https://arxiv.org/pdf/2104.01778.pdf
AST: Audio Spectrogram Transformer
Yuan Gong, Yu-An Chung, James Glass
Abstract
CNN이 그동안 audio classification에서 뛰어난 성능을 보였지만, 전체적인 길이와 정확한 해석에 필요한 맥락이 길어질 수록 CNN으로 커버하기에는 한계가 있는듯하다. 이를 보완하기 위해 CNN에 self-attention mechanism을 더한 형태의 hybrid 모델이 탄생한다. 해당 논문은 여기에서 CNN을 빼고 attention만을 활용한 모델인 Audio Spectrogram Transformer(AST)을 제시한다. 그리고 이 모델이 얼마나 뛰어난 성능을 발휘했는지를 보이고자 한다.
1. Introduction
as the inductive biases inherent to CNNs such as spatial locality and translation equivariance are believed to be helpful.
CNN이 좋을 것이라는 생각에 도전을 해보자.
Convolution-free, purely attention based model이 AST인데 특이하게도 이 모델은 ImageNet에 학습된 Vision Transformer의 무언가(파라미터?)를 전이transfer받았다고 한다.
세가지 장점을 가진다. 우선 성능이 좋다. AudioSet, ESC-50, Speech Commands등의 데이터셋에서 state-of-the-art의 성능을 냈다.
두번째로 기본적으로 다양한 길이의 인풋에 대응할 수 있도록 만들어졌다. 1초에서 10초의 인풋이었다. 근데 우리 데이터는 120초인데... 아무튼 이는 CNN이 다른 인풋에 최고의 성능을 위해서는 tuning이 필요한 것과 대조적이다.
세번째로 CNN hybrid model보다 간단한 아키텍쳐와 적은 파라미터를 가진다.
Related Work
AST and ViT have similar architectures but ViT has only been applied to fixed-dimensional inputs (images) while AST can process variable-length audio inputs.
2. Audio Spectrogram Transformer
2-1. Model Architecture
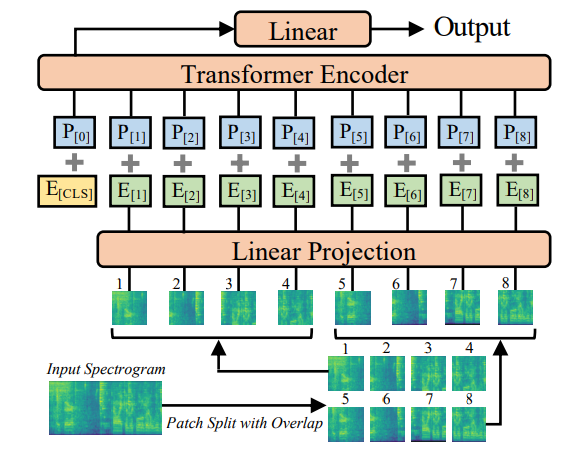
1.오디오 인풋을 128-dimensional log Mel filterbank(fbank)로 바꾸어준다.
2.spectrogram을 16 x 16 patch로 나누어준다.
3.각 patch가 768크기의 1D 벡터가 되도록 projection layer를 거친다. 이는 embedding과 같다.
4.위치 임베딩을 추가한다.
5.Transformer가 batchsize x 지정된 classes의 갯수의 아웃풋을 내놓는다.
사용한 transformer는 modification을 하지 않은 모델로 이것을 이용하면 사용이 편리하며 transfer learning이 쉽다는 장점이 있다.
2-2. ImageNet Pretraining
Transformer는 CNNs보다 더 많은 데이터를 필요로 한다. 다른 논문에서는 1천4백만장 이상의 이미지 데이터가 있을때 transformer의 성능이 더 뛰어나다고 지적한다. 그래서 이 모델은 이미지로 학습된 모델을 활용한 transfer learning을 사용한다. 다양한 논문에서는 vision task가 audio task에도 적용이 가능하다는 것을 증명한다.
ViT(vision Transformer)와 AST는 비슷한 아키텍쳐를 가지지만 실제적인 데이터에 모델을 적용하기 위해서는 몇몇 부분에 조정을 거칠 필요가 있다.
First, the input of ViT is a 3-channel image while the input to the AST is a single-channel spectrogram, we average the weights corresponding to each of the three input channels of the ViT patch embedding layer and use them as the weights of the AST patch embedding layer. We also normalize the input audio spectrogram so that the dataset mean and standard deviation are 0 and 0.5, respectively.
Second와 Third는 이해가 잘 되지 않아서 일단 생략합니다.
알아두면 좋을 것은 embedding을 거친 데이터는 784로 flatten된 1D array라는 것입니다. 784라면 28 x 28 사이즈의 이미지 데이터를 flatten한 값으로 image classification 모델의 인풋으로 넣어주기에 딱 좋은 크기인 것 같습니다.
3. Experiments
evaluating the AST on AudioSet
3-1. AudioSet Experiments
AudioSet is a collection of over 2 million 10-second audio clips excised from YouTube videos and labeled with the sounds that the clip contains from a set of 527 labels.
그리고 성능이 굉장히 좋았다고 합니다...!
4. 사용법
https://github.com/YuanGongND/ast
사용법을 자세히 설명해주신다. 관건은 데이터 파일을 넣을 수 있도록 잘 조정하는 작업이 될 것 같은데, 팁으로 ESC-50 recipe는 AudioSet pretrained model을 사용하므로 여기에서 사용한 조정 방법을 잘 참고하라고 하신다.
Pretrained Model은 AudioSet과 Speechcommands V2의 데이터에 맞추어진 모델을 제공한다.
1.설명에 따르면 오디오 데이터는 반드시 16kHz를 맞추어야 한다.
2.거기에 spectrogram을 128-dimensional log Mel filterbank(fbank)으로 만들어주어야 한다. 아래 코드를 보면 인풋이 100 time frames에 128 mel frequency로 만들어진 3차원 텐서라는 것을 알 수 있다.
3.또한 학습시에 사용된 인풋 데이터는 normalization을 거친 값이므로 우리의 데이터 또한 spectrogram의 값의 평균이 0이고 표준편차가 0.5이 되어야 한다.(다만 예제는 torch.rand이니까 0에서 1사이의 값이다?)
4.SpecAug parameters, the mixup rate, batch size, initial learning rate 등을 조정해주어야 한다.
5.learning rate scheduler, metrics, warmup setting, optimizer 등을 조정해준다.
# 아주 간단히 작동이 되는지를 확인할 수 있는 코드이다.
import os
import torch
from models import ASTModel
# download pretrained model in this directory
os.environ['TORCH_HOME'] = '../pretrained_models'
# assume each input spectrogram has 100 time frames
input_tdim = 100
# assume the task has 527 classes
label_dim = 527
# create a pseudo input: a batch of 10 spectrogram, each with 100 time frames and 128 frequency bins
test_input = torch.rand([10, input_tdim, 128])
# create an AST model
ast_mdl = ASTModel(label_dim=label_dim, input_tdim=input_tdim, imagenet_pretrain=True)
test_output = ast_mdl(test_input)
# output should be in shape [10, 527], i.e., 10 samples, each with prediction of 527 classes.
print(test_output.shape) 