Introduction
Irish folk 음악과 관련한 대회에 연구실에서 참가를 하게 되었다. 생성 모델에 관심이 깊었던만큼 나도 이번에 공부를 하게 될 것들에 기대가 크다. 대회는 총 3파트에 대해서 진행이 되는데 첫 번째는 멜로디 생성 모델, 두 번째는 표절과 리듬, 모드, structure, melody를 판단하는 모델, 세 번째는 주어진 tune에 대해 제목을 생성하는 모델이다. 우선 이번에 정리를 해볼 내용은 tune을 생성하는 모델과 tune에 맞는 제목을 생성하는 모델에 관한 내용이다.
melody generation model
멜로디를 생성하는 것은 Language model을 만드는 것과 다름이 없다. 다만 이번에는 내가 처음으로 모델을 만들어보고 실험을 하게 되어서, 좀더 구조적으로 접근을 해야할 필요가 있었다. 교수님께서 제안해주신 형태는 loss, model, trainer, utils로 구성된 파일들에 사용할 기본적인 함수들을 정리해두되 jupyter notebook에는 실험해볼 모델들을 만들어서 학습하고, 검증하는 방식이다.
title embedding model
제목을 생성하는 것은 처음 해보는 작업이었다. 우선 tune과 title의 임베딩 값을 representation learning을 할 필요가 있었다. 이 방식으로 tune과 title의 유사성을 캐치하는 모델을 만들 수 있다면, 새로운 tune에 대해서 적절한 임베딩을 계산한 뒤 수많은 타이틀 중에서 cosine 유사도를 활용해 적절한 타이틀을 골라내는 작업을 할 수 있을 것이다.
Obstacles & Walkthrough
melody generation model
data utils
dataloader를 사용하기 위해서는 index에 대해서 필요로 하는 데이터를 적절하게 return할 수 있는 dataset class를 만들어 줄 필요가 있다. abc 기보는 일정한 rule을 바탕으로 사용되기 때문에 abc 방식을 사용한 악보 데이터들을 tokenizing 하기 위해서는 이미 만들어져 있는 tokenizer인 pyabc 혹은 music21을 사용해야한다. 문제는 많은 수의 악보들이 표기가 잘못된건지 읽어지지 않는다는 것이다. 따라서 우선 try except 구문으로 읽어지는 친구들만 사용하기로 했다.
(아직 대회에 참가중이라 전체 코드를 오픈하지는 못하고 공유하면 좋을 부분만 올리겠습니다.)(대회 참가 팀이 7팀인건 안비밀...!)
# rglob을 이용해서 abc인 친구들을 모아주고
# 이 친구들은 .abc인 object이기 때문에 pyabc로 읽어주면 된다.
abc_list = list(self.dir.rglob('*.abc')) + list(self.dir.rglob('*.ABC'))
def tune_to_list_of_str(tune):
return [token._text for token in tune.tokens]# dataset의 구성은 3가지로 __init__에서 tune들을 모아주고,
# _get_vocab으로 tune의 모든 token들의 set을 만들어준 뒤 여기에 pad, start, end를 더해준다.
# 추가적으로 token to index dictionary를 만들어 준다.
# 결국 이 함수는 self.vocab, self.tok2idx를 만드는 역할을 한다.
# 이 함수는 __init__에서 실행해주면 된다.
# 마지막으로 __getitel__을 만들어서 노래(idx)에 맞는 token들의
# tune_tensor를 학습할 친구([:-1])와 타겟 친구([1:])로 짝을 맞추어 내보내주면 된다. packed sequence
rnn의 효율적인 연산을 위해서 packed sequence를 사용한다. 설명은 아래의 링크를 참조하는게 더 좋을 것 같다.
https://simonjisu.github.io/nlp/2018/07/05/packedsequence.html
language model
기본 모델은 embedding, rnn, linear로 구성한다. 인풋은 dataloader에서 packed squence를 사용한다. 따라서 모델의 구조를 벡터의 크기를 따라 생각해보면 (total_token)이 인풋일때 emb를 거치면 (total_token x embedding dim), rnn을 거치면 (total_token x hidden dim), linear를 거치면 (total_token x vocab size)가 된다.
