서론
클린 아키텍처의 저자인 로버트 C.마틴에 따르면,
SOLID 원칙은 함수와 데이터 구조를 클래스로 배치하는 방법
그리고 이들 클래스를 서로 결합하는 방법을 설명해준다고 한다.
그래서인지 구글에 SOLID를 검색해보면 다들 객체 지향 원칙이라고 표현한다.
그러나 여기서 객체 혹은 클래스는 객체 지향 언어의 클래스만을 얘기하는 것은 아니다.
SOLID에서의 클래스는 단순히 함수와 데이터를 결합한 집합을 일컫는다.
객체 지향 프로그래밍 - 핵심은 의존성 역전에서 다뤘던 것처럼, 객체 지향 언어들은 객체를 지향하는 것을 도와줄 뿐이다.
사실은 모든 소프트웨어에서 '객체를 지향'할 수 있다.
그러므로 나는 클래스를 함수와 데이터를 결합한 집합이라고 정의하는 것이 옳다고 생각한다.
암튼, SOLID 원칙이 어떤 건지 알아보자.
SOLID 란?
SOLID원칙은 다음 5가지 원칙의 앞글자를 따서 만든 단어다.
- SRP(Single Responsibility Principle) : 단일 책임 원칙
- OCP(Open-Closed Principle) : 개방-폐쇄 원칙
- LSP(Liskov Substituion Principle) : 리스코프 치환 원칙
- ISP(Interface Segregation Principle) : 인터페이스 분리 원칙
- DIP(Dependency Inversion Principle) : 의존성 역전 원칙
이렇게 나열하면 마치 수학 정리들을 모아둔 것 같다.
아마 많은 사람들이 SOLID가 뭔지 찾아보다가 원칙들의 이름을 보고 뒤로가기를 눌렀을 수도 있다.
이제 각 원칙들이 무슨 의미인지 최대한 명확하고 쉽게 알아보자.
SRP : 단일 책임 원칙
하나의 모듈은 하나의, 오직 하나의 액터에 대해서만 책임진다.
여기서 모듈은 클래스 혹은 메서드 수준의 모듈이다.
여기서 액터(actor)란 시스템을 변경하길 원하는 사용자나 이해관계자 집단이다.
이게 무슨 말일까?
마틴이 좋아하는 SRP 위반 사례를 살펴보자.
위반 사례
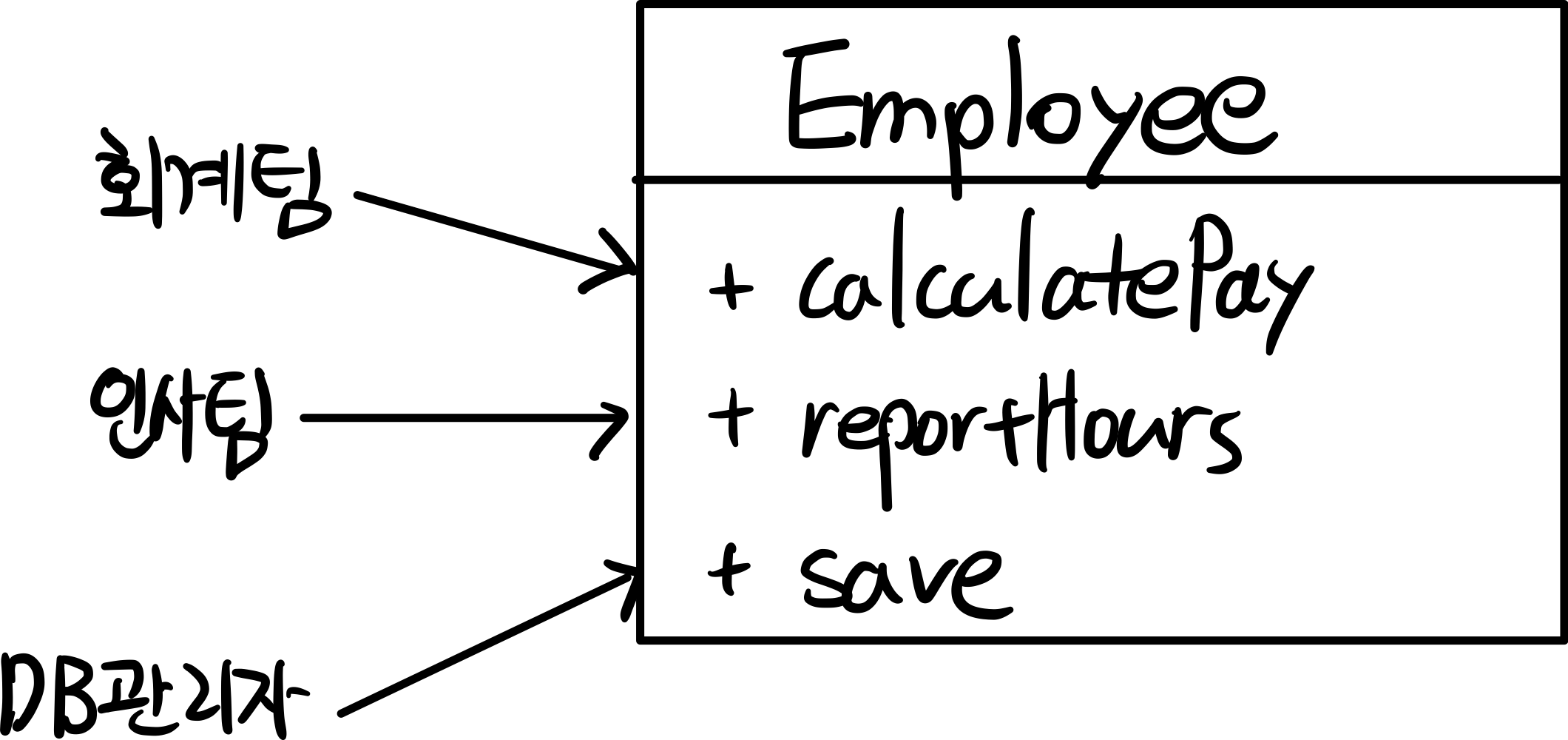
급여 애플리케이션의 Employee 클래스가 있다.
이 클래스는 사원의 데이터와 세 가지 메서드를 가진다.
- calculatePay() : 회계팀에서 급여를 계산하기 위해 사용
- reportHours() : 인사팀에서 근무시간을 계산하기 위해 사용
- save() : 데이터베이스 관리를 위해 사용
이 클래스가 SRP를 위반하는 이유는 3가지 다른 액터가 이 클래스를 변경할 수 있기 때문이다.
