Spectrogram
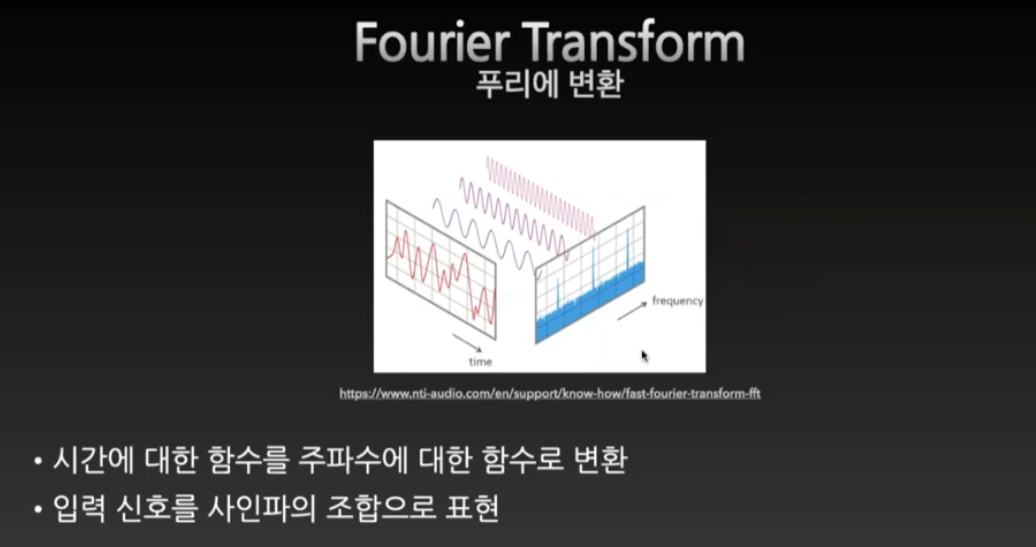
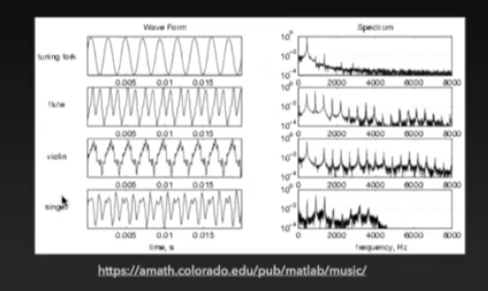

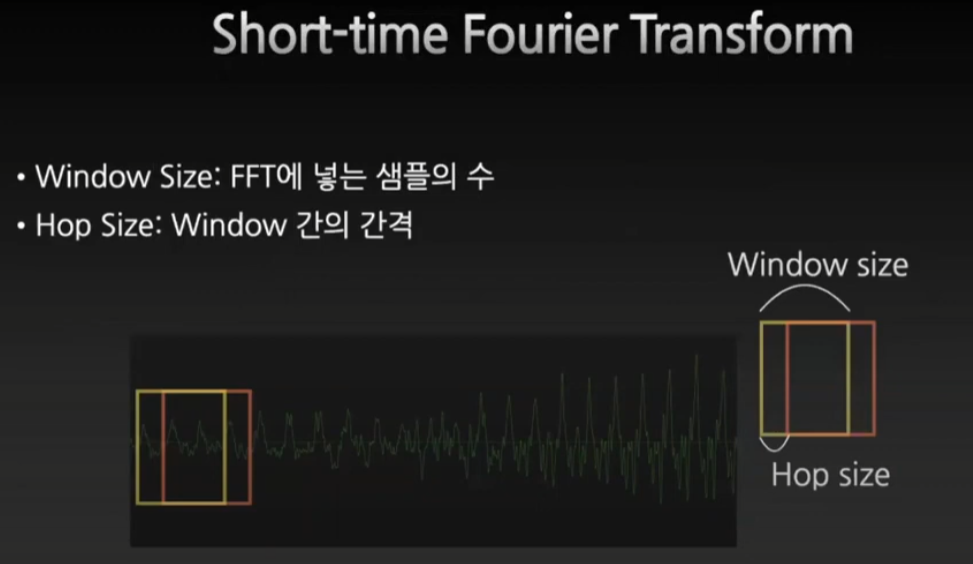
Short-time Fourier Transform

hann window
이 윈도우를 사용해서 샘플을 잘라준다!
