다층 퍼셉트론
퍼셉트론 : 선형분류기linear classifier 한계
선형 분리 불가능한 상황에서 일정한 양의 오류가 발생
1969년 minsky papert
퍼셉트론의 한계를 지적하고 다층 구조를 이용한 극복 방안을 제시하였지만 당시 기술로는 불가능
1986년 Rumelhar, hinton
다층 퍼셉트론 이론을 정립하고, 신경망 재부활
다층 퍼셉트론의 핵심 아이디어
1.은익층을 둔다. 은닉층은 원래 특징 공간을 분류하는 데 훨씬 유리한 새로운 특징 공간으로 변환한다.
2.시그모이드 활성함수를 도입한다. 퍼셉트론은 계단함수를 활성함수로 사용하였다. 이 함수는 경성hard 의사결정에 해당한다. 반면, 다층 퍼셉트론은 연성soft 의사결정이 가능한 시그모이드함수를 활성함수로 사용한다. 연성에서는 출력이 연속값인데, 출력을 신뢷로 간주함으로써 더 융통성 있게 의사결정을 할 수 있다.
3.오류 역전파 알고리즘을 사용한다. 다층 퍼셉트론은 여러 층이 순차적으로 이어진 구조이므로, 역방향으로 진행하면서 한 번에 한 층씩 그레이디언트를 계산하고 가중치를 갱신하는 방식의 오류 역전파 알고리즘을 사용한다.
특징공간 변환
퍼셉트론 2개를 사용한 XOR 문제의 해결
퍼셉트론1과 퍼셉트론2가 모두 +1이면 o분류이고 그렇지 않으면 x분류
퍼셉트론 2개를 병렬결합하면, 원래공간 x=(x1, x2)^T를 새로운 특징공간 z=(z1, z2)^T로 변환
다층 퍼셉트론
문제를 해결하는 데에 유리한 새로운 공간으로 만든뒤 거기에 선형 분리를 수행하는 퍼셉트론을 순차결합하면 다층 퍼셉트론이 된다.
다층 퍼셉트론의 용량
p개 퍼셉트론을 결합하면 p차원 공간으로 변환이 된다.
활성함수
딱딱한 공간 분할과 부드러운 공간 분할
계단함수는 딱딱한 의사결정 -> 영역을 점으로 변환
그외 활성함수는 부드러운 의사결정 -> 영역을 영역으로 변환
대표적인 비선형 함수인 sigmoid함수
이진 시그모이드 함수 : 0에서 1
양극 시그모이드 함수 : -1에서 1
알파 값으로 시그모이드 함수의 형태를 조절가능하다.
신경망이 사용하는 다양한 활성함수
로지스틱 시그모이드, 하이퍼볼릭 탄젠트(-1,1), 소프트플러스(0,8), 렉티파이어
일반적으로 은닉층에서 logistic sigmoid를 활성함수로 많이 사용, 깊은 신경망에서는 ReLU를 활용한다.
구조
d+1개의 입력노드 d는 특징의 개수 c개의 출력 노드
p개의 은닉 노드 p는 하이퍼 매개변수
p가 너무 크면 과잉적합, 너무 작으면 과소적합
2층 다층퍼셉트론의 매개변수(가중치)
입력 - 은닉층 - 출력
입력과 은닉을 연결하는 U1행렬(가중치u) 혹은 W1
은닉층 출력을 연결하는 U2행렬
동작
특징벡터 x를 출력벡터 o로 사상하는 함수로 간주할 수 있음
o = f(x) = f2(f1(x))
깊은 신경망은 4개이상의 층을 의미한다.
노드가 수행하는 연산
o = T(U2Th(U1X))
은닉층은 특징 추출기
은닉층은 특징 벡터를 분류에 더 유리한 새로운 특징공간으로 변환
현대 기계학습에서는 특징학습feature learning, data driven features로 부름
입력공간 - 특징공간1 - 특징공간2 - 출력공간(부류공간)
기본 구조
범용적 근사이론universal approximation theorem
하나의 은닉층은 함수의 근사를 표현
다층 퍼셉트론도 공간을 변환하는 근사함수
얕은 은닉층의 구조
지수적으로 더 넓은 폭width이 필요하게 됨
더 과잉적합 되기 쉬움
일반적으로 깊은depth 은닉층의 구조가 좋은 성능을 가짐, 공간을 재활용하며
은닉층의 깊이에 따른 이점
지수의 표현exponential representation
각 은닉층은 입력 공간을 어디서 접을지를 지정 -> 지수적으로 많은 선형적인 영역 조각들
다층 퍼셉트론에 의한 인식
다층 퍼셉트론 학습 과정
순방향 전파 : 입력층 -> 은닉층 -> 출력층 ->
역방향 전파 : 오차계산 -> 층방향 수정
정리하며
오류 역전파 : 전방 계산 대비 약 1.5~2배정도의 시간이 소요
은닉 노드가 충분히 많다면, 포화함수(활성함수)로 무엇을 사용하든 표준 다층 퍼셉트론은 어떤 함수라도 원하는 정확도만큼 근사화할 수 있다.
순수한 최적화 알고리즘으로는 높은 성능 불가능
데이터 희소성, 잡음, 미숙한 신경망 구조 등의 이유
성능 향상을 위한 다양한 경험을 개발하고 공유
아키텍처 : 은닉층과 은닉 노드의 개수를 정해야 한다. 은닉층과 은닉 노드를 늘리면 신경망의 용량은 커지는 대신, 추정할 매개변수가 많아지고 학습 과정에서 과잉적합할 가능성이 커진다. 현대 기계학습은 복잡한 모델을 사용하되, 적절한 규제 기법을 적용하는 경향이 있다.
