3. 데이터 전처리
총 세 가지 분석을 진행할 것이다.
- 단어 빈도에 따른 wordcloud
- 네트워크 분석
- 감성 분석
우선 데이터 전처리 및 분석에 필요한 라이브러리를 호출 및 다운로드한다.
!pip install --upgrade pip !pip install kiwipiepy !pip install wordcloud !apt-get update -qq !apt-get install fonts-nanum -qq > /dev/null font_path = "/usr/share/fonts/truetype/nanum/NanumGothic.ttf" import pandas as pd import os from google.colab import drive from kiwipiepy import Kiwi from kiwipiepy.utils import Stopwords import re import nltk from nltk.corpus import stopwords from wordcloud import WordCloud import matplotlib.pyplot as plt import matplotlib.font_manager as fm from collections import Counter from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score import numpy as np import networkx as nx
3.1. 수집한 데이터 불러오기 및 형식 맞추기
#객체 생성 kiwi = Kiwi() stopwords = Stopwords() # 구글 드라이브에 연결 drive.mount('/content/drive') #파일 경로 설정 file_path = '/content/drive/My Drive/Colab Notebooks/sum/intergrated_data.csv' #csv 파일을 호출해 형식 맞추기 raw_data = pd.read_csv(file_path) raw_data.set_index("Channel_ID", inplace=True) #ISO 8601 형식 데이터를 판다스 시계열(DateTime) 데이터로 변환 raw_data['Upload_Date'] = pd.to_datetime(raw_data['Upload_Date'], errors='raise', utc=True)앞의 객체 생성 부분은 한국어 텍스트 전처리를 위한 형태소분석기인 kiwi라이브러리이다.
(KoNLPy보다 가볍고 최근에 만들어졌으며, 접근성이 편해 사용하였다.)
3.2. 데이터 수집기간 설명 및 방송국 별 보도 제목 분류
# 데이터 수집 기간 설정 start_date = "2024-12-03" end_date = "2024-12-08" Data_12_1 = raw_data[(raw_data["Upload_Date"] >= start_date) & (raw_data["Upload_Date"] <= end_date)] # 방송사 리스트 설정 broadcast = list(Data_12_1.index.unique()) # 방송사별 Video_Title 수집 # 2차원 배열 생성 후 방송국별 방송 보도 제목 리스트에 추가 News_data_12_1 = [[] for _ in range(len(broadcast))] # 2차원 리스트로 각 방송국별 보도 제목이 들어감 for i, channel in enumerate(broadcast): News_data_12_1[i] = Data_12_1[Data_12_1.index == channel]["Video_Title"].tolist()기간 별로 키워드가 다르기 때문에 수집기간을 일주일로 설정했다.
출력 결과
이렇게 YTN의 보도 제목에 대해 추출할 수 있다.

3.3. 형태소 별로 분류하기
# 한글 텍스트 데이터 전처리 filtered_data_12_1 = [[] for _ in range(len(broadcast))] # 특수기호, 띄어쓰기 제거한 리스트 for i in range(len(broadcast)): for j in range(len(News_data_12_1[i])): cleaned_text = re.sub(r'[^\s\w\d]', ' ', News_data_12_1[i][j]) filtered_data_12_1[i].append(cleaned_text) # 리스트 2차원 filtered_data_12_1을 1차원으로 축소 combined_data_12_1 = [" ".join(sublist) for sublist in filtered_data_12_1] # 한글 텍스트 전처리 - tokenization, Pos tagging news_tokens_12_1 = [[] for _ in range(len(broadcast))] # 형태소로 분류한 문장을 불용어를 제외하고 리스트에 추가 for i in range(len(broadcast)): kiwi_tokens = kiwi.tokenize(combined_data_12_1[i], stopwords =stopwords) news_tokens_12_1[i].append(kiwi_tokens) # 형태소 중 명사만을 추출 Featured_POS = ['NNG','NNP', 'NNB'] news_noun_12_1 = [[] for _ in range(len(broadcast))] # 명사만을 추출한 형태소들을 2차원 리스트에 추가. for i in range(len(broadcast)): for sentence in news_tokens_12_1[i]: for token in sentence: if token.tag in Featured_POS: news_noun_12_1[i].append(token.form) # 불용어 사전 이외에 주제와 상관 없는 불용어 제외 for i in range(len(broadcast)): news_noun_12_1[i] = [word for word in news_noun_12_1[i] if word not in customized_stopwords]형태소 분석을 위해 다음과 같은 전처리를 진행했다.
