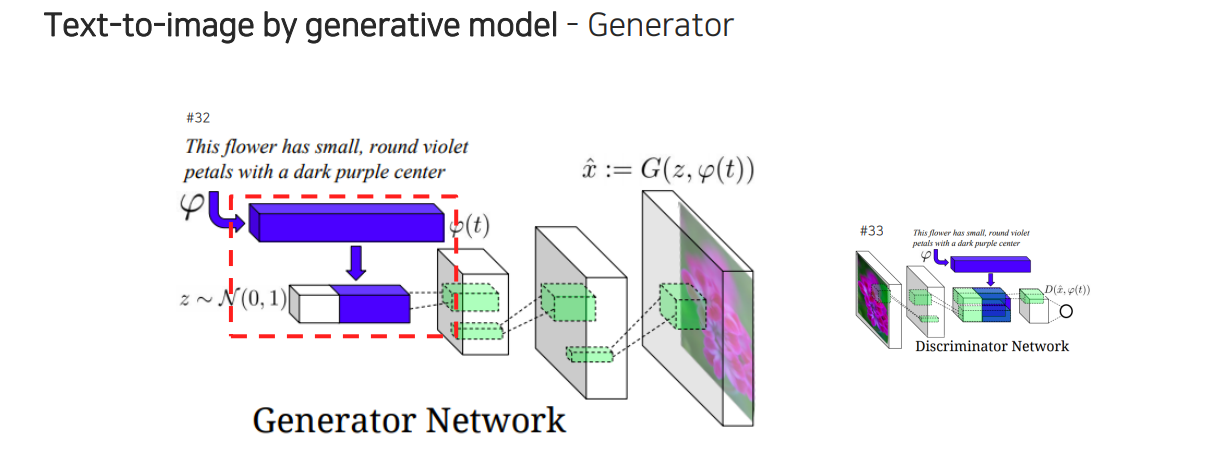 문장이 들어왔을 때 고정된 차원의 vector로 바꾸어 random vector하고 함께 concatenation을 하는 것이 중요한 부분이다. Random vector를 concatenation을 하는 이유는 1:N mapping 관계이기 때문이다. 문장 하나로부터 굉장히 다양한 image를 만들어낼 수가 있어서 random code 없이 학습이 되었을 경우에는 1:1 관계가 아닌 1:N 관계를 학습하려고 하기 때문에 애매한 결과가 나오게 되는 것이다. 그래서 위와 같이 random code를 넣어주게 되면 1:N 관계가 마치 1:1 관계인 것처럼 보여지게 되어 학습이 잘 진행되게 된다.
문장이 들어왔을 때 고정된 차원의 vector로 바꾸어 random vector하고 함께 concatenation을 하는 것이 중요한 부분이다. Random vector를 concatenation을 하는 이유는 1:N mapping 관계이기 때문이다. 문장 하나로부터 굉장히 다양한 image를 만들어낼 수가 있어서 random code 없이 학습이 되었을 경우에는 1:1 관계가 아닌 1:N 관계를 학습하려고 하기 때문에 애매한 결과가 나오게 되는 것이다. 그래서 위와 같이 random code를 넣어주게 되면 1:N 관계가 마치 1:1 관계인 것처럼 보여지게 되어 학습이 잘 진행되게 된다.
 Generator를 학습하기 위해서 discriminator도 필요한데, 이는 CNN을 통해서 feature를 tensor 형태로 우선 만들어준다. 그리고 만들어진 tensor가 정말 실제와 같은지 좀 더 구체적으로 비교하기 위해서 text로부터 똑같이 embedding vector를 만들어서 고정된 차원의 vector로 만들어서 모든 위치에 중복하게 배치를 시켜주어 channel 축으로 concatenation을 해준다. 그러면 feature vector가 각각의 문장으로부터 만들어진 vector와 실제로 같은지 비교 평가하도록 만들 수가 있다. 그래서 input으로 image와 sentense를 함께 참조하여 구분하는 형태로 학습이 진행된다.
Generator를 학습하기 위해서 discriminator도 필요한데, 이는 CNN을 통해서 feature를 tensor 형태로 우선 만들어준다. 그리고 만들어진 tensor가 정말 실제와 같은지 좀 더 구체적으로 비교하기 위해서 text로부터 똑같이 embedding vector를 만들어서 고정된 차원의 vector로 만들어서 모든 위치에 중복하게 배치를 시켜주어 channel 축으로 concatenation을 해준다. 그러면 feature vector가 각각의 문장으로부터 만들어진 vector와 실제로 같은지 비교 평가하도록 만들 수가 있다. 그래서 input으로 image와 sentense를 함께 참조하여 구분하는 형태로 학습이 진행된다.
