Optimizer Benchmark
코드구현
import import_ipynb
import numpy as np
import matplotlib.pyplot as plt
from optimizer import *
from collections import OrderedDictdef f(x,y):
return x**2 / 20.0 + y**2
def df(x,y):
return x/10.0 , 2.0*yinit_pos = (-7.0, 2.0)
params = {}
params['x'], params['y'] = init_pos[0], init_pos[1]
grads = {}
grads['x'], grads['y'] = 0, 0
optimizers = OrderedDict()
optimizers['SGD'] = SGD(lr=0.95)
optimizers['Momentum'] = Momentum(lr=0.1)
optimizers['AdaGrad'] = AdaGrad(lr=1.5)
optimizers['Adam'] = Adam(lr=0.3)idx = 1
plt.figure(figsize=(10,10))
for key in optimizers:
optimizer = optimizers[key]
x_history = []
y_history = []
params['x'], params['y'] = init_pos[0], init_pos[1]
for i in range(30):
x_history.append(params['x'])
y_history.append(params['y'])
grads['x'], grads['y'] = df(params['x'], params['y'])
optimizer.update(params, grads)
x = np.arange(-10, 10, 0.01)
y = np.arange(-5, 5, 0.01)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
# Z값은 2x2 행렬이며
mask = Z > 7
Z[mask] = 0
plt.subplot(2,2, idx)
idx += 1
# 가중치의 변화를 그린다.
plt.plot(x_history, y_history, 'o-', color='red')
# 배경인 색색깔의 등위선을 그린다.
plt.contour(X, Y, Z)
plt.ylim(-10, 10)
plt.xlim(-10, 10)
plt.plot(0, 0, '+')
plt.title(key)
plt.xlabel('x')
plt.ylabel('y')
plt.show()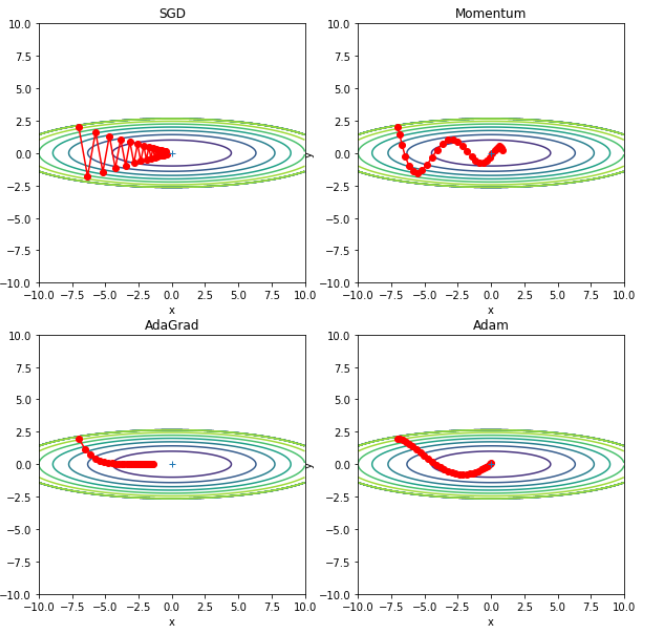
TwolayerNet에서 benchmark
코드구현
이전에 만든 TwolayerNet에 optimizer들을 사용해서 학습을 하고 optimizer별로 loss가 어떻게 줄어드는 지를 그래프로 그려보자.
import sys, os
sys.path.append("./dataset")
import numpy as np
from dataset.mnist import load_mnist
import import_ipynb
from two_layer_net import twolayerNet
import import_ipynb
from optimizer import *(x_train, y_train), (x_test, y_test) = load_mnist(normalize=True, one_hot_label=True) # flatten default T
max_iterations = 2000
train_size = x_train.shape[0]
batch_size = 128optimizers = {}
optimizers['SGD'] = SGD()
optimizers['Momentum'] = Momentum()
optimizers['AdaGrad'] = AdaGrad()
optimizers['Adam'] = Adam()
networks = {}
train_loss = {}
for key in optimizers.keys():
networks[key] = twolayerNet(input_size=784, hidden_size=50, output_size=10)
train_loss[key] = []for i in range(max_iterations):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
y_batch = y_train[batch_mask]
for key in optimizers.keys():
grads = networks[key].gradient(x_batch, y_batch)
optimizers[key].update(networks[key].params, grads)
loss = networks[key].loss(x_batch, y_batch)
train_loss[key].append(loss)
if i % 100 == 0:
print("=============" + "iterations:" + str(i) + "==============")
for key in optimizers.keys():
loss = networks[key].loss(x_batch, y_batch)
print(key + ":" + str(loss))import matplotlib.pyplot as plt
markers = {'SGD':'o','Momentum':'x','AdaGrad':'s','Adam':'D'}
x = np.arange(max_iterations)
plt.figure(figsize=(15,10))
for key in optimizers.keys():
plt.plot(x, train_loss[key], marker=markers[key], markevery=100, label=key)
plt.xlabel("iterations")
plt.ylabel('loss')
plt.ylim(0,2.5)
plt.legend()
plt.show()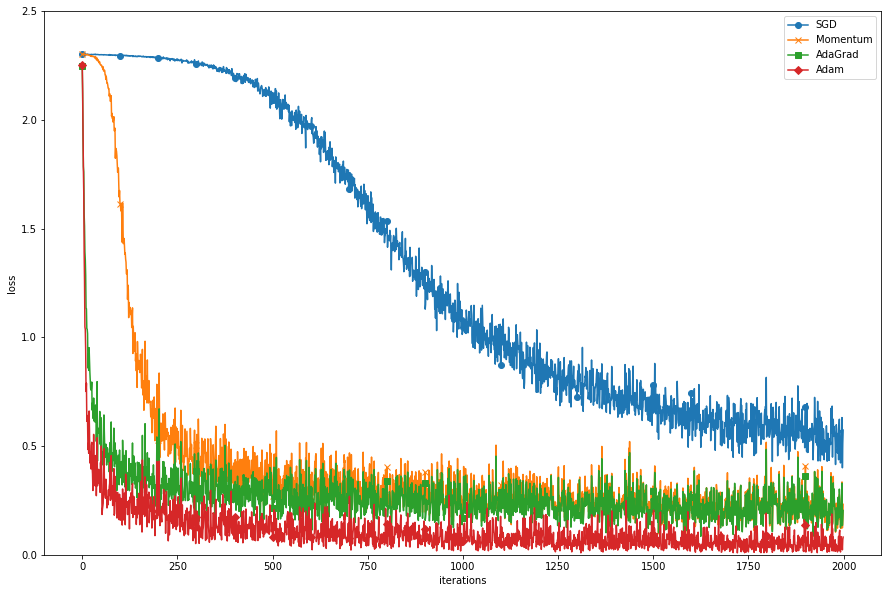

chords & code // harmony with structure