[DataFrame]
- 데이터 프레임은 시리즈 데이터 타입들이 모여서 이룬다.
- pd.Series()
- index, value
- pd.DataFrame()
- index, value, column
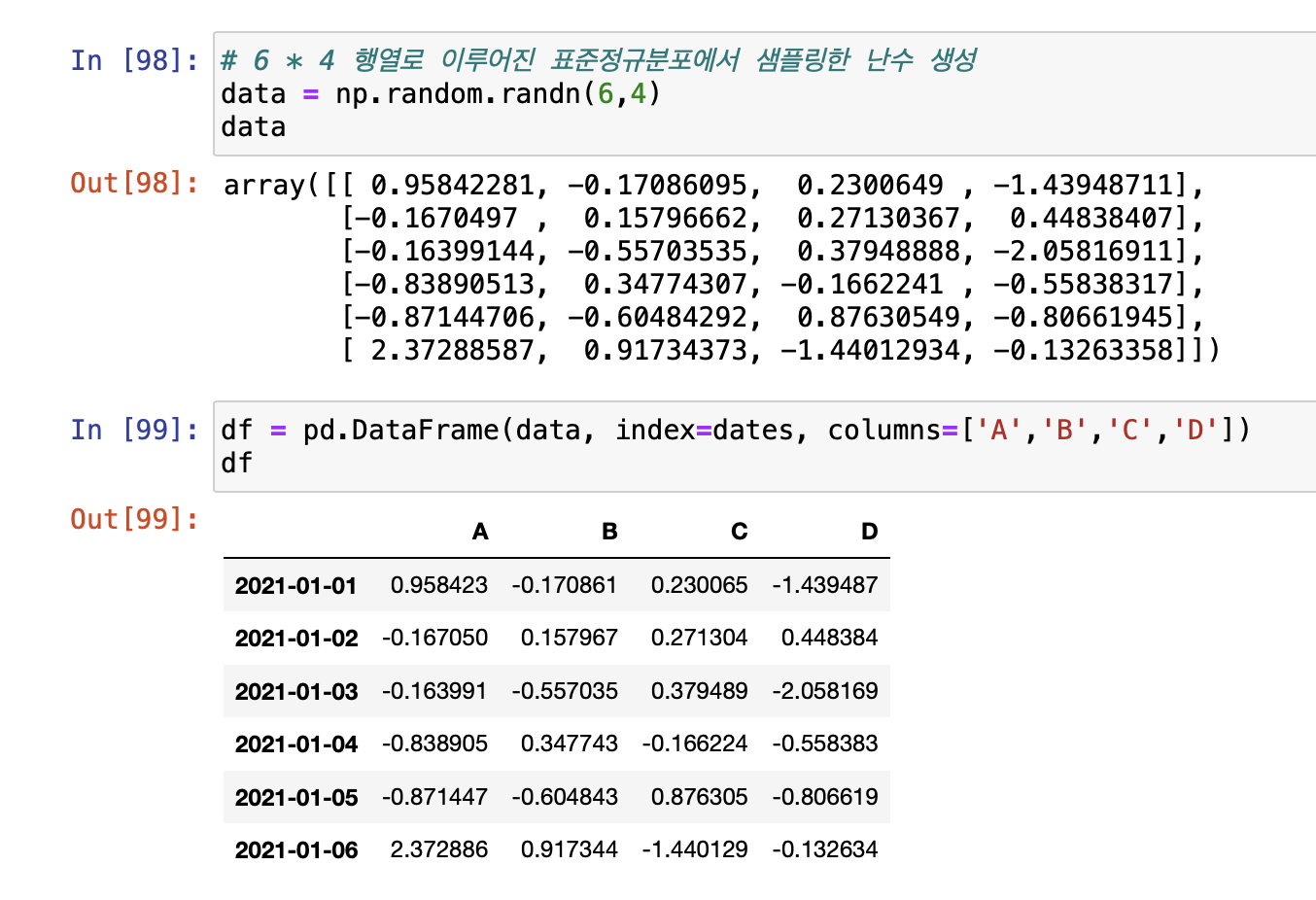
-> 날짜 데이터는 앞서 dates = pd.date_range('20210101', periods=6) 을 통해서 구했다.
[데이터 프레임 정보탐색]
- df.head( ) : 앞의 5개 데이터
- df.tail( ) : 뒤의 5개 데이터
- df.index( ): index 데이터
- df.columns: 컬럼 데이터, 데이터 타입
- df.values: 데이터 내용
- df.info ( ) : 데이터 프레임의 기본 정보 확인
- df.describe ( ) : 데이터 프레임의 기술통계 정보 확인
[데이터 정렬]
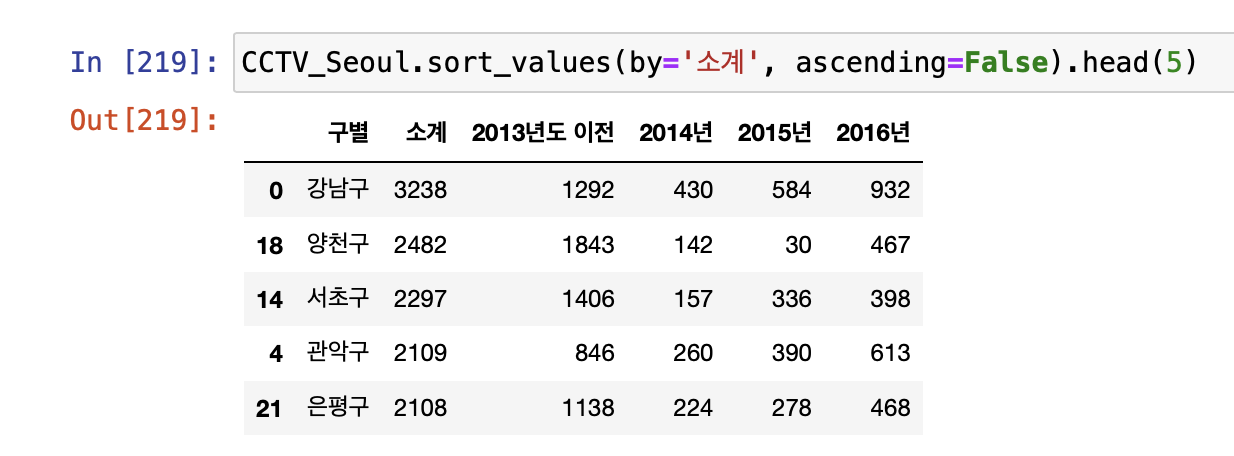
- sort_values( )
- 특정 컬럼(열)을 기준으로 데이터를 정렬한다.
- df
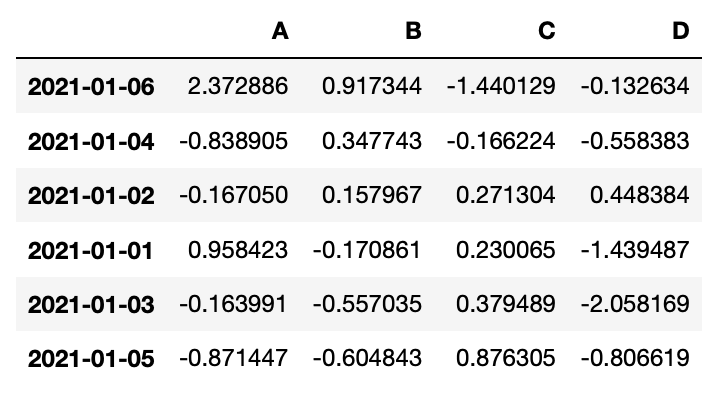
- df.sort_values(by='B', ascending=False, inplace=True
- B컬럼을 기준으로 내림차순해라
- ascending = True는 오름차순, False는 내림차순
- inplace=True를 해줘야 다음 셀에서도 정렬이 적용된다.
