Pandas 시작하기
https://laboputer.github.io/machine-learning/2020/04/07/pandas-10minutes/
위 블로그 내용을 함께 공부하면 좋다.
Table
행과 열을 이용해서 데이터를 저장하고 관리하는 자료구조(컨테이너)
주로 행은 개체, 열은 속성을 나타냄
Pandas로 1차원 데이터 다루기 -Series
1-D labeled array
인덱스를 직접 지정해줄 수 있다.
import pandas as pd
s = pd.Series([1, 4, 9, 16, 25])
s ->
0 1
1 4
2 9
3 16
4 25
dtype: int64
t = pd.Series({'one':1,'two':2,'three':3,'four':4,'five':5})
t ->
one 1
two 2
three 3
four 4
five 5
dtype: int64Series + Numpy
Series는 ndarray와 유사하다.
s[1] -> 4
t[1] -> 2
t[1:3] ->
two 2
three 3
dtype: int64
#bool배열을 이용한 인덱싱
s[s > s.median()] ->
3 16
4 25
dtype: int64
#indices를 이용한 인덱싱
s[[3,1,4]] ->
3 16
1 4
4 25
dtype: int64Series 메소드 정리
유일한 값 찾기 : pd.Series.unique()
유일한 값별로 개수 세기 : pd.Series.value_counts()
Series + Numpy
Series는 dict와도 유사하다.
#key와 value
t['one'] -> 1
#dict에 값 추가
t['six'] = 6
#in
'six' in t -> True
#dic의 get method
t.get('seven', 0)Series에 이름 붙이기
각 Series는 'name' 속성을 가지고 있다.
처음 Series를 만들 때 이름을 붙일 수 있다.
s = pd.Series(np.random.randn(5), name ='random_nums')
s ->
0 0.076699
1 -0.076254
2 1.162232
3 0.131577
4 0.083183
Name: random_nums, dtype: float64
s.name = '임의의 정규분포 난수'Pandas로 2차원 데이터 다루기 - dataframe
2-D labeled table
엑셀의 표와 유사하게 생긴 자료 구조이다. 가로와 세로가 있으며 키와 밸류가 있는 자료 구조이다. 인덱스를 지정할 수 있는 특징을 가진다.
- dict 형식으로 만들어주기
#dict를 생성한다.
d = {'height':[1,2,3,4,], 'weight':[30,40,,50,60]}
df = pd.DataFrame(d)
df ->
height weight
0 1 30
1 2 40
2 3 50
3 4 60- 2D data, index, columns를 입력해서 만들기
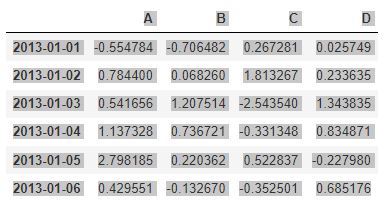
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))dtype 확인
numpy.array.dtype -> df.dtypes
각 column에 따라 dtype이 다를 수 있기 때문에 dtypes를 사용한다.
df.dtypes ->
height int64
weight int64
dtype: objectfrom Comma Separated value to dataframe
Pandas의 경우 CSV를 dataframe화 해줄 수 있다.
.read_csv()를 활용한다.
#동일경로에 country_wise_latest.csv가 존재하면
covid = pd.read_csv("./country_wise_latest.csv")Pandas 활용 1.일부분만 관찰하기
- head(n) : 처음 n개의 데이터 참조
#위에서부터 5개를 관찰하는 함수
covid.head(5)- tail(n) : 마지막 n개의 데이터를 참조
covid.tail(5)- index, colums, values 확인하기
df.index
# DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
# '2013-01-05', '2013-01-06'],
# dtype='datetime64[ns]', freq='D')
df.columns
# Index(['A', 'B', 'C', 'D'], dtype='object')
df.values
#df.to_numpy()를 이용한 값과 동일하다.
#2차원 ndarray로 변환된 행렬이 나온다.- describe() 사용하기
df.descrbie()
#순서대로 개수, 평균값, 표준편차, 최소값, 1사분위값, 중앙값, 3사분위값, 최대값이다.
# A B C D
# count 6.000000 6.000000 6.000000 6.000000
# mean 0.245593 0.087534 -0.072482 -0.297124
# std 1.407466 1.423367 0.549378 0.651149
# min -1.682384 -0.958267 -1.043931 -1.330950
# 25% -0.805462 -0.818679 -0.146146 -0.623695
# 50% 0.491811 -0.313566 -0.070392 -0.165601
# 75% 1.451725 0.113514 0.301730 0.110631
# max 1.638509 2.841777 0.495447 0.453095- sort_index(axis=,ascending) 사용하기
axis : 0=index, 1=column
ascending : True=오름차순, False=내림차순
df.sort_index(axis=1, ascending=False)- sort_values(by=)사용하기
#B칼럼 기준 정렬
df.sort_values(by='B')Pandas 활용 2.기본 방식으로 데이터 접근하기
Dataframe의 데이터를 접근하는 2가지 방법이 있다.
