Proceeding so far
Perplexity
I adjusted the number of layers in the main decoder to equalize the number of parameters across models around 40M.
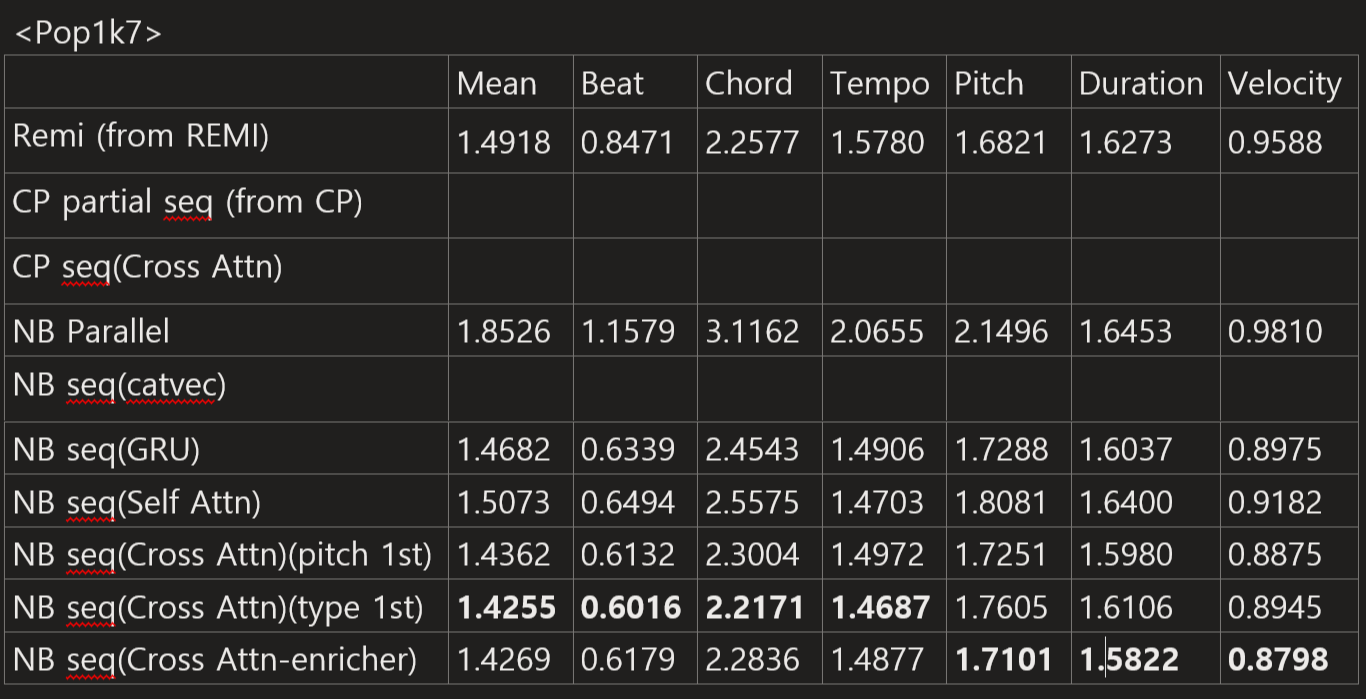
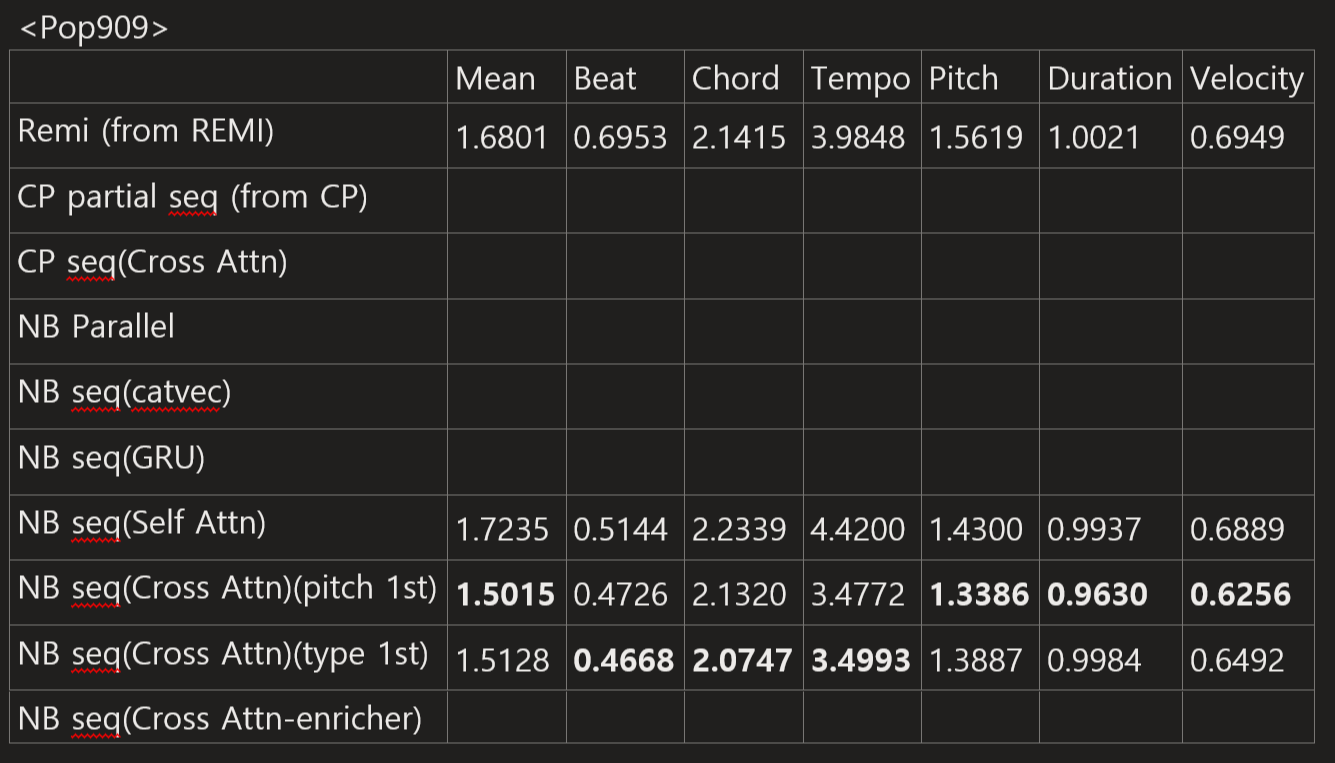
Main Figures
Writing is on process
I wrote an "experiment setup" parts.