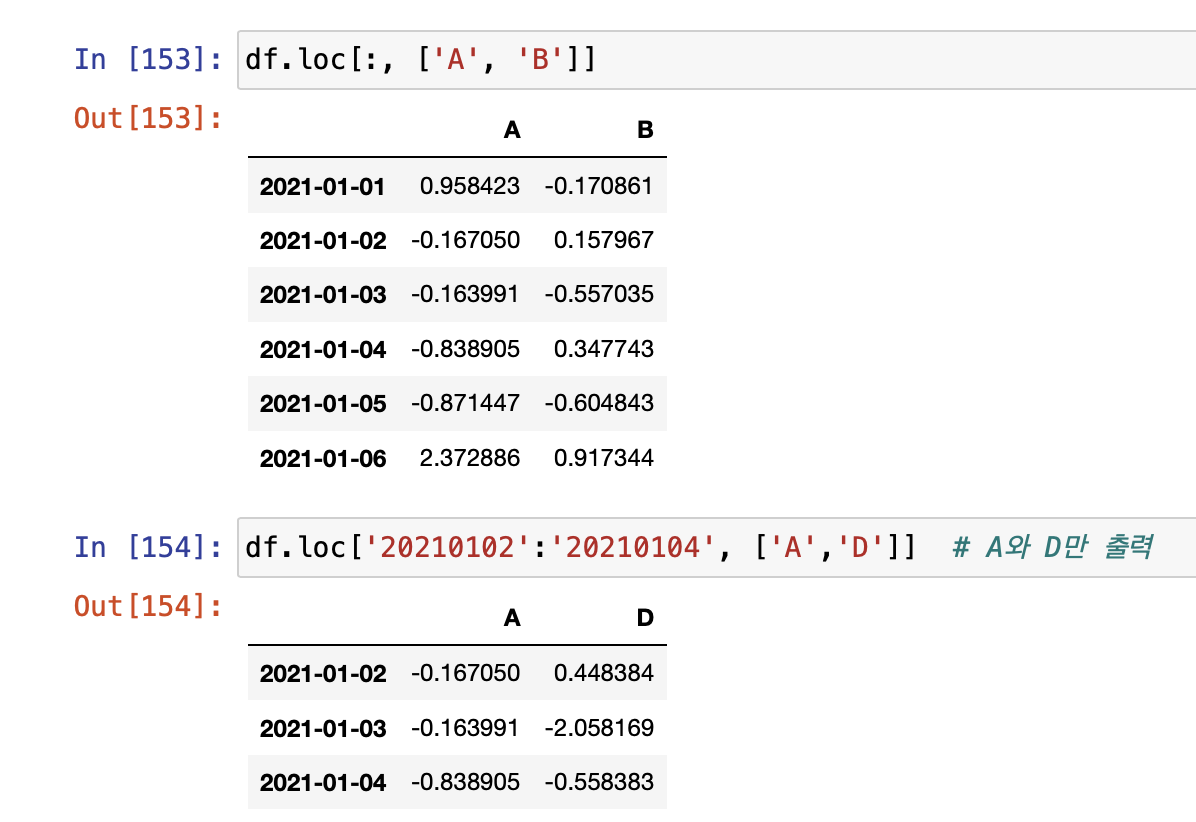
[데이터 선택]
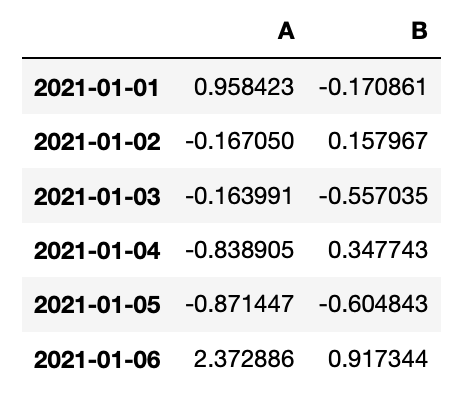
- 한개 컬럼 선택: df['A']
- df.A 도 가능
- 단, 알파벳만 가능하다.
- 두 개 이상 컬럼 선택: df[['A', 'B']]
- 단, 리스트 안에 담아서 실행해야 한다.
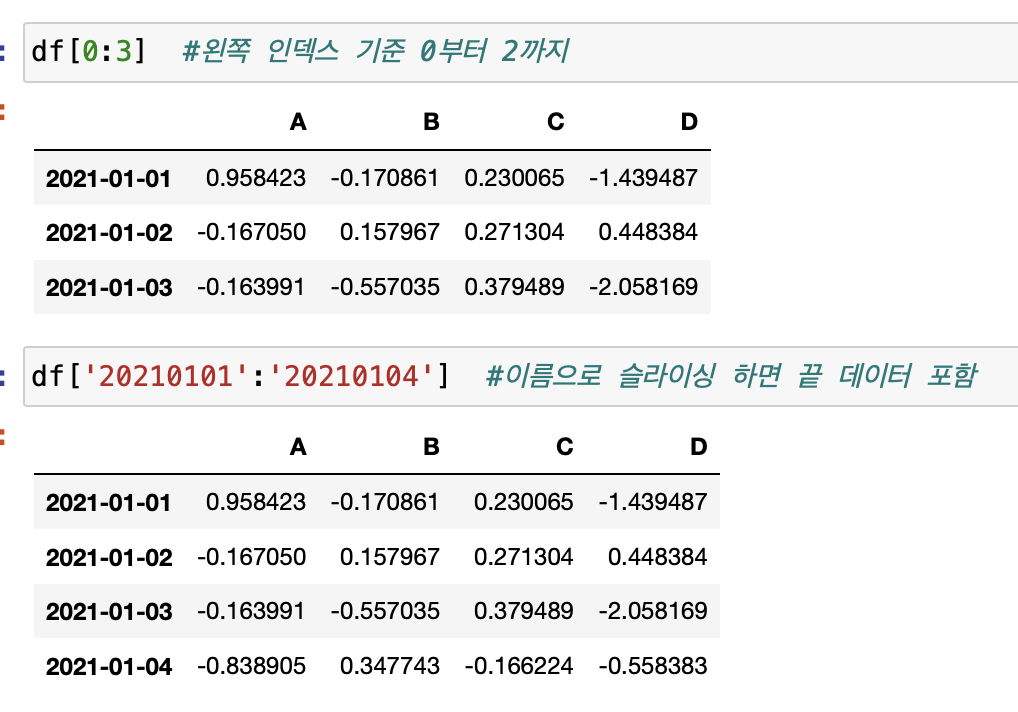
