Three contributions from the paper
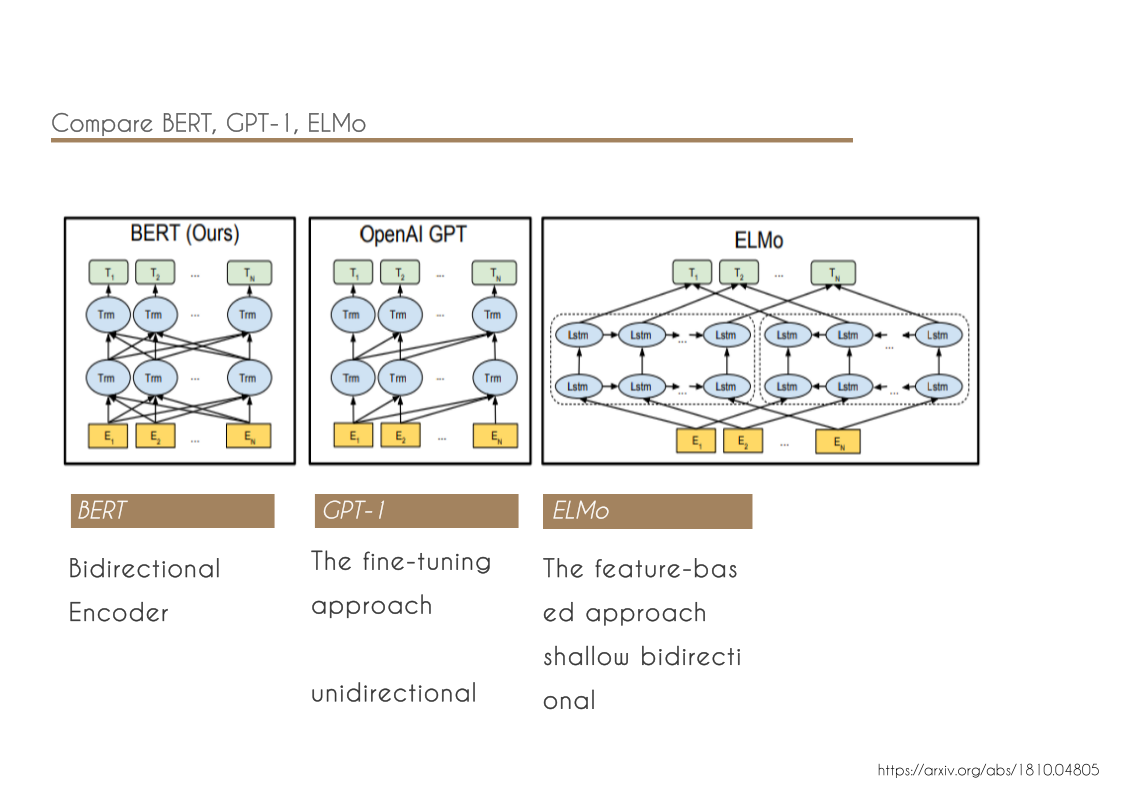
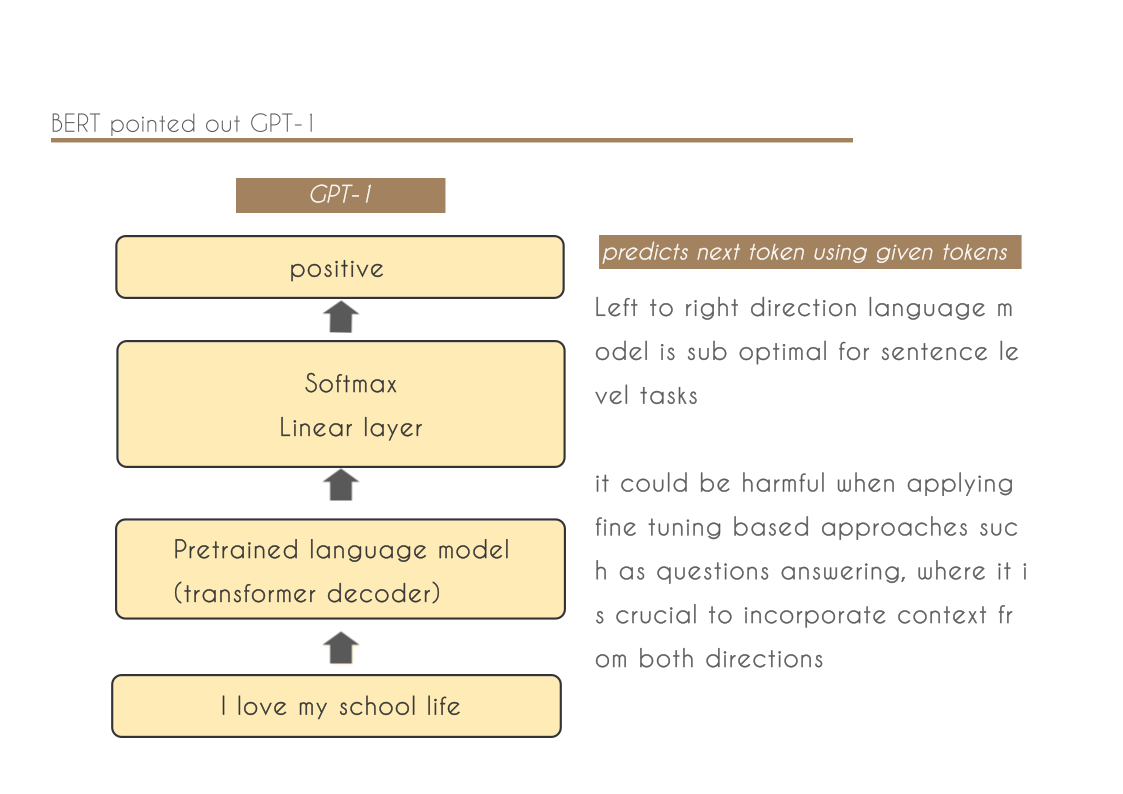
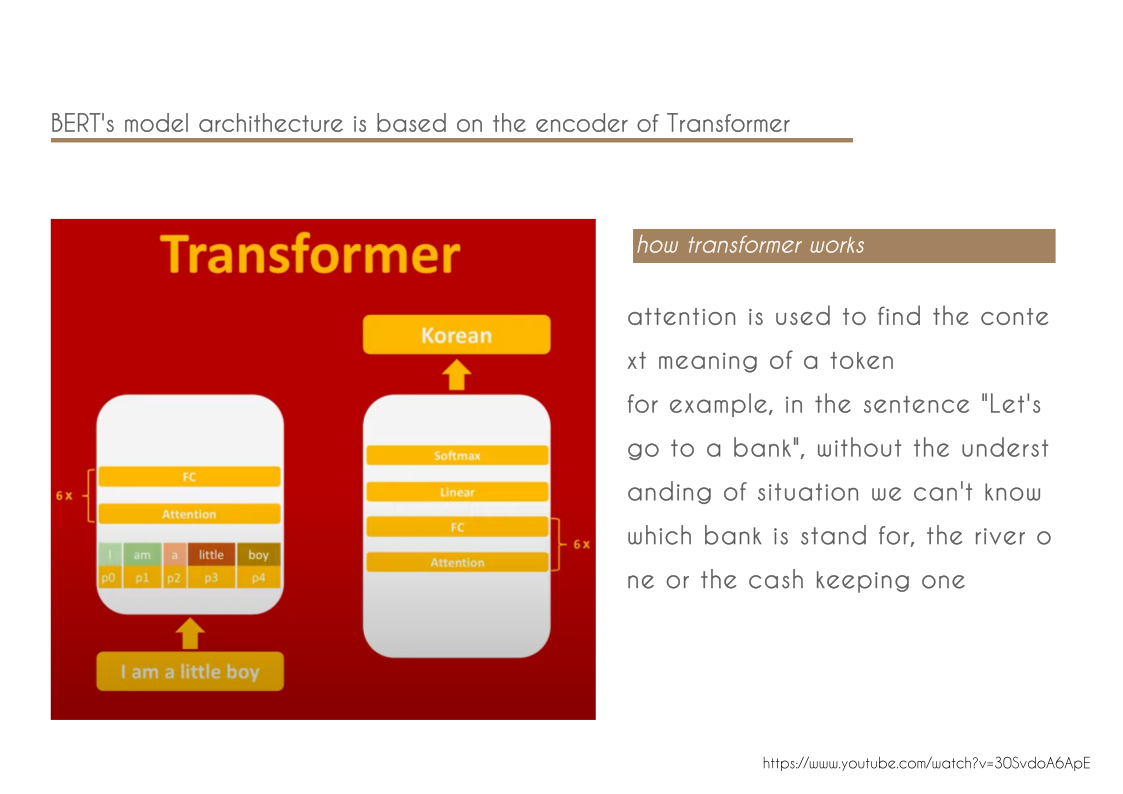
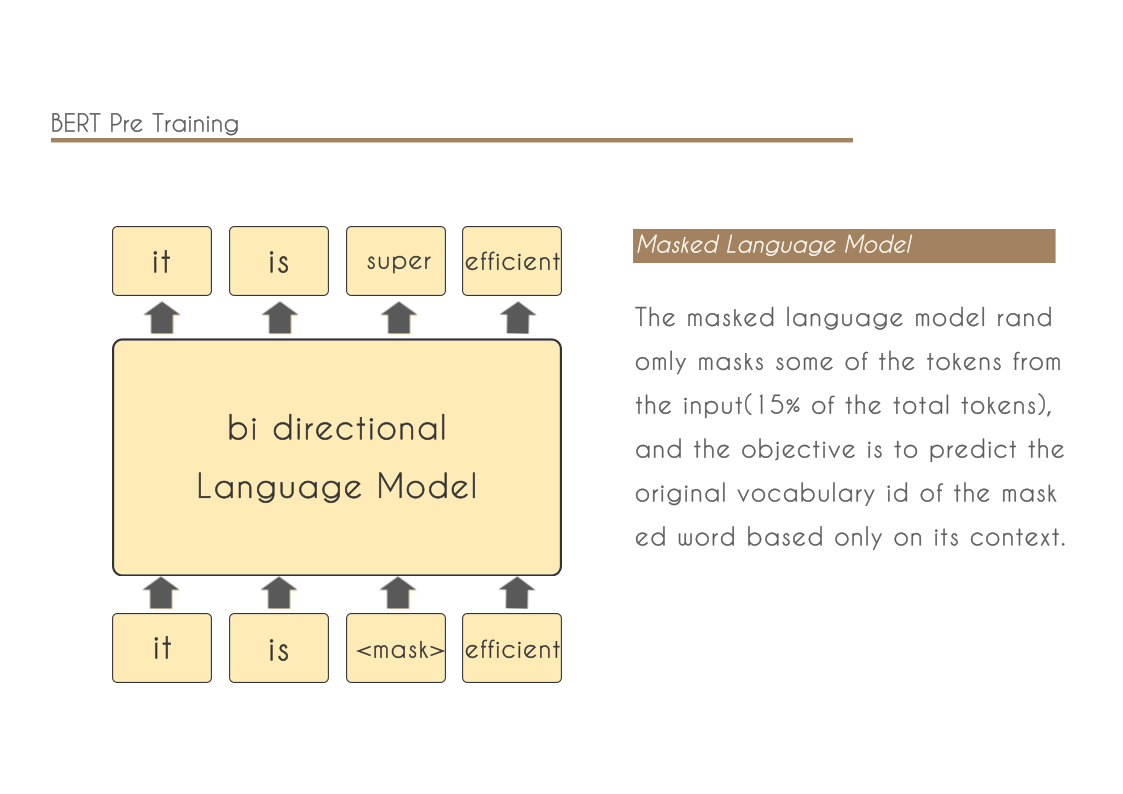
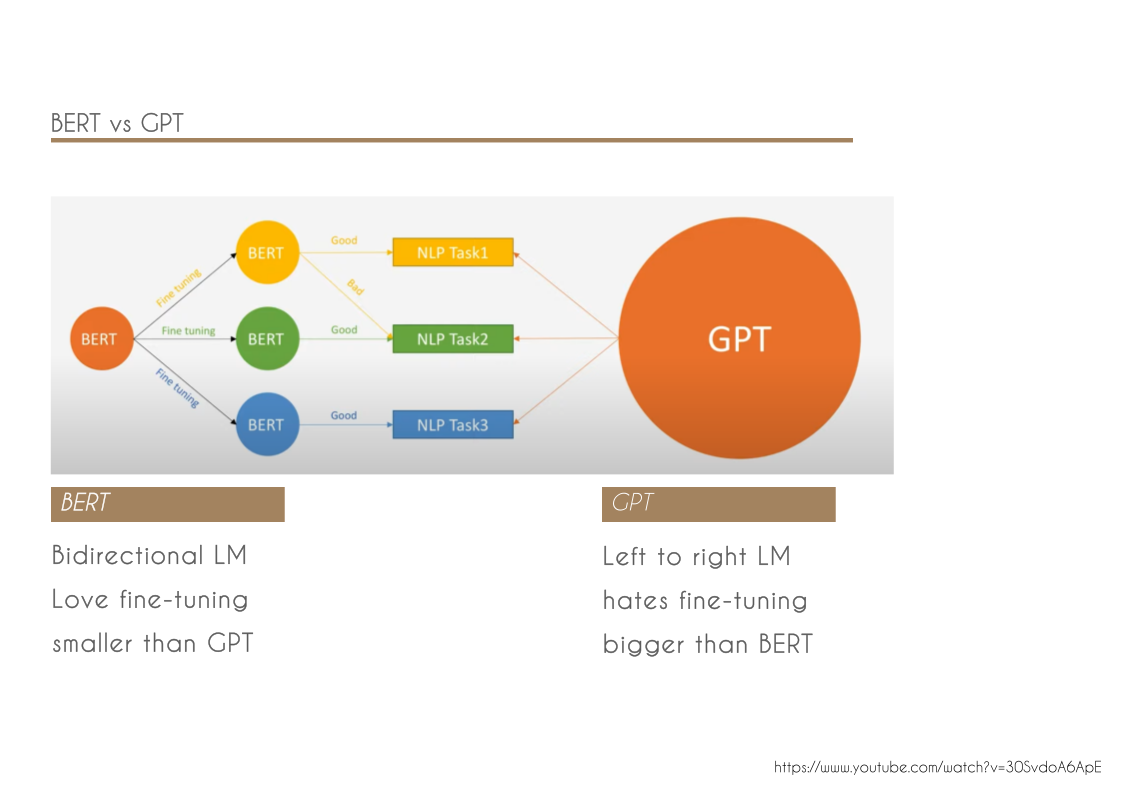
