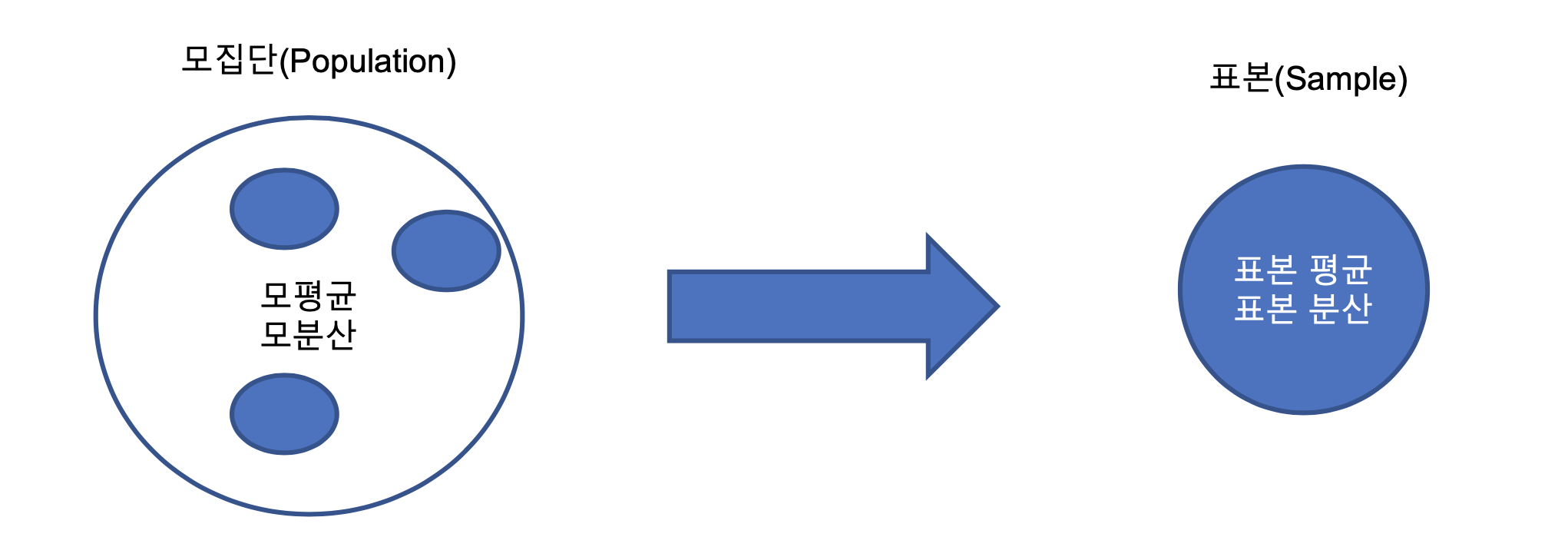
📍 모집단과 표본 분포
모집단(Population)과 표본(Sample)
- 모집단 : 투표권이 있는 국민
- 표본 : 출구조사때 나오는 표본
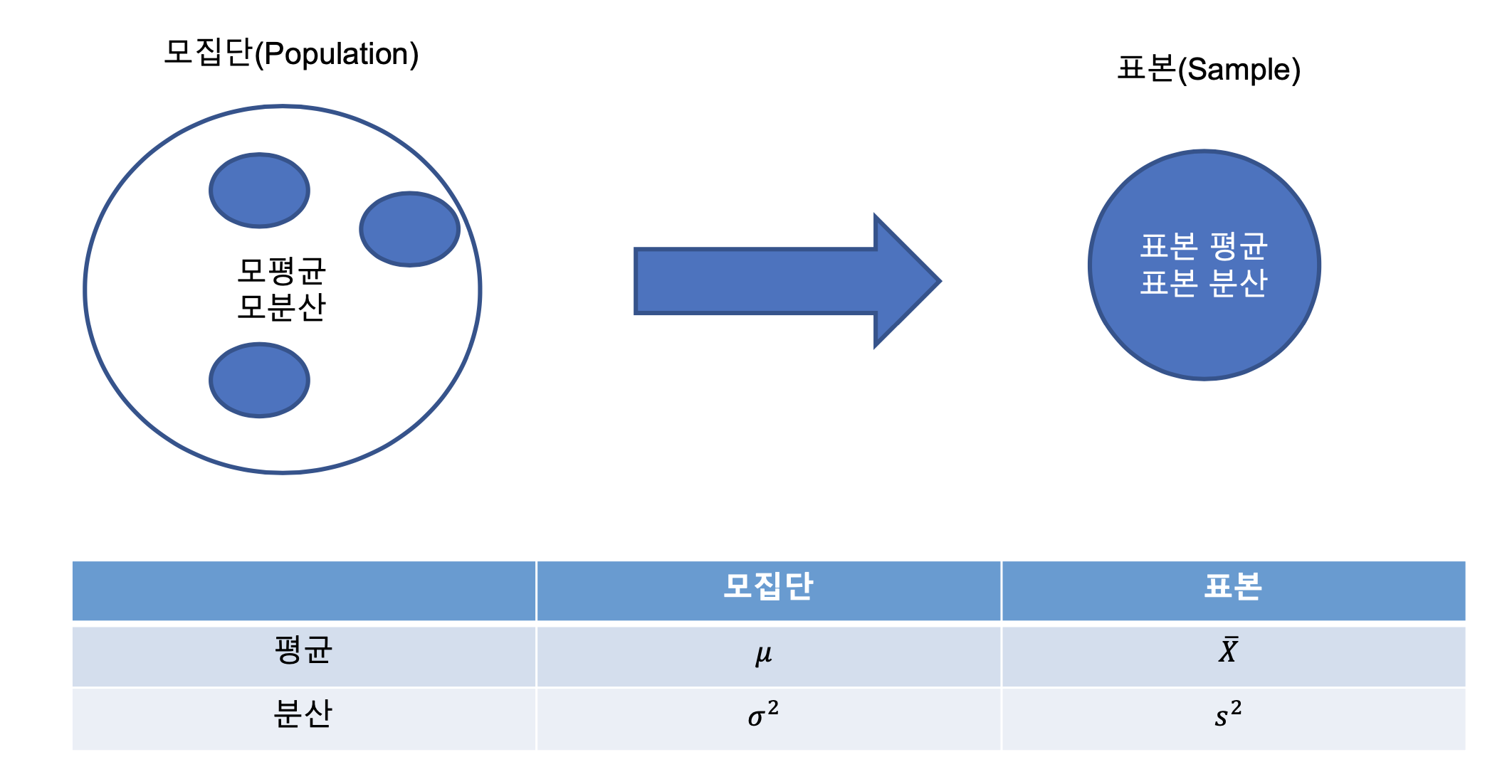
- 표본추출 : 모집단으로 부터 표본을 추출하는 것을 Sampling이라고 하며, 표본으로 부터 그 특성을 찾아내고 모집단의 특성을 추론하고자 함
🔖 모집단
모집단에서 표본을 추출하는 방법
- 복원추출 : 모집단에서 데이터를 추출할때 하나를 추출하고 다시 넣고 추출하는 방법으로 동일한 표본이 추출될 수 있음