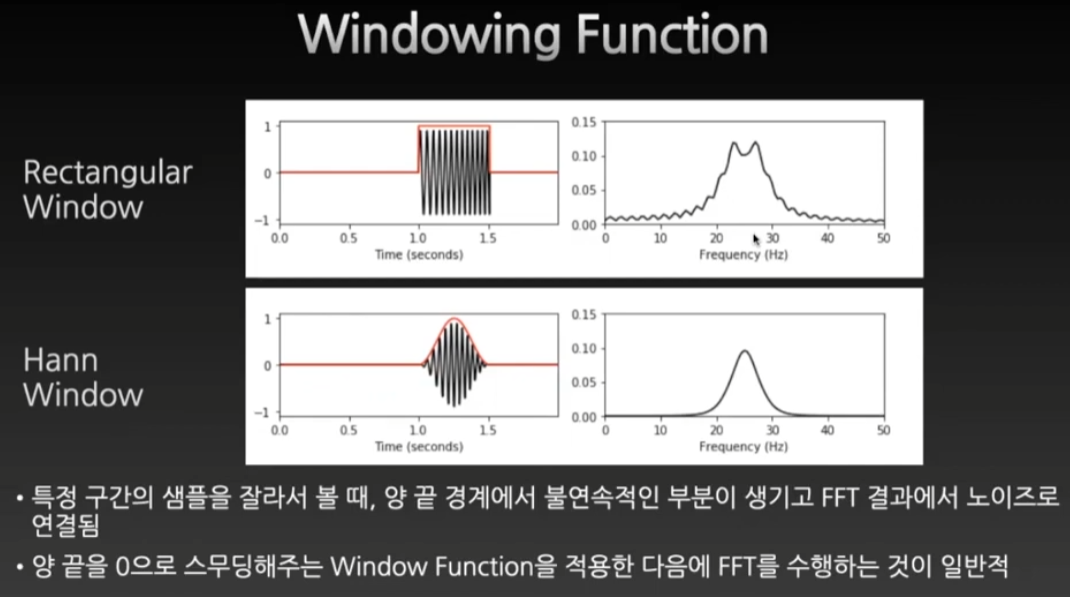
트레이드오프
20Hz의 경우에 44.1kHz는 1/20을 곱한 약 2000개의 샘플을 봐야한다. 그래서 만약에 윈도우를 늘리면 frquency는 더 잘 잡히나 더 많은 시간을 잡아먹기 때문에 시간의 해상도에서 손해를 보게 된다.

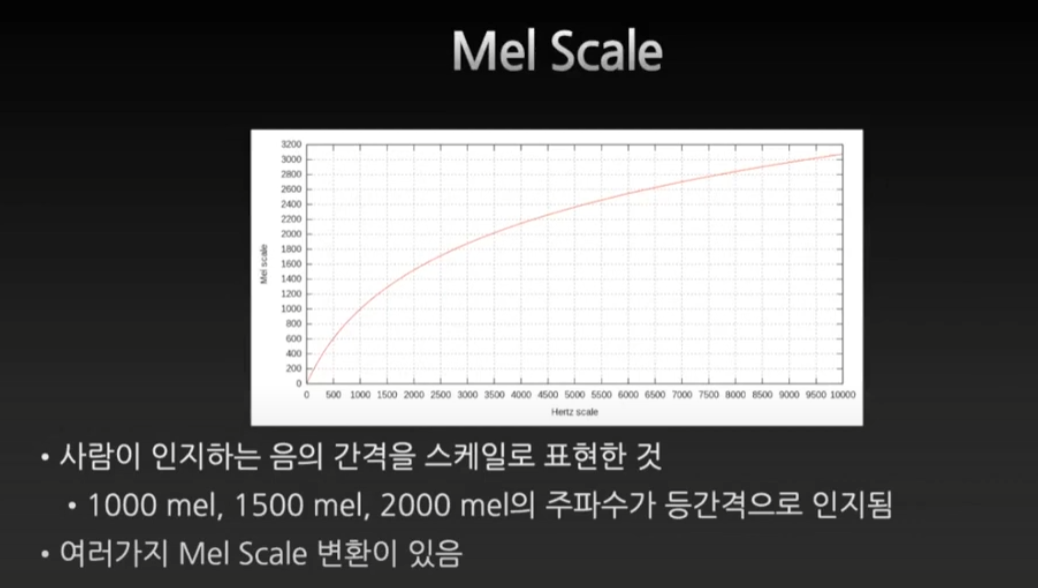
Mel Scale
사람의 귀도 완벽한 log적인 간격이 아니어서 mel이 등장한다.
