본 포스팅의 내용은 Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani, Jonathan Taylor (2023), 「An Introduction to Statistical Learning with Applications in Python」, Springer 를 참고하였습니다.
4.4 생성모형을 이용한 분류
지금까지는 로지스틱회귀를 통해 의 을 모형화하였다.
이제는 이 확률을 추정하는 또 다른 대안이면서 덜 직접적인 방법을 고려한다.
새로운 접근법에서는 예측변수 X의 분포를 반응변수 부류마다 개별적으로 나누어 모형화한다.
그런 다음 베이즈 정리(Bayes' theorem)를 사용해 이를 의 추정값으로 전환한다.
또한 이 모형은 각각의 부류 내에서 X의 분포가 정규분포로 가정될 때 로지스틱 회귀와 매우 유사한 형태이다.
로지스틱 회귀가 있음에도 불구하고 왜 다른 방법이 필요할까?
-
두 부류 사이에 상당한 분류가 있을 때 로지스틱 회귀모형의 모수 추정값은 불안정하다.
-
각각의 부류에서 예측변수 X의 분포가 대략 정규분포를 따르고 표본 크기가 작다면 이 절의 접근법은 로지스틱 회귀보다 더 정확할 수 있다.
-
이 절의 방법들은 반응변수가 두 개 이상인 부류로 자연스럽게 확장될 수 있다.
베이즈 정리
를 만족하는 개의 부류 중 하나의 집합에 대한 관측을 할 때,
우리는 질적 반응변수 는 의 집합에 따라 다를 것이고,
이때 를 랜덤하게 선택한 관측이 k번째 부류에 속할 전체 또는 사전확률(prior probability)이라고 하자.
는 번째 부류에 있는 관측값이 일 확률이 높으면 상대적으로 클 것이고, 매우 낮으면 작다.
'베이즈 정리'는 다음과 같이 정의할 수 있다.
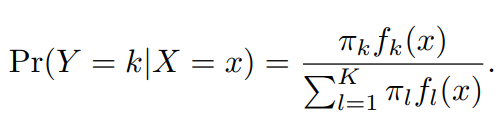
이는 모든 k개의 집단 속에서, 가 번째 해당하는 부류에 속할 확률이라는 것을 의미한다.
로 관측값 가 번째 부류에 속할 사후확률(posterior probability)를 의미한다.
그 말인 즉슨, 예측값이 주어졌을 때, 그 값이 번째 부류에 속할 확률을 의미한다.
앞서 논의했던 로지스틱회귀 함수에서 를 직접 구하는 것이 아닌 추정값을 식에 적용할 수 있음을 시사한다.
예를 들어 는 추정하는 일은 쉬운데, 번째 부류에 속하는 훈련 관측의 비율을 보면 된다.
하지만 밀도함수인 을 추정하는 일은 어렵기 때문에 몇 가지 단순화 가정을 거친다.
2장에서 논의한 것처럼 관측값 를 가 최대가 되는 부류로 분류하는 베이즈 분류기(bayes cassifier)가 모든 분류기 중에서 가장 오류율이 낮다.
따라서 밀도함수 를 추정할 수 있다면 베이즈 분류기에 근사가 가능하다.
여기에서는 서로 다른 추정값을 이용해 베이즈 분류기를 근사하는 선형판별분석(linear discriminant analysis), 이차판별분석(quadratic discriminant analysis), 나이브 베이즈(naive bayes)에 대해 논의할 예정이다.
4.4.1 인 선형판별분석
예측 변수가 1개일 때를 가정해보자. 를 추정하기 위한 의 추정값을 구해보자.
그 이후, 가 최대가 되는 부류로 관측을 분류할 것이다.
를 추정하기 위해서는 형태에 대해 몇가지 가정을 해야한다.
먼저 가 정규분포(normal distribution), 또는 가우스 분포(Gaussian distribution)
라고 가정해보자. 1차원일 경우 정규분포 밀도함수는 다음과 같다.
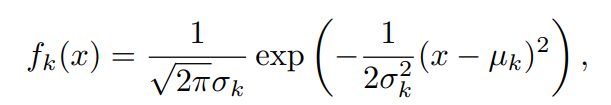
이 식에서 번째 부류에 대한 평균과 분산은 각각 이다. 위 식을 앞의 베이즈 정리에 대입을 해본다면 다음과 같은 식을 도출할 수 있다.
