Introduction
음원 데이터를 정해진 분류대로 레이블링 하는 프로젝트를 연구실에서 하게 되었다. 우리가 하게된 작업은 레이블링의 검수이며 오디오 샘플에 추가적으로 다른 사운드 이벤트나 특징을 추가하는 작업(annotation)을 보조하고 체크하는 것이다. 이 작업을 위해서 audioset에 학습이 되어있는 panns 모델을 활용을 하기로 했다. panns는 pip로 module화가 되어서 바로 사용이 가능하기 때문에 성능보다는 활용도의 측면에 장점이 있다.
panns 모델은 기본적으로 sound event detection을 제공하지만 확률값으로 아웃풋이 나오기에 이를 특정 threshold로 걸러줄 필요가 있다. 또한 아웃풋은 스펙트로그램을 기반으로 time_frame이 만들어지기 때문에 이를 시간 축으로 다시 반환해줄 필요가 있었다. 다행히도 panns에서 만드는 time_frame은 100 x 음원의 초 길이였다.
Sound Evenvt Detection
우리의 작업은 weak labeling을 하는 것이지만, 어노테이터들이 작업을 할때 음원 데이터에 strong labeling이 되어 있어야 좀더 편하게 작업을 할 수 있게 된다. 만약에 pre-annotated 데이터를 weak labeling을 한 상태로 넘겨주게 되면 annotator들이 전체 길이의 음원을 들어야 하기 때문에 효율적인 작업이 힘들어지게 된다.
weak labeling : 오디오 샘플 내에서 이벤트가 존재 하는지만을 체크
strong labeling : 오디오 샘플 내에서 이벤트가 발생하는 지점onset과 끝나는 지점offset을 체크
적분
지정한 threshold 값에 따라서 on & off time frame이 정해지지만 이 알고리즘을 그대로 사용하게 되면 지정한 값을 기준으로 확률값이 위치하는 label의 경우 고르게 걸러지지가 않게 된다. 따라서 확률값을 적분을 통해서 normalize를 해주면 튀는 값들을 어느정도 스무딩을 할 수 있게 된다. 아래 그림은 약 3천개에 해당하는 time_frame 각각의 확률값들로 이루어진 리스트들을 527개의 클래스마다 그려낸 그래프이다. 만약 0.1이라는 확률값 아래를 모두 삭제한다면 애매하게 0.1 주변에 걸쳐있는 확률값들은 삐죽삐죽 튀어나올 것이다. (참고로 그래프는 다크모드에서는 제대로 보이지 않습니다)
import matplotlib.pyplot as plt
plt.figure(figsize=(15,10))
for i in range (527):
plt.plot(framewise_output[0,:,i])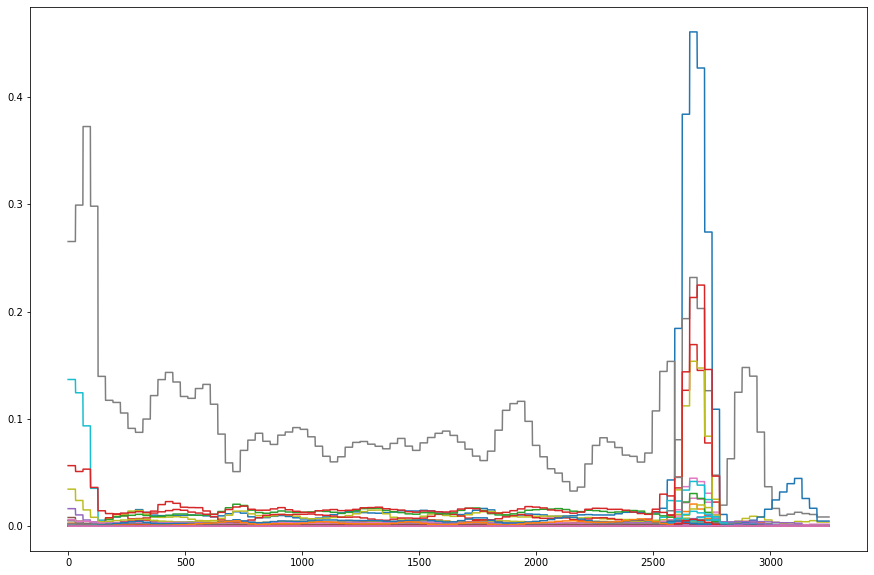
Obstacles & Walkthrough
아래의 코드는 정다샘 교수님께서 작성한 코드를 분석한 내용입니다.