이로 인해, 한 액터가 만든 수정사항이, 다른 액터들에 영향을 끼칠 수 있다.
예를 들어, calculatePay()와 reportHours()가 초과 근무를 제외한 정규 업무 시간을 계산하는 알고리즘을 공유한다고 가정하자.
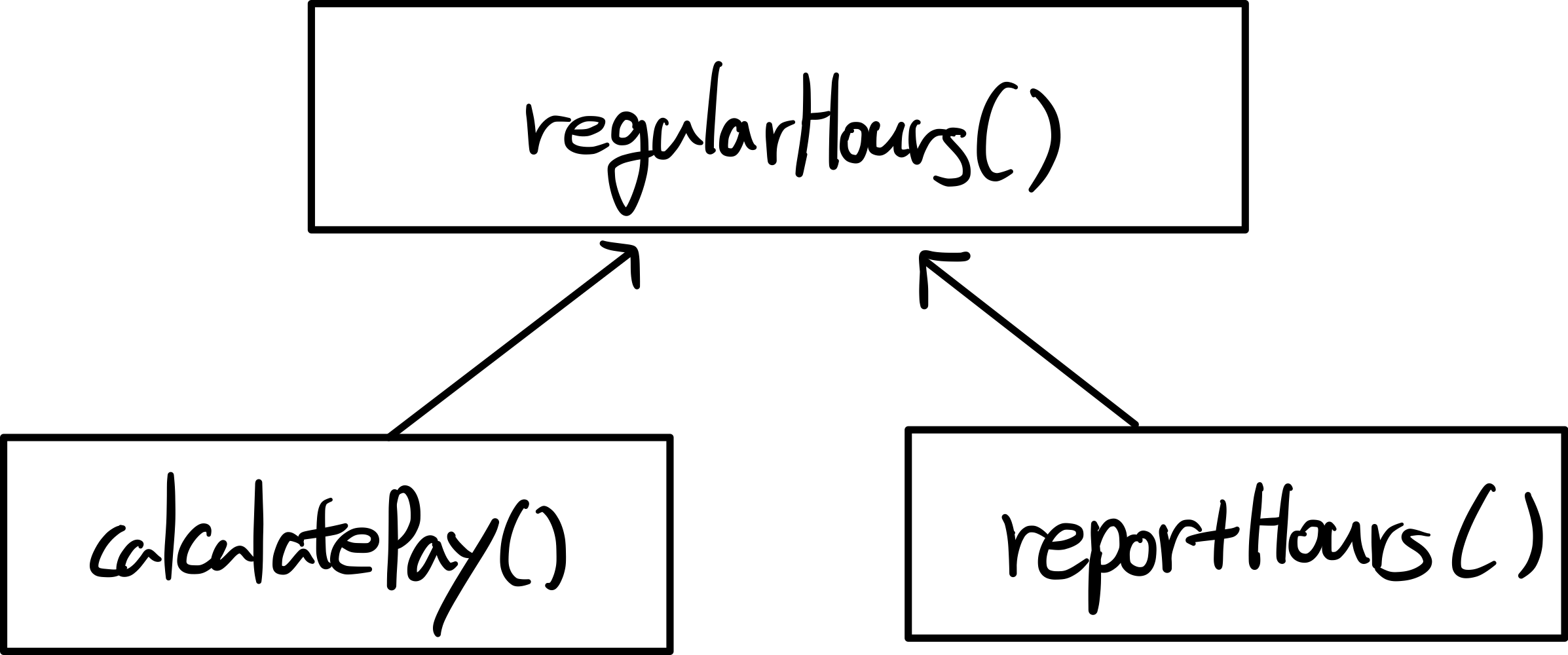
개발자는 코드 중복을 피하기 위해 regularHours()로 구현했다.
어느 날, 회계팀에서 정규 업무 시간을 계산하는 방식을 수정하기로 한다.
반면 인사팀에서는 정규 업무 시간을 다른 방식으로 회계팀과는 다른 목적으로 사용하기 때문에 변경을 원치 않는다.
회계팀에 요청을 받은 개발자는 calculatePay()가 regularHours()를 호출한다는 사실을 발견하지만,
안타깝게도 reportHours()에서도 호출한다는 사실은 모른다...
개발자는 요청된 변경사항을 적용하고 신중하게 테스트 한후 배포된다.
회계팀에서 열심히 수정하는 동안 인사팀은 이 사실을 모르고 있다.
인사팀 직원은 여전히 reportHours()가 생성한 보고서를 이용한다..
시간이 한참 흐른 후, 문제가 발견되었고 COO는 격노한다.
잘못한 데이터로 인해 수백만 달러의 예산이 지출되었다.
그럼 어떻게 해야할까?
해결책
가장 확실한 해결책은 데이터와 메서드를 분리하는 것이다.