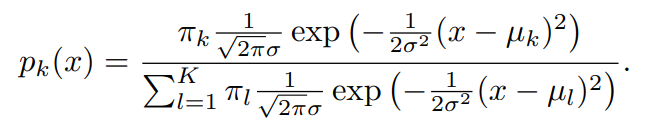
여기서 는 원주율이 아닌 사전확률을 의미한다.
베이즈 분류기는 해당식이 최대가 되는 부류에 관측값 를 할당하는 과정을 포함한다.
이를 로그를 취하고 행을 재배열 해보자.



해당 과정을 통해 결정함수에 대한 식을 알 수 있다.
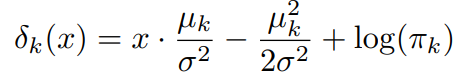
예를 들어 관측 부류인 K=2이고, 사전확률이 같은 경우, 베이즈 분류기는 결정함수를 통해 관측값의 부류를 추정할 수 있다.
사전확률을 같으므로 생략, 각 결정함수에 k=1, k=2 대입후 계산했을 때 구간인 베이즈 결정 경계(bayes decision boundary)를 알 수 있다.
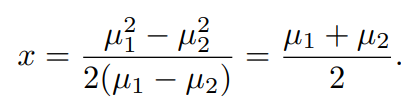
x 값이 크다면 클래스 1로, 작으면 2로 분류된다.
다음은 예시 그림이다.
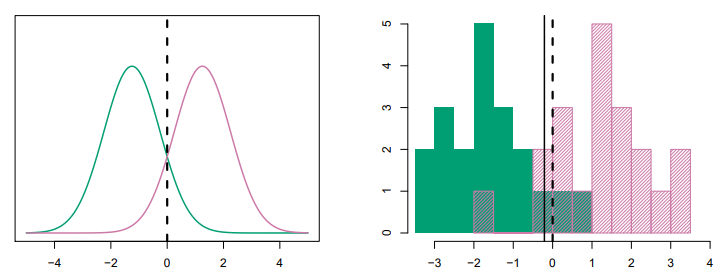
[그림 4.4] 왼쪽: 두개의 1차원 정규 밀도 함수. 오른쪽: 두 부류에서 20개의 관측값이 추출되어 히스토그램에 표시된 그림.
왼쪽 그림에서 두개의 부류일 때의 정규분포를 나타낸 것을 알 수 있고,
검정색 파선은 베이즈 결정 경계로 파선 을 기준으로 왼쪽은 부류 1로, 오른쪽은 부류 2로 분류 된다.
이 경우는 각각의 부류가 가우스 분포를 따르고 모든 모수를 알고 있기 때문에 베이즈 분류기를 계산할 수 있었고, 실제로는 베이즈 분류기를 적용하기 위해서는 모수와 사전확률, 분산을 추정해야한다.
선형판별분석(LDA) 방법은 에 대한 추정값을 적용해 베이즈 분류기를 근사하려고 한다.
다음과 같은 추정값이 사용된다.
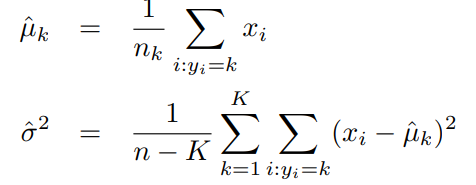
= 훈련 관측의 총 개수, = 번째 부류에 관측된 부류의 훈련관측 개수이다.
분산에 대한 추정값은 각각의 부류에 대한 표본분산의 가중평균으로 볼수 있다.
많은 베이즈 분류기에서 클래스별 분산이 같다고 가정, 모든 부류에 대해 동일한 분산을 추정하는 방식일 때, 가중평균 방식으로 결합해 정체 공통 분산을 추정한다.
가중평균을 사용하는 이유: 각 클래스별 표본 크기가 다를 수 있어, 단순 평균보다 각 클래스의 데이터 개수를 반영한 가중 편균이 더 정확한 분산 추정치를 제공할 수 있다.
사전 확률의 정보를 알고 있다면 직접 사용할 수 있고, 정보가 없는 경우에는 다음과 같이 훈련 관측 비율을 사용해 다음과 같이 추정한다.
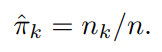
LDA 분류기는 위에 주어진 식을 대입해 다음 식이 최대가 되는 부류에 관측값 를 할당한다.
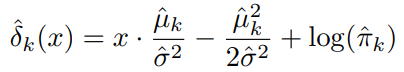
[그림 4.4]의 오른쪽 그림은 20개의 랜덤 추출한 것에 대한 히스토그램이다.
