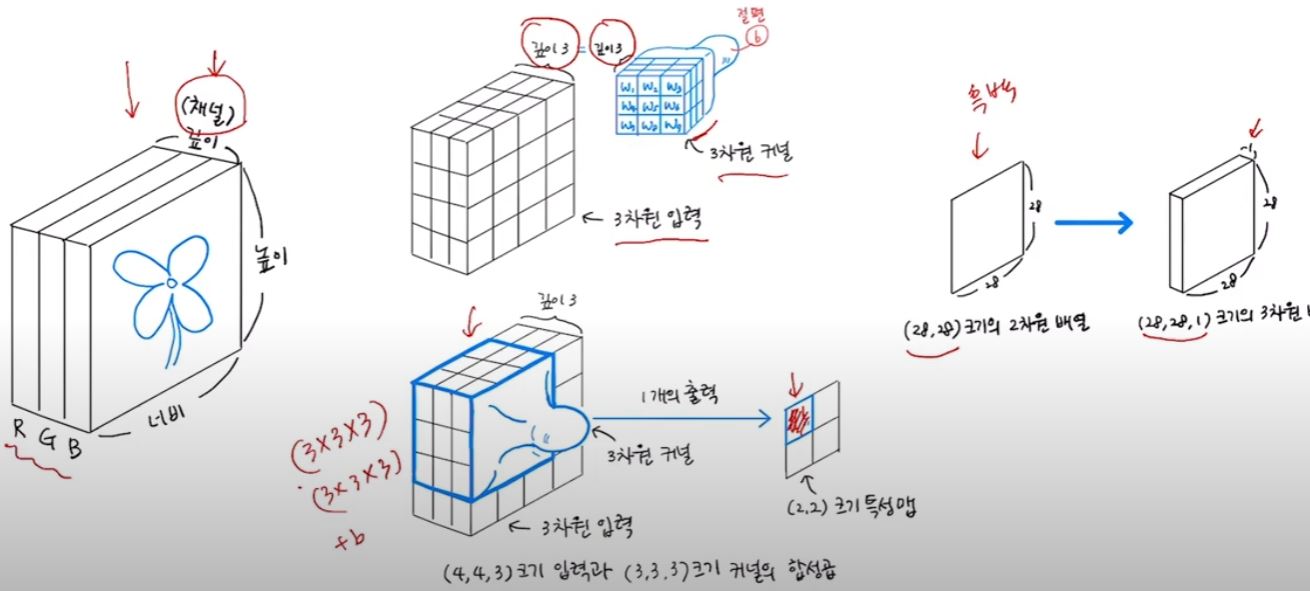
합성곱 신경망의 개념과 동작 원리 배우기
밀집층
각 특성에 뉴런의 가중치 곱하고 절편 더하기 -> 1개의 출력
ex) x1w1 + x2w2 + x3w3 + ... + x10w10 + b
2차원 이미지를 1차원으로 처리하는 방법이다.
합성곱
가중치 3개에 절편은 1개라면
0-2 특성에 뉴런(합성곱 층의 뉴런)의 가중치 w곱하고 절편 더하기 -> 1개의 출력
1-3 특성에 뉴런(합성곱 층의 뉴런)의 가중치 w곱하고 절편 더하기 -> 1개의 출력
2-4 특성에 뉴런(합성곱 층의 뉴런)의 가중치 w곱하고 절편 더하기 -> 1개의 출력
...
7-8 특성에 뉴런(합성곱 층의 뉴런)의 가중치 w곱하고 절편 더하기 -> 1개의 출력
총 8개의 출력
커널 = 필터 = 가중치
2차원 합성곱은 커널의 사이즈가 마스크처럼 슬라이딩하며 씌여진다고 생각하면 된다.
4x4사이즈에 3x3커널을 씌운다면(절편이 포함) 출력은 2x2가 된다. 이 출력을 특성맵이라고 한다.
다만 마스크가 씌여질때마다 활성화 함수가 적용이 된다.
합성곱은 2차원 입력이면 2차원 출력을 만들어 낸다.