# 모델은 __init__과 forward, inference로 이루어져 있다.
def forward(self, input_seq):
if isinstance(input_seq, PackedSequence):
emb = PackedSequence(self.emb(input_seq[0]), input_seq[1], input_seq[2], input_seq[3])
hidden, _ = self.rnn(emb)
logit = self.proj(hidden.data) # output: [num_total_notes x vocab_size].
prob = logit.softmax(dim=-1)
prob = PackedSequence(prob, input_seq[1], input_seq[2], input_seq[3])
else:
pass
return probinference를 할때 학습시와는 다르게 rnn에 last_hidden을 따로 넣어주어야 한다. 이후에는 while문으로 end token이 나올때까지 계속해서 token을 생성하게 한다.
def inference(self, start_token_idx=1, manual_seed=0):
'''
x can be just start token or length of T
'''
selected_token = torch.LongTensor([start_token_idx]).to(self.emb.weight.device)
last_hidden = torch.zeros([self.rnn.num_layers, 1, self.rnn.hidden_size]).to(self.emb.weight.device)
total_out = []
torch.manual_seed(manual_seed)
while True:
emb = self.emb(selected_token.unsqueeze(0)) # embedding vector 변환 [1,128] -> [1, 1, 128]
hidden, last_hidden = self.rnn(emb, last_hidden)
logit = self.proj(hidden)
prob = torch.softmax(logit, dim=-1)
selected_token = prob.squeeze().multinomial(num_samples=1)
if selected_token == 2: # Generated End token
break