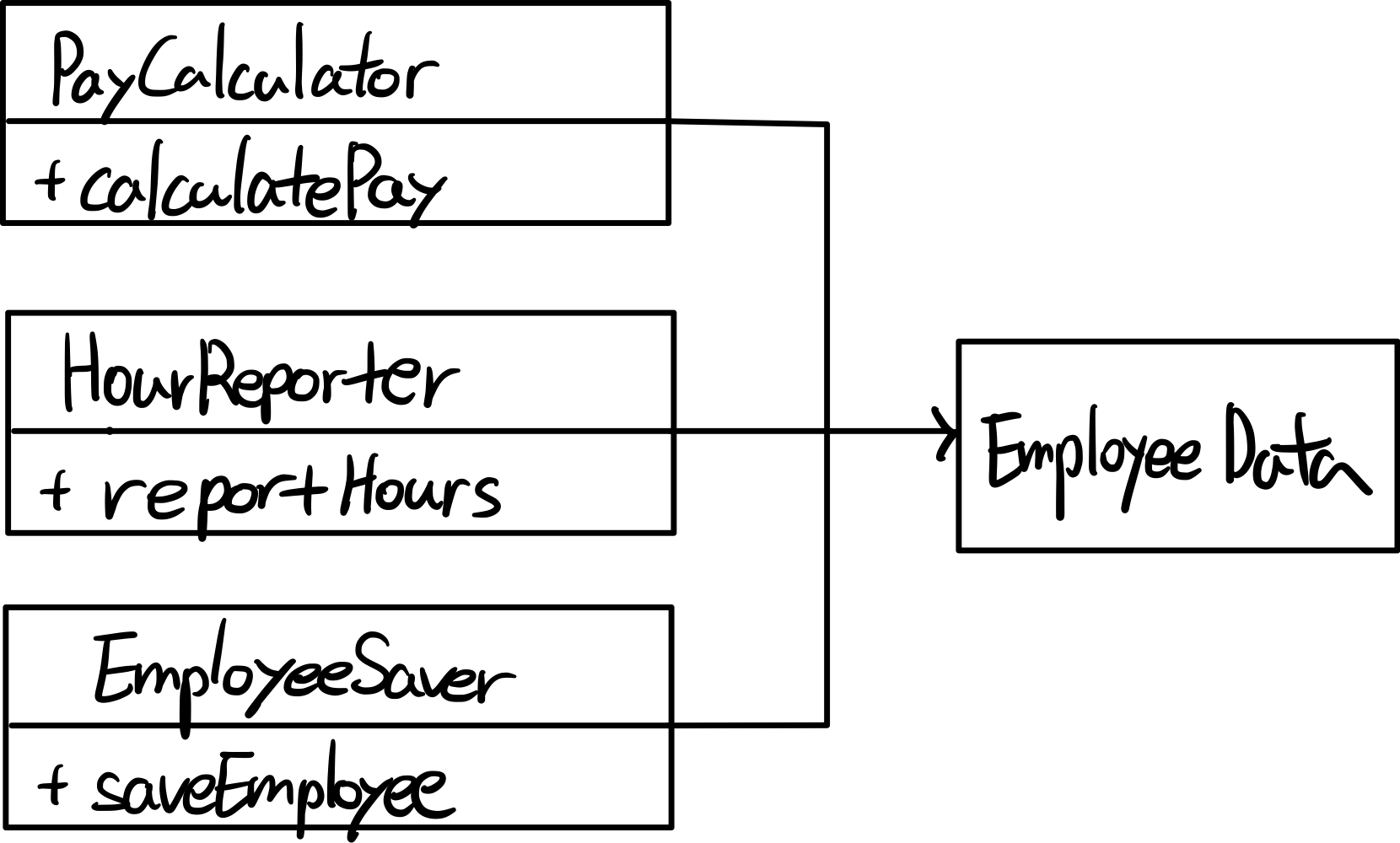
이제 각 액터는 본인들만의 클래스가 생겼다.
이제 한 액터의 수정사항은 다른 액터들에 영향을 끼치지 않는다.
만약 공동으로 사용하는 부분 (Employee Data 혹은 regularHours()를 위한 클래스도 새로 만든다면)을
수정할 일이 생겼을 때도, 다른 액터들에 영향을 미친다는 사실을 바로 알 수 있다.
이제 '액터'와 '책임'의 의미가 무엇인지 체감이 된다.
SRP는 서로 다른 액터가 의존하는 코드를 서로 분리하라는 원칙이다.
온갖 원칙 / 법칙들은 첨엔 무슨 소린가 싶다가도 이해하고 나면, 너무 명확하고 당연한 것 같아진다.
다른 원칙들도 계속해서 알아보자.
OCP : 개방-폐쇄 원칙
소프트웨어 엔티티(클래스, 모듈, 함수, 등)는 확장에는 열려있고 변경에는 닫혀있어야 한다.
이게 무슨 말이야?
뭔가를 확장하려면 코드를 수정해야하는거 아니야?
라는 생각이 제일 먼저 들 수 있다.
다시 말하자면, 어떤 것을 추가하더라도 기존의 기능을 수행하는 코드는 최소한으로 변경해야한다는 것이다.
이번에도 책의 예제를 살펴보자.
OCP 예시
재무제표를 웹 페이지로 보여주는 시스템이 있다.
어느 날, 이해관계자가 동일한 재무제표 정보를 보고서 형태로 변환해서 흑백 프린터로 출력하는 기능이 필요하다고 한다.
-> 확장의 시간이다.
이상적인 코드 변경의 양은 0이다.
기존의 시스템을 이루는 코드는 변경되지 않고 흑백 프린터 출력 용 코드만 추가하는 것이 가장 이상적이다.
어떻게 할 수 있을까?
서로 다른 목적으로 변경되는 요소를 적절하게 분리(= SRP) 하고
요소 사이의 의존성을 체계화(= DIP)함으로써 변경량을 최소화할 수 있다.
SRP적용
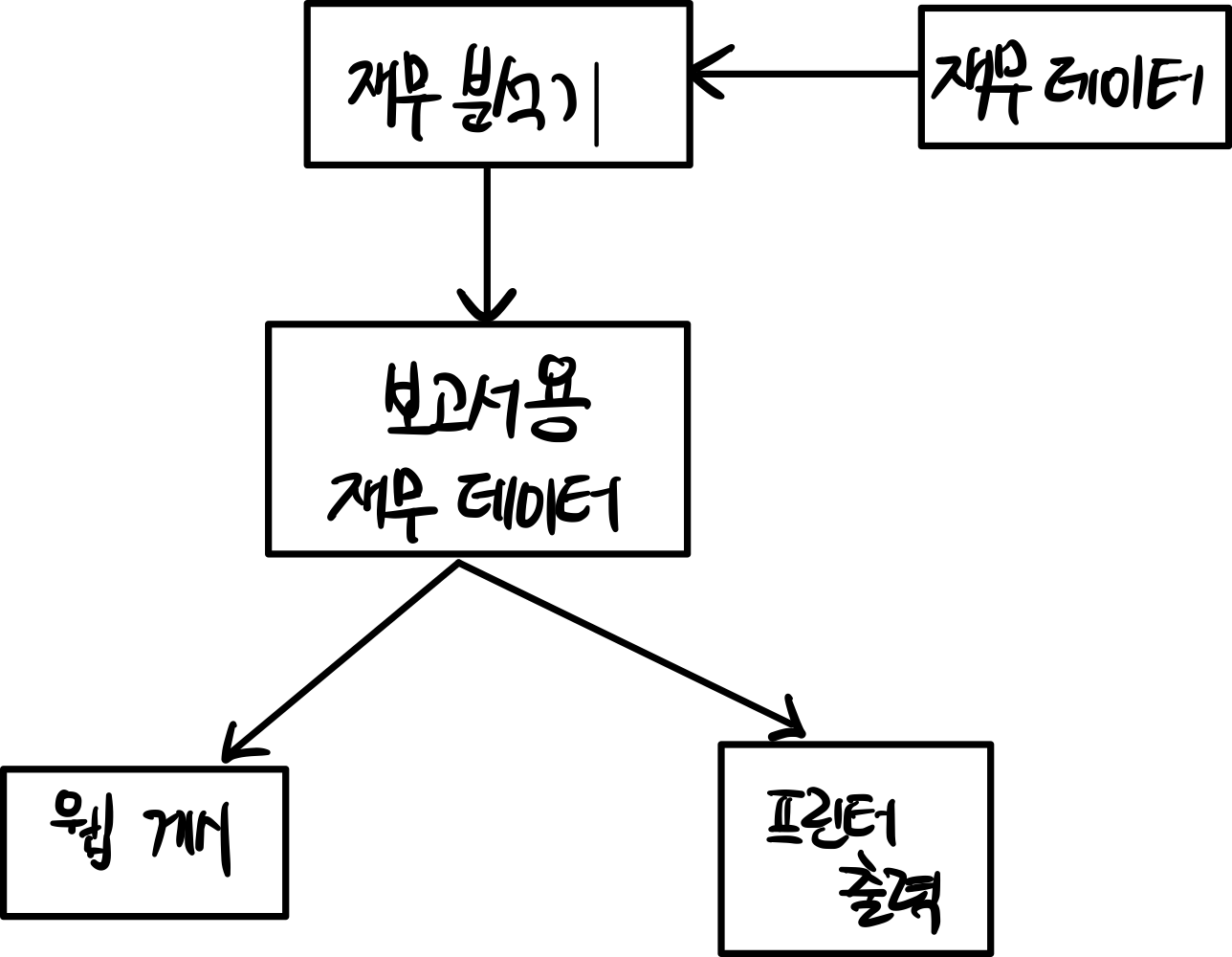
SRP를 적용한 데이터 흐름이다.