LDA 구현을 위해 을 추정했고, 최대가 되는 값을 녹색 실선으로 계산했다.
이 데이터에서는 최적의 베이즈 결정 경계보다 살짝 왼쪽에 위치해 있다. 베이즈 오류율과 LDA 테스트 오류율을 계산하기 위해 많은 수의 테스트 관측값을 생성할 수 있다.
베이즈 오류율과 LDA 테스트 오류율은 로 적은 차이가 나고 있어 설명을 잘 하고 있다.
LDA 분류기는 각 부류내의 관측값이 부류별 평균과 공통 분산을 가진 정규분포에서 나온 것을 가정한 것이고, 이 모수들에 대한 추정값을 베이즈 분류기에 적용해 결과를 도출한 것이다.
4.4.2 인 선형판별분석
이번에는 1차원이 아닌 부류별 평균 벡터와 공통의 공분산행렬을 가지는 다변량 가우스 분포(multivariate Gauss distribution, 다변량정규분포)에서 추출된다고 가정한다.
다변량 가우스 분포는 각각의 개별 예측변수가 1차원 정규분포를 따르며 예측변수 쌍 사이에는 일정한 상관관계를 가진다고 가정한다.
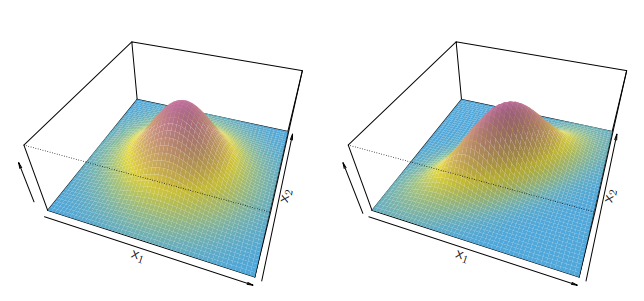
[그림 4.5] 두 개의 다변량 가우스 밀도함수로, 변수가 2개일 때 결과. 예측변수 간 상관관계에 따른 결과.
다음은 다변량 가우스 밀도함수이다.
축을 기준으로 표면을 잘랐을 때는 정규분포를 띄는 것을 알 수 있다.
왼쪽은 이고, 를 만족하는 밀도함수이고,
오른쪽은 인 밀도함수이다.
여기서 알 수 있는 점은 분산이 같고, 상관관계가 없은 밀도함수는 표면이 '종 모양'을 띄고 있다.
만약 상관관계가 다를 경우 오른쪽 그림처럼 표면이 '타원형' 모형으로 왜곡된다.
차원 확률변수 가 다변량 가우스 분포를 따른다는 것을 나타내려면 이라고 쓴다. 여기서 (p 성분을 가진 벡터)의 평균이고, 는 의 공분산행렬이다.
다변량 가우스 밀도는 다음과 같이 정의한다.
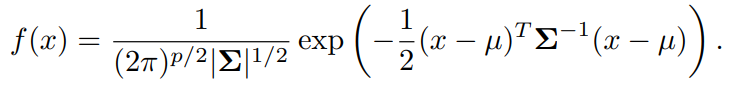

예측변수의 개수가 p>1인 경우 LDA 분류기는 k번째 부류의 관측값들이 다변량 가우스 분포 에서 추출된 것이라고 가정한다.
는 부류별 평균 벡터, 은 모든 부류에 대한 공분산행렬이다.
k번째 부류의 밀도함수 를 앞서 논의했던 식에 정리하면 관측값 가 최대가 되는 부류에 할당한다.
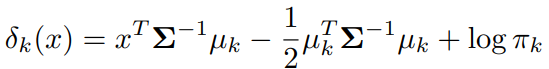
변화의 차이는 다음과 같다.
위 식을 통해 예시를 나타낸 그림이다.
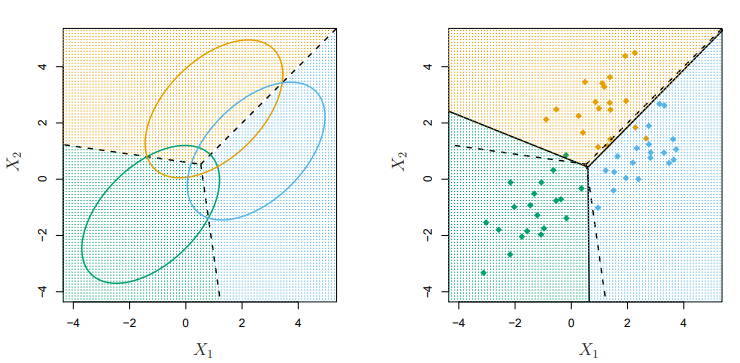
[그림 4.6] 세 개의 부류가 있는 예제. 공통의 공분산 행렬을 가지는 인 다변량 가우스 분포, 왼쪽: 모수에 대한 참 값을 나타낸 그림. 오른쪽: 표본 추출 20개
선형판별분석에서 중요한 가정은 공분산행렬이 동일하다는 것이다.
