Transformer
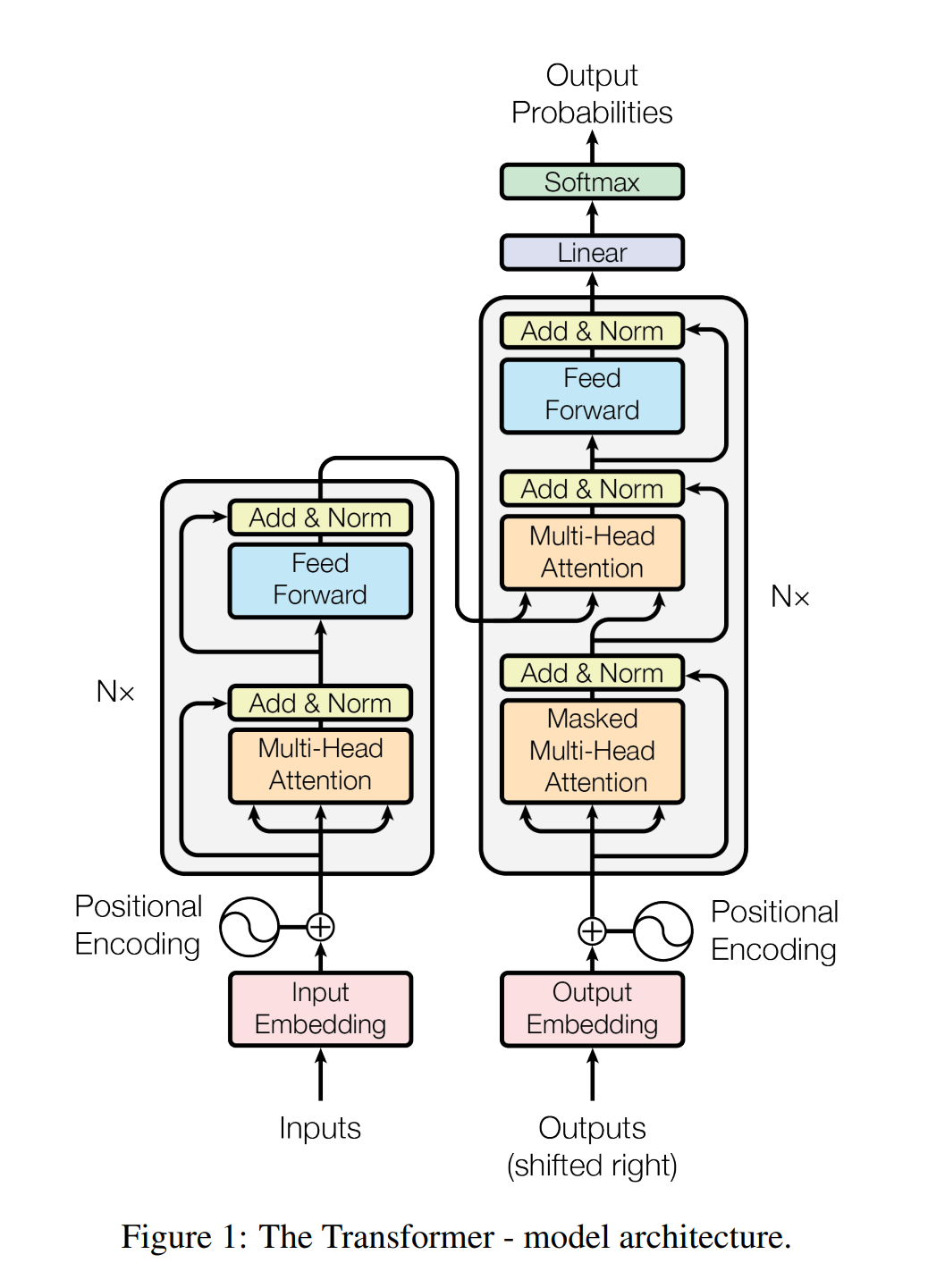
transformer class
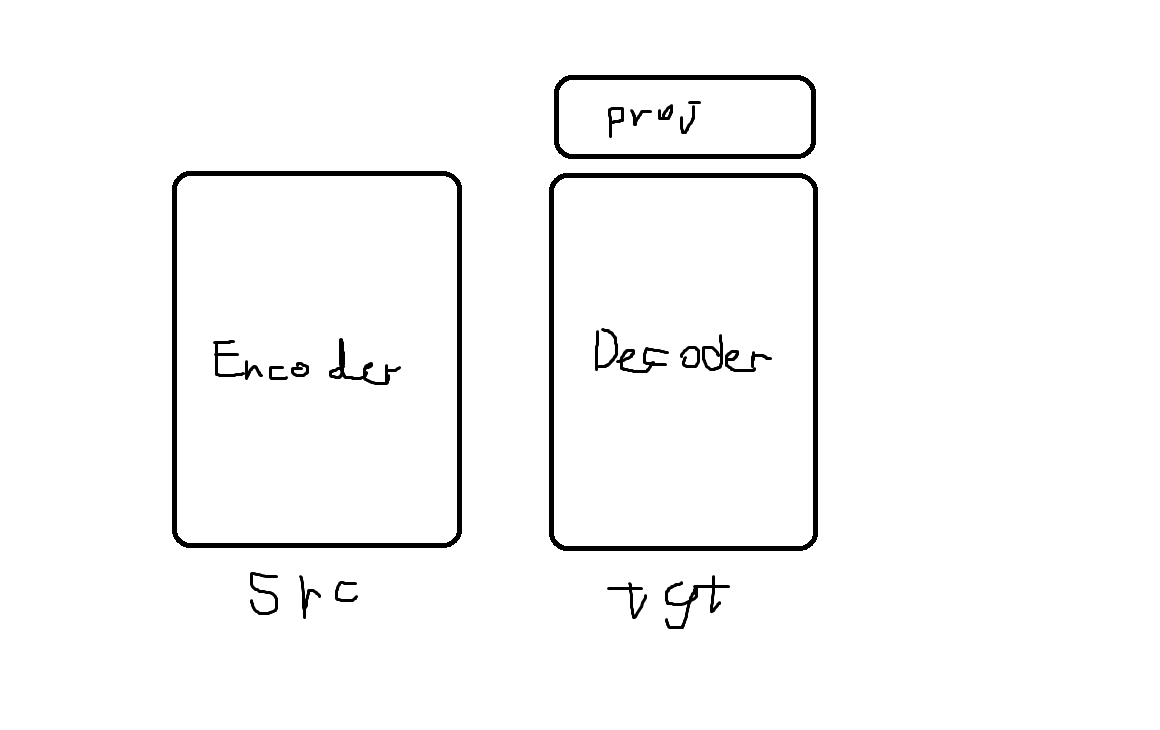
this class consists of encoder and decoder and projection layer which is added at the end of the decoder
class TransformerTranslator(nn.Module):
def __init__(self, in_size, emb_size, mlp_size, num_head, num_enc_layers, num_dec_layers, enc_vocab_size, dec_vocab_size):
super().__init__()
self.encoder = Encoder(in_size, emb_size, mlp_size, num_head, num_enc_layers, enc_vocab_size)
self.decoder = Decoder(in_size, emb_size, mlp_size, num_head, num_dec_layers, dec_vocab_size)
self.final_proj = nn.Linear(emb_size, dec_vocab_size)
def forward(self, src:torch.Tensor, tgt_i:torch.Tensor):
enc_out = self.encoder(src)
dec_out = self.decoder(tgt_i, enc_out)
return self.final_proj(dec_out['input']).softmax(dim=-1)Encoder class

this class consists of EncoderLayer and encoding parts which
1. make embeddings combined with positional encoding values and embeddings of each tokens
2. It prepares input dict. In encoder there are only src and mask. However, in decoder, tgt and tgt mask are added to the dict.
