Ch9. An Introduction to Kernel Synchronization
여러 쓰레드가 동시에 데이터를 접근하면서 각자 변경한 것들을 덮어씌울 수 있기 때문에 동시 접근하는 상황에서 공유 자원들이 보호되도록 보장해야한다. 과거에는 단일 프로세서만 지원되었기 때문에 커널 코드에 의해 인터럽트 되는 것 정도밖에 고려할 것이 없어 간단하게 처리할 수 있었다. 현재는 SMP(Symmetric multiprocessing)를 지원하며 커널 코드가 여러 다른 프로세서에서 실행될 수 있었다. 따라서 보호가 없는 환경에서 정확히 같은 시간에 공유 데이터에 동시에 접근하는 것 역시 가능해졌다.
1. Critical Regions and Race Conditions
공유 데이터를 접근하고 조작하는 코드 경로를 Critical region이라고 한다. 여러 쓰레드가 동시에 같은 자원에 접근해 실행되는 경우 안전하지 않은데, 이를 방지하기 위해 코드가 atomical하게 실행되어야한다. 만약 두 쓰레드가 같은 critical region에서 실행된다면 이를 race condition이라 한다. 안전하지 않은 동시성을 예방해 race 조건이 발생하지 않도록 보장하는 것을 synchronization이라고 한다.
1.1. Why Do We Need Protection?
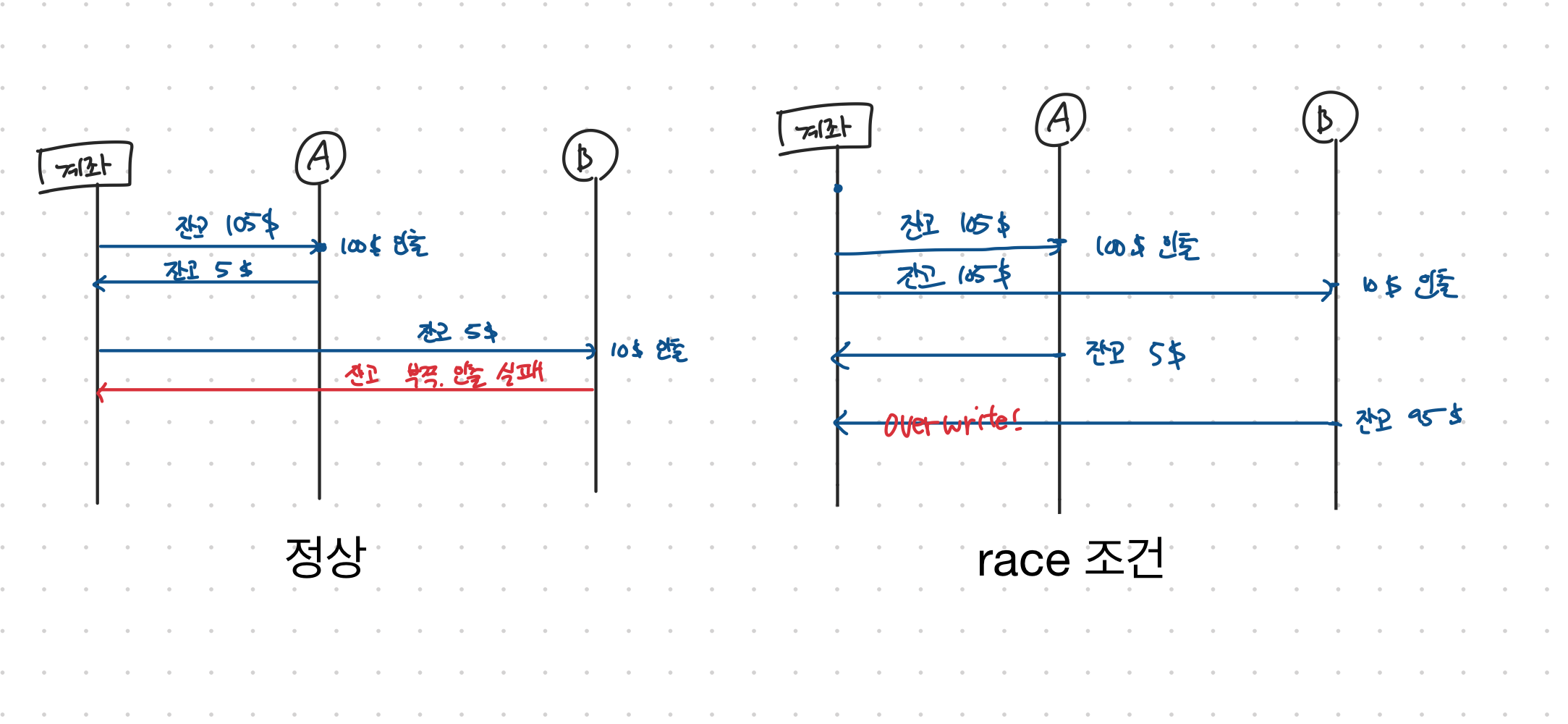
ATM에서 돈을 뽑는 것을 예로 들어 105달러가 있는 계좌에서 돈을 뽑는다 생각해보자. 10달러와 100달러를 뽑는 행위가 거의 동시에 발생한다고 생각해보았을 때 race 조건이 발생하면 105달러 계좌에서 100달러를 뽑고 5달러의 잔고를 작성한 후 105달러 계좌에서 10달러를 뽑고 95달러의 잔고를 덮어씌우는 경우가 발생할 수 있다. 따라서 한 거래가 끝나기 전에 해당 계좌를 잠궈두어 각각의 거래의 원자성을 보장하는 것이 필요하다.
1.2. The Single Variable