https://github.com/jdasam/nia-sound-event/blob/master/sed.ipynb
on & off algorithm
np.diff를 사용하면 해당하는 축에 다음의 요소에서 현재의 요소를 뺀 값을 현재의 요소의 인덱스에 넣는 새로운 리스트가 만들어진다. 이를 활용하면 정말 쉽게 on & off의 위치를 잡아낼 수 있게 된다.
np.nonzero를 활용하면 0이 아닌 특정한 값을 가지는 위치의 index들을 찾는 리스트를 만들 수가 있다.
def quantize_prediction(pred, threshold=0.1):
assert pred.ndim == 3
th_pred = (pred > threshold).astype(int) # True of False -> 1 or 0
diff_pred = np.diff(th_pred, axis=1).transpose(0,2,1) # batch x class x time_frame
onset = np.nonzero(diff_pred==1) # idx check
offset = np.nonzero(diff_pred==-1)
events = []
j = 0
for i, (batch_id, tag_id, onset_frame) in enumerate(zip(onset[0], onset[1], onset[2])):
event = {'batch_id': batch_id, 'label':sed.labels[tag_id], 'onset':onset_frame/100}
if j<len(offset[0]) and batch_id == offset[0][j] and tag_id == offset[1][j]:
event['offset'] = offset[2][j] / 100
j += 1
else:
event['offset'] = (pred.shape[1]-1) / 100
# print(len(offset[0]), batch_id, offset[0][j], tag_id, offset[1][j] )
events.append(event)
return events
quantize_prediction(framewise_output, 0.1)앞서 말했듯이 vacuum cleaner의 예측값이 여러개 튀어나온 모습을 볼 수 있다. 하지만 이 경우 우리는 strong label을 하는 것이 목적이 아니고, annotator들이 해당하는 label의 유무를 판단하기 위한 보조를 위해 예측값을 제공하는 것이기 때문에 튀어나온 값들은 필요가 없게 된다. 이 점을 해결하기 위해서 뒤의 코드에서는 가장 높은 확률값을 가지는 하나의 label만을 살리고 중복된 예측들은 없애주었다. 가령 vacuum cleaner의 예측들 중에서 단 하나만 남기는 것이다.
