Introduction
동빈나님이 준비해주신 코드를 조금 수정해서 커스텀 풍경 이미지를 분류하는 과제이다.
Obstacles
1.데이터를 조정해서 정확도를 높인다.
mix up, transfer의 방식을 사용한다. 구체적인 방식은 monthly proj내에 파일을 찾아본다.
2.모델을 정하고 적절한 epoch 횟수를 찾고, optimizer의 learning rate 조절함으로써 하이퍼 파라미터를 조절한다.
하이퍼 파라미터를 찾기 위한 학습을 하는데에 시간이 오래 걸렸다.
3.learning rate scheduler를 사용했다. 전부다 동빈나님이 알려주신 것을 적용하는 것이었지만 그것을 코딩하는 것에는 시간이 조금 걸린듯하다.
데이터 셋을 조정하고, efficientnet_b1 모델에 SGD를 사용해서 94.27퍼센트를 달성했다.
Code
데이터 준비하기
# 깃허브에서 데이터셋 다운로드하기
!git clone https://github.com/ndb796/Scene-Classification-Dataset-Split
# 폴더 안으로 이동
%cd Scene-Classification-Dataset-Split import os
classes = ['buildings', 'forests', 'glacier', 'mountains', 'sea', 'street']
train_path = 'train/'
val_path = 'val/'
print("[ 학습 데이터셋 ]")
for i in range(6):
print(f'클래스 {i}의 개수: {len(os.listdir(train_path + classes[i]))}')
print("[ 검증 데이터셋 ]")
for i in range(6):
print(f'클래스 {i}의 개수: {len(os.listdir(val_path + classes[i]))}')import torch
from torchvision import datasets, transforms
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # device object
#device = xm.xla_device()
transforms_train = transforms.Compose([
transforms.RandomResizedCrop((64, 64)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 정규화(normalization)
])
transforms_val = transforms.Compose([
transforms.Resize((64, 64)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
train_dataset = datasets.ImageFolder(train_path, transforms_train)
val_dataset = datasets.ImageFolder(val_path, transforms_val)
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=2)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=32, shuffle=True, num_workers=2)
print('Training dataset size:', len(train_dataset))
print('Validation dataset size:', len(val_dataset))
class_names = train_dataset.classes
print('Class names:', class_names)이미지를 확인해보기
import torchvision
import numpy as np
import matplotlib.pyplot as plt
# 화면에 출력되는 이미지 크기를 적절하게 조절하기
plt.rcParams['figure.figsize'] = [12, 8]
plt.rcParams['figure.dpi'] = 60
plt.rcParams.update({'font.size': 20})
def imshow(image, title):
# torch.Tensor => numpy 변환하기
image = image.numpy().transpose((1, 2, 0))
# 이미지 정규화(normalization) 해제하기
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
image = std * image + mean
image = np.clip(image, 0, 1)
# 화면에 이미지 출력하기
plt.imshow(image)
plt.title(title)
plt.show()
# 학습 데이터셋에서 하나의 배치를 불러와 보기
iterator = iter(train_dataloader)
# 현재 배치에 포함된 이미지를 출력하기
inputs, classes = next(iterator)
out = torchvision.utils.make_grid(inputs[:4])
imshow(out, title=[class_names[x] for x in classes[:4]])학습을 준비하기
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import pandas as pd
import seaborn as snsdef train(net, epoch, optimizer, criterion, train_dataloader):
print('[ Train epoch: %d ]' % epoch)
net.train() # 모델을 학습 모드로 설정
train_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(train_dataloader):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad() # 기울기(gradient) 초기화
outputs = net(inputs) # 모델 입력하여 결과 계산
loss = criterion(outputs, targets) # 손실(loss) 값 계산
loss.backward() # 역전파를 통해 기울기(gradient) 계산
optimizer.step() # 계산된 기울기를 이용해 모델 가중치 업데이트
#xm.optimizer_step(optimizer)
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
print('Train accuarcy:', 100. * correct / total)
print('Train average loss:', train_loss / total)