- We demonstrate the importance of bidirectional pre-training for language representations. Unlike Radford et al. (2018), which uses unidirectional language models for pre-training, BERT uses masked language models to enable pretrained deep bidirectional representations. This is also in contrast to Peters et al. (2018a), which uses a shallow concatenation of independently trained left-to-right and right-to-left LMs.
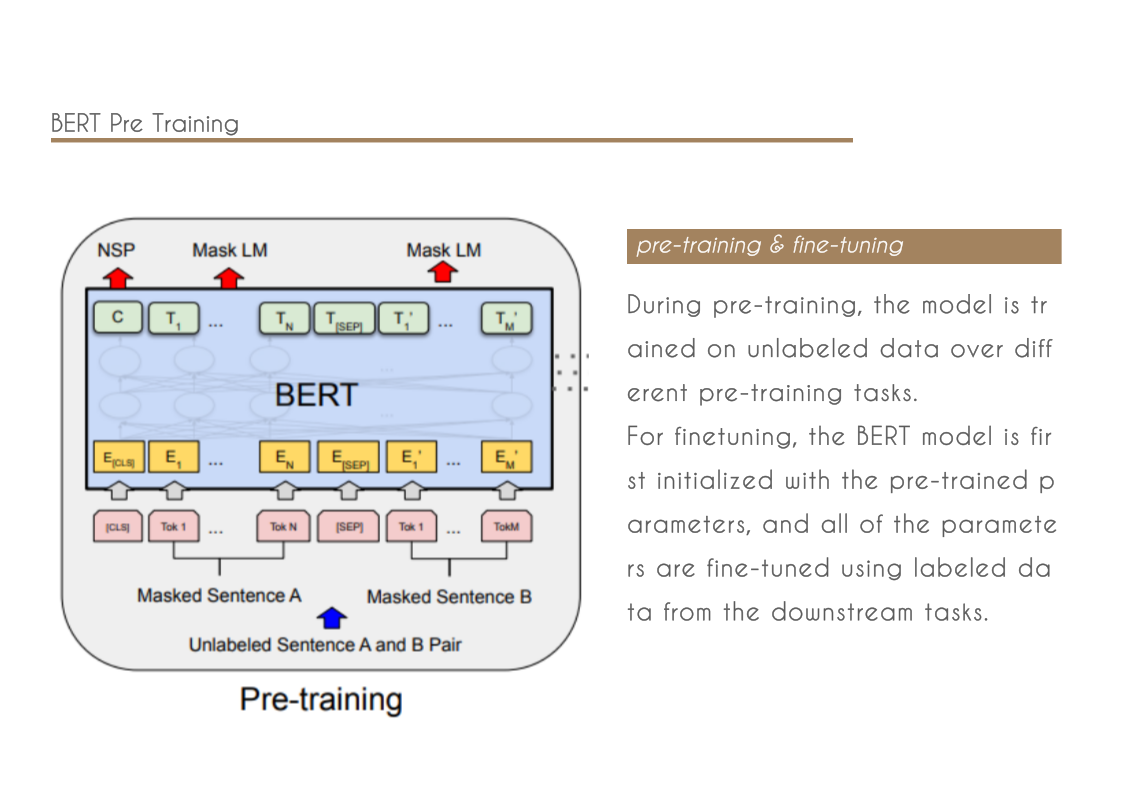
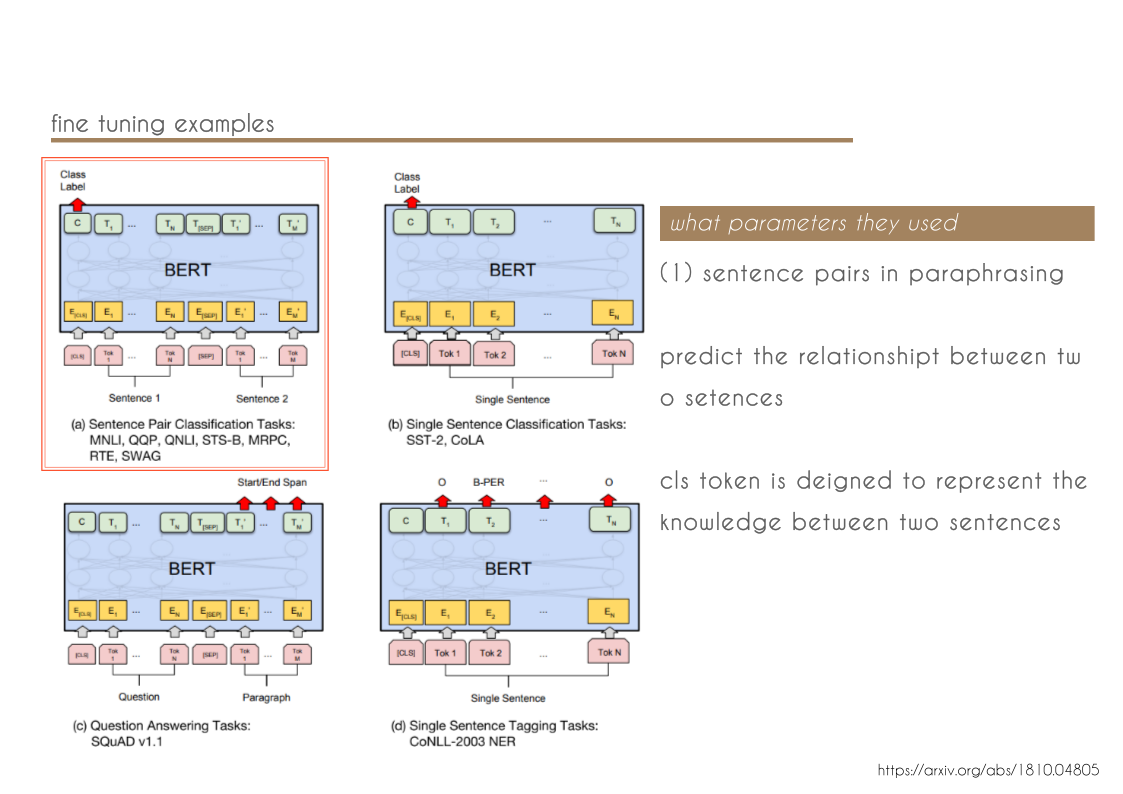