보고서를 보여주는 방법에 대한 책임이 웹과 프린터 두 갈래로 나뉘는 것을 볼 수 있다.
책임을 분리했다면, 한 책임에서의 변경이 다른 책임에 영향을 끼치지 않도록 의존성을 체계화해야한다.
의존성 체계화
처리 과정을 클래스 단위로 분할하고, 클래스를 컴포넌트 단위로 묶는다.
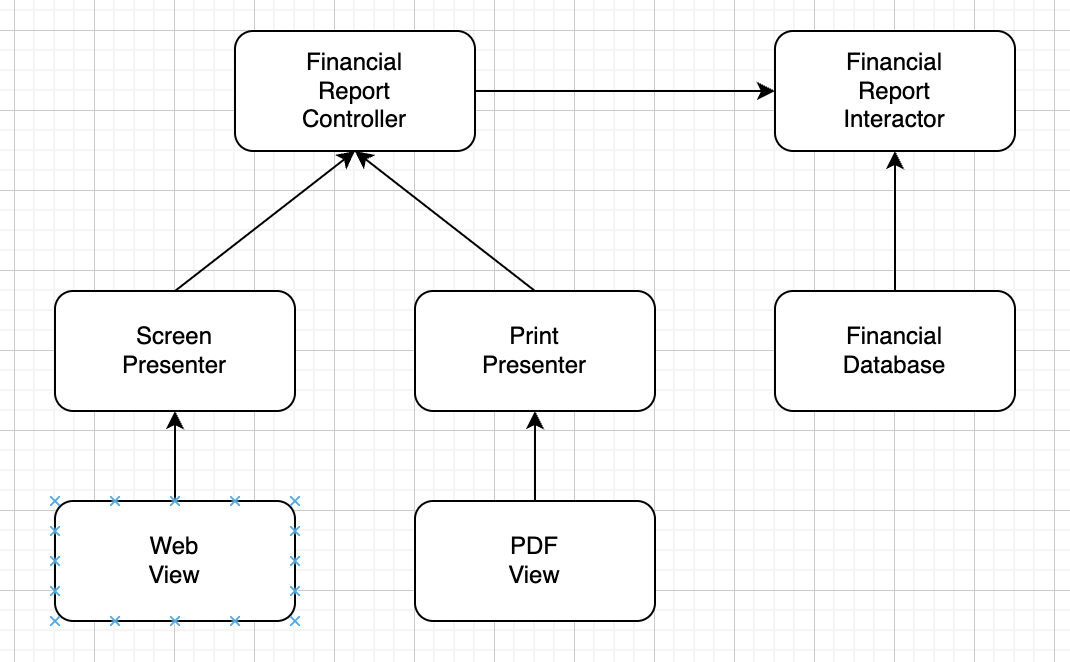
클래스까지 넣으면 너무 복잡해져서 컴포넌트 단위로만 표현했다.
화살표는 의존성의 방향이다.
- 모든 컴포넌트 의존성 관계는 단방향으로 이루어진다.
- 의존성 관계는 보호하려는 컴포넌트를 향한다.
A 컴포넌트에서 발생한 변경으로부터 B 컴포너트를 보호하려면 A가 B에 의존해야한다.
위 다이어그램을 보면
View로 부터 Presenter를 보호하고
Presenter로 부터 Controller를 보호하고
Controller, Database 로 부터 Interactor를 보호한다.
Interactor 컴포넌트는 아무 것도 의존하지 않는다.
Database, Controller, Presenter, View에서 발생한 어떤 변경도 interactor에 영향을 주지 않는다.
Interactor는 OCP를 가장 잘 준수할 수 있다.
Interactor를 이렇게 보호하는 이유는
가장 높은 수준의 정책을 가지고 있기 때문이다.
이렇게 컴포넌트의 '수준에'따라 보호의 계층구조를 형성한다.
높은 수준일 수록 보호를 받고 낮은 수준일 수록 보호받지 못한다.
이것이 아키텍처 수준에서 OCP가 적용되는 방식이다.
아키텍트는 기능이 어떻게, 왜, 언제 발생하는지에 따라 기능을 분리하고,
컴포넌트의 계층구조로 조직화한다.
-> 저수준 컴포넌트에서 발생한 변경으로부터 고수준 컴포넌트를 보호할 수 있다.
LSP : 리스코프 치환 원칙
리스코프는 subtype을 다음과 같이 정의했다.
