10강.확률적 경사 하강법Stochastic Gradient Descent
predict : decision function, z값
predict_proba : sigmoid값
target은 scikit-learn에서 str이어도 자동으로 처리한다.
점진적 학습, 온라인 학습
w, b를 유지, 업데이트하는 방법
이를 사용하는 방법 중 하나가 확률적 경사하강법이다. 이는 ML, DL을 훈련, 최적화 하는 방법이지 로지스틱과 같은 알고리즘은 아니다.
확률적 경사 하강법
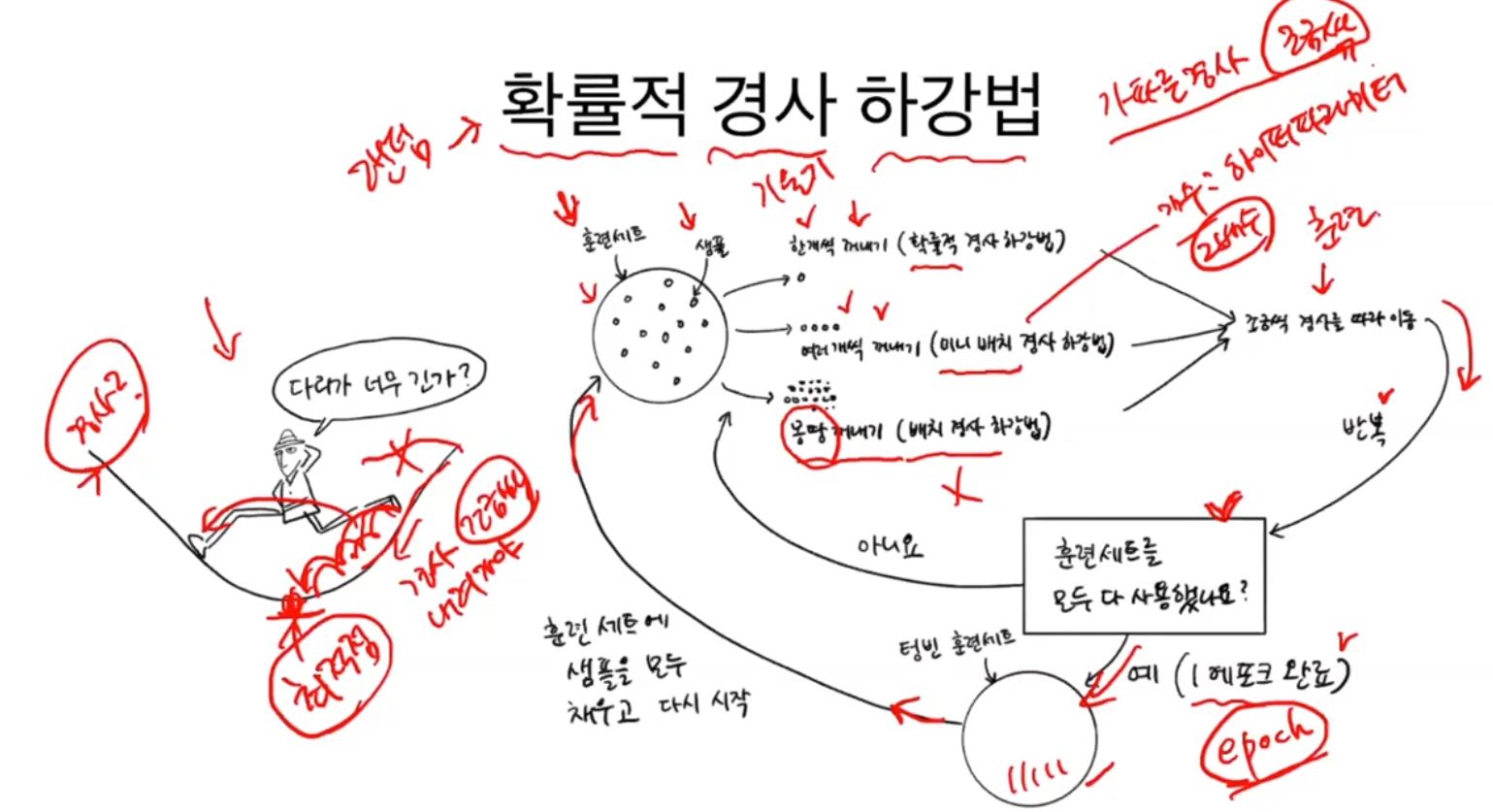
손실함수
머신러닝 알고리즘이 얼마나 나쁜지를 측정하는 함수, 다만 손실함수의 형태는 연속함수여야만 한다. 미분가능해야하기 때문이다.