왼쪽 그림에서는 세 개의 타원은 각 부류의 확률이 95%인 영역을 나타낸 것이다.
또한 검정색 파선은 베이즈 결정경계를 나타낸다.(
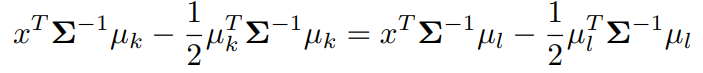
( 인 경우 관측값이 동일하기 때문에 사전확률은 사라진다.
다시 한번 미지의 모수 를 추정해야한다. 공식은 1차원 사례와 동일하다.
새로운 관측 을 할당하기 위해 LDA는 이 추정값들을 결정함수에 대입해 의 양을 구하고, 가 최대가 되는 부류로 분류한다.
여기서 결정함수는 선형함수라는 점을 유념해야한다.
(직관적 해석 가능, 비선형일 경우 베이즈 결정경계가 곡선이 될 수 있음)
오른쪽 그림은 세 부류 각각에서 추출한 20개의 관측값과 그에 따른 LDA 결정경계를 검은색 실선으로 나타냈다.
베이즈 분류기와 LDA결정경계의 테스트 오류율은 0.0746, 0.0770이다.
다시 예제로 돌아가 Default 데이터에서 신용카드 잔액과 학생 여부에 기반해 개인의 연체 여부를 예측하는 LDA를 수행할 수 있다.
10,000개의 훈련 표본에 적용된 LDA 모형은 '훈련' 오류율이 2.75%로 나타났다. 여기서 두 가지 주의할 점이 있다.
- 일반적으로 훈련 오류율이 테스트 오류율보다 낮다. 모수의 개수 비율과 표본의 개수의 비율이 높으면 과적합이 일어나 성능이 나빠질 수 있지만, 이 경우는 아니다.
- 훈련 표본에서 3.33%만이 연체한 경우에 예측변수와는 관련없이 항상 연체하지 않을 것이라고 예측할 가능성이 있다. 뻔한 영분류기(null classifier)은 LDA 훈련세트 오류율 보다 약간 높은 오류율을 보인다.
이와 같은 이진 분류기는 두 가지 유형의 오류를 범할 수 있다.
default -> no default로 잘못 할당하거나, 반대의 경우.
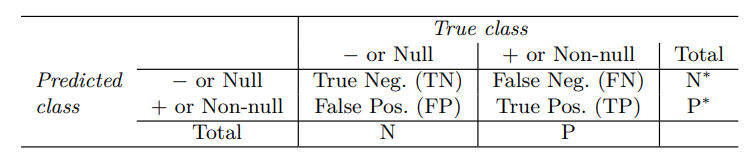
혼동행렬(confusion matrix)는 이러한 정보를 표시하는 편리한 방법이다.
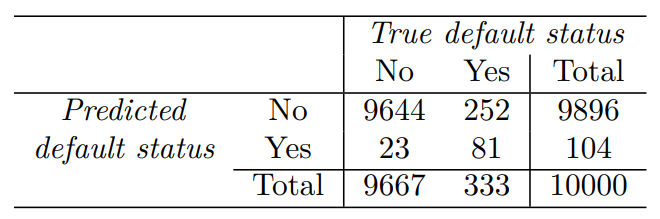
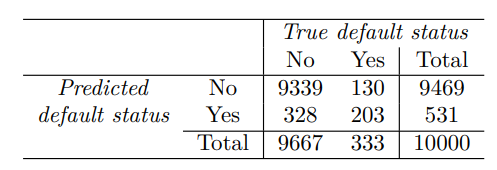
여기에서 LDA는 104명이 연체하지 않을 것이라고 판단했고, 81명은 실제로 연체했으며, 23명은 연체하지 않았다. 매우 낮은 오류율처럼 보이지만, 실제로 333명에서 81명만을 예측해 연체한 개인에서 오류율은 매우 높다.