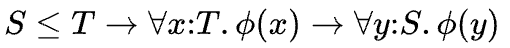
T의 객체인 x에 대해 Φ(x)가 증명가능한 특성일 때, T의 하위타입인 S의 객체 y에 대해서 Φ(y)도 참이다.
내가 수학을 배우는건가 싶지만, 사실 어려운 개념은 아니다.
쉽게 말하면, S가 T의 하위타입일때, T의 객체에 적용되는 것은 S의 객체에도 적용된다는 것이다.
이 정의를 따르면, 리스코프 치환 원칙이 드러난다.
T를 이용해서 정의한 모든 프로그램 P에서 x의 자리에 y를 치환하더라도 P의 행위가 변하지 않는다.
음.. 대충 감이 오는 것 같다.
예제를 통해 자세히 알아보자.
LSP를 준수하는 경우
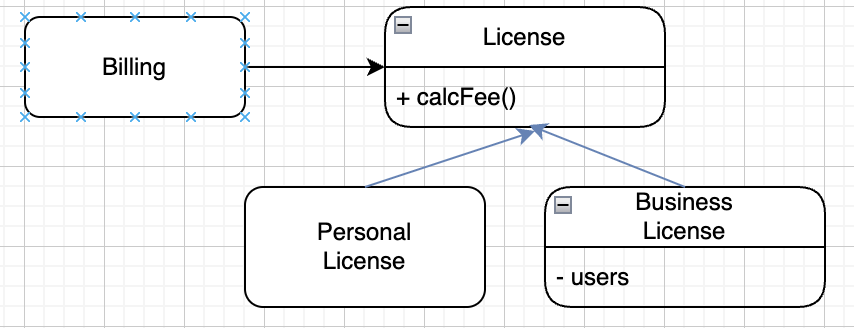
(여기서는 파란 화살표가 상속 관계, 검은 화살표는 사용관계)
Billing 프로그램은 License 클래스에서 calcFee() 메서드를 사용한다.
Personal License와 BusinessLicense는 License를 상속하는 하위타입이다.
이 두 클래스는 서로 다른 알고리즘을 이용해서 라이선스 비용을 계산한다.
Billing 플고그램의 행위가 둘 중 어느 타입을 사용하는지에 전혀 의존하지 않기 때문에,
두 클래스의 객체는 모두 License 타입의 객체를 치환할 수 있다.
정사각형/직사각형 문제
LSP를 위반하는 대표적인 문제이다.
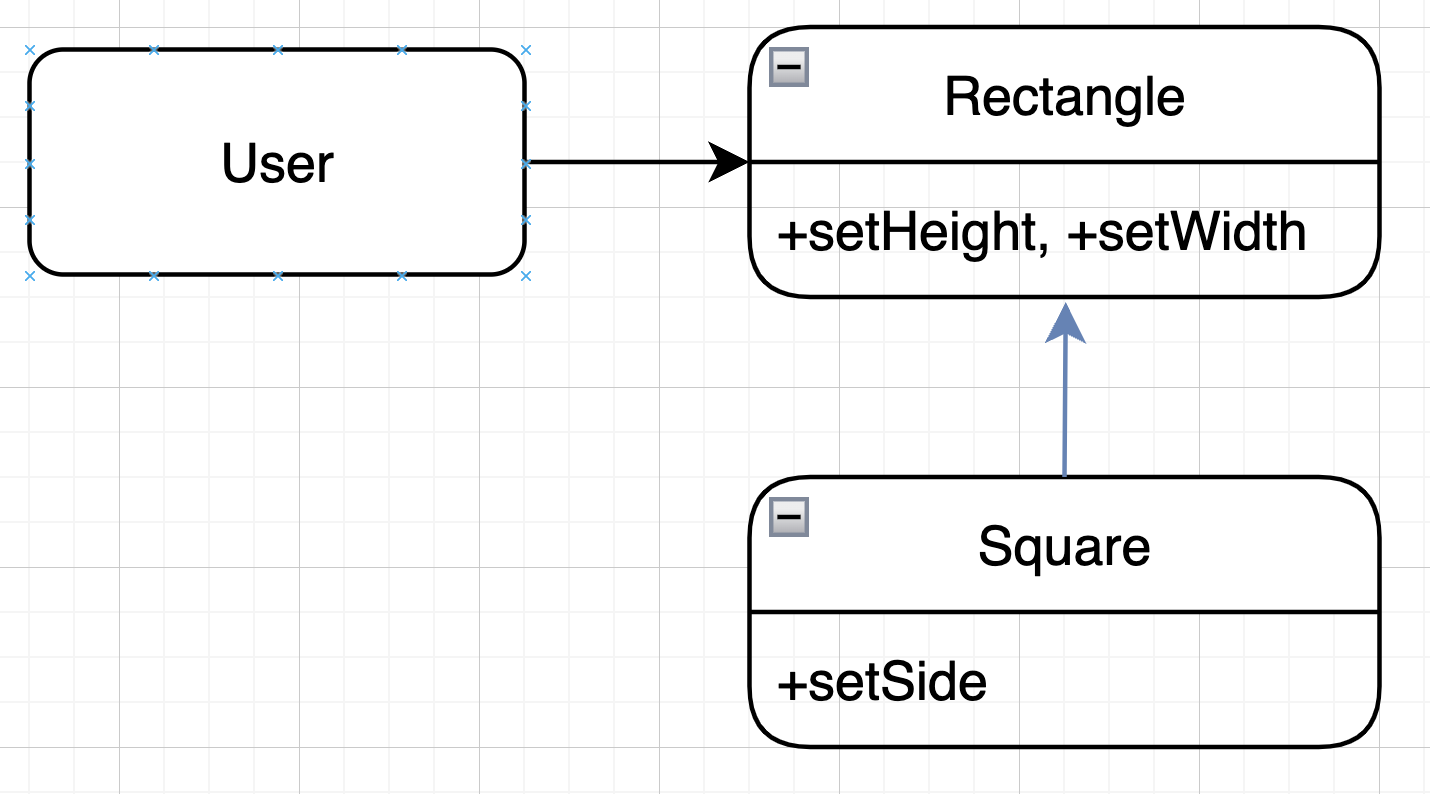
이 예제에서는 Square는 Rectangle의 하위타입이 될 수 없다.
왜냐하면 Rectangle의 높이와 너비는 독립적으로 변경할 수 있지만,
Square의 높이와 너비는 함께 변경되기 때문이다.
따라서 User의 프로그램에서 Square의 객체는 Rectangle의 객체를 치환할 수 없다.