로지스틱 손실함수, 이진 크로스 엔트로피 손실함수
회귀의 문제는 평균 절대값 오차, 평균 제곱 오차MSE를 사용가능하다.
분류의 경우는 정확도로 모델의 성능을 측정한다. 하지만 이는 미분을 할 수가 없기 때문에 최적화를 로지스틱 손실 함수를 사용한다.
이진분류의 경우에 타깃이 맞을경우 -log(예측확률), 타깃이 아닐경우 -log(1-예측확률)로 계산한다. 1의 로그 값은 0이므로 예측이 답에 가까울수록 0에 가까운 값이 나오게 된다.
데이터 전처리
import pandas as pd
fish = pd.read_csv()
fish_input = fish[['Weight','Length','Diagonal','Height','Width']].to_numpy()
fish_target = fish['Species'].to_numpy()
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_input, fish_target, random_state=42)
from sklearn,preprocessing import StandardScaler
ss= StandardScaler() #평균과 표준편차를 계산
ss.fit(train_input)
train_scaled = ss.transform(train_input)
train_sclaed = ss.transform(test_input)SGDClassifier(회귀는SGDRegressor)
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log', max_iter=10, random_state=42)
# loss=log로 로지스틱 손실 함수를 사용해서 최적화를 한다.
# max_iter는 에포크와 동일
sc.fit(train_scaled, train_target)
# 확률적이기 때문에 배치나 미니배치와는 다르게
# 부분적으로 샘플을 사용한다.
# 과소적합의 상태이다.
print(sc.score(train_scaled, train_target)) # 0.7731
print(sc.score(test_scaled, test_target)) # 0.775
# 점진적인 학습이 가능하다.
# 앞에서는 10에포크 였으니 좀더 한다.
# w, b를 그대로 사용한다.
# 만약에 fit을 쓰면 w, b를 새로 구한다.
sc.partial_fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target)) # 0.815
print(sc.score(test_scaled, test_target)) # 0.825에포크도 규제화의 하이퍼 파라미터와 마찬가지로 지나치면 과대적합으로 모자라면 과소적합으로 나타난다.
조기종료 early stopping
sc = SGDClassifier(loss='log', random_state=42)
train_score = []
test_score = []
classes = np.unique(train_target)
for _ in range(0,300):
sc.partial_fit(train_scaled, train_target, classes=classes)
# partial_fit은 데이터가 일부분만 전달될 수 있다고 가정하기 때문에
#전체 class의 갯수를 전달해주어야 한다.
train_score.append(sc.score(train_scaled, train_target))
test_score.append(sc.score(test_scaled, test_target))
sc = SGDClassifier(loss='log', max_iter=100, tol=None, random_state=42)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target)) # 0.9579
print(sc.score(test_scaled, test_target)) # 0.925
11강.로지스틱 회귀로 와인 분류하기 & 결정 트리
알코올, 당도, ph로 레드, 화이트 와인(label=1)을 구분
로지스틱 회귀
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_scaled, train_target)
print(lr.score(t_s, t_t)) # 0.7808
print(lr.score(te_s, te_t)) # 0.7769
print(lr.coef_, lr.intercept_)
[[0.512 1.673 -0.6876]][1.8177]Alchol, Ph, Sugar에 곱해진 가중치가 어떤 의미인지를 분석하기는 어렵다.