- 특수기호, 띄어쓰기를 제거한다.(영어의 경우 대문자 ->소문자 변경 작업 필요)
- 형태소 분석기를 통해 형태소를 분류한다.
- 분류된 형태소 중 명사를 추출한다.
- 불용어 사전에 등록(예:('가','같','것','게','겠' 등)불용어, 주제와 상관 없는 단어인 불용어(날씨, 주가 / 개인 설정)를 제외한다.
출력 결과
다음은 (12.3~12~8)기간 동안 YTN 방송국 보도 제목의 텍스트 전처리를 진행한 결과이다.

# 한글 텍스트 데이터 전처리 (각 제목별로 개별 처리) filtered_data_12_1_f = [[] for _ in range(len(broadcast))] # 특수기호, 띄어쓰기 제거한 리스트 for i in range(len(broadcast)): for j in range(len(News_data_12_1[i])): # 각 방송국의 뉴스 제목별 처리 cleaned_text = re.sub(r'[^\s\w\d]', ' ', News_data_12_1[i][j]) # 특수기호 제거 filtered_data_12_1_f[i].append(cleaned_text) # 개별 뉴스 제목 단위로 저장 # 한글 텍스트 전처리 - Tokenization, POS tagging (개별 뉴스 제목 단위) news_tokens_12_1_f = [[] for _ in range(len(broadcast))] for i in range(len(broadcast)): for j in range(len(filtered_data_12_1_f[i])): # 각 방송국의 각 제목에 대해 처리 kiwi_tokens = kiwi.tokenize(filtered_data_12_1_f[i][j], stopwords=stopwords) news_tokens_12_1_f[i].append(kiwi_tokens) # 개별 뉴스 제목 단위로 형태소 저장 # 형태소 중 명사만을 추출 (개별 뉴스 제목 단위) Featured_POS = ['NNG', 'NNP', 'NNB'] # 일반 명사, 고유 명사, 의존 명사 news_noun_12_1_f = [[] for _ in range(len(broadcast))] for i in range(len(broadcast)): for j in range(len(news_tokens_12_1_f[i])): # 각 방송국의 각 제목별로 처리 nouns = [token.form for token in news_tokens_12_1_f[i][j] if token.tag in Featured_POS] news_noun_12_1_f[i].append(nouns) # 개별 뉴스 제목 단위로 명사 리스트 저장 # 불용어 제거 (개별 뉴스 제목 단위) for i in range(len(broadcast)): for j in range(len(news_noun_12_1_f[i])): # 각 방송국의 각 제목별로 처리 news_noun_12_1_f[i][j] = [word for word in news_noun_12_1_f[i][j] if word not in customized_stopwords]다음은 네트워크 분석을 위해 방송국별로 제목별 분류하기 위한 코드로 위의 코드와 약간 변형했다.
출력 결과
4. 데이터 분석
데이터 분석은 연세대학교 이상엽 교수님의 유튜브 채널에 있는 텍스트 분석을 참고하였다.
텍스트 분석 (텍스트 마이닝)
4.1. 빈도 분석 - wordcloud
# wordcloud 생성 for i in range(len(broadcast)): news_words = ' '.join(news_noun_12_1[i]) wordcloud = WordCloud(max_font_size = 100, width=800, height = 600, background_color = 'pink', font_path = font_path) wordcloud.generate(news_words) plt.figure() plt.imshow(wordcloud, interpolation = 'bilinear') plt.axis('off') plt.show()wordcloud 라이브러리는 텍스트 데이터를 시각적으로 표현하는 도구로, 단어들의 빈도수를 기반으로 크기를 조절하여 시각화해주는 라이브러리다. 특히, 자연어 처리(NLP)에서 키워드 분석 및 데이터 시각화에 많이 사용된다.