4. Cross modal reasoning
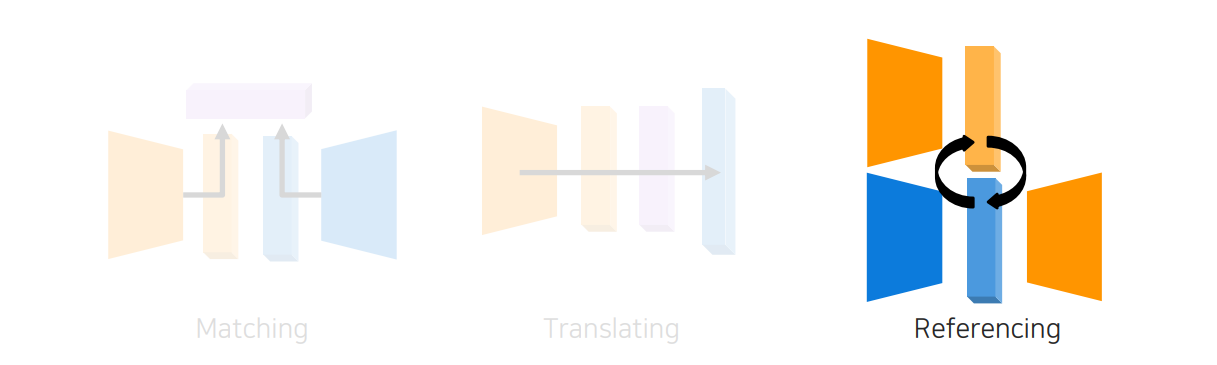 마지막으로 referencing(reasoning)은 input이 들어왔을 때 한쪽의 data를 반복적으로 참조하여 output에 반영하는 식으로 구현하게 된다.
마지막으로 referencing(reasoning)은 input이 들어왔을 때 한쪽의 data를 반복적으로 참조하여 output에 반영하는 식으로 구현하게 된다.
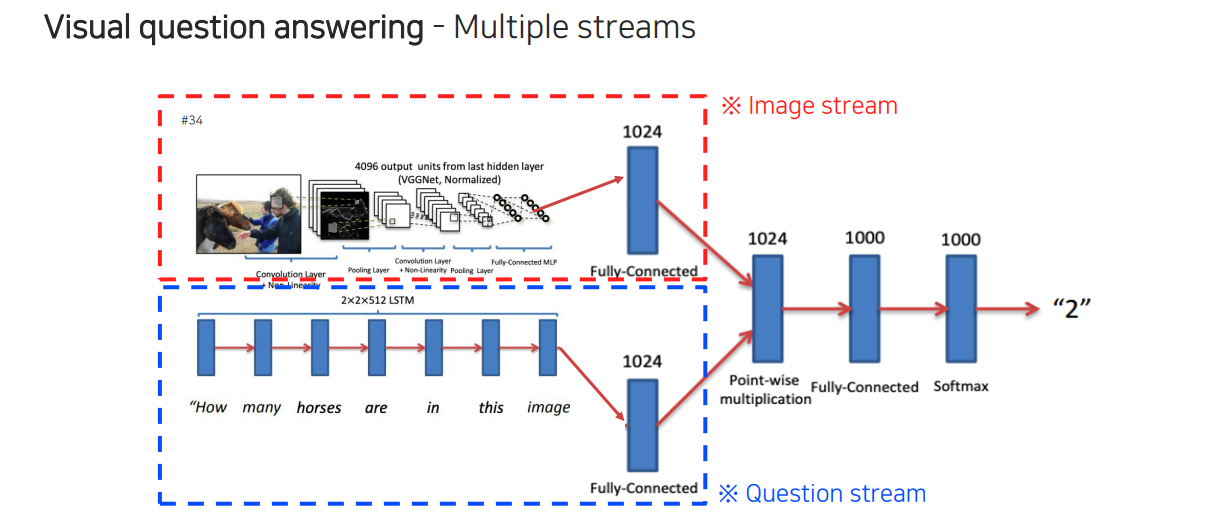 이를 조금 더 복잡한 task로 적용하게 되면 visual question answering과 같은 task를 수행할 수 있다. 먼저 image feature를 뽑아놓고 내가 질문하고자 하는 문장을 넣어서 vector를 만들어낸 다음에 이것을 통해서 질문에 해당하는 답이 출력되도록 image를 참조하도록 만드는 구조이다.
이를 조금 더 복잡한 task로 적용하게 되면 visual question answering과 같은 task를 수행할 수 있다. 먼저 image feature를 뽑아놓고 내가 질문하고자 하는 문장을 넣어서 vector를 만들어낸 다음에 이것을 통해서 질문에 해당하는 답이 출력되도록 image를 참조하도록 만드는 구조이다.
