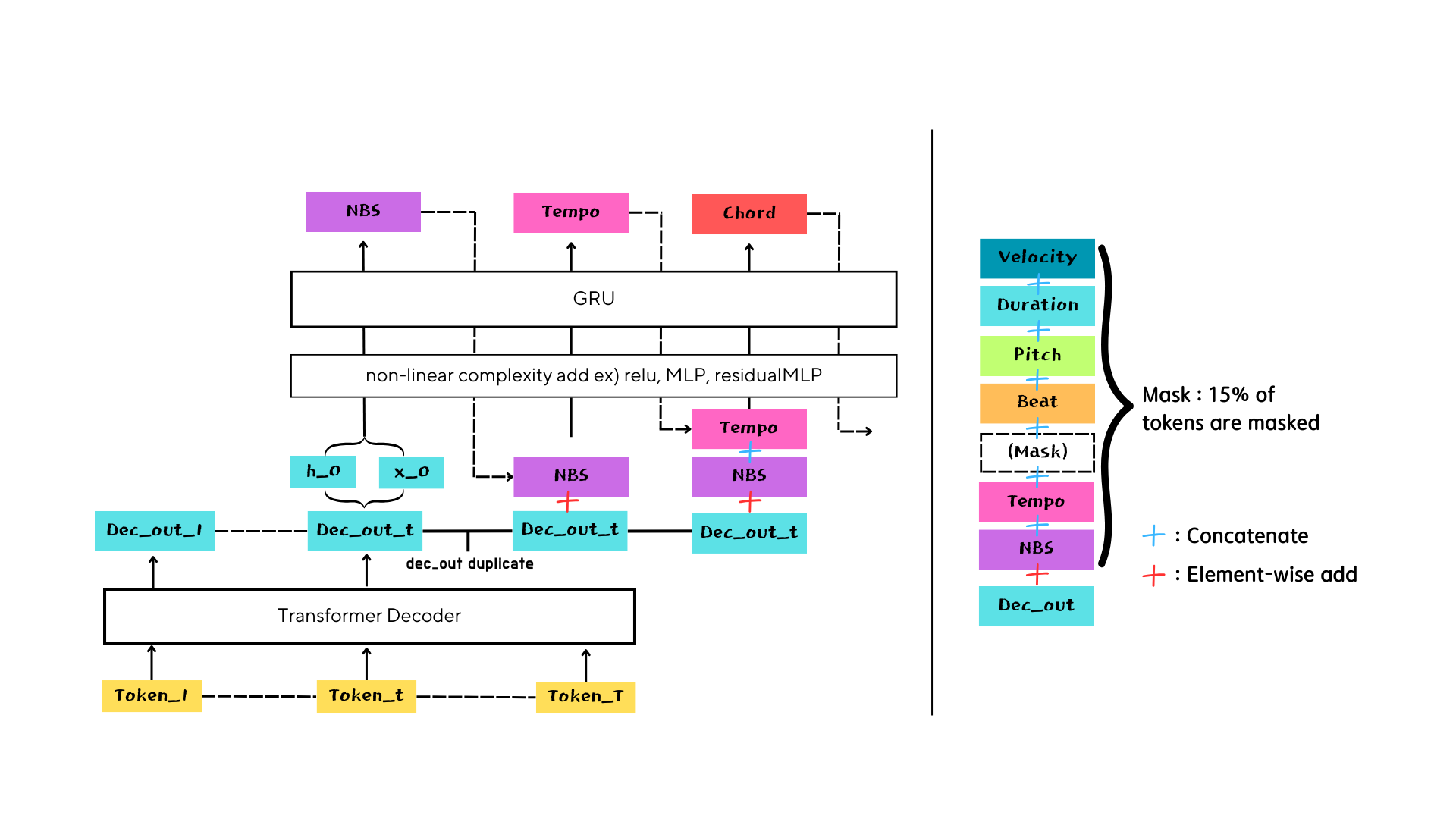
Introduction
CP vs. NL encoding sheme
what is the difference?
1. we added new_bar_started token class at the first of each tokens as this token class can be advantageous in "sequential prediction"
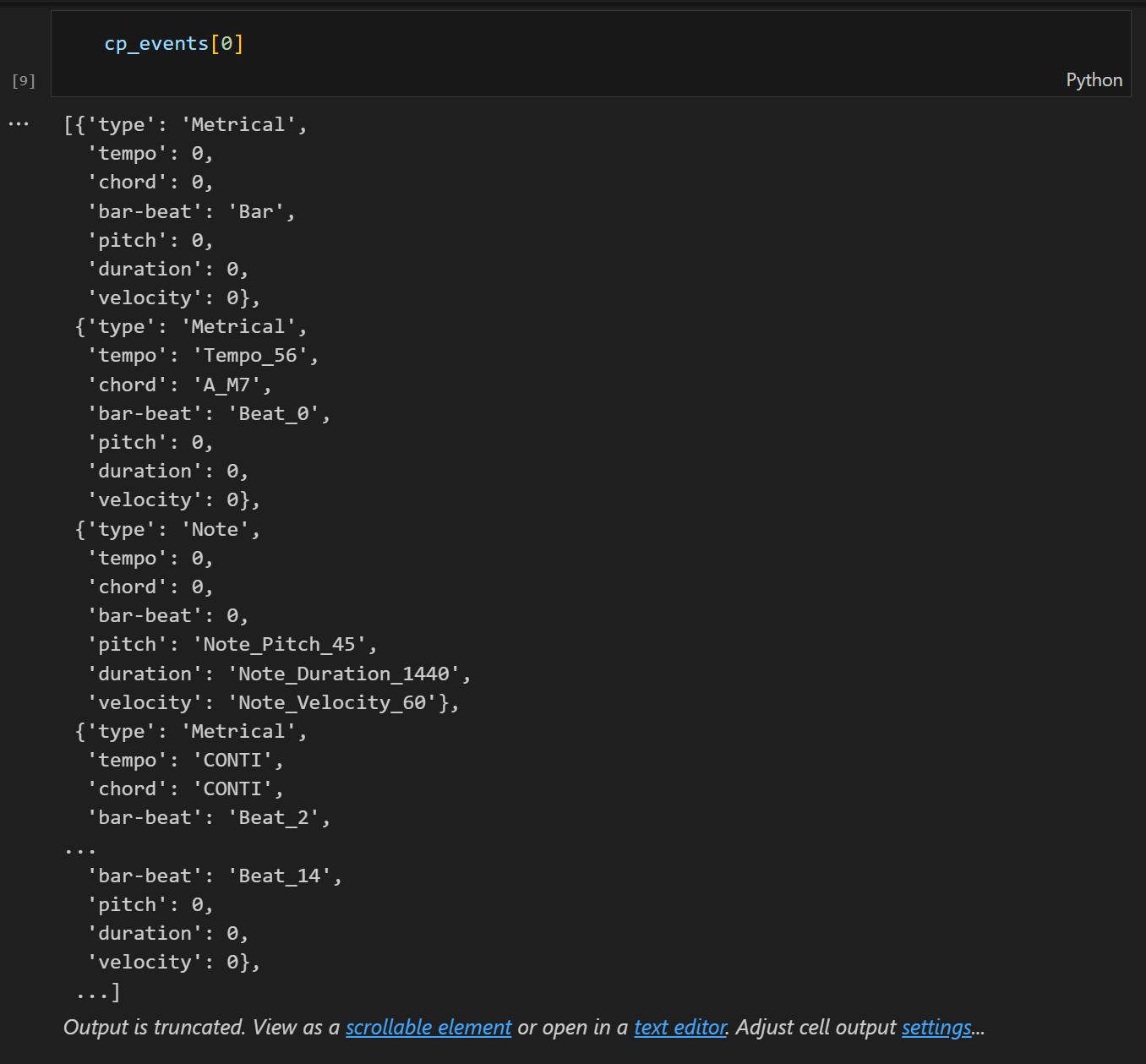
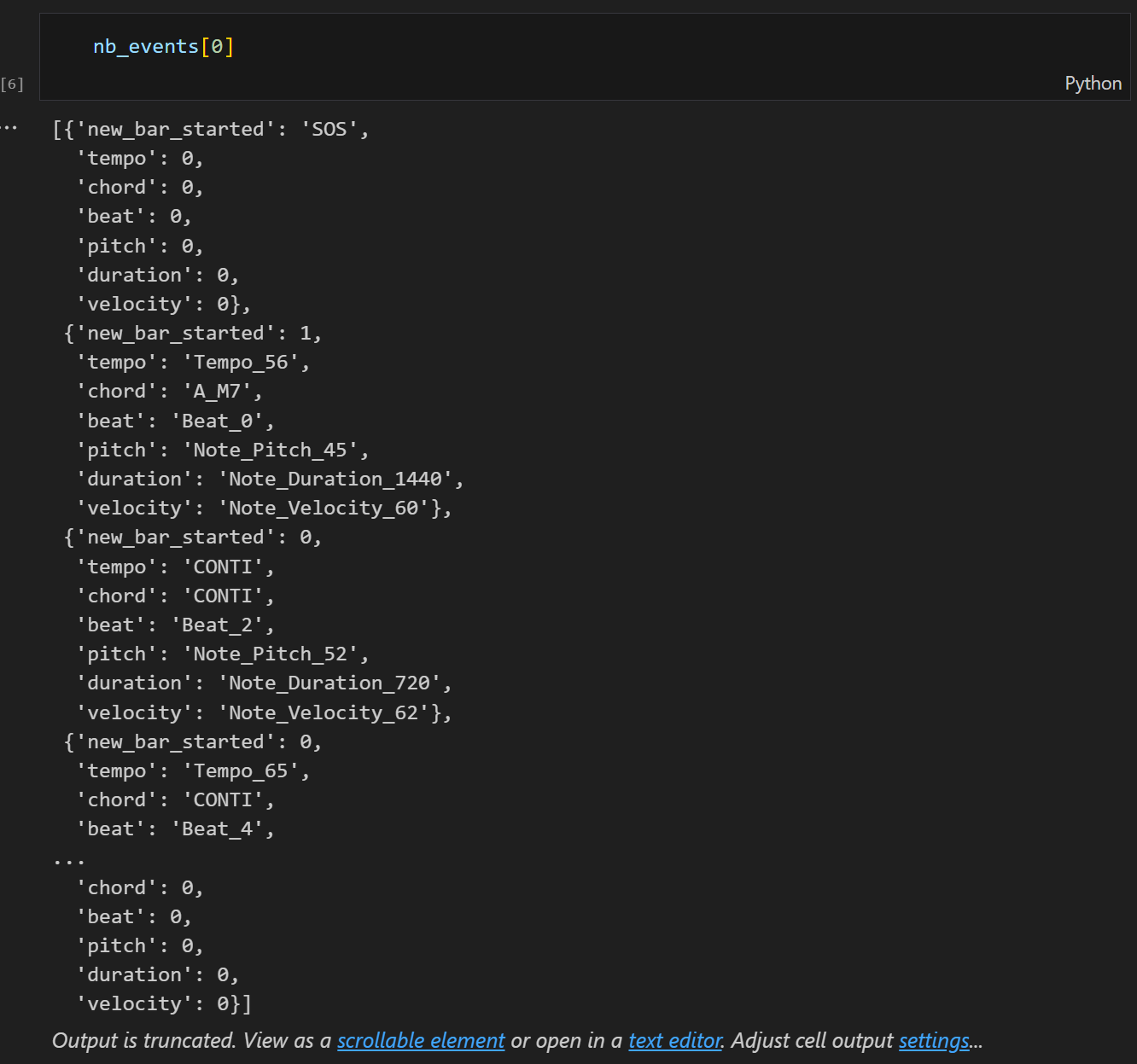
