[NLP] Back propagation and Neural Networks
Linear Classification with Dense Word Vectors

그림은 dense word vector을 DL의 input으로 하여 text classification를 하는 과정을 간단히 그림으로 나타낸 것이다.
text의 각 단어들을 dense vector로 만들어 더하고 weight 행렬을 곱하여 시그모이드 같은 activation function에 넣은 값을 score라고 하는 것 같다.
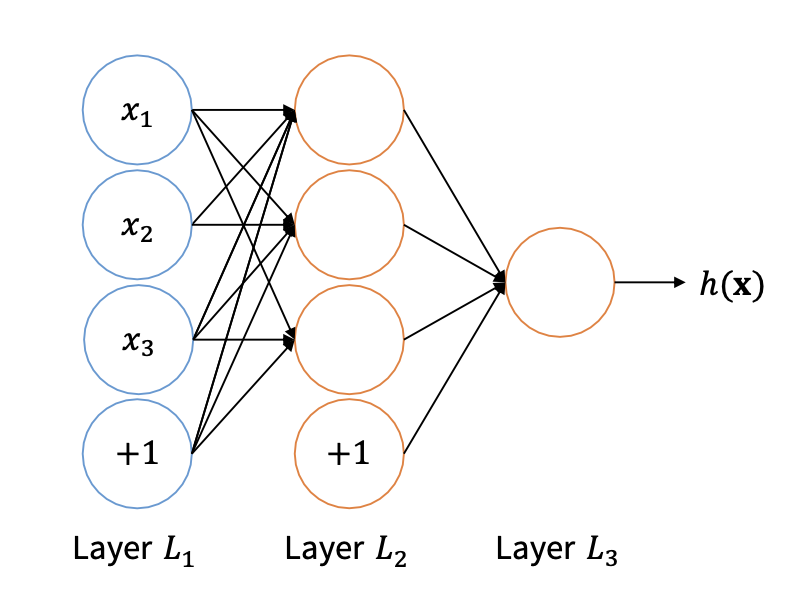
f: activate function
f 함수에 z 벡터의 값을 element wise로 대입하면 a 벡터가 된다.
즉, 지금 그림을 보았을 때, x의 개수가 3개이므로 3x1 벡터가 인풋으로 들어오고, output layer는 3x1 벡터이므로, W 행렬은 3x3이었을 것이다.
trans(W)X = A => (3x3)(3x1) = (3x1)이기 때문이다.
Non-linear activation function
그러면 왜 non-linear란 함수 f가 필요한 것일까?
그 이유는, 리니어한 연산은 계속 반복해도 그냥 리니어 하기 때문이다.
이렇게 W2를 곱하고, W1을 곱하는 연산을 했지만, 결국 W = W1*W2로 나타낼 수 있으므로 그냥 리니어 연산 한번 한 것과 같아지게 된다.
그러면 아래 그림처럼 classification을 할때 리니어한 라인으로 단순하게 나누는 것에 그친다. 하지만 non linear function을 쓴다면 아래 그림의 왼쪽처럼, 복잡한 classification도 가능해진다.

블로그 이전하려고 합니다! 👉 https://onfonf.tistory.com 🍀