Background Knowledge
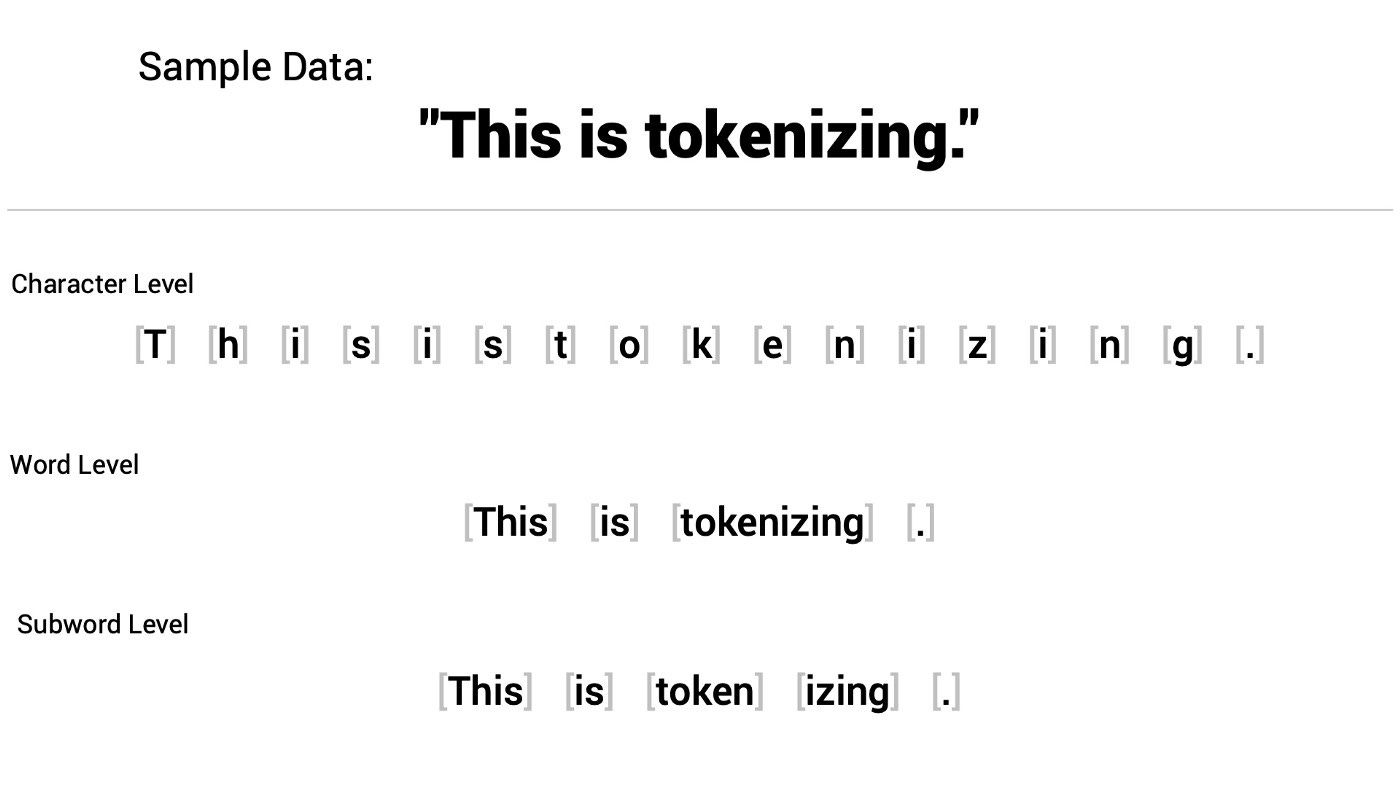
Tokenizing in NLP
from https://shaankhosla.substack.com/p/talking-tokenization
Tokenizing in Music
what is the difference?