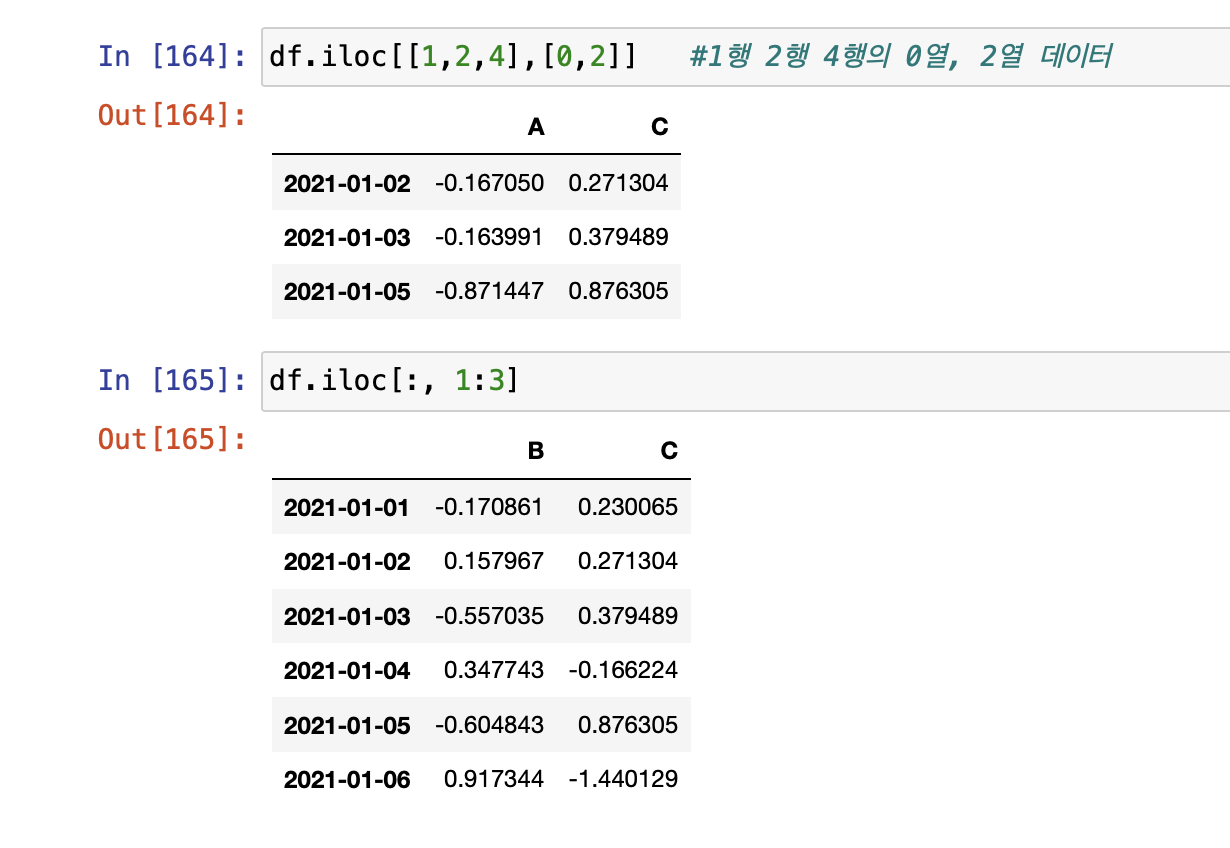
[offset index]
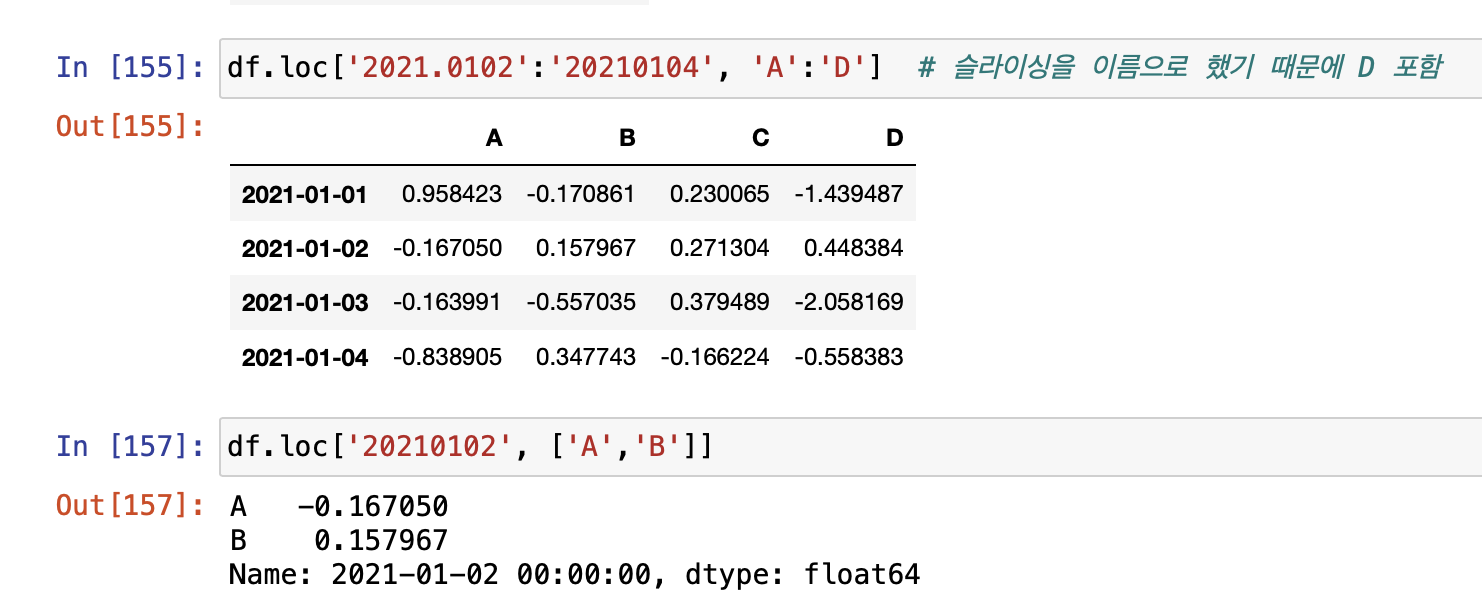
- [n:m]은 n부터 m-1까지 선택
- 인덱스나 컬럼의 이름으로 slice하는 경우는 끝을 포함한다.
- df 먼저 실행
- loc: location
- index 이름으로 특정 행, 열을 선택한다.