- 비복원추출 : 모집단에서 데이터를 추출 할때 하나를 추출하고 다시 넣지 않고 추출하는 방법
- Random Sampling : 모집단에서 데이터를 추출할 때 주의할 점은 편향되지 않아야 함, 각 개체가 모두 동일한 확률로 추출하는 방법
불균형 데이터(Imbalanced Data)의 문제
- 데이터가 불균형데이터일 경우 문제가 생김
예 ) 신용 평가 모형 개발, 제조 불량 예측 등 - 해결법
1 ) Sampling 기법을 통해 해결
2 ) 모델을 통한 성능 개선
Sampling 기법
- 관심의 대상이 아주 비율이 낮은 경우
Over Sampling
- 과도적합의 문제 발생할 수 있음
Under Sampling
- 임의로 뽑은 데이터가 편향될 수 있고, 모형의 성능이 떨어질 수 있음
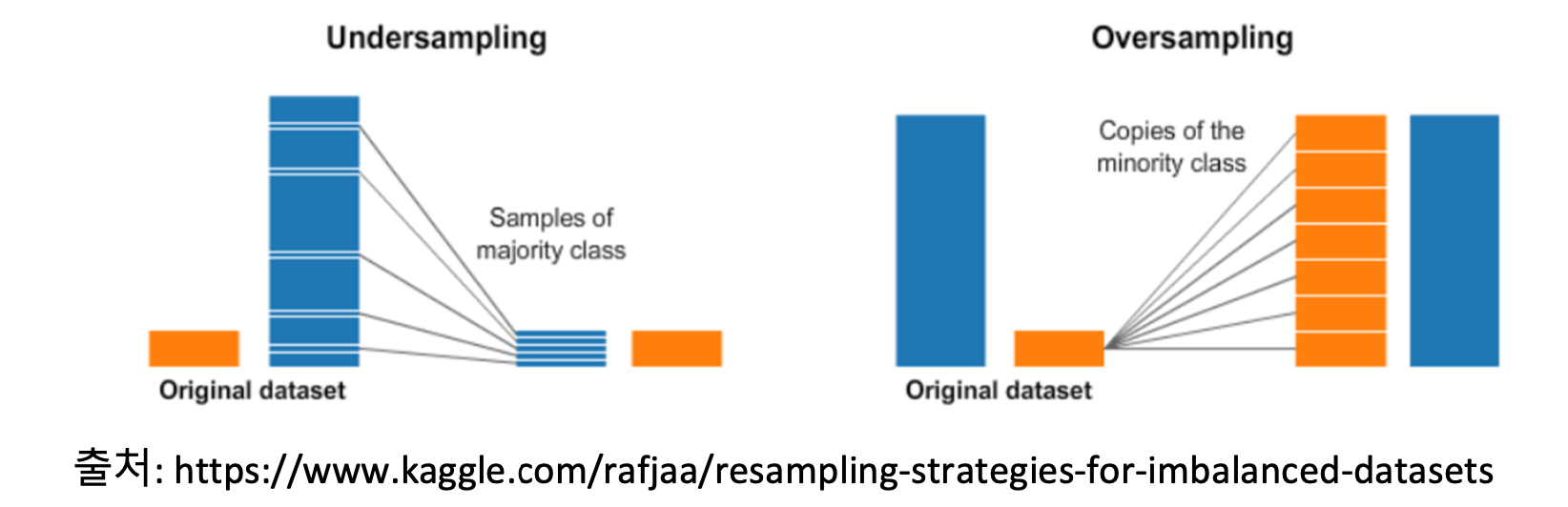
- 임의로 뽑은 데이터가 편향될 수 있고, 모형의 성능이 떨어질 수 있음
🔖 표본분포
통계량(Statistic)
- 표본에 기초하여 계산되는 수치 = 통계량
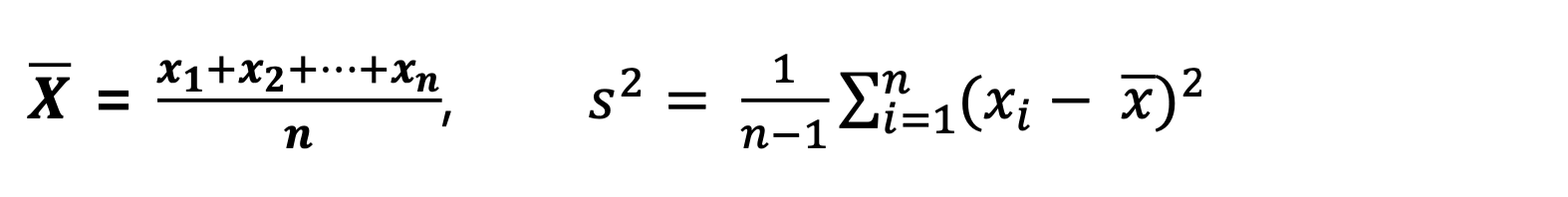
표본분포(Sampling distribution)
-
통계량들이 이루는 분포
표본평균(Sample mean)
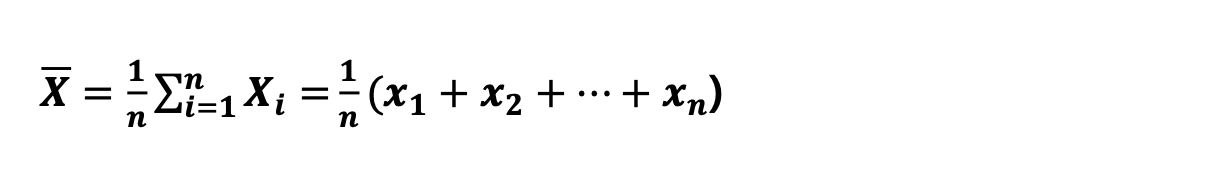
-
표본평균의 의 기대값
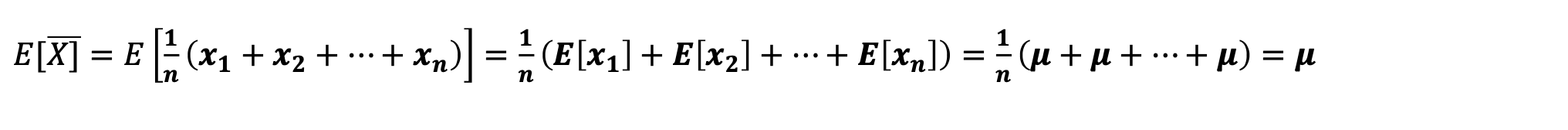
-
표본평균의 의 분산