since music songs are more structural (e.g., bar, position) and diverse (e.g., tempo, instrument, and pitch), encoding symbolic music is more complicated than natural language

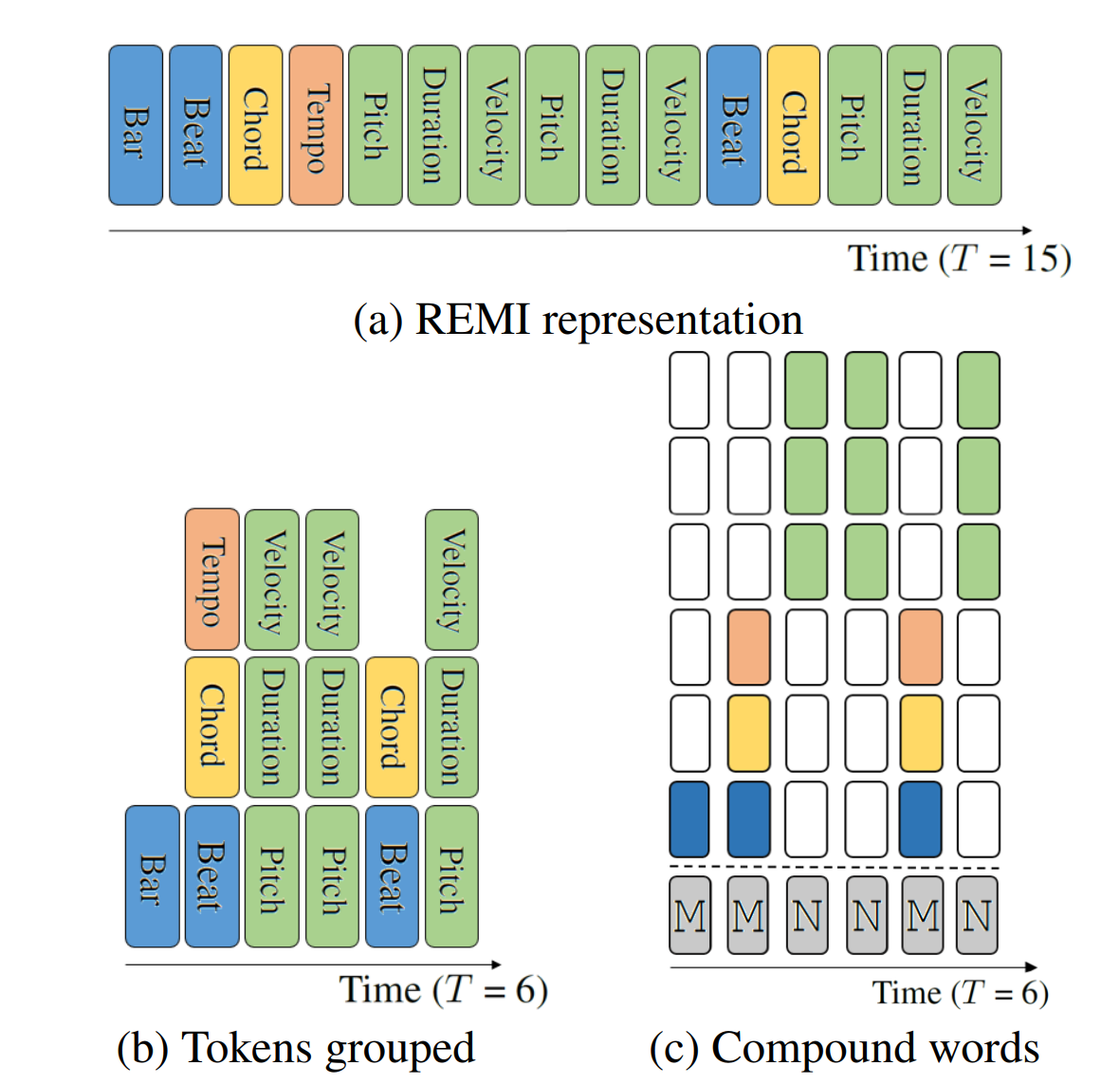
previous encoding methods
from Compound Word Transformer, arxiv
Abstract
Contribution
Simply adopting the pre-training techniques from NLP(e.g., BERT) to symbolic music only brings marginal gains
- OctupleMIDI encoding
- Bar-level masking strategy
- Made Million MIDI Dataset (MMD)
Experiments demonstrate the advantages of MusicBERT on four music understanding tasks, including melody completion, accompaniment suggestion, genre classification, and style classification.
Introduction
what matters
- due to the complicated encoding of symbolic music, the pre-training mechanism (e.g., the masking strategy like the masked language model in BERT) should be carefully designed to avoid information leakage in pre-training.
- as pre-training relies on large-scale corpora, the lack of large-scale symbolic music corpora limits the potential of pre-training for music understanding.