여러 개의 필터
4x4사이즈 인풋에 3x3 필터 3개(절편도 3개)를 사용한다면 2x2 출력이 3개가 되어
출력은 (2,2,3)이 된다. 다시말해서 특성맵의 마지막 차원은 필터의 개수에 대응이 된다.
케라스 합성곱 층
커널의 크기가 크면 특징을 잡는 능력이 떨어진다고 알려져 있다.
from tensorflow import keras
# 필터가 10개이며 3x3사이즈이다.
kears.layers.Conv2D(10, kernel_size=(3,3), activation='relu')패딩
필터를 사용하면 인풋의 사이즈가 작아지게 된다. 따라서 패딩으로 인풋을 둘러싸게되면 사이즈의 크기를 조절할 수 있게 된다. same padding으로 4x4를 패딩해주면 3x3커널의 아웃풋이 4x4로 나오게 된다.
패딩을 사용하지 않으면 픽셀마다 합성곱 연산에 기여하는 정도가 달라진다.
4x4인풋에 3x3커널을 사용하면 모서리 픽셀은 1번, 전후좌우 픽셀은 2번, 가운데 픽셀은 4번 참여를 하게 된다. 만약 패딩을 사용하게 되면 참여 횟수가 4, 6, 9번으로 늘어나게 된다.
케라스 패딩 설정
'valid' 패딩을 사용하면 특성맵의 크기가 줄어들게 된다.
keras.layers.Conv2D(10, kernel_size=(3,3), activation='relu', padding='same')스트라이드
커널을 얼마나 이동할지를 정한다.
4x4사이즈 인풋에 패딩을하고 스트라이드를 2로 지정하면 특성맵의 크기는 2x2가 된다.
케라스의 스트라이드 설정
keras.layers.Conv2D(10, kernel_size=(3,3), activation='relu', padding='same', strides=1)풀링
합성곱층은 입력과 특성맵의 크기를 동일하게 만드는 same패딩을 많이 사용한다.
풀링층은 특성맵의 크기를 줄이는 역할을 한다. (2,2,3)에 2x2풀링층을 사용하면 (1,1,3)이 된다.
평균 풀링과 최대 풀링을 많이 사용한다. 가중치 연산이 아니다.
또한 풀링층은 특성맵의 마지막 차원인 채널차원은 변경하지 않는다.
혹은 풀링은 채널차원마다 적용이 된다.
풀링은 겹치지 않기 때문에 2x2 풀링층이라면 자동으로 strides가 2가 된다.
케라스의 풀링층
keras.layers.MaxPooling2D(2)
# strides와 padding은 생략해도 된다.
keras.layers.MaxPooling2D(2, strides=2, padding='valid')합성곱 신경망의 구조

3차원 합성곱
커널을 도장을 찍는 것처럼 이해를 한다면 한번의 도장이 하나의 특성맵을 만든다고 이해를 하면 된다.
다만 커널이 여러개라 도장이 여러개라면 매번 새로운 도장을 사용할 때마다
그 특성값들이 특성맵의 마지막 차원에 쌓아나간다고 생각하면 될 것 같다.