두개의 쓰레드가 동시에 한 변수를 수정하는 예시로, 동시에 같은 i값을 받아와 값을 증가시키고 다시 쓰는 과정이 두 쓰레드에 걸쳐 interleave 되어있다. 이를 해결하기 위해 증가시키고 그 값을 쓰는 과정을 atomic instruction으로 실행되도록 하면 된다.

2. Locking
조금 더 복잡한 예로, 요청을 담은 큐를 두개의 함수가 조작한다고 생각해보자. 첫번째 함수는 큐 마지막에 새로운 요청을 추가하는 것이고, 두번째 함수는 큐의 첫번째 요청을 삭제하는 것이다. 여러 쓰레드가 동시에 이 큐에 접근해 큐의 요청을 동시에 추가하거나 삭제하다보면 큐의 자료구조에 손상을 줄 수 있다. 따라서 한번에 한 쓰레드만 구조체를 조작할 수 있도록 하는 것이 중요하다. Lock을 이용하면 이를 해결할 수 있다. Lock을 보유한 쓰레드만 critical region에 들어가 데이터를 조작할 수 있도록 통제하여 데이터를 보호할 수 있다. 다른 쓰레드가 lock을 보유해 사용 불가능한 상태일 때의 행동은 그 방법에 따라 다르다. 어떤 것은 busy wait 하고 있고, 어떤 것은 현재 태스크를 sleep 상태에 놓는다. Lock은 atomic한 연산을 사용해 추가적인 race를 막는다.
2.1. Causes of Concurrency
유저 스페이스에는 프로세스가 언제건 preempt되고 다른 프로세스가 스케줄 될 수 있기 때문에, 프로세스가 예기치 못하게 critical region에 접근 중 preempt될 수도 있다. 그리고 새롭게 스케줄된 프로세스가 같은 critical region에 접근하면 race가 발생할 수 있는 것이다. 혹은 여러 싱글 쓰레드 프로세스가 공유 파일에 접근하거나, 신호를 받는 단일 프로그램에서도 동시성에 따른 문제가 발생한다. 이처럼 두가지가 실제로 같이 일어나는게 아니라 interleave되는 것을 pseudo-concurrency라고 한다.
