
안녕하세요! 코딩테스트 회고록입니다.
저번에 파이썬 코딩테스트 스터디를 만들고 꾸준히 공부하고 있습니다.
하루에 1~2문제를 풀고 팀원과 함께 공유하고 설명하며 서로의 코드를 리뷰하고 있습니다.
근 2주간 문제 풀이를 하며 느낀 것은 자료 구조에 대한 이해도 입니다.
특히, 스택(Stack), 데크(Deque), 큐(Queue)에 대해 이해하고 푸는 것이 알고리즘 문제와 연계되어 큰 공부가 되었습니다.
저의 문제풀이를 잠시 살펴볼까요!
스택(stack)
-
스택은 후입선출(LIFO, Last In First Out) 원칙을 따르는 자료 구조입니다.
-
스택의 주요 연산은 아래와 같습니다.
push: 스택의 맨 위에 요소를 추가합니다.pop: 스택의 맨 위 요소를 제거하고 반환합니다.peek/top: 스택의 맨 위 요소를 제거하지 않고 반환합니다.is_empty: 스택이 비어있는지 확인합니다.
스택의 구조는 아래 그림과 같이 작동합니다.

level1. 햄버거 만들기
def solution(ingredient):
answer = 0
# 햄버거 스택 초기화
hamburger = []
# ingredient 요소 순회
for i in ingredient:
# 햄버거에 쌓아주기 -> Push 과정
hamburger.append(i)
# 햄버거의 생성 조건 -> 1,2,3,1
# 즉, 숫자 4개의 나열이 1,2,3,1 이어야 한다.
# 스택구조에서 숫자의 나열은 슬라이싱으로 표현 가능
if hamburger[-4:]==[1,2,3,1]:
# 햄버거 추가!
answer+=1
# 만들었으면 해당 요소들은 pop!
for k in range(4):
hamburger.pop()
return answer-
이 문제의 포인트는 주어진 재료 리스트에서 연속된 [1, 2, 3, 1] 패턴을 찾아 햄버거 개수를 세는 문제입니다. 스택을 활용하여 재료를 쌓고, 조건을 만족하면 햄버거로 간주하여 개수를 세고 재료를 제거합니다.
-
문제를 보고 Stack 자료구조를 사용한 이유는 2가지가 있습니다.
- 순서 유지: 스택은 요소를 쌓는 순서를 유지할 수 있습니다. 재료가 입력된 순서대로 쌓이고, 가장 최근에 쌓인 재료부터 확인할 수 있기 때문에 [1, 2, 3, 1] 순서대로 재료를 쉽게 검증할 수 있습니다.
- 후입선출(LIFO): 스택의 후입선출(LIFO) 특성은 마지막에 추가된 재료부터 확인하고 제거하는 데 유리합니다.
큐와 데크(queue & deque)
- 큐는 선입선출(FIFO: First In, First Out) 원칙을 따르는 데이터 구조입니다. 즉, 먼저 들어온 데이터가 먼저 나가는 구조를 가지고 있습니다.
- 큐의 주요 연산은 2가지 입니다.
enqueue: 큐의 뒤에 데이터를 추가합니다.dequeue: 큐의 앞에서 데이터를 제거하고 반환합니다.
- 큐는 데이터의 삽입과 삭제가 큐의 양끝에서 각각 일어나므로 앞과 뒤를 명확하게 구분지을 필요가 있습니다.
front: 큐의 맨 앞, 데이터가 나가는 곳rear: 큐의 맨 뒤, 데이터가 들어오는 곳
큐의 구조는 아래 그림과 같이 작동합니다.