2. token numbers are reduced
when using Pop piano cover dataset extended, which is introduced in CP paper, we can reduce about 800 tokens about 40% from cp style encoding
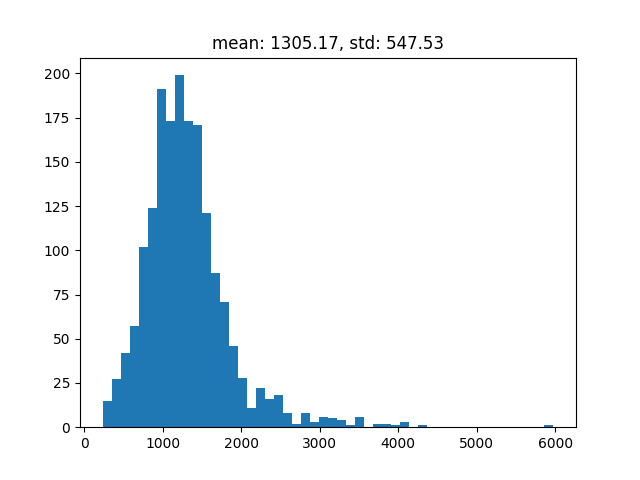
3. Deal with CONTI and ignore tokens
As we use note based tokens, the number CONTI tokens are raised a lot.