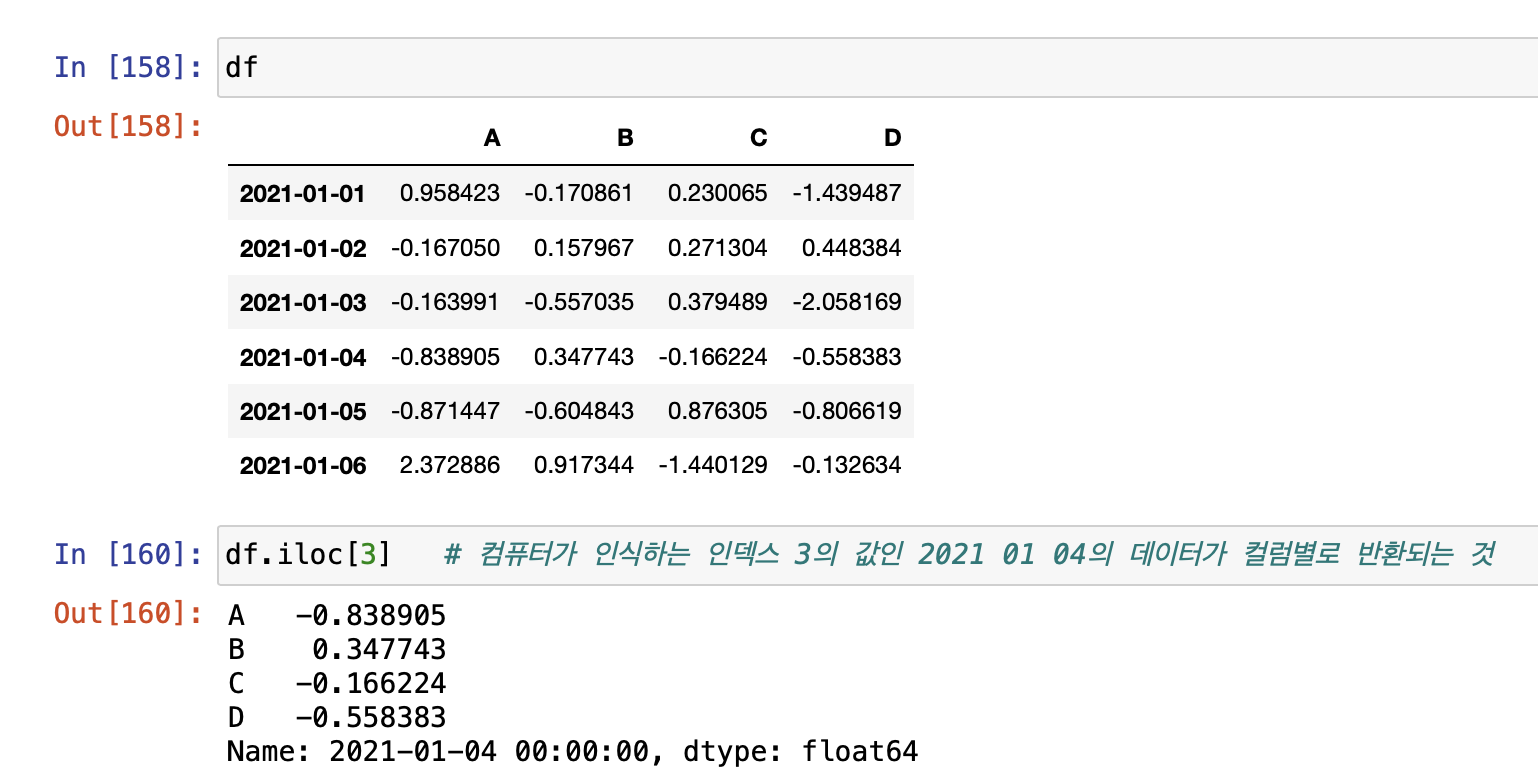
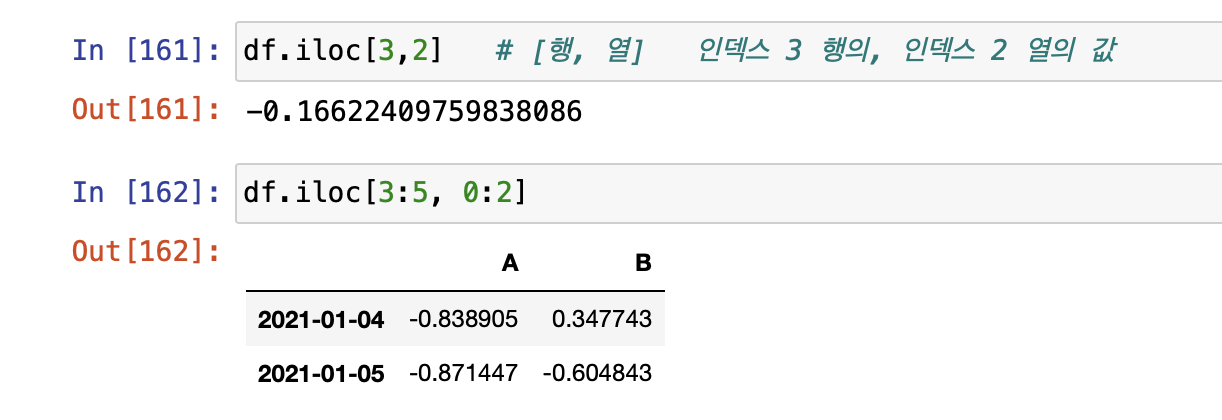
- iloc: inter location
- 컴퓨터가 인식하는 인덱스 값으로 선택
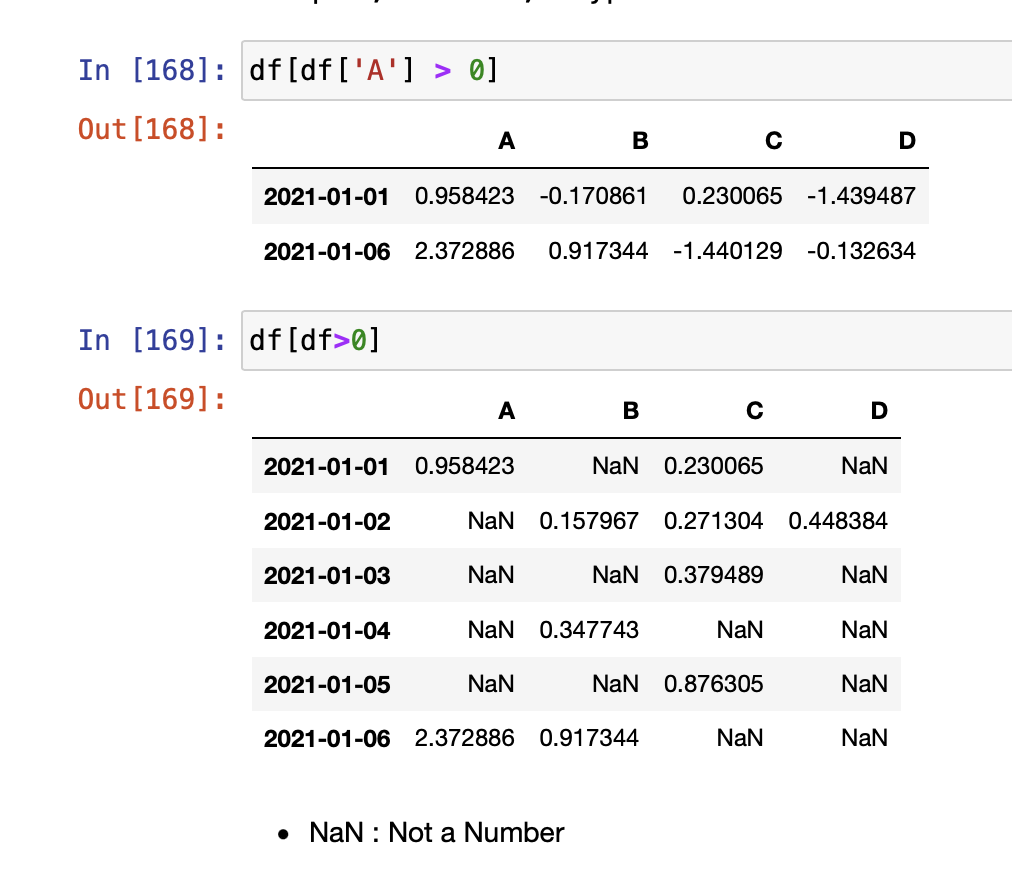
- condition (조건)
- df['A'] > 0
- A 컬럼에서 0보다 큰 숫자(양수)만 선택
