최종의 코드는 아래의 링크에서 확인할 수 있습니다.
https://github.com/clayryu/dev_adversarial_project
Introduction
이 프로젝트에서는 공격자 입장에서 딥러닝 모델을 평가하는 적대적 공격 기법에 대하여 공부를 해보았다. 동빈나님께서 적대적 공격 알고리즘의 설명과 코드를 포함한 문제지를 준비해주셨고, 우리의 최종 목적은 inception_v3 모델을 black box 컨디션이라 가정하고 공격하여 모델의 정확도를 가능한 떨어트리는 공격 모델을 만드는 것이었다.
adversarial attack에 대한 자세한 내용은 아래의 링크를 참고하면 좋다.
https://www.youtube.com/watch?v=QCgujoTPbmU
사용한 데이터 셋은 1000개의 클래스로 이루어진 5000장의 이미지 파일이다.
https://github.com/ndb796/Small-ImageNet-Validation-Dataset-1000-Classes
Results
이번에도 캐글 경진대회 형식으로 다른 팀들과 경쟁을 하는 방식으로 프로젝트를 진행했다.
이번에는 데이터 자체에 대한 접근을 할 수는 없었기 때문에 동빈나님의 hint를 따라서 attack 알고리즘을 MI-FGSM (CVPR 2018)을 사용했고, 추측하는 모델이 좀더 다양한 형태에 대해서 작동할 수 있도록 model ensemble을 준비했다.
Walkthrough & Obstacles
사실 adversarial attack이 굉장히 생소한 분야였기 때문에 제대로된 이해보다는 코드 작성을 위한 수준으로만 공부를 하고 코드의 작성과 더 좋은 결과를 내는 hyper parameter를 조정하는 데에 좀더 많은 시간을 쏟았다.
Attack Algorithm
https://arxiv.org/abs/1710.06081 를 참고. grad를 unpdate하는 과정에서 momentum을 이용해서 훨씬더 좋은 성능을 보여준다.
코드는 아래의 링크를 참고.
https://github.com/Harry24k/adversarial-attacks-pytorch/blob/master/torchattacks/attacks/mifgsm.py
Ensemble
pytorch의 torchvision에 있는 pre-trained model을 inception계열 빼고는 거의 다 사용해 본 것 같다. 이 과정중에서 특이한 점을 발견할 수 있었는데, 똑같은 efficientnet의 경우에도 torchvision에서 제공하는 것과 custom으로 만들어진 모델의 성능이 다르게, 아니 상당히 큰 차이를 낸다는 것이었다. 단일 모델 중에서 efficientnet_b1의 경우에서 accuracy를 13%까지 낮추는 좋은 결과를 냈다. 물론 inception 계열을 써버리면 바로 0%다. 또한 이 상황에서 MIFGSM의 알고리즘을 채용한 코드도 어떻게 작성이 되었냐에 따라서 상당한 차이를 보였다. 확실히 github에서 코드를 참고하더라도 같은 알고리즘의 다른 코드들 모두를 써보는 것이 좋을 듯 하다.
여기에서 그치지 않고 ensemble을 사용해서 좀더 좋은 결과를 만들어 보고자 했다. attack algorithm에서 하는 일은 perturbation의 값을 각 모델에 따라서 다양하게 업데이트 하는 것이기에 여러 모델들을 사용하게 되면 좀더 유연하게 대응이 가능해지는듯 하다.
사용하는 모델의 개수에 따라 결과가 몹시 좋아졌기에 3, 4, 5, 6개까지 ensemble model을 구성했다. 첫 ensemble model에는 efficientnet_b1, regnet, wide resnet_50을 사용했다. 이 구성에서 사용되는 모델의 순서, alpha, iter의 hyper parameter를 조정하는 다양한 시도를 했지만 11%의 벽을 넘기가 쉽지가 않았다. 그리고 ensemble model에 사용되는 모델의 개수를 늘리는 경우가 정확도에 훨씬 유의미한 결과를 냈기 때문에 이 후에는 모델의 개수를 늘리고 결과를 확인하는 정도에서 실험을 마무리하게 되었다.