total_out.append(selected_token)
return torch.cat(total_out, dim=0)trainer
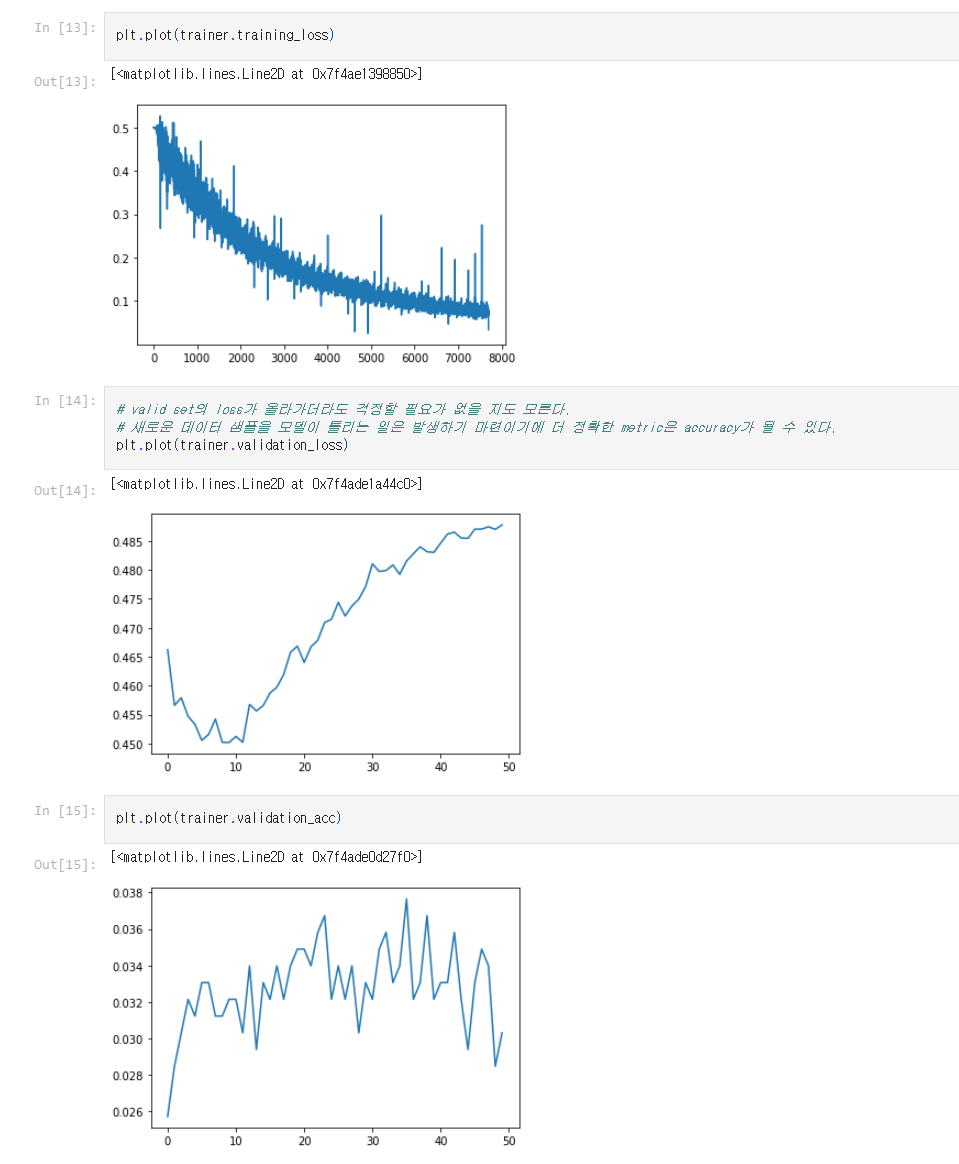
trainer는 데이터셋을 train용과 validation용으로 나뉘어서 만들어준다. epoch를 특정 횟수를 반복한다면 1번의 epoch안에서 특정한 batch 크기 만큼 데이터를 학습을 할 train_by_single_batch 함수가 필요하다. 이 함수는 return으로 그 배치에 대한 loss를 내주며 학습이 되었기 때문에 이 학습을 평가하기 위해 validate함수를 사용한다. 이 함수는 return으로 validation에 대한 loss accuracy를 내보낸다. 물론 validation은 모든 valid data에 대해서 이루어져야 한다. 학습은 배치 단위로 이루어지지만 평가는 모든 valid 데이터를 통해 이루어져야 같은 조건하에서 평가가 이루어질 수 있을 것이다.
이로써 기본적인 모델이 만들어졌다. 하지만 이로는 아직 부족하다. 추가적으로 리듬꼴을 학습하거나, key 등의 정보를 제공해서 학습을 할 수 있도록 해야한다. 또한 모델의 구조 자체를 rnn이 아니라 transformer로 바꿔줄 수도 있을 것이다. 이는 계속해서 실험하며 결과를 확인하고 발전시키는 과정이 필요로 할 것 같다.
title embedding model
embedding 모델은 tune, title의 두 가지가 필요하다. 이 두 모델이 각각 같은 사이즈의 임베딩을 만들어내면 그 둘을 비교해서 loss를 만들어 내면 된다.
hinge loss
loss 함수를 구하는 과정이 꽤 까다로웠다. 처음에 나는 loss 함수를 abc와 title의 두 positive 쌍의 embedding 사이의 cosine 유사도를 -로 잡으면 될거라고 생각했다. 간단히 표현하면 loss = - cos_sim(abc, ttl)이다. 이렇게 하면 두 임베딩이 가까울 수록 loss함수가 낮아지니까 학습이 가능할 거라고 생각을 했는데 결과적으로 이 함수는 틀렸다. 이유는 아래의 그림으로 설명이 가능한데 가령 이번 학습으로 abc와 ttl을 가까이 만들더라도 다음 학습에서는 rest에 있는 친구들 중에 하나의 쌍으로 인해 모델이 계속해서 극단적인 학습을 반복하게 되기 때문이다.(이 부분은 제 이해가 정확하지 않을 수도 있습니다.)
