[Symbolic-Music-Encoding]#extra Double-sequential Transformer for DHE presentation
Projects

Background Knowledge
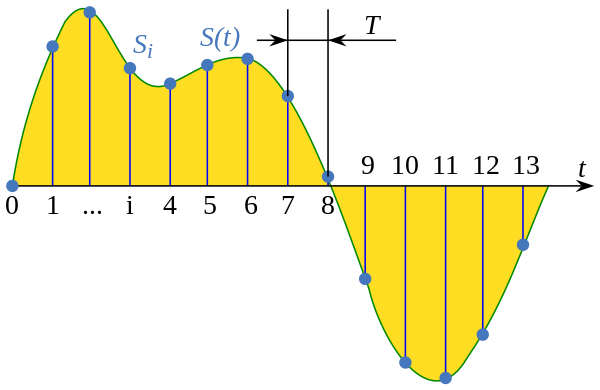
Audio as data
from wikipedia, Sampling (signal processing)
Music Generation
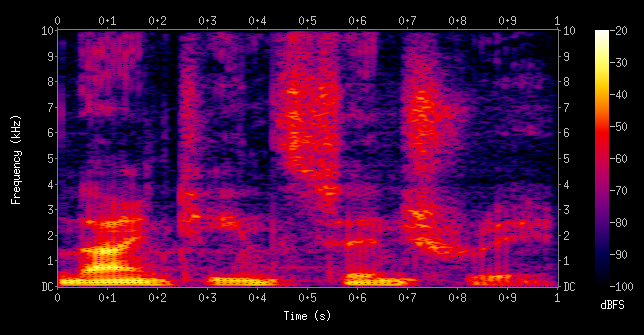
Spectrogram
from wikipedia, spectrogram
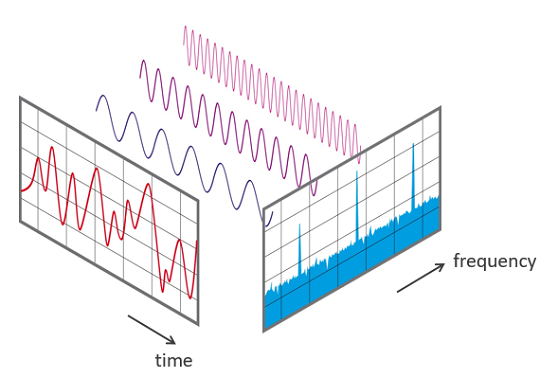
Fourier transform
from microsoft, Feature engineering and Machine Learning with IoT data
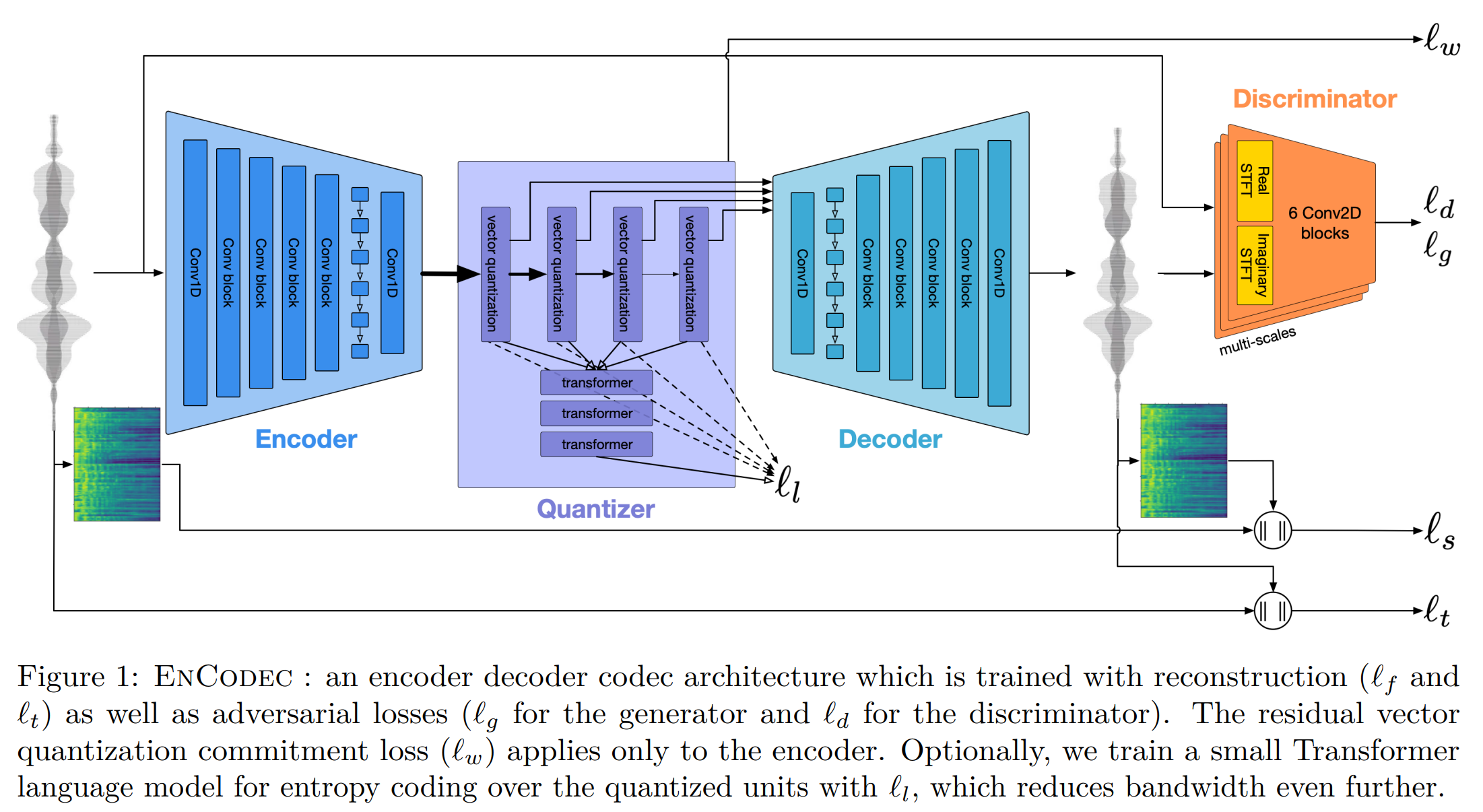
Encodec
from the paper "High Fidelity Neural Audio Compression", Alexandre Défossez et al. arxiv
MusicGen
from the paper "Simple and Controllable Music Generation", Jade Copet et al. arxiv

