Spectrogram에 관한 퀴즈
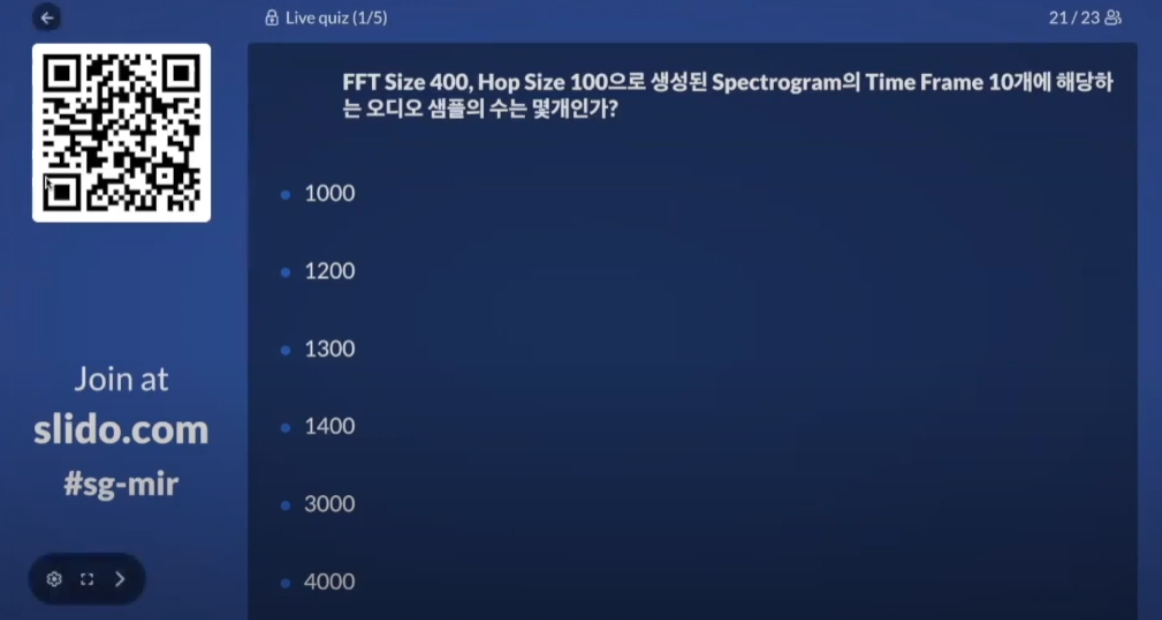
답 : 1300, CNN에서 필터가 들어가는 것과 같은 구조이다. FFT size - Hop size를 한 마진이 몇개가 들어가는지를 생각해보면 된다.
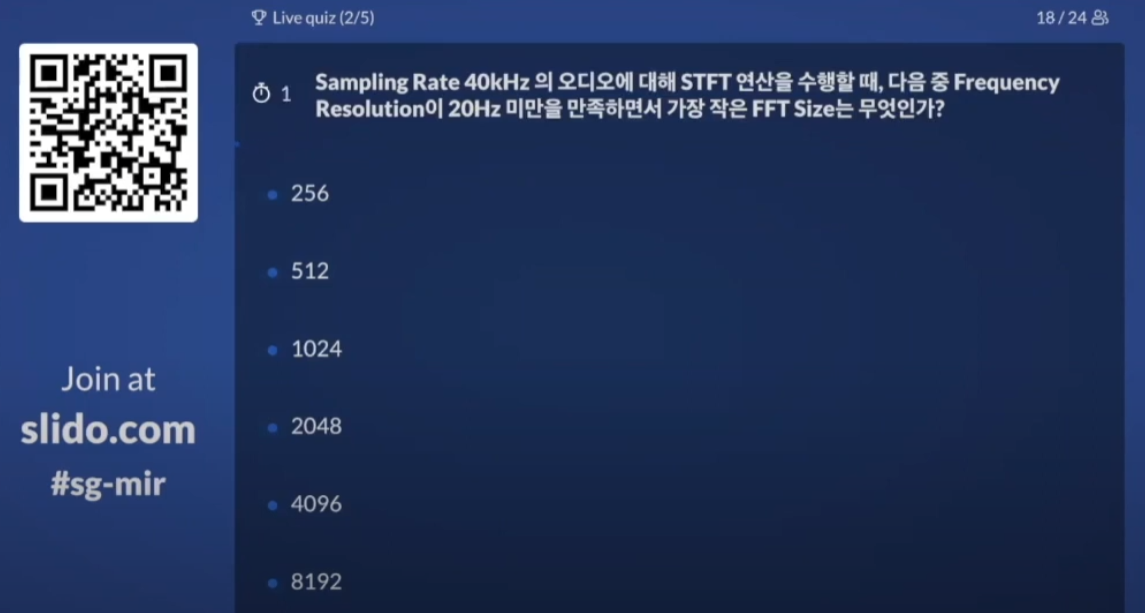
답 : 2048, SR을 FFT size로 나눈 값이 frequency resolution이 된다. 하지만 외울 필요 없이 조금만 생각해보면 1초를 40000만번으로 샘플링한 데이터에 대해서 1초에 20번 진동하는, 즉 한번의 진동에 1/20초가 필요한 파동이 잡히려면 최소 2000보다는 큰 윈도우 크기가 필요하다.
