나는 연구 주제를 선정함에 있어 주제가 흥미로운지, 비슷한 연구는 없는지에 대한 물음을 되새기며 진행하려고 노력한다.
최근 3개월 간 가장 큰 화두는 12월 3일 비상계엄 사건이라고 할 수 있고, 나를 포함한 많은 사람들에 대한 관심을 이끌고 있다.
따라서 비상계엄를 바라보는 매체의 다양한 시각을 텍스트 마이닝을 통해 분석하는 것을 주제로 삼았다.
1. 서론
1.1. 연구 배경
언론의 사건 보도는 사건에 대한 메시지를 전달하는 중요한 역할을 하고 있다.
또한 언론은 사건에 대한 인물의 판단을 여러 단어를 통해 긍정적, 또는 부정적으로 표현할 수 있고, 이러한 표현의 차이는 해당 인물에 대한 시민의 평가요소에 큰 부분을 차지한다.
인터넷 발달과 개인화의 고도화에 따른 현대사회는 지류로 된 신문이나, 송출 기반의 성격을 가진 Broadcast 방식을 띈 TV에서 언제든지 사건에 대한 컨텐츠를 소비할 수 있는 Unicast 플랫폼으로 확대되었다.
현재 언론사들의 사건보도에 대한 연구의 비판은 주관적이거나 편향된 용어의 사용, 유도적이거나 편향적인 해석과 설명, 표현 방식에서의 신중함이 부족하다는 선행 연구 결과를 확인했다.
따라서 대표적인 Unicast 플랫폼 매체인 ‘Youtube’를 선정하여 12월 3일 발생했던 비상계엄에서 한 달동안 이르는 사건의 타임라인에 대한 언론별 단어선택에서 나타나는 정치적 편향을 텍스트 마이닝 기법을 이용해 분석할 예정이다.
1.2. 연구 문제
다음 프로젝트에서 주로 다룰 연구 문제는 다음과 같다.
- 동일한 사건의 보도에 대한 단어 선택의 차이는 언론사별 차이가 나타나는가?
- 사건에 대한 단어 선택의 차이는 시기별로 어떠한 차이를 보이는가?
- 사건에 대한 단어 선택의 차이는 여론과 연관성이 있는가?
1.3. 연구 방법
텍스트 마이닝 기법을 통해 분석을 진행할 것이고, 다음과 같다.
- 텍스트 데이터 처리 및 분석
- wordcloud를 통한 단어빈도 분석 시각화
- 네트워크 분석을 통한 텍스트에서 나타나는 단어들과의 관계 분석
- 감성 사전을 기반으로 한 감성 분석
1.4. 데이터 수집
1) 수집 대상:
대중에게 영향력이 있으며, 신뢰도가 있는 유튜브 뉴스 보도 채널에 업로드 된 영상의 보도 제목
방송국을 가지고 있으며, 구독자 수가 많은 9개 방송국 선정
[' YTN', 'JTBC News', 'KBS News', 'MBCNEWS', 'MBN News', 'SBS 뉴스', '뉴스TVCHOSUN', '연합뉴스TV', '채널A News']
2) 수집 기간:
사건 발생 시간을 기준으로 2024.12.03 10:00 ~ 2025.12.29 23:59 기간 동안 수집
2. 데이터 수집
2.1. 유튜브 API 호출하기
먼저 데이터를 수집하기 위해 유튜브 API 라이브러리 중 'YouTube Data API v3'을 사용하였다.
또한 구글 드라이브에 파일을 저장하고자 한다.
from googleapiclient.discovery import build from google.colab import drive drive.mount('/content/drive') # 개인 API 키를 통해 유튜브 API 연결 youtube = build('youtube', 'v3', developerKey = '#개인 API 키')
- api 키를 받는 방법은 다음과 같은 출처에서 잘 정리되어있다.
