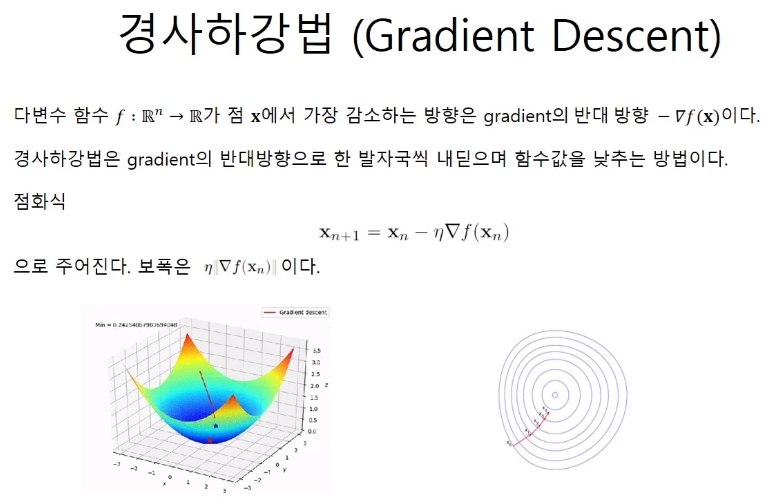
경사하강법
손실함수의 변수
인풋 데이터는 그 자체로 고정된 계수이다. 손실함수의 변수는 가중치와 편향이 된다.

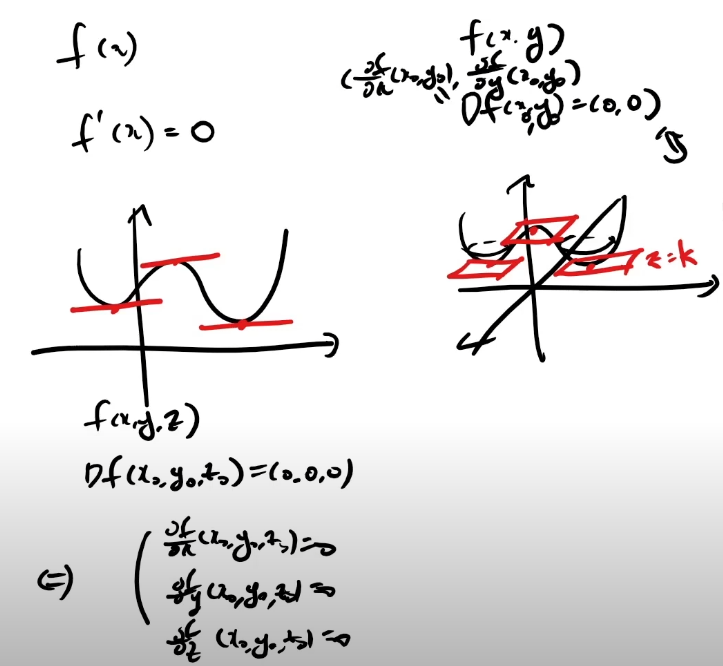
함수 값의 최대 최소를 구하는 문제는 gradient가 0이 되는 지점의 변수의 값을 구하는 문제이다.
MNIST 데이터에서의 손실함수의 변수의 개수
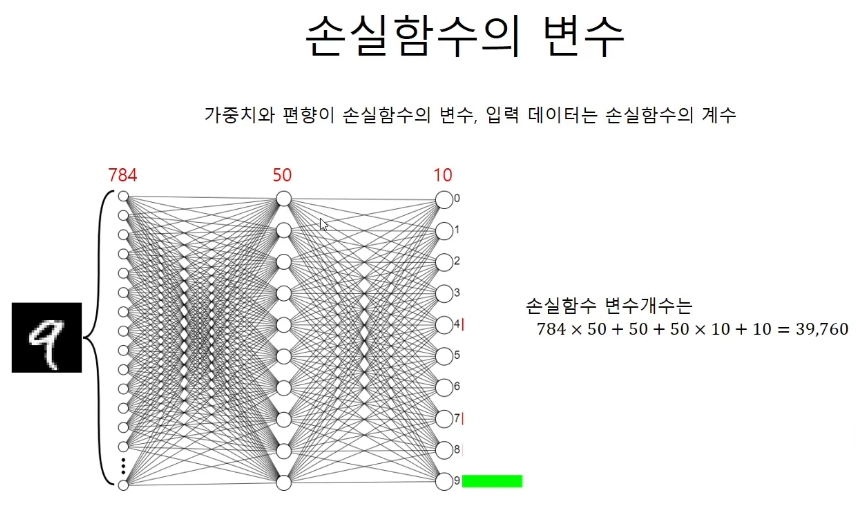
39,760개의 변수를 가지는 연립방정식을 푸는 것은 거의 불가능에 가깝다.