Symbolic music
https://velog.io/@clayryu328/Symbolic-Music-Encoding5.7-Figures-of-symbolic-music-processing
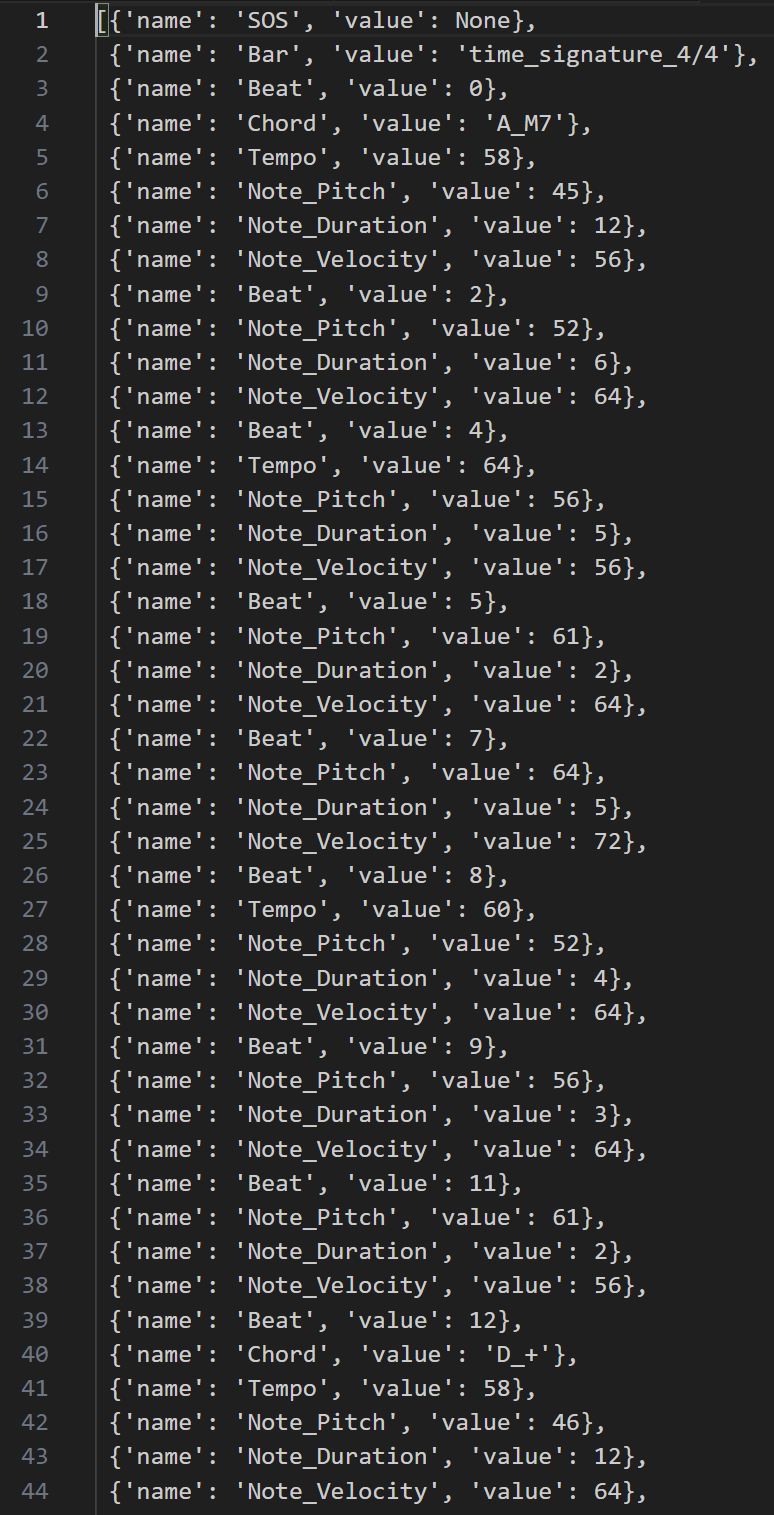
Introduction
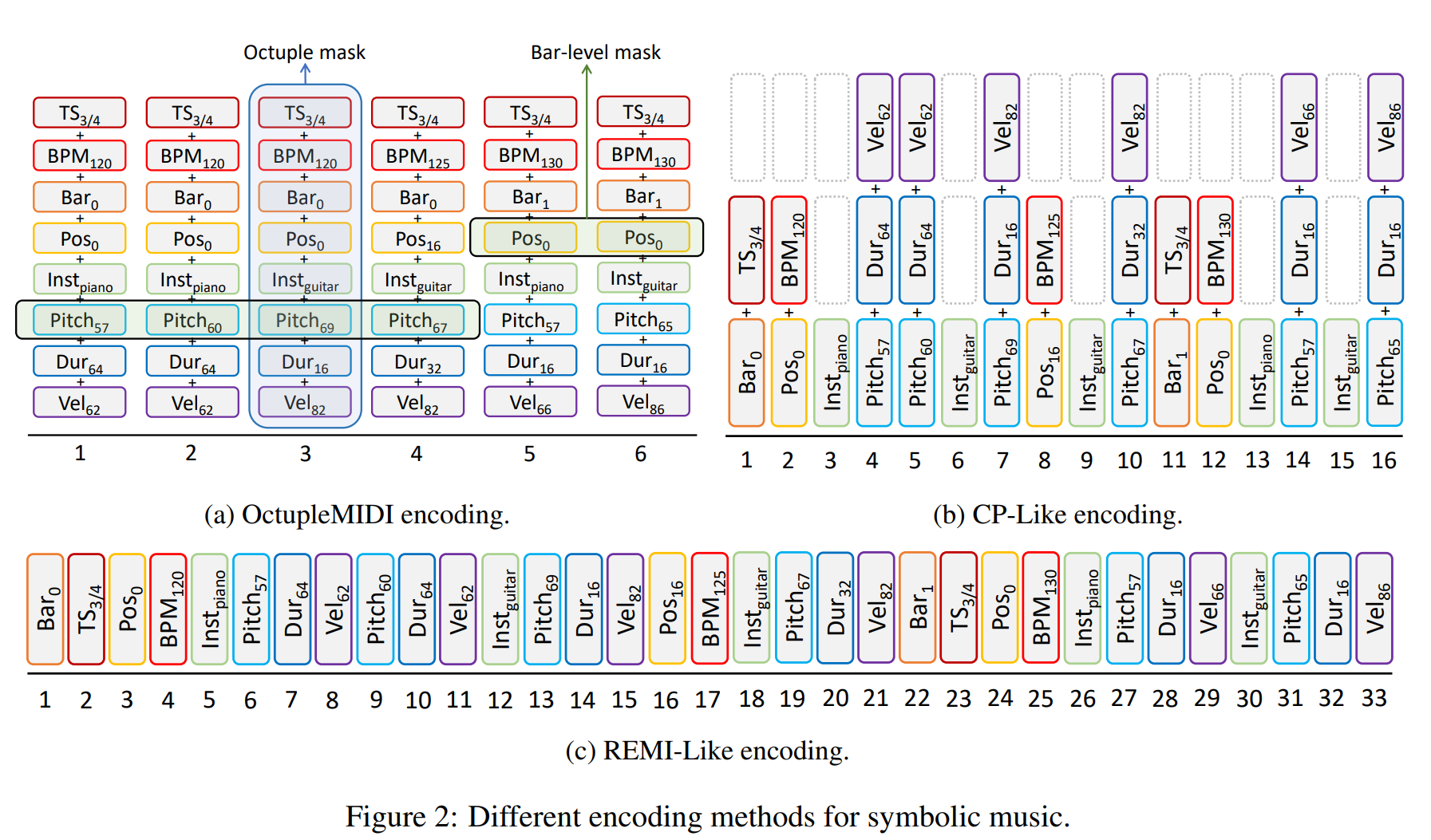
Comparison between encoding schemes
논문 출판전이라 비공개(하지만 과연 accept 이 될 수 있을까??)
Explore Decoding architecture
both on symbolic music and discrete audio tokens
- Parallel
- Catvec
- RNN
- Self attention
- Cross attention
- (Enricher)
Quantitative evaluation algorithm
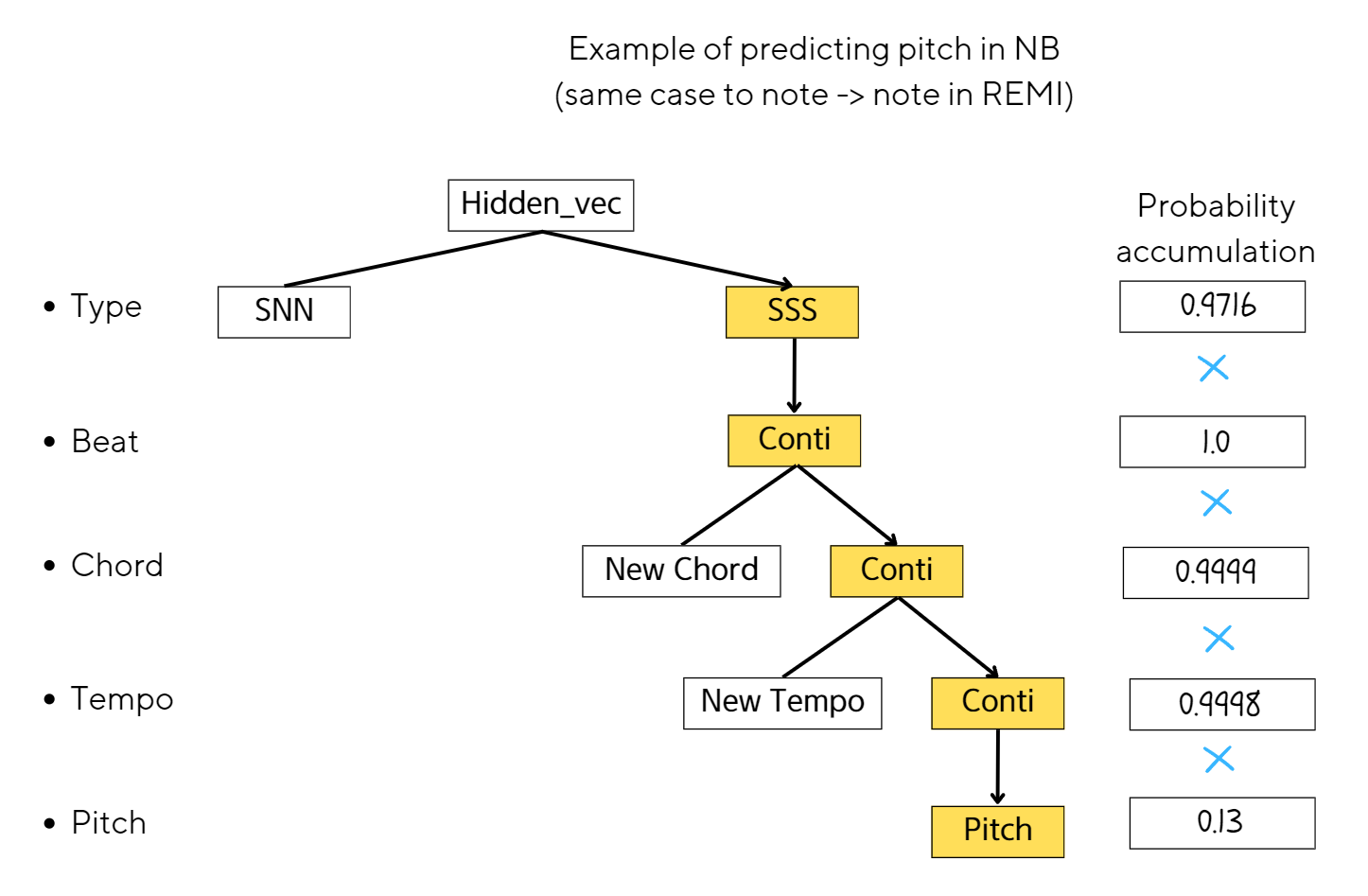
We introduce an evaluation algorithm for calculating perplexity for fair comparision with REMI, CP, and NB.