class Encoder(nn.Module):
def __init__(self, in_size, emb_size, mlp_size, num_head, num_layers, vocab_size):
super().__init__()
self.layers = nn.Sequential()
for i in range(num_layers):
self.layers.append(EncoderLayer(in_size,emb_size,mlp_size,num_head))
self.pos_enc = PosEncoding(emb_size, 10000)
self.token_emb = nn.Embedding(vocab_size, emb_size)
def forward(self, src):
mask = torch.ones([src.shape[0], src.shape[1], src.shape[1]])
mask[src==0] = 0
temp = torch.ones_like(src) # [N, T]
result = torch.arange(src.shape[-1]).to(src.device) * temp # [N, T]
src_pos = self.token_emb(src) + self.pos_enc(result) # [N, T, C]
return self.layers({'input':src_pos, 'mask':mask})class Decoder(nn.Module):
def __init__(self, in_size, emb_size, mlp_size, num_head, num_layers, vocab_size):
super().__init__()
self.layers = nn.Sequential()
for i in range(num_layers):
self.layers.append(DecoderLayer(in_size,emb_size,mlp_size,num_head))
self.pos_enc = PosEncoding(emb_size, 10000)
self.token_emb = nn.Embedding(vocab_size, emb_size)
def forward(self, tgt_i, enc_out):
mask = torch.triu(torch.ones(tgt_i.shape[0], tgt_i.shape[1], tgt_i.shape[1]))
cross_attention_mask = torch.ones(tgt_i.shape[0], enc_out['input'].shape[1], tgt_i.shape[1]) # N, Tk, Tq
# enc_out['mask'][:,:, 0]==0 shape is [N, Tk]
cross_attention_mask[enc_out['mask'][:,:, 0]==0] = 0 # so all values in the rows indexed by enc_out['mask'][:,:, 0]==0 are 0
temp = torch.ones_like(tgt_i)
result = torch.arange(tgt_i.shape[-1]).to(tgt_i.device) * temp
tgt_pos = self.token_emb(tgt_i) + self.pos_enc(result)
return self.layers({'input':tgt_pos, 'decoder_mask':mask, 'encoder_out':enc_out['input'], 'encoder_mask':cross_attention_mask})Encoder layer
class EncoderLayer(nn.Module):
def __init__(self, in_size, emb_size, mlp_size, num_head):
super().__init__()
self.att_block = ResidualLayerNormModule(SelfAttention(in_size, emb_size, num_head))
self.mlp_block = ResidualLayerNormModule(MLP(emb_size, mlp_size))
def forward(self, x):
out = self.mlp_block(self.att_block(x['input'], x['mask']))
return {'input':out, 'mask':x['mask']}Positional Encoding
I guess this figure is wrong because it lacks 0 position of sequences but it shows the other parts well
from https://tigris-data-science.tistory.com/m/entry/%EC%B0%A8%EA%B7%BC%EC%B0%A8%EA%B7%BC-%EC%9D%B4%ED%95%B4%ED%95%98%EB%8A%94-Transformer5-Positional-Encoding

values from matrix with total 50 length of sequence and 128 size of emb_size
from https://kazemnejad.com/blog/transformer_architecture_positional_encoding/

so with this calculating "timesteps.unsqueeze(1) / dim_axis.unsqueeze(0)" we can get a matrix size of timesteps(10000) x emb_size(512).
class PosEncoding(nn.Module):
def __init__(self, emb_size, max_t):
super().__init__()
self.emb_size =emb_size
self.max_t = max_t
self.register_buffer('encoding', self._prepare_emb())
def _prepare_emb(self):
dim_axis = 10000**(torch.arange(self.emb_size//2) * 2 / self.emb_size) # 10000 ** (normalized values between 0~1 num_emb_dim)
timesteps = torch.arange(self.max_t)
pos_enc_in = timesteps.unsqueeze(1) / dim_axis.unsqueeze(0)
pos_enc_sin = torch.sin(pos_enc_in) # x values for sin are between 0 ~ 1 so the values could never be the same
pos_enc_cos = torch.cos(pos_enc_in)
pos_enc = torch.stack([pos_enc_sin, pos_enc_cos], dim=-1).reshape([self.max_t, 512])
return pos_enc
def forward(self, x):
return self.encoding[x]how mixed up embeddings(context + position) work
Since the positional encodings are generated by sine and cosine functions with different frequencies, the model can learn to recognize certain patterns that emerge from their combination with token embeddings. These patterns help establish the relationships between different positions and learn to identify individual positions in the sequence. So, even though the positional information appears "mixed up" with the token embeddings, the attention mechanism can still learn to use this combined information effectively. The Transformer doesn't need to explicitly separate positional encoding from the token embeddings to recognize the positional information. Instead, it learns how to use this compound embedding in the context of similarity and attention weights computation by analyzing the relationships between sequences during training.
Mask for self-attention & cross-attention
def forward(self, tgt_i, enc_out):
mask = torch.triu(torch.ones(tgt_i.shape[0], tgt_i.shape[1], tgt_i.shape[1]))
cross_attention_mask = torch.ones(tgt_i.shape[0], enc_out['input'].shape[1], tgt_i.shape[1]) # N, Tk, Tq
# enc_out['mask'][:,:, 0]==0 shape is [N, Tk]
cross_attention_mask[enc_out['mask'][:,:, 0]==0] = 0 # so all values in the rows indexed by enc_out['mask'][:,:, 0]==0 are 0 The masking used in the cross-attention mechanism is different from the masking used in self-attention,
- where the primary goal is to prevent the model from attending to future tokens. (causalitiy mask)
In cross-attention, we're not concerned about the future tokens, as we have access to the complete source sentence at once. The purpose of masking in cross-attention is
- to ensure that the "padding" tokens in the source sentence do not contribute to the attention scores when calculating attention weights, and also it is used in calculating loss values. (padding mask)