경사하강법
39,760개의 변수를 가지는 연립방정식을 푸는 것은 거의 불가능에 가깝기 때문에 차선책으로 경사하강법을 사용한다.
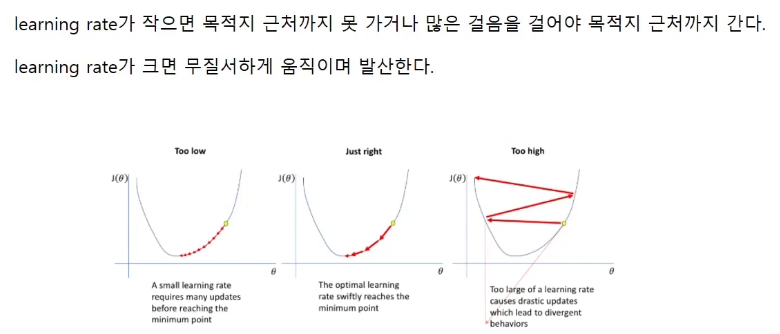
learning rate는 에타라고 읽는다.
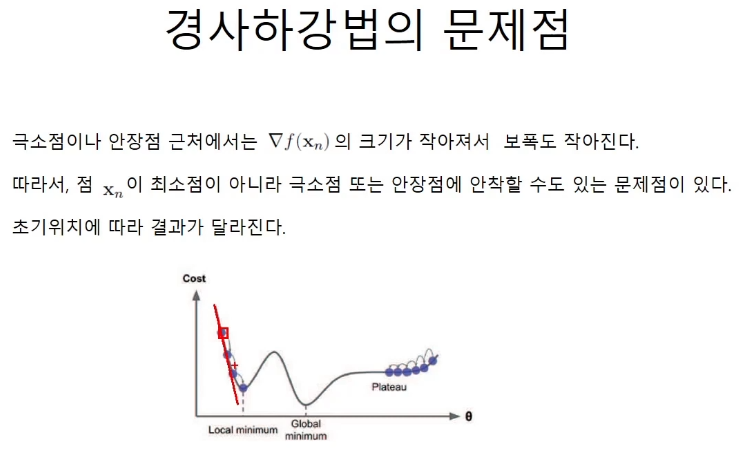
경사하강법의 문제점
global minimum, local minimum, plateau
Learning rate
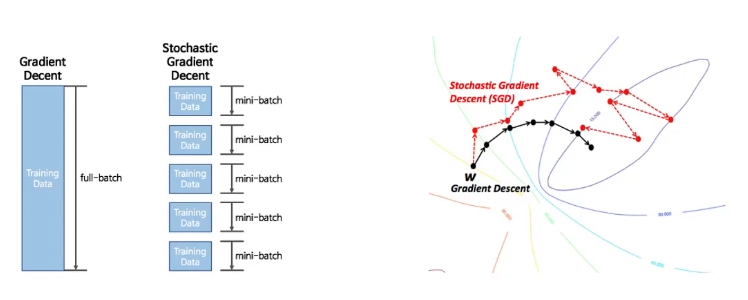
Stochastic Gradient Descent
전체를 대상으로 gradient를 구하는 것은 행렬연산으로 가능은 하지만 계산비용이 커진다는 단점이 있다. 따라서 batch를 통해서 일정 개수를 랜덤 샘플링해서 계산하는 방식을 쓴다.
