Introduction
최종 프로젝트는 주가 예측 모델을 구현하는 것이었고, 모델에 입력으로 들어갈 값 중에 하나는 그 순간에 발행된 기사가 주가에 미치는 영향력이었다. 불행히도 뉴스 기사 감성 분류를 하는 작업을 끝낼 즈음에 팀원들간의 의견 차이로 프로젝트가 중지되었다. 이 글에서는 뉴스 기사를 감성 분류를 하기위한 고민하고 해결해 나갔던 과정들을 담아보려고 한다.
Walkthrough & Obstacles
기사가 가진 영향력을 평가하기 위한 방법을 크게 2가지로 나누어서 생각을 했다. 우선 긍정적 영향력과 부정적 영향력으로 이진 분류 타겟을 목표로 한다고 가정할때 데이터에서 바로 이용할 수 있는 등락률의 상승과 하락을 기준으로 기사의 영향력을 계산 것이다. 하지만 이 방식은 성능이 아주 좋지 못했는데, 기사는 주가의 상승과 하락에 영향을 미치는 하나의 요소일 뿐이기에 이것으로 기사의 영향력을 평가하는 것은 잘못된 작업이었다. 그래서 다음으로 착수한 작업은 기사 단어들의 긍정과 부정을 바탕으로 그 기사의 긍정율을 계산하는 일이었다. 이 방식은 2가지 방법으로 진행이 될 수 있는데, 먼저 이미 만들어진 감성 분류 사전인 kosac를 이용해서 단어들의 긍정값을 계산하는 방법이 있고, 다음으로 custom 감성 분류 사전을 만들어서 단어들의 긍정값을 계산하는 방법이 있다.
kosac으로 작업을 하던중 프로젝트가 종료되었기에 여기에서는 custom 감성 분류 사전을 만드는 과정을 적어보려고 한다.
데이터와 전처리 과정