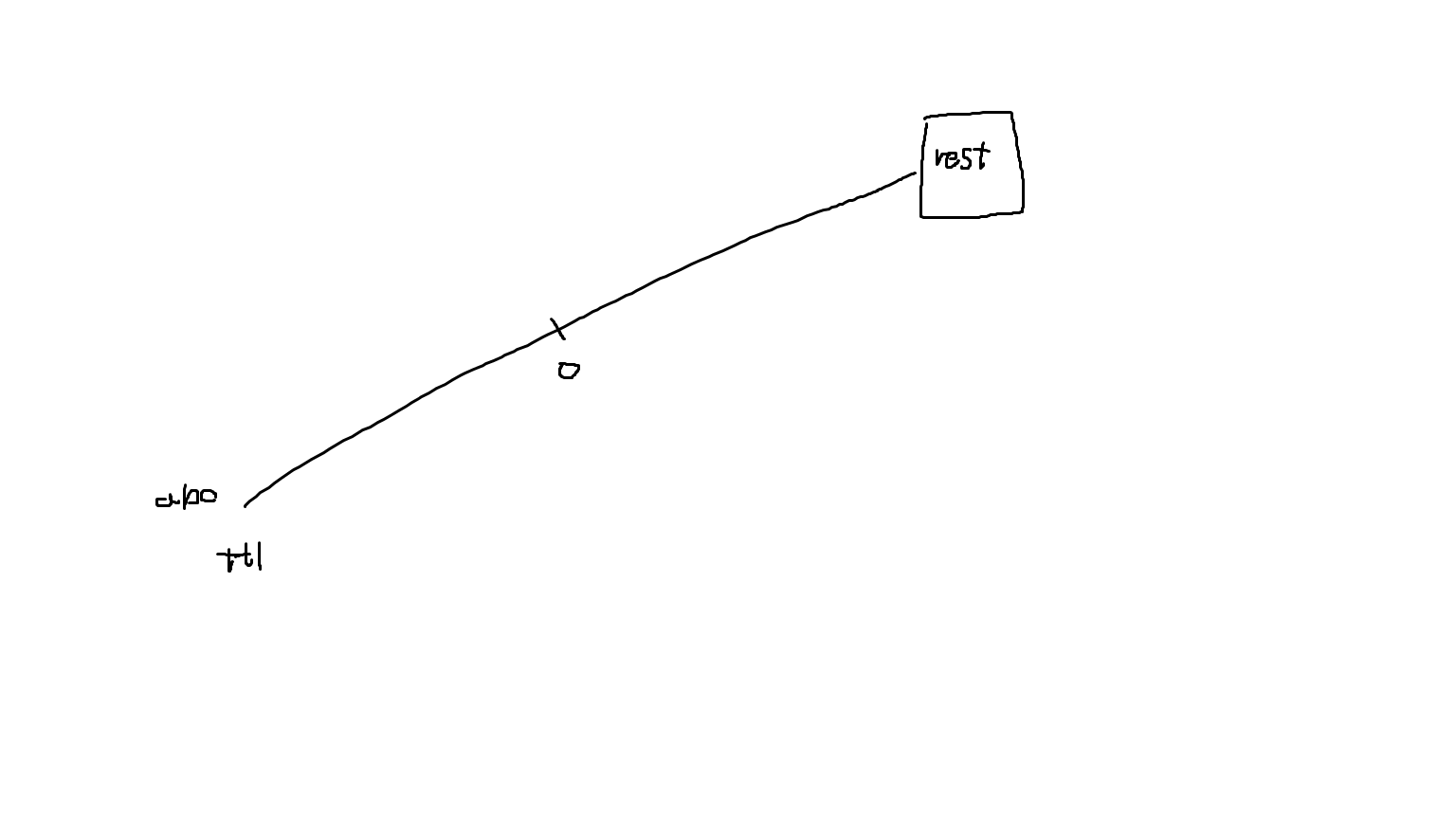
따라서 해당 링크의 https://arxiv.org/abs/1710.06648 에서 representation learning에 사용한 hinge loss를 사용하게 되었다. hinge loss를 사용하게 되면 마진을 넘기는(적절하게 학습이 된 상황) 경우에는 - 값이 되어버려 max값을 거치면 loss 값이 0이 되어서 학습이 되지 않게 된다.