출력 결과
다음은 YTN에 대한 단어 빈도 분석 결과를 시각화한 것이다.
'탄핵, '대통령', '계엄', '비상계엄' 같이 크기가 큰 단어는 여러 번 언급된 것이다.
이러한 시각화를 통해 일주일 동안의 키워드에 대해 한 눈에 볼 수 있다.

4.2. 텍스트 네트워크 분석
4.2.1. 단어 빈도 수 상위 K개 키워드 추출
def get_words(counter_results): words = [] for word, fre in counter_results: words.append(word) return words # 상위 K개 언급된 단어 추출 news_data_counter = [None] * len(broadcast) for i in range(len(broadcast)): frequency_12_1 =Counter(news_noun_12_1[i]) news_data_counter[i] = get_words(frequency_12_1.most_common(15))위 코드는 보도된 방송국 별로 어떤 단어를 가장 많이 사용했는지에 코드이다.
빈도수 상위 15개에 대한 코드를 출력했다.
출력 결과
다음은 YTN에 대한 보도 제목 단어 빈도수 상위 15개의 출력 결과이다.

4.2.2. 단어 네트워크 구축
def construct_network(text): vectorizer = CountVectorizer(min_df = 1, ngram_range = (1,1)) DTM_tf = vectorizer.fit_transform(text) feature_names = vectorizer.get_feature_names_out() DTM = np.array(DTM_tf.todense()) DTM_binary = np.sign(DTM) words_cooccurrence = np.dot(DTM_binary.T, DTM_binary) np.fill_diagonal(words_cooccurrence, 0) g = nx.convert_matrix.from_numpy_array(words_cooccurrence) mapping = {} for k, word in enumerate(feature_names): mapping[k] = word g1 = nx.relabel_nodes(g, mapping) return g1 new_sentences = [[] for _ in range(len(news_noun_12_1_f))] # 방송국별 결과 저장 리스트 for i in range(len(news_noun_12_1_f)): # 방송국별 루프 for sentence in news_noun_12_1_f[i]: # 각 방송국의 뉴스 제목 리스트 순회 new_sentence = [word for word in sentence if word in news_data_counter[i]] # 빈도 높은 단어만 선택 if len(new_sentence) > 1: # 단어가 2개 이상이면 채택 new_sentences[i].append(' '.join(new_sentence)) # 단어들을 하나의 문장으로 조합 network = construct_network(new_sentences[8])위 코드는 단어 연결 네트워크를 구축하기 위한 코드이다.
- 텍스트를 벡터화 (CountVectorizer)
문장 데이터를 DTM(Document-Term Matrix)으로 변환
단어별 등장 횟수 카운트- 동시 출현 행렬(Co-occurrence Matrix) 생성
단어 간 연관성 계산 (np.dot(DTM_binary.T, DTM_binary))
같은 문장에서 함께 등장한 단어쌍을 그래프 노드로 설정- networkx 그래프 변환
단어 간 연결을 기반으로 네트워크 그래프 생성- g1 = nx.relabel_nodes(g, mapping): 숫자 노드를 단어로 변경
4.2.3. 네트워크 그래프 그리기
# 네트워크 그래프 그리기 font_path = "/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf" font_prop = fm.FontProperties(fname=font_path) # Matplotlib에 폰트 적용 plt.rc('font', family=font_prop.get_name()) plt.rcParams['axes.unicode_minus'] = False # 마이너스 부호 깨짐 방지 # 네트워크 그래프 그리기 nx.draw_networkx(network, with_labels=True, font_family=font_prop.get_name()) # ✅ 폰트 적용 plt.show()다음은 네트워크 그래프를 그리는 코드이다.
여기서 한글이 깨지게 나오는데, 한글 폰트를 다운받고, 경로를 설정해야한다.
(colab의 경우 한글 폰트를 다운받은 다음에 런타임을 다시해야 한글이 나온다.)