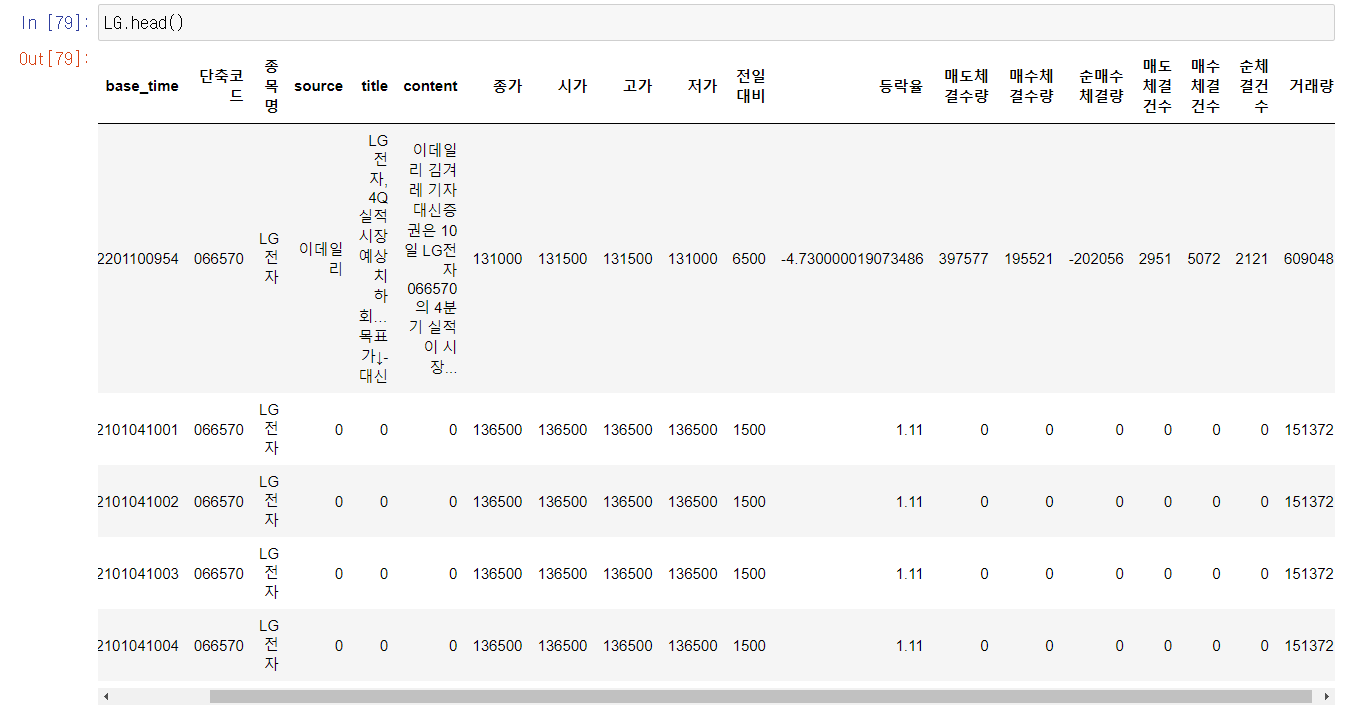
데이터는 팀원분께서 고생하셔서 정말 처리하기 쉽게 csv파일로 준비를 해주셨다. 지금 생각해도 참 감사하다. pandas로 불러온 데이터는 아래와 같으며 총 19개의 column 값들이 있는 168개의 종목들의 2021년부터 2022년까지의 1분봉 데이터였다. 총 데이터의 개수는 1천5백만개가 넘었으며 그 중에서 뉴스 데이터가 있는 데이터는 4만9천여개를 넘었다.
데이터 전처리 과정을 훑어보면 기준 시간이 str의 형태여서 이를 time의 형태로 바꿔줄 필요가 있었다.
base_time_num = pd.to_datetime(sk_data['base_time'], format = '%Y%m%d%H%M')
sk_data['base_time_num'] = base_time_num또한 90분봉 차이가 나는 등락율과 차이를 계산해서 이를 새로운 column에 label로 담아준다.
data_label = copy.deepcopy(data)
temp_list = data_label['등락율'].diff(periods = 90)
temp_list = list(temp_list)
no_nan = temp_list[90:] + temp_list[:90]
data_label['label'] = no_nan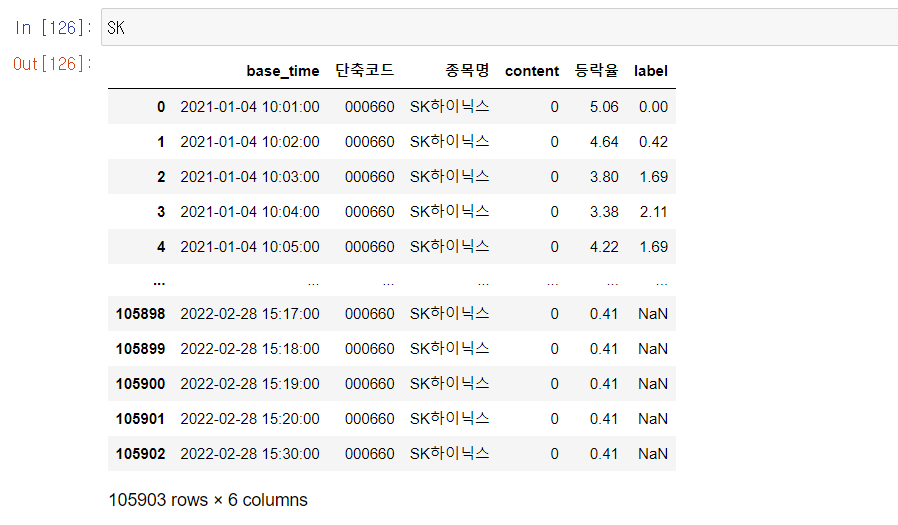
이 label 값이 0보다 크면 1, 0보다 작으면 0으로 bert 모델에 학습할 class를 만들어준다. 물론 결과는 아주 좋지 못했다.
