심층 신경망
층과 모델이 분리되어 관리된다.
2개의 층이라고 하면 입력층(입력값을 펼친 1차배열), 은닉층(뉴런 개수는 정하는대로), 출력층(클래스의 개수)을 의미한다.
은닉층에는 활성화 함수가 적용되어서 출력층으로 넘겨주어야 한다. 값들을 바꿔주지 않으면 선형계산의 나열이 되기 때문에 층을 나누는 의미가 없어진다.
간단한 심층 신경망 만들어보기
dense1 = keras.layers.Dense(100, activation='sigmoid', input_shape=(784,))
dense2 = keras.layers.Dense(10, activation='softmax')model = keras.Sequential([dense1, dense2])
model.summary()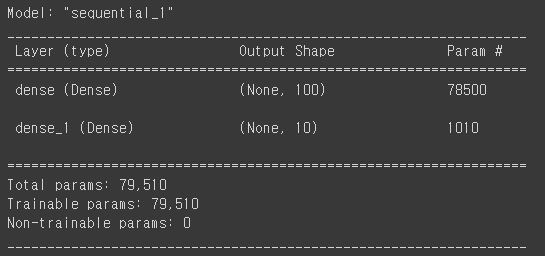
ouput shape의 인풋은 fit method에서 batchsize의 값(32, 64, 128)에 해당한다.
param은 매개변수의 개수를 의미한다.
은닉층에서는 784개의 인풋뉴런이 100개의 뉴런과 완전연결되어 있기 때문에 784x100인데 각 뉴런에는 절편이 하나씩 있기 때문에 78500이 된다.
층을 만드는 2가지 방법
model = keras.Sequential([
keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'),
keras.layers.Dense(10, activation='softmax', name='output')
], name='MNIST')model = keras.Sequential()
model.add(keras.layers.Dense(100, activation='sigmoid', input_shape=(784,)))
model.add(keras.layers.Dense(10, activation='softmax'))모델 훈련
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)ReLU함수와 Flatten 층
sigmoid함수는 선형출력 값이 너무 커지거나 작아질 경우 함수 값의 변화가 매우 작아진다. 따라서 신경망 모델이 빠르게 대응하기가 어려워지게 된다.
ReLU함수 max함수이다. 0보다 크면 그대로 출력하고 0보다 작으면 버린다.
flatten층은 입력값을 1차원 배열로 만들어 준다.
summary에서 인풋 뉴런의 개수를 바로 확인할 수 있다.
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(784,)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()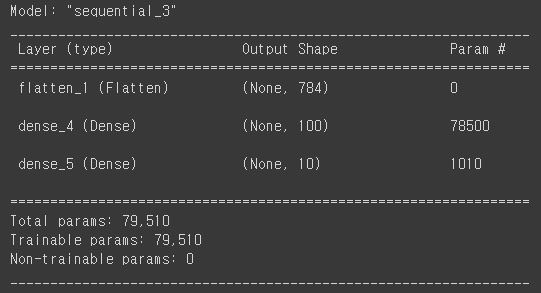
옵티마이저
확률적 경사하강법의 발전은
기본 경사 하강법 옵티마이저 :
SGD, learning-rate=0.01
momentum
nesterov
적응적 학습률 옵티마이저 :
RMSprop
Adam
Adagrad
사용법
# 파라미터를 기본으로
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics='accuracy')
# 파라미터를 바꾸고 싶을때
sgd = keras.optimizers.SGD()
model.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics='accuracy')
sgd = keras.optimizers.SGD(learning_rate=0.1)
sgd = keras.optimizers.SGD(momentum=0.9, nesterov=True)model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)손실곡선 그리기
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=5, verbose=0)
print(history.history.keys())
# dict_keys(['loss', 'accuracy'])plt.plot(history.history['loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()loss 곡선
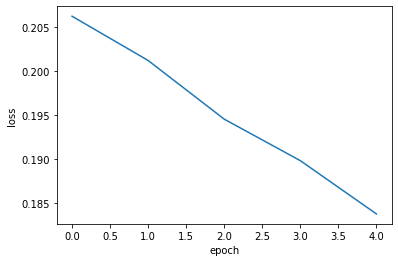
plt.plot(history.history['accuracy'])
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()검증 손실
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))
print(history.history.keys())
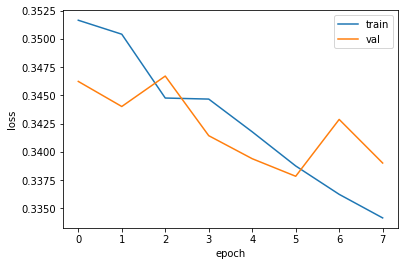
# dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()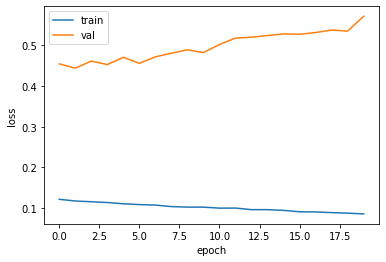
val에서 과대적합이 발생한다.
