Ch10. Kernel Synchronization Methods
리눅스 커널이 제공하는 동기화 기법군에 대해 소개한다.
1. Atomic Operations
Atomic operation은 원자성을 띈 instruction을 제공한다. 커널에서는 정수를 계산하는 연산과 개별 비트를 계산하는 두 종류의 atomic operation을 제공한다.
Atomicity(원자성)
물리학에서 일상적인 물질을 이루는 가장 작은 단위를 원자라고 하며, 쪼개지지 않는다는 성질을 가지고 있다. 이 성질 때문에 원자성이라고하면 한 작업이 방해받지 않고 진행되는 것이 보장되는 걸 의미한다.
1.1. Atomic Integer Operations
정수 atomic 메소드는 atomic_t 데이터 타입에서 실행된다. Atomic 함수들은 atomic_t 타입만 취급하고, 컴파일러 레벨에서도 최적화 하지 않는다. 또한 atomic_t의 사용은 아키텍쳐별 차이를 숨길 수 있다. 대부분의 경우에 atomic operation을 이용하는 것이 오버헤드가 적기 때문에 권장된다.
1.2. 64-Bit Atomic Operations
atomic_t는 32비트인 반면, 64비트인 atomic64_t도 존재한다. 다만 대부분의 32비트 운영체제에서 atomic64_t를 제공하지 않기 때문에 32비트인 atomic_t를 사용하는 것이 권장된다.
1.3. Atomic Bitwise Operations
Bitwise operaion의 경우 non-atomic한 함수도 제공한다. non-atomic한 함수는 atomic method 앞에 두개의 언더스코어(__)를 추가한다. 어느정도 안전성이 보장된 상황에 non-atomic 메소드를 이용해 성능을 올릴 수 있다.
int test_and_set_bit(int nr, void *addr); // Atomic
int __test_and_set_bit(int nr, void *addr); // Non-atomic2. Spin Locks
Critical region에서는 여러 함수가 실행되고 이것들이 atomic하게 발생되어야 한다. Atomic operation만으로는 이런 복잡한 환경을 제어하기 어렵기 때문에 조금 더 일반적인 lock을 이용해 동기화 문제를 해결한다. 리눅스에서 가장 일반적으로 이용되는 락은 spin lock이다. Spin lock은 하나의 쓰레드 실행에서만 가질 수 있다. Spin lock이 contended 된 상황에 쓰레드는 lock을 사용 가능해질 때 까지 루프를 반복한다(spin). Spin lock은 짧은 시간동안만 획득하는 가벼운 lock으로 디자인되었다. Lock이 contend된 동안 쓰레드를 재우거나(semaphore) 다른 코드를 실행하도록 할 수 있으나 약간의 오버헤드가 있다.
2.1. Spin Lock Methods
Spin lock은 아키텍쳐에 의존적이고 어셈블리에서 구현된다.
DEFINE_SPINLOCK(mr_lock);
spin_lock(&mr_lock);
/* Critical Region */
spin_unlock(&mr_lock);Spin lock은 인터럽트 핸들러에서도 사용될 수 있다(semaphore처럼 sleep하지 않기 때문). 인터럽트 핸들러에서 락을 이용하는 경우 락을 획득하기 전에 지역 인터럽트를 비활성화 해주어야한다.
DEFINE_SPINLOCK(mr_lock);
unsigned long flags;
spin_lock_irqsave(&mr_lock, flags);
/* Critical Region */
spin_unlock_irqrestore(&mr_lock, flags);
// interrupts are initially enabled
spin_lock_irq(&mr_lock);
spin_unlock_irq(&mr_lock);spin_lock_irq()와 spin_unlock_irq()함수도 존재한다. 주로 인터럽트가 항상 사용 가능한 경우에 쓸 수 있는 함수인데, 커널의 크기와 복잡도가 증가하면서 이 조건을 단정짓기 어려워졌기 때문에 권장하지 않는다.
2.2. Other Spin Lock Methods
spin_lock_init()함수는 spin lock을 동적으로 할당하는 함수이다. spin_trylock(), spin_is_locked()은 현재 락이 contended인지 아니면 사용 가능한지 확인한다. 이 외에도 여러 함수가 소개된다.
2.3. Spin Locks and Bottom Halves
Bottom half 작업중일때는 특정 locking 예방책이 필요하다. spin_lock_bh()는 락을 획득하고 모든 bottom half를 비활성화 한다.