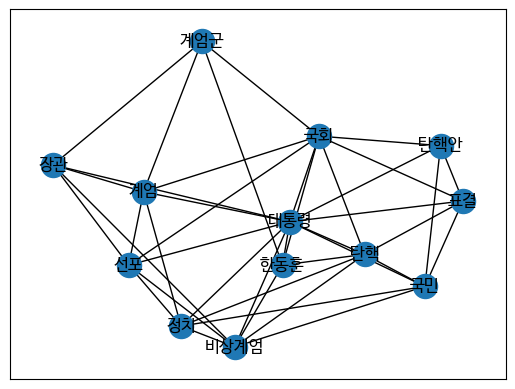
출력 결과
다음은 방송사 chanel A의 텍스트 네트워크 분석이다.
'계엄군', '장관', '계엄' 부분을 노드라고 하고, 노드 간의 실선을 엣지라고 한다.
matplotlib을 통해 그린 그래프만 보아서는 키워드의 중요성, 키워드 간의 연결 관계 등을 확인할 수 없다.
# 구글 드라이브에 연결 drive.mount('/content/drive') #파일 경로 설정 graphml_path = '/content/drive/My Drive/Colab Notebooks/network_채널A News.graphml' nx.write_graphml(network, graphml_path)위 코드를 통해 해당 그래프를 저장한다.
저장한 그래프(.graphml)을 통해 Gephi는 네트워크 그래프 분석 및 시각화 도구인 게피(Gephi) 에서 시각화 작업을 한다.
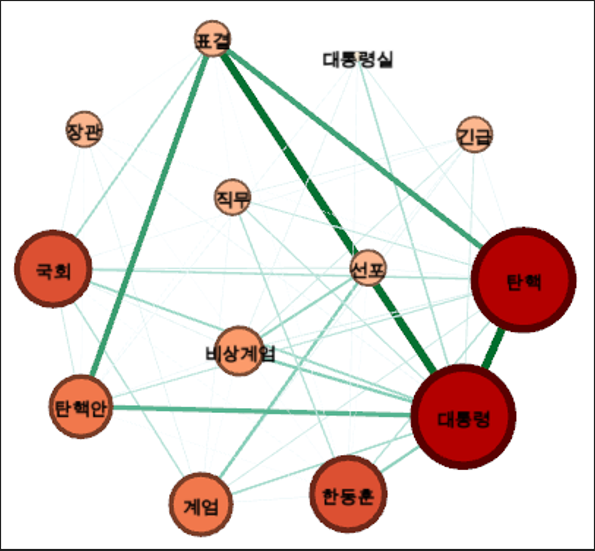
출력 결과
다음은 SBS 방송국에 대한 시각화 결과이다.
노드의 크기를 통해 '대통령', '탄핵', '국회' 등의 키워드가 자주 언급됨을 알 수 있다.
엣지가 두꺼운 '대통령-탄핵','대통령-선포' 는 두 키워드 사이의 연결 관계가 강한 것을 의미한다.
4.3. 감성어 사전 기반 감성 분석
4.3.1. 감성 분석 방법 선택
감성 분석은 크게 두 가지로 머신러닝을 통한 판별과 사전 기반 판별 방법으로 분석 가능하다.
머신러닝을 통한 감성분석은 감성의 극성과 정도성이 매겨진 ‘훈련자료’를 통해 분석기가 긍정, 또는 부정의 표현을 학습하고, 학습된 결과를 통해 분석 자료의 감성 극성 정도를 판별한다.
-
장점: 학습을 바탕으로 하기에 기존의 탐구되지 않은 분야의 자료나 시의적인 대상의 감성을 판별하는데 유리
-
단점: 학습을 위한 자료를 사전에 마련해야하고, 학습되지 않은 분야의 자료에 대한 대상의 분석의 정확도는 떨어짐(예: 영화 리뷰의 평점을 기반으로 정답 세트를 분류 후 학습)
사전 기반 판별은 문장 또는 단어의 극성을 사전에 정의하고 각각에 정도성을 부여한 감성사전(sentiment lexicon)을 이용하여 감성 점수를 산출하는 것이다.