-
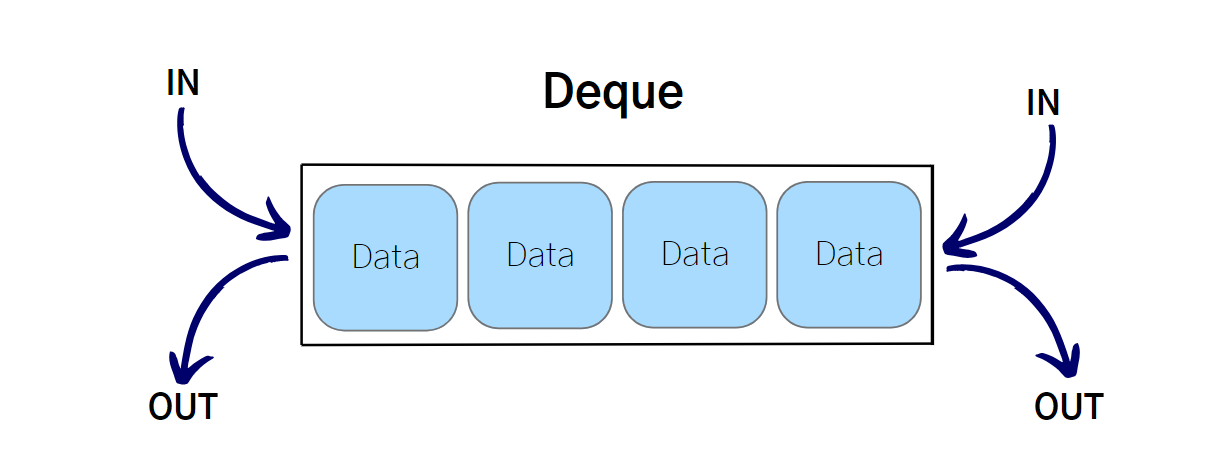
데크는 양쪽 끝에서 데이터를 추가하고 제거할 수 있는 데이터 구조입니다.
-
데크는 큐와 스택의 특성을 모두 가지고 있는 자료구조 입니다.
-
데크의 주요 연산은 아래와 같습니다.
addFront: 데크의 앞에 데이터를 추가합니다.addRear: 데크의 뒤에 데이터를 추가합니다.removeFront: 데크의 앞에서 데이터를 제거하고 반환합니다.removeRear: 데크의 뒤에서 데이터를 제거하고 반환합니다.
데크의 구조는 아래 그림과 같이 작동합니다.
level0. 배열 회전시키기
from collections import deque
def solution(numbers, direction):
# 주어진 numbers를 데크 구조로 변환
d_number = deque(numbers)
# 만약 right라면 데크에서 가장 오른쪽 원소를 pop
if direction == "right":
temp = d_number.pop()
# pop으로 추출한 원소를 다시 appendleft를 이용하여 맨 왼쪽에 추가
d_number.appendleft(temp)
# 만약 left라면 데크에서 가장 왼쪽 원소를 popleft
elif direction == "left":
temp = d_number.popleft()
# popleft로 추출한 원소를 다시 append를 이용하여 맨 오른쪽에 추가
d_number.append(temp)
return list(d_number)-
이 문제의 포인트는 주어진 배열을 왼쪽이나 오른쪽으로 한 칸씩 회전시키는 것입니다. 그렇기 때문에 양쪽의 삽입 및 삭제가 유용한 데크(deque)를 사용하면 쉽게 풀 수 있는 문제죠.
-
deque의 오른쪽 끝 요소를
pop하여 제거하고, 이를 왼쪽 끝에appendleft로 추가합니다. deque의 왼쪽 끝 요소를popleft로 제거하고, 이를 오른쪽 끝에append로 추가합니다. -
문제를 보고 데크를 사용한 이유입니다.
효율적인 연산: deque는 양 끝에서의 삽입과 삭제가 O(1) 시간복잡도를 가지므로, 배열의 양 끝에서 요소를 제거하고 추가하는 연산이 매우 빠르게 수행됩니다.
마무리
오늘은 간단하게 느낀 점과 더불어 스택과 큐,데크에 대해 간단히 알아봤습니다.
물론 2주간 2문제만 푼게 아닙니다!!!
꽤 많이 풀었지만 이 곳에서 전부 적으면 글이 길어질거 같아 간단한 회고와 간단한 문제를 알아보았습니다.
코테 스터디를 진행하면서 배운 점이나, 코테를 위해 추가로 학습하는 내용들은 따로 포스팅할 예정이며, DFS와 BFS, heapq 이 다음 내용이 되지 않을까 싶어요.
담에 또 찾아오겠습니다!