mel scale 코드 구현
spectrogram과 다르게 mel frequency는 sample rate가 꼭 필요하다.
n_stft는 frequency bin의 개수를 mel_bin에 맞추는 파라미터
mel_scale은 깊이를 log적으로 바꾸어준다.
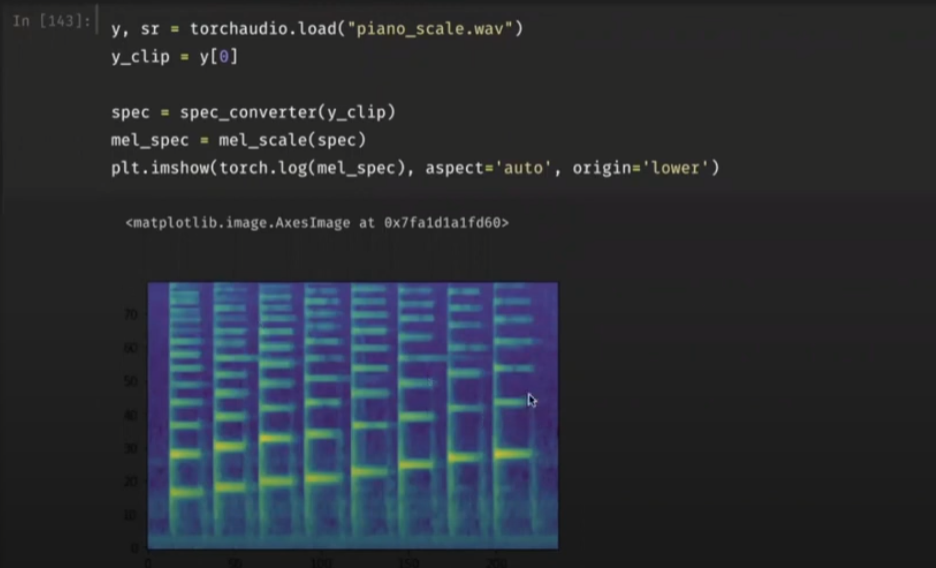
y, sr = torchaudio.load('piano_scale.wav')
y_clip = y[0]
spec_converter = torchaudio.transforms.Spectrogram(n_fft = 2048)
spec = spec_converter(yclip)
mel_scale = torchaudio.transforms.MelScale(n_mels=80, sample_rate=44100, f_min=20, f_max=8000,
n_stft = spec.shape[0]