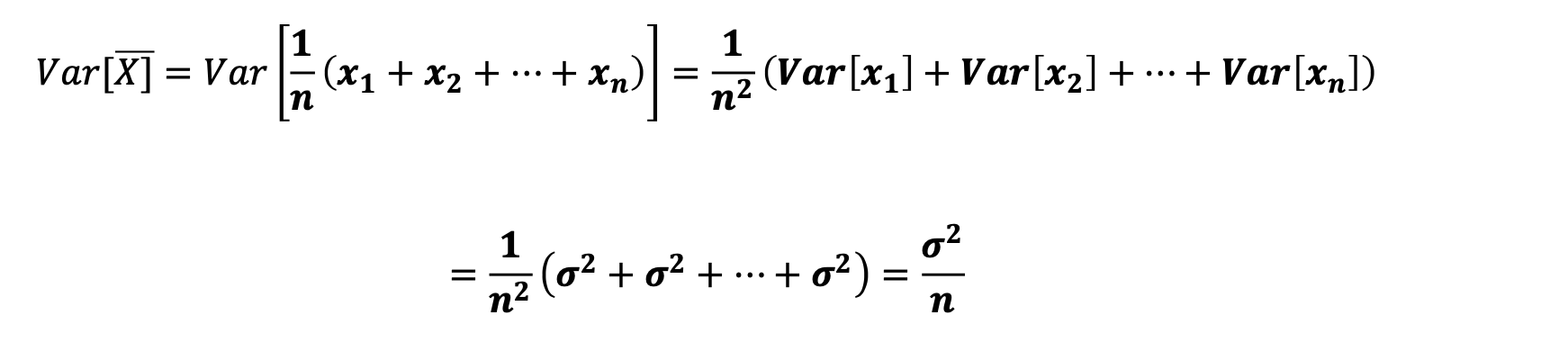

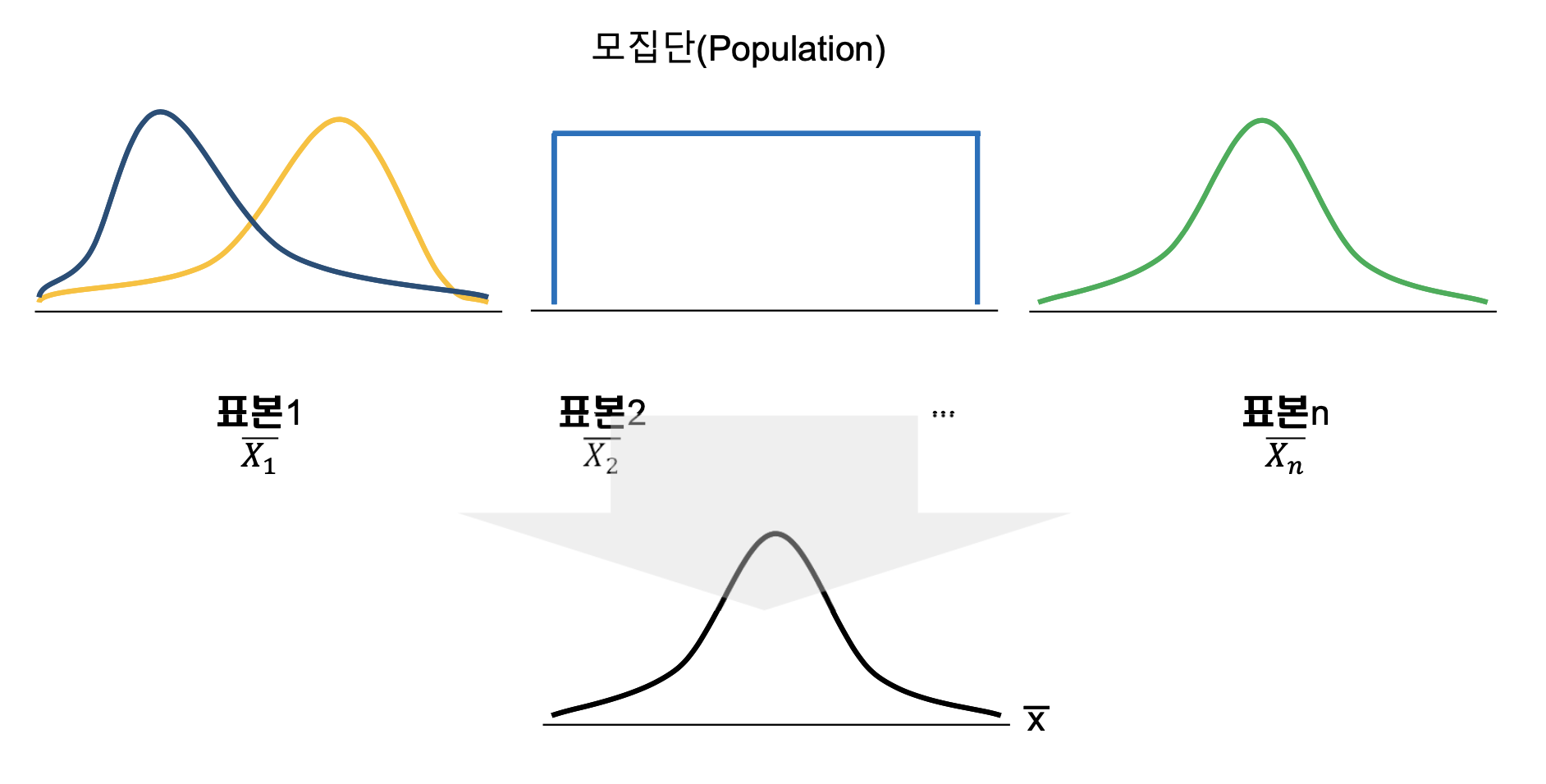
중심극한 정리(central limit theorem)
- 평균이 이고 인 임의의 모집단에서 랜덤 표본 을 추출할 때 표본의 크기 이 충분히크면, 표본 평균 는 근사적으로 정규분포 을 따른다


카이제곱 분포
카이제곱 분포는 범주형 자료 분석에서 활용함
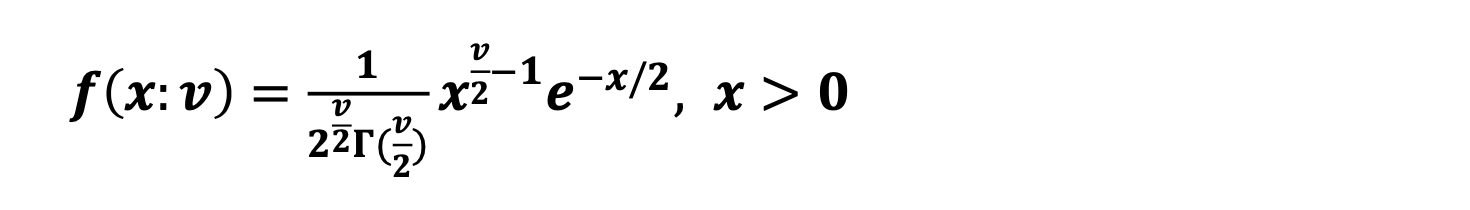
- 카이제곱의 기대값 :
- 카이제곱의 분산 :
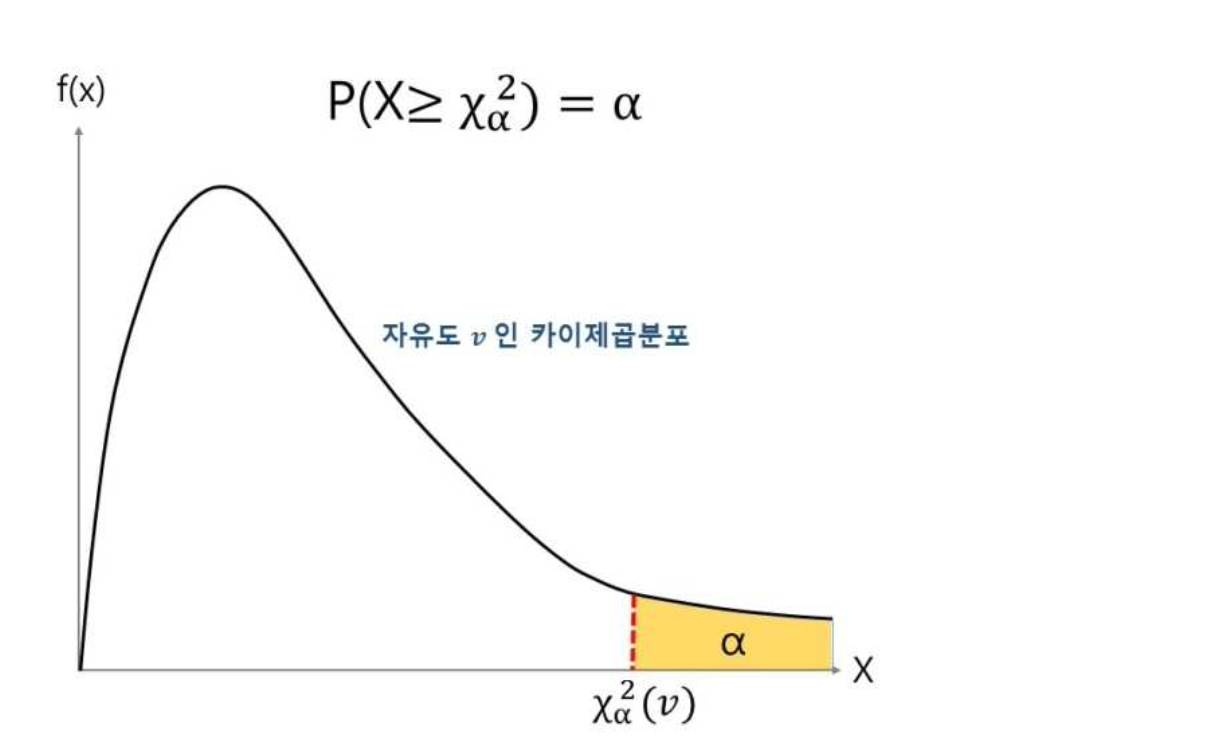
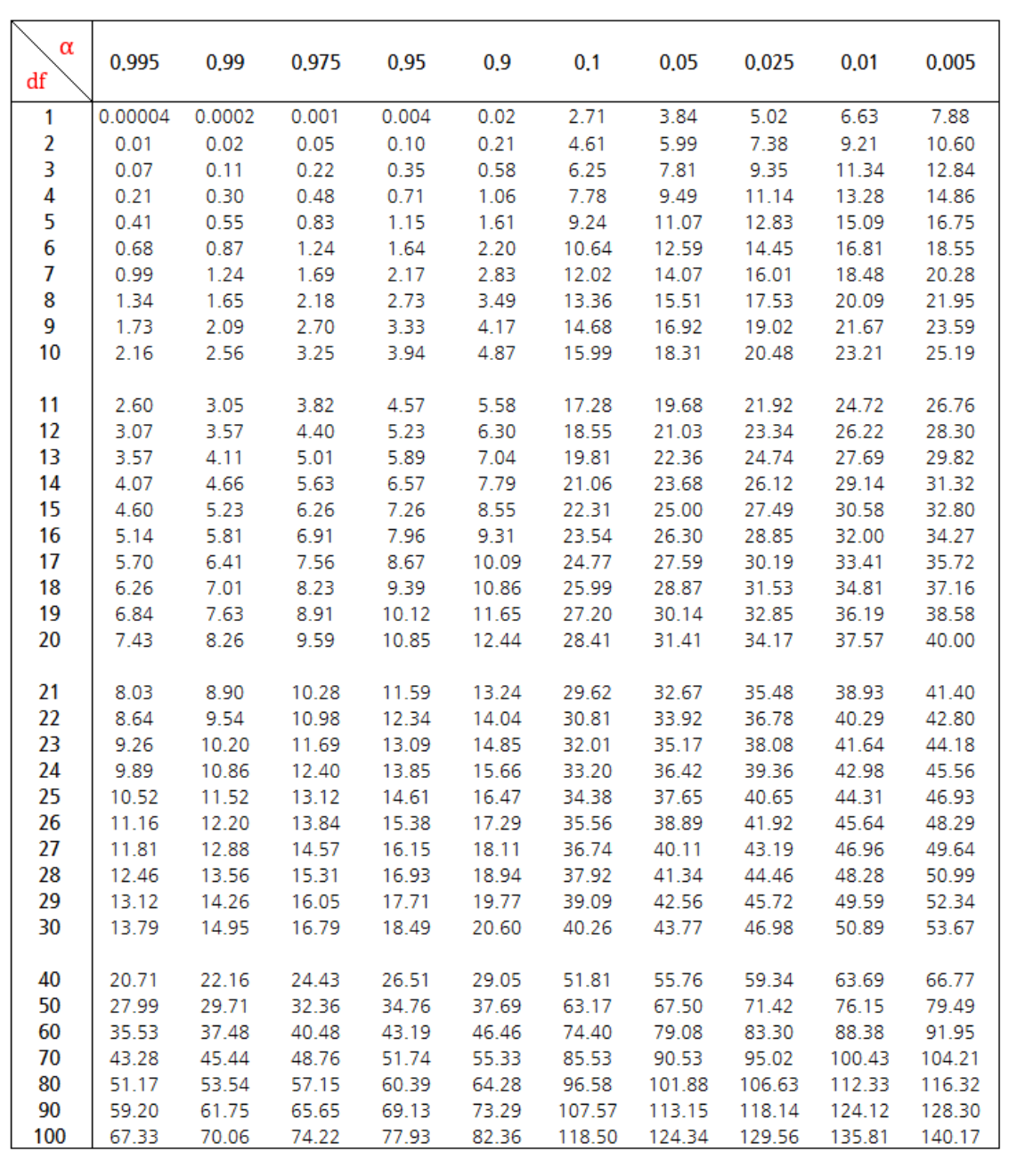