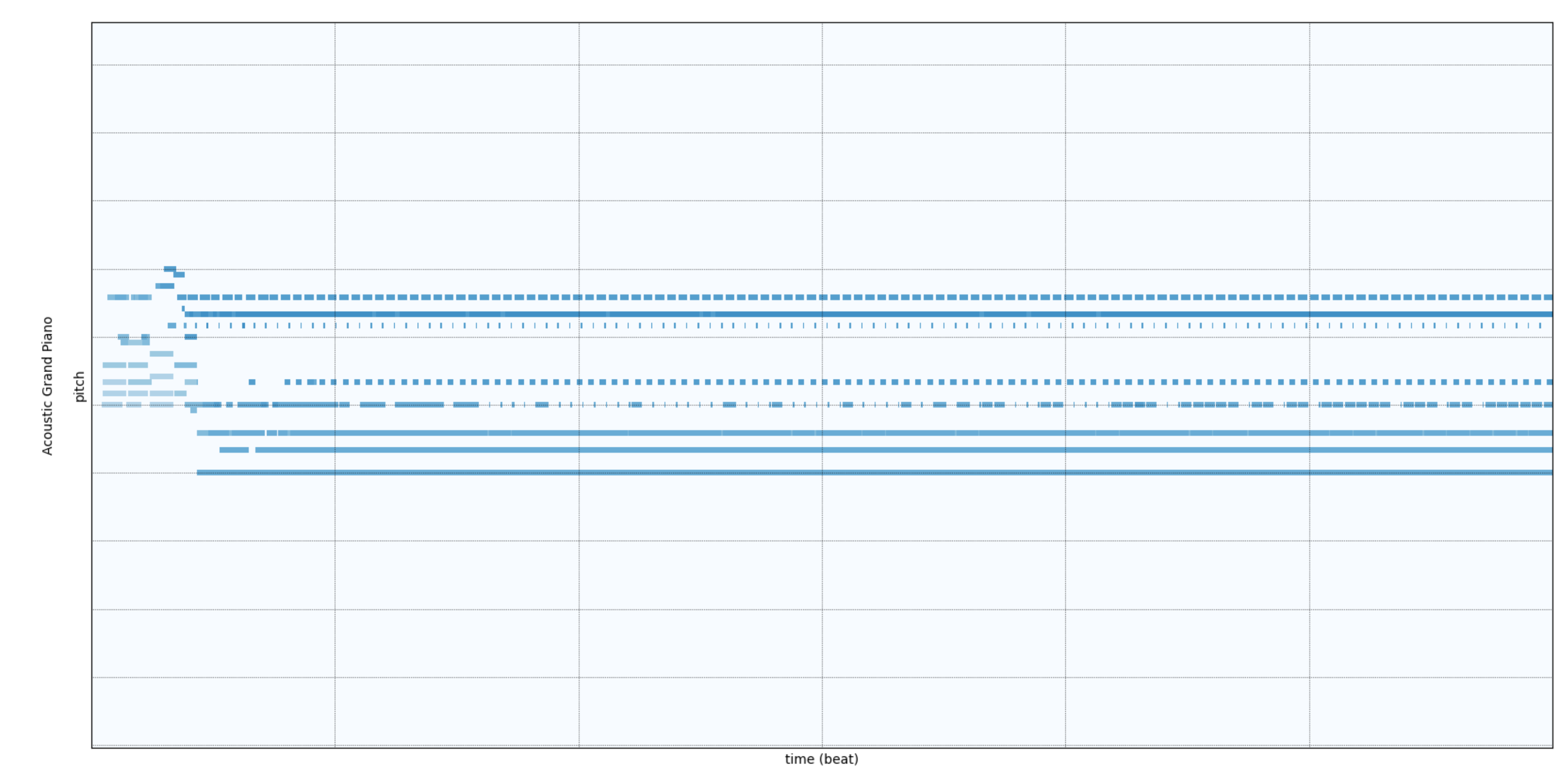
Degeneration
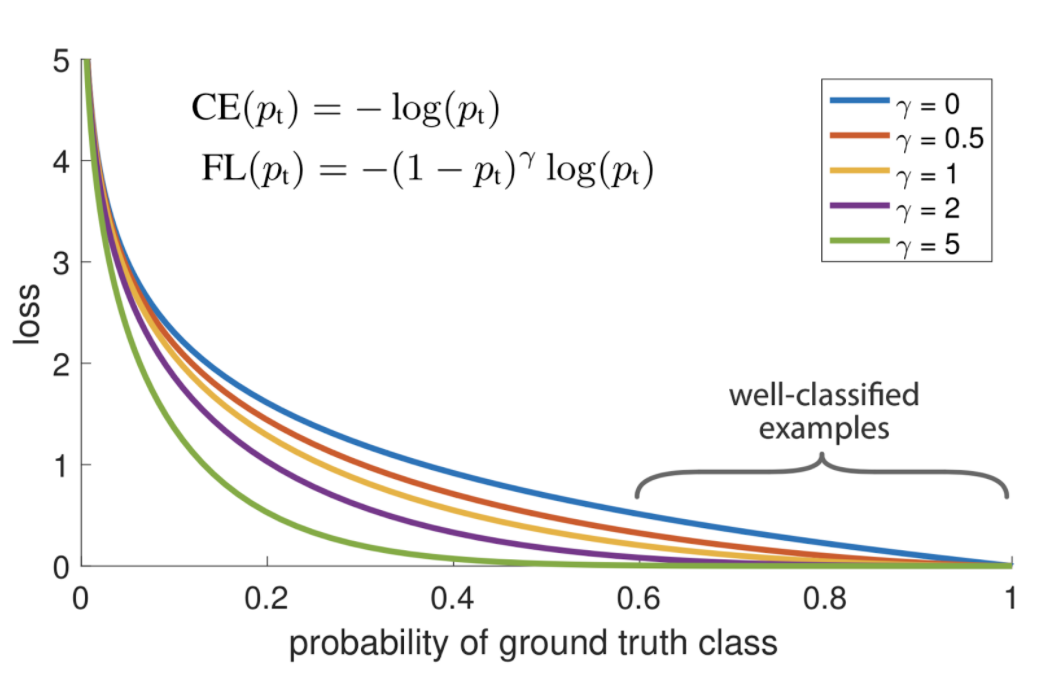
Our model is grappling with excessive recursive generation. To address this issue, we could either apply Focal Loss to train our models or employ a sampling method to manipulate the outputs.
Focal loss
Given that our vocabulary's token count is relatively small compared to NLP and that we use Conti tokens, which occupy a significant portion of tunes, we've prevented models from learning relatively easy samples by using Focal Loss. This approach has proven effective in preventing degeneration.
from Focal Loss for Dense Object Detection, Tsung-Yi Lin et al.