민감도(sensitive)와 특이도(specificity) 용어를 통해 분류기나 선별 테스트의 성능을 특징짓는데, 이때 부류별 성능이 중요하다.
민감도는 실제 연체자를 찾는 비율로, 24.3%이다.
특이도는 연체하지 않은 사람들이 올바르게 분류된 비율로 99.8%이다.
왜 LDA는 민감도가 낮게 나타날까?
왜냐하면 LDA는 '전체' 오류율을 최소화하는 베이즈 분류기에 근사하려고 하기 때문이다.
실제 연체자: 333명, 실제 비연체자: 9667명으로 비연체자에 대한 정확도를 높이기 위해 실제 연체자에 오류가 남에도 불구하고 잘못 할당한 것이다.
즉, 전체의 3%에 해당하는 오류율을 범하더라고 97%의 오류율을 최소화하는 과정에서 오류가 발생한 것이다.
베이즈 분류기는 사후확률이 최대가 되는 부류에 관측값을 할당하는 방식으로 작동한다.

따라서 베이즈 분류기와 LDA는 관측값을 default 부류에 할당하기 위해 사후 연체확률에 대해 50%의 임곗값을 사용한다.
그러나 연체한 개인의 연체 상태를 잘못 예측하는 것이 우려될 때, 임곗값을 낮추어 민감도를 높일 수 있다.
예) 사후 연체 확률을 20%로 내렸을 때
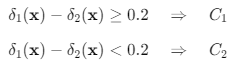

이 식을 통해 LDA 판별분석을 했을 때 결과는 다음과 같다.
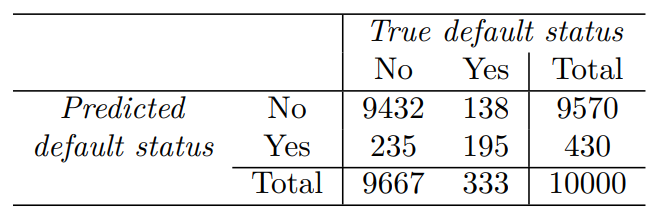
여기서는 58.6%의 민감도를 가진다. 그러나 전체 오류율을 3.33%에서 약간 증가한 3.73%이다.
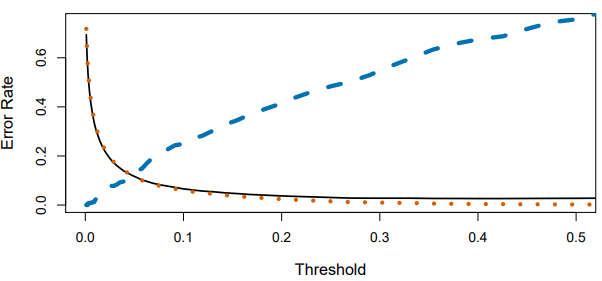
[그림 4.7] Default 데이터 세트에서 할당을 수행하는 사후확률의 임곗값의 함수
이 그림은 사후 연체 확률의 임곗값을 수정하면서 발생하는 트레이드오프를 보여주다.
베이즈 분류기는 임곗값이 0.5일 때 가장 낮은 전체 훈련 오류율(검정색 실선)을 보인다.
연체하지 않은 개인 사이의 오류율(주황색 파선) 또한 이에 따라 감소한다.
하지만 연체한 개인 사이의 오류율(파란색 파선)은 그와 반대로 오류율이 증가한다.
어떤 임계값이 최적인지 어떻게 결정할 수 있을까?
이러한 결정은 상세한 비용 정보 같은 '도메인 지식'을 바탕으로 이루어진다.
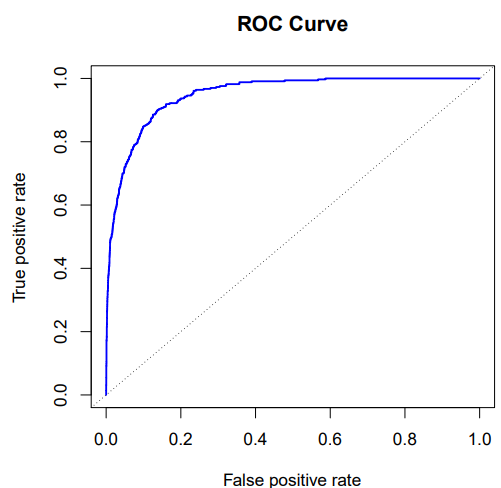
[그림 4.8] Default 데이터에 대한 LDA 분류기의 ROC 곡선
'ROC'곡선은 임계값에 대해 두 가지 유형의 오류를 동시에 표시하는 그래프이다.