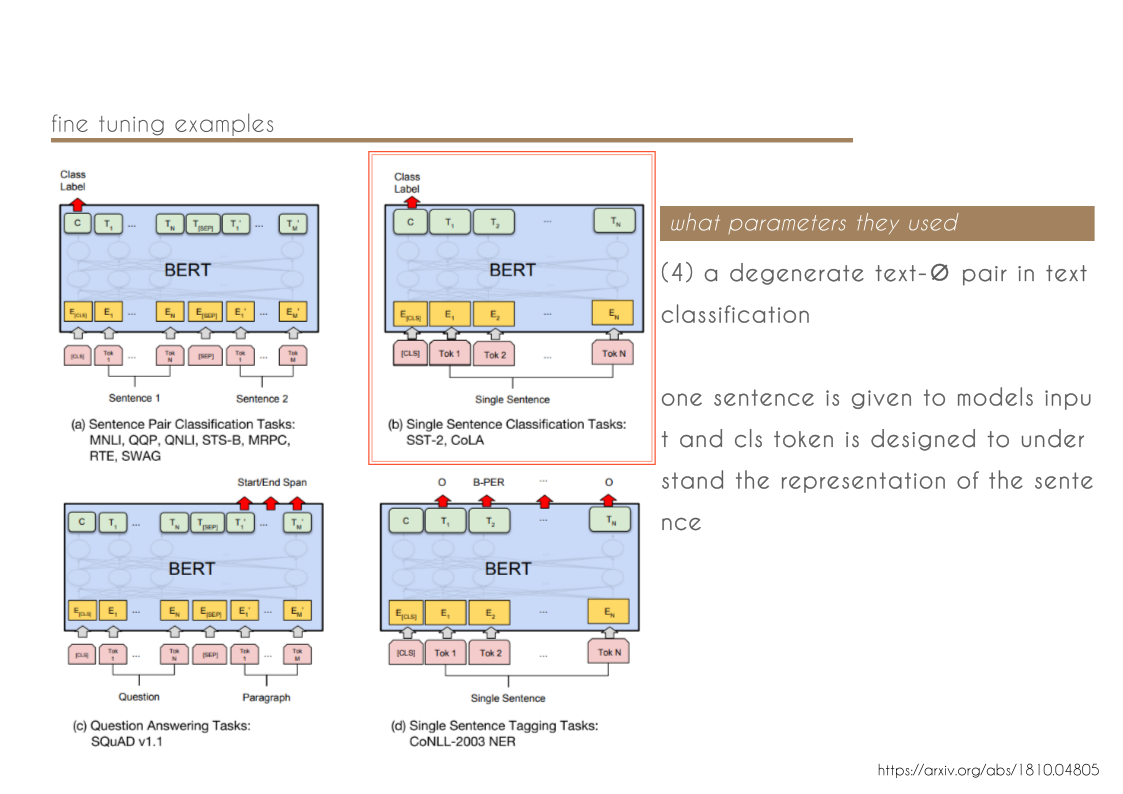
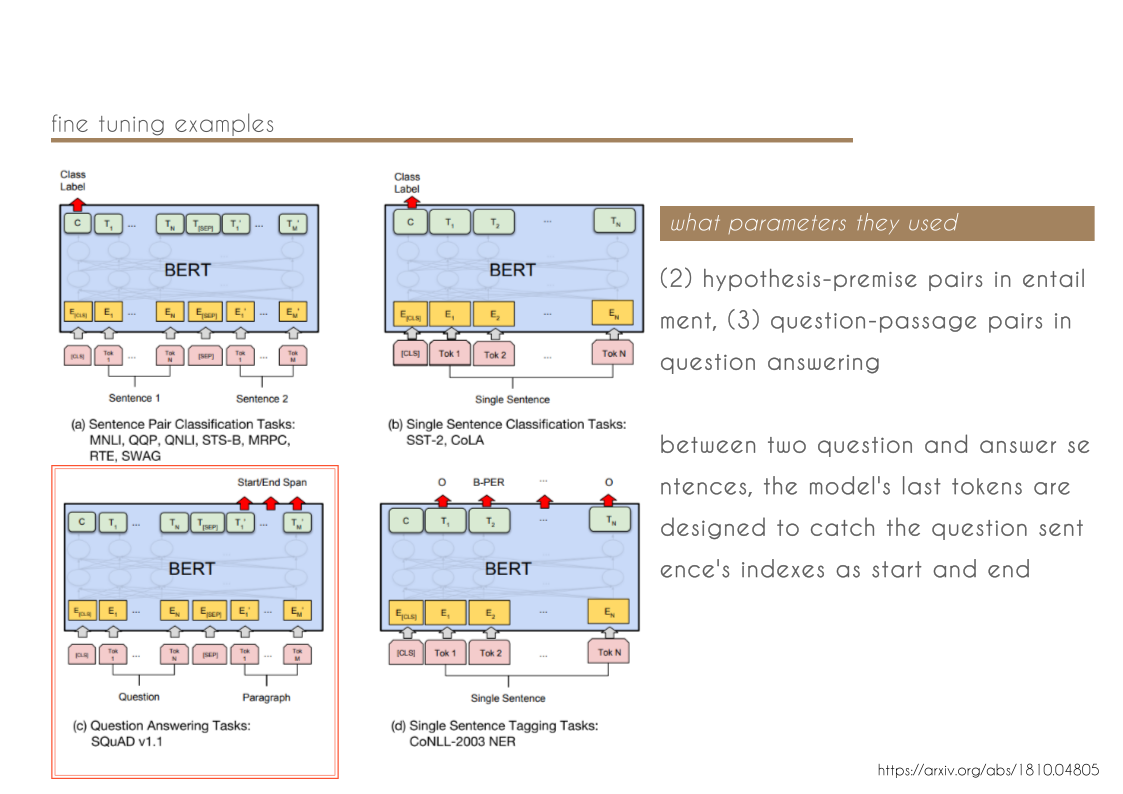
- We show that pre-trained representations reduce the need for many heavily-engineered taskspecific architectures. BERT is the first finetuning based representation model