드롭 아웃
은닉층에 있는 임의의 뉴런의 계산을 끈다. 개수는 지정이 가능하다. 과대적합과 특정 뉴런에의 의존도를 낮추는 역할을 한다.
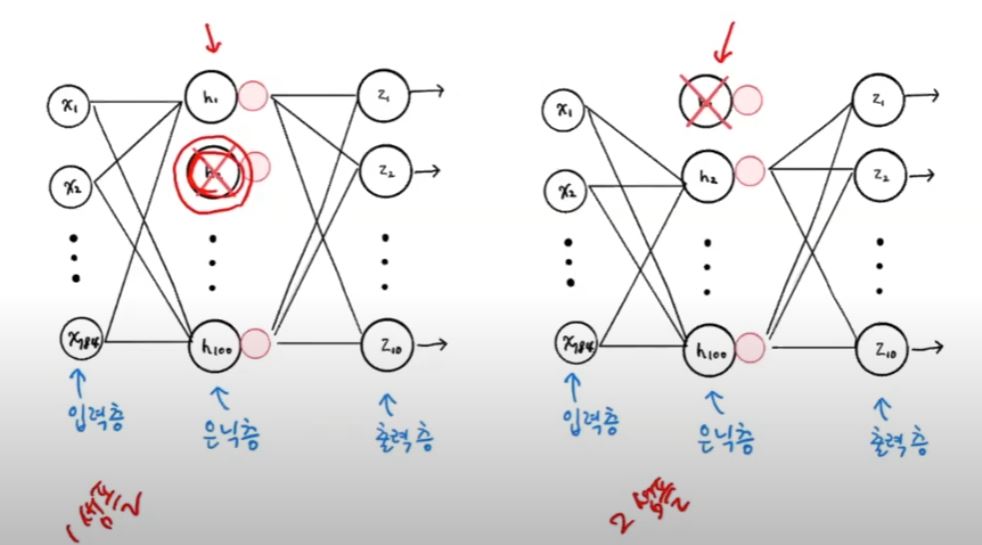
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(784,)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dropout(0.3))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()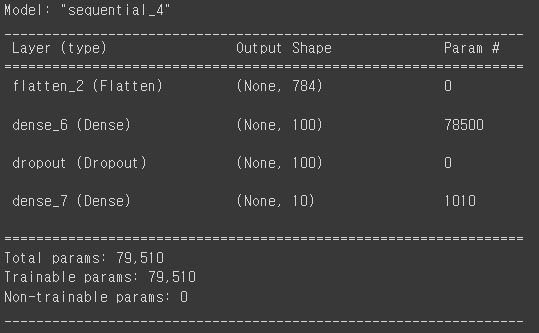
모델의 저장과 복원
2가지 방법이 있다.
model.save_weights('model-weights.h5')
model.load_weights('model-weights.h5')
model.save('model-weights.h5')
model = keras.models.load_model('model-weights.h5')평가하기 accuracy
# axis -1은 가장 마지막 axis값이 된다.
val_labels = np.argmax(model.predict(val_scaled), axis=-1)
print(np.mean(val_labels == val_target))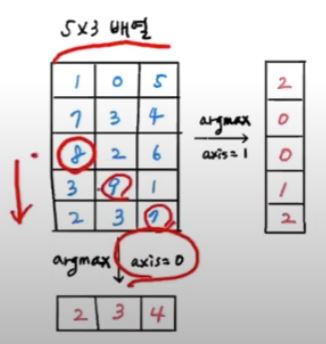
콜백
모델을 훈련하는 도중 지정한 작업을 수행한다. 가장 낮은 손실값이 되는 모델의 가중치를 저장해준다. 저장해둔걸 복원해서 쓰면 된다.
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-model.h5')
model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target), callbacks=[checkpoint_cb])
model = keras.models.load_model('best-model.h5')조기종료
epoch가 검증세트 손실이 증가하기 시작하는 순간부터는 더이상 훈련을 할 필요가 없게된다.
patience는 몇번 봐줄 것인가하는 매개변수이며,
restore True는 최고값인 때로 되돌리는 매개변수이다.
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-model.h5')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2, restore_best_weights=True)
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target), callbacks=[checkpoint_cb, early_stopping_cb])
model = keras.models.load_model('best-model.h5')
print(early_stopping_cb.stopped_epoch)plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()