수신자 조작 특성(receiver operating characteristics)의 약어이다.
요약된 분류기의 전반적인 성능은 곡선아래면적(AUC, area under the curve)
으로 주어진다.
이상적인 ROC 곡선은 왼쪽 상단 모서리를 감싸고 있으므로 AUC가 클수록 분류기의 성능이 우수하다고 말할 수 있다.
ROC 곡선은 가능한 모든 임곗값을 고려하기 때문에 다양한 분류기를 비교하는 데 유용하다.
이처럼 분류기의 임계값을 변경하면 참 양성률(true positive)와 거짓 양성률(false positive)가 달라진다.

4.4.3 이차판별분석
앞서 논의 했던 LDA의 중요한 가정은 각 부류 내의 관측값이 부류별 평균 벡터와 모든 K 부류에 공통적인 공분산행렬이 있는 다변량 가우스 분포에서 추출된다고 가정했다.
이차판별분석(QDA)은 또 다른 접근법을 제공한다.
먼저 LDA와 마찬가지로 관측값이 가우스 분포를 따른다고 가정하고, 모수의 추정값을 베이즈 정리에 대입한다.
여기서 차이점은 QDA는 각각의 부류가 자체 공분산행렬을 가진다고 가정한다.
즉, 형태라고 가정하며 여기서 는 k 번째 부류의 공분산행렬이다.
이런 가정 하에 베이즈 분류기는 관측값이 최대가 되는 부류에 를 할당한다.
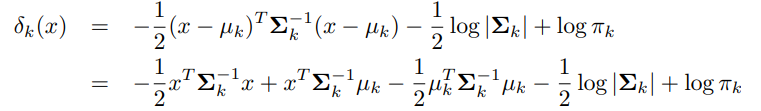
기존 LDA 결정함수는 양적 변수 는 이차함수로 나타내는 이차항이 모든 부류에서 같기 때문에 무시되었지만, QDA에서는 무시할 수 없기 때문에 식에 남았고, 이를 QDA라고 부르게 되었다.
K의 부류가 공통 공분산행렬을 공유하는지에 대한 여부가 중요한 이유는 무엇일까?
LDA와 QDA 분류기를 선호하는 기준은 편향-분산 트레이드오프(bias-variance trade-off)에 있다.
예측변수가 개일 경우 공분산행렬을 추정하면 개의 모수를 추정하는 게 필요하다.
반면 부류가 공통 공분산행렬을 공유한다고 가정하면 LDA 모형은 에 대해 선형이 되고, 이는 개의 선형 개수를 추정해야 한다는 것을 의미한다.
따라서 LDA는 QDA보다 유연성이 떨어지는 분류기로 분산이 낮다. 이는 예측 성능의 향상으로 이어질 수 있다.
그러나 공통 공분산행렬의 가정에서 크게 벗어날 경우 높은 편향값을 가지게 될 것이다.
따라서 훈련 관측값이 적고, 분산을 줄이는 것이 중요하다면 LDA를 선택하는 것이 합리적이고,
훈련 관측값이 크고, 분산을 고려하지 않거나, 공통 공분산행렬의 가정을 할 수 없는 경우 QDA를 선택하는 것이 합리적인 선택이다.
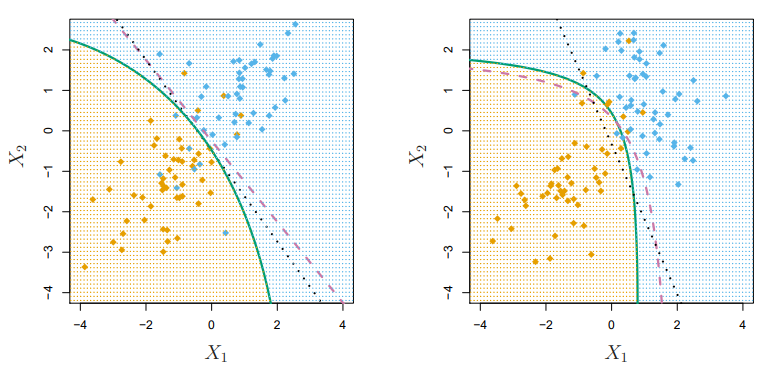
[그림 4.9] 왼쪽: 공분산행렬이 같을 때에 대한 베이즈,LDA, QDA. 오른쪽: 공분산행렬이 다를 때.