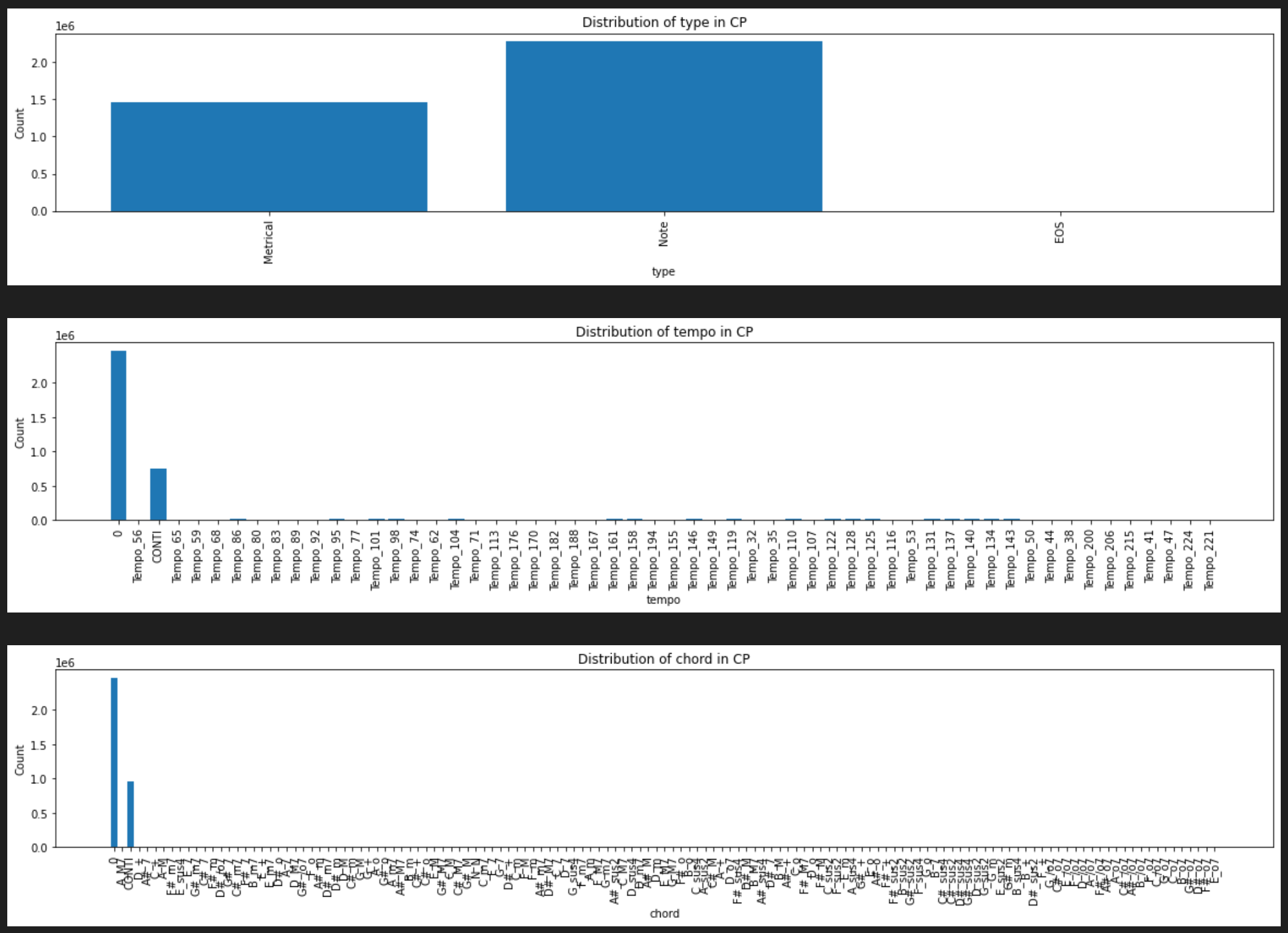
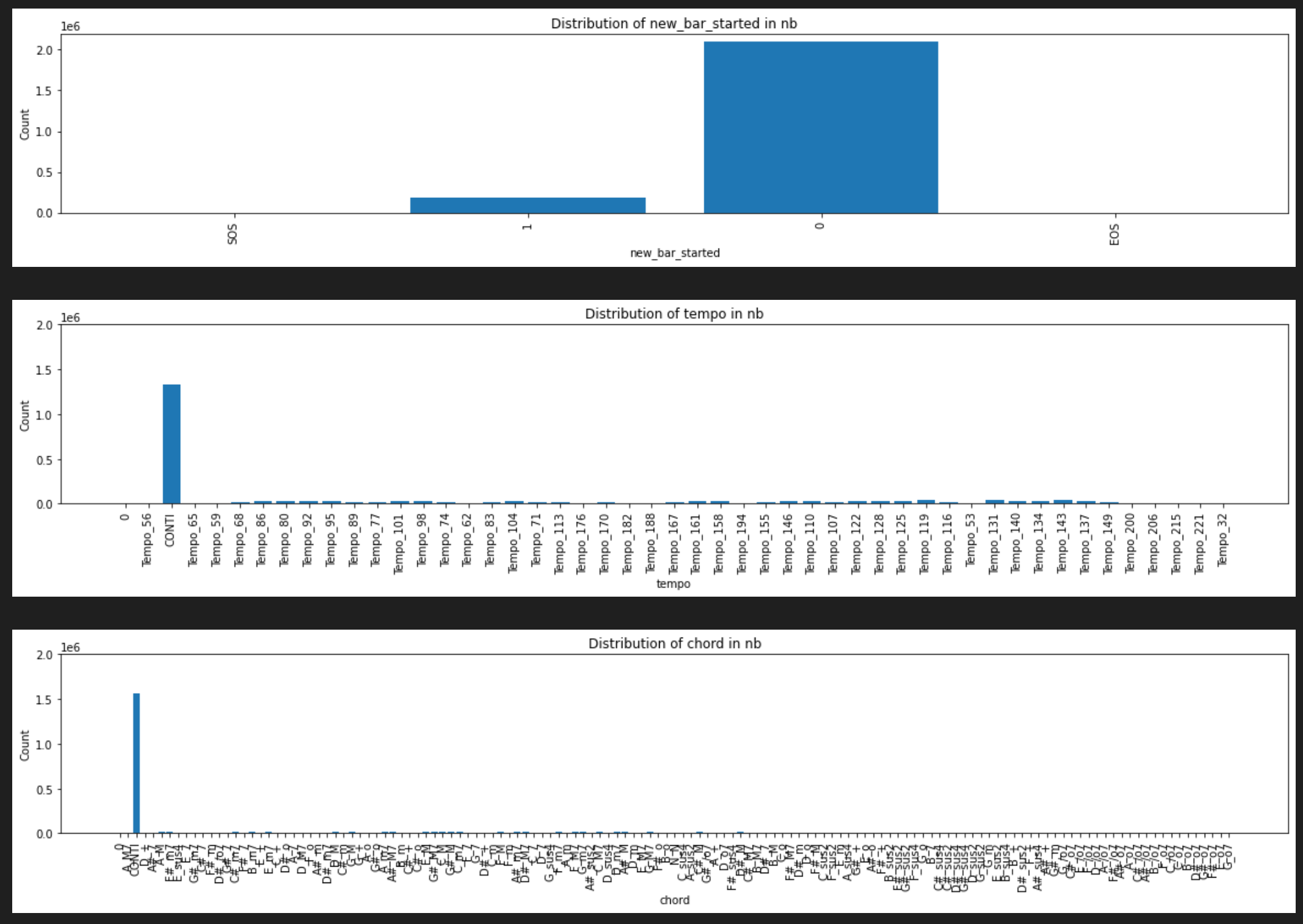
For the proper comparison between CP and NL, we excluded 0(ignore), CONTI tokens in calculating accuracy, also the padding mask is excluded too.