- df[] : 컬럼 하나의 데이터를 가져오기
dataframe을 column 단위로 잘라내면 그 자료는 series가 되기 때문에 ndarray와 같이 그 자료를 다룰 수 있게 된다. 또한 여러개의 column을 가져오고 싶은 경우 리스트의 형태로 column을 입력해주면 된다.
covid['Active']
covid.Activecovid[['Confirmed','WHO Region']]- df[index:index] : 슬라이싱으로 특정 범위의 행을 슬라이싱하기
df[0:3]
df['20130102':'20130104']Pandas 활용 3.bool배열의 조건을 이용해서 데이터 접근하기
하나의 column의 값에 따라 행들을 선택할 수 있다. 또한 DataFrame의 값들을 조건으로 bool배열을 만들어 사용할 수 있다. 가령 df가 숫자로만 이루어진 dataframe이라면 df[df > 0]도 가능하다.
bool배열 : True of False인 배열
df.unique() : series 안의 개체를 분류해서 종류별로 알려줌
#신규확진자가 100명이 넘는 나라를 찾아보자
#bool배열을 활용해서 indexing을 하면 된다.
covid['Country/Region'][covid['New cases'] >= 100]
#특이한점은 Series가 아니라 Dataframe에서도 bool배열을 이용한 indexing이 된다는 것이다.
covid[covid['New cases'] >= 100]#WHO 지역이 동남아시아인 나라 찾기
covid['WHO Region'].unique()
covid[covid['WHO Region'] == 'South-East Asia']Pandas 활용 4.행을 기준으로 데이터 접근하기
books_dict = {"Available":[True, True, False],"Location":[102,215,323],"Genre":['Programming','Physics','Math']}
books_df = pd.DataFrame(books_dict, index=['버그란 무엇인가','두근두근 물리학','미분해줘 홈즈'])
books_df ->
Available Location Genre
버그란 무엇인가 True 102 Programming
두근두근 물리학 True 215 Physics
미분해줘 홈즈 False 323 Math.loc : 이름으로 데이터 가져오기, 인덱스를 이용해서 가져오기
df.loc[인덱스명, 칼럼명] : 만약 인덱스명만 입력하면 행의 값으로 결과가 나온다. 그리고 인덱스 명은 리스트의 형태로 여러개가 지정이 가능하다. 또한 이름을 기준으로 슬라이싱이 가능하기 때문에 [멀티 리스트]와 :를 적절히 사용하면 원하는 구간의 값을 뽑아낼 수가 있다.
특이한점은 슬라이싱의 구간이 이상,이하라는 점이다. 그건 왜 그렇게 만들었지?
#loc에서 인덱스명만 입력한 경우
books_df.loc['버그란 무엇인가'] ->
Available True
Location 102
Genre Programming
Name: 버그란 무엇인가, dtype: object
books_df.loc[['버그란 무엇인가'],'Available':'Location'] ->
Available Location
버그란 무엇인가 True 102#'미분해줘 홈즈' 책이 대출가능한지 알수 있으려면?
books_df.loc['미분해줘 홈즈']['Available']
books_df.loc['미분해줘 홈즈', 'Available'] ->
False.iloc : 숫자 인덱스를 이용해서 가져오기
df.iloc[rowids, colidx] : 마찬가지로 인덱스번호만 입력할 경우 열로된 리스트가 출력된다. 멀티 인덱스의 경우도 .loc과 동일하며, 슬라이싱의 경우도 일반적인 슬라이싱과 사용법이 동일하다.
#인덱스 0행의 인덱스 1열을 가지고 오기
books_df.iloc[0,1] ->
102
#인덱스 1행의 인덱스 0~1열을 가지고 오기
books_df.iloc[0,0:2] ->
Available True
Location 102
Name: 버그란 무엇인가, dtype: objectPandas 활용 5.groupby
group by는 아래와 같은 과정을 말한다.
Splitting : 특정한 기준으로 DF를 분할한다.
Applying : 각 그룹에 통계함수를 독립적으로 적용시키는 것
Combining : Apply된 결과를 바탕으로 새로운 Series를 생성한다.(group_key : applied_value)
- groupby는 범주를 만들어서 해당 데이터들을 각 범주로 나누고, 그 범주들을 기준으로 평균.mean(), 최대값.max(), 최소값.min() 등을 구할 수 있게 해준다.
groups.agreegate(['mean','std'])
#2가지 이상의 값을 한번에 출력 가능하다.
groups.describes()
#통계를 모두 출력해줄 수 있다.- groupby로 두 개 이상의 column으로 그룹화가 가능하다.
#분기를 기준으로 그룹을 나누고 그 하부 그룹으로 달의 짝수 홀수로 나눈다.
groups_two = df.groupby(['분기','달의 짝수홀수'])#Who Region별 확진자수
#covid에서 확진자 수 column만 추출한다.
#이를 covid의 WHO Region을 기준으로 groupby한다.
covid_by_region = covid['Confirmed'].groupby(by=covid["WHO Region"])
#covid['Confirmed'].groupby(covid["WHO Region"])와 같다.
covid_by_region -> <pandas.core.groupby.generic.SeriesGroupBy object at 0x00000211B8763520>
#split만을 적용하면 객체로만 나온다.
covid_by_region.sum() ->
WHO Region
Africa 723207
Americas 8839286
Eastern Mediterranean 1490744
Europe 3299523
South-East Asia 1835297
Western Pacific 292428
Name: Confirmed, dtype: int64
#sum() /국가수
covid_by_region.mean() ->
WHO Region
Africa 15066.812500
Americas 252551.028571
Eastern Mediterranean 67761.090909
Europe 58920.053571
South-East Asia 183529.700000
Western Pacific 18276.750000
Name: Confirmed, dtype: float64