실제로 gradient를 구하는 과정
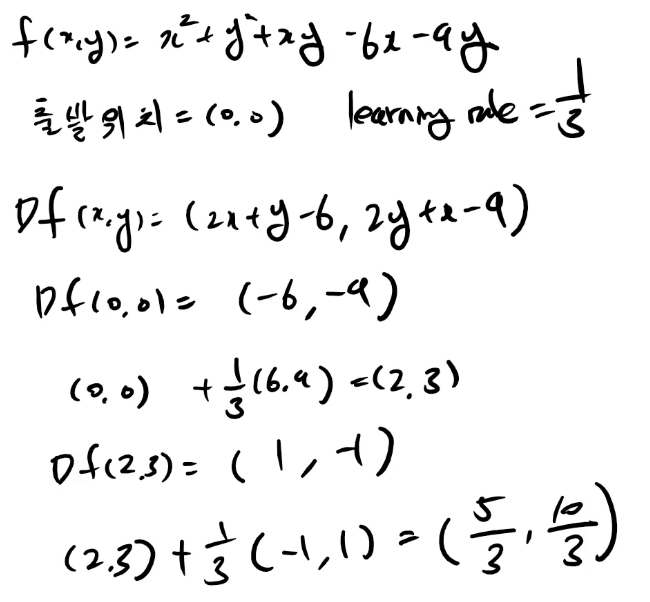
위 식을 연립방정식으로 구하면
2x + y -6 = 0과 2y + x -9 = 0의 해를 구하는 것과 같다.
gradient descent 코드 구현
import numpy as np
import matplotlib.pyplot as plt
from gradient_2d import numerical_gradient
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
x_history = []
for i in range(step_num):
x_history.append(x.copy())
grad = numerical_gradient(f,x)
x -= lr * grad
return x, np.array(x_history)numerical_gradient 코드로 최적의 W 가중치 찾아보기
앞서 만든 gradient_descent를 사용하지 않고
net.W = net.W - numerical_gradient를 활용해서 lr없이 W 가중치를 찾는 경사하강법을 구현한다.
import numpy as np
from functions import softmax, cross_entropy_error
from gradient_2d import numerical_gradient
class simpleNet :
def __init__(self):
self.W = np.random.randn(2,3)
def predict(self, x):
return np.dot(x, self.W)
def loss(self, x, t):
a = self.predict(x)
y = softmax(a)
loss = cross_entropy_error(y,t)
return loss
x = np.array([0.6, 0.9])
t = np.array([0, 0, 1])
net = simpleNet()
for i in range(10):
dW = numerical_gradient(f, net.W)
print(net.W)
print(softmax(net.predict(x)))
print(net.loss(x, t))
print('-----------------------')
net.W -= dWMNIST 데이터 학습 구현하기
accuracy는 39670 차원의 계단 형태의 함수이고
loss는 39670 차원의 곡선 형태의 함수이기 때문에 경사하강법을 위해서 loss함수를 사용한다.

class twolayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
#가중치 초기화
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
def predict(self, x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
return y
def loss(self, x, t):
y = self.predict(x)
return cross_entropy_error(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y==t) / float(len(y))
return accuracy
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
grads = {}
batch_num = x.shape[0]
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
dy = (y - t) / batch_num
grads['W2'] = np.dot(z1.T, dy)
grads['b2'] = np.sum(dy, axis = 0)
da1 = np.dot(dy, W2.T)
dz1 = sigmoid_grad(a1) * da1
grads['W1'] = np.dot(x.T, dz1)
grads['b1'] = np.sum(dz1, axis=0)
return grads
net = twolayerNet(784, 50, 10)
iter_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_lest = []
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iter_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
y_batch = y_train[batch_mask]
grad = net.gradient(x_batch, y_batch)
for key in ['W1', 'b1', 'W2', 'b2']:
net.params[key] -= learning_rate * grad[key]
loss = net.loss(x_batch, y_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = net.accuracy(x_train, y_train)
test_acc = net.accuracy(x_test, y_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print('train_acc : ', train_acc, 'test_acc : ', test_acc)
chords & code // harmony with structure