Bottom half는 프로세스의 컨텍스트 코드를 preempt할 수 있기 때문에 만약 데이터가 bottom half 프로세스 컨텍스트에서 공유된다면 이 데이터를 보호하기 위해 lock을 이용하고 다른 bottom half를 비활성화 해야한다.
Tasklet의 경우 타입이 다른 두 tasklet이 데이터를 공유한다면 spin lock을 획득하고 데이터에 접근하도록 해야한다. Tasklet의 경우 같은 타입은 동시에 실행할 수 없고, 같은 프로세서에서 실행되는 tasklet을 preempt하지 않기 때문에 특수한 상황만 고려하면 되고, 따로 bottom half를 비활성화 할 필요도 없다.
Softirq의 경우 lock을 이용해 데이터를 보호해야한다. Softirq도 같은 프로세서에서 실행되는 다른 softirq를 preempt하지 않기 때문에 bottom half를 비활성화 할 필요가 없다.
3. Reader-Writer Spin Locks
Lock의 활용도는 reader와 writer로 구분된다. 예를 들어 어떤 리스트에 업데이트(쓰기)와 탐색(읽기)작업을 진행한다고 하면, 리스트가 업데이트 될 때는 다른 쓰레드가 쓰거나 읽는 것을 못하도록 해야한다. 반대로 리스트가 탐색중일 때는 아무 쓰레드도 쓰기를 못하게 막기만 하면 된다. 탐색중에 다른 쓰레드가 읽는 것은 데이터를 변화시키지 않기 때문에 safe하다.
따라서 데이터 구조가 reader/writer 혹은 consumer/producer 패턴으로 사용된다면 락킹 매커니즘도 이를 따라가면 된다. 리눅스 커널에서는 reader-writer spin lock을 제공한다. 여러 reader들은 동시에 reader lock을 획득할 수 있다. 반면 writer lock은 다른 reader가 없는 상황에 한 writer에게만 획득될 수 있다.
DEFINE_RWLOCK(mr_rwlock);
read_lock(&mr_rwlock);
/* Critical Region (read only) */
read_unlock(&mr_rwlock);
write_lock(&mr_rwlock);
/* Critical Region (read and write) */
write_unlock(&mr_rwlock);리눅스의 reader-writer spin lock은 reader를 더 선호한다. Read lock이 걸려있는 동안 writer는 대기해야하지만 reader는 계속해 lock을 획득할 수 있다는 것이다. Reader가 계속 있는 동안 writer가 계속해서 대기하는 상황이 발생할 수 있다.
4. Semaphores
리눅스의 Semaphore는 sleeping lock이다. 어떤 task가 세마포어를 획득하려고 한다면 세마포어는 해당 task를 대기큐에 넣어 sleep 상태에 놓는다. 세마포어가 사용 가능해지면 대기큐의 task를 깨워 세마포어를 획득한다. 세마포어를 이용하면 프로세서 활용이 더 좋아지지만 spin lock에 비해 더 큰 오버헤드가 발생한다.
- 세마포어는 긴 시간 획득되는 lock에 적합하다.
- 반대로, 세마포어는 짧은 시간 획득되는 lock에 부적합한데, 이는 sleeping의 오버헤드, 대기큐의 유지 문제, 다시 깨우는 시간 등 비용 문제가 더 크기 때문이다.
- 세마포어는 프로세스 컨텍스트에서만 획득되어야 한다.
- 세마포어를 획득하고 sleep해도 데드락이 발생하지 않는다. 다른 프로세스도 같은 세마포어를 획득할 수 있다.
- 세마포어를 획득하고 spin lock을 획득할 수 없다.
세마포어와 spin lock중 하나를 고를 때 lock을 소지하는 시간을 기준으로 결정해야한다. 세마포어를 이용하면 더 길게 lock을 소지할 수 있다.
4.1. Counting and Binary Semaphores
Spin lock과 다르게 세마포어는 여러 task가 획득할 수 있고 이 허용치를 usage count 혹은 count라고 한다. Count는 세마포어를 정의할 때 설정한다. Spin lock처럼 하나의 lock 홀더만 있는 세마포어라면 이를 binary semaphore 혹은 mutex라고 한다. Count > 1인 세마포어를 counting semaphore라고 한다. 세마포어를 사용하는 경우 대부분 mutex를 사용하고자 한다.