[{'batch_id': 0, 'label': 'Music', 'onset': 28.47, 'offset': 29.43},
{'batch_id': 0, 'label': 'Vehicle', 'onset': 25.91, 'offset': 27.83},
{'batch_id': 0, 'label': 'Car', 'onset': 26.23, 'offset': 27.51},
{'batch_id': 0, 'label': 'Engine', 'onset': 26.23, 'offset': 27.19},
{'batch_id': 0,
'label': 'Medium engine (mid frequency)',
'onset': 26.23,
'offset': 27.19},
{'batch_id': 0,
'label': 'Accelerating, revving, vroom',
'onset': 26.23,
'offset': 27.51},
{'batch_id': 0, 'label': 'Vacuum cleaner', 'onset': 3.51, 'offset': 32.51},
{'batch_id': 0, 'label': 'Vacuum cleaner', 'onset': 18.55, 'offset': 32.51},
{'batch_id': 0, 'label': 'Vacuum cleaner', 'onset': 24.95, 'offset': 32.51}]onset & offset의 정확한 체크
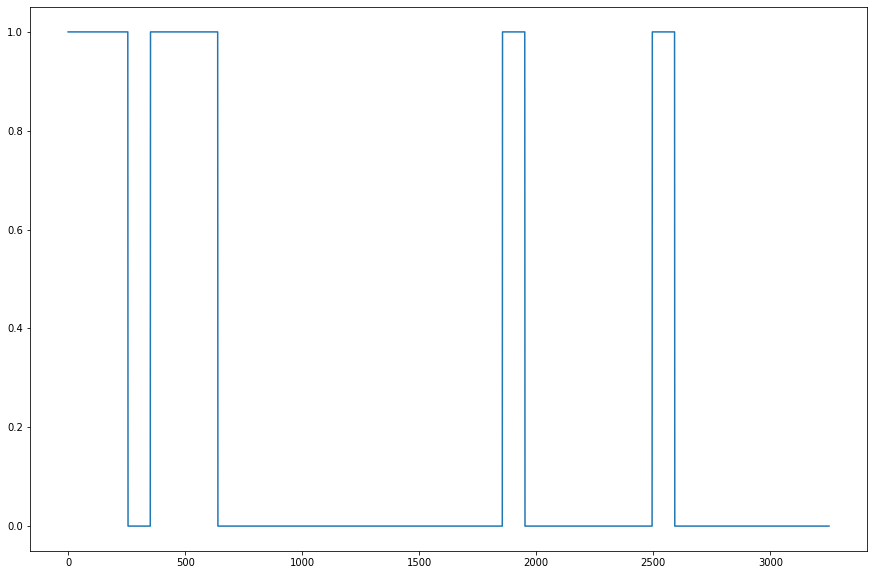
diff는 뒤에서 앞의 요소를 뺀 값을 체크한다. 하지만 만약에 아래 그림처럼 시작부터 True인 그래프가 있다면 onset은 체크가 되질 않는다. True - True = 0이므로. 또한 끝이 날때에 True가 계속해서 이어진다면 마지막엔 offset이 체크가 되질 않는다. 지금의 알고리즘이라면 상황에 따라 onset과 offset의 개수가 일치하지 않는 경우가 생긴다.(처음부터 시작하면 offset이 하나 더 많아지고, 끝까지 이어지면 onset의 개수가 하나더 많아진다.)
따라서 이를 해결하기 위한 방법이 필요하다. 교수님은 이를 해결하기 위해 앞뒤로 0의 확률값 즉, False를 예측하는 패딩을 덧댄다. 앞의 층의 추가는 np.concatenate를 활용하고, 뒤의 층의 추가는 pad_collate를 통해서 자연스레 해결이 된다. 이렇게 하면 onset과 offset의 크기가 일치하게 된다.
# torch 학습을 시킬때 인풋의 마지막 차원의 크기들이 달라지면 배치가 들어가질 않는다.
def pad_collate(raw_batch):
lens = [len(x) for x in raw_batch]
max_len = max(lens)
output = torch.zeros(len(raw_batch), max_len)
for i, sample in enumerate(raw_batch):
output[i, :len(sample)] = sample
return output, lensconfidence, 최고 확률값만을 뽑아내기
우리가 하는 것으 weak labeling이기 때문에 가장 높은 확률값을 나타내는 하나의 지점만 있어도 충분하다. 여러군데에서 알려줘봐야 레이블의 유무를 판단하는 작업을 더디게 할 뿐이다.
def quantize_prediction(pred, lens, threshold=0.1, shifted_index=0):