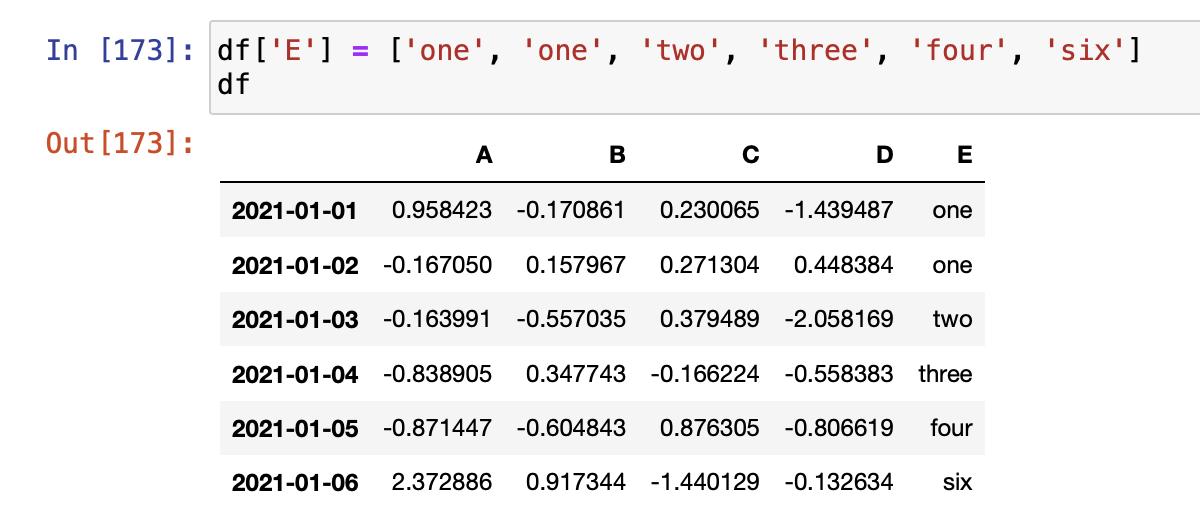
[컬럼 추가]
- 기존 컬럼이 없으면 추가를 하고, 기존 컬럼이 있으면 수정이 된다.
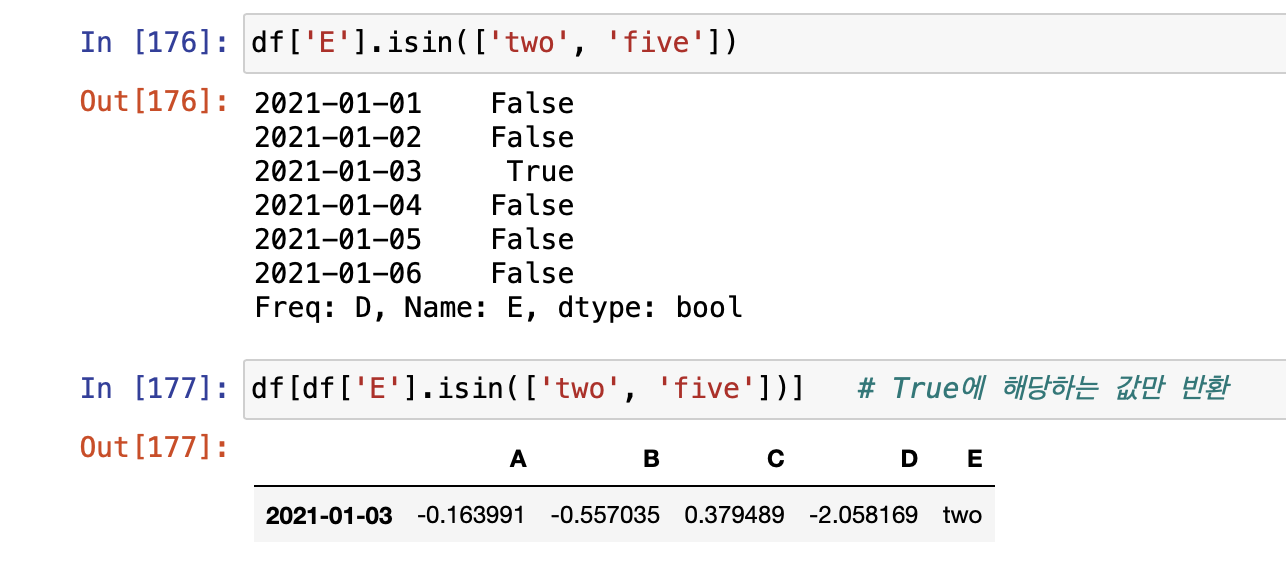
- isin( ) : 특정 요소가 있는지 확인한다.
[특정 컬럼 제거]
- del
- drop
- del
- del df ['E']