batch를 고려했을 때 이 알고리즘을 구현하는 것이 꽤 어려웠다. 아래 코드는 정다샘 교수님께서 정리를 해주신 코드이다. 만약에 batch가 5개라면 이 5개 안에서 loss를 구할 수 있는 함수가 필요할 것이다. 그리고 이 계산은 cosine 유사도를 활용하기 때문에 cosine 연산을 풀어서 매트릭스 곱과 norm으로 나눠주는 계산으로 접근을 해볼 수 있다. 즉 embedding 벡터 간의 곱으로 5 x 5 행렬을 만들어주고 이를 해당하는 embedding 요소의 norm으로 나눠주면 된다. 좀 지저분 하지만 아래의 그림을 참고해 보면 이후의 작업은 동그라미에 해당하는 positive_sim 5개의 벡터를 구하고 non_diag_index를 2개의 리스트로 만들어 준뒤에 세모에 해당하는 negative_sim을 구해서 torch.clamp를 이용해서 max 연산을 통과한 값들만을 추출해낸다.
이 방법을 사용하면 적절하게 학습된 친구들의 경우에 loss값이 추가되질 않아서 모델의 과도한 학습을 방지할 수 있게 된다.
def get_batch_contrastive_loss(emb1, emb2, margin=0.4):
num_batch = len(emb1)
dot_product_value = torch.matmul(emb1, emb2.T)
emb1_norm = norm(emb1, dim=-1)
emb2_norm = norm(emb2, dim=-1)
cos_sim_value = dot_product_value / emb1_norm.unsqueeze(1) / emb2_norm.unsqueeze(0)