중간에 제시된 해결방법
지금의 방식은 각 종목 별로 bert 모델을 학습을 시키는 방식을 택했다. 기사 내용에서 종목을 언급하는 부분이 많기도 했고, 종목의 업종과 관련한 단어들이 그 종목에서 더 많이 등장을 할 것이기에 따로 학습을 시키기로 결정을 했다.
결과가 좋지 않았기에 뉴스의 내용을 제외하고 뉴스의 제목만으로 학습을 하고, 특정 종목이 아닌 모든 종목을 인풋으로 넣어 학습을 하기도 하였지만 특별한 발전은 없었다. 참고로 사용한 bert 모델은 KOBERT, KB-ALBERT모델이었다.
이 상황에서 제시된 해결책은 데이터의 전처리를 좀더 확실하게 처리하는 것과 introduction에서 설명한 것처럼 labeling을 다시하는 것이었다.
custom 감성 분류 사전
custom 감성 분류 사전은 각 단어들에 특정한 값을 부여하는 방식으로 만들어진다. 이런 사전이 있다면 어떤 문장이나 문단이 주어졌을 때 그것을 그 단어의 값들의 계산으로 하나의 숫자로 간단하게 표현할 수 있다. 사전의 구현에는 아래의 사이트를 참고 했다.
https://sieon-dev.tistory.com/15?category=989047