Relatedworks
OctupleMIDI
from the paper "MusicBERT: Symbolic Music Understanding with Large-Scale Pre-Training", Mingliang Zeng et al. arxiv
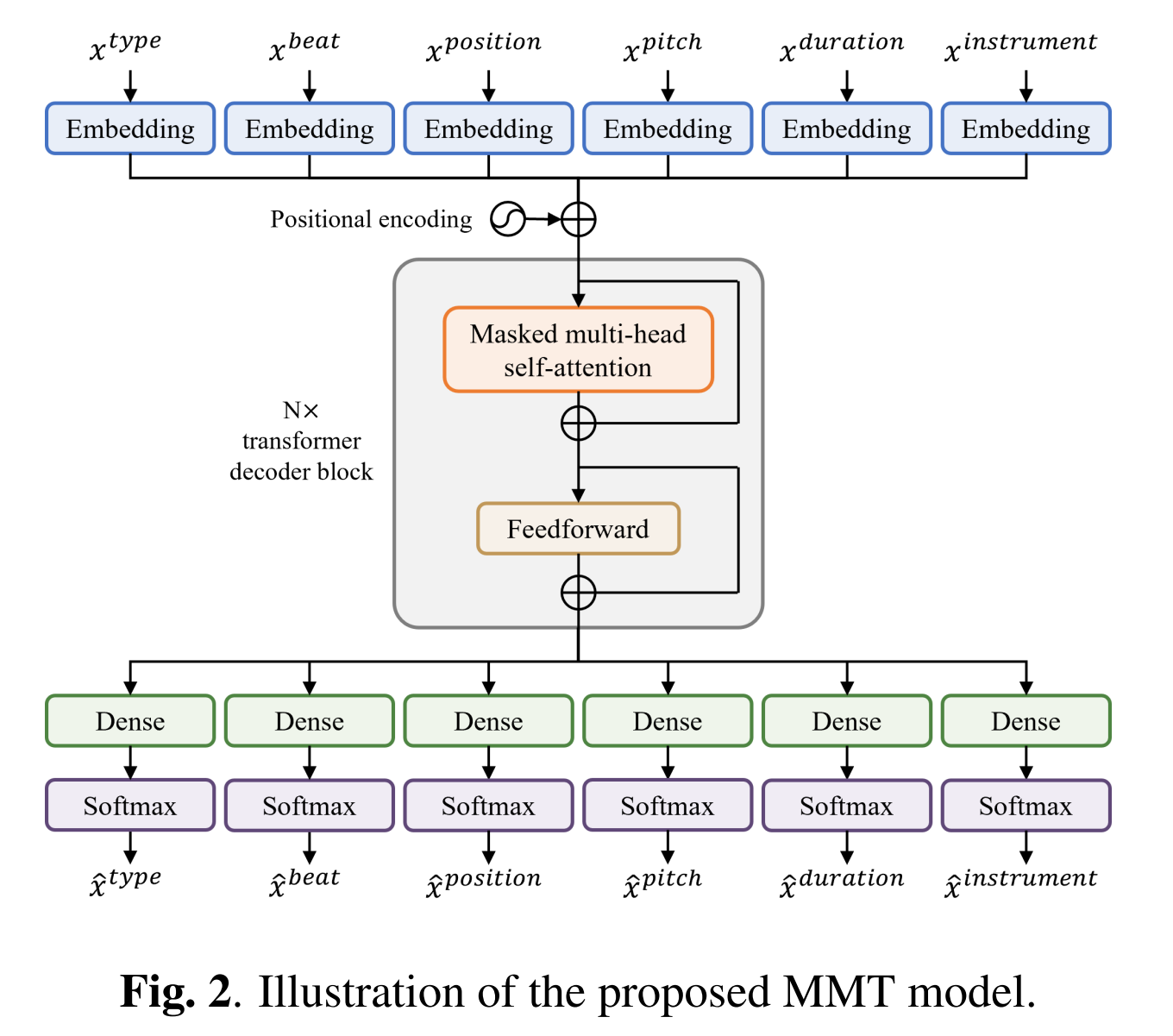
Multitrack music transformer
from the paper "Multitrack Music Transformer", Hao-Wen Dong et al. arxiv
Methodology
Data representation
symbolic encoding process
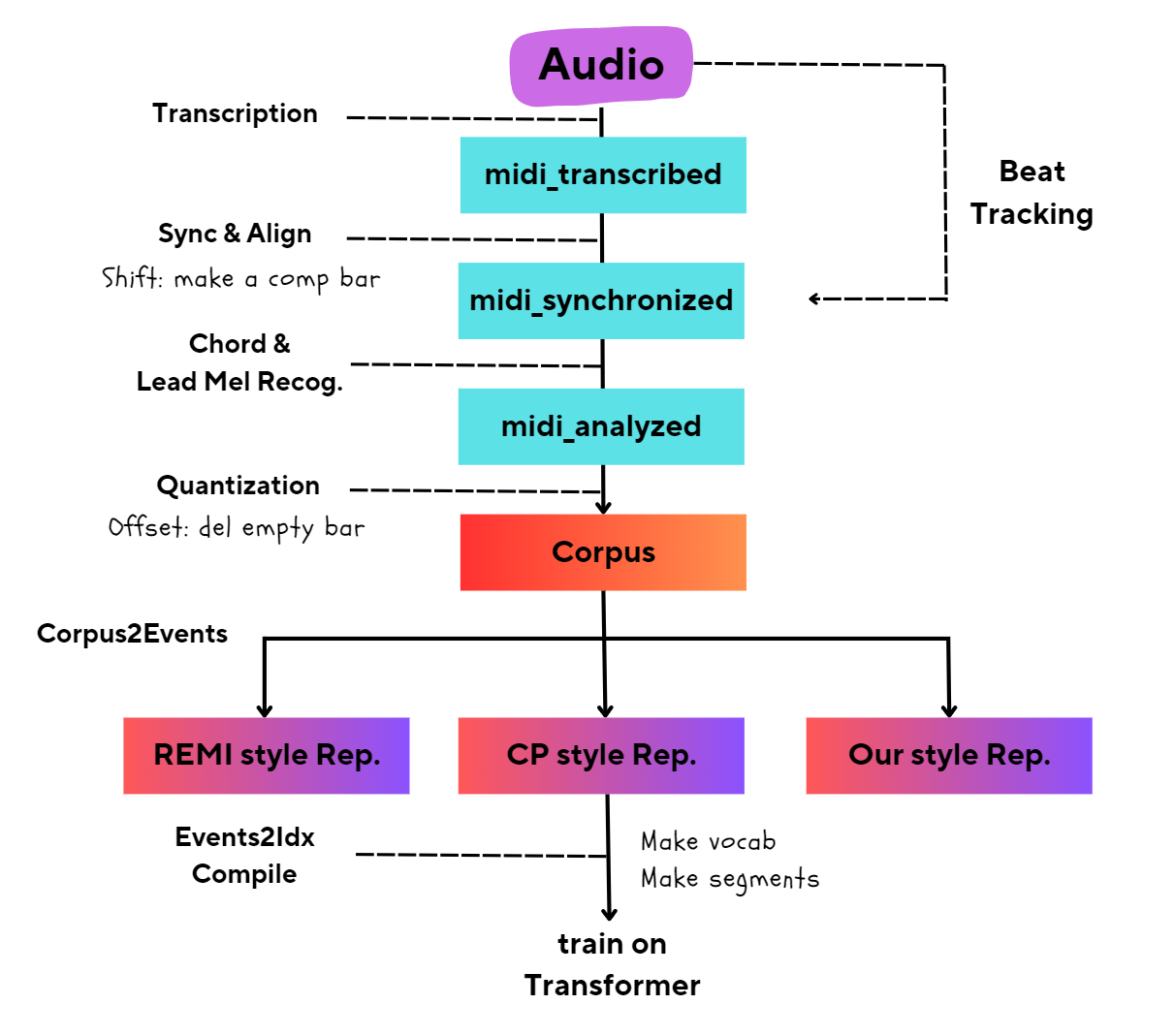
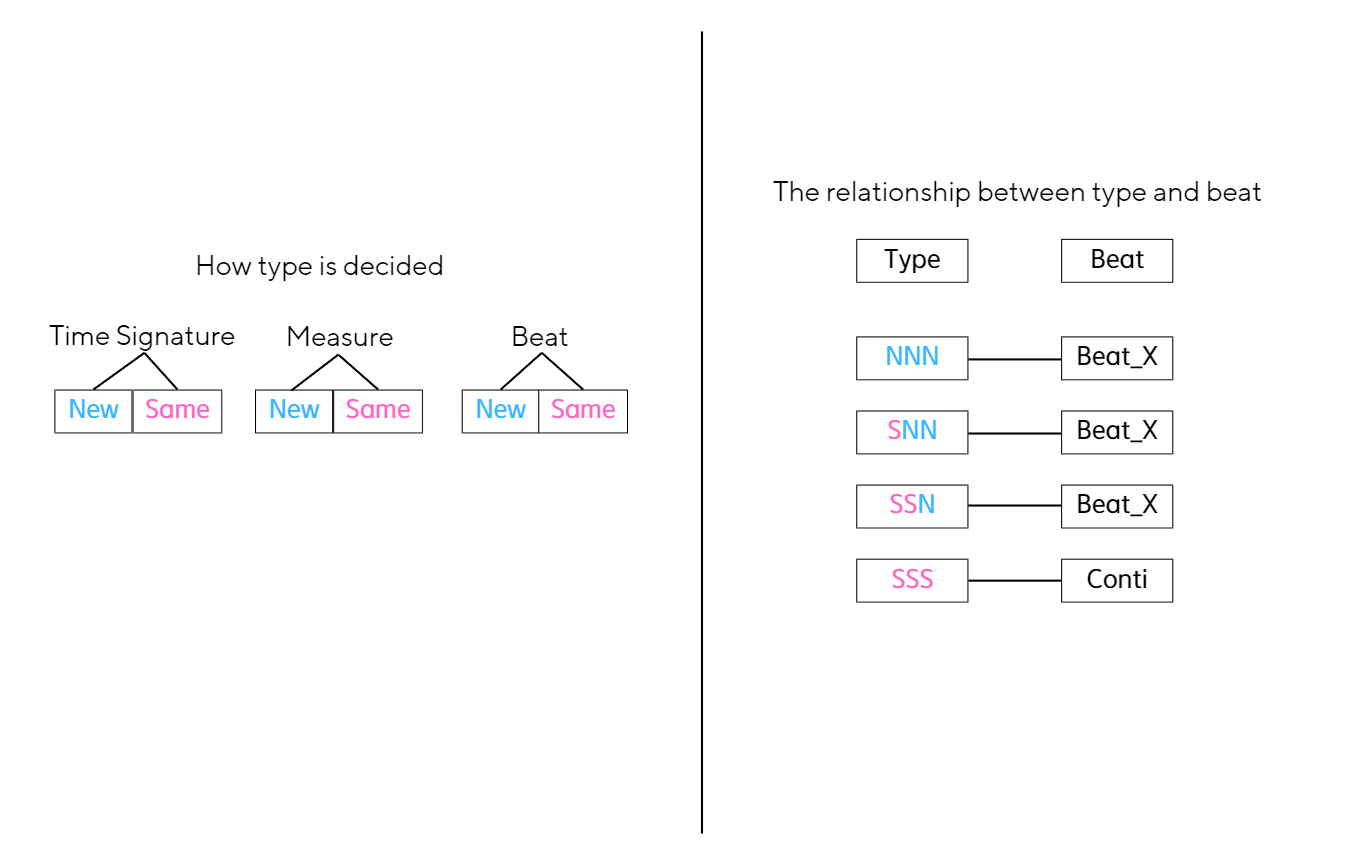
Type = Indicator
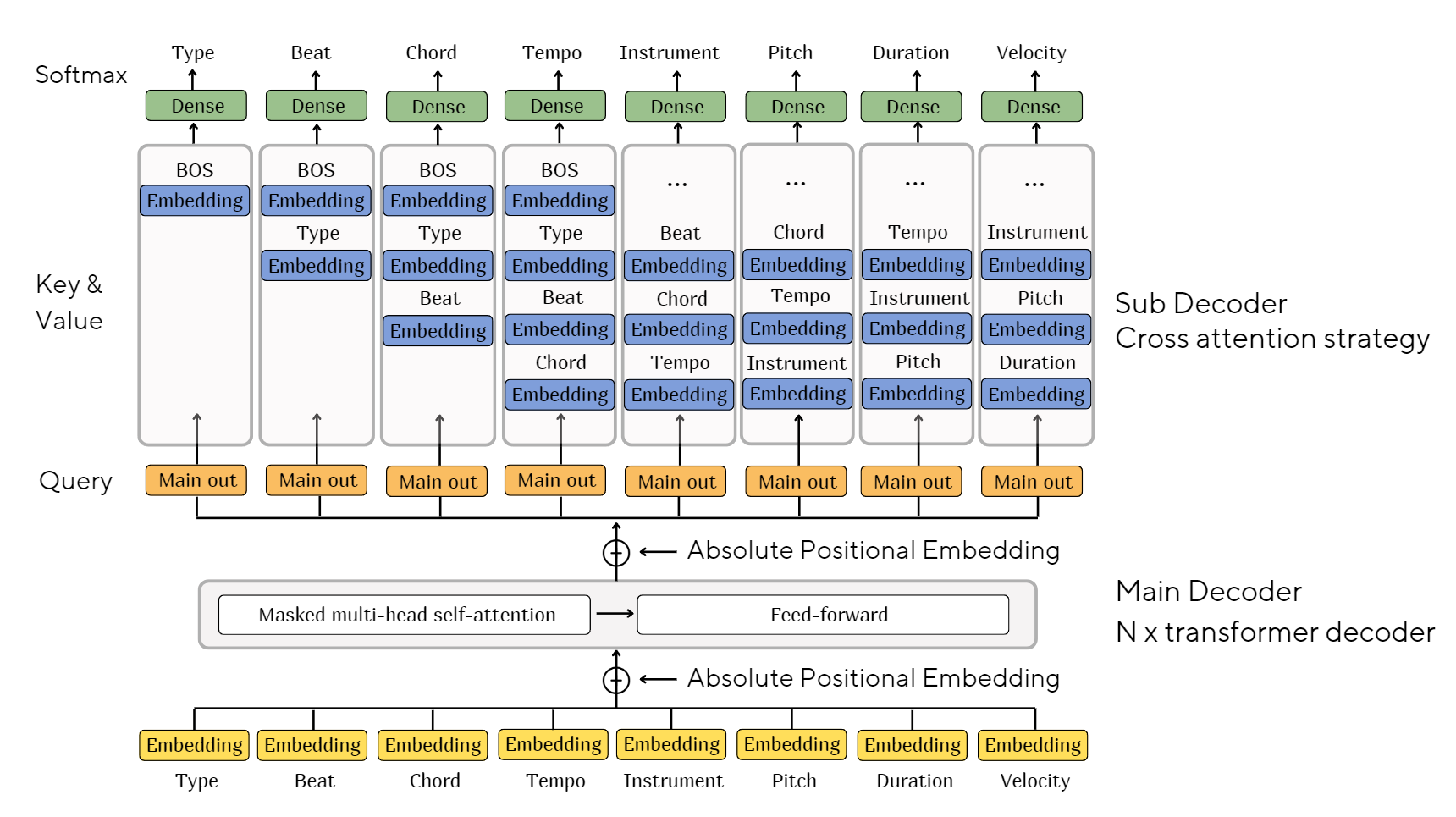
Model architecture
Cross attention strategy
Experiment setup
Model and Hyperparameter Configuration