return (100. * correct / total, train_loss / total)
def validate(net, epoch, val_dataloader):
print('[ Validation epoch: %d ]' % epoch)
net.eval() # 모델을 평가 모드로 설정
val_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(val_dataloader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = net(inputs) # 모델 입력하여 결과 계산
val_loss += criterion(outputs, targets).item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
print('Accuarcy:', 100. * correct / total)
print('Average loss:', val_loss / total)
return (100. * correct / total, val_loss / total)mixup 사용하기
mixup_alpha = 1.0
def mixup_data(x, y):
lam = np.random.beta(mixup_alpha, mixup_alpha)
batch_size = x.size()[0]
index = torch.randperm(batch_size).cuda()
mixed_x = lam * x + (1 - lam) * x[index]
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam
def mixup_criterion(criterion, pred, y_a, y_b, lam):
return lam * criterion(pred, y_a) + (1 - lam) * criterion(pred, y_b)
def train_with_mixup(net, epoch, optimizer, criterion, train_dataloader):
print('[ Train epoch: %d ]' % epoch)
net.train() # 모델을 학습 모드로 설정
train_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(train_dataloader):
inputs, targets = inputs.to(device), targets.to(device)
inputs, targets_a, targets_b, lam = mixup_data(inputs, targets) # Mixup 진행
optimizer.zero_grad() # 기울기(gradient) 초기화
outputs = net(inputs) # 모델 입력하여 결과 계산
loss = mixup_criterion(criterion, outputs, targets_a, targets_b, lam) # 손실(loss) 값 계산
loss.backward() # 역전파를 통해 기울기(gradient) 계산
optimizer.step() # 계산된 기울기를 이용해 모델 가중치 업데이트
#xm.optimizer_step(optimizer, barrier=True)
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += (lam * predicted.eq(targets_a).sum().item() + (1 - lam) * predicted.eq(targets_b).sum().item())
print('Train accuarcy:', 100. * correct / total)
print('Train average loss:', train_loss / total)
return (100. * correct / total, train_loss / total)transfer 사용하기
transforms_train_transferred = transforms.Compose([
transforms.RandomResizedCrop((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 정규화(normalization)
])
transforms_val_transferred = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
train_dataset_transferred = datasets.ImageFolder(train_path, transforms_train_transferred)
val_dataset_transferred = datasets.ImageFolder(val_path, transforms_val_transferred)
train_dataloader_transferred = torch.utils.data.DataLoader(train_dataset_transferred, batch_size=16, shuffle=True, num_workers=2)
val_dataloader_transferred = torch.utils.data.DataLoader(val_dataset_transferred, batch_size=16, shuffle=True, num_workers=2)
print('Training dataset size:', len(train_dataset_transferred))
print('Validation dataset size:', len(val_dataset_transferred))
class_names = train_dataset_transferred.classes
print('Class names:', class_names)learning_rate schedular
def adjust_learning_rate(optimizer, epoch):
lr = learning_rate
if epoch >= 15:
lr /= 10
if epoch >= 35:
lr /= 10
for param_group in optimizer.param_groups:
param_group['lr'] = lr학습하고 평가하기
import time
import torch.optim as optim
from efficientnet_pytorch import EfficientNet
net = EfficientNet.from_pretrained('efficientnet-b1')
# net = torchvision.models.efficientnet_b1(pretrained=True)
# 마지막 레이어의 차원을 6차원으로 조절
# num_features = net.fc.in_features
# net.fc = nn.Linear(num_features, 6)
net = net.to(device)
