컴퓨터구조 - DevWoony가 복습을 위해서 전공과목을 정리하는 내용이에요!
Paraller Computers
Paraller computer은 큰 문제를 빠르게 풀기 위해 협력하고 대화하는 processing 요소들의 집합이다.
- 얼마나 큰 집한인지?
- processing 요소가 얼마나 강력한지?
- processing 요소들이 어떻게 협력하고 대화하는지?
- 데이터가 어떻게 전환되는지?
- 어떤 타입으로 연결되어 있는지?
- 개발자가 알아야할 HW와 SW 기초요서는 무엇인지?
- 그것들이 performance로 전환이 되는지?
Paraller Computers의 변화
-
Computer 설계자들의 꿈! : 1950s
- 프로세서를 복제하여 성능 추가하였다.
- 보다 빠른 processor을 설계하였다.
- Uniprocessors는 빛의 속도의 한계 때문에 속도향상을 멈추었다.
-
Bit level parallelism : 1970~1985
- 4, 8, 16, 32 bit microprocessors로 점점 계산할때 bit를 넓혀 숫자범위를 넓혀왔고 한번에 큰 숫자를 계산가능토록 병렬화했다.
- 32 bit 부터는 이를 애매하게 보기 시작했다. 실제로 32 bit보다 큰숫자를 계산할 일이 일상에서 많이 존재하지 않다는 것이였다.
- 이에 최근에 나오는 64bit processor가 과연 빠른것인가? 라는 의문점을 가져볼 수 있다.
-
Instruction level parellelism(ILP) : ~1985~2005
- Pipelining, Superscalar, VLIW
- Out-of-Order excution
- 순차진행가능한 명령어와 불가능한것을 구분하는 과정 속에 Power가 증가했다.
- instructions와 Power가 비례해서 증가했고 'Power Wall' 문제에 부딪힌다.
- 1.5년마다 2배 성능 증가가 어려워졌다.
- 그에 따라 ILP는 한계에 부딪힌다.
Multiprocessor의 등장
- Process Level(=Program) 또는 Thread Level(=Function)에서의 parallelism이 시작되었다.
- Microprocessors은 이미 빠르고 Multiprocssors을 다시 디자인하는 것이 아니라 Microprocessors를 모아서 넣었다.
- 하지만 그에 따른 Software의 발전은 느리게 발전했다.
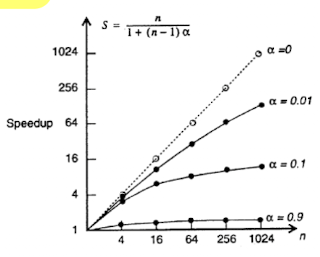
Amdahl's Law
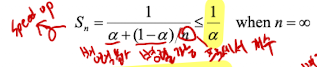
- n = 프로세스의 개수
- a = 프로그램의 순차적 요소(병렬불가 요소)
만약 a = 0이면 최대 향상 가능한 속도는 n이 된다.
하지만 실제로는 내부 processors들이 병렬처리할 때 commucation을 위한 memory의 size가 고정되어 있어 synchronization delays가 발생한다.
Flynn's Classification
- SISD (Single Instruction Single Data)
- Uniprocessors에서 사용된 방식
- MISD (Multiple Instruction Single Data)
- Multiple processors에서 Single Data를 처리??? 거이 상용화를 못함
- SIMD (Single Instruction Multiple Data)
- 간단한 programming 모델에서 사용하는 방식
- 낮은 오버헤드
- 유동성
- 회로에서 custom이 가능하고 멀티미디어, 그래픽, 동영상 처리용도로 사용
- MIMD (Multiple Instruction Multiple Data)
- 유동성
- 멀티프로세스
- 최근 대부분 이 부분을 사용
Communication Model
다음 두개의 개념은 HW와 SW에서 동시에 사용될 수 있는 단어이다.
- Shared Memory
- Processors들이 communication을 위해 메모리 영역을 공유
- Memory와 병렬로 만들어진 processor들과 다 연결해야하기 때문에 많은 전선들이 필요하다. 그래서 작은 machines에서 자유 사용되는 모델이다.