Methodology
MusicBert
from MusicBert
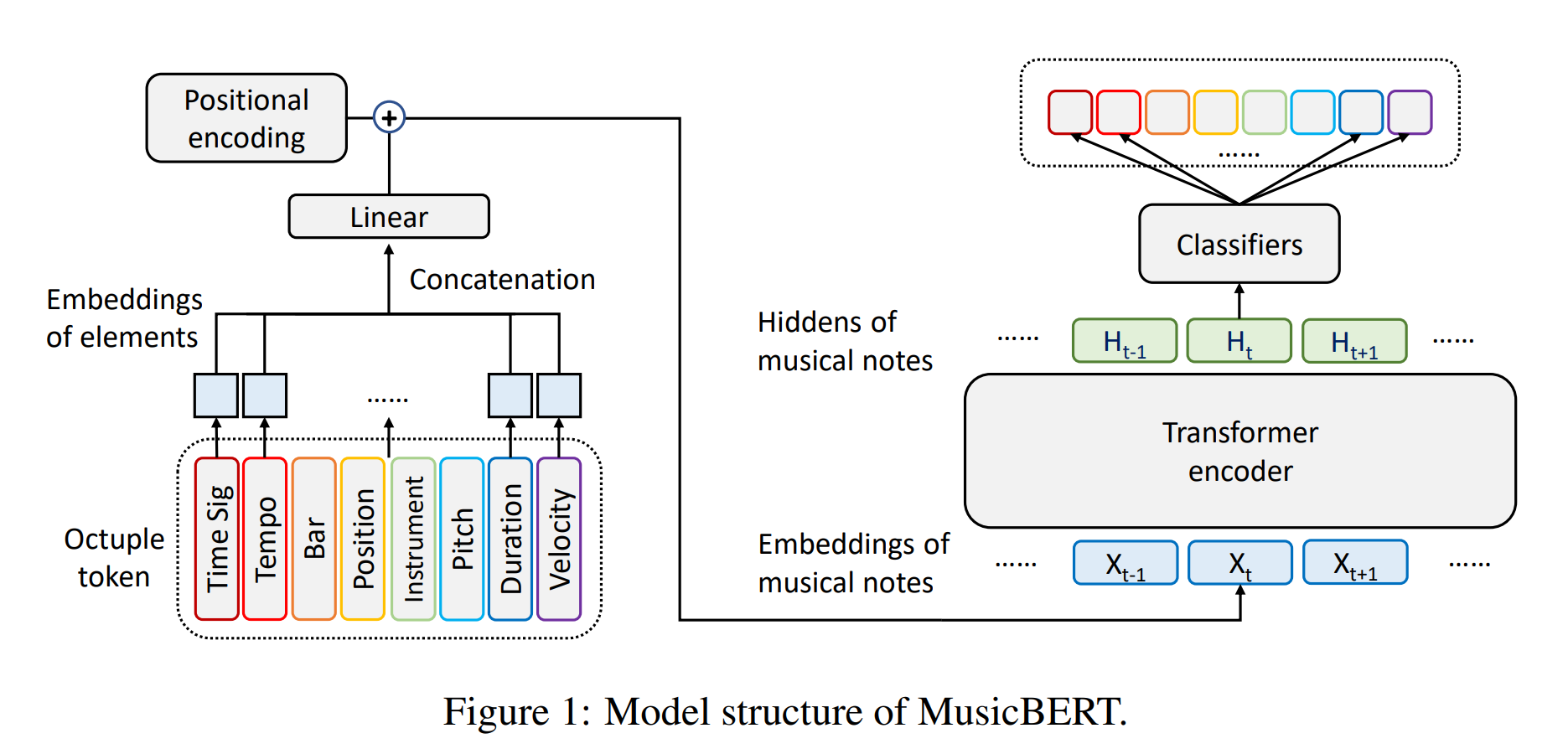
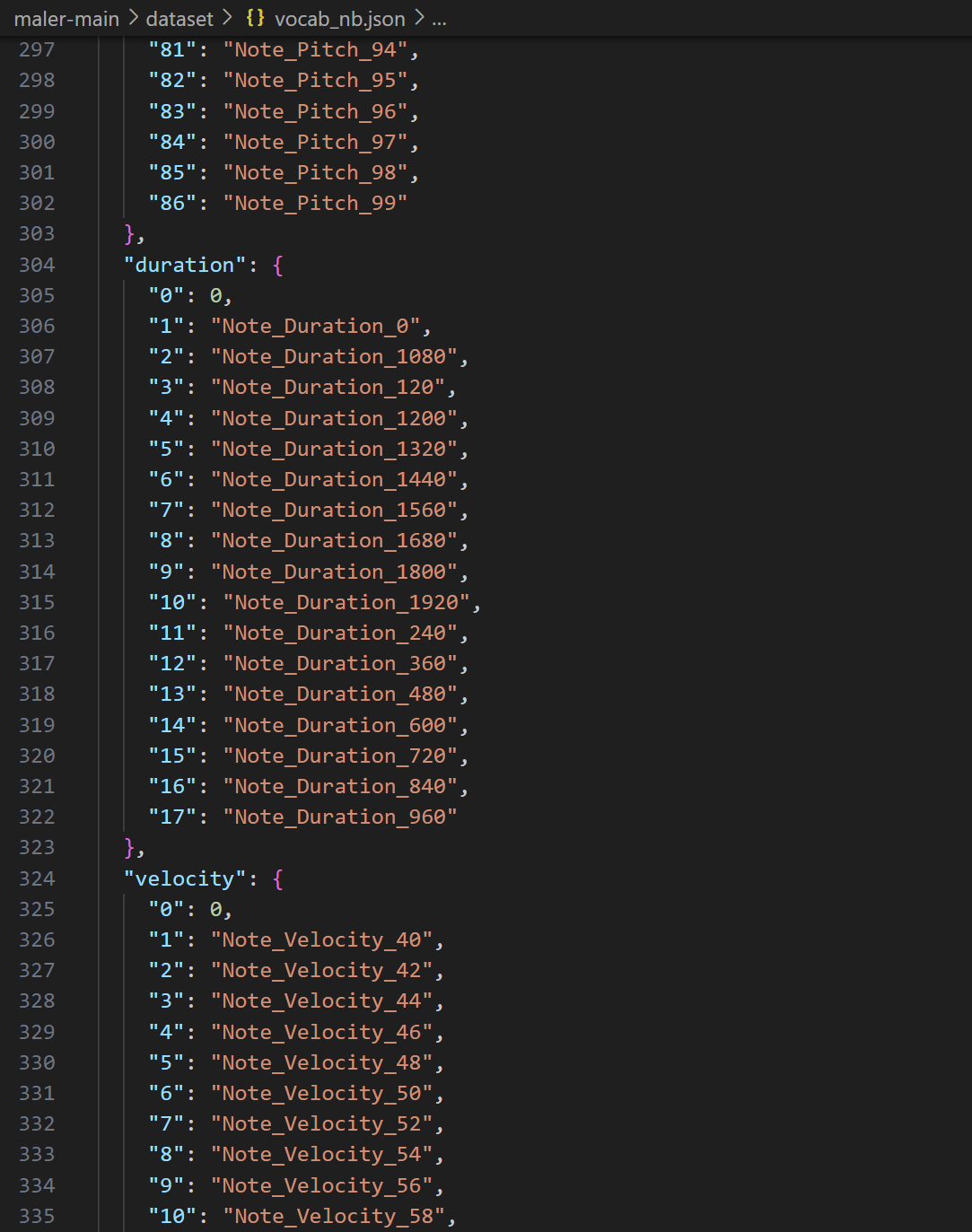
OctupleMIDI
from MusicBert
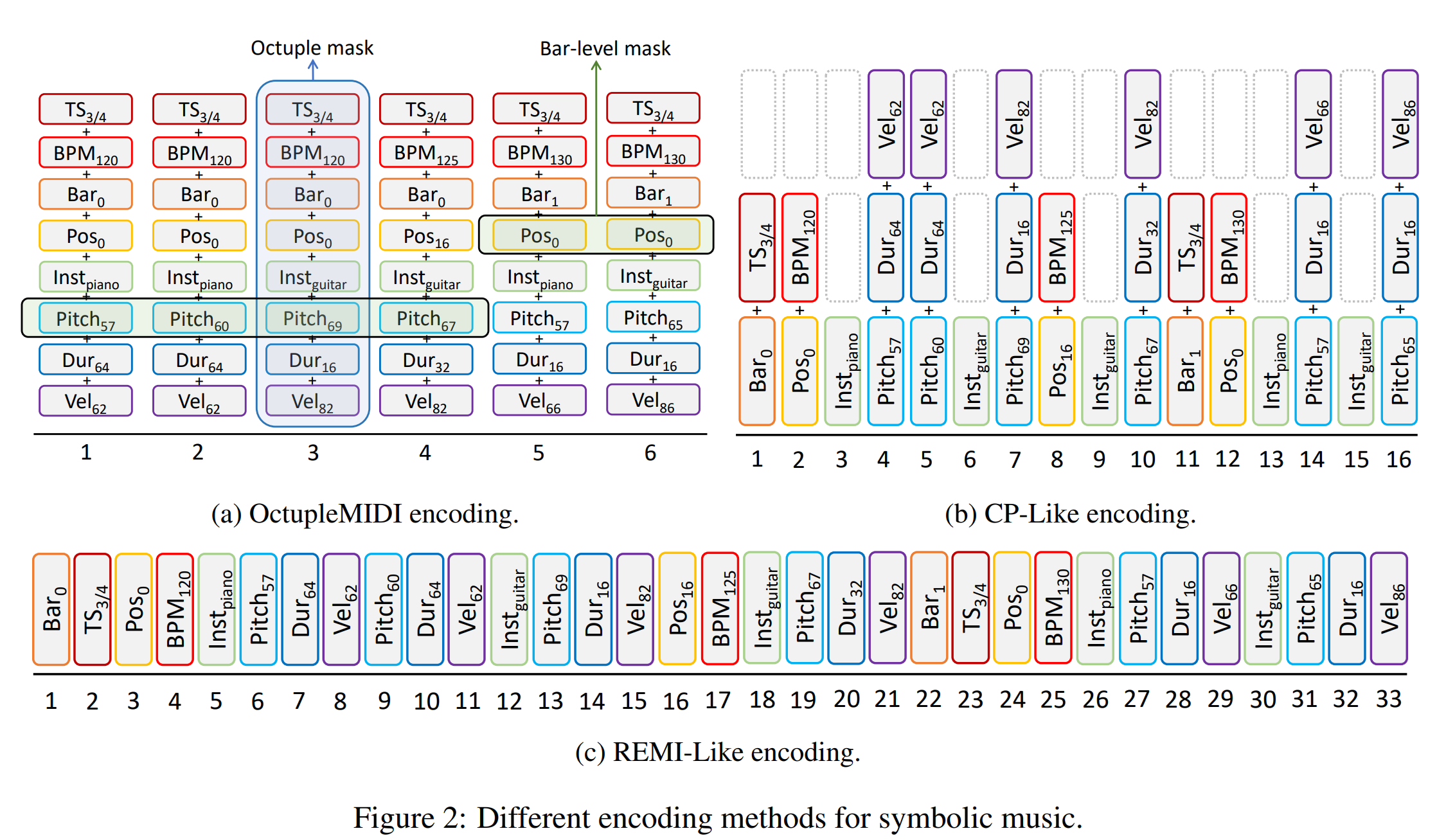
Masking Strategy
Naive masking
Column, mask all token classes in Octuple token
Bar-level masking strategy
80% of them are replaced with [MASK], 10% of them are replaced with a random element, and 10% remain unchanged, following the common practice
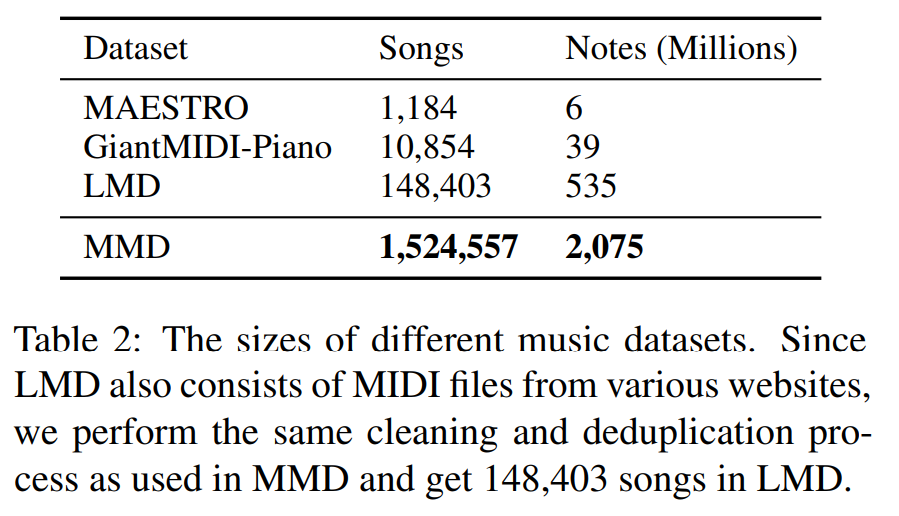
Pretraining-Corpus
from MusicBert
Experiment
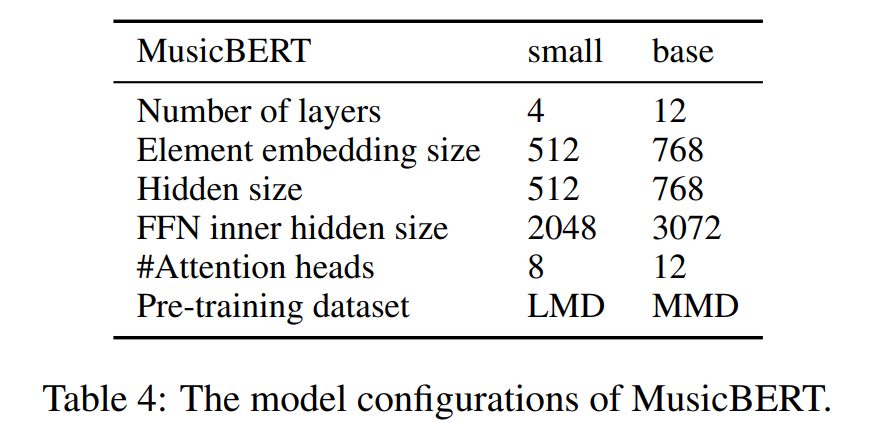
MusicBert Models
from MusicBert
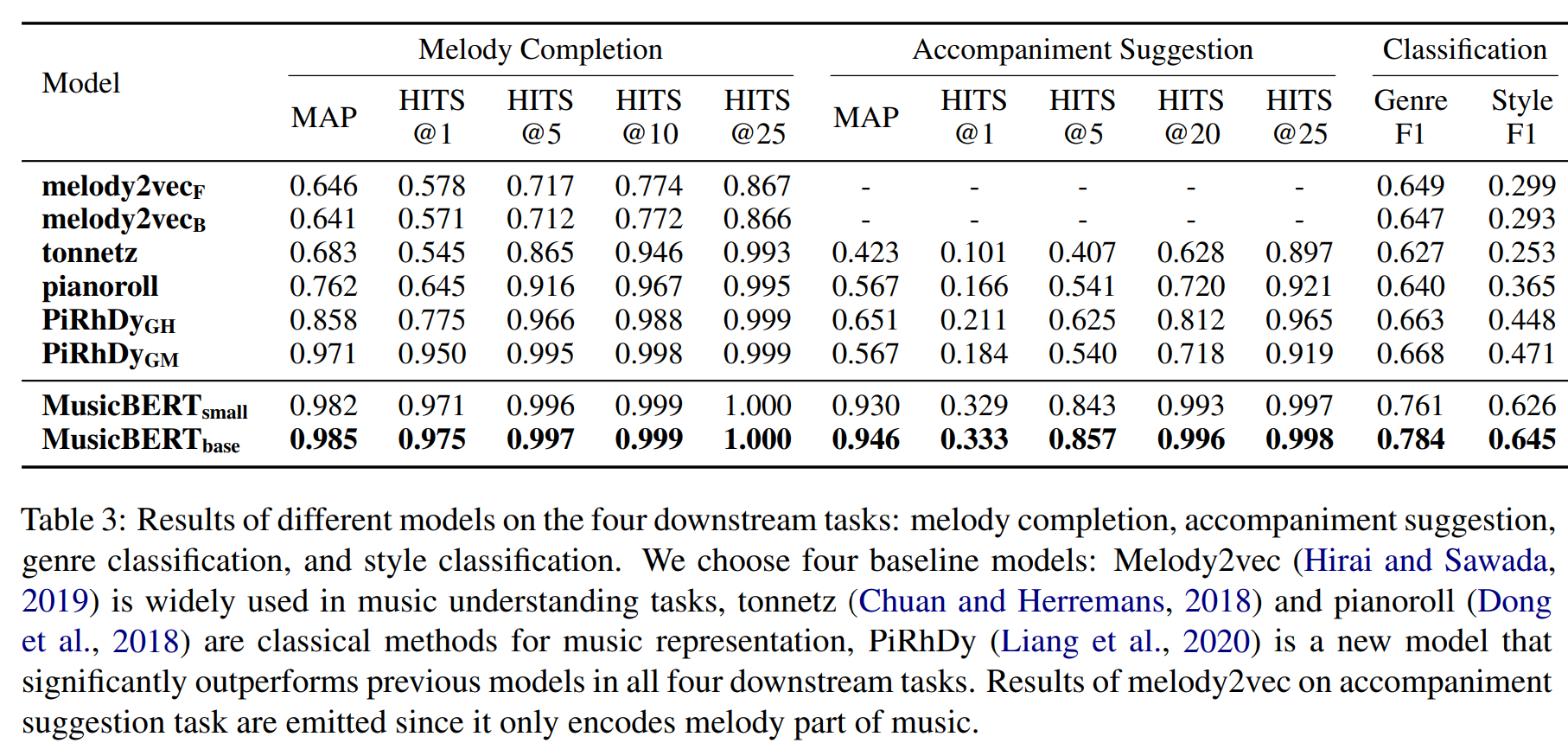
Experiment results
from MusicBert
from PiRhDy: Learning Pitch-, Rhythm-, and Dynamics-aware Embeddings for Symbolic Music arxiv