<잡설>
이게 묘한 문제인게 기하학적 정의에서는 정사각형은 직사각형의 부분집합이댜.
그런데 프로그래밍에서는 하위타입이 아니라니.
내 생각엔 사실 그렇게 충격적인 것은 아닌게,
이 예제의 클래스들은 직사각형과 정사각형의 정의를 따르지 않기 때문이다.
직사각형의 정의는 "네 각의 크기가 모두 같은 사각형"이다.
그러나 이 예제에서는 단순히 높이와 너비를 설정하고 있다.
이름만 직사각형이고 기하학의 직사각형과는 완전히 다른 개념이다.
아키텍처 수준의 LSP
이때까지 클래스 수준에서의 LSP를 알아보았다.
LSP는 인터페이스와 구현체에도 적용되는 광범위한 소프트웨어 설계 원칙으로 변모해 왔다.
간단하게 충전기 어댑터의 충전 프로그램을 상상해보자.
그리고 물리적인 충전단자를 소프트웨어의 인터페이스라고 상상해보자.
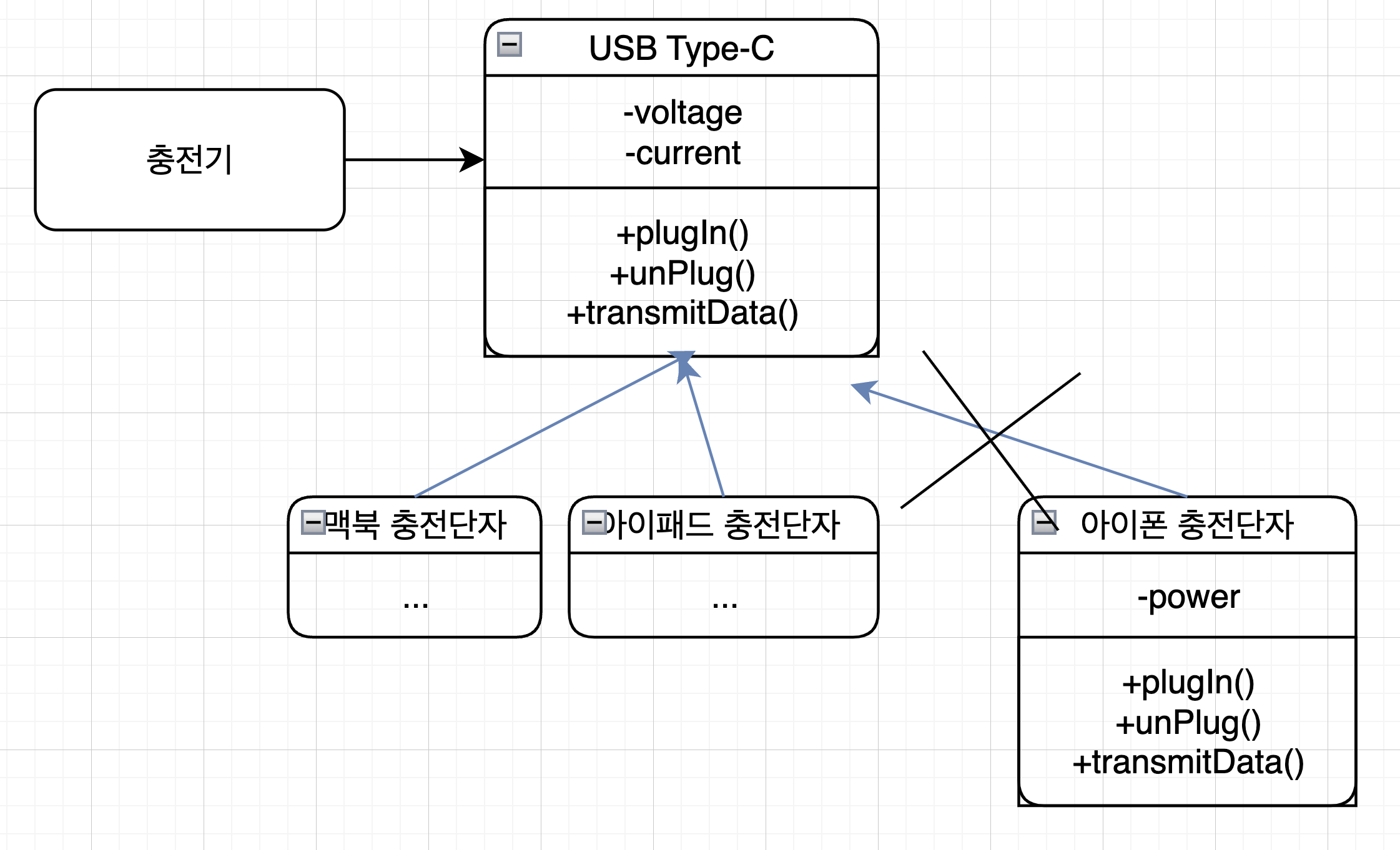
실제로 충전단자가 이렇게 구성되어있진 않겠지만, 이해를 돕기 위함이다.
이 예제에서 중요한 점은 모든 전자기기가 동일한 충전단자 인터페이스를 준수하도록 해야한다는 것이다.
서로 다른 충전단자가 C타입 충전단자의 모든 필드를 동일한 방식으로 처리해야한다.
그런데 아이폰 개발자는 C타입 충전단자의 인터페이스를 준수하지 않고 충전단자를 개발했다.
충전기 프로그램은 아이폰도 충전하기 위해서 아이폰의 충전단자만을 위한 로직을 추가해야한다..
LSP는 아키텍처 수준까지 확장되는 원칙이다.
치환 가능성을 위배하면 상당량의 별도의 메커니즘을 추가해야할 수도 있다.
ISP : 인터페이스 분리 원칙
사용하지 않는 요소를 의존해서는 안된다.
ISP는 이때까지의 원칙보다 훨씬 간단하다.
다음의 다이어그램으로 바로 이해가 가능할 것 같다.