초기값 : 보통 난수를 생성하여 설정하는데, 값의 범위와 분포가 중요하다.
학습률 : 처음부터 끝가지 같은 학습률을 사용하는 방식과 처음에는 큰 값으로 시작하고 점점 줄이는 적응적 방식이 있다.
활성함수 : 초창기 다층 퍼셉트론은 주로 로지스틱 시그모이드나 tanh 함수를 사용했는데, 은닉층의 개수를 늘림에 따라 그레이디언트 소멸과 같은 몇 가지 문제가 발생한다. 따라서 깊은 신경망은 주로 ReLu함수를 사용한다.
오류 역전파 알고리즘
은닉층을 통한 특징공간의 변환
행렬 곱 : 회전
편향 : 이동
비선형 함수 : 왜곡
목적함수의 정의
훈련집합
X Y에서 모든 샘풀을 옳게 분류하는 함수 f를 찾는 일
평균제곱 오차mean squared error
Compute Loss
Compute activations, Forward prop
Compute derrivatives, Back prop
오류 역전파 알고리즘의 설계
연산 그래프의 예
z = xy
logistic regression : y^ = s(xTw + b)
ReLU activation : H = max{0, XW + b}
linear regression
연쇄 법칙chain rule의 구현
반복되는 부분식들subexpressions을 저장하거나 재연산을 최소화
w -> x-> y -> z
Sz / Sw = Sz / Sy Sy / Sx Sx / Sw =
f'(y)f'(x)f'(w) =
f'(f(f(w)))f'(f(w))f'(w)
chain rule
끝에서부터 나오는 오류 신호가 전달되고 있다.
가중치의 값들을 각각 경사하강법으로 갱신한다.
알고리즘의 형태
U1 U2를 초기화 한다.
X의 순서를 섞는다.
전방계산으로 o를 구한다.
목적함수 J를 구한다.
U1 U2의 값을 J의 미분값으로 각각의 경사하강법으로 업데이트한다.
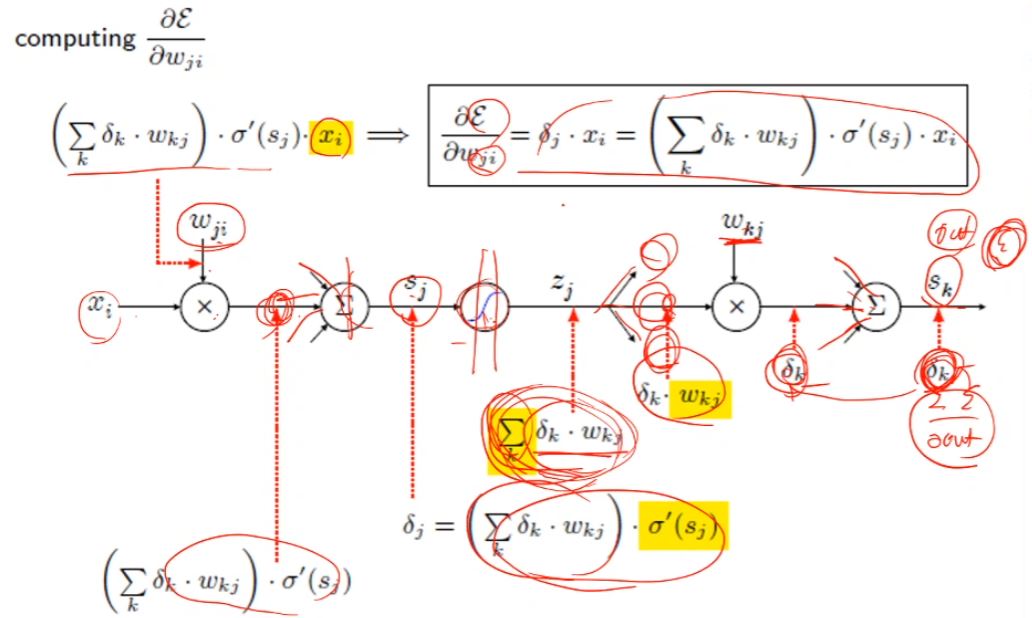
오류 역전파 알고리즘
출력의 오류를 역방향으로 전파하며 경사도를 계산하는 알고리즘, 반복되는 부분식들의 경사도의 지수적 폭발과 사라짐을 조심해야한다.
곱셉의 역전파의 예
out = in1 in2을 역전파를 구할때
sE / sin1 = sE/sout sout/sin1 =
sE/sout * in2
local gradient에는 다른 입력이 들어간다.
덧셈의 역전파의 예
out = sigma ini
sE / sini = sE/sout sout/sini =
sE/sout 1
out gradient가 각각에 전달되는 형태가 된다.
s자 모양 활성함수의 역전파의 예
out = sig(in)
sE / sin = sE/sout sout/sin =
sE/sout 0 or 1(ReLU를 사용하는 경우)
활성화 된 경우에는 미분값으로 1을 전달하고 활성화 되지 않은 경우에는 0이 된다.
실제 역전파의 예
미분
스칼라를 벡터로 미분하면 gradient
벡터를 벡터로 미분하면 jacobian
체인 룰에 의해서 스칼라(결과값)를 벡터(가중치)로 미분하는 것은 야코비안 행렬(은닉층 벡터를 가중치 벡터로 미분)과 gradient(결과값을 은닉층 벡터로 미분)의 곱으로 나타나게 된다.