positive_sim = cos_sim_value.diag().unsqueeze(1) # N x 1
non_diag_index = [x for x in range(num_batch) for y in range(num_batch) if x!=y], [y for x in range(len(cos_sim_value)) for y in range(len(cos_sim_value)) if x!=y]
negative_sim = cos_sim_value[non_diag_index].reshape(num_batch, num_batch-1)
loss = torch.clamp(margin - (positive_sim - negative_sim), min=0)
return loss.mean()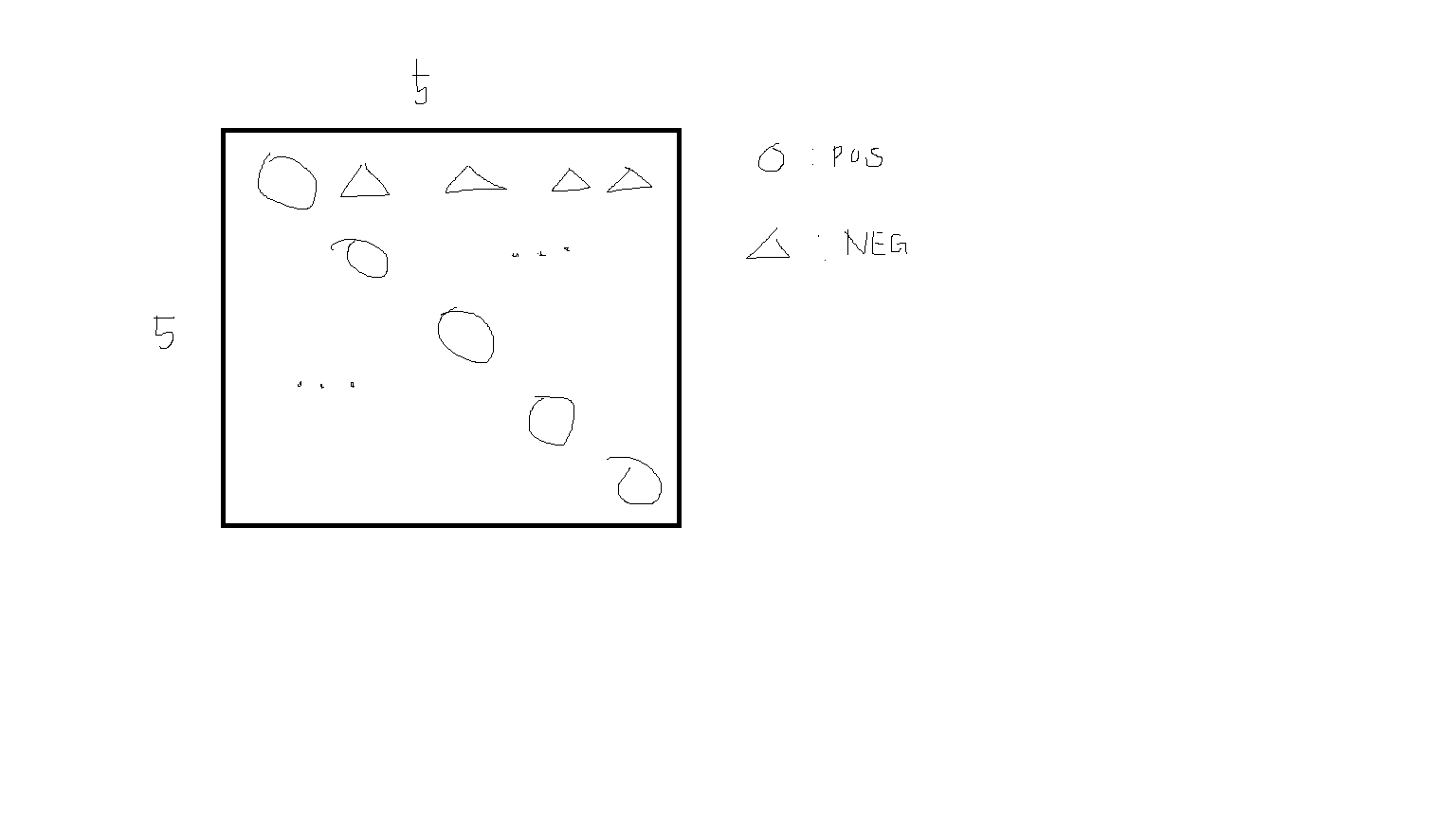
title embedding model
title의 경우에는 tokening을 좀더 고려를 해야하는 것이, 이미 vocab의 크기가 정해진 abc tune과는 다르게 title은 이전에는 없었던 단어들의 embedding을 구할 필요가 있다. 따라서 title들을 기존의 pretrained bert 모델을 활용해서 특정 embedding으로 한번 바꿔준 뒤에 그것을 우리가 원하는 차원의 embedding으로 다시 바꿔주는 모델을 만들었다. 여기에서 편의를 위해서 dataset을 구성할때 title string을 vector로 미리 바꾸어 주는 작업을 했다. 이렇게 하면 dataloader가 일정한 길이의 벡터들을 뽑아낼 수 있게 되어서 title embedding model에서는 이 벡터들을 layer에 올려주기만 하면 된다.