Dataset Preparation
!pip install torchaudio
import torch
import torch.nn as nn
import torchaudio
import IPython.display as ipd
import matplotlib.pyplot as plt
SR = 16000
eps = 1e-6 # epsilon, Log(0)를 막기위해 사용되는 수. torch.log(x+eps)
DEV = 'cpu' # device
torch.set_printoptions(sci_mode=False) # 소수점 출력을 제한Download Dataset
교수님이 쓰신 링크가 작동을 하질 않아서 기존에 내가 만들어둔 데이터셋을 사용했다.
!git clone https://github.com/clayryu/GTZAN-Dataset---Music-Genre-Classification.git
%cd GTZAN-Dataset---Music-Genre-Classification
%cd GTZAN_Dataset_Music_Genre_Classification
%cd DataDownsample and Save in PyTorch file
Pathlib 사용법
from pathlib import Path
dir_path = Path('genres_original/')
dir_path # PosixPath('genres_original') 객체로 나온다.
file_path = dir_path / 'blues' / 'blues.00100.wav' # 추가는 간단하다.
kpop_path = dir_path / 'kpop'
kpop_path.mkdir() # 새로 만드는 것도 간단하다.
kpop_path.exists()rglob을 활용한 generator 만들기
wav_paths = dir_path.rglob('*.wav')
wav_paths # <generator object Path.rglob at 0x7f314e0f66d0>
wav_paths_list = list(wav_paths)
for wav in wav_paths_list:
print(f'List: {wav}')
# 한번 반환하고 나면 더이상 작동하지 않는다.
# 그래서 위에서 list로 반환하고 나면 더이상 작동하질 않는다.
for wav in wav_paths:
print(f'Generator: {wav}')다운 샘플링
프로세스는 만들어둔 객체들의 리스트인 wav_paths_list에서 하나하나 뽑아서 down sampling을 하는 for loop을 만드는 것이다.
다운 샘플링은 torchaudio의 resample을 사용하는데 이는 오디오 데이터를 인풋으로 받지 않고 이미 샘플링이 된 tensor 데이터를 받아서 바꾸어 준다.
torchaudio.load에서 바로 샘플링 레이트를 조정할 수 있다면 좋을텐데 그런 기능은 없다고 한다.
wav_path = wav_paths_list[0]
audio_sample_tensor, sample_rate = torchaudio.load(wav_path)
print(audio_sample_tensor.shape, sample_rate)
# Mono, samples, sample rate
# torch.Size([1, 661794]) 22050
resampler = torchaudio.transforms.Resample(orig_freq=sample_rate, new_freq=SR)
downsampled_audio_tensor = resampler(audio_sample_tensor)저장하기
불행히도 파일 중 하나가 깨져있어서 pass루트를 만들어주었다.
print(wav_path.stem) # jazz.00048
print(wav_path.parent) # genres_original/jazz
print(wav_path.name) # jazz.00048.wav# 만약 모든 데이터의 sample rate가 22050인걸 모른다면 for loop을 돌릴때마다 class를 정의해주어야 한다.
resampler = torchaudio.transforms.Resample(orig_freq=22050, new_freq=SR)
for wav in wav_paths_list:
if wav.stem == 'jazz.00054':
pass
else:
audio_tensor, orig_sample_rate = torchaudio.load(wav)
#resampler = torchaudio.transforms.Resample(orig_freq=sample_rate, new_freq=SR)
downsampled_audio = resampler(audio_tensor)
# 채널 정보 삭제는 reshape를 해주거나 squeeze를 해주거나
#downsampled_audio = downsampled_audio.view(-1)
downsampled_audio = downsampled_audio.squeeze()
new_path = wav.parent / (wav.stem + '_downsampled.pt')
torch.save(downsampled_audio, new_path)Define Dataset and Dataloader
class AudioSet:
def __init__(self, dataset_dir, SR):
if not isinstance(dataset_dir, Path):
dataset_dir = Path(dataset_dir)
self.load_dataset(dataset_dir)
self.sr = SR
def load_dataset(self, dataset_dir):
pt_paths = dataset_dir.rglob('*.pt')