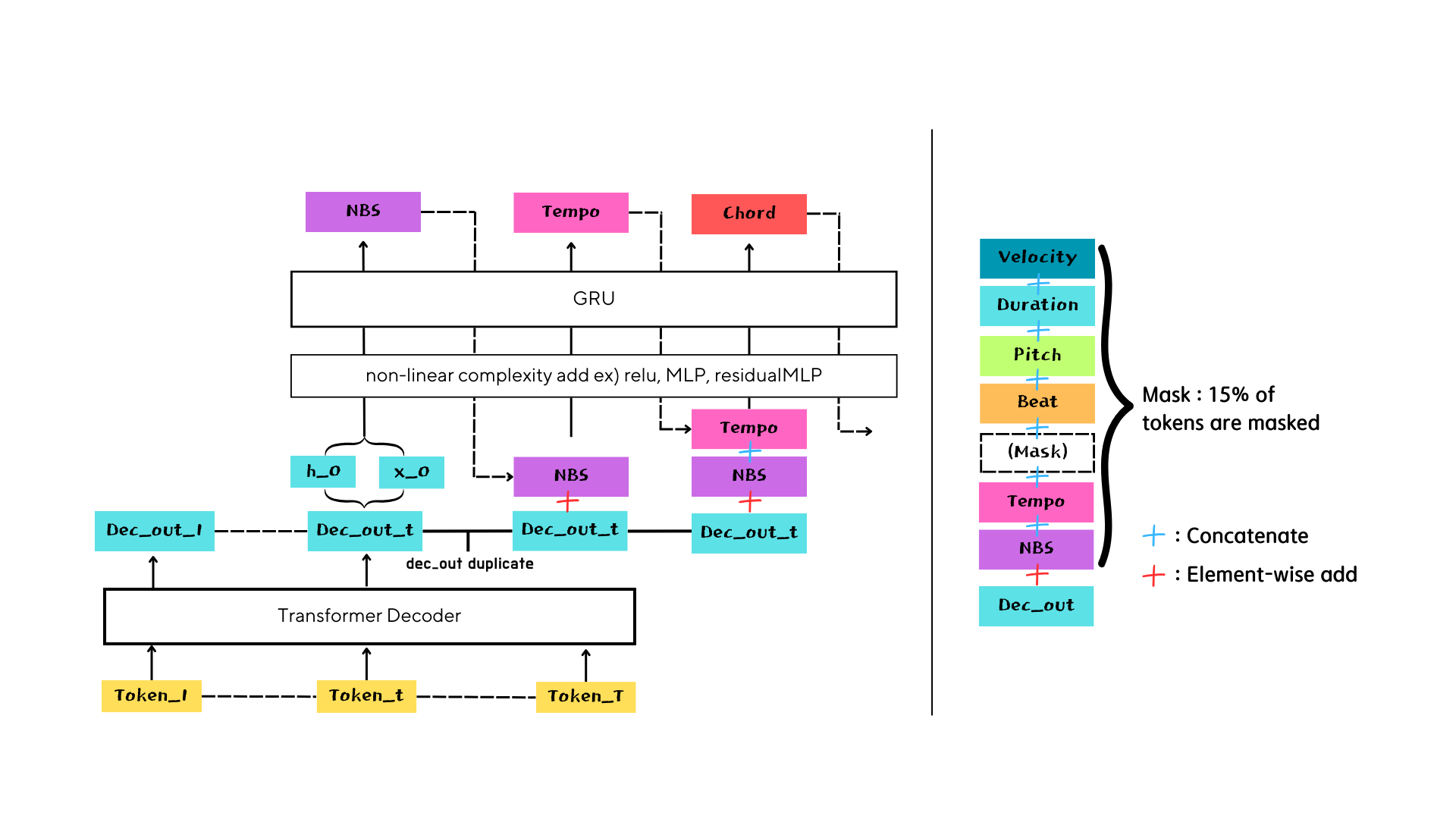
Methodolgy
Linear-based RNN
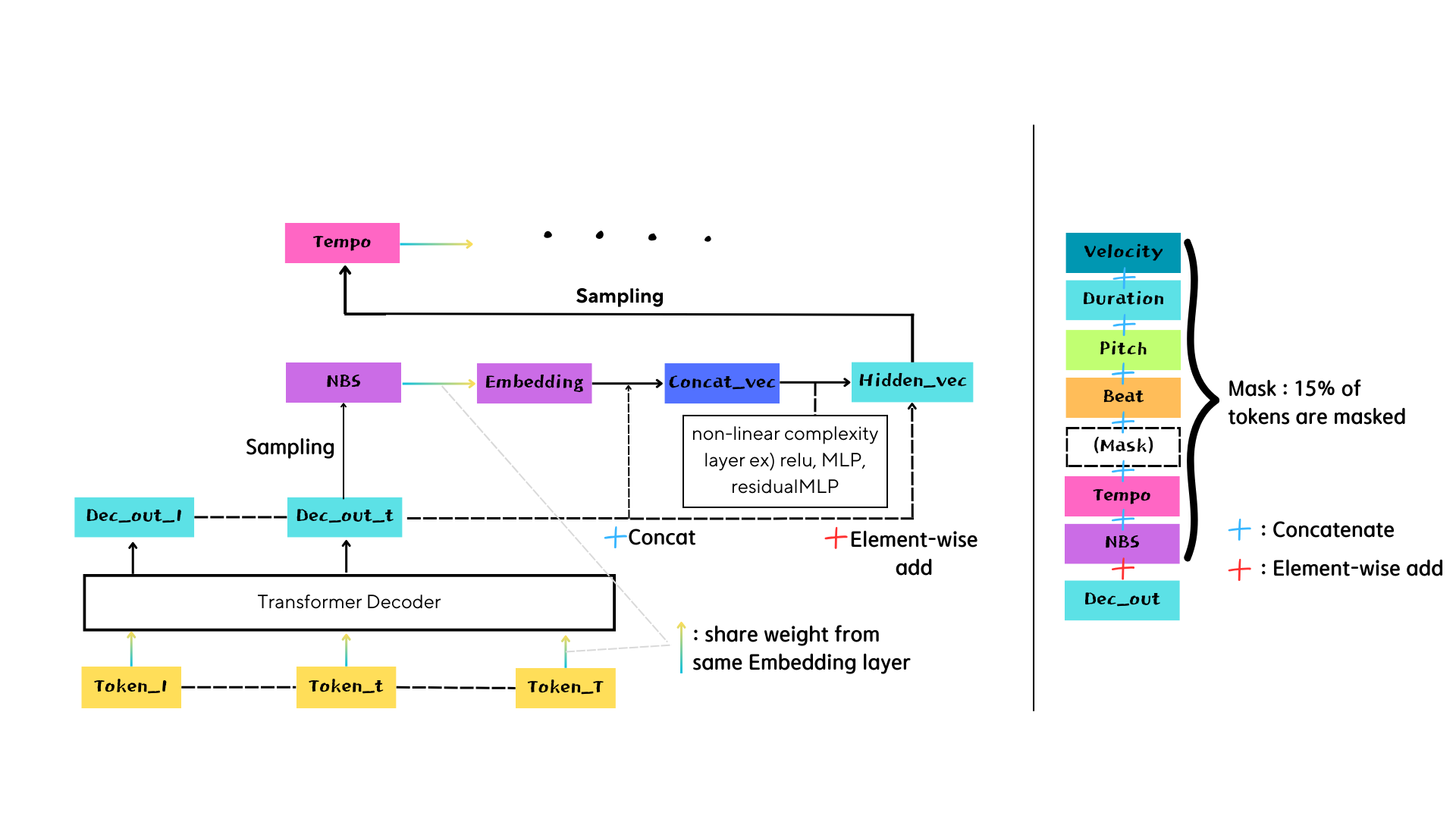
GRU-based RNN
Residual Connection
from Deep Residual Learning for Image Recognition, arxiv
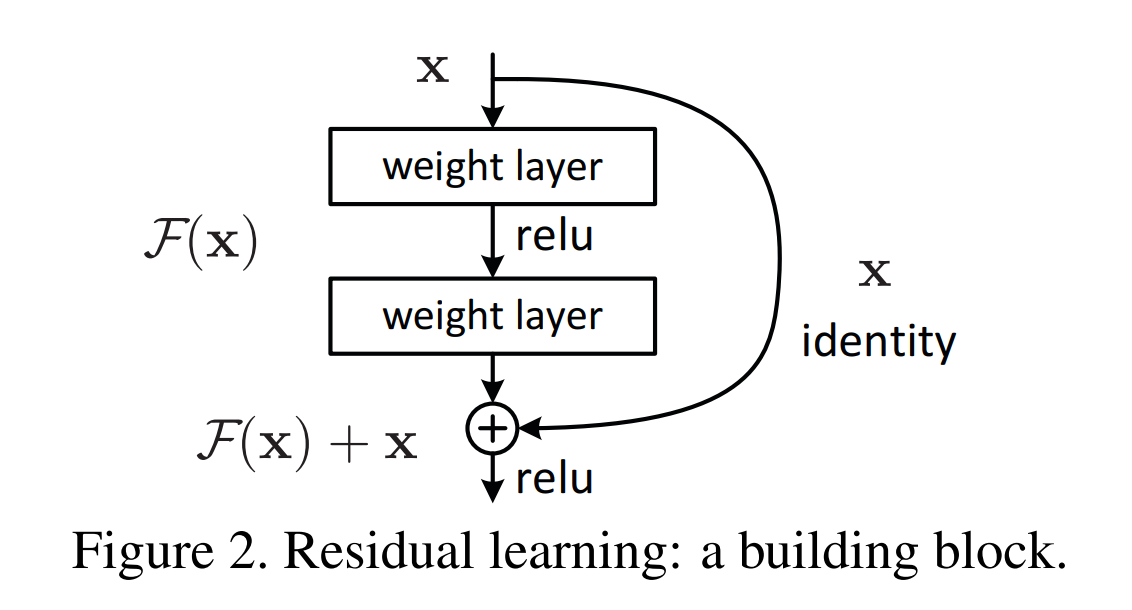
- Skip connection: The addition operation makes it easier for the model to learn identity functions which means that adding extra layers doesn't make things worse but provides an opportunity for further learning.
- Solving Vanishing Gradient Problem: Residual connections allow gradients to backpropagate directly through shortcut paths and hence mitigate this issue.
- Feature Reuse: The skip connection helps in reusing features learned from previous layers which might be lost if only considering the immediate previous layer's output.
ReLU
from Deep Learning using Rectified Linear Units (ReLU), arxiv
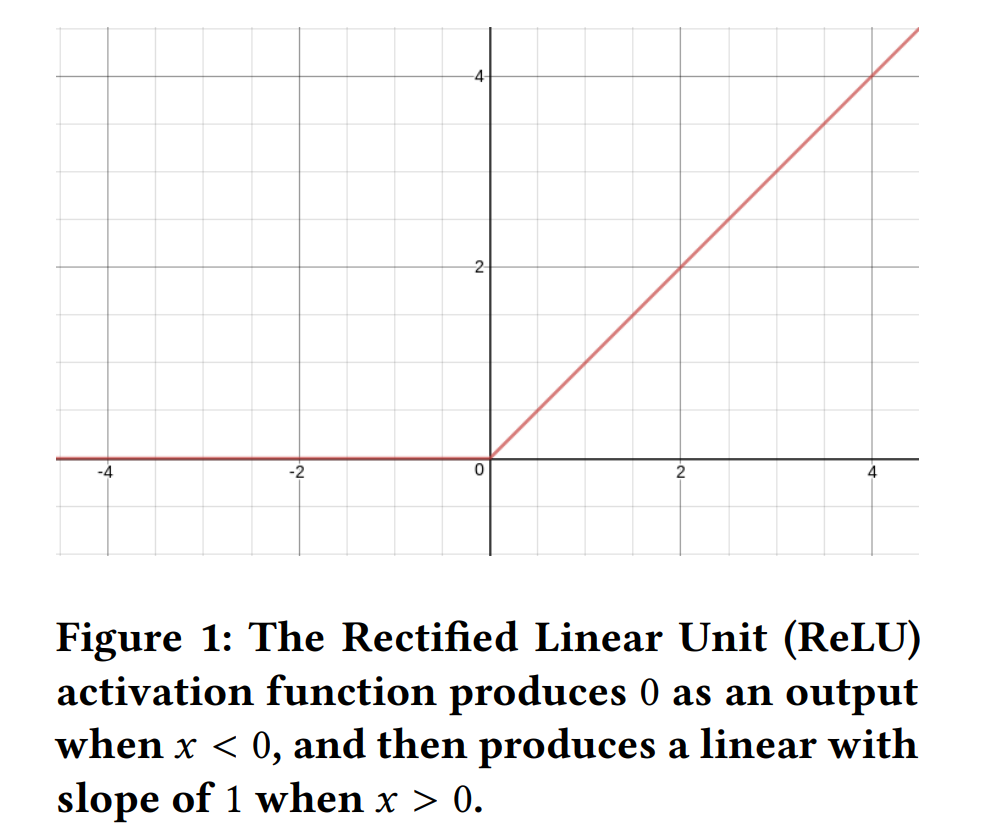
- Non-linearity: The use of ReLU introduces non-linearity which allows the network to learn more complex patterns.
- Sparsity: ReLU has an interesting property that it induces sparsity in the hidden units since it zeros out negative inputs. This means that at any given time during training, certain neurons are not activated thus making the network sparse and more efficient.
- Vanishing gradient problem: Traditional activation functions like sigmoid or tanh squish their input into a very small range ([0, 1] or [-1, 1]). When backpropagation uses these gradients for updates, layers at the beginning of the network train very slowly because they deal with smaller gradients (multiplying small numbers leads to even smaller numbers). On contrary, ReLU does not have this problem since its range is [0, infinity), hence alleviating vanishing gradient problem.