베이즈 분류기(보라색 파선), LDA(검은색 점선), QDA(녹색 실선)는 부류의 상관관계에 따라 다르게 표현된다.
왼쪽 그림은 두 부류의 상관관계가 같으므로 LDA 결정경계가 가 베이즈 분류기에 더 근사한다는 것을 알 수 있다.
오른쪽 그림은 두 부류의 상관관계가 다를 경우로, QDA 결정경계가 베이즈 분류기에 더 근사하다는 것을 알 수 있다.
4.4.4 나이브 베이즈
여기서는 베이즈 정리를 사용해 만들어진 '나이브 베이즈' 분류기를 다룬다.
베이즈 정리는 앞서 논의한 것처럼 사후 확률 을 와 의 추정값이 필요하고, 를 구하는 일은 쉽다.
밀도함수인를 추정하는 방법은 어렵다.
는 번째 부류의 관측에 대한 차원 밀도함수임을 기억할 필요가 있다.
LDA에서는 작업을 단순화 하기 위해 가정을 한다.
가 부류별 평균 와 공통 공분산행렬이 있는 다변량 정규 확률변수에 대한 밀도함수라고 가정한다.
QDA에서는 작업을 단순화 하기 위해 가정을 한다.
가 부류별 평균 와 부류별 공분산행렬이 있는 다변량 정규 확률변수에 대한 밀도함수라고 가정한다.
이러한 가정을 통해 개 차원 밀도함수를 추정하는 까다로운 문제를 개 차원 평균 벡터와 하나 또는 개 차원 공분산행렬을 추정하는 간단한 문제로 대체할 수 있다.
나이브 베이즈 분류기는 의 추정하는데 또 다른 접근법을 취한다.
이 함수들이 특정분포족(예: 다변량정규분포)에 속한다고 가정하는 대신 단일 가정을 한다.
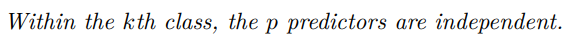
k번째 부류 내에서 예측변수 p는 독립이다.
수학으로 표현했을 때 다음과 같다.
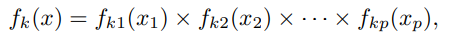
는 번째 부류에서 번째 예측변수의 밀도함수를 의미한다.
기본적으로 차원 밀도함수를 추정하는 일은 각 예측변수의 주변분포 뿐만 아니라 예측변수의 결합분포, 즉 서로 다른 예측변수 사이의 연관성을 고려해야 하기 때문에 어렵다.
다변량정규분포의 경우 서로 다른 예측 변수 사이의 연관성은 공분산행렬의 비대각원소로 요약된다. 일반적으로 이러한 연관성을 특성화하기 어렵고 추정하기도 까다롭다.
하지만 공변량이 각 부류 내에서 독립이라고 했을 때, 이러한 연관성을 고려할 필요가 없다.
즉, 를 추정하기 위해서는 각각의 1차원 밀도 만 추정하면 된다.
하지만 대다수의 상황에서 이러한 예측변수의 독립성이 나타나지는 않는다.
그럼에도 불구하고 해당 가정으로 모형을 만들었을 때, 성능이 좋은 결과를 보이기도 한다.
그 경우는 이 에 비교해 충분히 크지 않아 각 부류 내 예측변수들이 결합분포를 효과적으로 추정할 수 없는 경우 그렇다.
실제고 결합분포를 추정하기 위해서는 많은 데이터의 양이 필요하므로 나이브 베이즈가 좋을 수 있다.
또한 나이브 베이즈 가정은 약간의 편향의 증가를 야기하지만 분산을 감소시켜 편향-분산 트레이드 오프 결과로 잘 작동하는 분류기를 만든다.
나이브 베이즈 가정하에 베이즈 정리의 사후확률을 계산하는 식을 변형하면 다음과 같다.
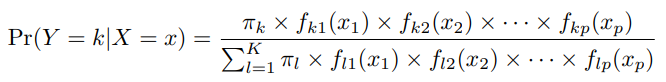
여기서 훈련 데이터 를 사용해 1차원 밀도함수 를 추정하기 위해 몇 가지 옵션이 필요하다.
- 가 양적일 때, 이라고 할 수 있다.
즉, 각 부류 내에서 j번째 예측변수가 정규분포에서 추출된다고 가정한다.
QDA 또한 비슷하지만 나이브 베이즈는 예측변수가 독립이라고 가정한다는 점에서 차이가 있다.