plt.imshow(mel_scale.fb, aspect='auto', origin='lower')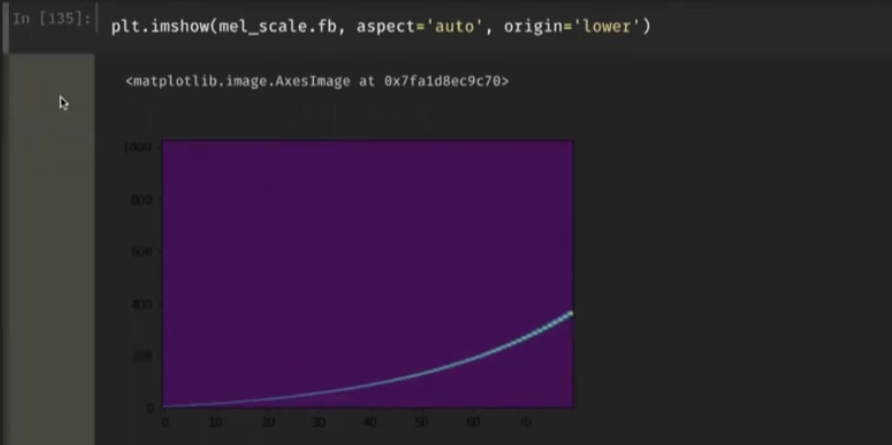
mel_spec = mel_scale(scale)
plt.imshow(torch.log(mel_spec), origin='lower', aspect='auto')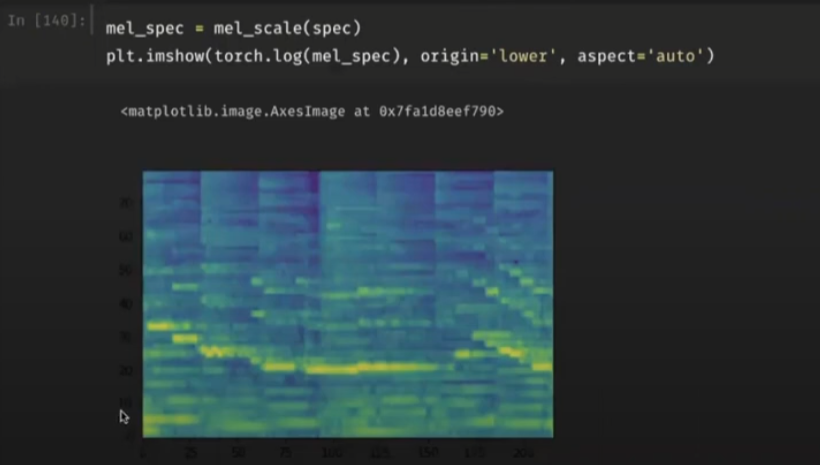
plt.imshow(torch.log(spec), aspect='auto', origin='lower'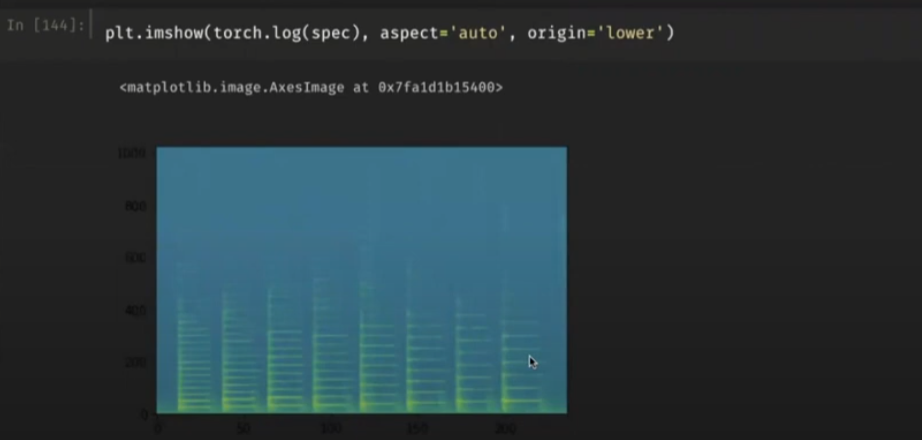
n_fft, hop_length
MelSpectrogram은 n_mels라는 파라미터를 받아서 frequency를 n_mels으로 고정해준다. spectrogram + mel_scale인 셈이다. 따라서 이 spectrogram을 인풋으로 받으면 배치사이즈를 제외한 파라미터가 n_mels * 체크 하고 싶은 만큼의 사이즈가 된다. 이 사이즈는 아래와 같이 계산된다.