만약 SMP를 지원하는 머신에서 두 프로세스가 정확히 같은 시간에 critical region에 접근하는 것이라면 이를 true concurrency라고 한다.
- Interrupts
- Softirqs and tasklets
- Kernel preemption
- Sleeping and synchronization with user-space
- Symmetrical multiprocessing
위의 항목들이 대표적인 동시성 문제의 원인들이다. 이런 내용들을 고려해 적절한 locking을 시작부터 디자인 하는 것이 좋다.
2.2. Knowing What to Protect
어떤 데이터가 보호가 필요한지 구분하는 것은 중요하다. 보통 보호가 필요 없는 데이터를 찾아내는 것이 더 쉽기 때문에 이를 시작으로 진행한다. 지역 변수, 동적으로 할당된 데이터 구조체 등 특정 쓰레드의 실행에 지역적인 데이터들은 보호가 필요 없다. 반면 전역 커널 데이터 구조체는 보호가 필요하다. 다른 쓰레드가 실행하며 데이터를 접근할 수 있는지 고민해보자. 종합하면 커널의 모든 전역적이고 공유되는 데이터가 동기화 기법이 필요하다.
3. Deadlocks
Deadlock은 각각의 쓰레드는 자원에 접근하기 위해 대기중이고, 모든 자원이 이미 사용중인 상황을 의미한다. 진전없이 모든 쓰레드가 계속 기다리기 때문에 데드락이 발생한다.

대표적인 예제가 ABBA 데드락이다. 각자 락을 가진 상태에서 다른 락을 요청하고 무한히 대기하는 상황이다.
데드락이 발생하지 않도록 코드를 짜는 것이 중요한데, 몇가지 좋은 규칙이 있다.
- lock ordering을 구현해라. 중첩 lock은 같은 순서대로 획득되어야한다.
- 이 코드가 항상 종료되는지 확인해라.
- 같은 락을 두번 획득하지 마라.
- 간단하게 디자인하라.
가장 중요한게 lock ordering의 구현이다. 예를 들어 cat, dog, fox의 세개의 락이 있는 상황에서 cat_lock은 dog lock 이전에 획득되어야 한다고 주석 등에 순서를 명시하는 것이다.
4. Contention and Scalability
Contention은 다른 쓰레드가 접근하려 하지만 이미 사용중인 lock을 의미한다. Lock이 자주 사용되거나 획득하고 긴시간 이용하는 경우 높은 contention이 일어났다고 말한다. Lock을 통해 동시에 데이터로 접근 하는 것을 직렬화 하여 하나씩 처리하기 때문에 높은 contention의 lock은 병목현상을 유발할 수 있다.
Scalability는 얼마나 시스템이 확장될 수 있는자에 대한 측정치이다. 운영체제 레벨에서는 많은 프로세스, 많은 프로세서, 혹은 많은 메모리를 scalability와 연관짓는다. 대부분의 lock은 전체 시스템같이 극단적으로 큰 데이터나 개별 요소와 같이 극단적으로 작은 데이터를 보호하는 것이 아닌 그 중간정도, 여러 구조체중 하나의 구조체정도, 를 보호하는 방향으로 되어있다.
리눅스 2.4버전과 그 이전 버전의 스케줄러는 하나의 runqueue를 사용했다. 리눅스 버전 2.6이 되어서 O(1) 프로세서가 프로세서별 runqueue를 도입하였고, lock 역시 하나의 전역 락에서 각 프로세서로 나눠진 락으로 발전되었다. Large machine에서는 단일 runqueue가 highly contended했기 때문에 이 변화는 성능을 높여줄 정도로 중요했다.
너무 coarse한 locking은 high lock contention인 경우 저조한 scalability를 보여주며, 너무 fine한 locking은 little lock contention인 경우 필요없는 오버헤드를 초래한다.
References
- Linux Kernel Development (3rd Edition) by Robert Love