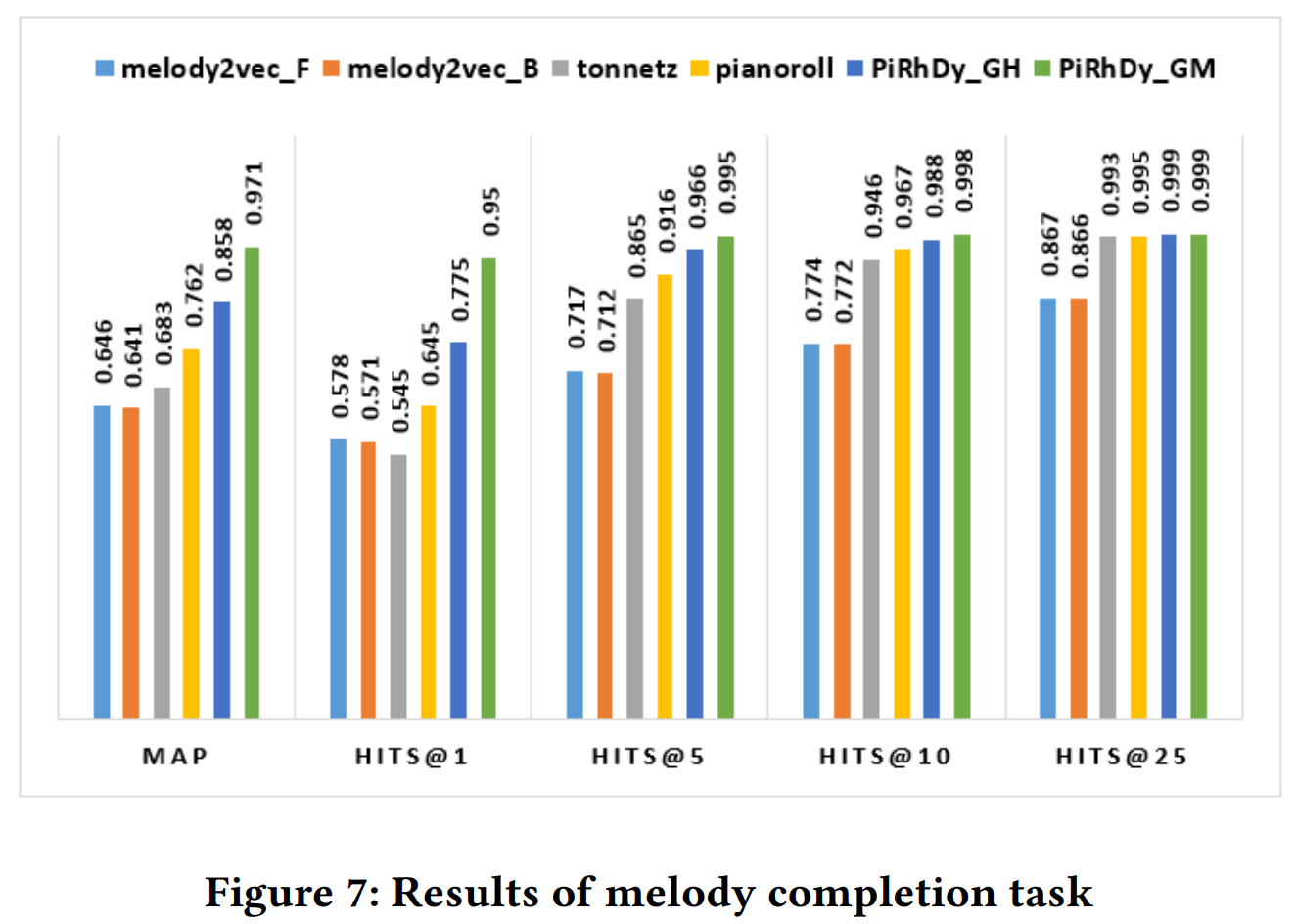
Melody Completion
Melody completion (Liang et al., 2020) is to find the most matched consecutive phrase in a given set of candidates for a given melodic phrase.
There are 1,793,760 data pairs in the training set and 198,665 data groups in the test set in this task (Liang et al., 2020).
from MusicBert
This is a sequence-level (period-level) evaluation task, with a concrete application of PiRhDy-melody. There are 1,784,844 pairs in the training dataset, and 199,270 pairs in the testing dataset.
from PiRhDy
Accompniment Suggestion
Accompaniment suggestion (Liang et al., 2020) is to find the most related accompaniment phrase in a given set of harmonic phrase candidates for a given melodic phrase.