nn.Linear(40 * size, output_size)
torch.transforms.MelSpectrogram(sample_rate=SR, n_fft=512, n_mels=40, f_max=6000)
# hop_size = n_fft // 2
num_total_samples = n_fft + (size - 1) * hop_size
in_second = num_total_samples / 16000
in_second # 0.176Make audio Dataset
sine wave를 만들어주는 함수들을 작성한다. 코드적으로 배울 것은 list comprehension에서 이중 for문을 사용이 가능하다는 것과 torch.stack으로 list를 한번에 tensor로 만들어 줄 수 있다는 점이다.
import torch
import torch.nn as nn
from math import pi
import IPython.display as ipd
import random
import matplotlib.pyplot as plt
SR = 16000
def make_sine_wave(freq, amp, dur, sr=16000):
num_samples = dur * sr
time_frame = torch.arange(num_samples)
time_frame_sec = time_frame / sr
return amp * torch.sin(2 * pi * freq * time_frame_sec)
def make_sine_wave_harmonics(freq, amp, dur, sr=16000, num_harm=7):
fund = make_sine_wave(freq, amp, dur, sr)
for i in range(2, num_harm):
fund += make_sine_wave(freq * i, amp*random.random()/i ** (1+random.random()), dur, sr)
return fund
def make_white_noise(amp, dur, sr):
return torch.randn(dur*sr)*amp
def make_pitch_class_dataset(n_samples_per_pitch):
pitches = [440., 466.2, 493.8, 523.3, 554.4, 587.3,
622.3, 659.3, 698.5, 740., 784.0, 830.6]
pitch_name = ['A', 'Bb', 'B', 'C', 'Db', 'D', 'Eb', 'E', 'F', 'Gb', 'G', 'Ab']
dataset = [make_sine_wave_harmonics(pitch, 0.3+random.random()/2, 3, SR, num_harm=3) + make_white_noise(random.random()*0.1, 3, SR)
for pitch in pitches for i in range(n_samples_per_pitch)]
# list comprehension에서 이중 for문을 사용할 수 있다.
# 왼쪽 for가 더 높은 카테고리가 된다.
pitches = [i for i in range(len(pitch_name)) for j in range(n_samples_per_pitch)]
dataset = torch.stack(dataset)
pitches = torch.LongTensor(pitches)
return dataset, pitches
def make_random_pitch_dataset(n_samples, pitch_range=(220, 880)):
min_pitch, max_pitch = pitch_range
pitches = [random.randint(min_pitch, max_pitch) for i in range(n_samples)]
dataset = [make_sine_wave_harmonics(pitch, 0.3, 3, SR) + make_white_noise(random.random()*0.2, 3, SR)
for pitch in pitches]
# Tensor list를 한번에 tensor로 만든다
dataset = torch.stack(dataset)
pitches = torch.Tensor(pitches)
return dataset, pitchesMake Spectrogram
torchaudio를 사용해서 spectrogram을 만들어본다. 흥미로운 점은 변수의 개수와 그래프를 그리는 방법에 대해서 다시금 생각해보게 되었다는 점이다. 변수가 1개일때 그래프를 그리면 2차 평면에서 그리는 그래프가 되고, 변수가 2개일때 그래프를 그리면 3차원 공간에서 입체적으로 그려지거나 spectrogram처럼 평면에 색깔로 그려지게 된다. 변수가 축이 된다! 이를 항상 의식하자.
!pip install torchaudio
import torchaudio
spec_converter_a = torchaudio.transforms.MelSpectrogram(sample_rate=SR, n_fft=4192, f_min=400, f_max=3200, n_mels=48)
spec_converter_b = torchaudio.transforms.MelSpectrogram(sample_rate=SR, n_fft=4192, f_min=400, f_max=3200, n_mels=96)
spec_a = spec_converter_a(dataset)
spec_b = spec_converter_b(dataset)
spec_a.shape # torch.Size([1200, 48, 23])
# 데이터 샘플 x 주파수의 축 x 시간 축Amplitude to DB
2차원에서 Amplitude값을 가지는 melspectrogram을 DB기반으로 바꾸어주어야 하는 이유를 배울 수 있다. log적으로 바꿔주어야 편차가 줄어든다.