자유도
- 표본수-제약조건의 수 또는 표본수-추정해야 하는 모수의 수를 의미, 일반적으로 을 사용함
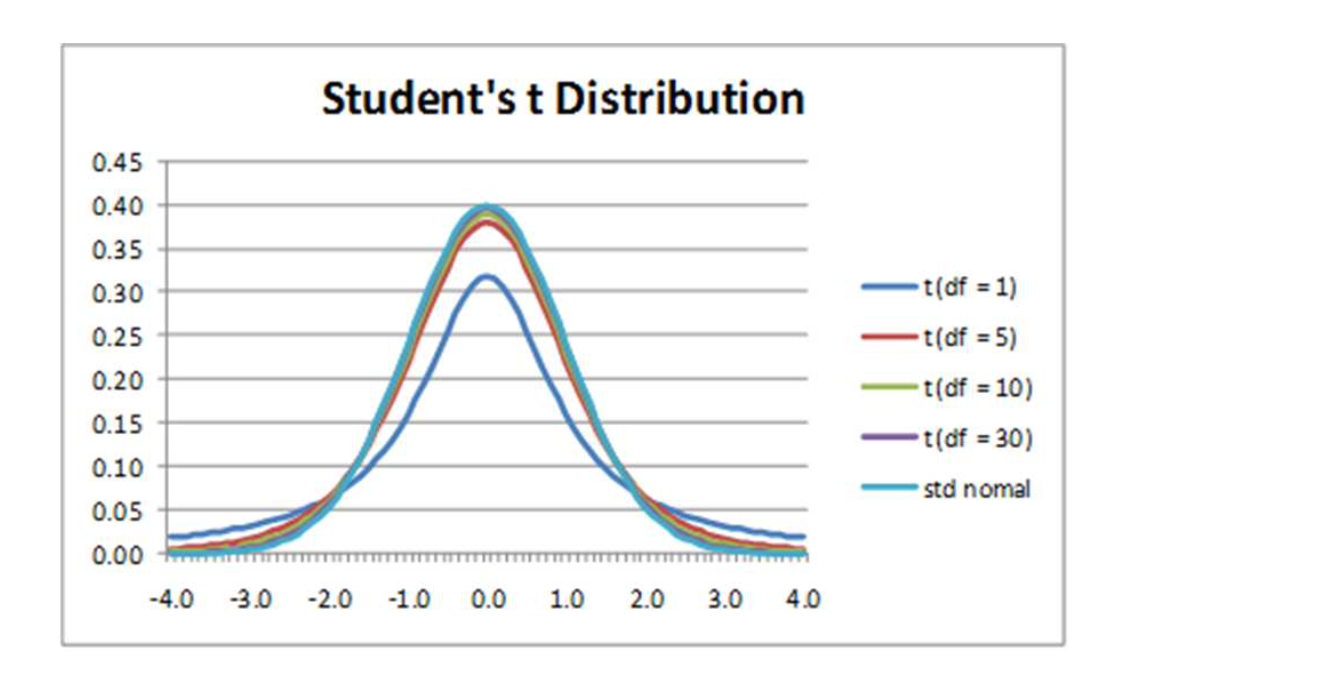
T분포(t-distribution)

- 만약 확률 변수 가 정규분포를 따르고 모표준편차 를 안다면

- 만약 모표준편차 를 모른다면, 를 대신해서 표본표준편차 를 이용하여 확률변수 를 정의함

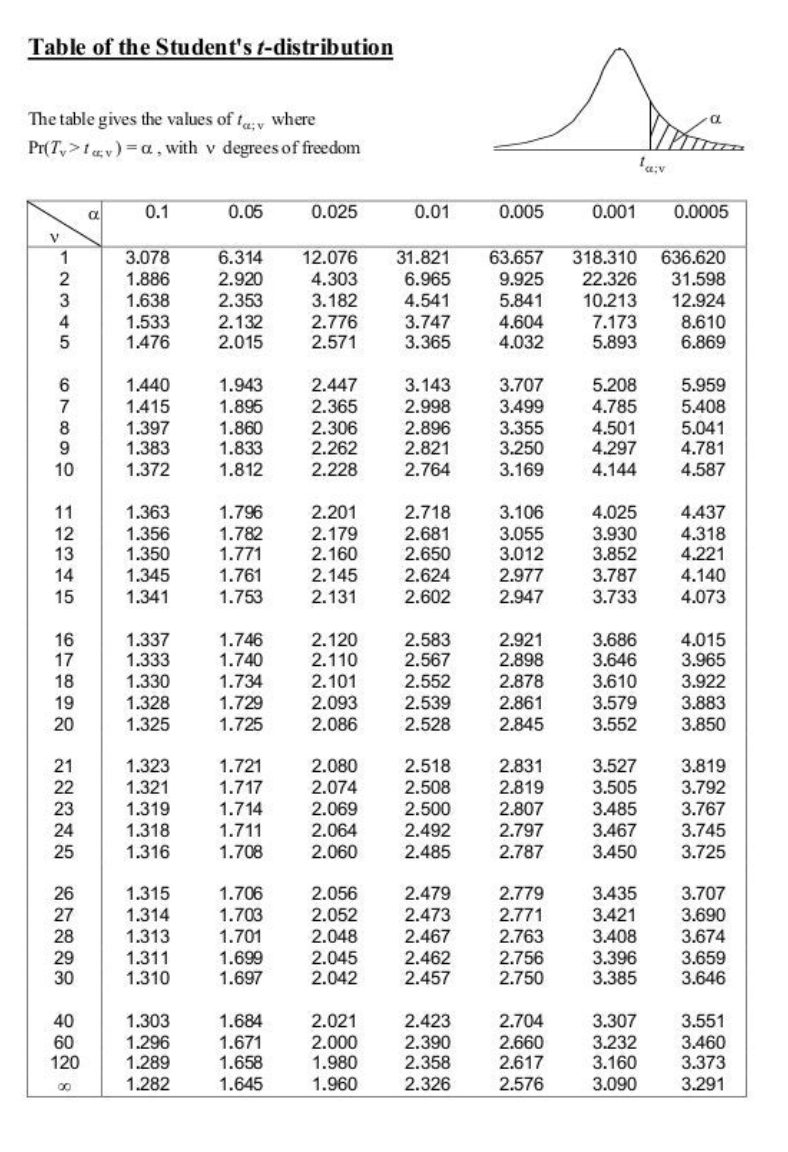
F분포(f-distribution)
서로 독립인 두 정규모집단의 분산 또는 표준편차들의 비율에 대한 통계적추론, 분산분석 등에 활용됨