- Simplicity and computational efficiency: The rectifier function is actually quite simple and computationally efficient compared to other activation functions like sigmoid or tanh.
Focal loss
from Focal Loss for Dense Object Detection, arxiv
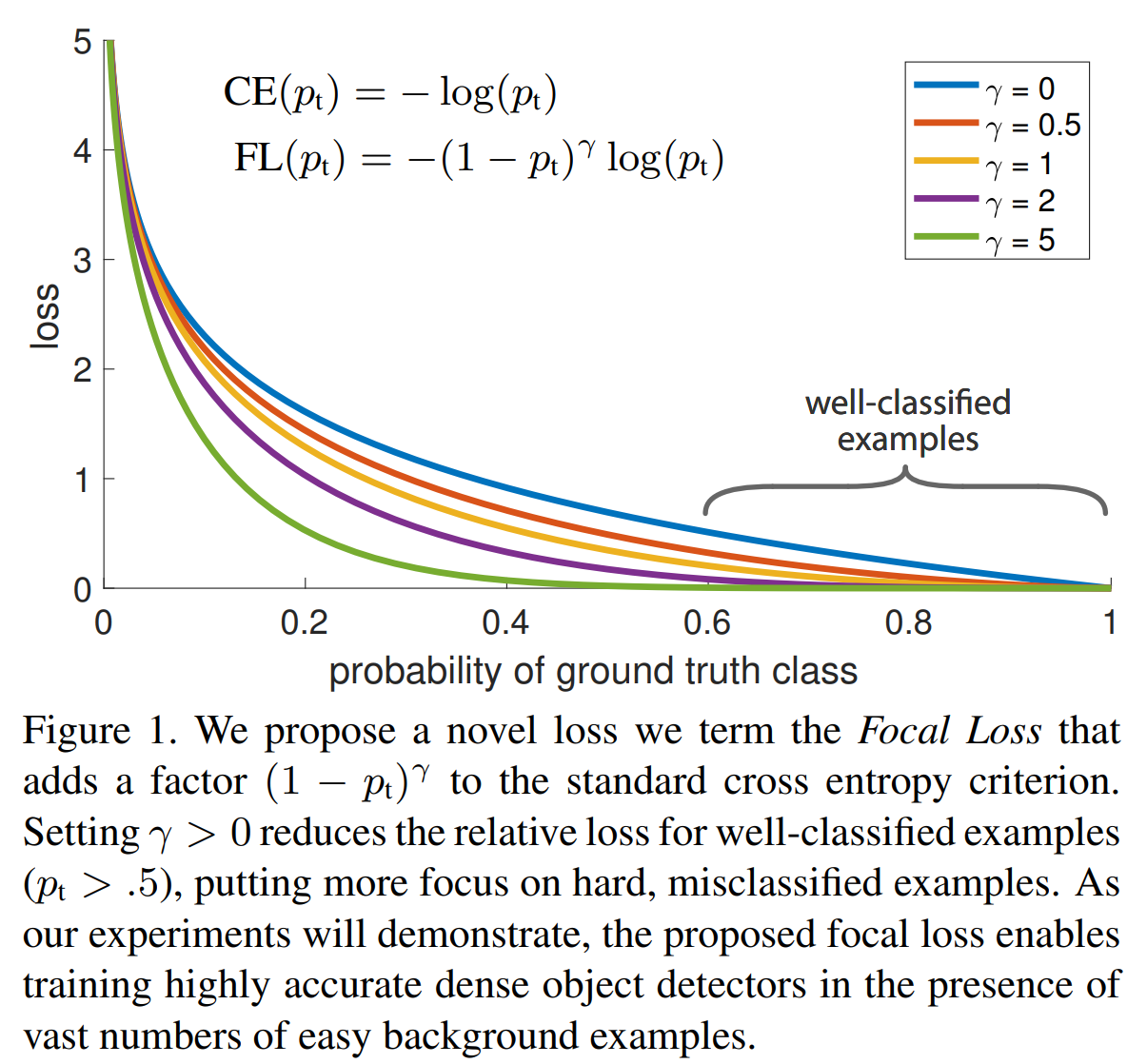
The focal loss function is designed to down-weight easy examples and thus focus training on hard negatives. It adds a modulating factor (1 - pt)^γ to the standard cross entropy criterion, where pt is the probability for the true class, and γ (gamma) is a focusing parameter that controls how much weight is given to hard negatives.
import torch
import torch.nn as nn
class FocalLoss(nn.Module):
def __init__(self, alpha=1., gamma=2.):
super().__init__()
self.alpha = alpha
self.gamma = gamma
def forward(self, inputs, targets):
BCE_loss = nn.BCEWithLogitsLoss()(inputs, targets)
pt = torch.exp(-BCE_loss)
F_loss = self.alpha * (1-pt)**self.gamma * BCE_loss
return F_lossExperiment
We splitted the data into fixed train and valid set.