that achieves state-of-the-art performance on a large suite of sentence-level and token-level tasks, outperforming many task-specific architectures.
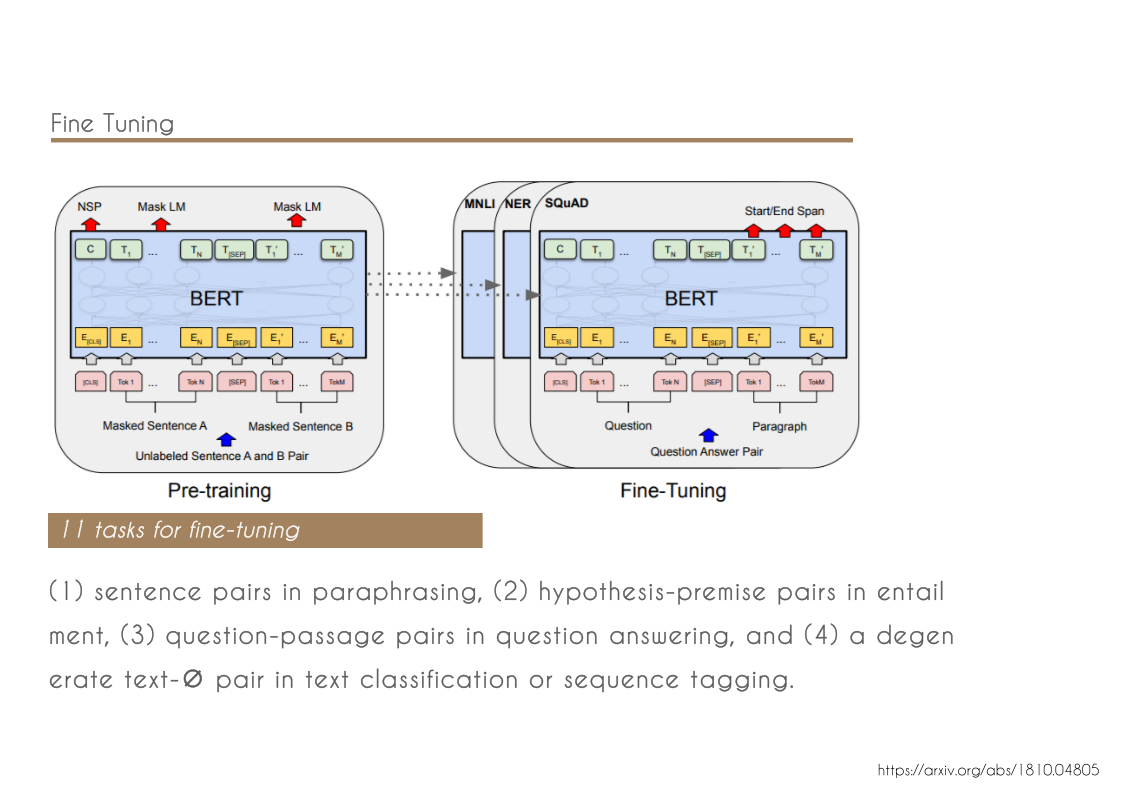
- BERT advances the state of the art for eleven NLP tasks.