[Spring Boot3] 초간단 Youtube Api 사용법 (Feat. 검색 기능을 구현해보자)
[미니프로젝트] 데이터 수집 - Youtube API에 관련한 유튜브 문서
Youtube > Data API
주의사항:
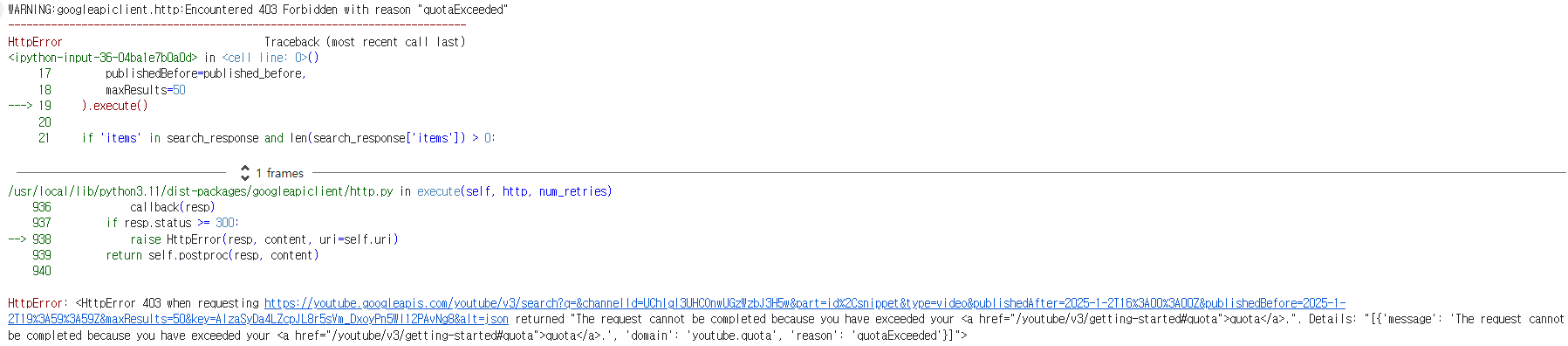
YouTube API에서 데이터를 추출할 때 쿼터 제한(Token Limit)이 적용된다. YouTube Data API v3는 일일 10,000 쿼터 단위를 제공하며, 각 API 요청마다 다른 비용(쿼터 사용량)이 한다.
용량 초과했을 때 다음과 같은 오류가 발생한다.
2.2. 원하는 채널 및 기간 설정
2.2.1. 수집하고 싶은 채널과 수집기간을 설정
(일일 토큰 할당량을 고려해 4시간을 기준으로 기간을 설정했다.)
published_after = '2024-12-2T19:00:00Z' published_before = '2024-12-2T23:59:59Z' channel_id =['@MBCNEWS', '@ytnnews24', '@sbsnews8', '@jtbc_news', '@newskbs', '@channelA-news', '@tvchosunnews', '@mbn', '@yonhapnewstv23']
2.2.2. 원하는 채널명 ID 추출.
# 추출 원하는 채널 ID 추출하는 방법 User_ids = [] # 채널 핸들에서 ID 추출 for channel in channel_ids: Id_response = youtube.search().list( part="snippet", q=channel, type="channel", maxResults=1 ).execute() # 검색 결과에서 채널 ID 추출 if 'items' in Id_response and len(Id_response['items']) > 0: channel_id = Id_response['items'][0]['snippet']['channelId'] User_ids.append(channel_id)
2.2.3. 설정한 날짜에 업로드 된 채널 제목 추출.
# 설정한 날짜에 업로드된 채널영상 추출 # 채널 정보를 저장할 딕셔너리 channel_info = { 'channel_titles': [], 'channel_names': [], 'channel_times': [] } # 각 채널에 대해 동영상 검색 for channel in channel_ids: search_response = youtube.search().list( q='', channelId=channel, part='id,snippet', type='video', publishedAfter=published_after, publishedBefore=published_before, maxResults=50 ).execute() if 'items' in search_response and len(search_response['items']) > 0: for item in search_response['items']: # 필요한 정보를 추출 channel_name = item['snippet']['channelTitle'] channel_time = item['snippet']['publishTime'] channel_title = item['snippet']['title'] # 추출한 데이터를 리스트에 추가 channel_info['channel_titles'].append(channel_title) channel_info['channel_names'].append(channel_name) channel_info['channel_times'].append(channel_time)
2.2.4. 수집한 데이터를 .csv 형식 저장
# CSV 파일 형식으로 저장 # 저장할 폴더 및 파일 경로 설정 folder_path = '/content/drive/My Drive/Colab Notebooks/News_Datasets' # 저장 경로 설정 os.makedirs(folder_path, exist_ok=True) csv_filename = os.path.join(folder_path, 'News_Data_20250102_4.csv') # 데이터프레임을 CSV로 저장 News_Data.to_csv(csv_filename, index=False, encoding='utf-8-sig')
2.2.5. 시간대 별로 수집한 .csv파일 모으기
# 통합 CSV 저장 folder_path = '/content/drive/My Drive/Colab Notebooks/News_Datasets' csv_files = [f for f in os.listdir(folder_path) if f.endswith('.csv')] df_list = [] for file in csv_files: file_path = os.path.join(folder_path, file) df = pd.read_csv(file_path, index_col=0) # 첫 번째 컬럼을 인덱스로 설정 df_list.append(df) merged_df = pd.concat(df_list, axis=0) output_path = "/content/drive/My Drive/Colab Notebooks/sum/intergrated_data.csv" merged_df.to_csv(output_path, encoding='utf-8-sig')