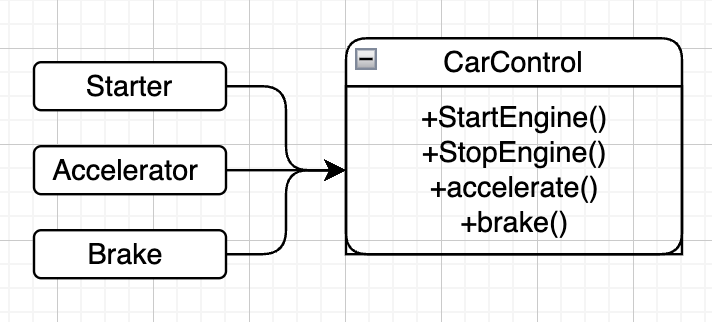
Starter와 Accelerator, Brake가 모두 CarControl 클래스를 사용한다.
Starter는 StartEngine() 과 StopEngine()
Accelerator는 accelerate()
Brake는 brake() 만을 사용한다.
여기서 CarControl이 정적 타입 언어로 작성되었다고 하자.
이 경우에 Starter는 accelerate()와 brake()를 사용하지 않음에도 이 두 메서드에 의존한다.
따라서 CarControl에서 두 메서드의 코드가 변경되면,
Starter와 관련된 코드는 전혀 변경되지 않았음에도
Starter 의 소스 코드도 다시 컴파일한 후 배포해야한다.
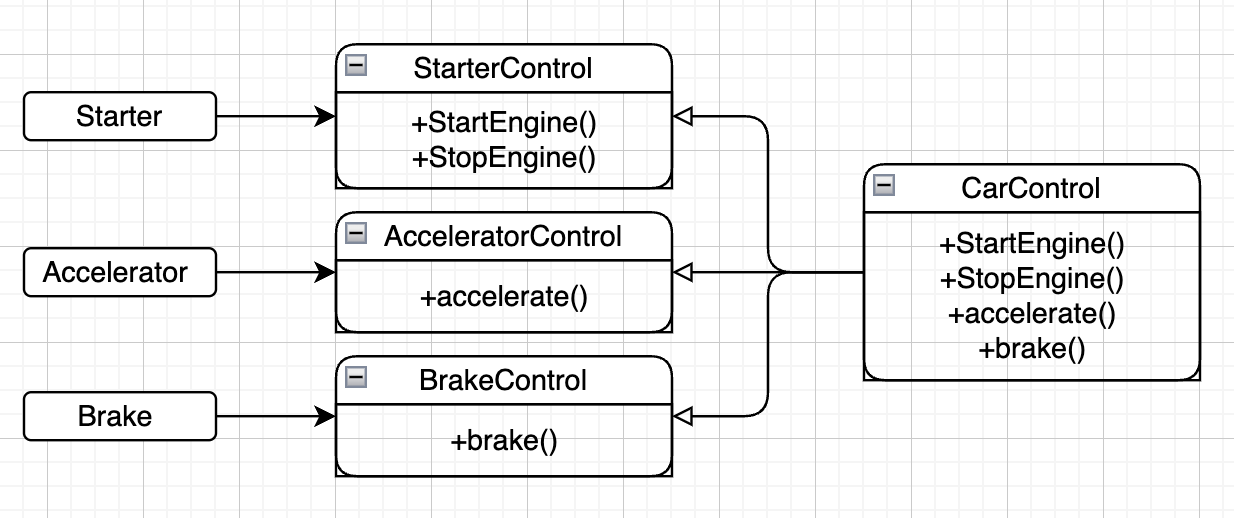
위와 같이 인터페이스를 분리한다면 의존성 문제는 쉽게 해결된다.
정적 타입 언어, 동적 타입 언어
ISP는 언어의 종류에 영향을 받는다.
정적 타입 언어는 컴파일 타임에 타입 정보가 결정되어 코드 변경 시 모든 의존 관계가 다시 컴파일되어야 하지만,
동적 타입 언어는 런타임에 타입 정보가 결정되므로 해당 메서드를 사용하는 부분만 런타임에 영향을 받는다.
따라서 동적 타입 언어에서는 의존하더라도 사용하지 않는 부분때문에 다시 컴파일할 필요가 없다.
그럼 파이썬과 같은 동적 타입 언어를 사용한다면 ISP는 신경안써도 되는 것일까?
당연히 아니다.
ISP는 단순히 소스 코드의 컴파일 때매 준수하는 것이 아니다.
아키텍처 수준의 ISP
ISP도 아키텍처 수준으로 확장할 수 있다.
온라인 스트리밍 서비스를 구축하는 아키텍트가 있다.
이 아키텍트는 사용자 인증 및 권한 관리를 위한 프레임워크를 사용하기로 결정했다.
이 프레임워크를 만든 개발자는 사용자 정보 데이터베이스를 반드시 사용하도록 만들었다.

스트리밍 서비스 -> 프레임워크 -> DB 의 의존관계가 만들어졌다.
프레임워크에 불필요한 기능이 User DB에 포함된다고 가정하자.
그 기능이 변경되거나 문제가 생길 경우,
프레임워크와 스트리밍 서비스에 영향을 끼치게 된다.
ISP를 아키텍처 수준에서 준수하면 시스템의 모듈 간 의존성을 최소화하고,
각 모듈이 필요한 기능만 사용하도록 할 수 있다.
DIP : 의존성 역전 원칙
상위 수준의 모듈은 하위 수준의 모듈에 의존해서는 안 되며, 둘다 추상화에 의존해야한다.
추상화
추상 인터페이스에 변경이 생기면 이를 구체화한 구현체들도 수정해야한다.
반면 구현체에 변경이 생기더라도 대다수의 경우 인터페이스는 변경 될 필요가 없다.
즉, 인터페이스는 구현체에 비해 변동성이 낮다.
안정된 소프트웨어 아키텍처는 변동성이 큰 구현체에 의존하는 것은 지양하고,
안정된 추상 인터페이스에 의존하는 것을 지향하는 아키텍처이다.
이 원칙은 구체적인 실천법으로 요약 가능하다.
-
변동성이 큰 구체 클래스를 참조하지 말라.
대신 추상 인터페이스를 참조해라. -
변동성이 큰 구체 클래스로부터 파생하지 말라.
상속 관계는 소스 코드에 존재하는 모든 관계 중 가장 변경하기 어렵다.
따라서 상속은 신중하게 사용해야 한다. -
구체 함수를 오버라이드 하지 말라.
대체로 구체 함수는 의존성을 필요로 한다.
따라서 구체 함수를 오버라이드 하면 의존성을 상속하게 된다.
차라리 추상 함수로 선언하고 구현체들에서 각자의 용도에 맞게 구현해야 한다. -
구체적이며 변동성이 크다면 절대 참조하지 말라.