(여기서 부류별 공분산행렬은 대각행렬으로, 비대각원소가 모두 0이므로 공분산은 0이다.)
-
가 양적일 때, 비모수 방법으로 추정이 가능하다.
간단한 방법은 각 부류의 관측값에 대한 히스토그램을 만들어 와 동일한 히스토그램 구간에 속하는 번째 부류에서 훈련 관측값의 비율로 을 추정 가능하다. -
가 질적 변수일 때, 번째 예측 변수의 훈련 관측 비율을 계산 가능하다.
예를 들어 100개의 관측치가 1,2,3을 만족할 때 를 다음과 같이 추정할 수 있다.
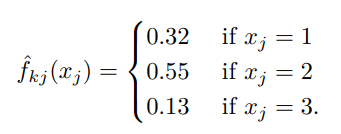
이제 예측변수 인 토이 예제를 통해 베이즈 분류기를 살펴보자.
그리고 예측변수 3개 중 2개는 양적변수, 1개는 수준이 3개인 질적변수이다.
또한 사전확률 라고 가정해보자.
이고, 인 추정 밀도함수는 다음과 같다.
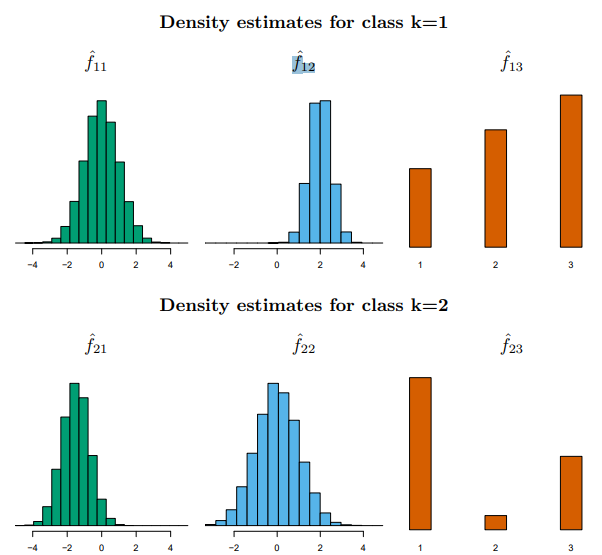
[그림 4.10] 각 부류에서 세 예측변수 각각의 추정밀도를 보여주고 있다.
새로운 관측값 을 분류할 때 위 그림을 통해 나온 추정값을 나이브 베이즈의 사후확률 추정식에 대입했을 때 , 으로 해당 관측값은 첫 번째 부류에 분류될 확률이 높다.
다음은 Deafault 데이터 세트에 나이브 베이즈 분류기를 적용한 결과 만들어진 혼동행렬이다.
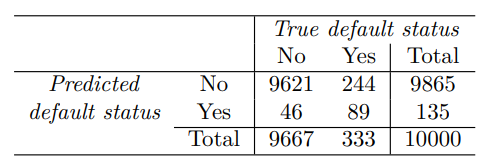
여기서 사후 확률 는 연체(default)라고 예측한다.
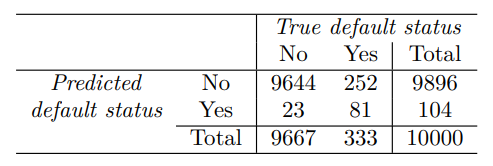
기존 LDA를 결과의 차이를 비교해본다면 LDA의 전체 오류율이 약간 낮은 반면, 나이브 베이즈는 연체자를 더 높은 비율로 올바르게 예측한다.
나이브 베이즈의 이 구현에서는 각각의 양적 변수가 가우스 분포에서 도출된다고 가정하며, 각 부류에서 예측변수는 독립이라고 가정한다.
여기서 연체로 예측하기 위한 확률 임곗값을 이라고 한다면 다음과 같다.
전체 오류율은 증가했고, 실제 연체자의 3/2 정도 예측에 성공했다.
이 예제에서는 나이브 베이즈가 LDA를 눈에 띄게 성능이 좋다고 할 수는 없다.
n=10,000이고, p=2이므로 나이브 베이즈 가정으로 생긴 분산의 감소가 반드시 유익한 것은 아니다.
예측변수가 더 많거나, 관측치가 더 작아 분산의 감소가 중요한 경우에는 나이브 베이즈를 사용하는 것이 LDA나 QDA에 비해 더 큰 이점을 가진다.