세마포어는 P()와 V()의 두 atomic operation을 지원한다. 리눅스에서는 이를 down()(=P())과 up()(=V())함수로 부른다. down()은 count를 1 감소시킴으로써 세마포어를 획득한다. 만약 count가 음수라면 task는 대기큐로 간다. up()은 세마포어를 풀고 count를 증가시킨다.
4.2. Creating and Initializing Semaphores
세마포어는 동적으로 생성되는 경우가 더 많다.
// 정적 생성
struct semaphore name;
sema_init(&name, count);
// 동적 생성
sema_init(sem, count);4.3. Using Semaphores
down_interruptible() 함수를 통해 세마포어를 획득한다. 세마포어를 획득할 수 없으면 해당 프로세스를 TASK_INTERRUPTIBLE 상태에 둔다. down() 함수는 태스크를 TASK_UNINTERRUPTIBLE 상태에 둔다. 신호에 반응하도록 하기 위해 대부분의 상황에서는 down_interruptible()함수를 이용한다.
5. Reader-Writer Semaphores
세마포어도 spin lock처럼 reader-writer가 있으며 그 관계역시 유사하다.
// 정적 생성
static DECLARE_RWSEM(name);
// 동적 생성
init_rwsem(struct rw_semaphore *sem);모든 reader-writer 세마포어는 mutex이다. 모든 reader-writer 락은 uninterruptible sleep을 이용하기 때문에 down함수도 한 종류만 있다.
down_read(&mr_rwsem);
up_read(&mr_rwsem);
down_write(&mr_rwsem);
up_write(&mr_rwsem);down_write_trylock(), downgrade_write()
6. Mutexes
Mutex는 상호 배제(mutual exclusion)를 지원하는 모든 sleeping lock을 의미한다. 세마포어의 count가 1인 경우 역시 이에 해당한다. 최근 리눅스 커널에서는 mutex를 상호 배제를 구현한 sleeping lock의 대명사로써 지정하였다.
Mutex는 세마포어에 비해 더 간편한 인터페이스와 더 높은 효율을 제공한다.
// 정적 생성
DEFINE_MUTEX(name);
// 동적 생성
mutex_init(&mutex);
mutex_lock(&mutex);
/* Critical Region */
mutex_unlock(&mutex);Mutex의 간단함과 효율성은 세마포어보다 더 제한적이다. Mutex의 이용 사례는 아래와 같다.
- 하나의 task만 mutex를 가질 수 있다.
- 한 컨텍스트에서 lock한 mutex를 다른 컨텍스트에서 unlock할 수 없다.
- 재귀적인 lock과 unlock은 허용되지 않는다.
- mutex를 가진 프로세스는 종료될 수 없다.
- 인터럽트 핸들러나 bottom half는 mutex를 획득할 수 없다.
- mutex는 공식 API만을 이용해 관리된다.
6.1. Semaphores Versus Mutexes
세마포어와 mutex는 비슷하다. 보통 세마포어는 low-level과 같은 특정 코드에서만 필요하다. Mutex에서 시작해 제한사항에 걸려 대안이 없는 경우에 세마포어로 변경하는 것이 좋다.