- 장점들
- 쉬운 프로그래밍
- 적은 지연율
- 하드웨어의 쉬운 캐쉬 제어
- Message passing
- Processors들은 각자 Memory의 영역을 가지며 message를 통해 소통한다.
- Message를 통해 소통하므로 메모리와 processor을 전선으로 다 연결할 필요가 없다. 대신 오버헤드가 증가한다.
- 장점들
- 보다 작은 하드웨어
- 쉬운 설계
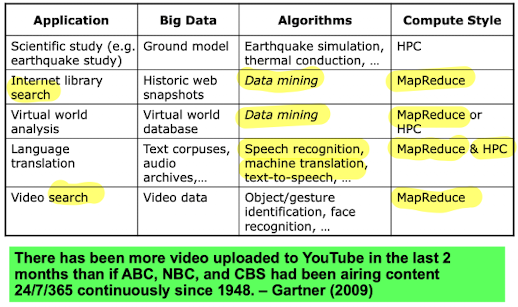
Request-Level Parallelism (RLP)
- 수백, 수천개의 요청이 초단위로 이루어질 때
- 다음과 같은 독립적인 요청들을 병렬 처리
- DB의 읽기만을 위한 요청
- 약간의 읽기 및 쓰기를 공유하는 요청
- 거이 없는 경우지만 읽기 및 쓰기를 공유하거나 데이터의 synchronization 필요한 요청
- 다음과 같은 독립적인 요청들을 병렬 처리
- MapReduce의 중요성
- MapReduce는 데이터의 처리를 거대한 클러스터에서 단순화하는 것을 의미한다.
웹 검색 분석
Goole검색과 같이 유명한 인터넷 서비스에서의 예제
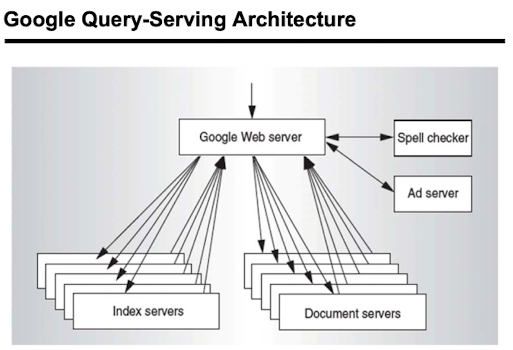
- Google에서 "John Hennessy" 검색한다.
- Google Warehouse Scale Computer(WSC)의 직접요청
- Front-end load balancer은 request를 WSC에서 여러개의 cluster된 Google Web Servers(GWS) 중 하나로 보낸다.
- 많은 Google Web Servers(GWS) 중 선택된 하나의 서버는 Document server와 소통하며 request를 처리하고 response 페이지를 구성한다.
- GWS는 많은 Index Servers들고 소통하며 "John"과 "Hennessy"를 포함하는 문서를 찾아낸다.
- document 리스트를 반환한다.