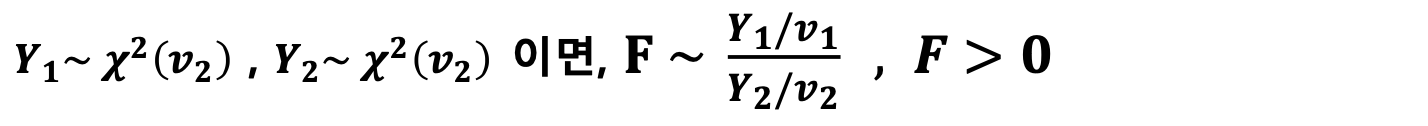
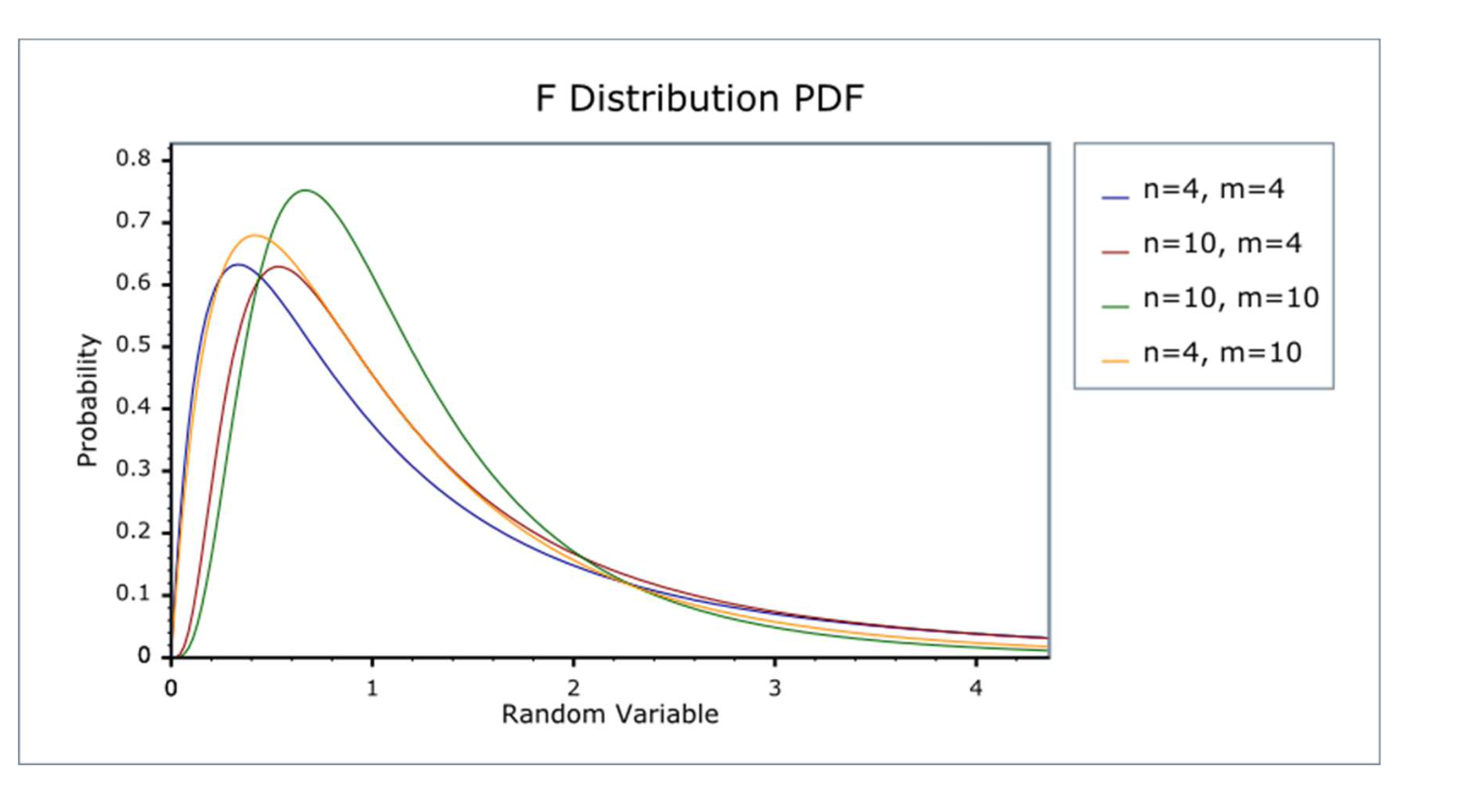
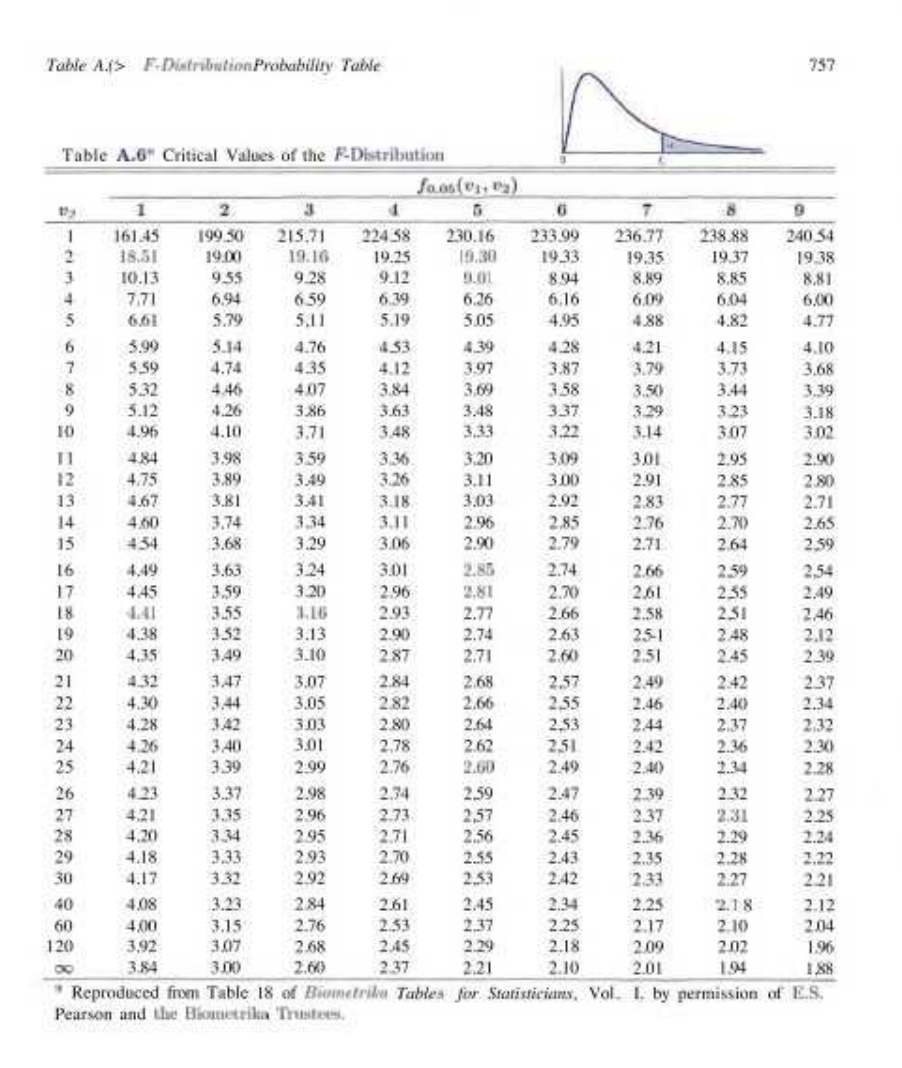
-> 카이제곱분포와 같은 모양이지만 자유도가 2개라는 차이가 있음
📍 추정
🔖 추정 : 모집단에 대한 추론(통계적 추론)의 개념을 설명
- 모집단의 모수를 모를 경우 표본으로 추출된 통계량을 모집단의 근사값으로 사용하는 것을 추정이라고 함
추정량(estimato) : 표본 평균으로 모평균을 추정할 때 표본 평균을 모평균에 대한 추정량이라고 함
모수를 추정하는 방법 : 점추정(point estimation), 구간추정(interval estimation)