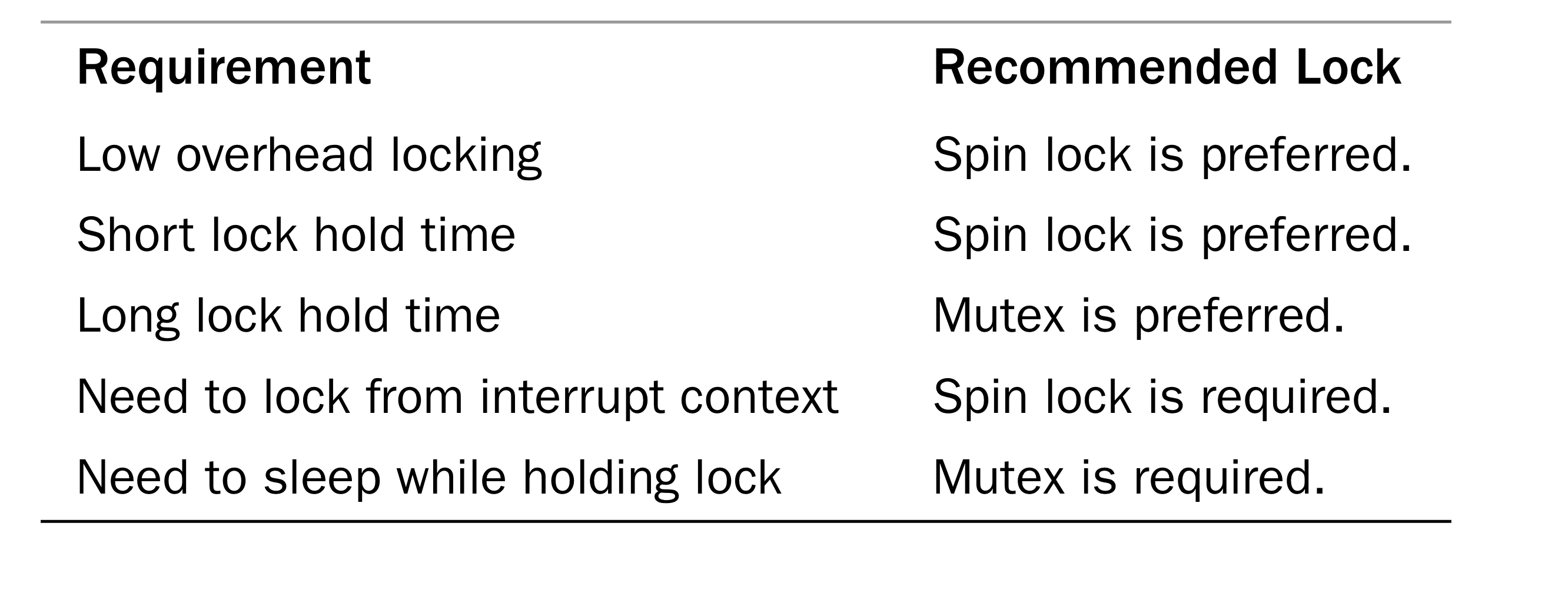
6.2. Spin Locks Versus Mutexes
인터럽트 컨텍스트에서는 spin lock만 이용할 수 있다.
7. Completion Variables
이벤트의 발생으로 한 task가 다른 task에게 신호를 보내야 하는 상황에서 커널의 두 task를 동기화 하기위해 completion 변수를 이용하는게 쉬운 방법이다. 한 task가 completion 변수를 기다리는 동안 다른 task는 일을 수행한다. 일을 마친 task는 completion 변수를 이용해 대기중인 task를 깨운다. 이는 세마포어와 상당히 유사한데, 실제로도 세마포어로 해결하지 못하는 문제들에 대한 간단한 해결책으로도 사용된다. 예를 들어 vfork()는 completion 변수를 이용해서 부모 프로세스를 깨운다.
8. BKL: The Big Kernel Lock
BKL은 리눅스의 원래 SMP 구현에서 세분화된 locking으로의 전환을 쉽게하기 위해 탄생한 전역 spin lock이다. BKL의 속성은 다음과 같다.
- BKL을 소지한 채로 sleep할 수 있다. Task가 스케줄되지 않으면 자동으로 드랍되고, 스케줄되면 다시 획득된다. 권장하지는 않지만 가능은 하다.
- BKL은 재귀적인 lock이다.
- BLK은 프로세스 컨텍스트에서만 사용할 수 있다.
- 새로운 BKL 사용자는 제한된다.
BKL은 아직 커널에서 종종 사용되지만, 이것의 사용은 현재 권장되지 않는다. BKL은 spin lock처럼 동작한다. BKL은 커널 preemption도 비활성화 한다. BKL의 주요한 문제는 데이터가 아닌 코드를 보호하는 경우가 많다는 것이다. 이 때문에 다른 lock으로 대체하기에 어렵다.