최종적으로 6개의 모델을 사용할 때 정확도를 3.32%까지 낮출 수 있었다.
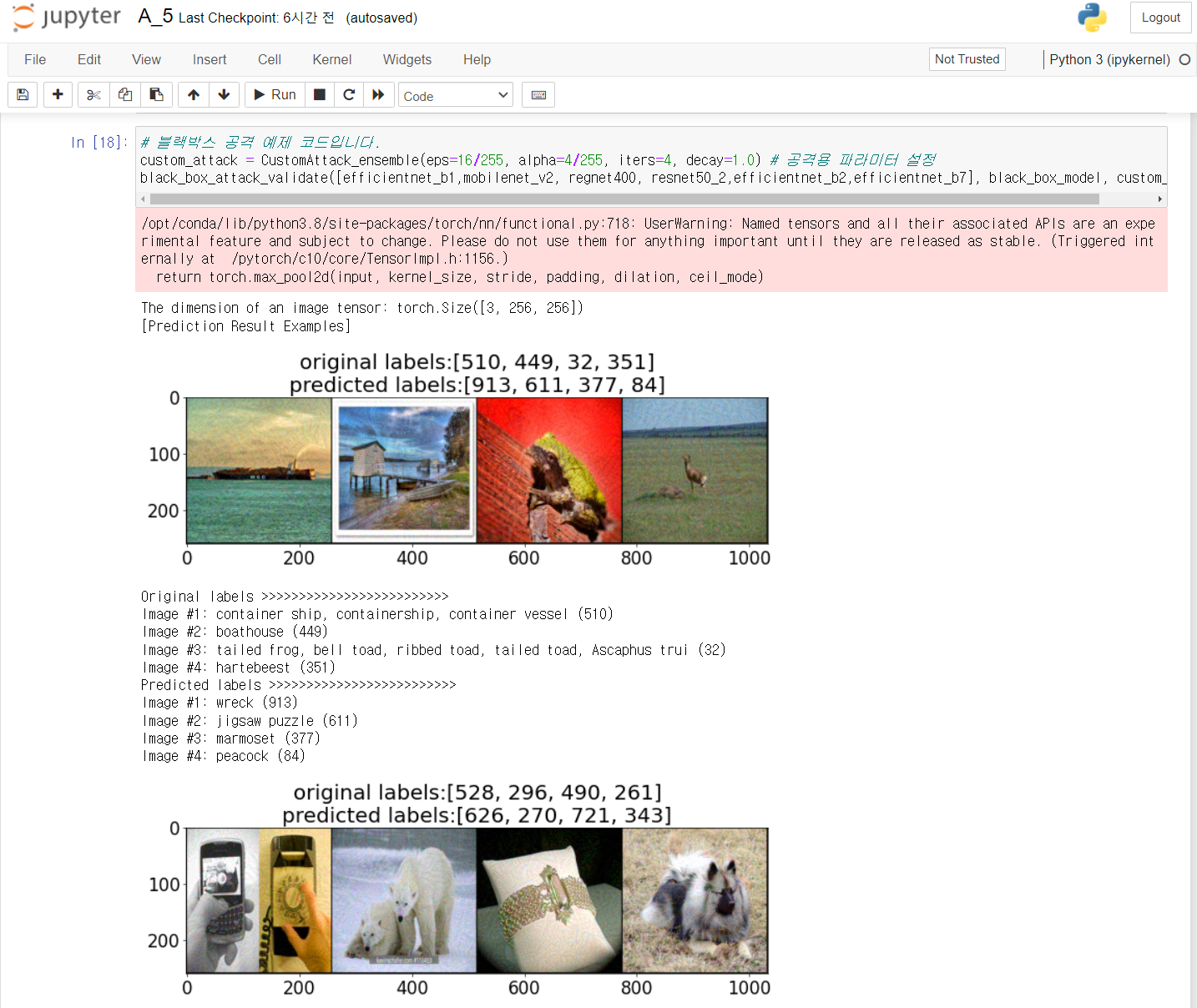
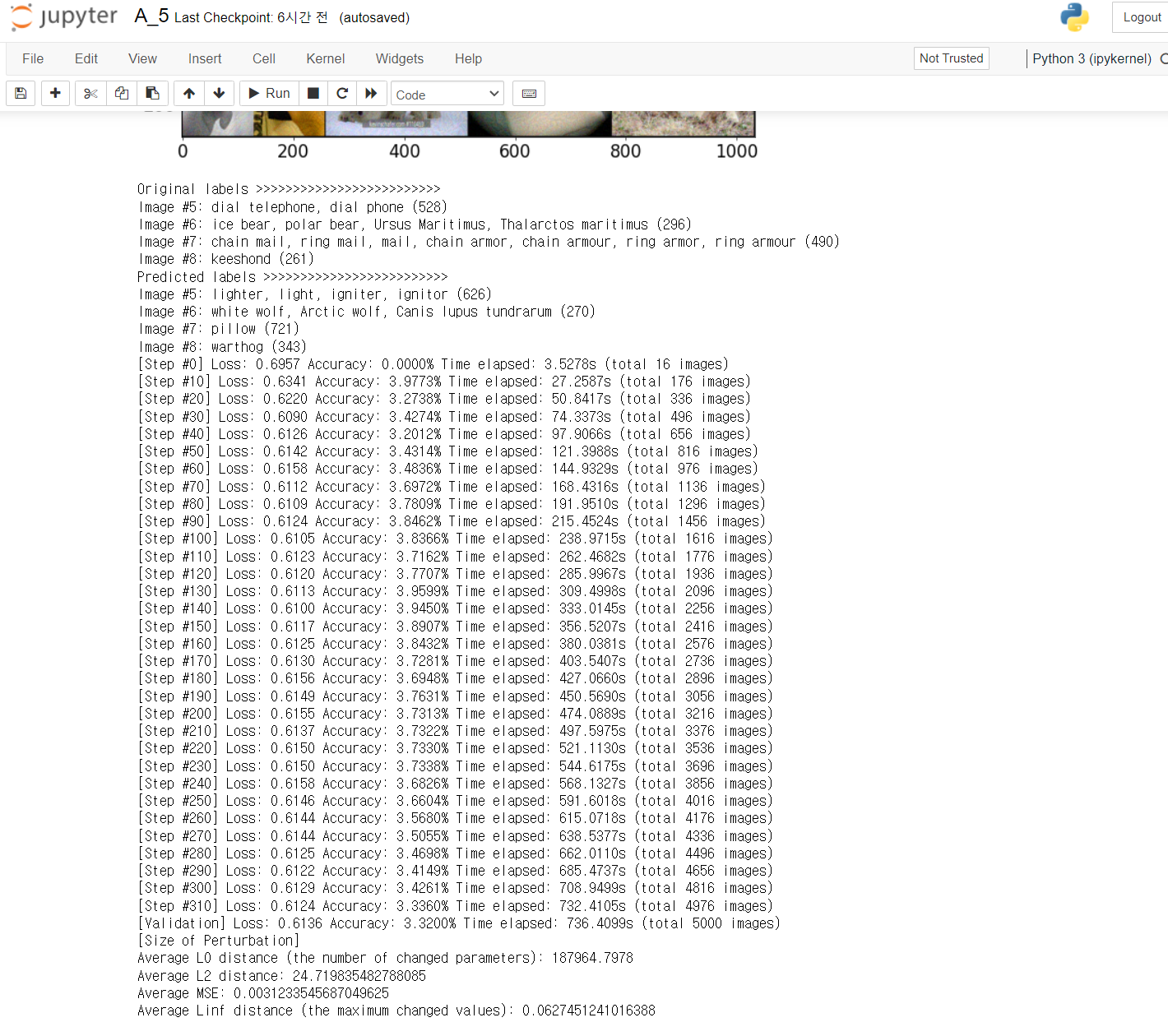
사람의 눈에서는 이미지에 영향을 미치지 않는데도 정확도가 거의 0%에 가까워지는 공격력을 가진 모델이라니 정말 무섭다. 보안과 관련해서 이번 프로젝트는 딥러닝이 가진 한계와 그것이 가질 위험성을 느낄 수 있게 된 것 같다.