구현 코드는 동일한 방식을 사용해서 생략을 하고 결과물은 다음과 같았다.
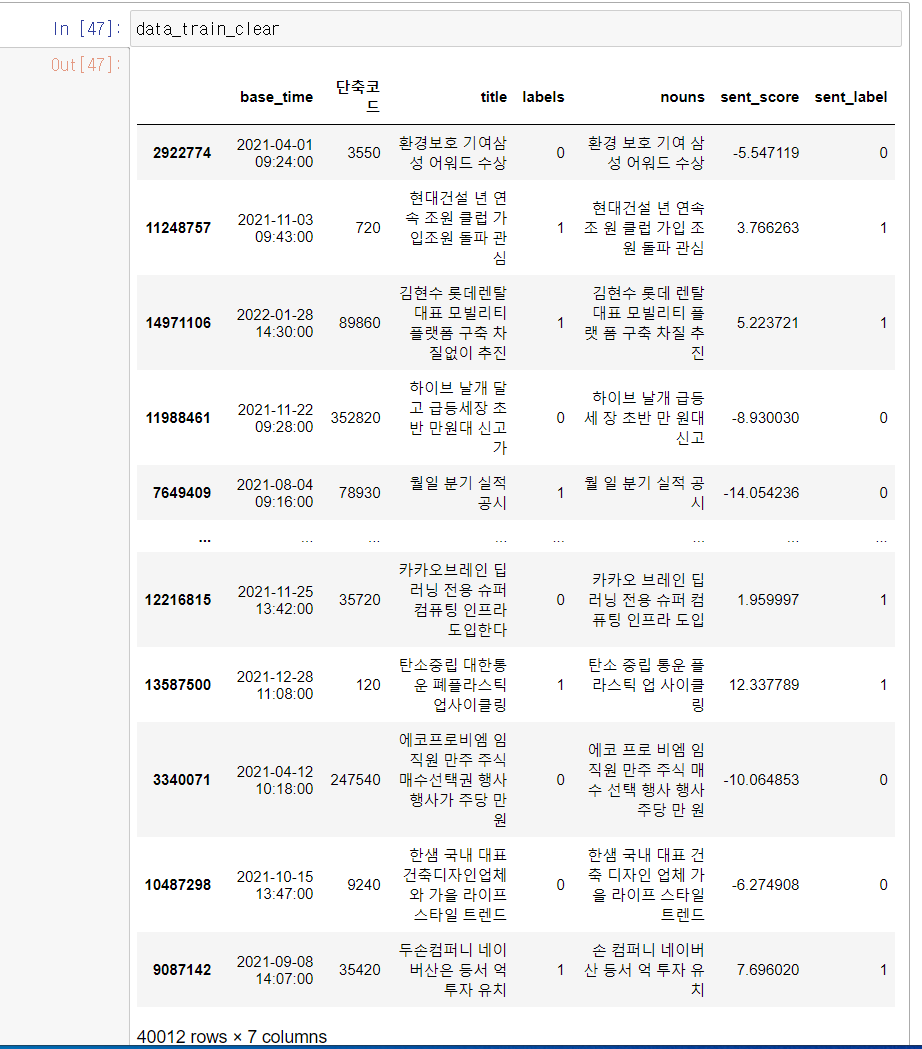
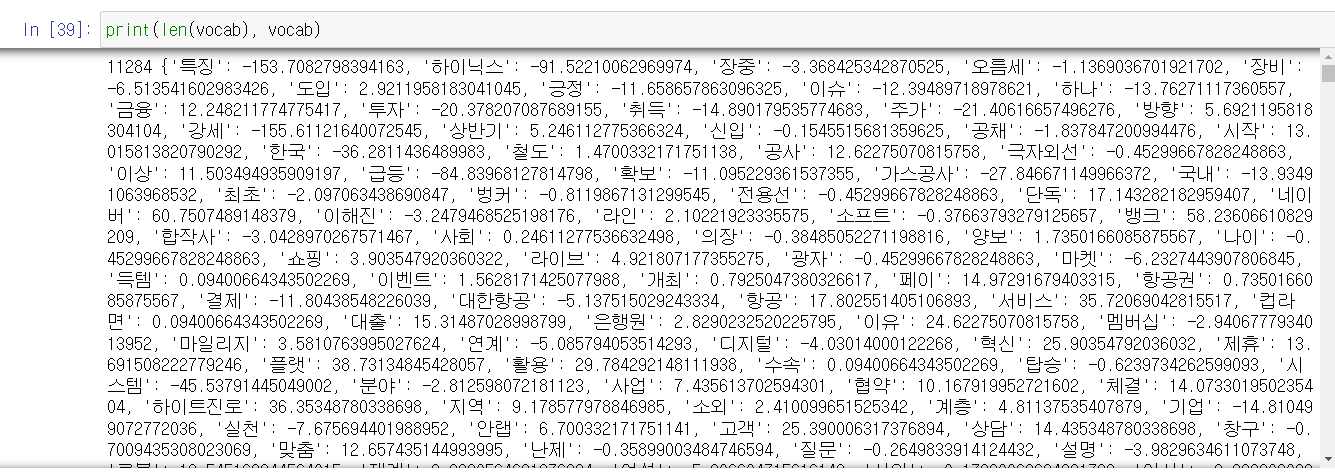
Results
우선 작업을 하던 와중에 프로젝트가 뒤집어져서 정말 아쉽다. 좋은 팀원분들이었는데 특정한 주제에 대한 의견에 있어서 차이가 도저히 봉합이 되지가 않았기에 어쩔 수 없이 각자의 길을 가는 것으로 결론을 냈다.
위에서 만든 사전을 바탕으로 만든 label도 강화학습을 통한 주가 예측 모델의 예측값을 바탕으로 재조정을 한 뒤에 학습을 시킬 에정이었고, 그 부분이 팀이 구상한 알고리즘의 핵심이었기 때문에 좀더 진행이 되었다면 어땠을까라는 궁금증과 아쉬움이 많이 남는다.
kosac를 통한 감성 분류와 단어가 아닌 동사나 형용사를 사용한 사전의 추가 등 실험 해보고 싶고, 해야할 일이 많았는데 이런 결과가 나온 것이 아쉽다. 하지만 이 작업들을 통해서 실험 뿐만이 아니라 인간 관계에 대해서도 이런 저런 생각을 해보며 내 자신을 좀더 알게되는 경험을 했기 때문에 잘 마무리하고 다음의 과정으로 다시 나아가야 할 것 같다. 사람은 역시 사람에게 배우는 것 같다.