- drop
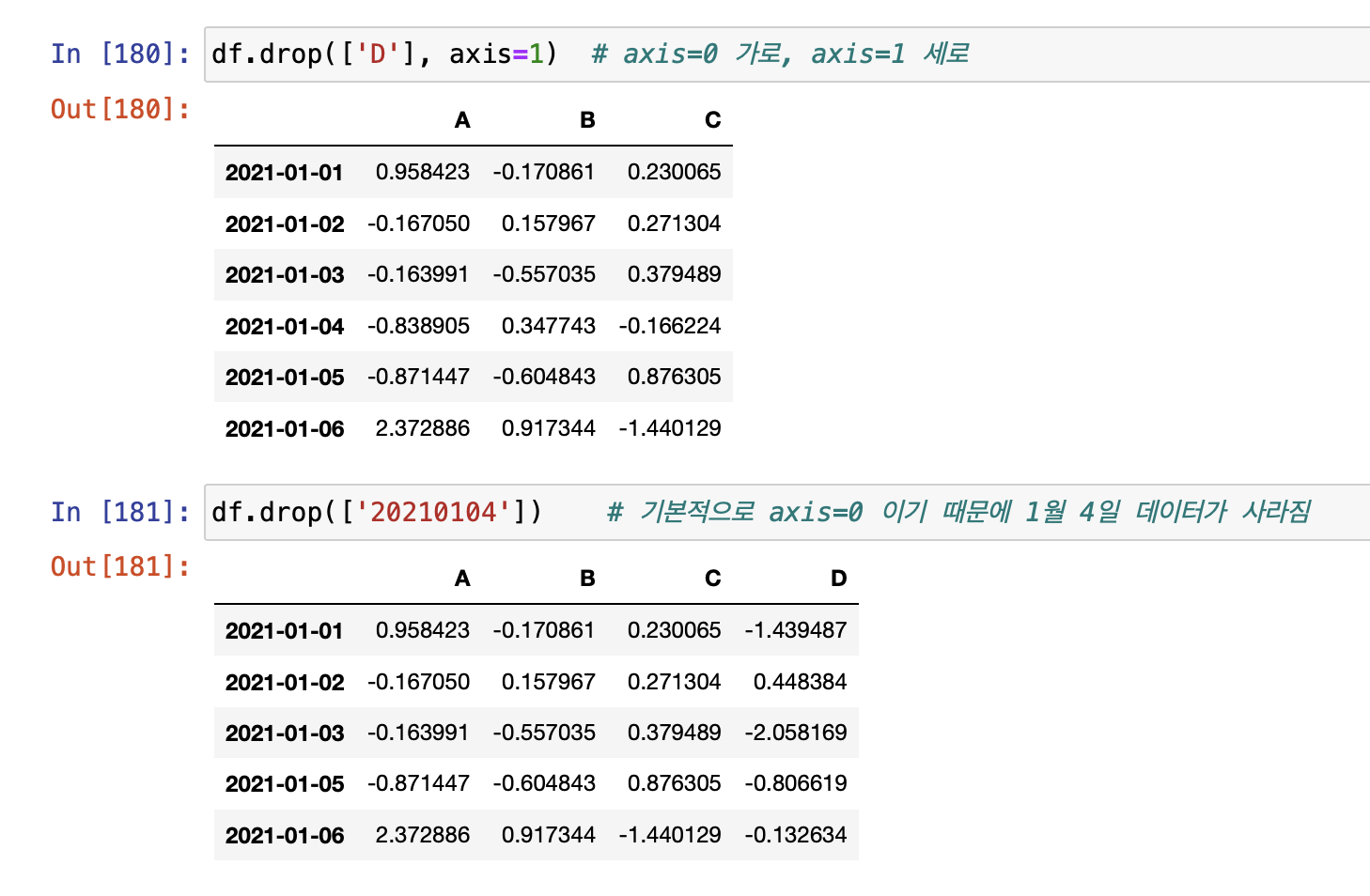
[apply]
- appl( ) 안에 문자열로 기능을 넣어 실행
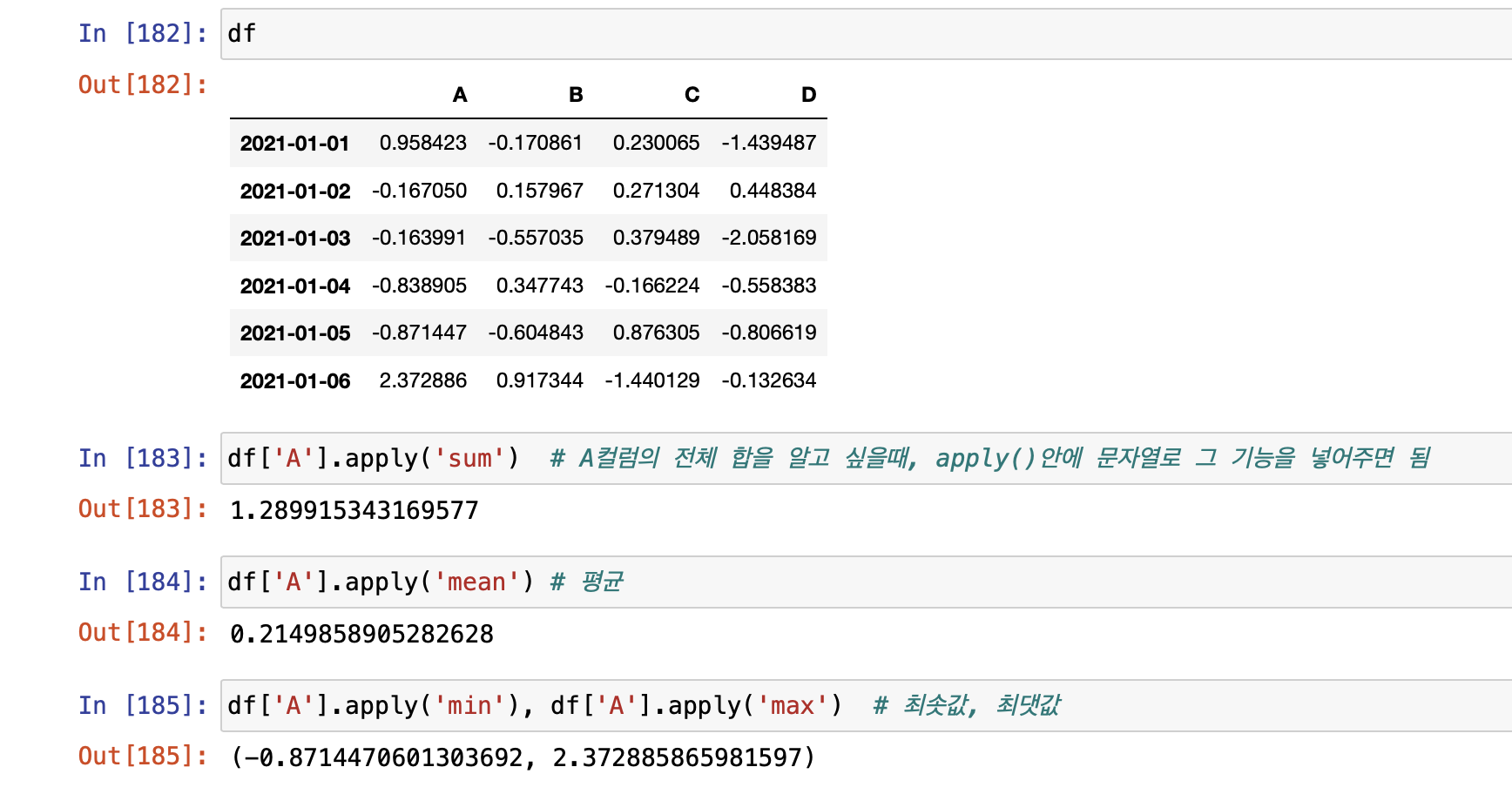
- numpy 기능도 이용 가능
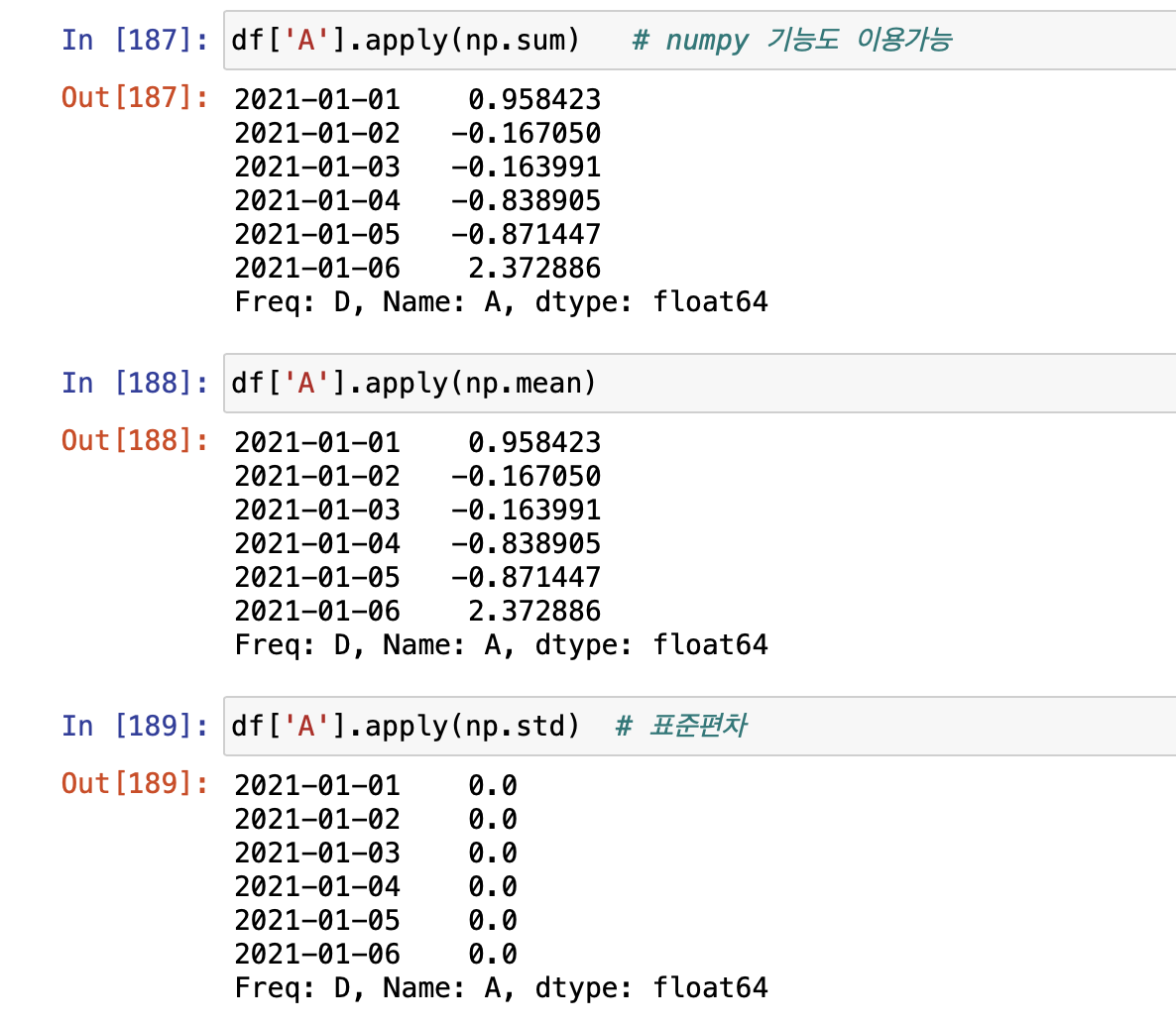
- 직접 만든 함수도 apply 안에 적용 가능