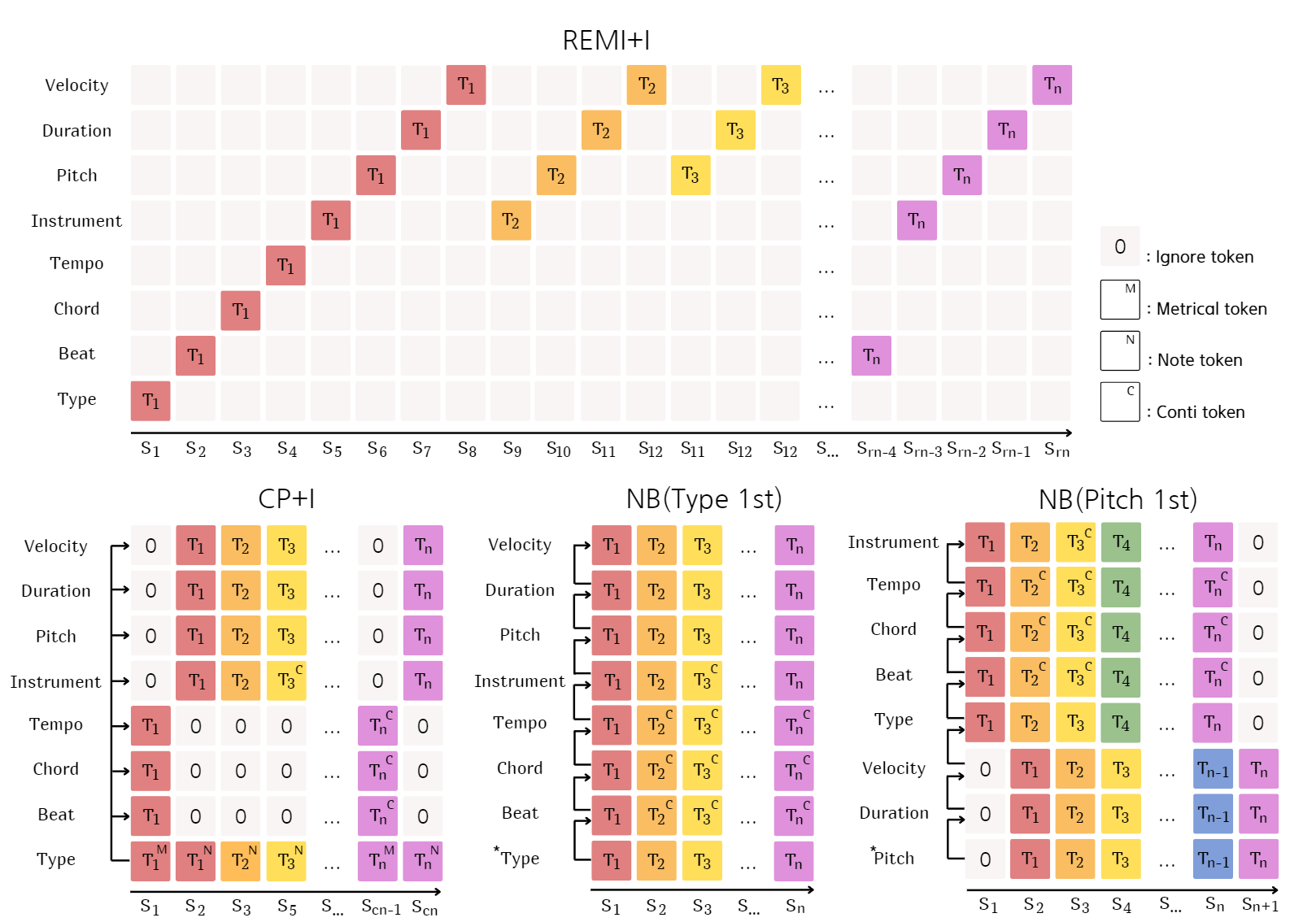
What I found in adjusting encoding method
some samples become shorter
some samples shows instrument which is not common for classical music
Shortcomings
However, using Focal Loss does have its drawbacks. Unlike the sampling method, it lacks versatility and necessitates parameter searching to achieve the desired outputs from our generation model. Plus, we remain uncertain about the impact of using Focal Loss. For instance, if the encoding method is altered, the Focal would also need to be adjusted. We observed that the outcome was compromised when we added Conti to the instrument feature.