결정트리
당도가 2보다 작은가요? 예 -> 레드, 아니오 -> 화이트, 20고개의 질문
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target)) # 0.9969
print(dt.score(test_scaled, test_target)) # 0.8592
import matplotlib.pyplot as plt
from sklear.tree import plot_tree
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()결정트리 분석
plt.figure(figsize=(10,7))
plot_tree(dt, max_depth=1, filled=True, feature_names=['alchol','sugar','pH'])
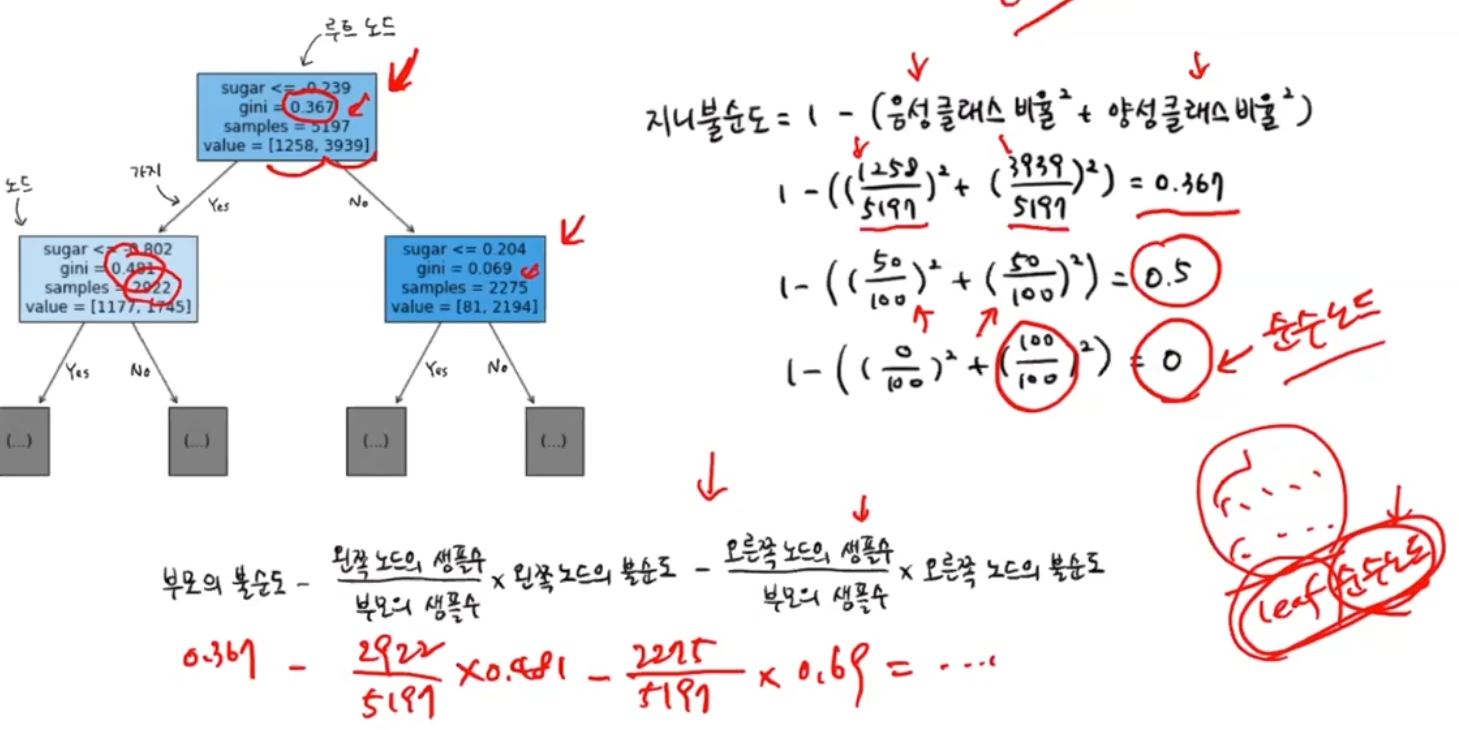
plt.show()gini 불순도
gini가 0이면 순수노드 0.5에 가까워지면 불순도가 높은 노드이다. leaf 노드는 순수노드들이다.
부모노드와 자식노드간의 불순도의 차이를 계산을해서 불순도가 좀더 크게 분할을해나가게 된다.
제한하지 않으면 너무 많은 트리가 생기기 때문에 overfitting의 문제가 생긴다.
가지치기pruning
가장 간단한 방법은 max_depth를 사용하는 것이다.