epoch = 35
learning_rate = 0.01 # 일반적으로 fine-tuning을 진행할 때는 학습률(learning rate)을 낮게 설정
file_name = "efficientnet_b1.pt"
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9, weight_decay=0.0002)
#optimizer = optim.Adam(net.parameters(), lr=learning_rate)
train_result = []
val_result = []
start_time = time.time() # 시작 시간
for i in range(epoch):
adjust_learning_rate(optimizer, i)
train_acc, train_loss = train_with_mixup(net, i, optimizer, criterion, train_dataloader_transferred) # 학습(training)
val_acc, val_loss = validate(net, i + 1, val_dataloader_transferred) # 검증(validation)
# 학습된 모델 저장하기
state = {
'net': net.state_dict()
}
if not os.path.isdir('checkpoint'):
os.mkdir('checkpoint')
torch.save(state, './checkpoint/' + file_name)
print(f'Model saved! (time elapsed: {time.time() - start_time})')
# 현재 epoch에서의 정확도(accuracy)와 손실(loss) 값 저장하기
train_result.append((train_acc, train_loss))
val_result.append((val_acc, val_loss))손실, 정확도를 그려보기
epoch = 35
# 정확도(accuracy) 커브 시각화
plt.subplot(211)
plt.plot([i for i in range(epoch)], [i[0] for i in train_result])
plt.plot([i for i in range(epoch)], [i[0] for i in val_result])
plt.title("Accuracy Curve")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend(["train", "val"])
# 손실(loss) 커브 시각화
plt.subplot(212)
plt.plot([i for i in range(epoch)], [i[1] for i in train_result])
plt.plot([i for i in range(epoch)], [i[1] for i in val_result])
plt.title("Loss Curve")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend(["train", "val"])
plt.tight_layout()
plt.show()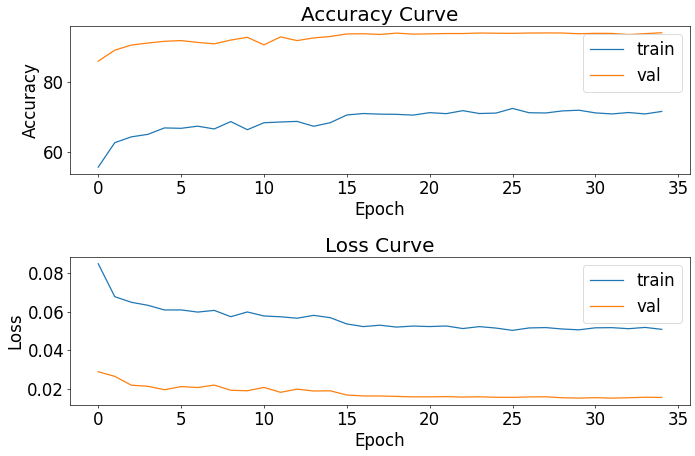
최종 모델을 혼동행렬로 그려보기
# 네트워크에 데이터셋을 입력하여 혼동 행렬(confusion matrix)을 계산하는 함수
def get_confusion_matrix(net, num_classes, data_loader):
net.eval() # 모델을 평가 모드로 설정
confusion_matrix = torch.zeros(num_classes, num_classes, dtype=torch.int32)
for batch_idx, (inputs, targets) in enumerate(data_loader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = net(inputs)
_, predicted = outputs.max(1)
for t, p in zip(targets.view(-1), predicted.view(-1)):
confusion_matrix[t.long(), p.long()] += 1
return confusion_matriximport pandas as pd
import seaborn as sns
net = EfficientNet.from_pretrained('efficientnet-b1')
net = net.to(device)
file_name = "./checkpoint/efficientnet_b1.pt"
checkpoint = torch.load(file_name)
net.load_state_dict(checkpoint['net'])
# 평가 데이터셋을 이용해 혼동 행렬(confusion matrix) 계산하기
confusion_matrix = get_confusion_matrix(net, 6, val_dataloader_transferred)
print("[ 각 클래스당 데이터 개수 ]")
print(confusion_matrix.sum(1))
print("[ 혼동 행렬(confusion matrix) 시각화 ]")
res = pd.DataFrame(confusion_matrix.numpy(), index = [i for i in range(6)], columns = [i for i in range(6)])
res.index.name = 'True label'
res.columns.name = 'Predicted label'
plt.figure(figsize = (10, 7))
sns.heatmap(res, annot=True, fmt="d", cmap='Blues')
plt.show()
print("[ 각 클래스에 따른 정확도 ]")
# (각 클래스마다 정답 개수 / 각 클래스마다 데이터의 개수)
print(confusion_matrix.diag() / confusion_matrix.sum(1))
print("[ 전체 평균 정확도 ]")
print(confusion_matrix.diag().sum() / confusion_matrix.sum())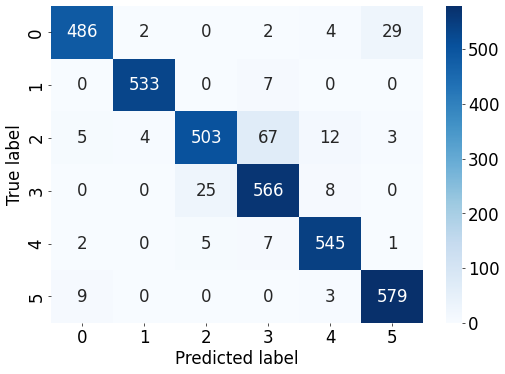
[ 각 클래스에 따른 정확도 ]
tensor([0.9293, 0.9870, 0.8468, 0.9449, 0.9732, 0.9797])
[ 전체 평균 정확도 ]
tensor(0.9428)
chords & code // harmony with structure