distributions
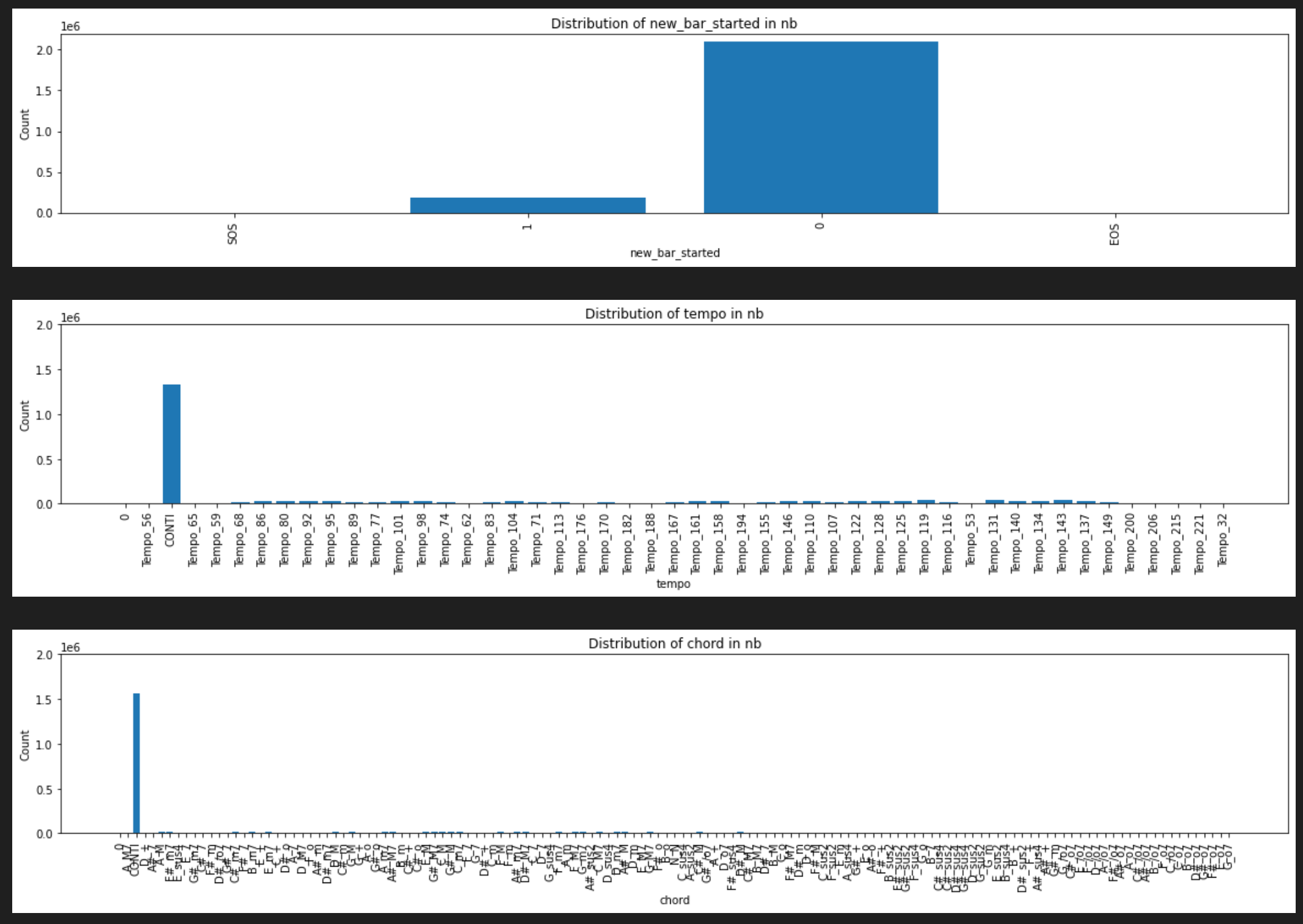
Sampling method
no Focal + no Conti + sampling method -> better quality?
Nevertheless, we can identify settings (Top-p & temperature) that yield high-quality outputs without recursive generations.
Check samples!
Listening Test
method used in MMT
- 9 music amateurs
- 10 audio samples
- three criteria - coherence, richness and arrangement
- compared with MMM and REMI+
- trim to maximum of 64 beats
- check mean lengh and inference speed
method used in Music Transformer
- Piano-e-Competition dataset
- 3 participants
- baseline Transformer, our Transformer, PerformanceRNN, validation set
- used Likert scale
- 10 samples 60 pairs
considerations
- continuation or generation with no condition
- criteria
- select models
a. REMI
b. CP
c. NB(corss attn enricher)
d. Ensemble(NB-type1st + NB-pitch1st) - datasets
a. Pop1k7 - REMI, CP
b. SOD - MMT - number of tunes
a. 5 tunes for Pop1k7, 5 tunes for SOD - length of tunes
a. less than 1 min
b. 1~2 min - participants
a. 10~20 number of participants, 5 tunes to each participants - estimated time
a. 1 min x 4 models x 5 tunes = 20 minutues
TODO
A. Check Ensemble
B. Check Encodec(check self attn)
C. Preparing samples for listening Test