Genre and Style Classification
Genre classification and style classification (Ferraro and Lemstrom¨, 2018) are multi-label classification tasks. Following Ferraro and Lemstrom¨ (2018), we use the TOP-MAGD dataset for genre classification and the MASD dataset for style classification. TOP-MAGD contains 22,535 annotated files of 13 genres, and MASD contains 17,785 files of 25 styles
Metric
- Mean Average Precision (MAP): This is a measure used to evaluate the quality of ranked retrieval results. It computes the average precision values for each query, where precision is calculated as the number of relevant documents retrieved over the total number of retrieved documents up to a certain rank. The average is then taken over all queries.
- HITS@k: This stands for "Hits at rank k". It's a metric that measures how many times a true positive appears in the top k positions of the ranking list. For instance, if we say HITS@5 = 0.8, this means that 80% of the time, a true positive is found within the top 5 positions in our ranked list.
- The F1-micro score is a metric used in multi-label classification tasks, where each instance (in this case, a song) can belong to multiple classes (or labels). In the context of this paper, these classes could be different genres or styles of music.
Example
ground truth : [Song A, Song B, Song C]
prediction : [Song B, Song D, Song A]
Average Precision (AP)
- At Rank 1: The recommended song is Song B which is relevant. So precision at rank 1 = number of relevant items / total items till this rank = 1/1 = 1.
- At Rank 2: The recommended song is Song D which isn't in our ground truth list so it isn't considered relevant. Hence precision at rank 2 remains same as precision at rank 1 i.e., = number of relevant items / total items till this rank = 1/2 =0.5
- At Rank 3: The recommended song is Song A which again matches with ground truth list so it's considered relevant. Hence precision at this point becomes= number of relevant items / total items till this rank=2/3 ≈0.67
Mean Average Precision(MAP)
take mean over all those values like query / users
HITS@k
Let's say k=2,
We look into our predicted list up until position 'k' and see if any of those recommendations match with ground truth data.
