NLP
Natural Language Processing는 오래 되어서 특별한 용어가 있다.
데이터셋을 말뭉치라고 부르기도 한다.
분리된 단어들을 토큰이라고 부를 수 있다.
사람의 언어는 특정한 숫자로 바꿔줘야한다. 전처리 과정이 필요하다.
He(10) follows(11) the(12) cat(13). He(10) loves(14) the(12) cat(13).
분류된 토큰의 집합을 어휘사전이라 부른다.
IMDB 리뷰
감성 분석
긍정 리뷰와 부정 리뷰로 나뉘어져 있다.
케라스로 데이터 불러오기
from tensorflow import keras
import tensorflow as tf
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inlinefrom keras.datasets import imdb
(train_input, train_target), (test_input, test_target) = imdb.load_data(num_words=500)
print(train_input.shape, test_input.shape)
# (25000,) (25000,)# train_input은 넘파이 배열 안에 파이썬 리스트로 이루어진 리뷰들이 들어있다.
print(train_input[0])
# [1, 14, 22, 16, 43, 2, 2, 2, 2, 65, 458, 2, 66,
# 샘플의 시작부분의 토큰은 1이다.
# 2 숫자는 500개의 어휘사전에 포함되지 않은 단어를 의미한다.
print(train_target[:20])
# [1 0 0 1 0 0 1 0 1 0 1 0 0 0 0 0 1 1 0 1]훈련 세트 준비
train_input, val_input, train_target, val_target = train_test_split(train_input, train_target, test_size=0.2, random_state=42)
lengths = np.array([len(x) for x in train_input])
print(np.mean(lengths), np.median(lengths))
# 리뷰들 각각의 길이의 평균과 중간값
# 239.00925 178.0plt.hist(lengths)
plt.xlabel('length')
plt.ylabel('frequency')
plt.show()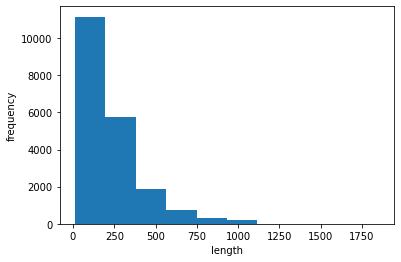
시퀀스 패딩
어떤 문장이 있을때 문장에 토큰을 7개를 사용할때 3개의 토큰만을 사용한다면 나머지 4개의 토큰은 0으로 채워줄 수 있다.

from keras.preprocessing.sequence import pad_sequences
train_seq = pad_sequences(train_input, maxlen=100)
print(train_seq.shape)
# (20000, 100)
print(train_seq[0])
# [ 10 4 20 9 2 364 352 5 45 6 2 2 33 269 8 2 142 2
5 2 17 73 17 204 5 2 19 55 2 2 92 66 104 14 20 93
76 2 151 33 4 58 12 188 2 151 12 215 69 224 142 73 237 6
2 7 2 2 188 2 103 14 31 10 10 451 7 2 5 2 80 91
2 30 2 34 14 20 151 50 26 131 49 2 84 46 50 37 80 79
6 2 46 7 14 20 10 10 470 158]
print(train_input[0][-10:])
# [6, 2, 46, 7, 14, 20, 10, 10, 470, 158]
# 일반적으로 문장을 자를땐 앞부분을 잘라준다.
# 뒷부분에 더 중요한 내용을 답고 있다고 생각하기 때문이다.print(train_seq[5])
# [ 0 0 0 0 1 2 195 19 49 2 2 190 4 2 352 2 183 10
10 13 82 79 4 2 36 71 269 8 2 25 19 49 7 4 2 2
2 2 2 10 10 48 25 40 2 11 2 2 40 2 2 5 4 2
2 95 14 238 56 129 2 10 10 21 2 94 364 352 2 2 11 190
24 484 2 7 94 205 405 10 10 87 2 34 49 2 7 2 2 2
2 2 290 2 46 48 64 18 4 2]
# 이 문장은 길이가 100이 안돼서 앞부분에 패딩 처리를 해주었다.
# 뒷부분에 더 가중치를 두기 위해서이다.val_seq = pad_sequences(val_input, maxlen=100)순환 신경망 모델 만들기
model = keras.Sequential()
# 뉴런의 개수 8개
# 100개의 타임 스텝과 500개의 원핫 인코딩된 단어
model.add(keras.layers.SimpleRNN(8, input_shape=(100,500)))
model.add(keras.layers.Dens(1, activation='sigmoid'))one-hot encoding
각 토큰이 숫자로서 크기를 가지지 않도록 one-hot encoding을 해주어야 한다.
train_oh = keras.utils.to_categorical(train_seq)
val_oh = keras.utils.to_categorical(val_seq)
print(train_oh.shape)
# (20000, 100, 500)
print(train_oh[0][0][:12])
# 첫번째 문장의 첫번째 토큰을 12번째 one-hot encoding 값을 본다.
# [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]
print(np.sum(train_oh[0][0]))
# 1.0모델 구조 확인
500개의 입력에 x 8개의 뉴런이 완전연결이 되고,
순환되는 은닉상태의 개수는 뉴런의 개수이며
이 은닉상태는 완전연결이 되기 때문에 8x8
각 뉴런별로 1개의 절편이 있어서 8
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn_1 (SimpleRNN) (None, 8) 4072
dense (Dense) (None, 1) 9
=================================================================
Total params: 4,081
Trainable params: 4,081
Non-trainable params: 0
_________________________________________________________________모델 훈련
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model.compile(optimizer=rmsprop, loss='binary_crossentropy', metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-simplernn-model.h5')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3, restore_best_weights=True)
history = model.fit(train_oh, train_target, epochs=30, batch_size=64, validation_data=(val_oh, val_target), callbacks = [checkpoint_cb, early_stopping_cb])plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()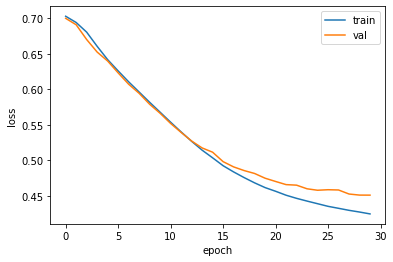
임베딩 벡터
one-hot encoding은 모델 학습에 효율이 떨어진다.
어휘사전과 패딩의 크기를 늘리면 차원의 크기가 급격하게 늘어난다는 단점이 있다.
또한 각각의 단어 간의 관계를 무시한채 인코딩을 하기때문에 아쉽다.
임베딩 벡터는 단어를 벡터값들로 채우기 때문에
두 단어 사이의 거리를 통해 가까운 정도를 찾아낼 수 있다.
개수도 많이 줄일 수 있다.
차원의 개수가 많이 줄어도 비슷한 결과를 만들어낸다.
model12 = keras.Sequential()
# 500개의 어휘사전을 분류해야하는
# 16개의 벡터를 만든다.
model12.add(keras.layers.Embedding(500, 16, input_length=100))
model12.add(keras.layers.SimpleRNN(8))
model12.add(keras.layers.Dense(1, activation='sigmoid'))
model12.summary()
# 500 x 16
# 16 x 8 + 8 x 8 + 8
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 100, 16) 8000
simple_rnn_2 (SimpleRNN) (None, 8) 200
dense_1 (Dense) (None, 1) 9
=================================================================
Total params: 8,209
Trainable params: 8,209
Non-trainable params: 0
_________________________________________________________________
chords & code // harmony with structure