추상 팩토리
위 규칙들을 준수하려면 변동성이 큰 구현체의 객체는 신중히 생성해야한다.
객체를 생성하려면, 해당 객체의 구현체에 의존성이 발생하기 때문이다.
이런 의존성을 처리하기 위해 추상 팩토리를 사용한다.
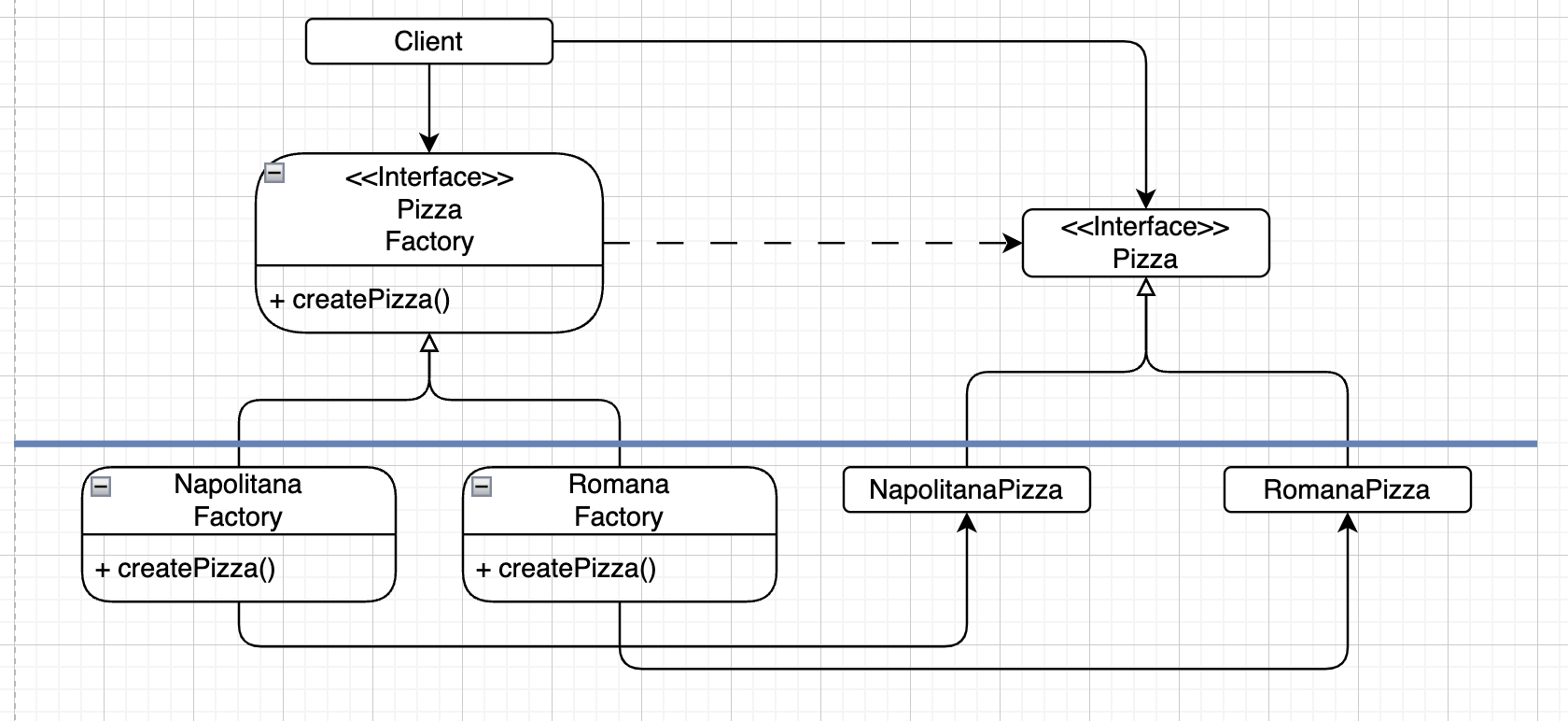
Client는 Pizza객체를 생성할 때,
추상 컴포넌트인 PizzaFactory를 이용하여 생성한다.
그리고 Pizza 인터페이스를 이용해 생성된 Pizza객체를 다룬다.
PizzaFactory는
NapolitanaFactory와 RomanaFactory를 이용하여
각각의 객체를 생성한다.
Pizza는
생성된 NapolitanaPizza와 RomanaPizza의 코드를 호출한다.
추상 팩토리 패턴을 사용하면 클라이언트 코드가 객체의 생성과 사용 방법을 추상화된 인터페이스에 의존하므로,
객체의 구체적인 클래스를 바로 참조하지 않고도 유연하게 변경 가능한 코드를 작성할 수 있다.
또한 새로운 종류의 객체를 추가하거나 객체의 생성 방법을 변경할 때 클라이언트 코드에 영향을 주지 않으면서 확장성을 높일 수 있다.
-> 밀라노 피자를 추가하고 싶다면 클라이언트의 코드는 전혀 고칠 필요가 없다.
그저 MilanoFactory 구체 컴포넌트를 생성하여 PizzaFactory를 상속하고,
MilanoPizza는 Pizza를 상속하도록 하면 된다.
파란선을 기준으로 추상 컴포넌트와 구체 컴포넌트로 나뉜다.
추상 컴포넌트는 애플리케이션의 고수준 업무 규칙을 포함한다.
구체 컴포넌트는 업무 규칙을 다루기 위한 세부사항을 포함한다.
고수준 업무 규칙을 보호하기 위해 의존성을 추상 컴포넌트로 향하게 했다.
그리하여 의존성이 제어흐름과는 반대 방향으로 역전된다.
따라서 이 원칙을 의존성 역전이라고 부른다.
끝
SOLID의 각 원칙들의 정의를 알아보고
아키텍트의 관점에서 탐구해 보았다.
원칙들을 하나씩 알아보는 과정에서 예전의 경험이 떠올랐다.
그 당시에 구조를 어떻게 해야할까 고민을 했던 적이 몇번 있었다.
이렇게 하면 안될 것 같은데 정확히 어떤 점이 문제이고 어떻게 고쳐야할지는 몰랐다.
이제는 좀더 명확하게 구조를 설계할 수 있을 것 같다.
내 코드의 결과가 순살프로그램이 아닌 뼈대가 튼튼한 프로그램이 되기 위한 좋은 양분이 될 것이다.

이런 유용한 정보를 나눠주셔서 감사합니다.