점추정 : 모수를 하나의 특정값으로 추정하는방법
- 일치성(Consistency) : 표본의 크기가 모집단의 크기에 근접해야 함
- 불편성(unbiased estimator) : 추정량이 모수와 같아야 함
- 유효성(efficiency) : 추정량의 분산이 최소값이어야 함
- 평균오차제곱(Mean Squared Error, MSE) : 평균오차제곱이 최소값이어야 함
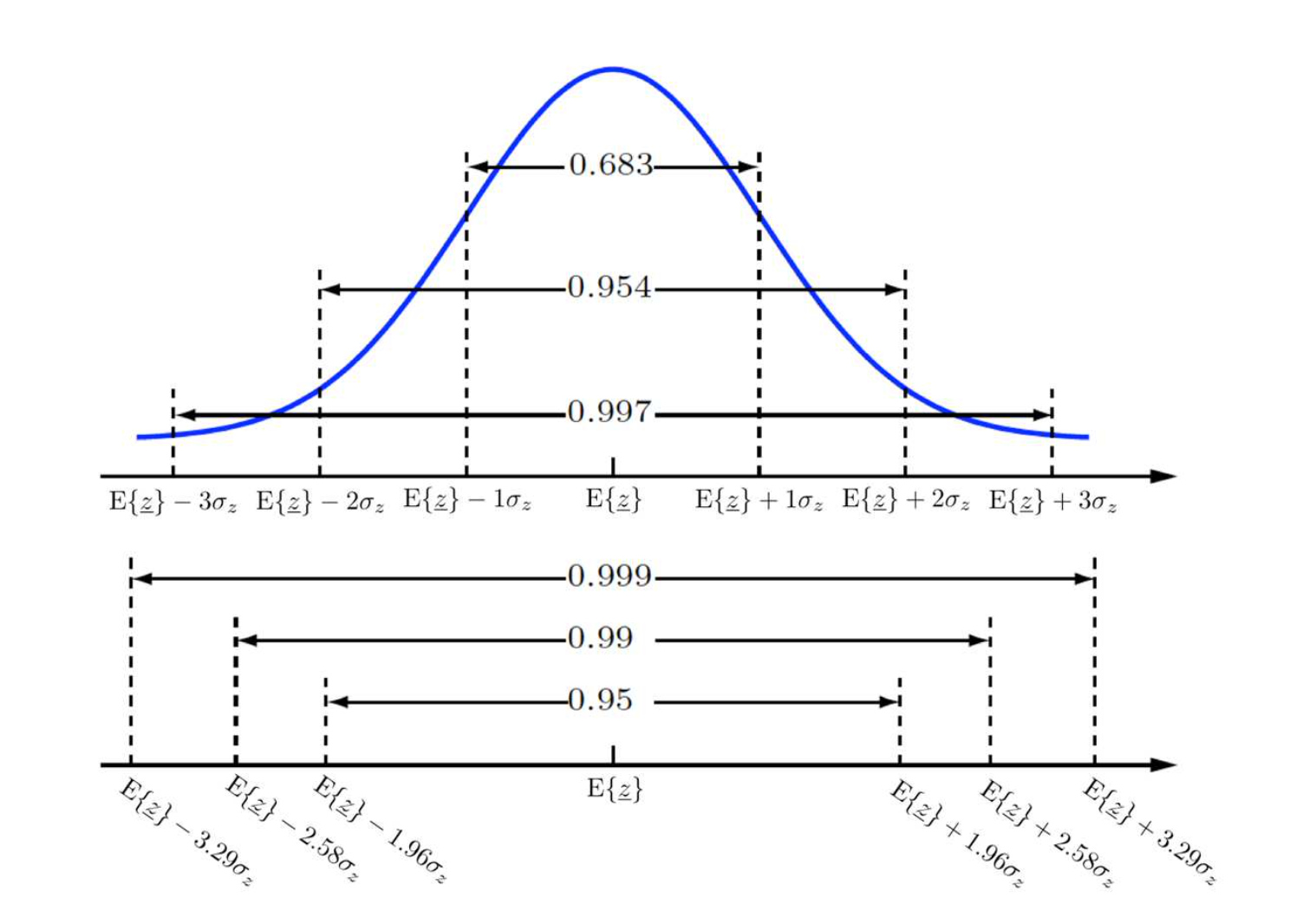
구간추정 : 모수가 포함될 수 있는 구간을 추정하는 방법
- 유의 수준(significant level) : 신뢰수준 95%라는 것은 구간추정된 값의 오차가 발생할확률이 5%라는 것을 의미 이 오차를 유의수준이라고 하며, p=0.05라고 함
- 신뢰 수준은 100* (1- )로 계산 하며, 는 오차 수준임
- 신뢰구간(confidence level) : 추정값이 존재하는 구간에 모수가 포함될 확률
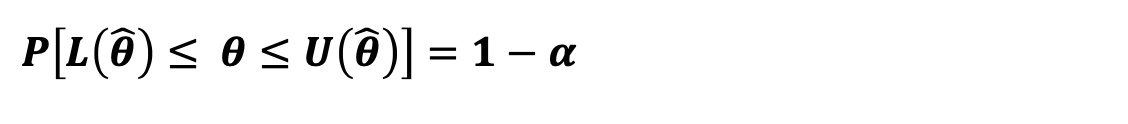
🔖 모비율 추정
점추정 : 비율에 대한 추정으로 우리가 원하는 속성(class)에 속하면 '1'아니면 '0'일 때, 1의 속성을 갖는 것의 개수를 라고 하면 임, 이때 모비율의 점추정량을 표본 비율(sample proportion)이라고 함
구간추정 : 모비율 구간 추정에서 정규분포의 근사가 가능한 대표본은 보통 를 동시에 만족 해야 함