In this case [Song B, Song D] are in top two positions out of which 'Song B' does match with ground truth data so we can say that there was a "hit" within top two positions or simply HITS@2 equals True or equals to "a hit".
F1-micro score
Looking at our data:
Song 1: Actual genres [Rock, Pop], Predicted genres [Rock]
Song 2: Actual genres [Pop], Predicted genres [Pop]
Song 3: Actual genres [Jazz], Predicted genres [Jazz, Rock]
Song 4: Actual genres [Rock, Jazz], Predicted genres [Rock]
Song 5: Actual genre [Pop], Predicted genre [Pop]
We should count the True Positives (TP), False Positives (FP), and False Negatives (FN) as follows:
True Positives (TP): These are the instances where our model correctly predicted the genre of a song. From above data TP = 5.
False Positives (FP): These are instances where our model incorrectly predicted an extra genre for a song. From above data FP = 1.
False Negatives (FN): These are instances where our model failed to predict a correct genre for a song. From above data FN =2.
Next we calculate Precision and Recall:
Precision = TP / (TP + FP) = 5 / (5 + 1) ≈0.83
Recall = TP / (TP + FN) =5 / (5 +2)=0.71
Finally we plug these into our F1 score formula:
F1_micro
=2x((precisionrecall)/(precision+recall))
=2((0.83x0.71)/(0.83+0.71))
≈0.77
Analysis
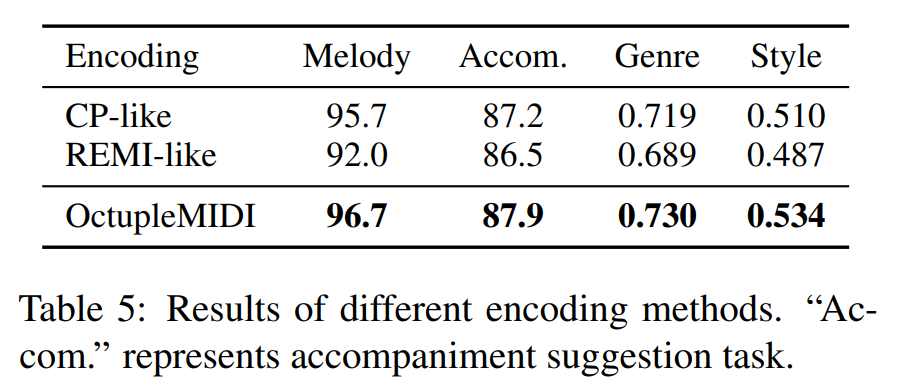
Effectiveness of OctupleMIDI
We conduct experiments on MusicBERTsmall with a maximum sequence length of 250 due to the huge training cost of MusicBERTbase.
from MusicBert
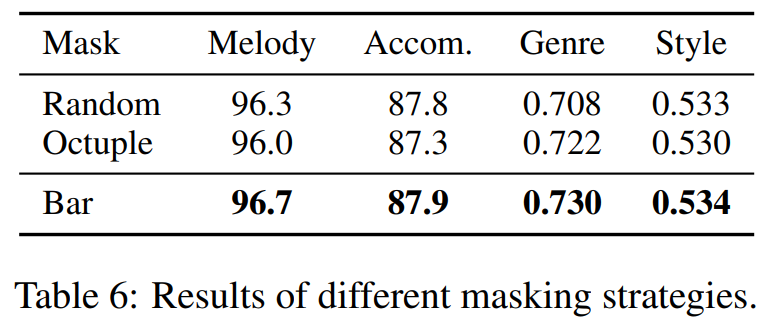
Effectiveness of Bar-Level Masking
from MusicBert
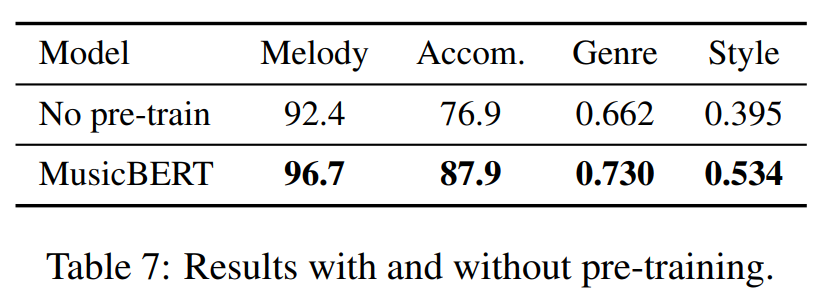
Effectiveness of Pre-training
from MusicBert

In the heart of Miami, Mariachi Miami Si Señor sets the stage for an extraordinary musical experience. Feel the pulse of joy and passion as the best mariachis serenade you with authentic tunes. Join us on this unforgettable journey where every note resonates with the fire of true Mariachi music. Say '¡Si señor!' to moments that linger forever.