언어모델
이어질 단어나 문장이 일어날 확률을 구하는 것
기계번역machine translation
P(high winds tonight) > P(large winds tonight)
번역을 할때 단어를 번역하는 것이 아니라 문맥에 맞게 단어를 넣어줄 필요가 있다.
맞춤법 검사spell correction
The office is about fifteen minuets from my house
P(fifteen minutes from) > P(fifteen minuets from)
음성인식speech recognition
P(I saw a van) >> P(eyes awe of an)
언어모델
연속적인 단어들에 확률을 부여하는 모델
P(W) = P(w1,w2,w3,w4,w5,...,wn)
관련된 일 : 연속적인 단어들이 주어졌을 때 그 다음 단어의 확률을 구하는 것
P(wn|w1,w2,...,wn-1)
P(W), 결합확률, chain rule

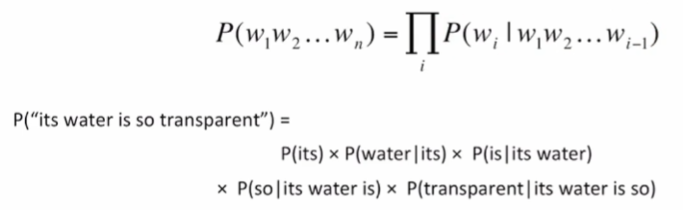
Count

Markov Assumption
한 단어의 확률은 그 단어 앞에 나타나는 몇 개의 단어들에만 의존한다
Unigram 모델
코퍼스 데이터에서 count를 통해서 문장의 생성이 가능하다.
각각의 단어가 독립적이라고 가정한다.
https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/09/16/LM/ 참고
Bigram, N-gram 모델
한 단어가 주어졌을때 그 단어 앞뒤의 단어를 참고한다.
N-gram
MLE 계산
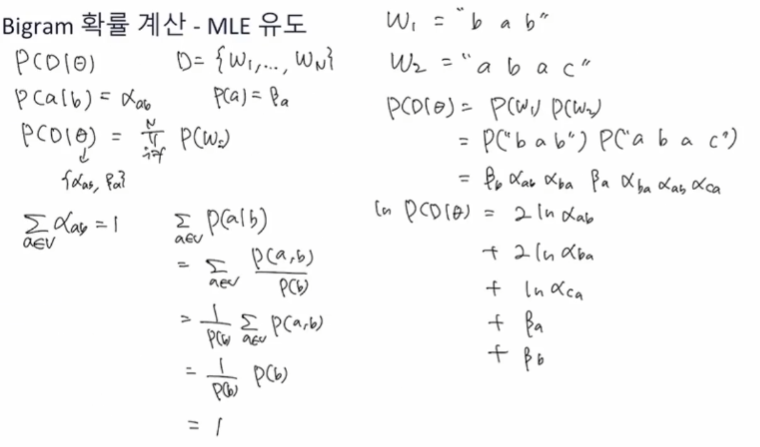
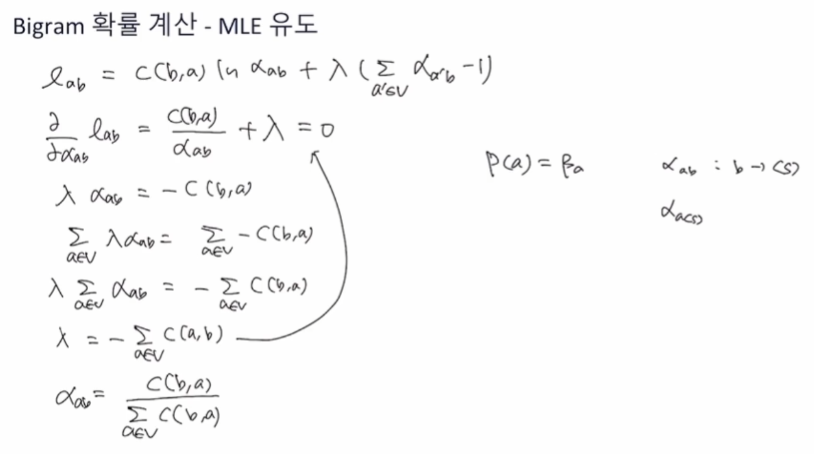
Bigram 확률계산
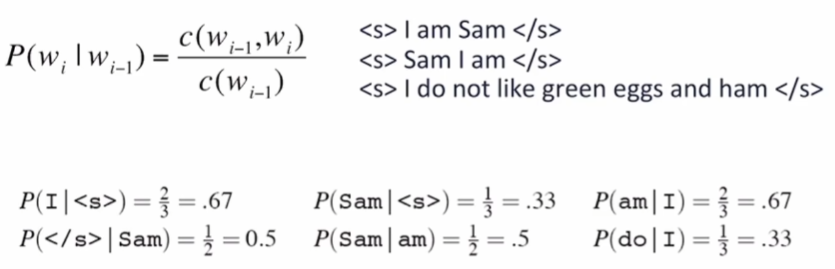
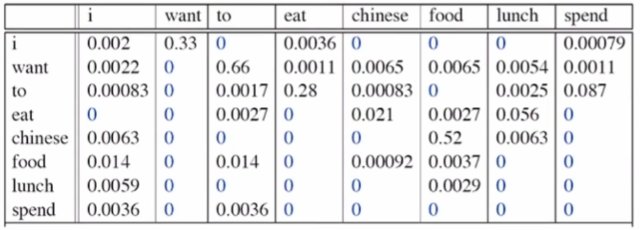
예제

외재적 평가extrinsic evaluation
언어모델은 일반적으로 그 자체가 목표이기보다 특정 과제(맞춤법 검사 등)을 위한 부분으로서 쓰여지게 된다.
따라서 언어모델이 좋은지 판단하기 위해서는 그 과제의 평가지표를 사용하는 경우가 많다.
예를 들어, 맞춤법 검사를 위해서 두 개의 언어모델 A, B를 사용한다고 할 때
1.각 모델을 사용해서 얼마나 정확하게 맞춤법 오류를 수정할 수 있는지 계산한다.
2.정확도가 높은 언어모델을 최종적으로 사용한다.
내재적 평가intrinsic evaluation
외재적 평가는 시간이 많이 걸리는 단점이 있다.
언어모델이 학습하는 확률자체를 평가할 수 있다.(Perplexity)
이 기준으로 최적의 언어모델이 최종 과제를 위해서는 최적이 아닐 수도 있다.
하지만 언어모델의 학습과정에 버그가 있었는지 빨리 확인하는 용도로 사용할 수 있다.
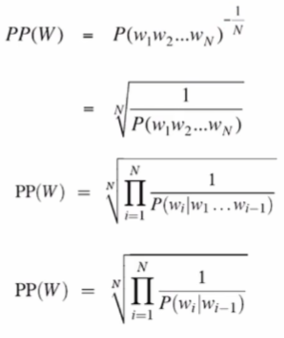
Perplexity
테스트 데이터를 높은 확률로 예측하는 모델
perplexity : 확률의 역수를 단어의 개수로 정규화한 값
perplexity를 최소화 하는 것이 확률을 최대화 하는 것