합성곱 신경망을 사용한 이미지 분류
데이터 준비하기
from tensorflow import keras
import tensorflow as tf
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inlinetrain_scaled = train_input.reshape(-1, 28, 28, 1) / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
print(train_scaled.shape, train_target.shape)모델 만들기
첫번째 합성곱 층

model = keras.Sequential()
model.add(keras.layers.Conv2D(32, kernel_size=3, activation='relu', padding='same', input_shape=(28,28,1)))
model.add(keras.layers.MaxPooling2D(2))두번째 합성곱 + 완전연결층

model.add(keras.layers.Conv2D(64, kernel_size=(3,3), activation='relu', padding='same'))
model.add(keras.layers.MaxPooling2D(2))
model.add(keras.layers.Flatten())
# 은닉층
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dropout(0.4))
# 출력층
model.add(keras.layers.Dense(10, activation='softmax'))
keras.utils.plot_model(model, show_shapes=True)
컴파일과 훈련
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
checkpoin_cb = keras.callbacks.ModelCheckpoint('best-cnn-model.h5')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2, restore_best_weights=True)
history = model.fit(train_scaled, train_target, epochs=20, validation_data=(val_scaled, val_target), callbacks=[checkpoin_cb, early_stopping_cb])평가와 예측
model.evalutae(val_scaled, val_target)
# loss : 0.2118 - accuracy : 0.9212
plt.imshow(val_scaled[0].reshape(28,28), cmap='gray_r')
plt.show()
preds = model.predict(val_scaled[0:1])
print(preds)
[[각 class에 해당하는 softmax값]]테스트 세트 점수
test_scaled = test_input.reshape(-1,28,28,1) / 255.0
model.evaluate(test_scaled, test_target)