Framework
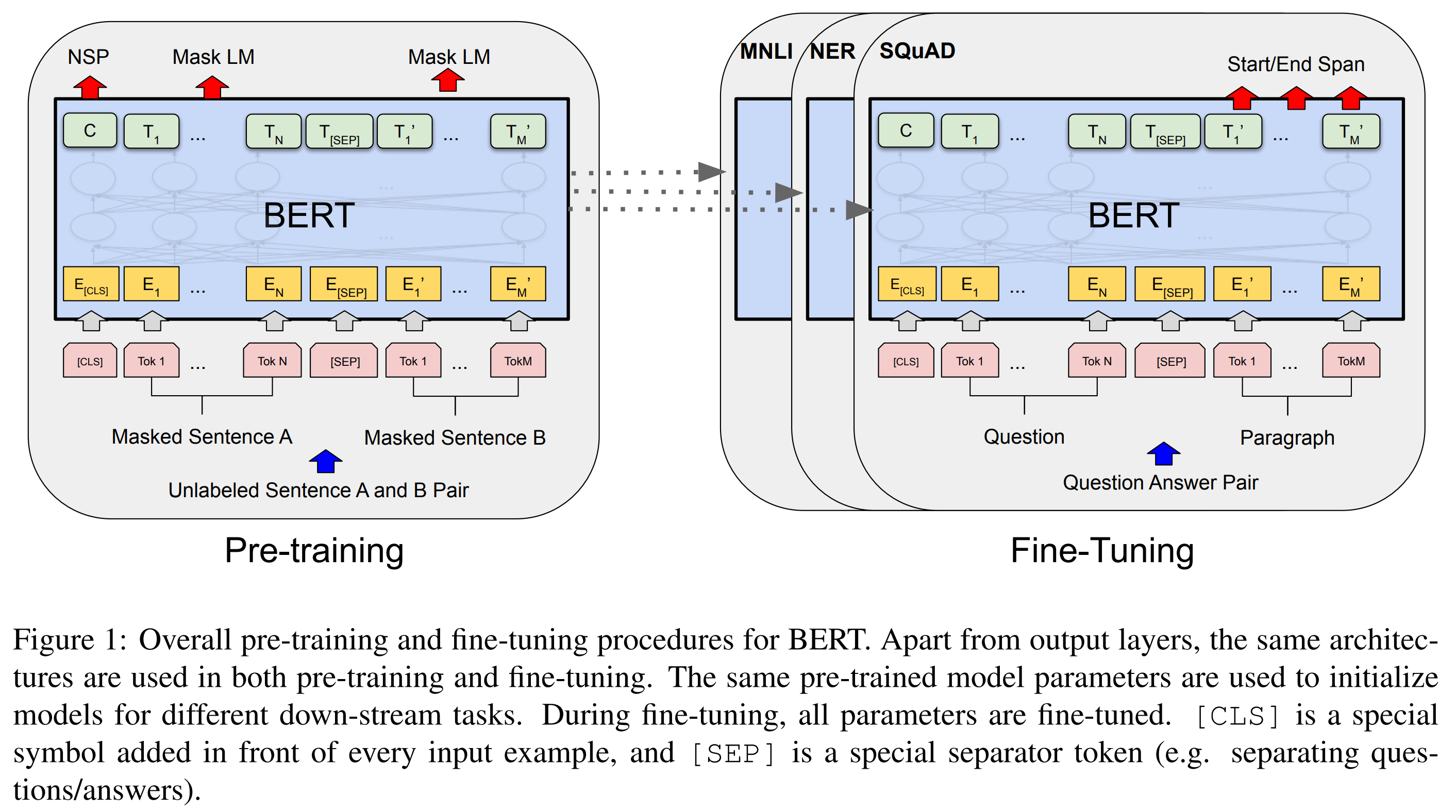
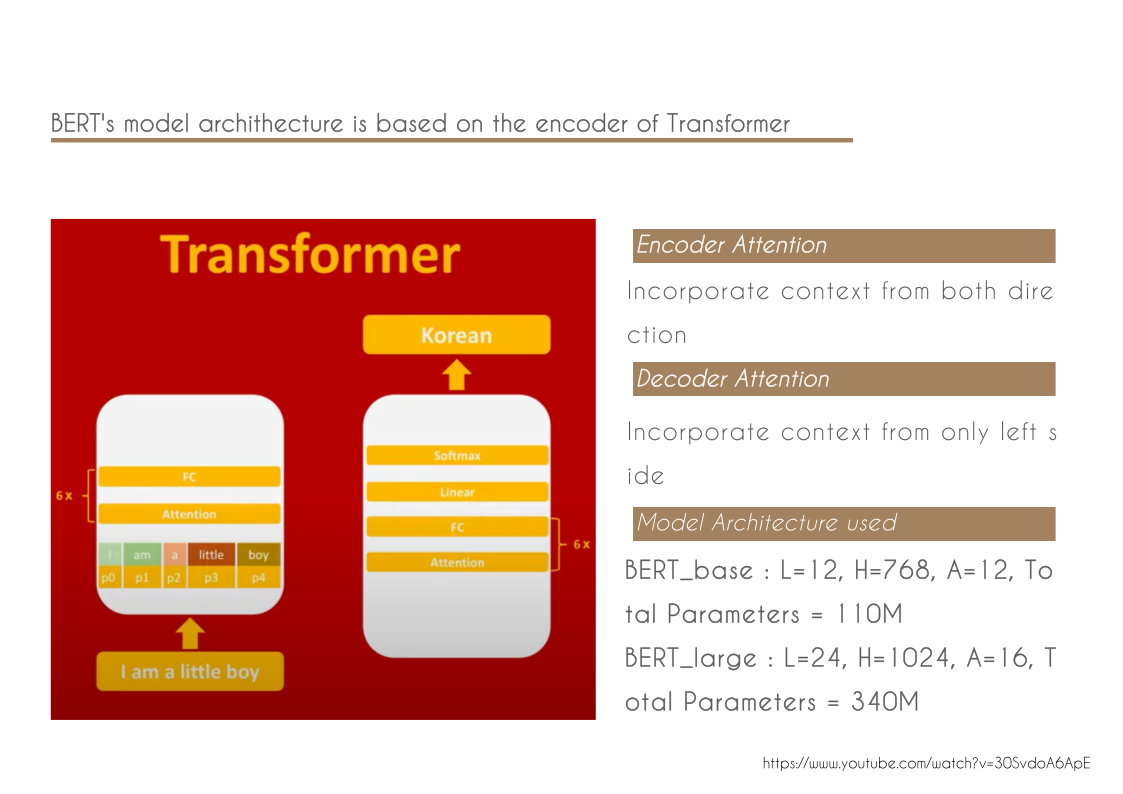
Size of the model
BERTBASE (L=12, H=768, A=12, Total Parameters=110M)
BERTLARGE (L=24, H=1024, A=16, Total Parameters=340M)
BERTBASE was chosen to have the same model size as OpenAI GPT for comparison purposes.