So, now we can compare two different encoding schemes with same number of note-related tokens (pitch, duration, velocity)

CP(Green) vs. NB(Purple) in linear
This results are recorded before I used focal loss and excluded CONTI tokens
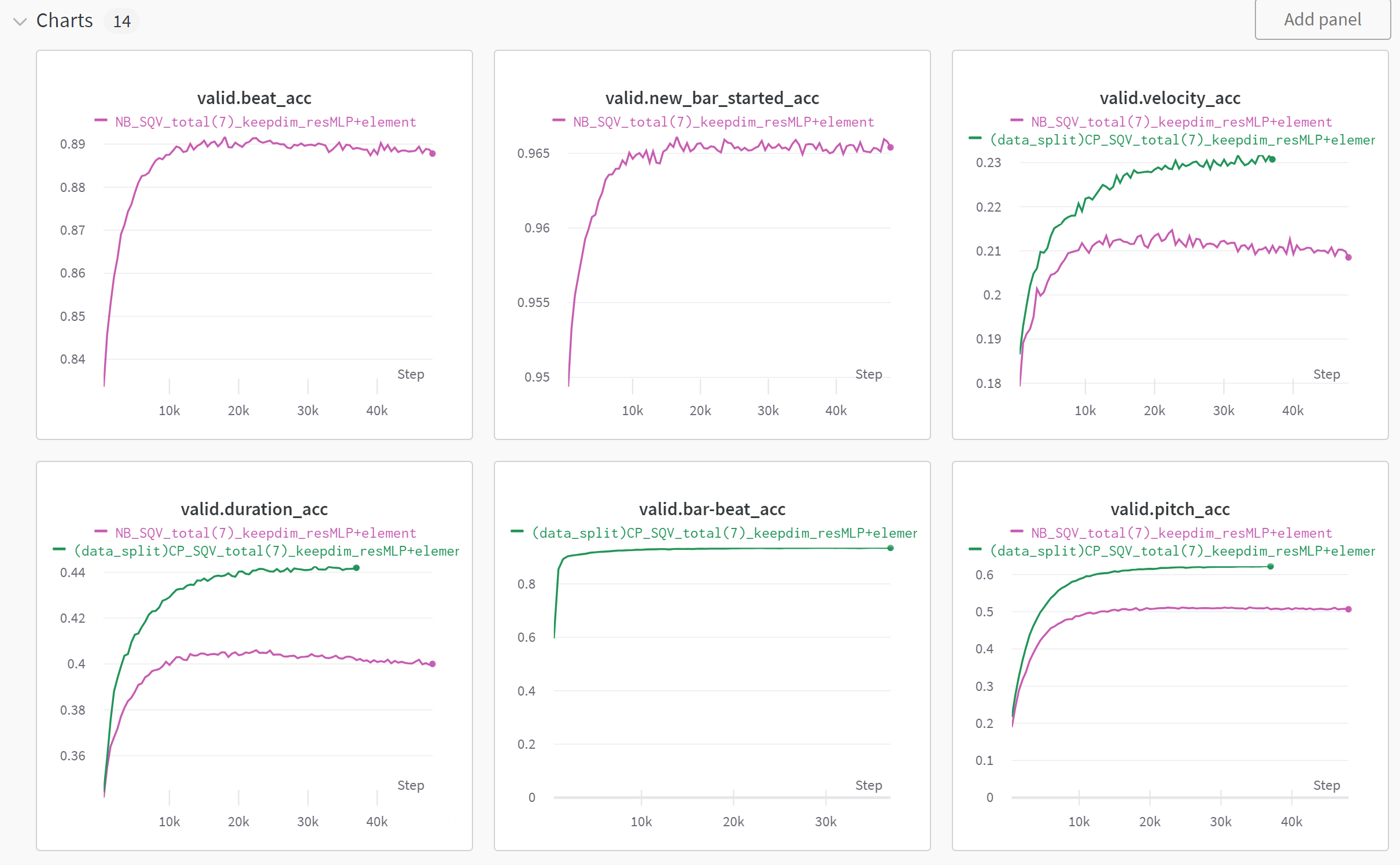
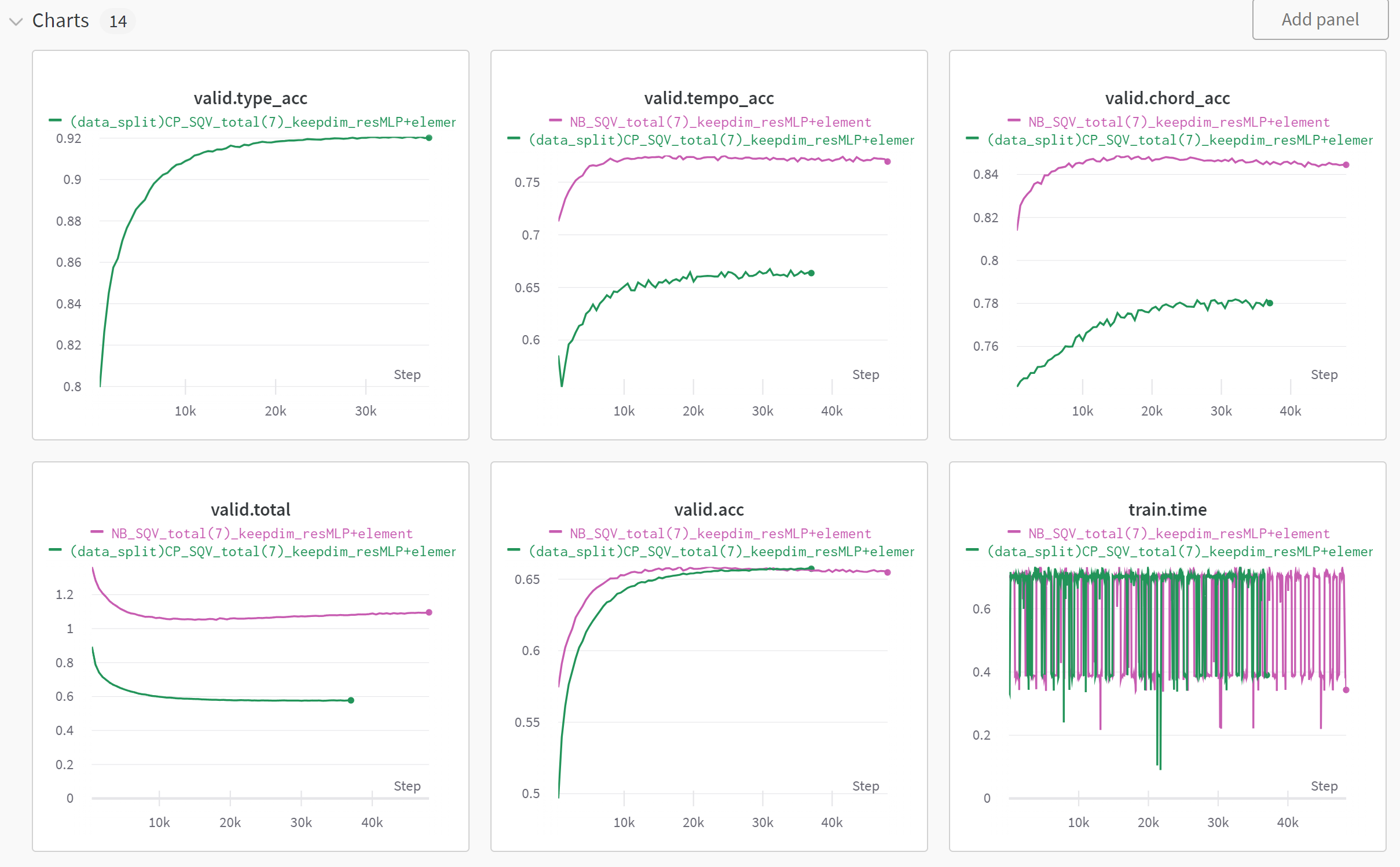
CP(Green) vs. NB(Purple) in GRU
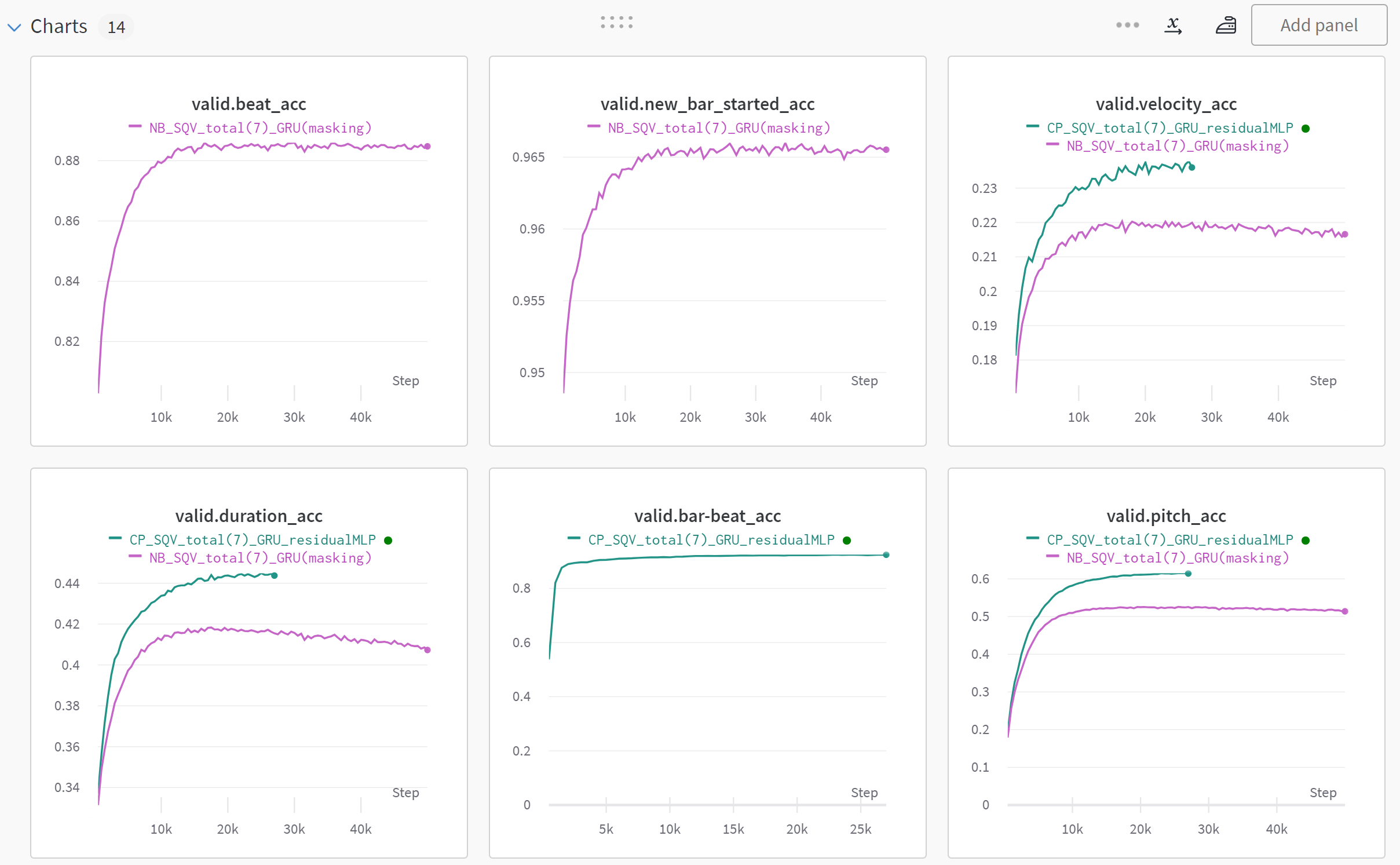