Our research involved training the Double-Sequential Transformer (DST) model using three distinct encoding schemes: REMI, CP, and NB, across three datasets: Pop1k7, Pop909, and SOD. Each dataset underwent training with ten unique models, incorporating variations in the sub-decoder. To ensure equitable comparison across encoding schemes, we aimed for a uniform parameter count across datasets, targeting approximately 40 million parameters. For enhanced efficiency in processing long sequences, we incorporated Flash attention [Dao et al., 2022]. The training regimen spanned 100,000 steps, leveraging the AdamW optimizer [Loshchilov and Hutter, 2017], with a segment batch size of 8, β1 set at 0.9, β2 at 0.95, and a gradient clipping threshold of 1.0. A cosine learning rate schedule was employed, featuring a 2000-step warmup phase, with the learning rate minimized at the 80,000-step mark. Instead of early stopping, dataset-specific dropout rates were utilized to mitigate overfitting. Training was executed on individual GPUs, each under 24GB of memory capacity, utilizing mixed precision. To curtail recursive generation, top p (nucleus) sampling and temperature adjustments were applied to the logits for each dataset, with optimal settings disclosed in Table X.
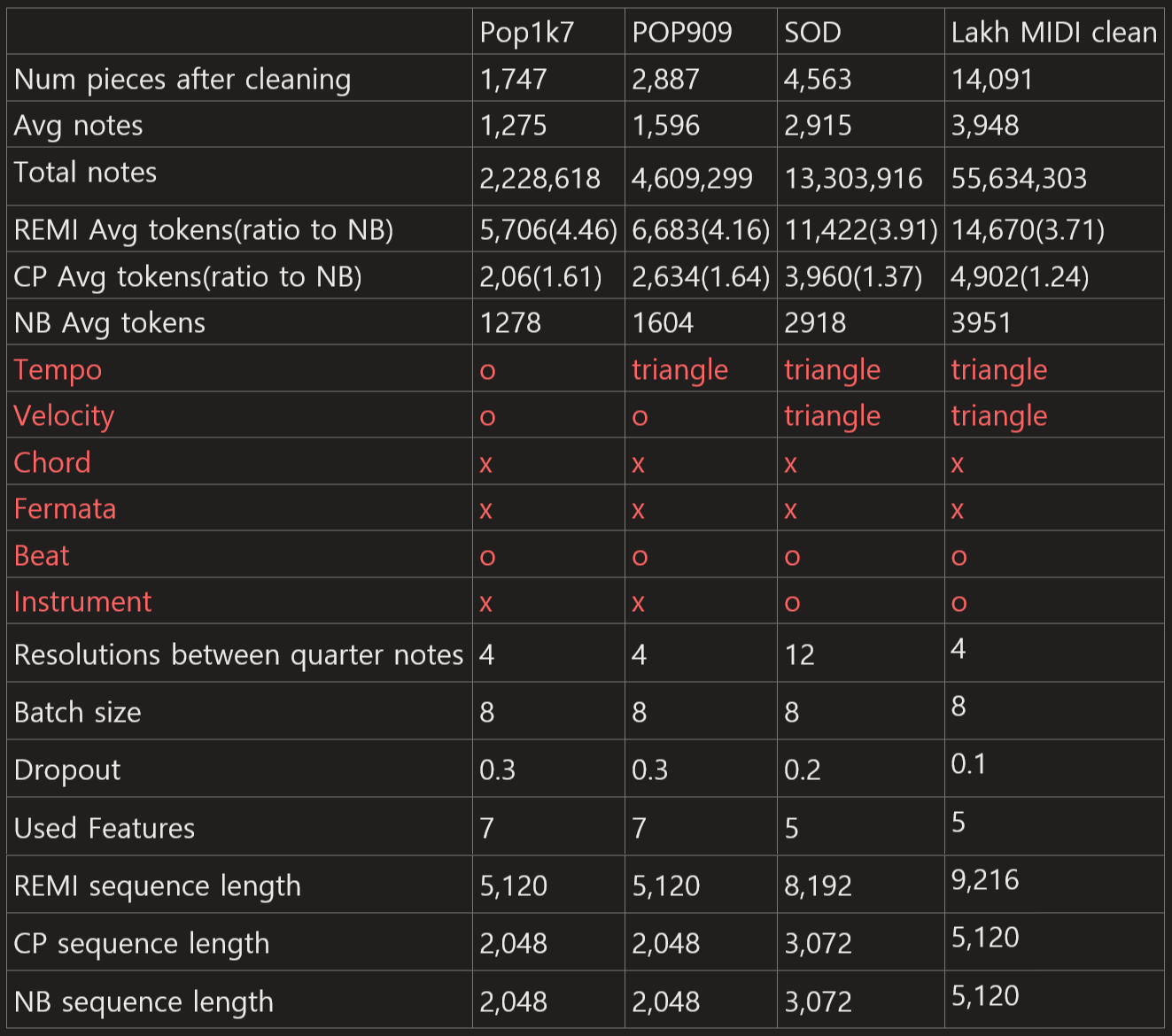
Dataset Specifications
The datasets varied in temporal resolution, specifically between quarter notes, and encompassed diverse feature sets. For expressive MIDI compositions, such as Pop1k7 and Pop909, seven features were analyzed: type, beat, chord, tempo, pitch, duration, and velocity. Conversely, score MIDI datasets, including SOD and LMD Clean, were examined based on five features: type, beat, instrument, pitch, and duration. The LMD full dataset was excluded due to its high incidence of duplicated songs under varying labels, given that perplexity served as a principal evaluative metric. An extensive filtering process was applied to the datasets, with the resultant dataset quantities presented in Table X. Data was partitioned to allocate 10% for validation and 10% for testing purposes. Training involved the dynamic update of the input sequence, through random segmentation of tunes into predetermined lengths, per training epoch. Augmentation techniques for pitch and chord involved random semitone shifts within a range of s ∼ U(−5, 6) (s ∈ Z). Despite a general data split of 90%/10%/10% for training/validation/testing, discrepancies in tune labelling were noted within the LMD dataset, indicating potential data leakage despite verification efforts.