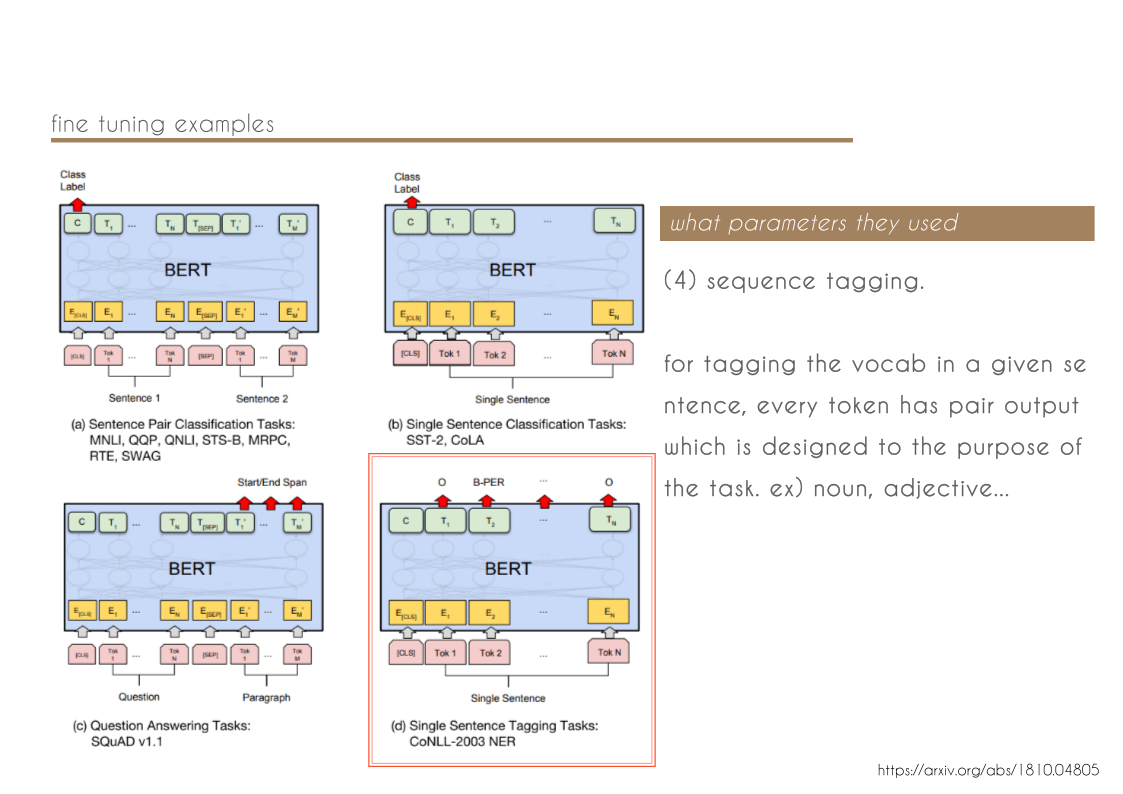
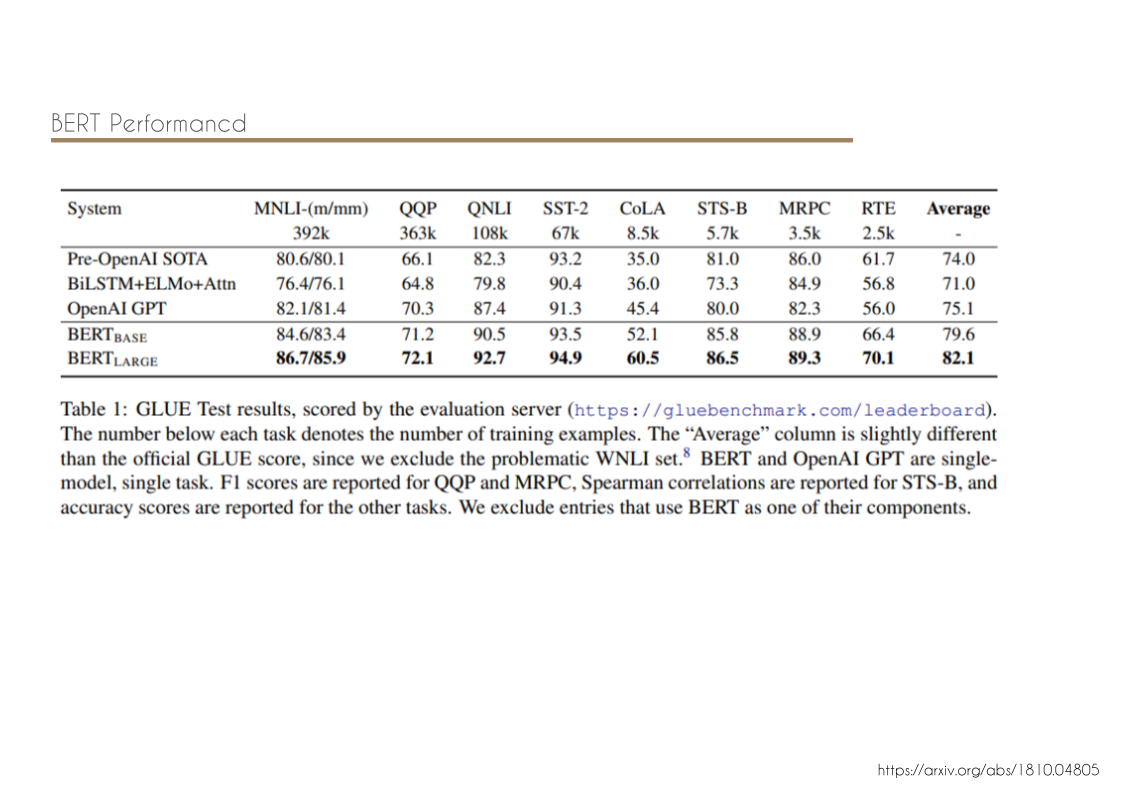