assert pred.ndim == 3
th_pred = (pred > threshold).astype(int) # batch x timestep x class
# concate은 순서대로 붙이니까 앞에 zeros로 False를 만들어준다.
th_pred = np.concatenate([np.zeros([th_pred.shape[0], 1, th_pred.shape[2]]), th_pred], axis=1) # add initial step
diff_pred = np.diff(th_pred, axis=1).transpose(0,2,1)
onset = np.nonzero(diff_pred==1)
offset = np.nonzero(diff_pred==-1)
events_of_piece = []
total_events = []
j = 0
prev_batch_id = -1
for i, (batch_id, tag_id, onset_frame) in enumerate(zip(onset[0], onset[1], onset[2])):
event = {'data_id': int(batch_id + shifted_index), 'label':sed.labels[tag_id], 'onset': float(onset_frame/100)}
if j<len(offset[0]) and batch_id == offset[0][j] and tag_id == offset[1][j]:
event['offset'] = float(offset[2][j] / 100)
j += 1
else:
event['offset'] = lens[batch_id] / 32000
# 이 아래 부분은 가장 높은 확률값을 가진 하나의 label을 남김으로 중복 예측을 피하는 코드이다.
event['confidence'] = max(pred[batch_id, onset_frame:int(event['offset']*100), tag_id])
if batch_id == prev_batch_id:
events_of_piece.append(event)
else:
if events_of_piece != []:
events_of_piece = retain_one_event_per_tag(events_of_piece)
total_events.append(events_of_piece)
events_of_piece = []
prev_batch_id = batch_id
# 제일 마지막 id를 체크하기 위해 추가
if events_of_piece != []:
events_of_piece = retain_one_event_per_tag(events_of_piece)
total_events.append(events_of_piece)
return total_events
def retain_one_event_per_tag(events):
'''
events = list of tag events
'''
unique_tags = list(set([x['label'] for x in events])) # 유일한 태그들로 정리
outputs = []
for tag in unique_tags:
selected_events = [x for x in events if x['label']==tag] # 태그에 해당하는 이벤트들 모두 뽑아내기
scores = [x['confidence'] * (x['offset']-x['onset']) for x in selected_events] # 점수 산정 = 길이 x 확률
max_id = scores.index(max(scores)) # list.index
outputs.append(selected_events[max_id])
return outputs앞선 문제점들을 해결하면 아래와 같이 시작점onset과 끝나는 지점offset의 크기가 동일한 결과를 얻을 수 있다.
# batch, label, time_frame
onset[0], onset[1], onset[2]
(array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
2, 2, 3, 3]),
array([137, 300, 307, 343, 348, 353, 369, 377, 377, 377, 377, 300, 300,
300, 300, 300, 300, 300, 300, 328, 328, 329, 329, 330, 331, 332,
332, 396, 396, 396, 396, 396, 396, 396, 396, 397, 397, 397, 397,
397, 397, 397, 397, 397, 369, 418, 137, 137]),
array([2848, 2592, 2624, 2624, 2624, 2624, 0, 0, 352, 1856, 2496,
160, 640, 1408, 2400, 3392, 3808, 4704, 5120, 3424, 5184, 3424,
5184, 3424, 3424, 3424, 5184, 352, 704, 1504, 1664, 1952, 2528,
3936, 5344, 384, 832, 1696, 1984, 2560, 2720, 3104, 3968, 5408,
0, 0, 0, 416]))# batch, label, time_frame
offset[0], offset[1], offset[2]
(array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
2, 2, 3, 3]),
array([137, 300, 307, 343, 348, 353, 369, 377, 377, 377, 377, 300, 300,
300, 300, 300, 300, 300, 300, 328, 328, 329, 329, 330, 331, 332,
332, 396, 396, 396, 396, 396, 396, 396, 396, 397, 397, 397, 397,
397, 397, 397, 397, 397, 369, 418, 137, 137]),
array([2944, 2784, 2752, 2720, 2720, 2752, 64, 256, 640, 1952, 2592,
352, 704, 1536, 2528, 3552, 3872, 5056, 5376, 3552, 5280, 3584,
5312, 3552, 3584, 3552, 5280, 672, 1376, 1632, 1824, 2304, 3264,
4736, 5632, 608, 1344, 1792, 2144, 2688, 3040, 3200, 4704, 5440,
96, 96, 128, 480]))이후에는 결과값을 json화해서 label-studio에 넘겨주는 코드이다. 이 내용은 생략한다.