Big Data
Big Data의 배경
- 어플리케이션이 큰 데이터를 요구
- 데이터의 증가
- 계산의 증가
- 큰용량으로 이동불가 데이터 발생
Big Data의 요구사항
- 많은 CPU를 요구
- 병렬처리를 요구
- 동시접근이 필요
- 지연율을 scaling 가능
- 느린자원을 성장을 위해 scaling이 가능
- 급한자원을 power/demand를 위해 scaling이 가능
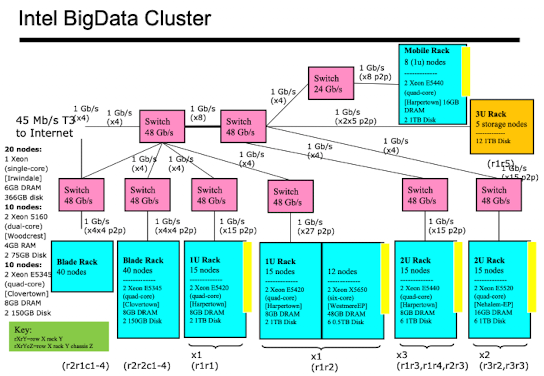
Cloud Software Stack
Hadoop과 Maui-Torque와 같은 어플리케이션
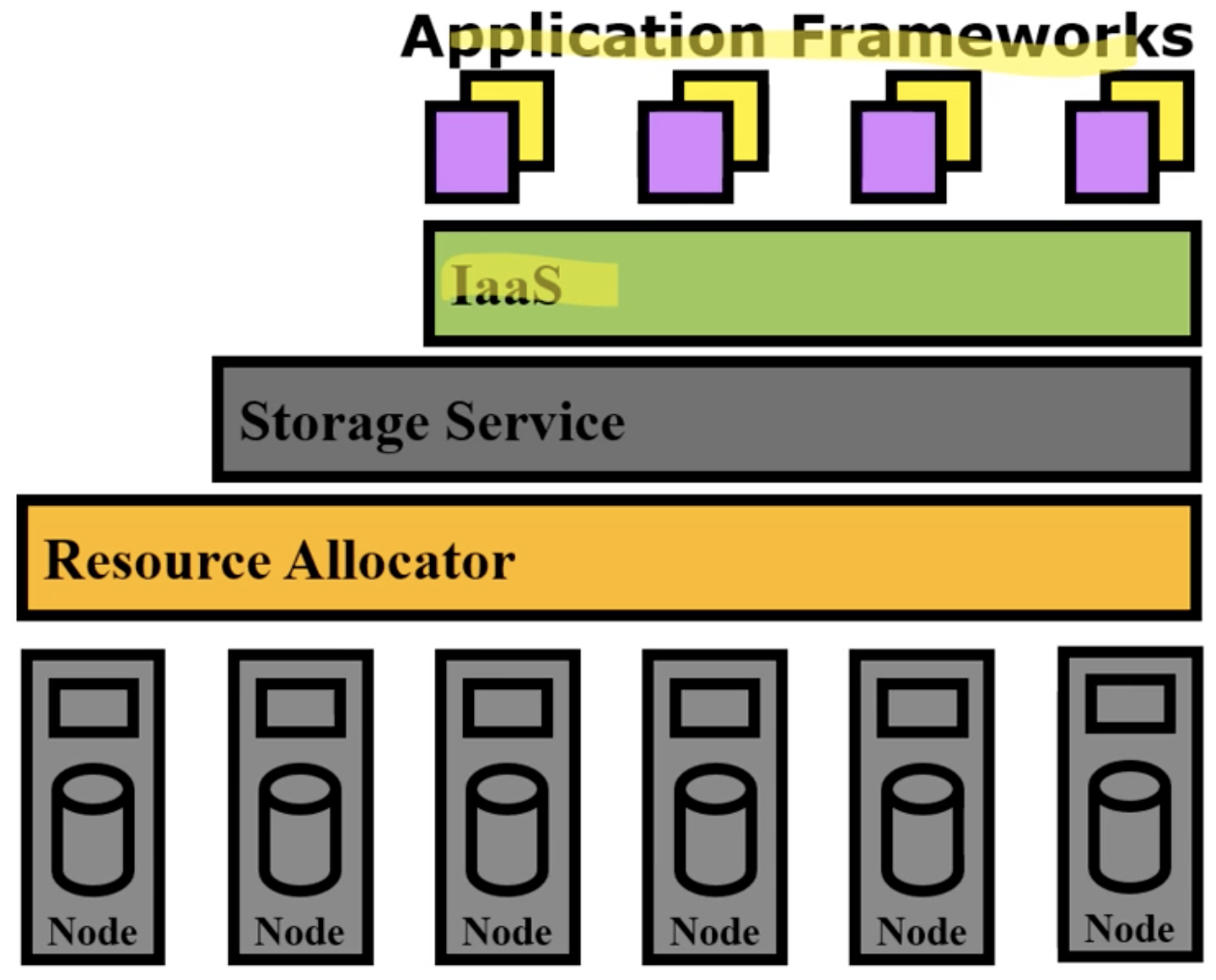
출처: [Computer Organization And Design: The Hardware/Software Interface]

냉장고에 카페인이 가득한 회사에 가고싶다.