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(t_s, t_t)) # 0.8454
print(dt.score(te_s, te_t)) # 0.8415스케일 조정하지 않은 특성 사용하기
결정트리는 스케일을 조정하지 않아도 사용이 가능하다. 전처리가 필요 없다. standardscale을 사용하지 않아도 점수가 동일하다.
print(dt.feature_importances_)
# [0.1234 0.8686 0.0079]트리는 앙상블 모델을 만들 수 있기 때문에 중요한 의미를 가진다.
12강.교차 검증과 그리드 서치
검증세트
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
sub_input, val_input, sub_target, val_target = train_test_split(train_input, train_target, test_size=0.2, random_state=42)교차검증
from sklearn.model_selection import cross_validate
scores = cross_validate(dt, train_input, train_target)
print(scores)
{'fit_time' : array([0.007, 0.006, 0.007, 0.007, 0.006]),
'score_time : array([0.00077, 0.00055, 0.00057, 0.00052, 0.00059]),
'test_score' : array([0.86, 0.84, 0.87, 0.84, 0.83])
}
import numpy as np
print(np.mean(scores['test_score'])) # 0.85DL에서는 검증세트와 훈련세트를 한번만 나누어서 사용하거나, gridsearch를 사용한다. 데이터가 이미 풍부하며, 한번의 검증에 많은 자원이 필요하기 때문이다.
ML에서는 교차검증을 사용한다.
분할기splitter를 사용한 교차검증
from sklearn.model_selection import StratifiedKFold
# 회귀는 KFold 분류는 StratifiedKFold
scores = cross_validate(dt, train_input, train_target, cv=StratifiedKFold())
print(np.mean(scores['test_score'])) # 0.855
# 10개의 fold를 shuffle해서 쓴다
splitter = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)
scores = cross_validate(dt, train_input, train_target, cv=splitter)
print(np.mean(scores['test_score'])) # 0.857그리드 서치
from sklearn.model_selection import GridSearchCV
# 매개변수는 서로 영향을 주고 받기 때문에
# 최적의 결과를 찾기 위해서는
# 한꺼번에 여러 매개변수를 주고 찾아야 한다.
# impurity_decrease는 불순도의 차이이다.
# min을 줌으로써 이정도도 안되는 모델은 찾지말라는 뜻이다.
params = {'min_impurity_decrease':[0.0001, 0.0002, 0.0003, 0.0004, 0.0005]}
gs= GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1) # n_jobs로 cpu사용률을 정함
gs.fit(train_input, train_target)
dt = gs.best_estimator_
print(dt.score(train_input, train_target)) #0.9615
print(gs.best_params_) # {'min_impurity_decrese' : 0.0001}
print(gs.cv_results_['mean_test_score'])
[0.8681 0.8645 0.8649 0.8678 0.8678]
# 파라미터를 다양하게
# 9x15x10x5개의 모델을 사용한다.
params = {'min_impurity_decrese' : np.arange(0.0001, 0.001, 0.0001),
'max_depth' : range(5,20,1),
'min_samples_split' : range(2,100,10)}확률 분포 선택
grid search는 특정 범위에서 촘촘하게 탐색을 하기 때문에 잘 모르는 경우 범위를 크게 주고 그 안에서 랜덤서치를 하는게 더 유리할 수도 있다.
from scipy.stats import uniform, randint
rgen = randint(0,10)
rgen.rvs(10)
array([9,2,1,8,6,4,5,6,2,6])
np.unique(rgen.rvs(1000), return_counts=True)
(array([0,1,2,3,4,5,6,7,8,9]),
array([95,90,90,115,97,96,108,101,113,95]))
ugen=uniform(0,1)
ugen.rvs(10)
#0에서 1사이의 실수값 10개가 나온다.
array([])랜덤 서치random search
params = {'min_impurity_decrese' : uniform(0.0001, 0.001),
'max_depth' : randint(20,50),
'min_samples_split' : randint(2,25),
'min_samples_leaf' : randint(1,25),
}
from sklearn.model_selection import RandomizedSearchCV
gs= RandomizedSearchCV(DecisionTreeClassifier(random_state=42), params, n_iter=100, n_jobs=-1, random_state=42)
gs.fit(train_input, train_target)
print(gs.best_params_)
{'max_depth':39, 'min_impurity_decrese' : 0.0003410, ...}
print(np.max(gs.cv_results_['mena_test_score'])) # 0.8695
dt= gs.best_estimator_
print(dt.score(test_input, test_target)) # 0.86