[CCTV 데이터와 인구현황 데이터]
- CCTV 데이터
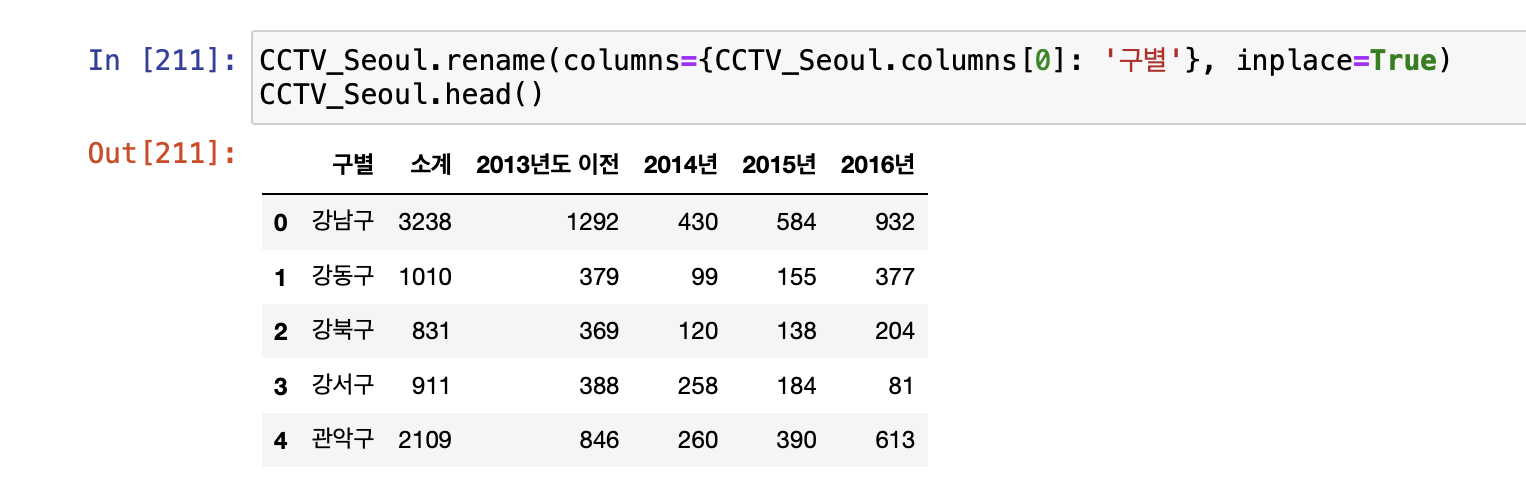
- 기존 컬럼이 없으면 추가, 있으면 수정
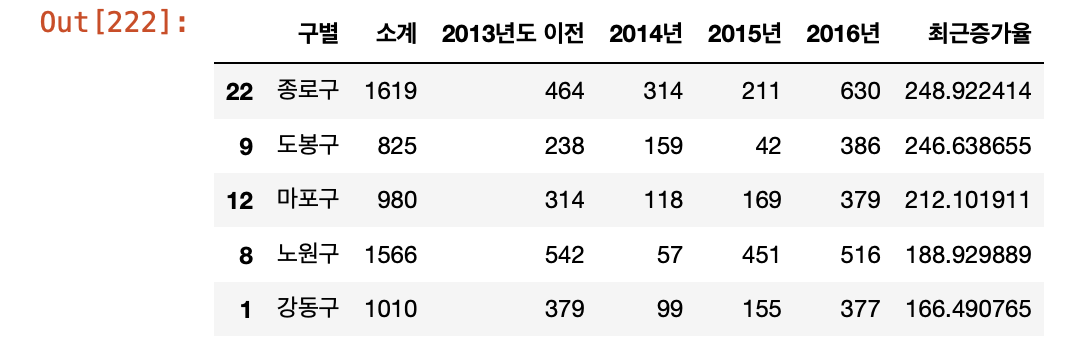
CCTV_Seoul['최근증가율'] = (CCTV_Seoul['2015년'] + CCTV_Seoul['2014년'] / CCTV_Seoul['2013년도 