Quantitative Assessment
Listening Test
is on process
Results
Perplexity tables for all the models with three encoding schemes.
논문 출판 전이라 비공개(어떻게든 되겠지...)
Shortcomings
Degeneration
applying propler sampling method is required
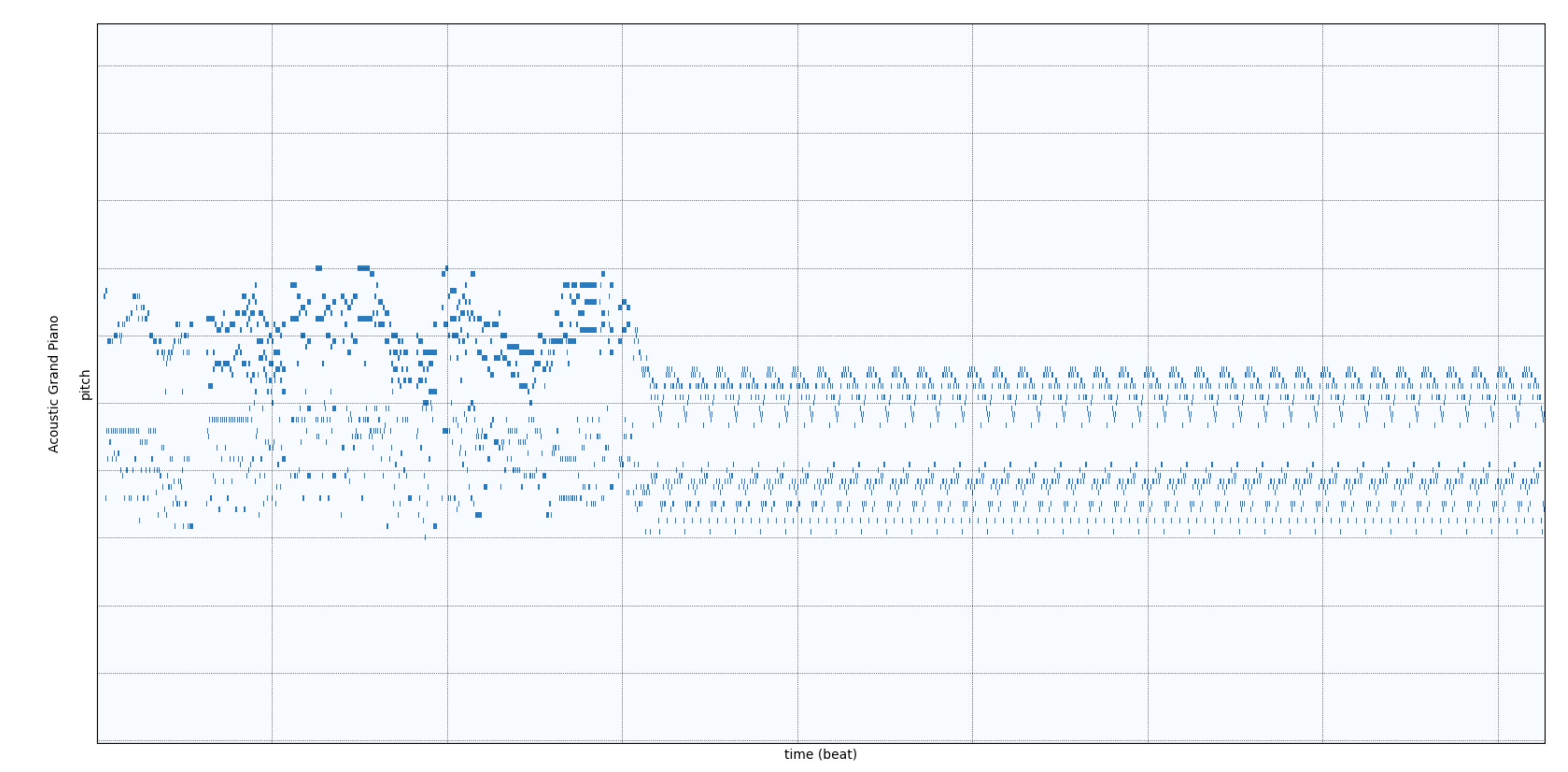
Result is unstable
direction for the paper can't be decided yet