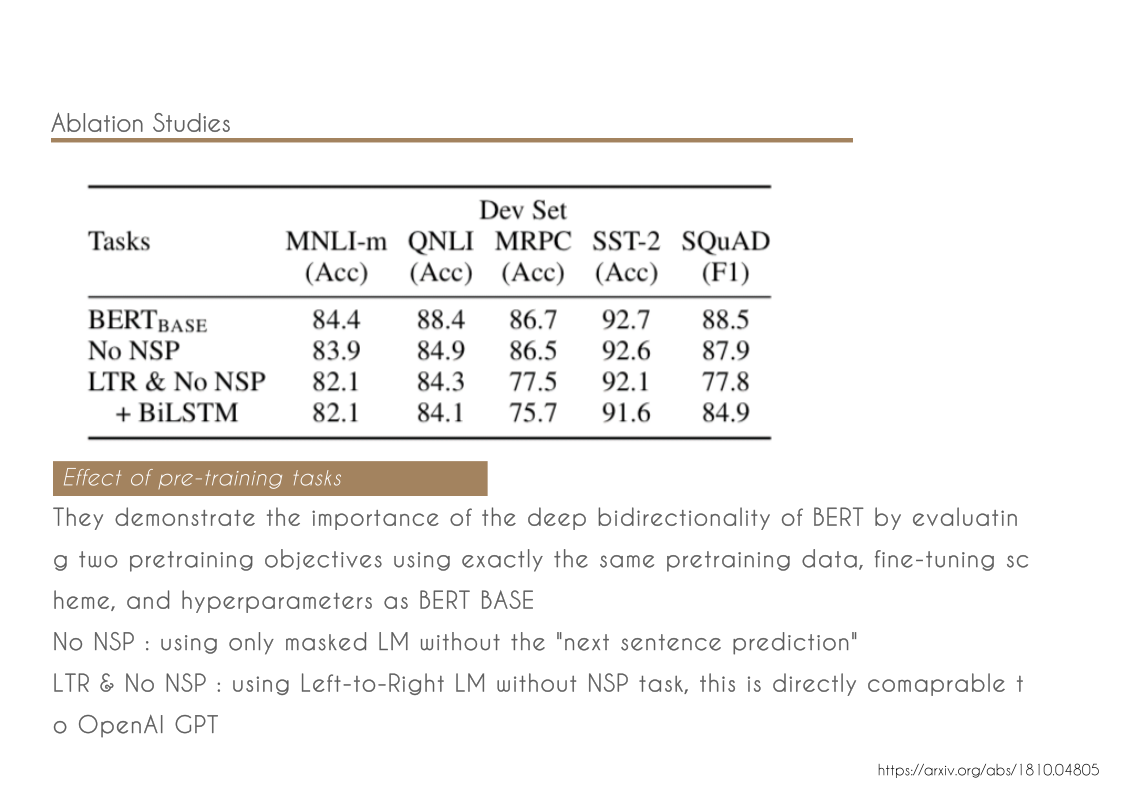
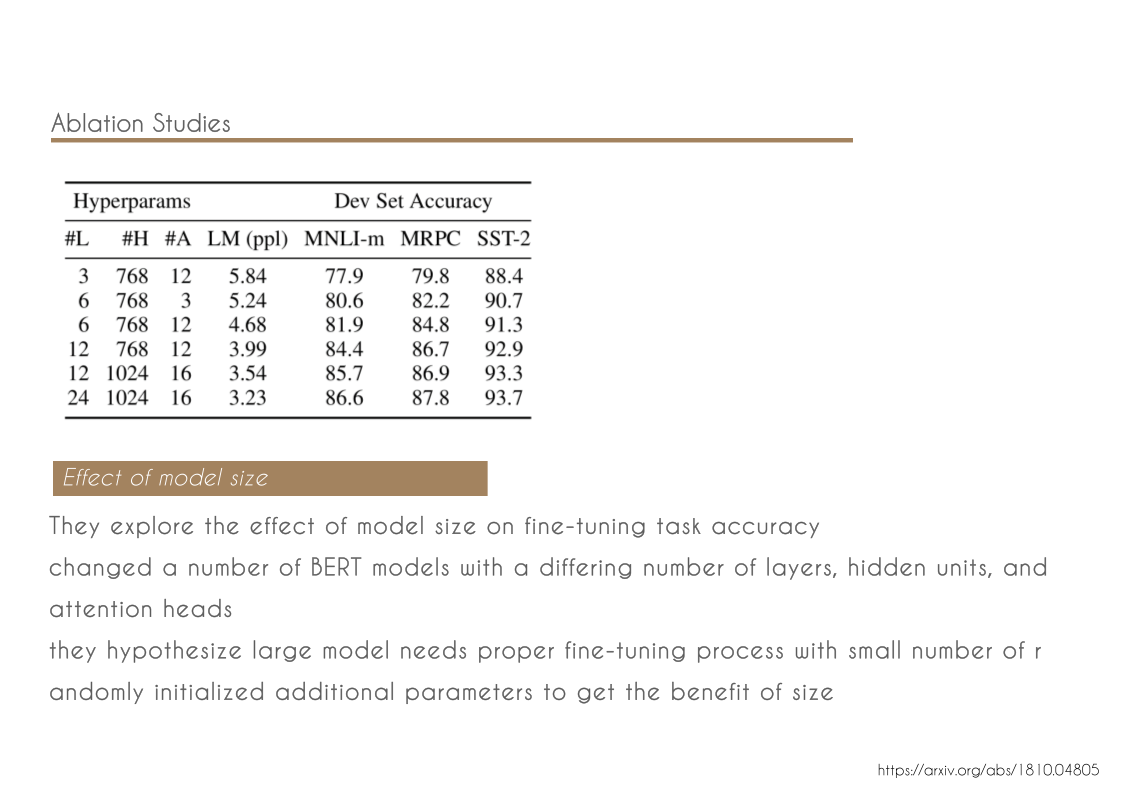



chords & code // harmony with structure