amp_to_db_converter = torchaudio.transforms.AmplitudeToDB()
spec_a_db = amp_to_db_converter(spec_a)
spec_b_db = amp_to_db_converter(spec_b)
data_sample = spec_a[0]
torch.max(data_sample), torch.median(data_sample)
# (tensor(142881.5469), tensor(42.8917))
data_sample_db = spec_a_db[0]
torch.max(data_sample_db), torch.median(data_sample_db)
# (tensor(51.5498), tensor(16.3237))
Split Dataset
rand_ids = torch.randperm(dataset.shape[0])
print(rand_ids[:10])
# tensor([ 298, 780, 796, 679, 784, 1090, 1023, 871, 45, 334])
test = dataset[rand_ids]
test[0] == dataset[298]
# True
dataset_shuff = dataset[rand_ids]
pitches_shuff = pitches[rand_ids]
spec_converter = torchaudio.transforms.MelSpectrogram(sample_rate=SR, n_fft=4192, f_min=400, f_max=3200, n_mels=48)
spec_shuff = spec_converter(dataset_shuff)
spec_shuff_db = amp_to_db_converter(spec_shuff)
train_ratio = 0.8
slice_idx = int(len(dataset_shuff) * 0.8) # 1200 * 0.8
# print(slice_idx)
train_set = spec_shuff_db[:slice_idx]
test_set = spec_shuff_db[slice_idx:]
train_label = pitches_shuff[:slice_idx]
test_label = pitches_shuff[slice_idx:]
test_set.shape # torch.Size([240, 48, 23])
Make Neural Network
# fully connected layer는 1차원 벡터만을 인풋으로 받을 수 있다.
# 따라서 flatten을 해서 48 x 23를 쓰던지
# 혹은 시간의 한 부분을 잘라서 쓸 수 있다.
class PitchClassifier(nn.Module):
def __init__(self):
super().__init__()
self.layer = nn.Linear(in_features = 48, out_features = 12)
def forward(self, x):
return self.layer(x)
pitch_classifier = PitchClassifier()
#pitch_classifier(train_set) == pitch_classifier.forward(train_set)Test if the model can work
# 우선은 스펙트로그램의 단면을 잘라서 넣어보자.
train_set_5 = train_set[:,:,5]
test_set_5 = test_set[:,:,5]
pitch_classifier(train_set_5[:10])Softmax - Loss - Backpropagation - Optimizer
def softmax(x, dim):
exp_v = torch.exp(x)
sum_v = torch.sum(exp_v, dim=dim, keepdim=True)
return exp_v / sum_vNegative log-likelihood
0에 가까워 질수록 무한에 가깝게 손실값이 커지는 함수
def get_nll_loss(pred, target):
prediction_for_target_class = pred[torch.arange(len(pred)), target]
return torch.mean(-torch.log(prediction_for_target_class))# 단면으로 자른 값을 모델에 넣어서 학습한뒤에 loss 값을 계산한다.
loss = get_nll_loss(softmax(train_set_5_output, -1), train_label[:10])
loss.backward()
pitch_classifier.layer.weight.grad.shape
# torch.Size([12, 48])
# weight가 계산된 gradient를 들고 있다.# 계산된 gradient를 어떻게 업데이트 해줄까?
optimizer = torch.optim.Adam(pitch_classifier.parameters(), lr=0.001)
optimizer.step()Iteration
optimizer.zero_grad()를 해주어야 들고가는 gradient가 중첩되지 않는다.
loss_tracker = []
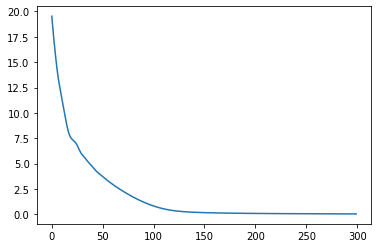
for i in range(300):
optimizer.zero_grad()
pred = pitch_classifier(train_set_5)
pred = softmax(pred, dim=-1)
loss = get_nll_loss(pred, train_label)
loss.backward()
optimizer.step()
loss_tracker.append(loss.item())
plt.plot(loss_tracker)