이전']) CCTV_Seoul.sort_values(by='최근증가율', ascending=False).head()
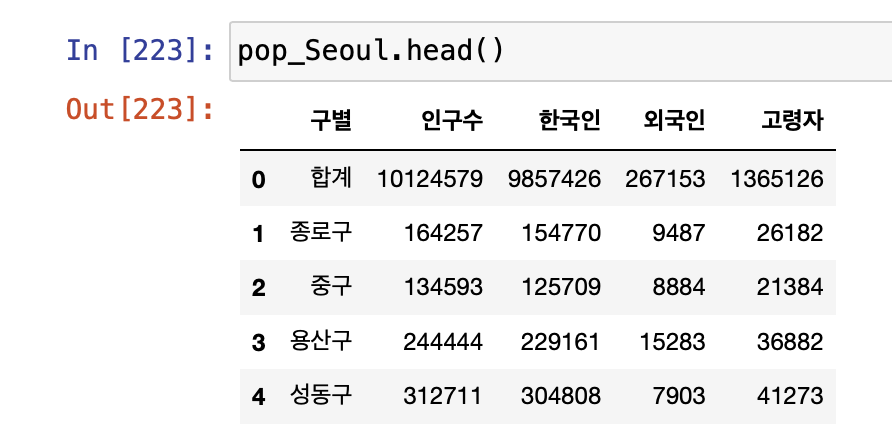
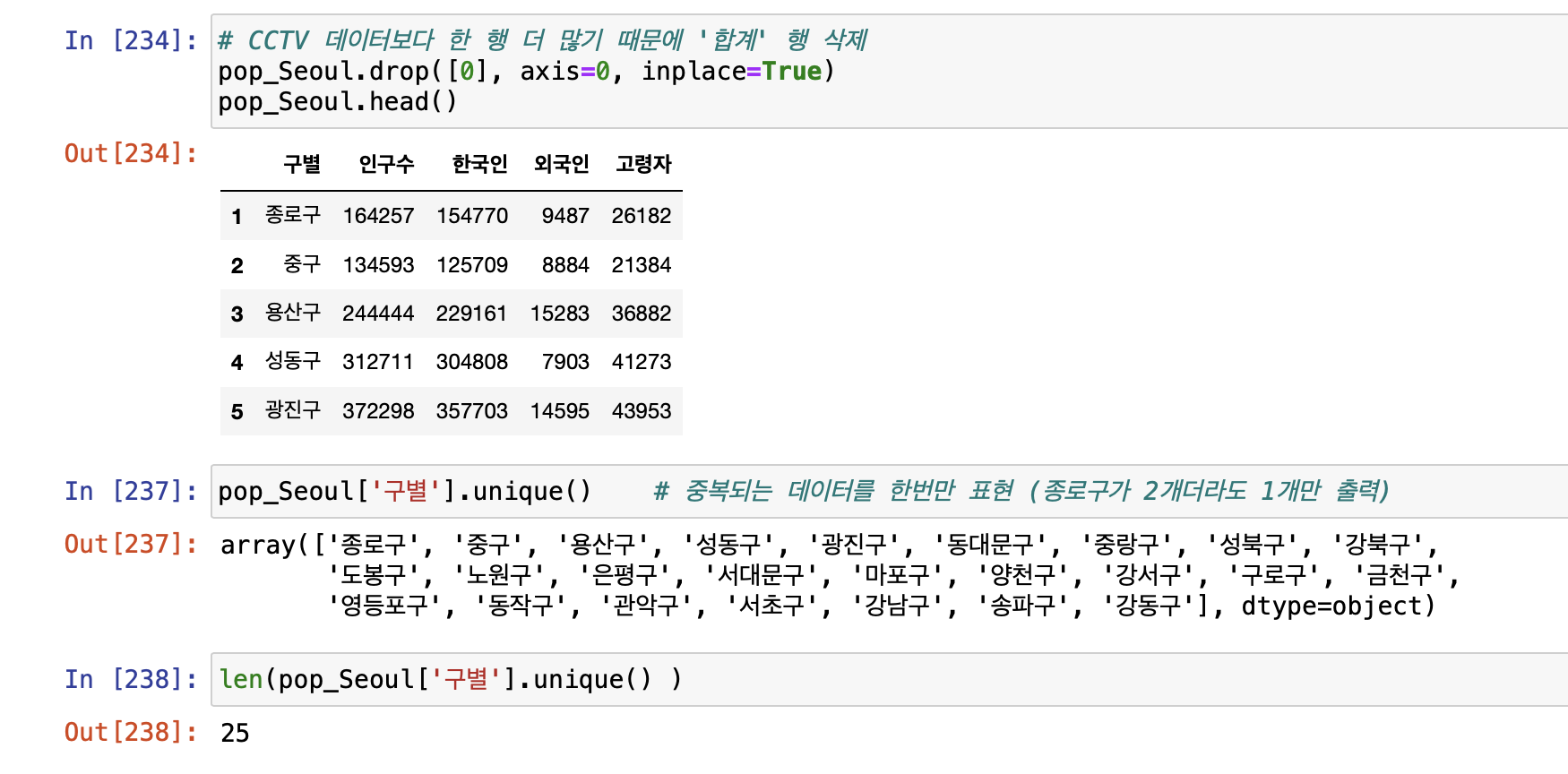
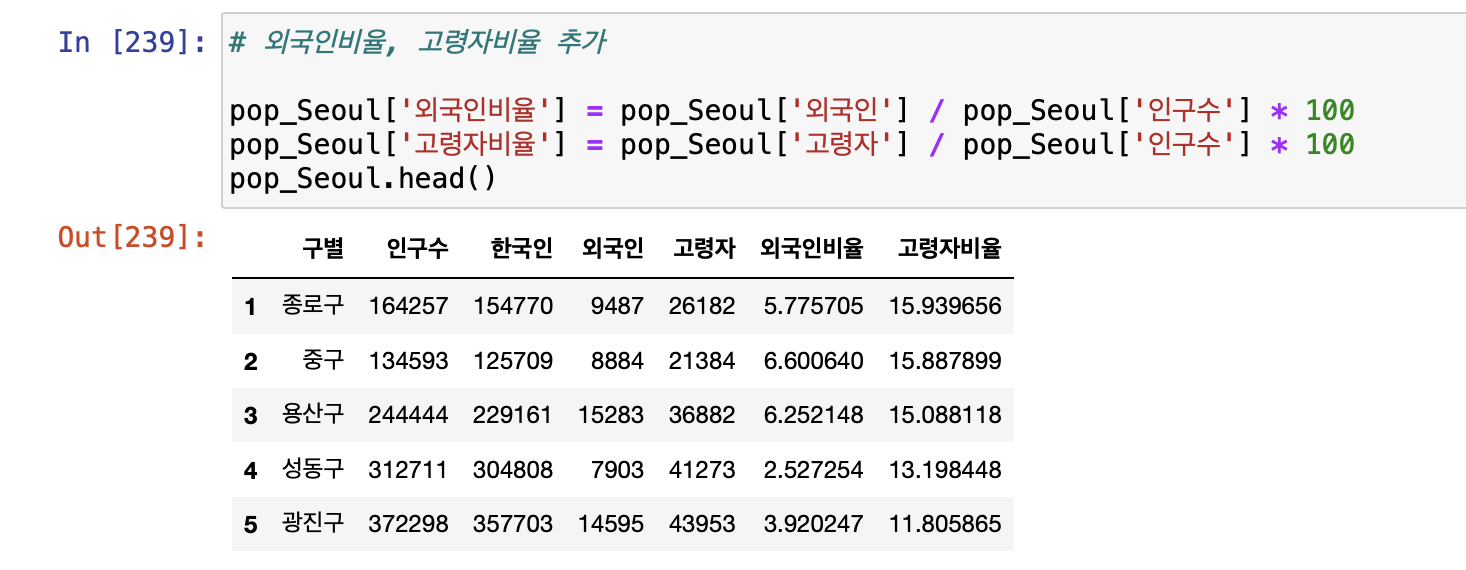
- 인구현황 데이터

늘 온 마음을 다해 :)