- 장점: 범용적인 어휘를 기반으로 구축된 사전을 이용하기에 다양한 주제 영역에서 활용할 수 있어, 다양한 이슈와 주제를 다루는 언론 보도를 분석하는데도 적합한 것으로 판단된다.
주제의 도메인과 분석자의 필요에 따라 사전의 어휘를 확장하거나 변형할 수 있다. - 자연어의 수많은 어휘와 다양한표현 형태를 담은 사전을 마련하는데 많은 시간과노력이 요구된다. 또한, 특정한 어휘나 표현이 자주 사용되는 분야의 텍스트에서는 오히려 판별력이 떨어질 우려가 있다
따라서 내가 하고자 하는 주제는 정치 성향에 대한 정답 데이터 세트가 없기 때문에 머신러닝을 통한 감성분석에는 한계가 있다고 판단해 감성어 사전을 통해 감성 점수를 산출해 분석을 진행할 예정이다.
다음은 - 논문 [최창식, 임영호. (2021). 대통령 관련 보도의 감성 분석과 정파성의 지형 : 신문별 감성지수의 차이, 일관성, 대통령 지지도와의 관계를 중심으로. 한국언론학보, 65(1), 35-70. 10.20879/kjjcs.2021.65.1.035]의 기사의 감성지수에 대한 식이다. 이를 이용해 방송사별 감성지수를 비교할 예정이다.
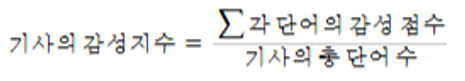
4.3.2 키워드에 맞는 단어 분류
def filter_news_by_keywords_3d(news_noun_12_1_s, news_data_counter_s): """ 방송국별 뉴스 제목에서 키워드가 포함된 제목만 선택하여 3차원 리스트로 반환하는 함수. - news_noun_12_1_s: 방송국별 뉴스 제목 리스트 (3차원 리스트) - news_data_counter_s: 방송국별 키워드 리스트 (2차원 리스트) Returns: - 필터링된 방송국별 뉴스 제목 리스트 (3차원 리스트) """ filtered_news_s = [] for station_news, keywords in zip(news_noun_12_1_s, news_data_counter_s): if not keywords: # keywords가 None 또는 빈 리스트라면 건너뛰기 filtered_news_s.append([]) # 빈 리스트 추가 (3D 구조 유지) continue selected_titles = [] for title in station_news: # 제목 내에 키워드 리스트 중 하나 이상 포함된 경우만 선택 if any(word in keywords for word in title): selected_titles.append(title) # 제목을 단어 리스트(2D)로 유지 filtered_news_s.append(selected_titles) # 방송국별 리스트(3D) 유지 return filtered_news_s # 3차원 리스트 유지 filtered_news_3=filter_news_by_keywords_3d(news_noun_12_1_s, news_data_counter_s)위 코드는 방송국별 뉴스 제목에서 키워드가 포함된 제목만 선택하여 분류하는 코드이다.
출력 결과

4.3.3 KNU 감성어 사전을 이용한 감성지수 구하기
import json class KnuSL: def __init__(self, file_path_s): with open(file_path_s, encoding="utf-8-sig", mode="r") as f: self.data = json.load(f) self.senti_dict = {item["word"]: int(item["polarity"]) for item in self.data} def get_sentiment_score(self, word): """단어의 감성 점수를 반환 (없으면 0)""" return self.senti_dict.get(word, 0) def calculate_sentiment_scores(filtered_news_3, senti_analyzer): """ 방송국별 뉴스 제목의 단어를 감성 사전을 기준으로 점수화하여 합산. - filtered_news_3: 방송국별 뉴스 제목의 리스트 (2차원 리스트) - senti_analyzer: KnuSL 클래스의 인스턴스 """ broadcast_scores = [] for broadcast_news in filtered_news_3: total_score = 0 for title in broadcast_news: for word in title: total_score += senti_analyzer.get_sentiment_score(word) broadcast_scores.append(total_score) return broadcast_scores다음은 KNU 감성어 사전을 통해 감성지수를 구하는 과정이다.