# generator는 1회용이라 list로 만들어준다.
pt_paths = list(pt_paths)
self.audios = [ torch.load(pt_fn) for pt_fn in pt_paths ]
self.labels = [ pt_fn.stem.split('.')[0] for pt_fn in pt_paths ]
self.label_names = set(self.labels)
self.name_to_idx = { label : idx for idx, label in enumerate(self.label_names) }
'''
for pt_fn in pt_paths:
loaded_sample = torch.load(pt_fn)
audios.append(loaded_sample)
'''
def __getitem__(self, idx):
# torch.stack은 같은 길이의 토치만을 합칠 수 있다.
# 따라서 audio의 길이를 맞춰주어야 dataloader를 이용할때 편하다.
# 30초짜리 음원이지만 3초로 모두 자른다.
audio = self.audios[idx][:self.sr * 3]
label = self.name_to_idx[self.labels[idx]]
return audio, label
def __len__(self):
return len(self.audios)audioset = AudioSet('genres_original/', SR=16000)
print(audioset.name_to_idx)
# {'blues': 0, 'disco': 1, 'reggae': 2, 'classical': 3, 'hiphop': 4, 'pop': 5, 'country': 6, 'metal': 7, 'rock': 8, 'jazz': 9}Define a collate functions that makes batch to Tensor
# torch.stack은 같은 길이의 토치만을 합칠 수 있다.
# 따라서 받은 tensor의 길이를 지정해주거나
# 애초에 넘길 데이터의 길이를 조정해주어야 한다.
def collate_func(batch):
audio = torch.stack([x[0][:478000] for x in batch])
label = torch.LongTensor([x[1] for x in batch])
return audio, label
dataloader = DataLoader(dataset=audioset, batch_size=64, shuffle=True, collate_fn=collate_func)
for batch in dataloader:
pass
batch[0][0].shape # torch.Size([478000])Define Neural Network
# NN안에 스펙트로그램을 넣을 것인가
# 전처리로 스펙트로그램까지 해줄것인가
# 모델이 최적의 성능을 내는 스펙트로그램 세팅을 기억하기 위해 모델에 넣어본다
class GenreClassifier(nn.Module):
def __init__(self, sr):
super().__init__()
self.spec_converter = torchaudio.transforms.MelSpectrogram(sample_rate=sr, n_fft=8192, n_mels=48)
self.db_converter = torchaudio.transforms.AmplitudeToDB()
self.layer0 = nn.Linear(in_features=48, out_features=36)
self.layer1 = nn.Linear(in_features=36, out_features=32)
self.layer2 = nn.Linear(in_features=32, out_features=10)
def forward(self, audio_input):
spec = self.spec_converter(audio_input)
db_spec = self.db_converter(spec) # batch_size x n_mels x num_time_frame
out = self.layer0(db_spec.transpose(-1,-2)) # layer0의 입력차원이 입력텐서의 가장 마지막에 위치해야함
out = torch.relu(out)
out = self.layer1(out)
out = torch.relu(out)
out_all = self.layer2(out) # batch_size x num_time_frame x num_class==10
#print(out_all.shape)
out = torch.max(out_all, dim=1)[0] # 하나의 데이터당 하나의 값을 뽑아서 사용
#print(torch.max(out_all, dim=1))
#print(out.shape)
return torch.softmax(out, dim=-1)Make a train loop
model = GenreClassifier(sr=SR)
optimizer = torch.optim.Adam(model.parameters())
loss_function = torch.nn.NLLLoss()
num_epochs = 10
loss_record = []
for epoch in range(num_epochs):
for batch in dataloader:
optimizer.zero_grad()
audio, label = batch
pred = model(audio)
loss = loss_function(torch.log(pred+eps), label)
loss.backward()
optimizer.step()
loss_record.append(loss.item())
plt.plot(loss_record)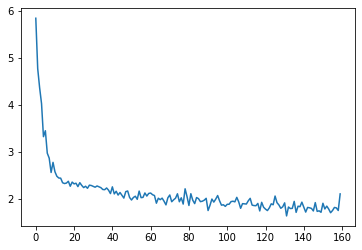
# 모델이 업데이트 된 횟수
# 데이터셋이 1000개이고 배치가 64이므로
# 한 에폭당 1000 // 64 + 1번 업데이트
len(loss_record) # 160
chords & code // harmony with structure