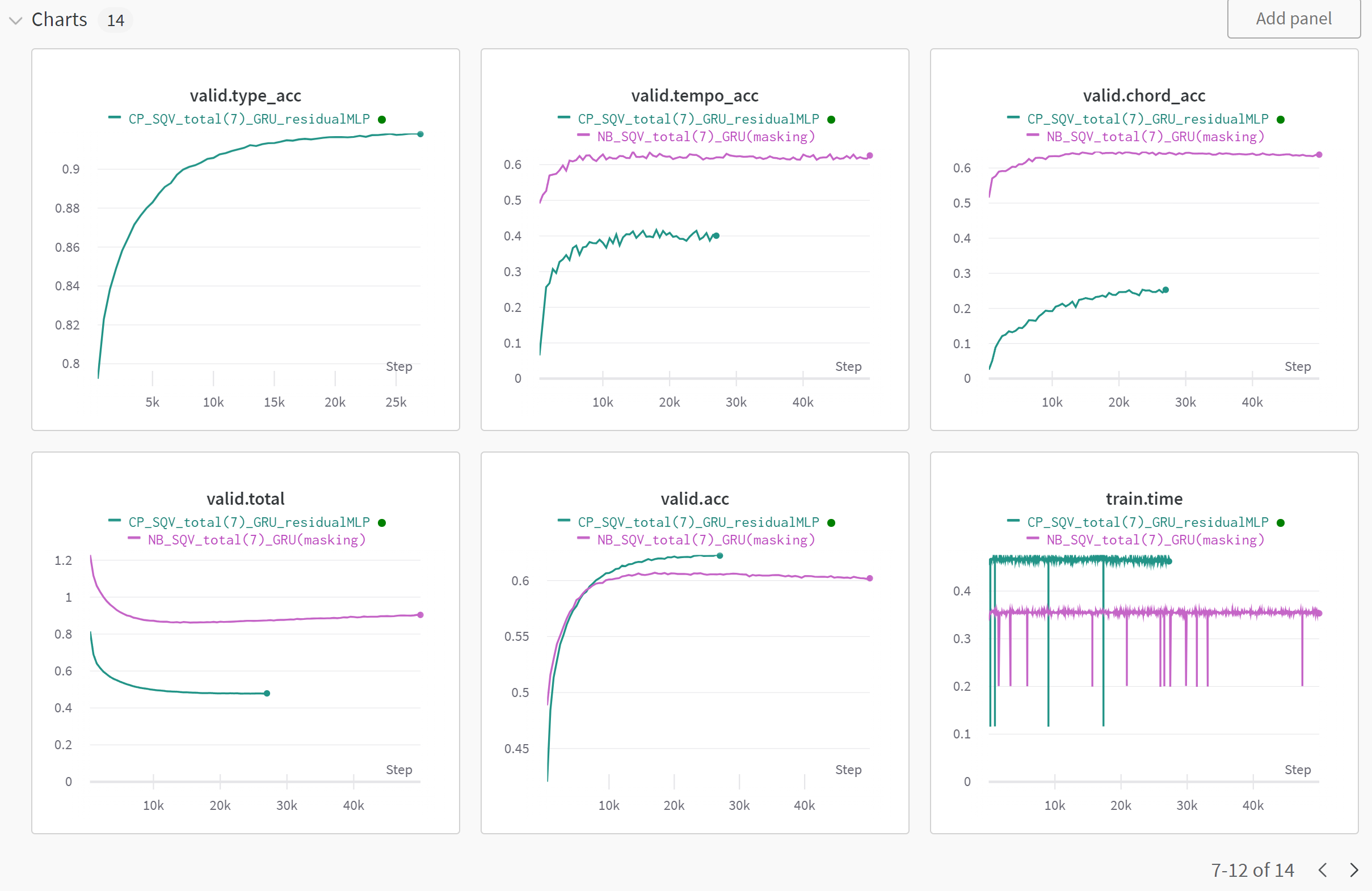
Think Positively
there are plenty of rooms that NB can fulfill
TODO
- Transformer-XL
- RNN part architecture : attention, pitch-first
- Test on a new dataset
- Using different parameters, especially raise size of the model(d_model) because NB encoding is more complicated
- Experiment on different hyper parameters, batch, seed, learning rate