- KNU(KNU Korean Sentiment Lexicon): 한국어 감성 분석을 위한 감성 단어 구축, 단어별 긍정(positive) 또는 부정(negative) 감성 점수(-2 ~ +2)를 포함, 텍스트 감성 분석(Sentiment Analysis)에 유용하다.
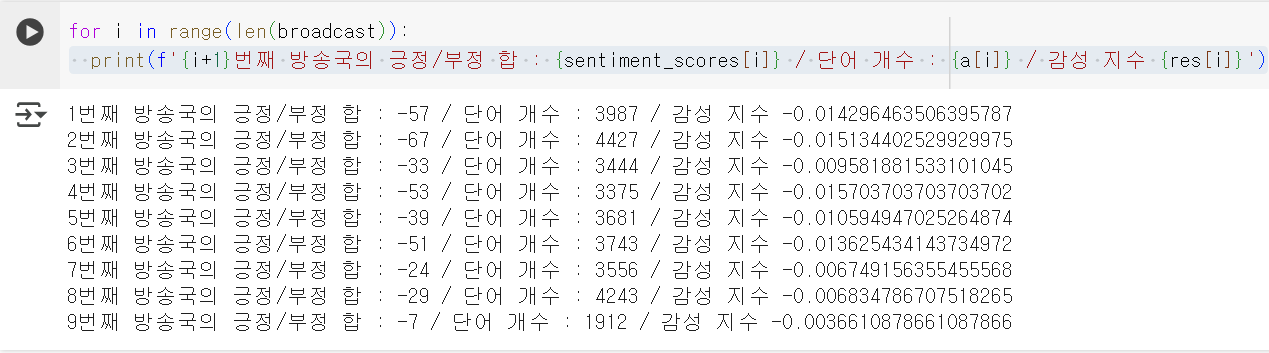
# 감성 사전 JSON 파일 경로 file_path_s = '/content/drive/My Drive/Colab Notebooks/SentiWord_info.json' # 감성 분석기 객체 생성 senti_analyzer = KnuSL(file_path_s) # 감성 점수 계산 sentiment_scores = calculate_sentiment_scores(filtered_news_3, senti_analyzer) # 방송국별 뉴스 제목의 단어 수를 저장할 리스트 a = [0] * len(filtered_news_3) # 3중 루프를 사용하여 방송국별 뉴스 제목 내 단어 개수 합산 for i in range(len(filtered_news_3)): # 방송국 개수만큼 반복 for j in range(len(filtered_news_3[i])): # 방송국 내 뉴스 제목 개수만큼 반복 a[i] += len(filtered_news_3[i][j]) # 제목의 단어 개수를 더하기 res = [0] * len(broadcast) for i in range(len(broadcast)): res[i] = sentiment_scores[i] / a[i] print(res)앞에 있는 함수를 호출해 방송국별 보도 제목의 단어에 대한 긍정-부정 정도를 판별하고, 감성지수를 구한다.
출력 결과
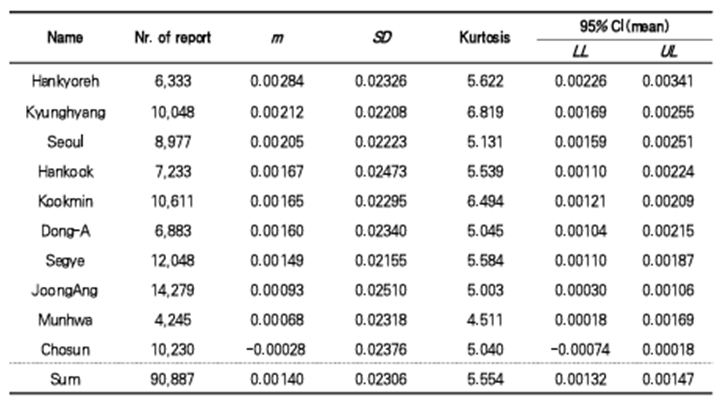
방송국 별로 감성 지수를 구한 결과이다.