# 문장의 embedding을 뽑는 방법으로 sentence transformer를 사용했다.
# 384차원으로 만들어주기 때문에 벡터를 batch에 맞게 넣어주면 된다.
def _get_title_emb(self):
model = SentenceTransformer('all-MiniLM-L6-v2')
#self.ttl2emb = [model.encode(title) for title in self.title]
self.ttl2emb = model.encode(self.title, device='cuda')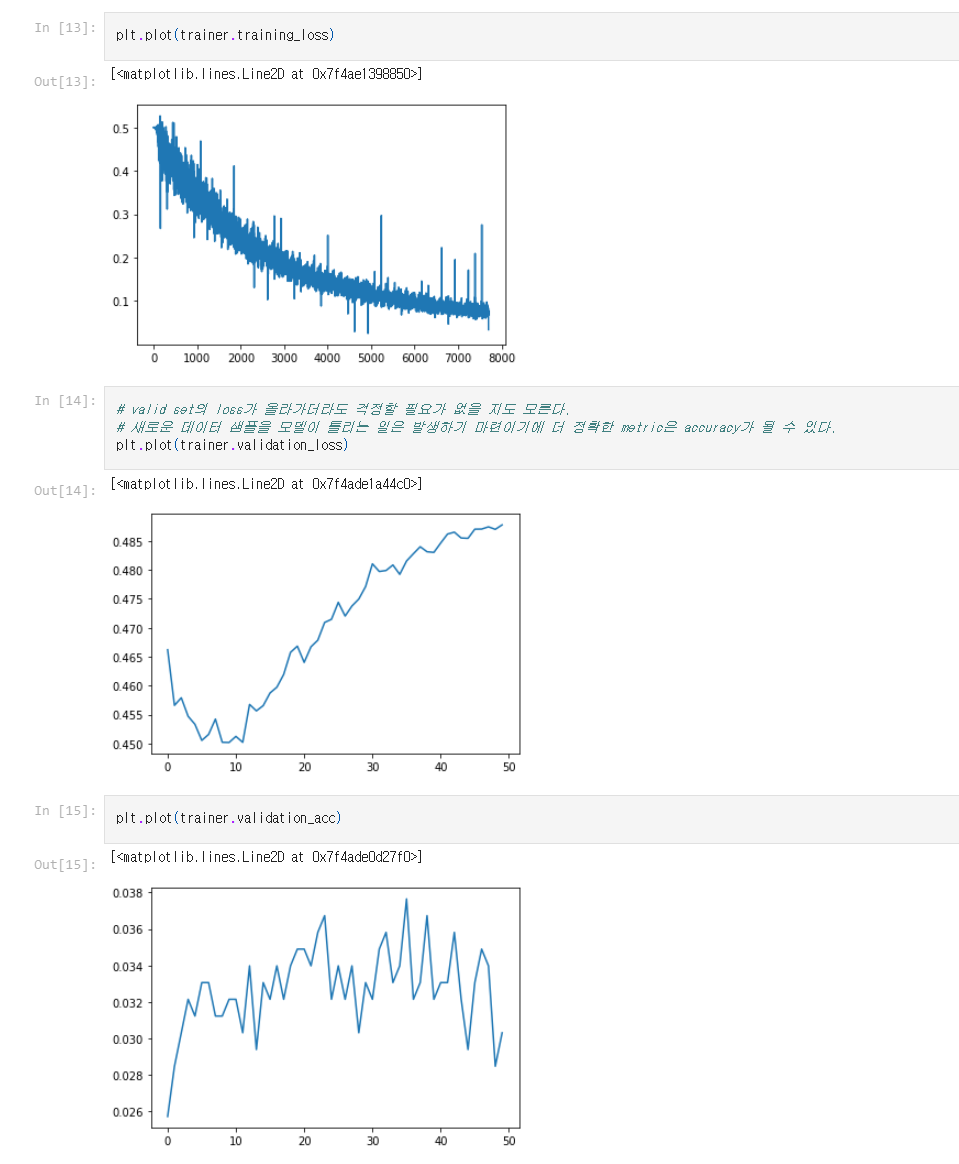
이후에는 trainer를 조금 손봐서 모델의 성능을 평가하는 평가대?를 만들어 두었다. 결과가 그리 좋지는 못하지만 이를 바탕으로 실험을 해나가면 될 것 같다.

Elevate your music production game with innovative software like Ableton Live and FL Studio. Dive into a world of endless possibilities where you can create, edit, and mix your tracks with ease. Whether you're a seasoned pro or just starting out, these DAWs provide the tools and inspiration to bring your musical vision to life. Let your creativity flow and start Producing Music that moves the masses.