9. Sequential Locks
Sequential lock은 리눅스 커널 2.6버전에 새롭게 공개된 락이다. 공유 데이터를 읽고 쓰는데 간단한 방법을 제공한다. Sequence counter를 유지보수함으로써 동작한다. 데이터를 쓸때는 락을 획득하고 sequence number 증가시킨다. 데이터를 읽기 전과 읽고난 후에는 sequence number를 읽는데, 만약 두 값이 동일하다면 읽는 중 데이터 쓰기 작업이 발생하지 않은 것이다. 그리고 값이 짝수이면 쓰기가 진행중이지 않음을 의미한다.
seqlock_t mr_seq_lock = DEFINE_SEQLOCK(mr_seq_lock);
write_seqlock(&mr_seq_lock);
/* write */
write_sequnlock(&mr_seq_lock);
do {
seq = read_seqbegin(&mr_seq_lock);
/* read */
} while(reqd_seqretry(&mr_seq_lock));Seq lock은 많은 reader, 적은 writer가 있으며, writer를 reader보다 선호하는 경우(writer가 starve하지 않음) 사용되는 것이 이상적이다. 대표적인 활용 사례는 리눅스의 jiffies라는 변수이다.
10. Preemption Disabling
커널이 preemptive하기 때문에 커널의 프로세스는 더 높은 우선순위의 프로세스를 실행하기 위해 언제든 멈출 수 있다. 이는 이전 프로세스와 동일한 critical region에서 실행될 수 있다는 의미이기도 하다. 따라서 커널 preemption은 spin lock을 마커로하여 nonpreemptive 영역을 표현한다. Spin lock이 획득된 상태라면 커널은 preemptive하지 않다. 커널 preemption 관련 동시성 문제와 SMP는 같은 문제이기 때문에 커널이 SMP-safe하면 kernel preempt-safe하다.
반면 어떤 상황들은 spin lock을 필요로 하지 않지만 커널 preemption을 비활성화 하고싶다. 대표적인 상황이 프로세서별 데이터이다. 이를 해결하기 위해서 preempt_disable()함수를 이용해 커널 preemption을 비활성화할 수 있다. 이 함수는 중첩될 수 있기 때문에 preempt_disable()이 호출된 만큼 preempt_enable()이 호출되어야 한다. preempt count는 획득한 락의 수와 preempt_disable()의 호출 수를 저장한다. 이 값이 0이면 커널은 preemptive하다. preempt_count()함수를 통해 이 값을 확인할 수 있다.
프로세서별 데이터 문제에 대한 깔끔한 해결책으로 get_cpu()함수를 통해 프로세서 번호를 받아오는 방법이 있다. 이 함수는 커널 preemption을 비활성화하고 현재 프로세서 번호를 반환한다. 다시 커널 preemption을 활성화하라면 put_cpu()함수를 이용한다.
11. Ordering and Barriers
여러 프로세서 혹은 하드웨어 기기간 동기화 문제를 다루는데 있어서 프로그램 코드에 작성된 순서에 따른 메모리 읽기 및 쓰기 문제가 발생한다. 하드웨어와 통신할 때 주어진 읽기가 다른 읽기 혹은 쓰기 이전에 발생하도록 보장한다. 게다가 SMP 시스템에서는 쓰기작업이 코드에 적힌 순서대로 동작하는 것이 중요하다. 이 문제를 복잡하게 하는것은 컴파일러와 프로세서가 성능 향상을 위해 읽기쓰기를 재배치할 수 있다는 점이다. 다행히 프로세서와 컴파일러가 주어진 순서대로 작업을 진행하도록 강제할 수 있는데, 이 방법이 barrier이다.
컴파일러는 컴파일 타임에 재배치를 진행하기 때문에 정적이다. 반면 프로세서는 실행도중 동적으로 재배치를 진행한다.
a = 1;
b = a;다음과 같은 코드가 있다고 할 때, 프로세서나 컴파일러는 다른 컨텍스트에 있는 코드에 대해 알지 못한다. 가끔은 작성한 코드의 의도대로 특정한 순서에 맞게 보여지는 것이 필요하다.
rmb()함수는 읽기 메모리 barrier를 제공한다. 이는 이 함수 너머로는 어떠한 load도 재배치되지 않는 것을 보장한다. wmb()함수는 쓰기 barrier를 제공한다. 앞의 rmb()함수와 동일하지만 write에 대해서만 보장한다. mb()함수는 읽기와 쓰기 barrier를 제공한다.
rmb()의 변형 함수인 read_barrier_depends()는 후속 읽기가 의존하는 읽기들에만 읽기 barrier를 제공한다. 다시 말해 서로 의존하는 읽기에만 읽기 barrier를 보장한다.
barrier()함수는 컴파일러가 읽기나 쓰기를 최적화하지 못하도록한다.
References
- Linux Kernel Development (3rd Edition) by Robert Love