# loss : 0.2360 - accuracy : 0.9163합성곱 신경망의 시각화
가중치 시각화
model.layers
[<keras.layers.convolutional.Conv2D at 0x7f58939fac50>,
<keras.layers.pooling.MaxPooling2D at 0x7f589365d850>,
<keras.layers.convolutional.Conv2D at 0x7f589365f590>,
<keras.layers.pooling.MaxPooling2D at 0x7f589394a050>,
<keras.layers.core.flatten.Flatten at 0x7f5893615690>,
<keras.layers.core.dense.Dense at 0x7f58936bc650>,
<keras.layers.core.dropout.Dropout at 0x7f588fe710d0>,
<keras.layers.core.dense.Dense at 0x7f589393c090>]conv = model.layers[0]
print(conv.weights[0].shape, conv.weights[1].shape)
# (3, 3, 1, 32) (32,)
conv_weights = conv.weights[0].numpy()
plt.hist(conv_weights.reshape(-1,1))
plt.xlabel('weights')
plt.ylabel('count')
plt.show()
가중치의 초기값은 균등분포의 형태로 평균이 0에 가까운 값들로 구성된다.
층의 가중치 시각화
fig, axs = plt.subplots(2,16, figsize=(15,2))
for i in range(2):
for j in range(16):
axs[i, j].imshow(conv_weights[:,:,0,i*16 +j], vmin=-0.5, vmax=0.5)
axs[i, j].axis('off')
plt.show()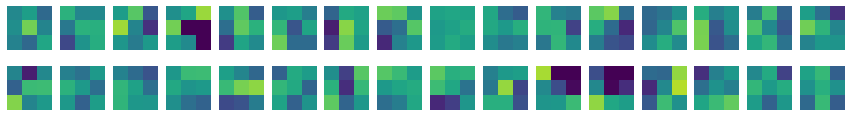
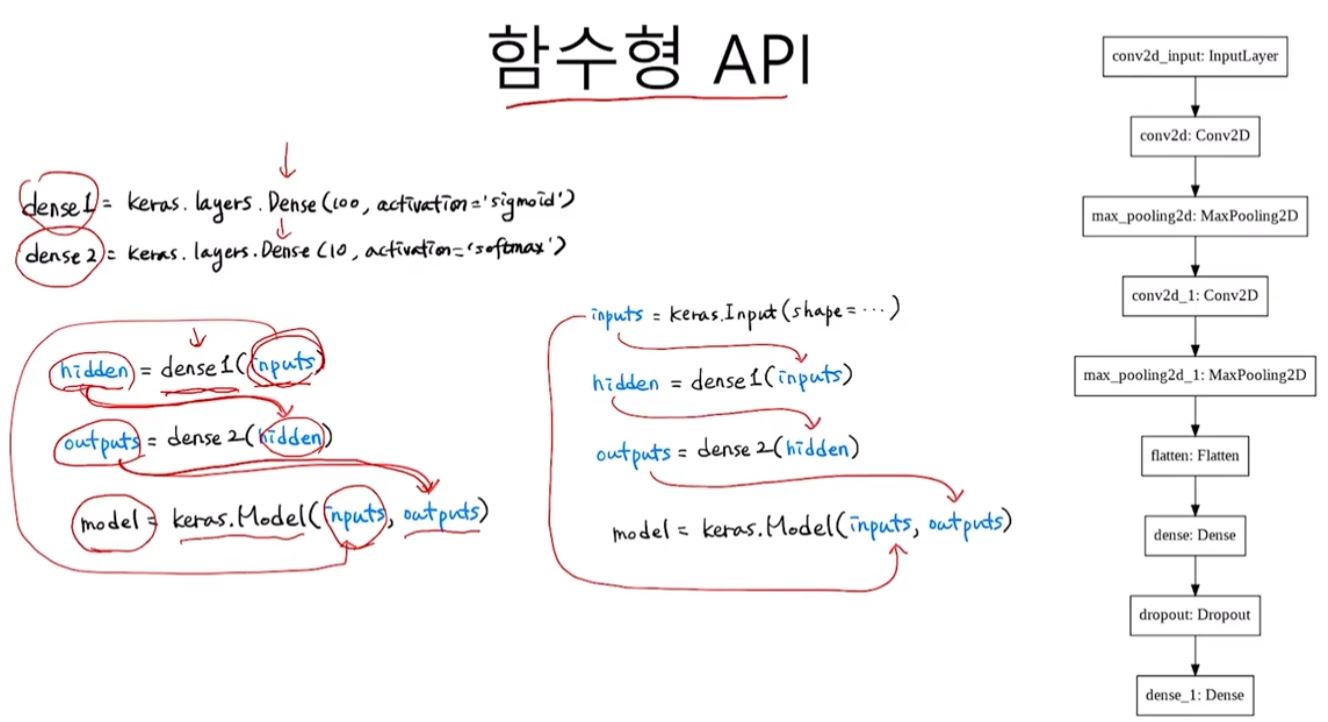
함수형 API
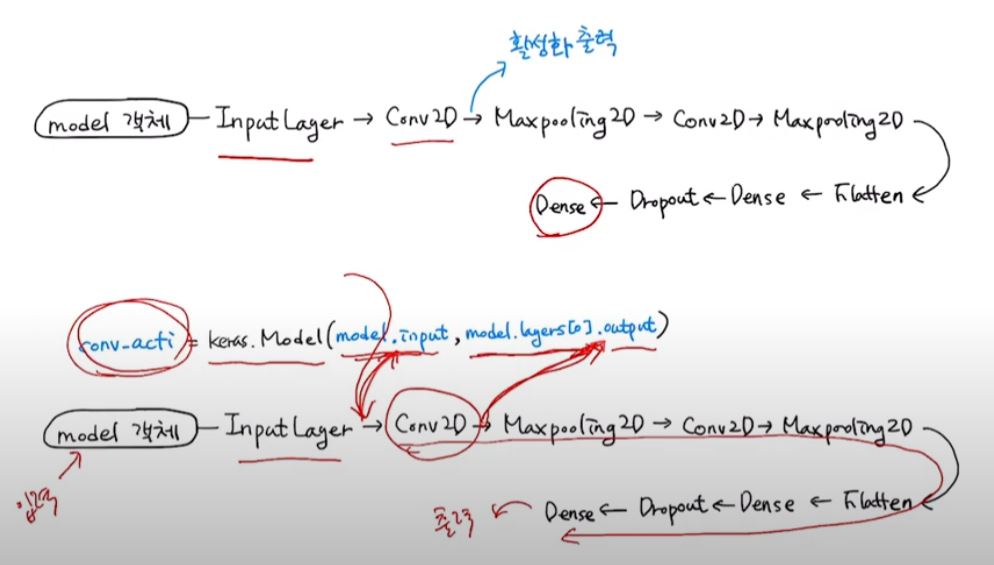
층을 통과한 값의 시각화
plt.imshow(train_input[0:1][0,:,:]/ 255.0)
plt.imshow(train_input[0:1][0,:,:])
# 둘의 그림은 같다??
conv_acti = keras.Model(model.input, model.layers[0].output)
inputs = train_input[0:1].reshape(-1,28,28,1) / 255.0
feature_maps = conv_acti.predict(inputs)
print(feature_maps.shape)
# (1, 28, 28, 32)fig, axs = plt.subplots(2,16, figsize=(20,4))
for i in range(2):
for j in range(16):
axs[i, j].imshow(feature_maps[0,:,:,i*16 +j])
axs[i, j].axis('off')
plt.show()