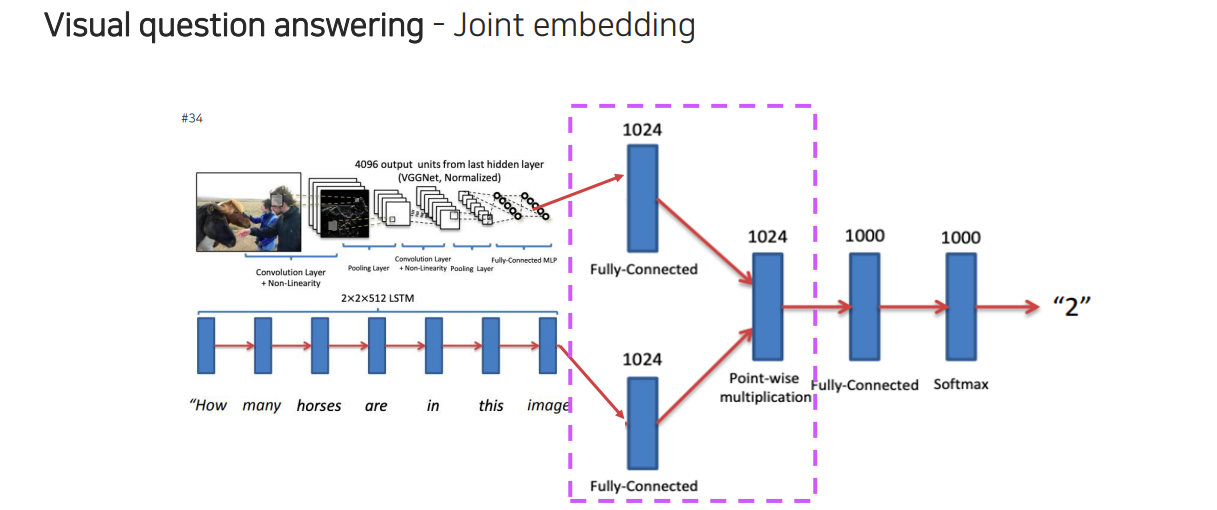 그런데 여기서 위의 부분을 잘 살펴보면 joint embedding과 닮은 부분이 있다. 각각의 vector를 잘 결합하게 되는데 여기서는 point-wise multiplication을 사용한 것이다.
그런데 여기서 위의 부분을 잘 살펴보면 joint embedding과 닮은 부분이 있다. 각각의 vector를 잘 결합하게 되는데 여기서는 point-wise multiplication을 사용한 것이다.
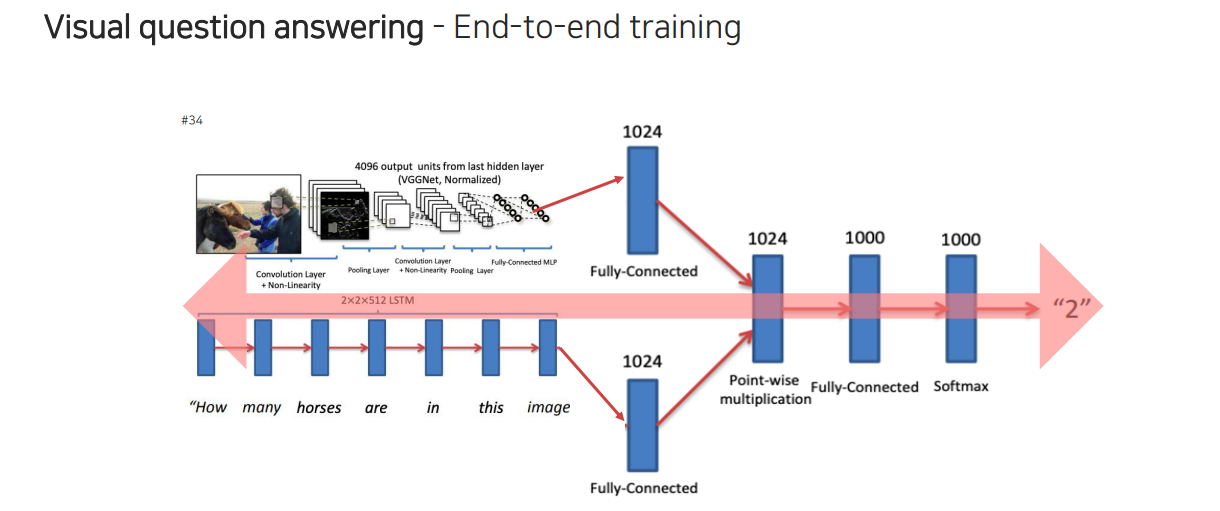 이러한 식으로 end-to-end 구조로 만들 수가 있다.
이러한 식으로 end-to-end 구조로 만들 수가 있다.
